Oracle数据库面试题-9
81. 请解释Oracle数据库中的林业数据处理方法。
Oracle数据库中的林业数据处理
在Oracle数据库中处理林业数据涉及到存储、管理、分析和可视化与林业相关的数据。以下是林业数据处理的一些关键方面以及如何使用Oracle数据库进行示例性的SQL说明:
-
数据库设计:为了管理林业数据,需要在Oracle数据库中设计表来存储不同类型的林业数据。这些表可能包括森林区域表、树种表、植被调查表、林业许可证表、采伐数据表和林产品出货表等。每个表都会包含与林业生产和管理活动相关的信息。
-
数据存储:存储林业数据时,需要确保数据的完整性和准确性。数据库设计应该考虑到数据的一致性和引用完整性,以便于未来进行数据分析和预测。
-
数据分析和查询:Oracle SQL是进行林业数据查询和分析的强大工具。通过编写SQL语句,可以轻松地从数据库中提取林业数据,进行森林资源评估、林区分析、许可证管理和其他数据驱动的决策支持。
-
性能优化:针对林业数据的查询和分析,可能需要对数据库进行性能优化,例如索引、分区和物化视图等技术。
-
空间和时间分析:林业数据经常需要根据空间和时间进行分析。Oracle数据库支持空间数据类型(如SDO_GEOMETRY)和时间数据类型(如TIMESTAMP),可以有效地进行这类查询。
-
安全性和合规性:数据库安全性是确保数据完整性和遵守法律法规的关键。Oracle提供了高级的安全特性,如数据加密、网络安全和审计功能。
示例SQL代码
以下是一些示例SQL代码,展示了如何在Oracle数据库中管理林业数据,并不代表实际的林业数据库设计。
-- 创建示例表-- 森林区域表
CREATE TABLE forest_area (area_id NUMBER PRIMARY KEY,area_name VARCHAR2(100),location SDO_GEOMETRY,area_description VARCHAR2(4000)
);-- 树种表
CREATE TABLE tree_species (species_id NUMBER PRIMARY KEY,genus VARCHAR2(50),species VARCHAR2(50),common_name VARCHAR2(100)
);-- 植被调查表
CREATE TABLE vegetation_survey (survey_id NUMBER PRIMARY KEY,area_id NUMBER REFERENCES forest_area(area_id),survey_date TIMESTAMP,species_id NUMBER REFERENCES tree_species(species_id),count NUMBER
);-- 林业许可证表
CREATE TABLE forestry_license (license_id NUMBER PRIMARY KEY,area_id NUMBER REFERENCES forest_area(area_id),license_type VARCHAR2(100),issue_date TIMESTAMP,expiry_date TIMESTAMP
);-- 采伐数据表
CREATE TABLE timber_harvest (harvest_id NUMBER PRIMARY KEY,area_id NUMBER REFERENCES forest_area(area_id),species_id NUMBER REFERENCES tree_species(species_id),harvest_date TIMESTAMP,volume NUMBER
);-- 示例数据插入-- 插入森林区域数据
INSERT INTO forest_area (area_id, area_name, location, area_description)
VALUES (1, 'Amazon Rainforest', SDO_GEOMETRY(2001, NULL, SDO_POINT_TYPE(-63.90, -3.72, NULL), NULL, NULL), 'The largest rainforest in the world, located in South America.');-- 插入树种数据
INSERT INTO tree_species (species_id, genus, species, common_name)
VALUES (1, 'Acacia', 'senior', 'Coastal Sequoia');-- 插入植被调查数据
INSERT INTO vegetation_survey (survey_id, area_id, survey_date, species_id, count)
VALUES (1, 1, TO_TIMESTAMP('2023-04-01 12:00:00', 'YYYY-MM-DD HH24:MI:SS'), 1, 10000);-- 插入林业许可证数据
INSERT INTO forestry_license (license_id, area_id, license_type, issue_date, expiry_date)
VALUES (1, 1, 'Timber Harvest', TO_TIMESTAMP('2023-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), TO_TIMESTAMP('2024-12-31 23:59:59', 'YYYY-MM-DD HH24:MI:SS'));-- 插入采伐数据
