OpenPPL PPQ量化(5):执行引擎 源码剖析
目录
PPQ Graph Executor(PPQ 执行引擎)
PPQ Backend Functions(PPQ 算子库)
PPQ Executor(PPQ 执行引擎)
Quantize Delegate (量化代理函数)
Usage (用法示例)
Hook (执行钩子函数)
 前面四篇博客其实就讲了下面两行代码:
前面四篇博客其实就讲了下面两行代码:
ppq_ir = load_onnx_graph(onnx_import_file=onnx_import_file)ppq_ir = dispatch_graph(graph=ppq_ir, platform=platform, dispatcher=setting.dispatcher, dispatching_table=setting.dispatching_table)量化部分的精髓才刚刚开始,但是别急,咱先来点轻松的哈。这一讲看看执行引擎executor是如何实现的。虽然这部分和量化原理关系不大,但是学一学总没有坏处呀!
感动哭了,PPQ的中文注释也写得太详细了吧,这就看看官方注释,让博主水一篇博客吧哈哈哈
PPQ Graph Executor(PPQ 执行引擎)
为了量化并优化神经网络模型,PPQ 实现了基于 Pytorch 的执行引擎,该执行引擎能够执行 Onnx 与 Caffe 的模型文件,目前支持 90 余种常见 Onnx 算子,涵盖 1d, 2d, 3d 视觉、语音、文本模型。
PPQ 的执行引擎位于 ppq.executor 目录下,由两个主要部分组成: ppq.executor.torch.py 文件中包含了执行引擎自身; ppq.executor.op 文件夹中则包含了不同后端的算子库。
在开始阅理解执行引擎之前,我们先介绍算子库的相关内容
PPQ Backend Functions(PPQ 算子库)
核心算子库位于 ppq.executor.op.torch.default 文件中,该文件中包含了所有算子默认的执行逻辑。
我们知道,对于一个量化算子而言,由于硬件的不同其执行逻辑也可能发生变化。例如 LeakyRelu 算子的负数部分在 GPU 上会采用 x * alpha 的方式完成计算,而在 FPGA 则会采用 x = x >> 3 完成计算。正因为这种差异的存在, PPQ 允许相同的算子在不同平台(TargetPlatform)上拥有不同的执行逻辑。
这也意味着针对每一个平台,我们都将实现一个平台独特的算子库文件,这些算子库都继承于 ppq.executor.op.torch.default。
def Mul_forward(op: Operation, values: List[torch.Tensor], ctx: TorchBackendContext = None, **kwargs) -> torch.Tensor:ASSERT_NUM_OF_INPUT(op=op, values=values, min_num_of_input=2, max_num_of_input=2)values = VALUE_TO_EXECUTING_DEVICE(op=op, ctx=ctx, values=values)multiplicand, multiplier = valuesreturn multiplicand * multiplier上文中的内容即 ppq.executor.op.torch.default 中 Mul 算子的执行逻辑,在 PPQ 中,所有算子在执行时都将接受一系列 torch.Tensor 作为输入,而后我们调用 pytorch 完成算子的计算逻辑。
你可以打开 PPQ 的算子库文件查看其他算子的执行逻辑,并且 PPQ 也提供了 register_operation_handler 函数,借助该函数你可以注册自定义算子的执行逻辑;或是覆盖现有算子的执行逻辑。
def register_operation_handler(handler: Callable, operation_type: str, platform: TargetPlatform):if platform not in GLOBAL_DISPATCHING_TABLE:raise ValueError('Unknown Platform detected, Please check your platform setting.')GLOBAL_DISPATCHING_TABLE[platform][operation_type] = handler该函数位于 ppq.api, 你可以使用语句 from ppq.api import register_operation_handler 来引入它。
PPQ Executor(PPQ 执行引擎)
接下来我们向你介绍 PPQ 执行引擎 TorchExecutor,你可以使用语句 from ppq import TorchExecutor 导入执行引擎。初始化执行引擎则需要传入一个 PPQ 计算图实例对象,
在这里我们假设已经获取到了一个量化后的计算图对象 ppq_quant_ir,并使用下面的语句初始化计算引擎
executor = TorchExecutor(graph=ppq_quant_ir)executor.forward(inputs=..., output_names=..., hooks=...)我们使用 executor.forward 接口获取图的执行结果,它将可以传入三个参数:
- inputs: inputs (Union[dict, list, torch.Tensor]): [input tensors or somewhat]
- output_names (List[str], optional): output variable names. default is None.
- hooks (Dict[str, RuntimeHook], optional): A hook table for customizing operation behaviour and collate data during executing.
当执行引擎获取到推理请求时,它将按拓扑顺序依次执行图中的算子,下图展示了一个简单的示例:
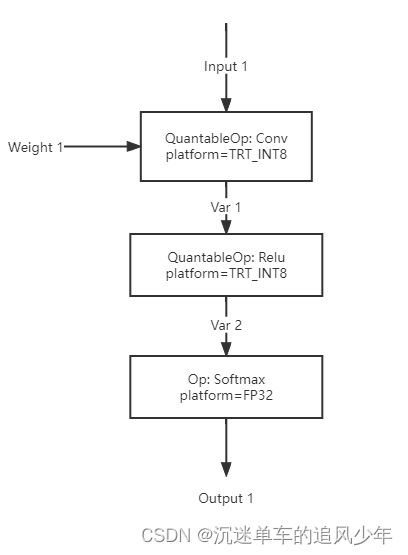
在这里,我们的图中包含三个算子 Conv, Relu, Softmax,他们将按照拓扑次序被依次执行。PPQ 的执行引擎会在执行完 Conv 算子后,将 Conv 算子的结果暂存于 Var 1 中,供 Relu 算子取用。
而在执行完 Relu 算子后,PPQ 执行引擎则会及时地释放 Var 1 中暂存的数据,因为他们不会被其他算子取用,而且也不是网络的输出 Variable。在每一次推理过后,PPQ 还会清空网络中所有的暂存变量以释放显存。
