机器学习与数据挖掘知识点总结(一)
简介:随着人工智能(AI)蓬勃发展,也有越来越多的人涌入到这一行业。下面简单介绍一下机器学习的各大领域,机器学习包含深度学习以及强化学习,在本节的机器学习中主要阐述一下机器学习的线性回归逻辑回归(二分类以及多分类问题),以及深度学习的一些神经网络变型,包括有CNN经典模型残差神经网络(ResNet),RNN经典模型长短时期记忆网络(LSTM)。
在人工智能上花一年时间,这足以让人相信上帝的存在。--艾伦佩利
目录
1、激活函数
(1)什么是激活函数:
(2)常见激活函数:
2、线性回归与逻辑回归任务
3、梯度优化算法
(1)梯度下降(Gradient descent,简称GD)
(2)梯度消失以及梯度爆炸
(3)学习率(learning rate,简称lr)
4、拟合问题
(1)训练集和测试集
(2)过拟合与欠拟合
(3)如何解决过拟合和欠拟合问题
(4)提前stop training
5、数据预处理部分
归一化(Normalization)与标准化(Standardization)
数据缺失
图像处理(计算机视觉)
6、RNN循环神经网络
LSTM算法
7、CNN卷积神经网络
8、使用Tensorflow1.0/2.0框架创建神经网络
1、激活函数
(1)什么是激活函数:
神经网络有单一的神经元接收上一层神经元的输出作为本神经元的输入,即一种在神经元上运行的函数,把神经元的输入映射到输出端。
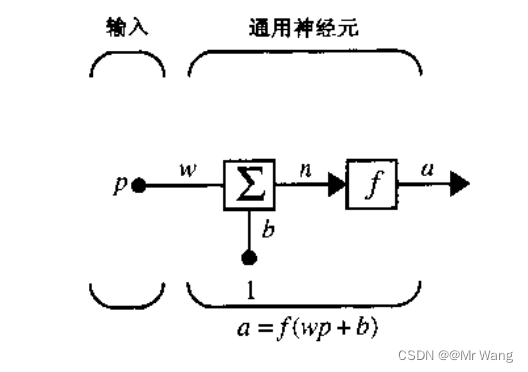
如图1(单输入单输出神经元)所示,p为输入,w为权重,b为偏置,若引入激活函数f,则相应的输出为a=f(wp+b),但若无激活函数,相应的输出a'=wp+b。其实也就是说,
它的作用是引入非线性性质,使得神经网络能够学习和逼近更复杂的函数。在实际生活中,无论如何搭建神经网络,输出都是对于输入的线性模型叠加。因此引入非线性因素后使得神经网络可以逼近任意非线性函数,使得神经网络可以应用到大量的非线性模型中。
(2)常见激活函数:
tanh、relu、sigmoid、relkyrelu激活函数,各个激活函数的图像在Tesorflow多层感知器实现广告的预测-CSDN博客
中有详细介绍,其中softmax是一个特殊的整流函数。下面要与线性回归与逻辑回归联合在一起。
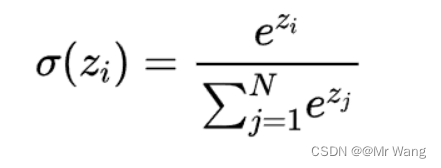
由分类问题可以引出二分类以及多分类问题,对于大多的二分类问题,仅需要在预测结果回复True or False,但对于多分类问题,需要使用softmax激活函数为每一个类别分别设置一个概率,这样便可以计算出每一个类别占总体的百分比。但仅这样是考虑不全面的,当输入存在有负数时,单靠上面那种方法显然是不可行的,故有引入指数函数,以保证最后每个单元输出的概率在范围(0,1),输出之和为1。
Softmax函数的特点包括:
(1)将输入映射到0和1之间:Softmax函数确保每个类别的概率在0和1之间,因此可以用来表示每个类别的相对权重。
(2)归一化:Softmax函数对原始分数进行归一化,使所有类别的概率之和为1,这使得它适用于多类别互斥的分类问题。
(3)放大差异:Softmax函数会放大具有更高原始分数的类别的概率,因此可以更好地区分不同类别的可能性。
2、线性回归与逻辑回归任务
回归分析是处理多变量间相关关系的一种数学方法,当自变量为非随机变量而因变量为随机变量时,它们的关系分析成为 回归分析。回归分析又可分为线性回归与逻辑回归。
什么是分类任务,什么是回归任务?
线性回归主要功能是拟合数据,就是将输入项分别乘以一些常量(constant),将他们的结果求和即为输出,线性回归可以分为一元线性回归与多元线性回归。
线性回归易理解且快,但对于一些相对复杂的模型(比如非线性关系或样本属性的维度过大时),预测结果不好。
- 一元线性回归:
,其中,x为自变量,a为相关系数,b为截距,Y则为因变量。
- 多元线性回归(多自变量单因变量):
,其中,
为回归系数,b为截距。
本人线性回归案例:Tensorflow练手机器学习原理--线性回归-CSDN博客
逻辑回归主要功能是区分数据,找到决策边界。
逻辑回归实际上是一种分类方法。
本人逻辑回归案例:Tensorflow之逻辑回归与交叉熵-CSDN博客
3、梯度优化算法
损失函数(Loss function):☞单个样本预测结果和正确结果的误差值。
代价函数(Cost function):☞所有样本损失函数的总和,用来衡量评估模型的好坏,一般情况下它的值越小则模型越好。
(1)梯度下降(Gradient descent,简称GD)
对于线性关系y = w*x + b,而言,需要找到最优的和
,使得训练的误差(损失Loss)最小,对于计算机而言,可以借助强大的计算能力去多次搜索和试错,使得误差逐渐减小,最简单的优化方法就是暴力搜索和随机试验,但当面对大规模和高维度数据时效率极低,下面介绍一下梯度下降算法。
将梯度下降算法配合强大的图形处理芯片GPU的并行加速能力非常适合优化海量数据的神经网络模型。
函数的梯度指的是函数对各个自变量的偏导数组成的向量(多元微分),梯度的方向是函数值变化最快的方向。
在建立好模型后,会有相关的损失函数,比如均方差损失函数或交叉熵损失函数等。分别对于每一个参数
,求出损失函数关于其的梯度,然后朝着梯度相反的方向使得函数值下降的最快,反复求解梯度,最后就能到达局部最小值。
- 在单变量函数中,梯度其实就是函数的微分,代表函数在给定的某一个点的切线的斜率。
- 在多变量函数中,梯度为多元微分组成的向量,代表一个方向,梯度的方向就指明了函数在给定点上升最快的方向。
梯度下降更新公式:
,这里的
梯度上升更新公式:
,需要找最大时用梯度上升。