INSERT INTO timber_harvest (harvest_id, area_id, species_id, harvest_date, volume)
VALUES (1, 1, 1, TO_TIMESTAMP('2023-06-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), 500);-- 数据查询示例-- 查询特定森林区域的植被调查数据
SELECT * FROM vegetation_survey WHERE area_id = 1;-- 查询特定树种的采伐数据
SELECT * FROM timber_harvest WHERE species_id = 1;-- 使用空间函数进行数据分析-- 计算每个森林区域的植被调查次数
SELECT area_id, COUNT(*) AS survey_count
FROM vegetation_survey
GROUP BY area_id;-- 查询在特定时间范围内采伐的树木数量
SELECT SUM(volume) AS total_harvested_volume
FROM timber_harvest
WHERE harvest_date BETWEEN TO_TIMESTAMP('2023-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND TO_TIMESTAMP('2023-12-31 23:59:59', 'YYYY-MM-DD HH24:MI:SS');在上述示例中,我们首先创建了四个表来存储森林区域、树种、植被调查和采伐数据。然后,我们插入了一些示例数据,并展示了如何使用SQL查询来查询特定森林区域的植被调查数据、查询特定树种的采伐数据,以及使用时间函数来进行数据分析,例如查询在特定时间范围内采伐的树木数量。
实际的林业数据库设计会更加复杂,并需要考虑数据的准确性、空间和时间关系的维护、以及性能优化。此外,还需要根据具体的业务需求实现特定的数据处理逻辑,例如,对于林业数据的存储,可能需要遵循森林资源的采集和记录标准。
82. 请解释Oracle数据库中的渔业数据处理方法。
Oracle数据库中的渔业数据处理
在Oracle数据库中处理渔业数据需要考虑存储、管理、分析和可视化与渔业相关的数据。以下是渔业数据处理的一些关键方面以及如何使用Oracle数据库进行示例性的SQL说明:
-
数据库设计:设计Oracle数据库时,需要创建表来存储捕鱼数据、渔船信息、渔业资源评估数据、渔场信息、渔业法规数据和其他与渔业生产和管理相关的数据。每个表都需要根据渔业数据的特性来设计,确保数据的完整性和准确性。
-
数据存储:存储渔业数据时,可能需要考虑数据的一致性和引用完整性,以确保未来进行数据分析和预测时可以得到可靠的结果。
-
数据分析和查询:Oracle SQL是进行渔业数据查询和分析的强大工具。可以编写SQL语句来提取渔业数据,进行渔业资源评估、渔场分析、渔获量预测和其他数据驱动的决策支持。
-
性能优化:针对渔业数据的查询和分析,可能需要对数据库进行性能优化,例如索引、分区和物化视图等技术。
-
空间和时间分析:渔业数据经常需要根据空间和时间进行分析。Oracle数据库支持空间数据类型(如SDO_GEOMETRY)和时间数据类型(如TIMESTAMP),可以有效地进行这类查询。
-
安全性和合规性:数据库安全性对于保护渔业数据的隐私和遵守法律法规至关重要。Oracle提供了高级的安全特性,如数据加密、网络安全和审计功能。
示例SQL代码
以下是一些示例SQL代码,展示了如何在Oracle数据库中管理渔业数据,并不代表实际的渔业数据库设计。
-- 创建示例表-- 渔船信息表
CREATE TABLE fishing_vessels (vessel_id NUMBER PRIMARY KEY,vessel_name VARCHAR2(100),vessel_type VARCHAR2(50),owner_name VARCHAR2(100)
);-- 渔场信息表
CREATE TABLE fishing_grounds (ground_id NUMBER PRIMARY KEY,ground_name VARCHAR2(100),location SDO_GEOMETRY,ground_description VARCHAR2(4000)
);-- 捕鱼数据表
CREATE TABLE fishing_catches (catch_id NUMBER PRIMARY KEY,vessel_id NUMBER REFERENCES fishing_vessels(vessel_id),ground_id NUMBER REFERENCES fishing_grounds(ground_id),catch_date TIMESTAMP,species VARCHAR2(100),weight NUMBER,quantity NUMBER
);-- 渔业资源评估数据表
CREATE TABLE fishery_resource_assessment (assessment_id NUMBER PRIMARY KEY,ground_id NUMBER REFERENCES fishing_grounds(ground_id),assessment_date TIMESTAMP,biomass NUMBER,abundance VARCHAR2(100)