下面的代码段展示了一个非量化算子的执行逻辑:
for operation in executing_order:outputs = operation_forward_func(operation, inputs, self._executing_context)outputs = outputs if isinstance(outputs, (list, tuple)) else [outputs]fp_outputs = outputsfor output_idx, output_var in enumerate(operation.outputs):output_var = operation.outputs[output_idx]output_var.value = outputs[output_idx]for var in self._graph.variables.values():if not var.is_parameter:var.value = NonePPQ 的执行引擎是专为量化计算图的执行而设计的————接下来让我们深入到量化算子的执行过程中去。
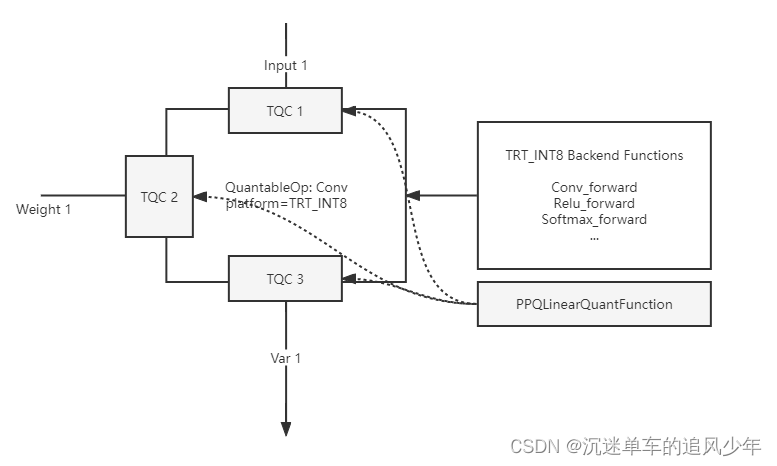
对于一个量化算子而言,其每一个输入和输出变量都会有一个 Tensor Quantization Config (TQC) 控制结构体对量化过程进行描述。
对于一个量化 Conv 算子而言,PPQ 将为它创建 2-3 个 Input TQC,以及一个 Output TQC。分别对其输入变量以及输出变量的量化行为进行描述。
下面的代码展示了如何为量化算子创建特定的 TQC 描述量化逻辑。
if operation.type == 'Conv':config = self.create_default_quant_config(op = operation,num_of_bits = 8,quant_max = 127,quant_min = -128,observer_algorithm = 'percentile',policy = QuantizationPolicy(QuantizationProperty.PER_TENSOR +QuantizationProperty.LINEAR +QuantizationProperty.SYMMETRICAL),rounding = RoundingPolicy.ROUND_HALF_EVEN)for tensor_quant_config in config.input_quantization_config:tensor_quant_config.state = QuantizationStates.FP32operation.config = config在 图2 中,我们展示了 PPQ 执行引擎对于量化算子的执行逻辑:
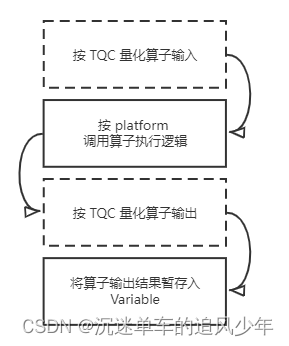
在 PPQ 中,算子的执行被分为四个过程:
- 首先 PPQ 将根据算子上的 TQC 信息量化算子的输入。量化过程并非是原地的,量化后的数据将会是一个新的 torch.Tensor。
- 随后 PPQ 在算子库中寻找算子的执行逻辑,我们已经提到对于每一个平台,他们都可以拥有自己的一套独立的算子库。PPQ 将按照算子的平台找到特定的计算逻辑,并调用他们完成计算得到结果。
- PPQ 将根据算子上的 TQC 信息量化算子的输出。同样地,输出的量化也不是原地的。
- 最后我们将量化好的结果写入到计算图的 Variable 上,从而供后续的算子取用。
对于一个非量化算子而言,上述步骤中的 1,3 是可以省略的。
下 图3 展示了一个量化卷积算子 与 TQC 之间的关系:
Quantize Delegate (量化代理函数)
PPQ 允许你为网络中特定的 TQC 注册量化代理函数。这样你就可以注册自定义的量化处理逻辑,而非使用 PPQLinearQuantFunction 完成量化。
def register_quantize_delegate(self, config: TensorQuantizationConfig,delegator: TorchQuantizeDelegator):使用 executor.register_quantize_delegate(config, function) 完成函数注册,被注册的函数必须满足 TorchQuantizeDelegator 所定义的接口。
下面我们给出一个简单的量化代理函数例子:
class MyQuantDelegator(TorchQuantizeDelegator):def __call__(self, tensor: torch.Tensor, config: TensorQuantizationConfig) -> torch.Tensor:if config.policy.has_property(QuantizationProperty.ASYMMETRICAL):raise ValueError('Sorry, this delegator handles only Symmetrical Quantizations.')print('You are invoking cusitmized quant function now.')return torch.round(tensor / config.scale) * config.scale在执行器遇到 TQC 时,将会调用 executor.quantize_function 执行量化,其逻辑为:
def quantize_function(self, tensor: torch.Tensor, config: TensorQuantizationConfig = None) -> torch.Tensor:if config is None or not QuantizationStates.is_activated(config.state): return tensorelif config in self._delegates: return self._delegates[config](tensor, config)else:if config.policy.has_property(QuantizationProperty.DYNAMIC):return self._dynamic_quant_fn(tensor, config)else:return self._default_quant_fn(tensor, config)Usage (用法示例)
PPQ 的执行器初始化需要一个计算图实例作为参数:
executor = TorchExecutor(graph=ppq_quant_ir)executor.forward(inputs=..., output_names=..., hooks=...)这一计算图可以是量化过后的,也可以是没有量化的。但 PPQ 希望传入的计算图经过正确调度,传入没有调度的计算图将会触发警报:
if not graph.extension_attrib.get(IS_DISPATCHED_GRAPH, False):ppq_warning('Can not create executor with your graph, graph is not correctly dispatched, ''use dispatch_graph(graph=ir, platform=platfrom, setting=setting) first.')executor.forward 需要三个参数,下面举例对其进行说明:
# 传入三个变量 a, b, c 作为输入executor.forward(inputs=[a, b, c], output_names=..., hooks=...)# 分别对图中 input, var 1 两个变量传入 a, b 作为输入executor.forward(inputs={'input': a, 'var 1': b}, output_names=..., hooks=...) # 传入一个完整的 tensor 作为输入executor.forward(inputs=torch.zeros(shape=[1,3,224,224]), output_names=..., hooks=...)# 要求网络输出 output, Var 1 的值executor.forward(inputs=..., output_names=['output 1', 'Var 1'], hooks=...)executor.forward 函数默认不需要梯度,如果希望执行带有梯度的网络,需要使用 executor.forward_with_gradient 函数。 forward 函数的返回值永远是一个 torch.Tensor 数组,其中元素的顺序由 output_names 参数决定。
Hook (执行钩子函数)
在调用 executor.forward 函数时可以传入 hooks 参数。钩子函数是注册在 op 上的,你可以传入一个字典用来说明需要调用的钩子函数:
字典 {'Conv 1': myhook} 说明了希望在算子 Conv 1 的执行器件调用钩子函数 myhook。
钩子函数必须继承于 RuntimeHook 类,必须实现成员函数 pre_forward_hook, post_forward_hook。在这两个函数中,你可以制定特定的逻辑修改算子输入输出的值。
class RuntimeHook(metaclass=ABCMeta):def __init__(self, operation: Operation) -> None:self._hook_to = operationdef pre_forward_hook(self, inputs: list, **kwargs) -> list:return inputsdef post_forward_hook(self, outputs: list, **kwargs) -> list:return outputsTorchExecutor - executor object which use torch as its backend.
torch backend is used to graph simulating & training(QAT)
all operation forward functions are written with pytorch,so that they will have gradient recorded by torch engine. which means you can directly access to tensor.grad after using output.backward()
Args:
graph (BaseGraph):
executing graph object,
TorchExecutor will automatically send all graph parameters towards executing device.
fp16_mode (bool, optional): [whether the simulator is running in fp16 mode(unimplemented).]. Defaults to True.
device (str, optional): [
executing device, as same as torch.device,
you can not select gpu to executing yet,
graph will always be send to the very first visible cuda device.
]. Defaults to 'cuda'.
相关文章:
OpenPPL PPQ量化(5):执行引擎 源码剖析
目录 PPQ Graph Executor(PPQ 执行引擎) PPQ Backend Functions(PPQ 算子库) PPQ Executor(PPQ 执行引擎) Quantize Delegate (量化代理函数) Usage (用法示例) Hook (执行钩子函数) 前面四篇博客其实就讲了下面两行代码: ppq_ir load_onnx_graph(onnx_impor…...
【脚本开发】运维人员必备技能图谱
脚本(Script)语言是一种动态的、解释性的语言,依据一定的格式编写的可执行文件,又称作宏或批处理文件。脚本语言具有小巧便捷、快速开发的特点;常见的脚本语言有Windows批处理脚本bat、Linux脚本语言shell以及python、…...
N字形变换-力扣6-java
一、题目描述将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:P A H NA P L S I I GY I R之后,你的输出需要从左往右逐行读…...
)
概论_第5章_中心极限定理1__定理2(棣莫弗-拉普拉斯中心极限定理)
在概率论中, 把有关论证随机变量和的极限分布为正态分布的一类定理称为中心极限定理称为中心极限定理称为中心极限定理。 本文介绍独立同分布序列的中心极限定理。 一 独立同分布序列的中心极限定理 定理1 设X1,X2,...Xn,...X_1, X_2, ...X_n,...X1,X2,...Xn…...
详细解读503服务不可用的错误以及如何解决503服务不可用
文章目录1. 问题引言2. 什么是503服务不可用错误3 尝试解决问题3.1 重新加载页面3.2 检查该站点是否为其他人关闭3.3 重新启动设备3.3 联系网站4. 其他解决问的方法1. 问题引言 你以前遇到过错误503吗? 例如,您可能会收到消息,如503服务不可…...

