德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第七周) - 结构化预测
结构化预测
- 0. 写在大模型前面的话
- 1. 词法分析
- 1.1. 分词
- 1.2. 词性标注
- 2.2. 句法分析
- 2.3. 成分句法分析
- 2.3. 依存句法分析
- 3. 序列标注
- 3.1. 使用分类器进行标注
- 4. 语义分析
0. 写在大模型前面的话
在介绍大语言模型之前,先把自然语言处理中遗漏的结构化预测补充一下,因为大模型实打实地最先干掉的行业便是自然语言处理,虽然网传各个最容易被大模型替代的行业里从来没有自然语言处理,但现实是有了大模型后,之前的所有自然语言处理技术都显得不那么有价值了。
当然,大模型本质上还是处理自然语言,但其实最大的变化便是忘掉之前的技术,一切像数据和算力看齐。
老兵不死,只是逐渐凋零。
1. 词法分析
词法分析(Lexical Analysis)是对输入文本进行预处理和基础处理的关键步骤。其主要任务是将文本分割成更小的单元(通常是词素或token),并对这些单元进行进一步处理以提取有用的信息。
以下是NLP中词法分析的主要任务和功能:
- 分词(Tokenization):将输入文本分割成独立的词素(Token)。将连续的文本字符串切分成有意义的单词或符号。
- 词性标注(Part-of-Speech Tagging):为每个词素分配其词性(如名词、动词、形容词等)。识别每个单词的语法类别和功能,有助于理解句子的结构和含义。
- 词形还原(Lemmatization):将单词还原为它的词根或规范形式(如动词的原形)。减少词汇形态的多样性,将不同形式的单词归为同一个词。
- 词干提取(Stemming):将单词简化为词干形式,一般通过删减词缀来实现。简化单词,尽量捕捉其基础形式。
- 命名实体识别(Named Entity Recognition):识别文本中的命名实体,如人名、地名、组织名、日期等。从文本中提取有意义的实体信息。
- 正则表达式匹配(Regex Matching):使用正则表达式从文本中提取特定模式或信息。识别和抽取符合特定模式的数据如电子邮件地址、日期等。
- 分块(Chunking):将词性标注后的文本进行分块。例如标识出名词短语(NP)、动词短语(VP)等。为更高层次的语法分析提供基础。
1.1. 分词
分词(Tokenization)是将连续的文本字符串拆分成独立的词素(Token)的过程。分词策略在处理各种自然语言时有所不同,这是由于各个语言的词汇结构和语法规则存在显著差异。
英文分词相对来说比较直接,因为英文单词通常由空格和标点符号分隔。大多数情况下,英文句子中的空格、标点符号等自然分隔符可以有效地分隔词汇。还可以依托自然分隔符和基本规则,如撇号和连字符等特别符号处理。
中文分词相对复杂,因为汉字连续书写,不像英文单词那样有明显的分隔符(如空格)。这使得中文分词成为NLP领域中的一个重要且具有挑战性的任务。中文句子中的词汇之间没有明确的分隔符。同一个字符序列可能有不同的词汇组合方式,导致多种解析结果。处理新词、专有名词和更新快的词汇(如网络用语)。
中文分词的方法:
- 基于规则和字典的方法:利用预定义的词典和规则进行分词。前向最大匹配(Maximum Forward Matching, MFM),从左到右扫描,选择最长的词。逆向最大匹配(Maximum Backward Matching, MBM),从右到左扫描,选择最长的词。
- 统计模型:计算n-gram概率序列进行分词。利用隐马尔可夫模型结合观测概率和转移概率进行词性标注和分词。
- 机器学习和深度学习方法:基于Transformer的模型,如BERT,利用自注意力机制处理全局信息,适用于复杂的分词任务。
- 前向最大匹配 Python 实现