在下面举一个多变量函数的梯度下降过程,目标函数为,最小值对应为(0,0),假设初始起点为(1,2),(初始起点就相当于网络参数初始化部分,有很多种方法:random初始化,Xavier初始化,He初始化等,选择合理的初始化方法有利于更好的处理网络梯度问题,提高网络性能),初始学习率
=0.1,则函数的梯度为
,多次Iterate,
就这样不断减小,向最小值(0,0)不断逼近,结束。
(2)梯度消失以及梯度爆炸
梯度消失:神经⽹络靠输⼊端的⽹络层的系数逐渐不再随着训练⽽变化,或者变化⾮常缓慢。随着⽹络层数增加,这个现象越发明显。
解决方案:
- 使用更稳定的激活函数:ReLU、Leaky ReLU 或 ELU 激活函数通常比 Sigmoid 和 Tanh 更不容易出现梯度消失问题;
- 使用 Batch Normalization:Batch Normalization 可以加速神经网络的收敛,并且减少梯度消失问题。
- 使用残差连接(Residual Connections):ResNet 中的残差连接可以帮助信息在网络中更快地传播,减轻梯度消失问题。
梯度爆炸:梯度爆炸是深度神经网络训练过程中的一种现象,指的是在反向传播过程中,梯度值因为多次相乘而急剧增大,导致梯度变得非常巨大甚至溢出。这会造成参数更新过大,导致模型无法收敛或产生不稳定的训练结果。
解决方案:
- 梯度截断(Gradient Clipping):限制梯度的大小,防止梯度爆炸。
- 初始化权重:使用适当的权重初始化方法,如Xavier初始化,可以帮助减少梯度爆炸的发生。
- 调整学习率:适当调整学习率的大小,可能有助于避免梯度爆炸。
(3)学习率(learning rate,简称lr)
学习率代表在一次迭代过程中梯度向损失函数的最优解移动的步长,通常用表示,它的大小决定网络学习的快慢。
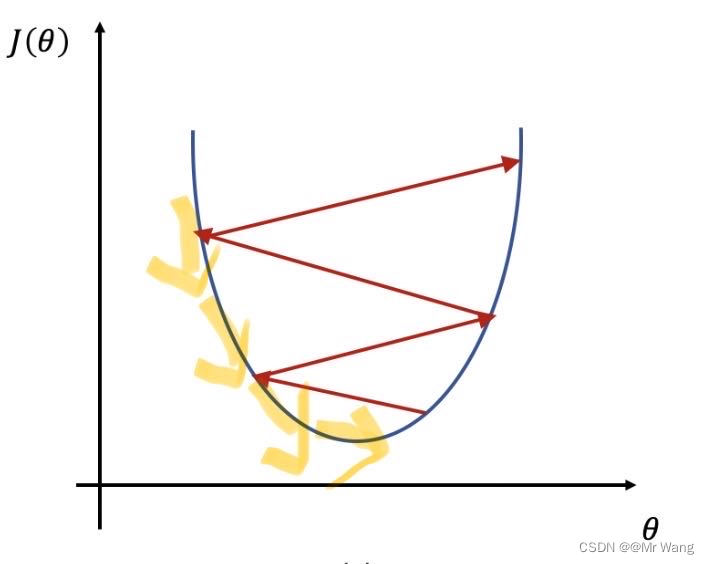
- 当学习率过大时,网络参数学习会很快,进而加快收敛速度,但有可能会在最优解附近来回震荡导致最后难以收敛,如图3中的红色箭头所示。
- 当学习率过小时,网络参数学习会很慢,这样虽然不会错过最优解,但也容易陷入局部最优。
因此,选择一个合适的学习率,对于网络参数的学习至关重要,合适的学习率可以使网络参数以适当的速度逼近全局最优解(如图3黄色箭头)。但学习率一般是需要观察训练过程的各个参数的性能,(不能仅靠损失函数来判定,需要多方面评估)。学习率一般为0.1,0.001,0.0001这样找到一个区间,然后在区间内可以采用二分法逐步判断找到适合的学习率。但如果最后损失收敛在一个较大的范围,可以考虑使用便学习率,这样让损失最后收敛在一个较小的范围。
4、拟合问题
模型的容量是指模型拟合复杂函数的能力。
(1)训练集和测试集
训练集(Train set):是用于模型拟合的数据样本。
验证集(Development set):是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。一般地,通过验证集寻找最优的网络深度(隐藏层个数)以及网络的宽度(每层的神经元个数)。由原本的训练集数据划分而来,用于调参和选择模型。
在这里,超参数可以有很多,主要包括一些在训练过程中不会发生变化的参数,比如学习率(采用定学习率时),经验回放缓存大小,小批量训练大小等。
测试集(Test set):用来评估模型最终的泛化能力。
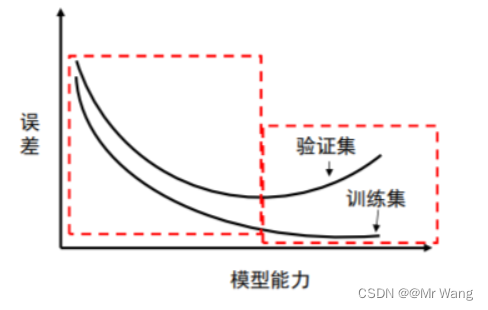
(2)过拟合与欠拟合
- 过拟合是指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测的很好,但对未知数据预测得很差的现象。这种情况下模型可能只是记住了训练集数据,而不是学习到了数据特征。在这种情况下,模型会在训练集上表现良好,在测试集(未见的数据集)上表现不太好。
- 欠拟合是指模型描述能力太弱,以至于不能很好地学习到数据中的规律。产生欠拟合的原因通常是模型过于简单。在这种情况下,模型在训练集和测试集表现都不会太好。
(3)如何解决过拟合和欠拟合问题
以及什么是droupout,如何解决过拟合问题?
解决过拟合问题(通过降低网络容量):
- 重新设计网络容量:降低网络深度或减小网络宽度。
- 增加训练数据样本,或者是说为数据集扩增,比如在强化学习中网络参数引入随机噪声(加入Noisy Net,名义上称为噪声,实际可以对action产生与
差不多的效果)再训练,或者是对原始图像做部分截取或旋转角度等。
- Dropout:Dropout是通过改动神经网络本身实现的,在训练时随机断开神经网络的连接,减少每次模型在训练时实际参与计算的参数量,但在测试时,为保证模型获得较好的性能Dropout会恢复所有的连接部分,如图4所示。
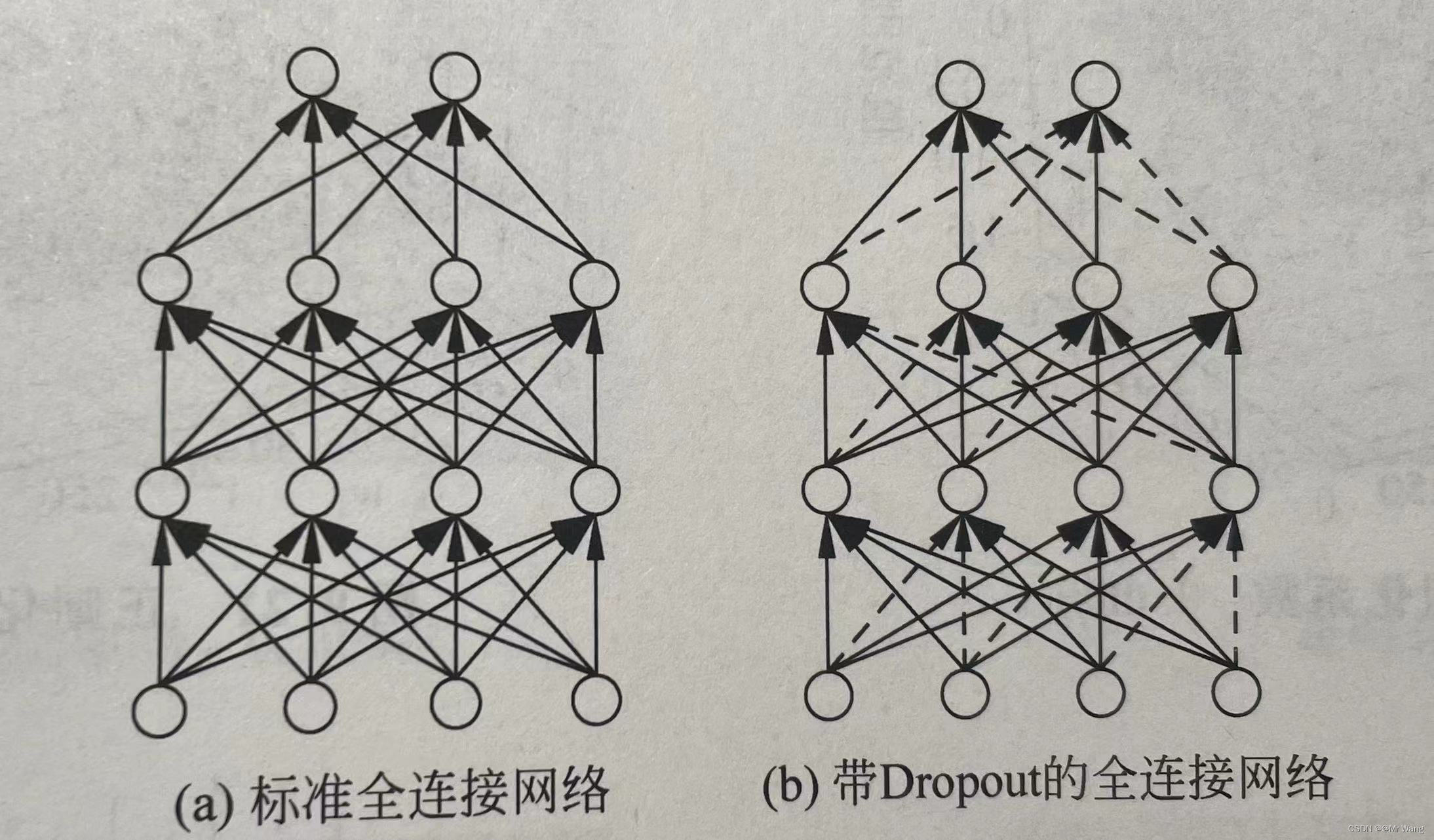
- 添加正则化手段(L0,L1,L2)
- 提前停止训练。
解决欠拟合问题:可以通过增加网络容量(增加网络深度以及网络宽度),尝试更加复杂的网络结构。
(4)提前stop training
一般地,把对训练集中的一个Batch运算称作为一个step,对训练集的所有样本循环迭代一次称为一个Epoch。
当模型正常拟合的情况下,模型的各个参数会趋向收敛的状态,损失不再降低,这时如果不及时停止训练模型,就会导致模型过度学习训练的数据集,不仅学习到了数据集的特征,还把额外的观测误差也学习到,极大的降低泛化能力。
# 带有Early stopping的网络训练算法
Output:the performence of the network parameter seta and test
Random initialize the parameter seta
Initialize the size of mini-banch and experience replay buffer |D|