【前端vue2面试题】2023前端最新版vue模块,高频17问(上)
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的关于vue2面试题(上) 目录 vue2面试题 1、$route 和 $router的区别 2、一个…...
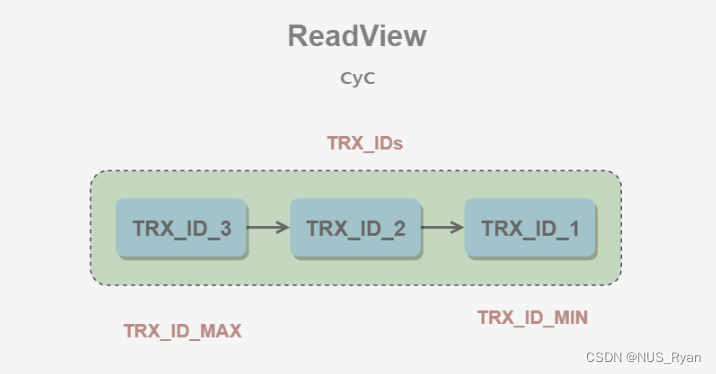
数据库(三):多版本并发控制MVCC,行锁的衍生版本,记录锁,间隙锁, Next-Key锁(邻键锁)
文章目录前言一、MVCC以及MVCC的缺点1.1 MVCC可以为数据库解决什么问题1.2 MVCC的基本思想1.3 版本号1.4 Undo日志1.5 ReadView1.6 快照读和当前读1.6.1 快照读1.6.2 当前读二、记录锁三、间隙锁四、邻键锁总结前言 一、MVCC以及MVCC的缺点 MVCC,即多版本并发控制…...
c# 自定义隐式转换与运算符重载
用户定义的显式和隐式转换运算符 参考代码 用户定义的显式和隐式转换运算符 - 提供对不同类型的转换 | Microsoft Learn 代码例程 using System;public readonly struct Digit {private readonly byte digit;public Digit(byte digit){if (digit > 9){throw new Argumen…...
【MyBatis】| MyBatis的逆向⼯程
目录 一:MyBatis的逆向⼯程 1. 逆向⼯程配置与⽣成 2. 测试生成的逆向⼯程 一:MyBatis的逆向⼯程 (1)所谓的逆向⼯程是:根据数据库表逆向⽣成Java的pojo类,SqlMapper.xml⽂件,以及Mapper接⼝…...