);-- 渔业法规数据表
CREATE TABLE fishery_regulations (regulation_id NUMBER PRIMARY KEY,regulation_type VARCHAR2(100),title VARCHAR2(200),description VARCHAR2(4000)
);-- 示例数据插入-- 插入渔船信息数据
INSERT INTO fishing_vessels (vessel_id, vessel_name, vessel_type, owner_name)
VALUES (1, 'Blue Whale', 'Longliner', 'John Doe');-- 插入渔场信息数据
INSERT INTO fishing_grounds (ground_id, ground_name, location, ground_description)
VALUES (1, 'Great Barrier Reef', SDO_GEOMETRY(2001, NULL, SDO_POINT_TYPE(151.21, -30.04, NULL), NULL, NULL), 'World''s largest coral reef system.');-- 插入捕鱼数据
INSERT INTO fishing_catches (catch_id, vessel_id, ground_id, catch_date, species, weight, quantity)
VALUES (1, 1, 1, TO_TIMESTAMP('2023-04-01 12:00:00', 'YYYY-MM-DD HH24:MI:SS'), 'Red Snapper', 2.5, 10);-- 插入渔业资源评估数据
INSERT INTO fishery_resource_assessment (assessment_id, ground_id, assessment_date, biomass, abundance)
VALUES (1, 1, TO_TIMESTAMP('2023-05-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), 15000, 'High');-- 插入渔业法规数据
INSERT INTO fishery_regulations (regulation_id, regulation_type, title, description)
VALUES (1, 'Quota', 'Fishing Quota for Red Snapper', 'Annual catch limit for Red Snapper in the Great Barrier Reef.');-- 数据查询示例-- 查询特定渔场的捕鱼数据
SELECT * FROM fishing_catches WHERE ground_id = 1;-- 查询特定渔船的捕鱼数据
SELECT * FROM fishing_catches WHERE vessel_id = 1;-- 使用时间函数进行数据分析-- 计算每个渔场的年捕鱼量
SELECT ground_id, SUM(quantity) AS annual_catch_volume
FROM fishing_catches
WHERE catch_date BETWEEN TO_TIMESTAMP('2023-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND TO_TIMESTAMP('2023-12-31 23:59:59', 'YYYY-MM-DD HH24:MI:SS')
GROUP BY ground_id;-- 查询在特定时间范围内捕获的鱼的总重量
SELECT SUM(weight * quantity) AS total_weight_captured
FROM fishing_catches
WHERE catch_date BETWEEN TO_TIMESTAMP('2023-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND TO_TIMESTAMP('2023-12-31 23:59:59', 'YYYY-MM-DD HH24:MI:SS');在上述示例中,我们首先创建了四个表来存储渔船信息、渔场信息、捕鱼数据和渔业资源评估数据。然后,我们插入了一些示例数据,并展示了如何使用SQL查询来查询特定渔场或渔船的捕鱼数据,以及使用时间函数来进行数据分析,例如计算特定时间范围内捕鱼的总重量。
实际的渔业数据库设计会更加复杂,并需要考虑数据的准确性、空间和时间关系的维护、以及性能优化。此外,还需要根据具体的业务需求实现特定的数据处理逻辑,例如,对于捕鱼数据的存储,可能需要遵循特定的渔业数据收集标准。
83. 请解释Oracle数据库中的信息系统集成方法和技术。
Oracle数据库中的信息系统集成方法和技术
在Oracle数据库中集成信息系统,指的是将多个来源的数据和系统统一到一个Oracle数据库中,以便于数据分析、业务流程自动化和决策支持。以下是一些信息系统集成方法和相关的Oracle技术:
-
数据库链接(Database Linking):Oracle数据库允许你创建数据库链接到其他数据库或数据库实例,使得你可以在单个查询中跨数据库访问数据。这种方法对于分布式数据库环境尤其有用。
-