def forward_max_match(text, dictionary):max_len = max(len(word) for word in dictionary)i = 0tokens = []while i < len(text):match = Nonefor j in range(max_len, 0, -1):if i + j <= len(text) and text[i:i+j] in dictionary:match = text[i:i+j]tokens.append(match)i += jbreakif not match:tokens.append(text[i])i += 1return tokensdictionary = {"我", "爱", "北京", "天安门"}
text = "我爱北京天安门"
tokens = forward_max_match(text, dictionary)
print(tokens)
# Output: ['我', '爱', '北京', '天安门']
1.2. 词性标注
词性标注是自然语言处理(NLP)中的一种技术,用于为给定文本中的每一个单词分配其适当的词性标签。常见的词性标签包括名词(Noun, N)、动词(Verb, V)、形容词(Adjective, Adj)、副词(Adverb, Adv)等等。这种标注在各种语言处理任务中非常重要,包括语法解析、信息抽取、机器翻译等。
词性标注方法:
- 基于规则的标注方法:基于一组预定义的规则(如词形变化规则)来标注词性。这种方法简单但受限于规则的定义和复杂性。
- 基于统计的标注方法:基于概率和统计模型,使用大规模标注数据训练模型来预测词性。如隐马尔可夫模型(HMM)、条件随机场(CRF)等。
- 深度学习方法:使用现代深度学习技术,如RNN和Transformers来标注词性。如BERT等预训练语言模型。
常见的标签集有以下几种:
- Penn Treebank标签集:这是用于英语的一个广泛采用的标签集,如NN(名词单数)、NNS(名词复数)、VB(动词原形)、VBD(动词过去式)等。
- Universal POS Tags:这是一个通用性更强的标签集,适用于多种语言,如NOUN(名词)、VERB(动词)、ADJ(形容词)、ADV(副词)等。
- ICTCLAS标签集:这是由中科院计算技术研究所开发的中文词性标注标准。
假设我们有一句话:“The quick brown fox jumps over the lazy dog.”,我们需要对其进行词性标注。下面是一个可能的标注结果:
- “The” - DET(限定词)
- “quick” - ADJ(形容词)
- “brown” - ADJ(形容词)
- “fox” - NOUN(名词)
- “jumps” - VERB(动词)
- “over” - ADP(介词)
- “the” - DET(限定词)
- “lazy” - ADJ(形容词)
- “dog” - NOUN(名词)
词性标注在自然语言处理中的重要性在于:
- 简化结构化分析:帮助其他语言处理任务理解句子的结构。
- 信息抽取:提高信息抽取的精度。
- 机器翻译:改善翻译的语法和流畅度。
- 命名实体识别:有助于识别专有名词和其他关键元素。
2. 句法分析
句法分析(Syntactic Parsing)是自然语言处理中的重要任务,旨在识别和解释输入文本的语法结构。句法分析的目标是生成解析树(Parse Tree),以显示句子各成分之间的关系,以及句子的整体语法结构。解析树包括成分关系(Constituency Parsing)和依存关系(Dependency Parsing)两种主要类型。
2.1. 成分句法分析
成分句法分析(Constituency Parsing),又称为短语结构分析,是自然语言处理中一个关键的技术任务。它的目标是将输入句子解析成一个语法树(Parse Tree),该树描述了句子如何根据某种句法规则结构化。
成分句法分析的目标是构建一个树状结构,用以表示句子的层级关系和组成成分。树的每一个节点表示一个句法成分,如短语、词组或词的类型(如名词短语、动词短语等)。