repeatfor step=1,2,...,N doRandom sample Batch{(x,y)}~DUpdate seta with gradient descent algorithmendif every the n-th Epoch doTest the performence of all {(x,y)}~Dif Multiple failures to improve performance during validation doSave the state of the network,early stoppingend ifend if
until Training to the maximum number of Epoch
5、数据预处理部分
特征选择、特征提取、特征工程
特征选择:从原始数据中选择最相关和最有价值的特征,从而提高模型的性能和准确性,同时减少模型的复杂度和计算资源消耗。就是为了消除一些冗余和目标无关的特征,保留对预测目标有用的特征,进而提高模型的泛化能力和效率。
使用的方法:
特征提取:将原始数据转换为具有更高维度或更有意义的特征表示的过程,旨在提高模型的学习效果。
特征工程:通过对数据进行处理和转换,提取出更有用的特征以供机器学习模型使用,从而改善模型的性能和效果,有利于减少数据噪声,提高模型的泛化能力。
为什么要建立特征工程?
-
归一化(Normalization)与标准化(Standardization)
归一化与标准化都是对数据做变换的方式,对数据特征缩放到某一个范围,把原始数据的某一列数据转换到某一个范围或者某种形态。
归一化:将某一列中的数据缩放到某一个区间范围内,通常这个区间可以为[0,1],[-1,1]等,可以根据实际需要设定,归一化可以有很多种形式,如:
min-max normalization:
,[0,1]区间
mean normalization:
,[-1,1]区间
标准化:将数据变换为均值为0且标准差为1的分布,此分布会追随原本数据的分布状态,因此,经标准化后数据的分布不一定是正态分布的。
standardization:
中心化:零均值处理,就是用原始数据减去这些数据的均值后的值。
批归一化(Batch Normalization):可以对每一批(batch)数据进行归一化,传统的归一化操作一般都是在输入网络之前对特征进行归一化,但是BN可以在网络的任意一层进行归一化处理。
-
数据缺失
数据缺失可由机械错误(机械原因导致的数据集中缺失数据)和人为错误(由人的主观因素:漏录,无效数据等)导致。若有数据缺失,则要么删除有缺失项的数据整体,要么是对数据缺失的数据项做一些处理,再就是对其置之不理。
缺失值从缺失的分布来讲可以分为完全随机缺失(数据的缺失是随机的,数据的缺失不依赖任何不完全变量或完全变量),随机缺失(数据缺失不是完全随机的,依赖于其他完全变量)和非完全随机缺失(数据缺失依赖于不完全变量本身)。
缺失值从缺失属性来讲,若所有缺失值都为同一属性(同一列)则为单值缺失,若为不同的属性,则为任意缺失。
1、删除包含缺失项的数据整体,主要包含简单删除发和权重法。
- 简单删除:将存在缺失值的个案删除,当缺失值为非完全随机时,可通过对完整数据加权来减小偏差
- 用可能值插补缺失值:
-
图像处理(计算机视觉)
图像透视变化☞改变图像的透视效果,使得原本在三维空间中呈现的透视关系在二维图像中得到修正或变换。透视变换通常用于校正图像中的透视畸变,例如将斜视角拍摄的图像调整为正视角,或者将图像中的某些区域拉伸或压缩以改变其形状。
图像去噪/降噪☞在数字图像中减少或去除由于图像采集、传输或处理过程中引入的噪声的过程。噪声可以是由传感器、电路、环境等因素引起的随机干扰,降噪技术旨在提高图像的质量和清晰度,以便更好地进行后续的图像分析、处理或展示。
图像配准☞将多幅图像中的对应特征点或区域进行匹配和对齐的过程,以使它们在同一坐标系下对齐或校准。这个过程通常涉及到图像中的旋转、平移、缩放和畸变等变换,旨在消除图像间的空间差异,以便进行后续的分析或处理。
图像分割☞将数字图像划分为多个具有独特特征或语义的区域或像素的过程。这些区域通常代表了图像中的不同对象、结构或区域。
数据清洗☞对数据进行检查、修复、删除或补充,以确保数据质量符合特定标准或要求的过程。这包括识别和纠正数据中的错误、缺失、重复或不一致的部分,以便在进行数据分析、建模或应用程序开发时能够得到准确、可靠的结果。
目标检测☞在图像或视频中自动识别和定位特定对象的过程,目标检测不仅要确定图像中是否存在目标,还要准确地标出目标的位置。
6、RNN循环神经网络
RNN中包含的模型目前主要有LSTM和GRU,下面简单介绍一下LSTM算法。
RNN与传统全连接网络不同,引入新的名词隐状态(hidden state),隐状态可以对序列行的数据提取特征,再转换为输出。
其中,和
经过上述变换后,得到当前时间戳的新的状态向量
并写入内存状态中,然后对应在每个时间戳上均有输出
产生,
。上述网路结构在时间戳上重叠,网络循环接受序列的每个特征向量
,并刷新内部状态向量ht,同时形成输出yt。f一般为非线性激活函数,且尤为重点的就是在RNN中计算时,每一个时间戳计算时所用到的参数U,W,b都是一样的,即经典RNN的参数是共享的(RNN的权值是在同一个向量中,只是时间戳t不同而已)。
...
其中,在任意时间戳t,对应为当前时间戳的输入,
对应为上一个时间戳的网络状态向量,
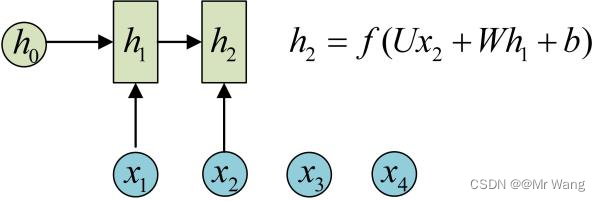
对于输出,可以通过自己设定,可以让当前时刻t的状态向量直接作为输出(什么处理也不做),即
;可以对
做一个线性变换,即输出
;也可以对
做一个非线性处理,比如在其外面再加入激活函数,sigmoid,relu,softmax等变换,即输出
。这里要注意,对状态向量
做处理时,也要遵守权值共享原则。