数据库复制(Database Replication):Oracle提供了多种数据库复制技术,如物理复制、逻辑复制和闪回复制,以便在不同数据库间同步数据,实现数据的实时或异步同步。
-
数据集成和数据仓库(Data Integration and Data Warehousing):Oracle提供了Data Integrator(ODI)和GoldenGate等工具,可以帮助你集成来自多个源的数据,并将数据加载到数据仓库中进行分析。
-
数据库触发器(Database Triggers):触发器可以在数据库中定义,以便在特定事件发生时自动执行操作,如插入、删除或更新数据时执行存储过程。
-
存储过程和函数(Stored Procedures and Functions):存储过程和函数可以封装复杂的业务逻辑,并在数据库中执行,提高了数据处理的效率和安全性。
-
Web服务和RESTful接口(Web Services and RESTful APIs):Oracle提供了支持Web服务和RESTful接口的技术,使得数据库可以通过网络服务进行数据交换。
-
中间件(Middleware):使用Oracle中间件,如Oracle WebLogic Server和Oracle SOA Suite,可以集成不同的系统和应用,实现企业服务总线(ESB)和消息队列等功能。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中使用数据库链接、触发器和存储过程来集成信息系统:
-- 创建示例表-- 销售订单表
CREATE TABLE sales_orders (order_id NUMBER PRIMARY KEY,customer_id NUMBER,order_date DATE,total_amount NUMBER(10, 2)
);-- 库存表
CREATE TABLE inventory (product_id NUMBER PRIMARY KEY,product_name VARCHAR2(100),quantity_on_hand NUMBER
);-- 远程库存表(通过数据库链接访问)
CREATE DATABASE LINK remote_db CONNECT TO remote_user IDENTIFIED BY remote_password USING 'remote_db_instance';-- 创建触发器来同步库存信息
CREATE OR REPLACE TRIGGER sync_inventory_after_order
AFTER INSERT ON sales_orders
FOR EACH ROW
DECLAREremote_quantity NUMBER;
BEGIN-- 从远程数据库获取产品数量SELECT quantity_on_hand INTO remote_quantity FROM inventory@remote_dbWHERE product_id = :NEW.product_id;-- 更新本地库存UPDATE inventorySET quantity_on_hand = remote_quantity - :NEW.quantityWHERE product_id = :NEW.product_id;
END;
/-- 存储过程来处理订单
CREATE OR REPLACE PROCEDURE place_order(p_order_id NUMBER,p_customer_id NUMBER,p_product_id NUMBER,p_quantity NUMBER,p_total_amount NUMBER
) AS
BEGIN-- 插入销售订单INSERT INTO sales_orders (order_id, customer_id, order_date, total_amount)VALUES (p_order_id, p_customer_id, SYSDATE, p_total_amount);-- 通过数据库触发器同步库存(假设在插入订单时触发了触发器)
END;
/-- 示例调用存储过程
EXEC place_order(1, 100, 1, 5, 99.95);-- 通过数据库链接查询远程库存信息
SELECT * FROM inventory@remote_db WHERE product_id = 1;
在上述示例中,我们首先创建了两个表:sales_orders和inventory。然后,我们创建了一个数据库链接remote_db到另一个数据库实例,该实例包含远程的inventory表。接着,我们创建了一个触发器sync_inventory_after_order,当插入新的销售订单时,它会更新本地的inventory表,以反映远程数据库中的库存变化。最后,我们创建了一个存储过程place_order来处理订单,并在订单插入后通过触发器同步库存信息。通过使用数据库链接、触发器和存储过程,我们可以集成多个系统,实现信息的同步和一致性。
84. 请解释Oracle数据库中的数据仓库建设方法和技术。
Oracle数据库中的数据仓库建设方法和技术
在Oracle数据库中建设数据仓库涉及到以下几个关键步骤和技术:
-
设计数据仓库架构:这包括确定数据仓库的目的、数据源、数据提取、转换和加载(ETL)策略、数据仓库的模式(如星形模式或雪花模式)等。
-
数据ETL过程:数据必须从操作数据库(OLTP)系统中提取、转换和加载到数据仓库中。Oracle提供了多种工具和技术来支持ETL,如Oracle Data Integrator(ODI)、SQL*Loader和Data Pump。