常见的成分标签:
- S:句子(Sentence)
- NP:名词短语(Noun Phrase)
- VP:动词短语(Verb Phrase)
- PP:介词短语(Prepositional Phrase)
- DT:限定词(Determiner)
- JJ:形容词(Adjective)
- NN:名词(Noun)
- VBZ:动词三单现(Verb, 3rd person singular present)
主要方法:
- 上下文无关文法(Context-Free Grammar, CFG):基于一组规则和词典来生成和解析句子。规则示例:S -> NP VP,NP -> DT NN,VP -> VBZ NP。使用生成递归下降解析器或CKY算法进行解析。
- 概率上下文无关文法(Probabilistic Context-Free Grammar, PCFG):在CFG的基础上增加规则使用的概率,用于更精细的控制和解析。通过最大似然估计或EM算法进行规则概率的训练。
- Chart Parsing:使用动态规划技术,如CYK算法或Earley算法,进行高效的句法树生成。可以处理模糊语法和解析数据的不确定性。
- 基于统计模型的解析:如斯坦福解析器(Stanford Parser),使用PCFG和其他统计方法进行解析。通过大规模语料库(如Penn Treebank)训练模型。
- 基于神经网络端到端解析:结合深度学习模型,直接输出解析树。如使用CRF(条件随机场)层在最后一层优化标签序列的选择。
成分句法分析在多个领域有广泛应用:
- 机器翻译:理解源语言和目标语言的句法结构,提高翻译质量。
- 信息抽取:解析复杂文本以提取有用信息,如实体、关系等。
- 问答系统:理解用户输入以提供更准确的答案。
- 情感分析:分析句子的情感倾向,由其组成成分的情感进行聚合。
2.2. 依存句法分析
依存句法分析(Dependency Parsing)是一种句法分析方法,旨在识别句子中词语之间的语法依存关系。每个词语都有一个或多个依赖词(即其修饰词),这些依存关系能揭示句子的结构和词语在句子中的作用。
两个词语之间的一种语法关系,通常表示为一个头词(Head)和一个依存词(Dependent),这是一种依存关系(Dependency Relation)
一个有根的、有向、无环图,每个节点代表句中的一个词,边表示依存关系,这样就形成了依存树(Dependency Tree)。
句子:“The quick brown fox jumps over the lazy dog.”
依存树可能如下:
jumps├── fox│ ├── The│ ├── quick│ └── brown└── over└── dog├── the└── lazy
在这个依存树中,“jumps”是主谓关系的中心词,“fox”是主语,“dog”是宾语。
依存关系可以细分为不同类型,如:
- 主谓关系(subject-verb):如“fox” -> “jumps”
- 动宾关系(verb-object):如“jumps” -> “over”
- 形容词修饰名词(adjective-noun):如“quick” -> “fox”
这些关系常用统一的标签表示,称为依存标签(Dependency Labels),例如:nsubj(名词主语)、dobj(直接宾语)、amod(形容词修饰)。
依存句法分析的方法:
- 基于规则的方法:转换系统(Transition-Based Systems),使用一系列操作(如SHIFT、REDUCE、LEFT-ARC、RIGHT-ARC)逐步构建依存树。优点:高效,适合实时应用。缺点:规则繁琐,容易出错,需要大量领域知识。
- 数据驱动的方法:图算法(Graph-Based Methods),将句法分析问题转化为图的最优生成问题,使用图算法生成依存树。
- 基于统计模型的解析:离散特征(如词性、词汇)和连续特征(如词嵌入)结合,使用统计模型预测依存关系。
- 神经网络方法:神经依存解析(Neural Dependency Parsing):对于每个词,使用神经网络预测其依存头和依存关系。
3. 序列标注
序列标注(Sequence Labeling)是一种自然语言处理任务,目标是给序列中的每个元素分配一个标签。常见的应用包括词性标注(POS tagging)、命名实体识别(NER)、分块(Chunking)、语义角色标注(Semantic Role Labeling)、句法解析(Syntactic Parsing)等。
在序列标注任务中,每个标签不仅依赖于当前元素,还可能依赖于上下文中的其他元素。这使得序列标注不同于独立的单元素标注任务。因此,合理的建模方法通常需要考虑元素之间的依赖关系。常用方法包括:隐马尔可夫模型(HMM),条件随机场(CRF)。
3.1. 使用分类器进行标注
使用分类器进行标注(Tagging with Classifiers)适用于较为独立的标注任务,在这种方法中,我们把标注任务视为分类问题,即为每个元素分配一个类别。我们可以使用各种分类器,如支持向量机(SVM)、随机森林(Random Forests)和神经网络等。
使用分类器进行标注的主要步骤:
- 特征提取:为序列中每个元素提取特征,这些特征可以包括词本身、词的上下文、词的形态学特征等。
- 训练分类器:使用带标注的数据集训练分类器,其中每个元素对应一个特定的标签。
- 预测标签:训练好的分类器用于预测新数据的标签。
使用分类器进行标注的优点是比较简单,容易实现,可以利用很多不同的机器学习算法。缺点是如果不考虑上下文信息,标注效果可能会受限。独立于上下文的分类器可能无法捕捉词与词之间的依赖关系。
4. 语义分析
语义分析(Semantic Analysis)旨在理解和解释语言背后的意义。语义分析不仅仅关注词语的表面形式,而是试图理解词语和句子在特定语境中的真实含义。
大语言模型直接建模语义,利用大量的文本数据,通过自监督学习来捕捉复杂的语言规律和语义信息。就像我们母语学习类似,是从实际生活中学习语义,并不需要先进行词法分析或句法分析。
相关文章:
德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第七周) - 结构化预测
结构化预测 0. 写在大模型前面的话1. 词法分析 1.1. 分词1.2. 词性标注 2.2. 句法分析 2.3. 成分句法分析2.3. 依存句法分析 3. 序列标注 3.1. 使用分类器进行标注 4. 语义分析 0. 写在大模型前面的话 在介绍大语言模型之前,先把自然语言处理中遗漏的结构化预测补…...