Python|每日一练|哈希表|罗马数字|图算法|圆周率|单选记录:给定数列和|罗马数字转整数|计算圆周率
1、要求编写函数fn(a,n) 求aaaaaa⋯aa⋯aa(n个a)之和,fn须返回的是数列和(算法初阶) 要求编写函数fn(a,n) 求aaaaaa⋯aa⋯aa(n个a)之和,fn须返回的是数列和。 从控制台输入正整数a和n的值(两…...

分布式之分布式事务V2
写在前面 本文一起来看下分布式环境下的事务问题,即我们经常听到的分布式事务问题。想要解决分布式事务问题,需要使用到分布式事务相关的协议,主要有2PC即两阶段提交协议,TCC(try-confirm-cancel)…...

算法笔记(二)—— 认识N(logN)的排序算法
递归行为的时间复杂度估算 整个递归过程是一棵多叉树,递归过程相当于利用栈做了一次后序遍历。 对于master公式,T(N)表明母问题的规模为N,T(N/b)表明每次子问题的规模,a为调用次数,加号后面表明,除去调用之…...

最长湍流子数组——滚动窗口,双指针,暴力求解
978. 最长湍流子数组难度中等216收藏分享切换为英文接收动态反馈给定一个整数数组 arr ,返回 arr 的 最大湍流子数组的长度 。如果比较符号在子数组中的每个相邻元素对之间翻转,则该子数组是 湍流子数组 。更正式地来说,当 arr 的子数组 A[i]…...

45.在ROS中实现global planner(1)
前文move_base介绍(4)简单介绍move_base的全局路径规划配置,接下来我们自己实现一个全局的路径规划 1. move_base规划配置 ROS1的move_base可以配置选取不同的global planner和local planner, 默认move_base.cpp#L70中可以看到是…...
Java中导入、导出Excel——HSSFWorkbook 使用
一、介绍 当前B/S模式已成为应用开发的主流,而在企业办公系统中,常常有客户这样子要求:你要把我们的报表直接用Excel打开(电信系统、银行系统)。或者是:我们已经习惯用Excel打印。这样在我们实际的开发中,很多时候需要…...

c#数据结构-列表
列表 数组可以管理大量数组,但缺点是无法更变容量。 创建小了不够用,创建大了浪费空间。 无法预测需要多少大小的时候,可能范围越大,就会浪费越多的空间。 所以,你可能会想要一种可以扩容的东西,代替数组…...
Sa-Token实现分布式登录鉴权(Redis集成 前后端分离)
文章目录1. Sa-Token 介绍2. 登录认证2.1 登录与注销2.2 会话查询2.3 Token 查询3. 权限认证3.1 获取当前账号权限码集合3.2 权限校验3.3 角色校验4. 前后台分离(无Cookie模式)5. Sa-Token 集成 Redis6. SpringBoot 集成 Sa-Token6.1 创建项目6.2 添加依…...