-
数据建模:将原始数据转换为适合分析的形式需要进行数据建模。这通常涉及到创建数据仓库模式,它是数据仓库的逻辑结构,包括维度表、事实表和视图。
-
性能优化:数据仓库的性能优化包括物理存储层面的优化和查询优化。Oracle提供了多种性能优化技术,如索引、分区、物化视图等。
-
数据挖掘和报告:数据仓库可以使用数据挖掘工具来分析数据,并生成报告,为业务决策提供支持。Oracle提供了多种数据挖掘选项,如Oracle Data Miner和OLAP(在线分析处理)。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中创建数据仓库模式和执行数据挖掘任务:
-- 创建数据仓库模式-- 维度表:产品维度
CREATE TABLE dim_products (product_key NUMBER PRIMARY KEY,product_id NUMBER,product_name VARCHAR2(100),category_name VARCHAR2(50),subcategory_name VARCHAR2(50)
);-- 维度表:时间维度
CREATE TABLE dim_time (time_key NUMBER PRIMARY KEY,year NUMBER,quarter NUMBER,month NUMBER,day NUMBER
);-- 事实表:销售事实
CREATE TABLE fact_sales (product_key NUMBER,time_key NUMBER,sales_amount NUMBER(10, 2),quantity NUMBER,FOREIGN KEY (product_key) REFERENCES dim_products (product_key),FOREIGN KEY (time_key) REFERENCES dim_time (time_key)
);-- 数据挖掘示例:销售趋势分析
-- 假设我们想要分析每年的销售趋势
SELECT d.year, SUM(f.sales_amount) AS total_sales
FROM fact_sales f
INNER JOIN dim_time d ON f.time_key = d.time_key
GROUP BY d.year
ORDER BY d.year;-- 数据挖掘示例:产品销售排行
-- 假设我们想要知道最畅销的产品
SELECT p.product_name, SUM(f.quantity) AS total_quantity_sold
FROM fact_sales f
INNER JOIN dim_products p ON f.product_key = p.product_key
GROUP BY p.product_name
ORDER BY total_quantity_sold DESC;-- 性能优化示例:创建索引以提高查询性能
CREATE INDEX idx_fact_sales_product ON fact_sales (product_key);
CREATE INDEX idx_fact_sales_time ON fact_sales (time_key);
在上述示例中,我们首先创建了两个维度表(dim_products和dim_time)和一个事实表(fact_sales)。维度表提供了产品和时间的详细信息,而事实表包含了销售数据的度量单位。我们创建了一些示例查询来分析销售趋势和产品销售排行,并为这些查询创建了索引以提高性能。
创建数据仓库是一个涉及多个步骤和技术的复杂过程,但Oracle提供了必要的工具和平台来支持数据仓库的建设和管理。通过合理的设计、ETL过程、数据建模和性能优化,可以确保数据仓库能够有效地支持企业的决策支持系统。
85. 请解释Oracle数据库中的数据挖掘和分析方法和技术。
在Oracle数据库中,数据挖掘和分析是指使用统计分析、机器学习和数据挖掘技术来从数据仓库中提取有价值的信息和知识的过程。Oracle数据库提供了多种数据挖掘和分析的功能和技术,包括:
-
数据挖掘组件:Oracle自带一些数据挖掘组件,如Oracle Data Miner,它提供了多种算法和工具,用于数据挖掘任务,如分类、聚类、关联规则学习等。
-
统计分析函数:Oracle SQL提供了丰富的统计分析函数,如聚合函数(如SUM、AVG、MAX、MIN)、排名函数(如RANK、DENSE_RANK)、百分位函数等,这些函数可以用于基本的数据分析。
-
机器学习函数:Oracle SQL也支持机器学习函数,允许开发者直接在数据库中执行预测分析、聚类分析等任务,而不需要外部数据挖掘软件。
-
高级分析技术:Oracle数据库还支持复杂的分析技术,如时间序列分析、空间分析、文本分析等,这些技术可以从非结构化数据中提取有价值的信息。
-
集成和API:Oracle数据库可以与其他数据科学和分析工具集成,例如可以通过Oracle Machine Learning notebooks进行交互式分析。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中使用数据挖掘和分析技术:
-- 使用数据挖掘组件进行聚类分析
-- 假设我们想要对客户进行聚类以发现相似性