5-Maven-setttings和pom.xml常用配置一览
5-Maven-setttings和pom.xml常用配置一览 setttings.xml配置 <?xml version"1.0" encoding"UTF-8"?> <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xs…...

input输入框设置样式
input清除自带样式 input, textarea,label, button,select,img,form,table,a{-webkit-tap-highlight-color: rgba(255,255,255,0);-webkit-tap-highlight-color: transparent;margin: 0;padding: 0;border: none; } /*去除iPhone中默认的input样式*/ input, button, select, t…...

平稳交付 20+ 医院,卓健科技基于 OpenCloudOS 的落地实践
导语:随着数字化转型于各个行业领域当中持续地深入推进,充当底层支撑的操作系统正发挥着愈发关键且重要的作用。卓健科技把 OpenCloudOS 当作首要的交付系统,达成了项目交付速度的提升、安全可靠性的增强、运维成本的降低。本文将会阐述卓健科…...
Python下载库
注:本文一律使用windows讲解。 一、使用cmd下载 先用快捷键win R打开"运行"窗口,如下图。 在输入框中输入cmd并按回车Enter或点确定键,随后会出现这个画面: 输入pip install 你想下载的库名,并按回车&…...
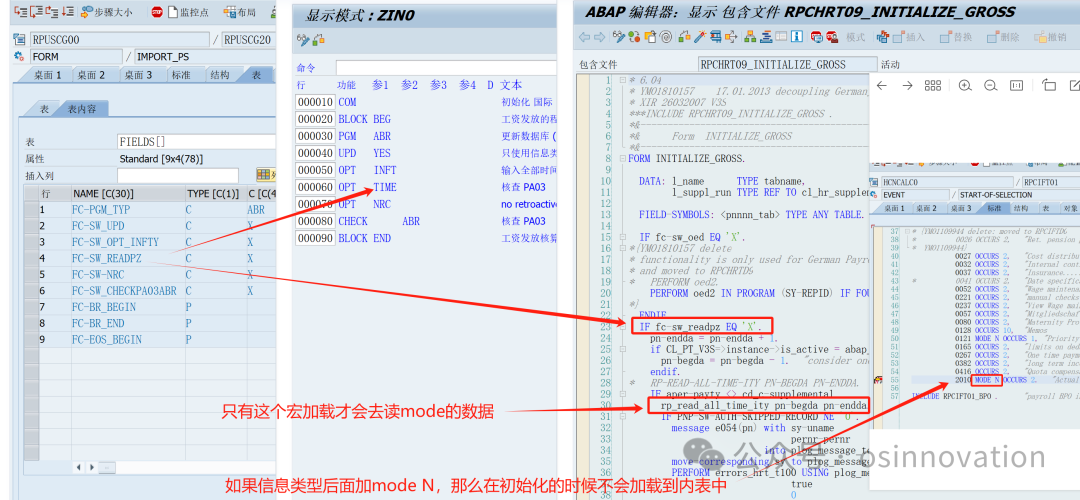
SAP HCM OPT函数作用
导读 INTRODUCTION OPT函数:SAP HCM工资核算是很多函数的汇总集,原有有兴趣问过SAP的人为什么SCHEMA需要这样设计,SAP的人说是用汇编的逻辑设计的,当时是尽可能用机器语言加速速度读取,每个函数都有对应的业务逻辑代码…...