RNN的堆叠形式如图6左边所示,展开则由图6中的右边所示,RNN可以看成是一个神经网络的多次复制,每一个神经网络模块A会把消息依次传递给下一个模块。
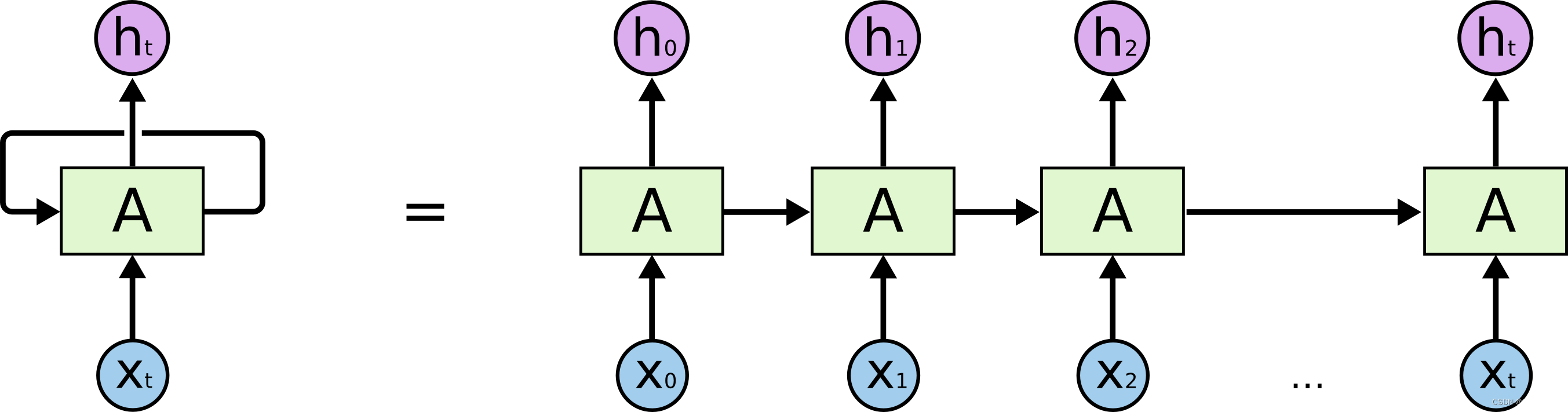
解释一下RNN的短期和长期依赖问题:
以自然语言处理为例,当RNN在处理较简单的句子预测时,前面的信息和预测的词间距很小时,那么,RNN会学会使用先前的信息,较好的表现。但是当在一些复杂的场景时,在预测“I grow up in China ... and I like China”这段文本的最后一个词China时,可能会知道当前需要填写一个语言类型,但是需要离当前位置较远的先前提到的“China”的前后文的。经研究人员发现,RNN仅能理解有线长度范围内的信息,对于较长范围内的有用信息往往不能很好地利用起来,即会丧失学习连接到如此远的信息的能力,称为短时记忆。
故经研究人员研究,发现记忆能力更强,一种更擅长处理较长的序列信号的数据,LSTM(Long Short-Term Memory),下面将介绍LSTM算法。
-
LSTM算法
下面讲述一下LSTM算法,相对于基础的RNN网络只有一个状态向量,LSTM新增了一个状态向量
,同时引入门控(Gate)机制,通过门控单元来控制信息的遗忘和刷新。
所有的RNN网络,都是一种具有重复神经网络的链式的结构,在标准的RNN网络中,这个重复的模块(神经网络)只有一个简单的结构,例如一个tanh或sigmoid层,tanh使得数据范围控制在[-1,1]之间,有利于帮助调节流经神经网络的之值。但对于LSTM网络,重复的模块有一个不同的结构,LSTM中重复的模块一般包含有四个交互的层,3个sigmoid和一个tanh层,使用sigmoid的原因主要是因为其取值范围在[0,1],有利于较好的选取数据记忆(更新或遗忘,x*0=0,x*1=x)。
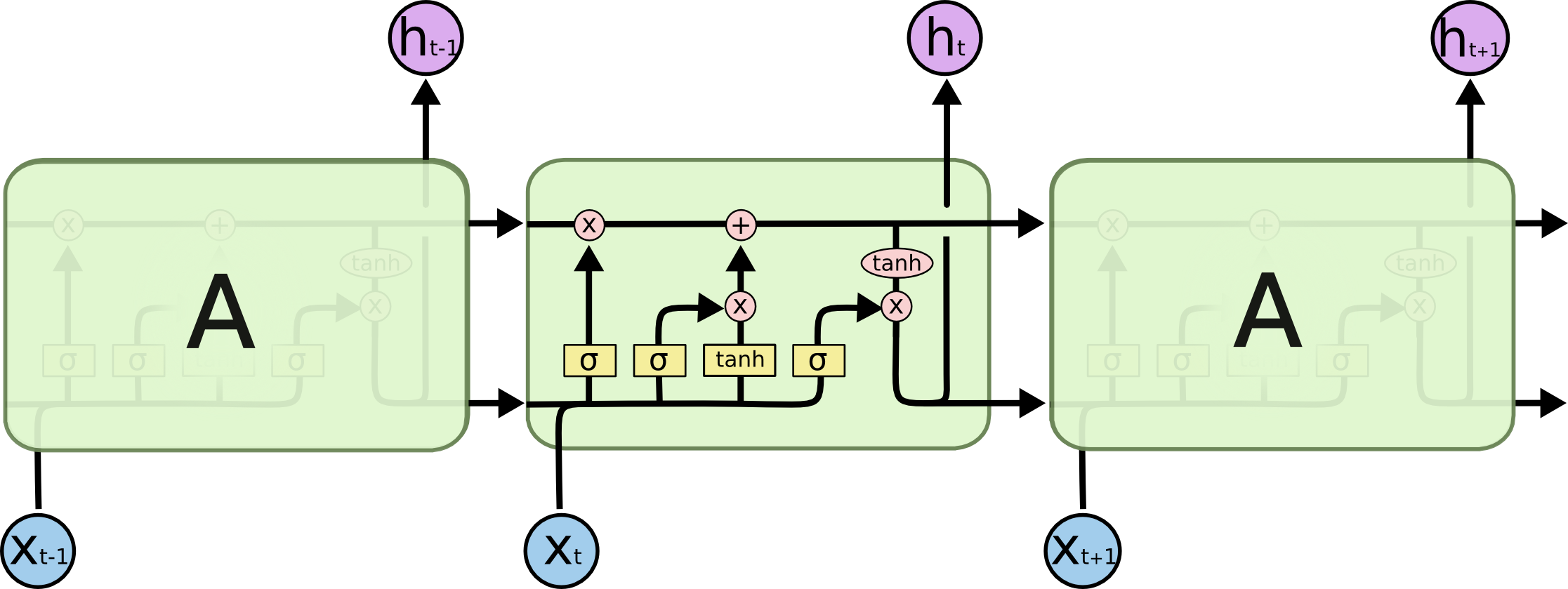
在这里,如图8,讲一下各个符号代表的含义,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。圆圈代表pointwise的操作,诸如向量的和或向量的乘(看圈中是什么符号),而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。