leaflet显示高程
很多地图软件都能随鼠标移动动态显示高程。这里介绍一种方法,我所得出的。1 下载高程数据一般有12.5m数据下载,可惜精度根本不够,比如mapbox的免费在线的,或者91卫图提供百度网盘打包下载的,没法用,差距太大…...
电子学会2022年12月青少年软件编程(图形化)等级考试试卷(三级)答案解析
目录 一、单选题(共25题,共50分) 二、判断题(共10题,共20分) 三、编程题(共3题,共30分) 青少年软件编程(图形化)等级考试试卷(三级) 一、单选题(共25题,共50分) 1. 默认小猫角色…...

ubuntu 驱动更新后导致无法进入界面
**问题描述: **安装新ubuntu系统后未禁止驱动更新导致无法进入登录界面。 解决办法: 首先在进入BIOS中,修改设置以进行命令行操作,然后卸载已有的系统驱动,最后安装新的驱动即可。 开机按F11进入启动菜单栏…...
告别Pyscenedetect误判!用TransNet V2精准切割视频转场(附Python实战代码)
告别Pyscenedetect误判!用TransNet V2精准切割视频转场(附Python实战代码) 视频内容创作者和开发者们,是否曾为传统视频切割工具的误判而头疼?高速运动的赛车镜头被误认为转场,长达数秒的渐变过渡被完全忽…...

突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南
突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南 【免费下载链接】tidal-dl-ng TIDAL Media Downloader Next Generation! Up to HiRes / TIDAL MAX 24-bit, 192 kHz. 项目地址: https://gitcode.com/gh_mirrors/ti/tidal-dl-ng 场景痛点:当高品…...
)
别再只调PID了!用Mahony算法搞定IMU姿态解算(附C代码逐行解析)
Mahony算法实战:从IMU数据到稳定姿态解算的C语言实现 在嵌入式系统和机器人开发中,姿态解算一直是个令人头疼的问题。许多工程师习惯性地依赖PID控制器,却忽视了更优雅的数学解决方案。Mahony算法作为一种基于四元数的姿态融合算法࿰…...

League Akari:英雄联盟玩家的终极自动化工具箱完整指南
League Akari:英雄联盟玩家的终极自动化工具箱完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款专为《英…...

新手零代码入门:借鉴cherry studio理念,用快马AI生成你的第一个网页
作为一个刚接触编程的新手,我一直想搭建一个简单的个人博客页面来展示自己的文章。但面对复杂的代码和陌生的术语,总感觉无从下手。直到发现了InsCode(快马)平台,它让我用自然语言描述需求就能生成可运行的代码,整个过程就像cherr…...

SPIRAN ART SUMMONER场景应用:打造个人专属的最终幻想风格头像与壁纸
SPIRAN ART SUMMONER场景应用:打造个人专属的最终幻想风格头像与壁纸 1. 开启你的斯皮拉艺术之旅 你是否曾经幻想过拥有《最终幻想10》中那样唯美梦幻的角色形象?现在,借助SPIRAN ART SUMMONER,这个梦想可以轻松实现。这款融合了…...

Emotion2Vec+ Large语音情感识别:开箱即用,9种情绪精准分析
Emotion2Vec Large语音情感识别:开箱即用,9种情绪精准分析 1. 语音情感识别技术概述 语音情感识别技术正在改变我们与机器交互的方式。这项技术通过分析语音中的声学特征,能够准确识别说话者的情绪状态。Emotion2Vec Large作为当前领先的语…...

告别复杂配置!Qwen-Image-2512图片生成服务保姆级部署教程
告别复杂配置!Qwen-Image-2512图片生成服务保姆级部署教程 1. 为什么选择这个镜像? 在AI图片生成领域,Qwen-Image-2512模型以其出色的中文理解和图像质量著称。但传统部署方式往往需要面对以下挑战: 复杂的Python环境配置数十G…...

Go的runtime.LockOSThread:将goroutine绑定到系统线程
Go语言以其轻量级的goroutine和高效的并发模型著称,但在某些特殊场景下,开发者需要更精细地控制goroutine与系统线程的绑定关系。这时,runtime.LockOSThread便成为了一个关键工具。本文将深入探讨这一机制,帮助读者理解其原理、应…...

南北阁4.1-3B极简WebUI入门必看:无需React/Vue的纯Python前端方案
南北阁4.1-3B极简WebUI入门必看:无需React/Vue的纯Python前端方案 想给本地部署的南北阁(Nanbeige)4.1-3B大模型配一个好看又好用的聊天界面,是不是一想到要学React、Vue这些前端框架就头大?或者觉得Streamlit做出来的…...