Tensorflow音频分类
tensorflow https://www.tensorflow.org/lite/examples/audio_classification/overview?hlzh-cn 官方有移动端demo 前端不会 就只能找找有没有java支持 注意版本 注意JDK版本 package com.example.demo17.controller;import org.tensorflow.*; import org.tensorflow.ndarra…...
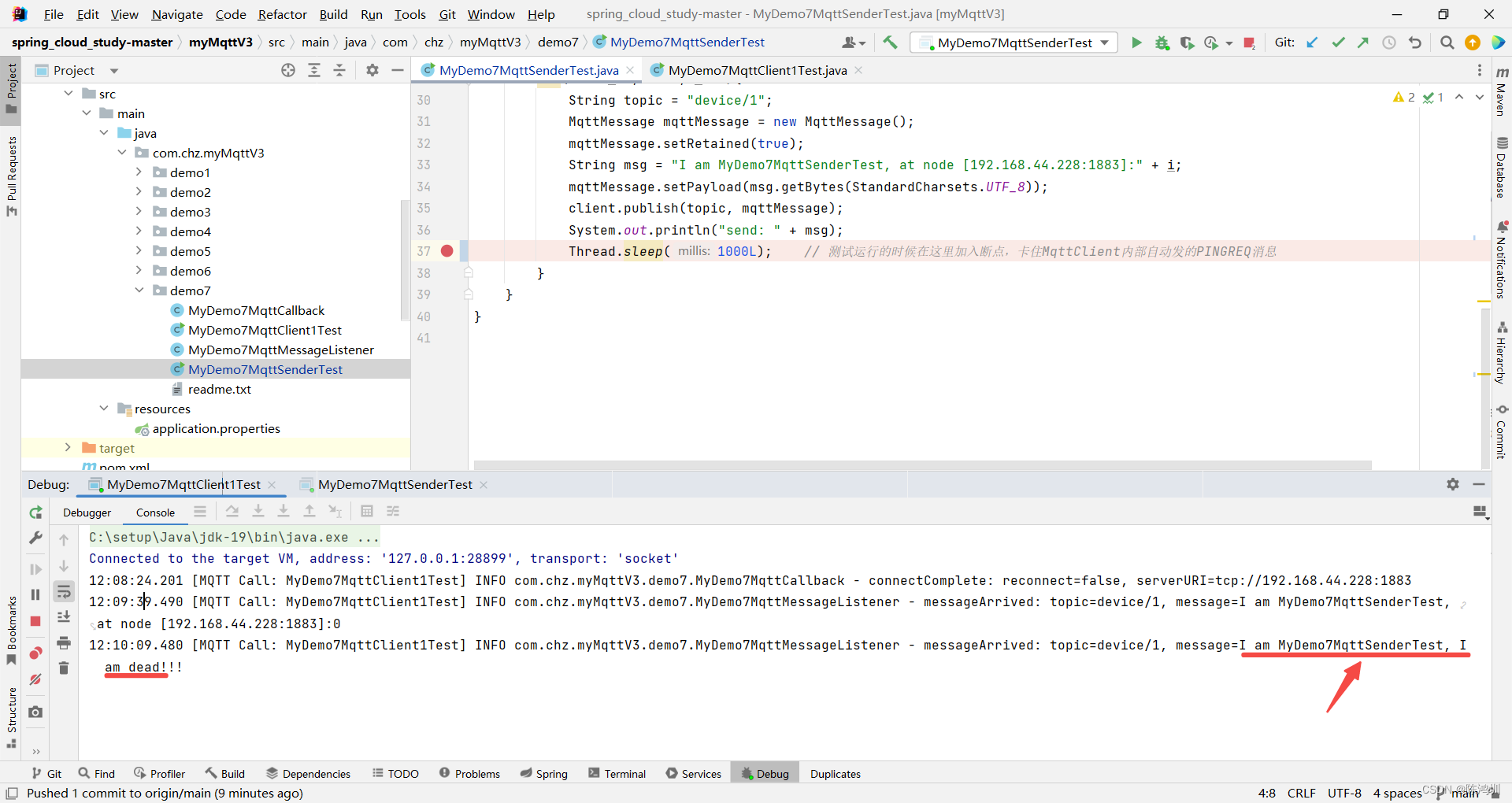
mqtt-emqx:keepAlive机制测试
mqtt keepAlive原理详见【https://www.emqx.com/zh/blog/mqtt-keep-alive】 # 下面开始写测试代码 【pom.xml】 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2…...

C++基础7:STL六大组件
目录 一、标准容器 1、顺序容器 vector 编辑 deque list 容器适配器 stack queue prority_queue: 关联容器 有序关联容器set、mutiset、map、mutimap 增删查O(log n) 无序关联容 unordered_set、unordered_mutiset、unordered_map、unordered_mutimap 增删…...

特别名词Test Paper1
特别名词Test Paper1 ability 能力abstract 摘要accountant 会计accuracy 准确度acid 酸action 行动activity 活动actor 男演员adult 成人adventure 冒险advertisements 广告,宣传advertising 广告advice 建议age 年龄agency 代理机构,中介agreement 同…...

每日题库:Huawe数通HCIA——全部【813道】
1.关于ARP报文的说法错误的是?单选 A.ARP报文不能被转发到其他广播域 B.ARP应答报文是单播方发送的 C.任何链路层协议都需要ARP协议辅助获取数据链路层标识 DARP请求报文是广播发送的 答案:C 解析: STP协议不需要ARP辅助 2.园区网络搭建时,使用以下哪种协议可以避免出现二层…...