在这里,由于LSTM由遗忘门、输入门和输出门组成,下面简单叙述一下各部分的用处,就能看懂各个部分的过程,如图 9,
遗忘门:通过读取和
做一个sigmoid(等同于图9中的
)的非线性映射,输出一个向量
,向量中的不同维度上的值有不同的意义(1完全保留,0忘记/丢失)。
输入门:会决定什么样的信息被存放在细胞状态中,sigmoid决定什么值将要被更新,tanh层创建了一个新的候选值向量Ct,被加入到状态中。
输出门:

7、CNN卷积神经网络
首先,阐述一下为什么要有卷积神经网络CNN,CNN相比于全连接神经网络的好处有哪些?
- 局部相关性:以图片类型数据为输入的场景为例,对于二维图片数据在传入全连接层之前(fully-connected layer),需将矩阵打平成为一维向量,然后每个像素点与每个输出节点两两相连,其输出与输入的关系为(nodes(I)表示第I层的节点集合):
下面,找一种近似的简化模型,可以分析输入节点对输出节点的重要性分布,仅考虑较重要的一部分输入节点,这样输出节点只需要与部分输入节点相连接,表达为:
其中top(I,j,k)表示第I层中对于J层中的j号节点重要性最高的前n个节点集合,通过这种方式,可以把权值个数由|| I ||*|| J || 减少到k*|| J ||,其中 || I ||和|| J ||分别表示I、J层的节点数量。
接着问题转化为探索第I层中对于第J层中的j号输出节点重要分布,然后认为图片每个像素点和周边像素点的关联度更大(位置相关)。以二维图片数据为例,简单认为像素的欧氏距离小于等于x的像素点重要性较高,大于x的像素点重要性较低,这种仅关注和自己距离较近的部分节点而忽略距离较远的节点称为局部相关性。
- 权值共享:每个输出节点仅与感受野区域内k*k个输入节点相连接,输出节点数为|| J ||,则当前层参数量为k*k*|| J ||,通过权值共享的思路,对于每个输出节点
,均使用相同的权值矩阵W,那么无论输出节点数量|| J ||为多少,网络参数量总是k*k。准确的说,在但单入通道、单卷积核的条件下,参数量由|| I ||*|| J ||成功减低到k*k。
CNN由输入层、卷积层、池化层、全连接层以及输出层组成。
- 输入层:输入图像等信息。
- 卷积层:用来提取图像的底层特征。
- 池化层/降采样:防止过拟合,将数据维度减小。
- 全连接层:汇总卷积层和池化层得到的图像的底层特征和信息。
- 输出层:根据全连接层的信息得到概率最大的结果。
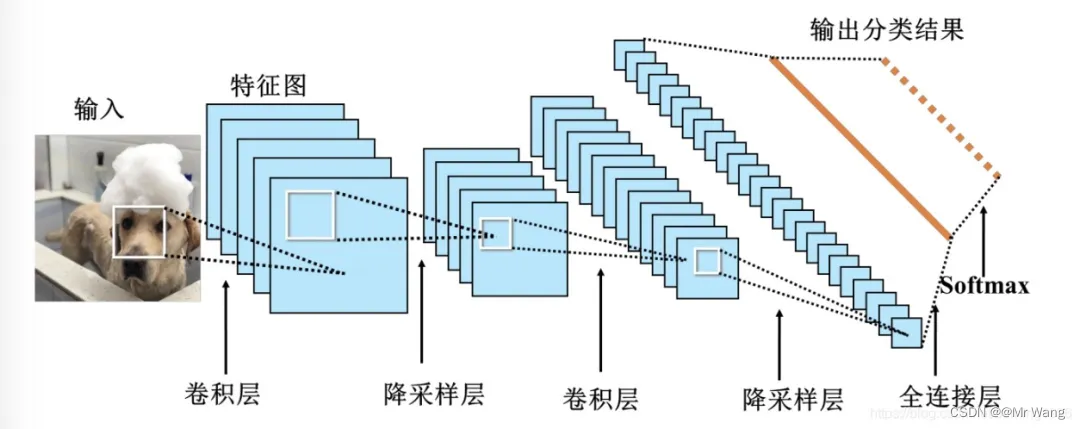
输入层:就是把相对应的图像转换为与其对应的由像素构成的二维矩阵,并将次二维矩阵存储起来等待后面操作。
卷积层:可以包含有多个可学习的滤波器(也称为卷积核),在输入数据上滑动,进行卷积操作进而生成特征图(图像领域中通常为新生成的二维矩阵),且每个卷积核只能完成某种逻辑的特征提取,当需要有多种逻辑特征提取时,可以选择增加多个卷积核得到多种特征。