#04 Stable Diffusion与其他AI图像生成技术的比较
文章目录 前言1. Stable Diffusion2. DALL-E3. GAN(生成对抗网络)4. VQ-VAE比较总结 前言 随着人工智能技术的飞速发展,AI图像生成技术已成为创意产业和科研领域的热点。Stable Diffusion作为其中的佼佼者,其性能和应用广受关注。…...
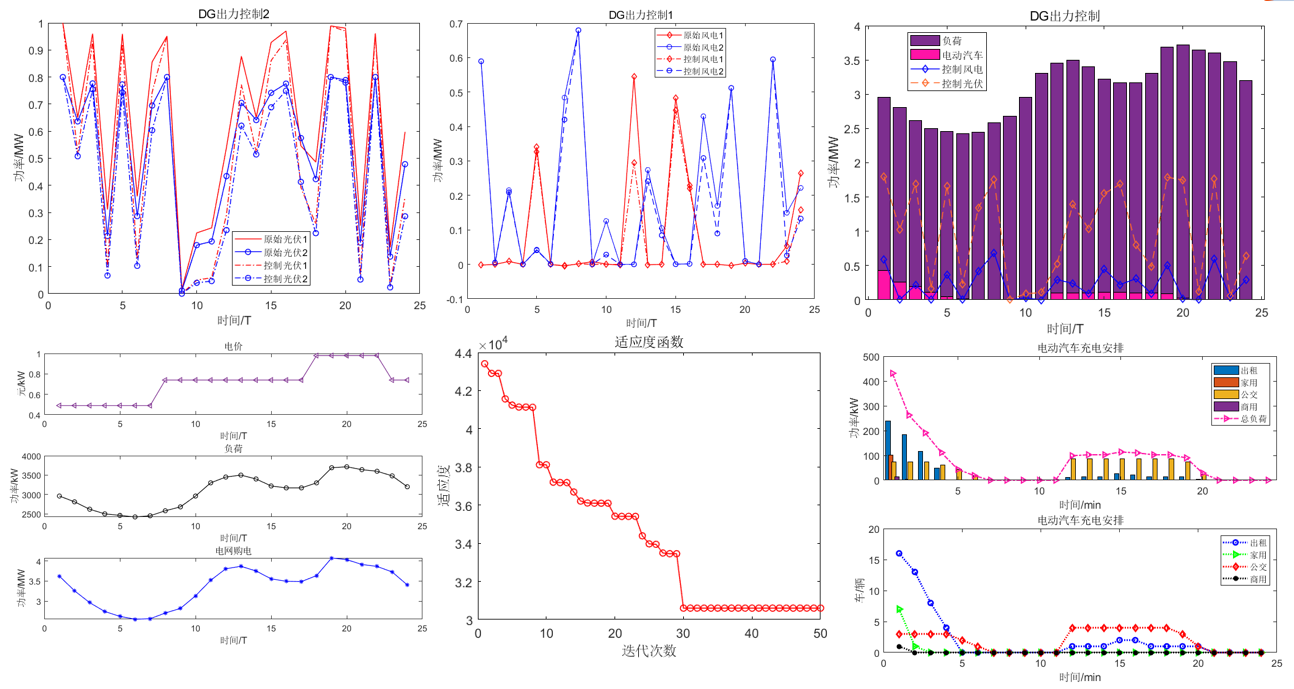
不确定性+电动汽车!含高比例新能源和多类型电动汽车的配电网能量管理程序代码!
前言 能源供应的可持续性和清洁性是当今世界共同关注的议题,配电网与可再生能源发电相结合,通过多能互补和梯级利用,在不同时空取长补短,提高能源利用率,减少温室气体排放,是解决能源短缺和环境问题的有效…...

准确-K8s系列文章-修改containerd 默认数据目录
修改 Kubernetes 集群中 containerd 默认数据目录为 /data/containerd 前言 本文档适用于 Kubernetes 1.24 及以上版本的集群,介绍如何将 containerd 默认的数据目录从 /var/lib/containerd 修改为 /data/containerd。 步骤 1. 停止 containerd 服务(…...

深入探索Linux命令:`aulastlog`
深入探索Linux命令:aulastlog 在Linux系统中,安全管理一直是管理员和用户关注的焦点。aulastlog是一个非常有用的工具,用于显示用户最近登录的日志。它通过分析/var/log/lastlog文件来提供这些信息,这个文件记录了系统上所有用户…...

Debezium日常分享系列之:Debezium 2.6.2.Final发布
Debezium日常分享系列之:Debezium 2.6.2.Final发布 一、新功能和改进1.Oracle 数据库查询过滤超过 1000 个表 二、修复和稳定性改进1.PostgreSQL 偏移刷新竞争条件2.Avro 兼容性 一、新功能和改进 1.Oracle 数据库查询过滤超过 1000 个表 Debezium Oracle 连接器允…...

PHP质量工具系列之phpmd
PHPMD PHP Mess Detector 它是PHP Depend的一个衍生项目,用于测量的原始指标。 PHPMD所做的是,扫描项目中可能出现的问题如: 可能的bug次优码过于复杂的表达式未使用的参数、方法、属性 PHPMD是一个成熟的项目,它提供了一组不同的…...
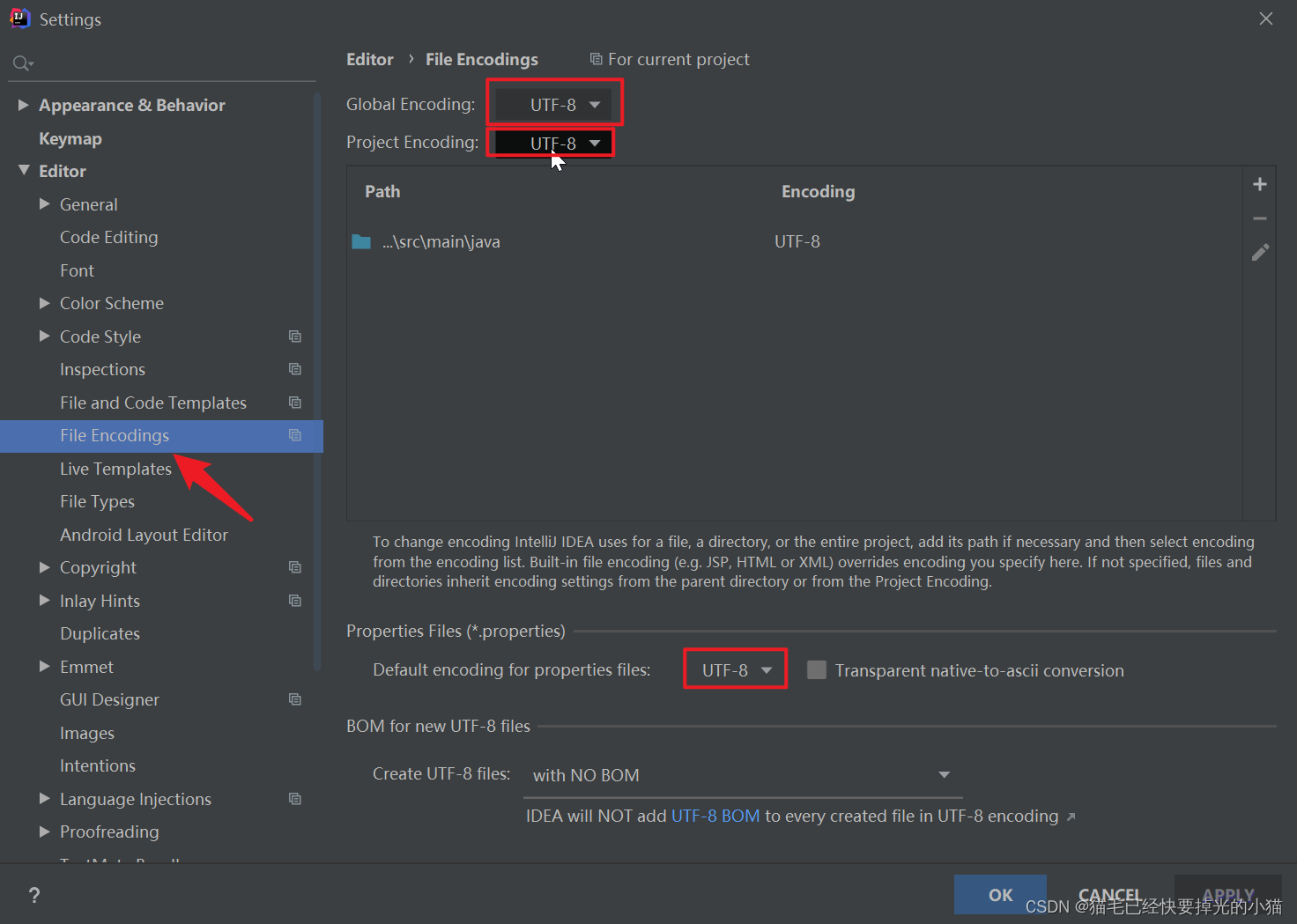
【java】速度搭建一个springboot项目
使用软件:IDEA,mysql 使用框架:springboot mybatis-plus druid 坑点 使用IDEA搭建一个springboot项目的时候,需要考虑一下IDEA版本支持的JDK版本以及maven版本。否则再构建项目,引入pom的时候就会报错。 需要检查…...