以图片的二维矩阵为例,想要提取其中特征,那么卷积操作就会为存在特征的区域确定一个高值,否则确定一个低值。
卷积核也是一个二维矩阵,当然这个二维矩阵要比输入图像的二维矩阵要小或相等,卷积核通过在输入图像的二维矩阵上不停的移动,每一次移动(按照从左到右,移动到右边边界后回到行首,接着从上到下的顺序移动,一直移动到原始图片数据的右下方)都进行一次乘积的求和,作为此位置的值。
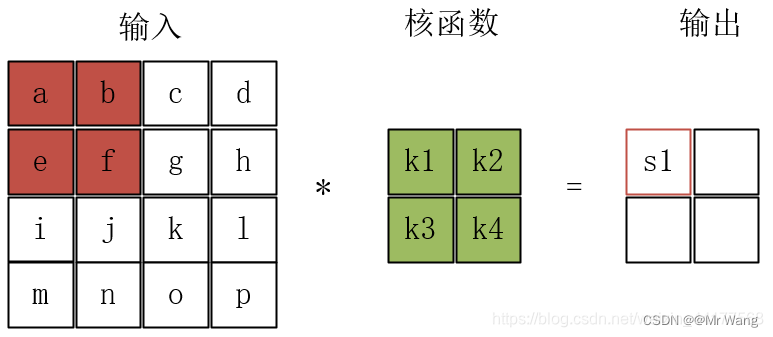
中间的核函数就是卷积核,左边红色方框内的四个元素称为感受野,与卷积核的大小相同,那么是如何得到特征图的呢?卷积核与感受野之间的运算就是把两个矩阵对应的元素相乘得到的矩阵各元素求和填到特征图的对应位置上。卷积核为2*2,感受野也为2*2(每次移动的步长为2),故在计算特征图的时候s1 = a*k1+b*k2+e*k3+f*k4,s2=c*k1+d*k2+g*k3+h*k4,s3=i*k1+j*k2+m*k3+n*k4,s4=k*k1+l*k2+o*k3+p*k4,且s2填写在s1的右边,最后特征图为[[s1,s2],[s3,s4]]。
下面讲解一下为什么要填充(Padding):
由于卷积核在计算特征图时,需要与原本的图像数据中截取感受野大小的窗口进行计算,随着每次移动一定的步长,会发现靠近中间的图片像素数据会被计算多次,但靠近边框的图片像素点数据被计算的次数会少很多,因此选择在原始数据的外围扩展一些空格,这样原本边框的数据也会被计算多次。
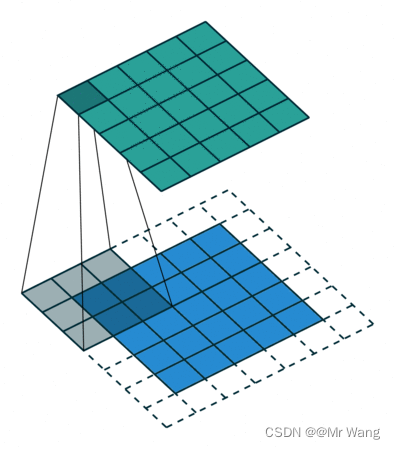
池化层:减小特征图的空间维度,从而减少模型的参数量和计算复杂度,并且可以增强模型的鲁棒性.
有几个卷积核就有多少个特征图,现实中情况肯定更为复杂,也就会有更多的卷积核,那么就会有更多的特征图。池化层又称为下采样/降采样,也就是说,当我们进行卷积操作后,再将得到的特征图进行特征提取,将其中最具有代表性的特征提取出来(保持主要特征并减少冗余信息来提取出更加重要的特征),可以起到减小过拟合和降低维度的作用,这个过程如下所示:
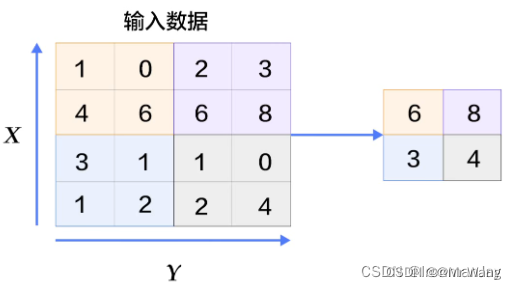
另外,池化可以分为最大池化和平均池化。
最大池化就是每次取正方形中所有值的最大值,这个最大值也就相当于当前位置最具有代表性的特征,如图13所示,最大池化用的稍微多点。
平均池化就是取此正方形区域中所有值的平均值,考虑到每个位置的值对于此处特征的影响。
全连接层: 对运算得到的特征图展平,将其维度变为1*x,然后进行计算,得到输出值。
全连接层将卷积层和池化层提取到的特征连接起来,并输出最终的分类或回归结果。它采用传统神经网络中常见的全连接结构,每个神经元都与上一层的所有神经元相连。全连接层的作用是对特征进行组合和整合,以便进行最终的预测。
输出层:输出最后的预测结果,如图14所示,二分类用sigmoid,多分类用softmax。
import tensorflow as tf
from tensorflow.keras import layers# 构建CNN模型
model = tf.keras.Sequential()# 添加卷积层
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(layers.MaxPooling2D((2, 2)))# 添加更多卷积层和池化层
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))# 将特征图展平为一维向量
model.add(layers.Flatten())# 添加全连接层
model.add(layers.Dense(64, activation='relu'))# 输出层
model.add(layers.Dense(10, activation='softmax'))# 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 加载数据并训练模型
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))8、使用Tensorflow1.0/2.0框架创建神经网络
- Tensorflow1.0代码:注意,1.0版本的对应x,y只是占位符,张量形状此时已经有,值是在下面对话session中传入的。
import tensorflow as tf# 定义神经网络的输入
x = tf.placeholder(tf.float32, [None, 784])# 定义神经网络的参数
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))# 定义神经网络的输出
y = tf.nn.softmax(tf.matmul(x, W) + b)# 定义损失函数
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))# 定义优化方法
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)# 创建会话并进行训练
with tf.Session() as sess:sess.run(tf.global_variables_initializer())for i in range(1000):batch_xs, batch_ys = mnist.train.next_batch(100)sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})- Tensorflow2.0代码
import tensorflow as tf# 加载数据,数据预处理部分
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0# 定义神经网络的模型
model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
model.evaluate(x_test, y_test, verbose=2)Reference
[1]《Tensorflow深度学习》书籍
[2] 《Netural Network Design》书籍
[3]激活函数(Activation Function)小结_有一个机器学习常用的激活函数activation function,当输入<0-CSDN博客
[4]学习率设置-CSDN博客
[5]回归分析(线性回归、逻辑回归)详解与 Python 实现_多变量逻辑回归分析-CSDN博客
[6]梯度下降算法原理讲解——机器学习-CSDN博客
[7]标准化和归一化,请勿混为一谈,透彻理解数据变换-CSDN博客
[8]如何从RNN起步,一步一步通俗理解LSTM_rnn lstm-CSDN博客
[9]卷积神经网络CNN的由来,为什么要用卷积?_卷积神经网络为什么叫卷积-CSDN博客
[10]卷积神经网络(CNN)详细介绍及其原理详解-CSDN博客
[11]卷积神经网络 Convolutional Neural Network | CNN-CSDN博客
[12]卷积神经网络(Convolutional Neural Network,CNN)
[13]https://zhuanlan.zhihu.com/p/589762877
相关文章:
机器学习与数据挖掘知识点总结(一)
简介:随着人工智能(AI)蓬勃发展,也有越来越多的人涌入到这一行业。下面简单介绍一下机器学习的各大领域,机器学习包含深度学习以及强化学习,在本节的机器学习中主要阐述一下机器学习的线性回归逻辑回归&…...