SystemVerilog测试框架示例
这里是一个完整的SystemVerilog测试框架示例,包括随机化测试和详细注释。 顶层模块 (Top Module) module top;// 信号声明logic clk;logic rst_n;// 接口实例化dut_if dut_if_inst(.clk(clk), .rst_n(rst_n));// DUT实例化 (假设DUT模块名为dut)dut u_dut(.clk(du…...
-图表决策树)
每天一个数据分析题(三百五十六)-图表决策树
图表决策树中将图表分成四类,分别是? A. 比较类 B. 序列类 C. 构成类 D. 描述类 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案...

云原生存储优化:优化云原生环境的存储性能
云原生存储优化:优化云原生环境的存储性能 一、云原生存储优化概述 1.1 云原生存储优化的定义 云原生存储优化是指通过优化存储架构、配置和使用方式,提高云原生环境中存储的性能、可靠性和成本效益的过程。 1.2 云原生存储优化的价值 性能提升ÿ…...

如何用嘎嘎降AI处理理工科论文:公式图表密集的理工科毕业论文降AI免费完整操作流程
如何用嘎嘎降AI处理理工科论文:公式图表密集的理工科毕业论文降AI免费完整操作流程 帮三个不同学校的同学处理过论文降AI问题,每次情况不完全一样,但流程基本是固定的。 主推工具:嘎嘎降AI(www.aigcleaner.com&#…...

【Prometheus】如何诊断 Prometheus 查询缓慢或超时的问题?
Prometheus 查询性能深度调优:从高基数陷阱到 TSDB 存储引擎的全链路诊断 用户问题原文:“如何诊断 Prometheus 查询缓慢或超时的问题?” 在支撑单集群500万+时间序列的生产环境中,Prometheus 查询性能是 SRE 团队的生命线。一次缓慢的查询不仅会拖垮 Grafana 面板,更可能…...

软件测试十年老兵自述:从月薪3K到年薪50W的跃迁密码
一个Bug改变的人生轨迹十年前的那个下午,我还记得格外清晰。作为某外包公司的“点点点”工程师,我机械地对着一个后台管理系统重复着测试用例。月薪3000,坐标二线城市,每天的工作就是执行别人写好的用例,发现Bug就提交…...
介绍(提供DNS服务器)骨干网络、Peering对等互联、MPLS、带宽、延迟、丢包、抖动、SD-WAN)
ISP运营商(Internet Service Provider 互联网服务提供商)介绍(提供DNS服务器)骨干网络、Peering对等互联、MPLS、带宽、延迟、丢包、抖动、SD-WAN
文章目录ISP 是什么?一文读懂互联网服务提供商(Internet Service Provider)一、ISP 是什么?二、ISP 在网络中的位置三、ISP 的核心作用1. 提供互联网接入四、ISP 如何分配 IP 地址?五、ISP 与 DNS 的关系六、ISP 的网络…...

5G手机发展复盘:从技术挑战到市场现实的工程化演进
1. 从“挤牙膏”到“大跃进”:复盘2020年5G手机的真实开局2019年初,当高通在分析师面前用三星和摩托罗拉的工程样机演示5G时,整个行业都弥漫着一种乐观情绪,仿佛一场席卷全球的换机潮即将在2020年爆发。然而,作为一名在…...

从社交推荐到金融风控:动态链路预测在工业界的5个落地场景详解
动态链路预测:从理论到商业价值的五大实战场景 社交平台上那些"可能认识的人"推荐,金融交易中突然拦截的欺诈提醒,电商首页精准推送的"猜你喜欢"——这些看似无关的场景背后,都藏着一个关键技术:动…...
)
别再只会用555了!用继电器搭建LED闪烁电路的3个隐藏知识点(附电路图)
继电器驱动LED闪烁电路:超越555的三大物理奥秘与实战设计 在电子爱好者的世界里,LED闪烁电路就像"Hello World"之于程序员,是入门必修的第一课。大多数教程会引导初学者使用555定时器这种"标准化方案",却很少…...

自我提升智能体的自进化原理和实践
自我提升智能体skill赋予了AI助手从错误中反思、学习并自动繁衍新通用技能的持续进化能力。 1 实际案例 帮我运行测试,看看为什么登录模块失败。 流程如下: 第一步,任务开始前,Hook 触发 activator.sh(通过 UserPromptSubmit 触发)。它不会输出一大堆规则,只是提醒 AI 一…...

从零到一:手把手教你用LabelImg高效构建VOC与YOLO数据集
1. 为什么你需要掌握LabelImg标注工具 刚接触计算机视觉时,我最头疼的就是数据准备环节。记得第一次尝试训练目标检测模型,花了两周时间收集了上千张图片,却在标注环节卡住了——手动画框太慢,格式转换出错,反复返工差…...