行心科技中禄松波携手,开启智能健康新时代
在2024年第34届健博会暨中国大健康产业文化节的盛大舞台上,广州市行心信息科技有限公司(以下简称“行心科技”)与浙江中禄松波生物工程有限公司(以下简称“中禄松波”)宣布达成战略合作,共同推动医康养产业…...
前端多人项目开发中,如何保证CSS样式不冲突?
在前端项目开发中,例如突然来了一个大项目,很可能就需要多人一起开发,领导说了,要快,要快,要快,你们给我快。然后下面大伙就一拥而上,干着干着发现,一更新代码࿰…...

【YOLOv10改进[CONV]】使用DualConv二次创新C2f模块实现轻量化 + 含全部代码和详细修改方式 + 手撕结构图 + 全网首发
本文将使用DualConv二次创新C2f模块实现轻量化,助力YOLOv10目标检测效果的实践,文中含全部代码、详细修改方式以及手撕结构图。助您轻松理解改进的方法。 改进前和改进后的参数对比: 目录 一 DualConv 1 结合33卷积和11卷积核 2 DualConv 3 可视化 二 C2f_DualConv助…...
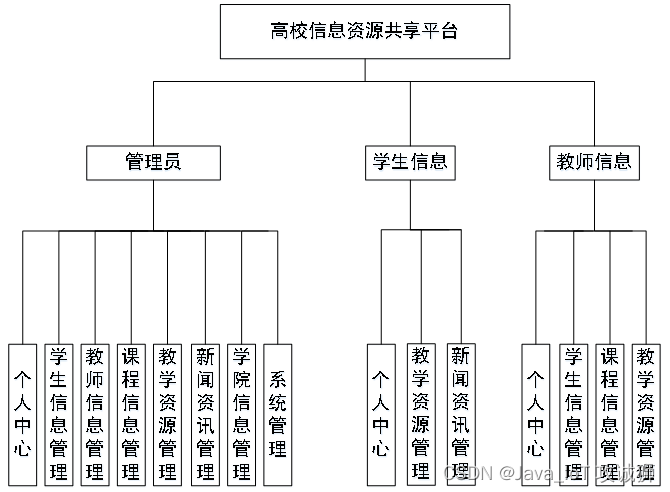
基于SSM+Jsp的高校信息资源共享平台
开发语言:Java框架:ssm技术:JSPJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包…...
软件测试--Linux快速入门
文章目录 软件测试-需要掌握的Linux指令Linux命令操作技巧Linx命令的基本组成常用命令 软件测试-需要掌握的Linux指令 Linux命令操作技巧 使用Tab键自动补全上下键进行翻找之前输入的命令命令执行后无法停止使用CtrC,结束屏幕输出 Linx命令的基本组成 命令 [-选项] [参数] …...

module ‘django_cas_ng.views‘ has no attribute ‘login‘
这个错误表明你正在尝试从django_cas_ng.views模块中访问一个名为login的属性,但是这个模块中并没有名为login的属性或方法。 解决这个问题,你需要确认你的代码中是否有错误的引用。django_cas_ng是一个CAS(Central Authentication Service&…...
CW32F030K8T7单片机在即热式热水器的应用介绍
随着智能家居技术的不断进步,即热式热水器作为现代家庭中的重要组成部分,正逐渐向智能化、节能化方向发展。本方案通过采用武汉芯源半导体的CW32F030系列单片机,以其高性能、超强抗干扰等特性,为即热式热水器的智能化提供了理想的…...

HTML静态网页成品作业(HTML+CSS)—— 美食湘菜介绍网页(5个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有5个页面。 二、作品演示 三、代…...

使用redis构建简单的社交网站
Redis命令实践通常涉及对Redis服务器的直接操作,包括数据的增删改查以及管理Redis实例。以下是一些基本的Redis命令及其使用场景: 连接Redis服务器: 使用Redis客户端连接到Redis服务器:redis-cli 设置和获取键值对: SET key value࿱…...

【Java面试】九、微服务篇-SpringCloud(上)
文章目录 1、SpringCloud五大组件2、服务注册和发现2.1 Eurake2.2 Eurake和Nacos的区别 3、Ribbon负载均衡3.1 策略3.2 自定义负载均衡策略 4、服务雪崩与熔断降级4.1 服务雪崩4.2 服务降级4.3 服务熔断 5、服务限流5.1 Nginx限流5.2 网关限流 6、微服务监控7、面试 1、SpringC…...

Python 树状数组
树状数组(Binary Indexed Tree, BIT),又称为斐波那契堆,是一种数据结构,用于高效地解决以下问题: 单点更新:在数组的某个位置增加或减少一个值。区间查询:查询数组中一段连续区间的…...
)
【QEMU中文手册】2.2 调用方式(持续更新中)
本文由 AI 翻译(ChatGPT-4)完成,并由作者进行人工校对。如有任何问题或建议,欢迎联系我。联系方式:jelin-shoutlook.com。 原文:Invocation — QEMU documentation qemu-system-x86_64 [选项] [磁盘镜像]磁…...
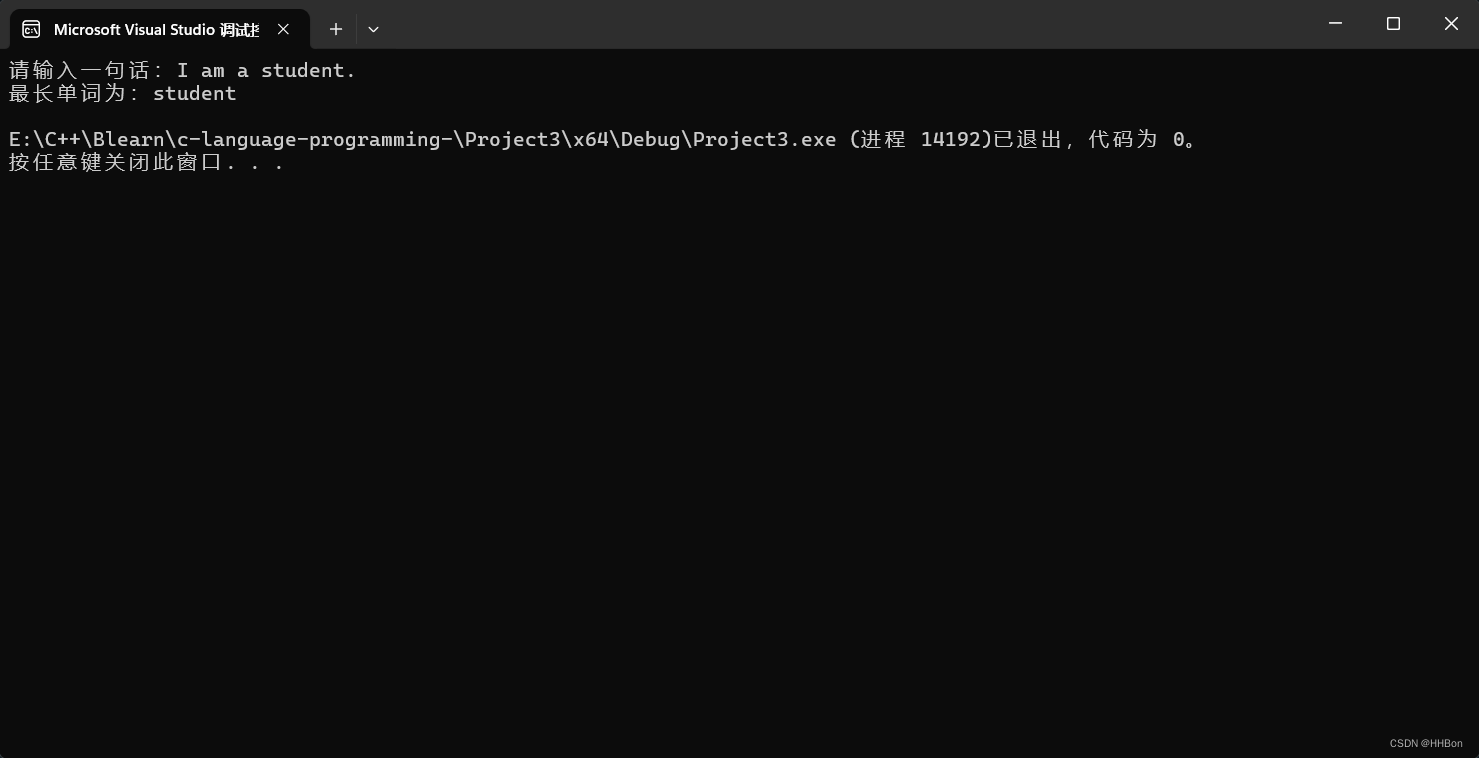
(函数)判断一句话中最长的单词(C语言)
一、运行结果; 二、源代码; # define _CRT_SECURE_NO_WARNINGS # include <stdio.h>//声明函数; int aiphabetic(char); int longest(char[]);int main() {//初始化变量值;int i;char line[100] { 0 };//获取用户输入字符…...

QT5.5.0中使用lambda表达式时遇到的问题
QT5.5中使用lambda表达式的遇到的error_qt中lamda不起作用-CSDN博客...

【Go语言精进之路】构建高效Go程序:了解切片实现原理并高效使用
🔥 个人主页:空白诗 文章目录 引言一、切片究竟是什么?1.1 基础的创建数组示例1.2 基础的创建切片示例1.3 切片与数组的关系 二、切片的高级特性:动态扩容2.1 使用 append 函数扩容2.2 容量管理与性能考量2.3 切片的截取与缩容 三…...

Python与C语言:深入探索两者的奥秘与差异
Python与C语言:深入探索两者的奥秘与差异 在编程的世界里,Python和C语言如同两位性格迥异的伙伴,各自拥有独特的魅力和应用场景。Python以其简洁易懂的语法和强大的库支持赢得了众多开发者的青睐,而C语言则以其接近硬件的低级特性…...

图像编解码器在AI绘画中的革新作用
随着人工智能技术的飞速发展,AI绘画已经从一个简单的概念演变为一个充满创意与可能性的领域。在这场技术与艺术的融合中,图像编解码器扮演着至关重要的角色。它们不仅提升了AI绘画的质量和效率,还拓宽了艺术创造的边界。本篇博客将深入探讨图…...

SecureCRT[po破] for Mac SSH终端操作工具[解] 安装教程
文章目录 效果一、准备工作二、开始安装1、双击运行软件,将其从左侧拖入右侧文件夹中,等待安装完毕2、 应用程序显示软件图标,表示安装成功 三、输入对应参数1、解决“软件已损坏,无法打开,要移到废纸篓”问题解决步骤…...

【大数据架构】基于流式数据的大数据架构升级
背景 团队在升级大数据架构,摒弃了原来基于hadoop的架构,因此抛弃了hive,hdfs,mapreduce这一套,在讨论和摸索中使用了新的架构。 后端使用kafka流式数据通过rest catalog写入iceberg,存储于minio。在写入iceberg的时候,首先是写data数据文件,然后再写iceberg的metada…...

如何用Bypass Paywalls Clean突破付费墙限制?技术解析与实战指南
如何用Bypass Paywalls Clean突破付费墙限制?技术解析与实战指南 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在数字内容付费墙日益严密的今天,Bypass Payw…...

别再用默认字典了!DVWA暴力破解实战:从Low到High,手把手教你配置Burp Suite的Pitchfork模式
别再用默认字典了!DVWA暴力破解实战:从Low到High,手把手教你配置Burp Suite的Pitchfork模式 在渗透测试的入门阶段,暴力破解往往是最先接触的攻击手段之一。但许多新手在DVWA的High级别面前束手无策——那些看似简单的登录表单&am…...

Phi-3-mini-4k-instruct-gguf实战案例:用轻量模型替代Llama3-8B做高频短任务降本
Phi-3-mini-4k-instruct-gguf实战案例:用轻量模型替代Llama3-8B做高频短任务降本 1. 为什么选择轻量模型 在AI应用落地的过程中,我们常常面临一个困境:大模型效果虽好,但部署成本高、响应速度慢。特别是在处理大量高频短任务时&…...

暗黑破坏神2单机增强神器:PlugY插件全方位使用指南
暗黑破坏神2单机增强神器:PlugY插件全方位使用指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 对于暗黑破坏神2单机玩家而言,有限的储物空…...

从SolidWorks到ROS:六自由度机械臂URDF模型转换实战指南
1. 从SolidWorks到ROS的桥梁:URDF模型转换概述 当你费尽心思在SolidWorks中完成了六自由度机械臂的三维建模,看着那些精密的齿轮和连杆在软件中流畅转动时,脑海中可能已经浮现出它在ROS环境中大展身手的场景。但问题来了:如何让这…...

【flash-attn安装成功却import失败?一个ABI参数引发的‘血案’】
1. 为什么flash-attn安装成功却import失败? 最近在部署Llama2模型时,遇到了一个让人抓狂的问题:明明用pip安装了flash-attn,执行import时却报错提示找不到这个包。更诡异的是,pip list明明显示安装成功了,…...

BurpSuite导入P12证书遇到密码问题?3种无密码解决方案实测
BurpSuite导入P12证书遇到密码问题?3种无密码解决方案实测 在企业安全测试和渗透评估过程中,客户端证书认证是常见的防护机制。当BurpSuite提示需要P12证书密码而您又无法获取时,整个测试流程可能陷入僵局。本文将分享三种经过实战验证的解决…...

AI报告文档审核赋能人才培养:IACheck打造环境检测人机协同审核虚拟仿真新体系
在环境检测行业持续走向精细化与规范化的过程中,报告审核能力逐渐成为影响整体质量的重要因素。然而,与检测设备和分析技术不断升级相比,审核人员的培养却长期依赖经验积累与“师带徒”模式,这种方式虽然能够传递实践经验…...

深圳嵌入式技术产业创新与应用全景
1. 深圳嵌入式科技产业全景扫描 深圳作为中国科技创新高地,已形成全球最完整的嵌入式技术产业链。从消费电子到工业控制,从汽车电子到医疗设备,嵌入式系统正以"润物细无声"的方式重塑各个行业。这座城市聚集了超过2000家嵌入式相关…...

Wireshark抓包实战:用一道CTF题彻底搞懂IP分片与UDP重组
Wireshark抓包实战:用一道CTF题彻底搞懂IP分片与UDP重组 在网络安全竞赛中,一个看似简单的UDP传输任务可能隐藏着协议层面的精妙设计。去年CyBRICS赛事中的lx100题目就完美诠释了这一点——参赛者需要从相机传输的UDP流量中提取图片,而真正的…...