BEGINDBMS_DATA_MINING.CREATE_MODEL(model_name => 'customer_clustering',mining_function => dbms_data_mining.DBMS_DATA_MINING.CLUSTER,data_table_name => 'customers',case_id_column_name => 'customer_id',settings_table_name => 'cluster_settings');
END;
/-- 使用机器学习函数进行预测分析
-- 假设我们想要预测未来的销售额
SELECT time_id, sales_amount,ML_PREDICT(sales_amount USING MODEL ml_model_name) AS predicted_sales
FROM sales_history
ORDER BY time_id;-- 使用统计分析函数进行基本分析
-- 假设我们想要了解销售额的总体趋势
SELECT EXTRACT(YEAR FROM sale_date) AS year, SUM(sales_amount) AS total_sales
FROM sales
GROUP BY EXTRACT(YEAR FROM sale_date)
ORDER BY year;-- 文本分析示例:查找关于特定产品的评论
-- 假设我们想要找到关于某个产品的所有正面评论
SELECT review_text
FROM product_reviews
WHERE product_id = 123 AND sentiment = 'positive';
在上述示例中:
- 使用
DBMS_DATA_MINING包创建了一个聚类模型customer_clustering,用于识别数据集中相似的客户。 - 使用
ML_PREDICT函数基于机器学习模型对未来的销售额进行了预测。 - 使用
SUM和EXTRACT函数对销售额进行了基本的时间序列分析,以了解销售额的总体趋势。 - 文本分析示例展示了如何查询特定产品相关的正面评论。
这些示例说明了Oracle数据库如何结合其内置的数据挖掘和分析功能来帮助用户从数据中提取有价值的信息。然而,要成功执行这些分析,通常需要对数据进行适当的准备和清洗,以及选择合适的数据挖掘方法和模型。
86. 请解释Oracle数据库中的数据质量管理方法和技术。
在Oracle数据库中,数据质量管理是一个重要的过程,它涉及到确保数据的准确性、一致性、完整性和可靠性。Oracle提供了多种数据质量管理的功能和技术,包括:
-
数据完整性约束:Oracle数据库允许定义数据完整性约束,如主键、外键、非空、唯一性等,这些约束可以确保数据的完整性。
-
触发器:触发器是数据库中的一种程序,它在特定事件发生时自动执行,例如插入、更新或删除数据时,可以用来强制实施业务规则和数据完整性。
-
检查约束:检查约束是一种特殊的约束,它允许你指定一个条件,该条件必须对于表中的每一行数据都成立。这对于确保数据符合特定的业务规则非常有用。
-
视图:视图是一种虚拟表,它基于一个或多个表(或其他视图),可以隐藏复杂的数据结构,并且可以定义为只读或只插入,这有助于保护基础数据不被未经授权的访问和修改。
-
序列:序列是一种生成唯一数字序列的数据库对象,常用于主键值的生成,这有助于保证数据的唯一性。
-
索引:索引可以提高查询性能,但它们也可以用于保证数据的唯一性或快速访问。唯一索引强制列的值唯一,而非唯一索引则提高了查询效率。
-
数据审计和监控:Oracle提供了数据库审计功能,可以监控数据库活动,记录用户对数据的所有操作,这有助于事后分析数据变更的原因和追踪数据问题。
-
数据清洗服务:Oracle提供的数据清洗服务可以帮助用户识别和纠正数据中的不一致性和错误,从而提高数据质量。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中实施数据质量管理:
-- 创建一个带有主键约束的表
CREATE TABLE products (product_id NUMBER PRIMARY KEY,product_name VARCHAR2(100) NOT NULL,product_price NUMBER(10, 2) CHECK (product_price > 0)
);-- 使用触发器确保数据一致性
-- 例如,在插入新产品时,自动生成产品ID
CREATE OR REPLACE TRIGGER product_id_trigger
BEFORE INSERT ON products
FOR EACH ROW
BEGINSELECT product_seq.NEXTVAL INTO :new.product_id FROM DUAL;
END;
/-- 创建一个视图,保护基础数据不被直接访问和修改
CREATE VIEW v_products AS
SELECT product_id, product_name, product_price
FROM products
WITH READ ONLY;-- 在插入或更新数据时,使用触发器和检查约束来保证数据质量
INSERT INTO products (product_name, product_price) VALUES ('Widget', 9.99);UPDATE products SET product_price = 11.99 WHERE product_id = 1;-- 使用索引来提高查询性能
CREATE INDEX idx_product_name ON products (product_name);-- 监控数据库活动
-- 开启数据库审计
AUDIT SELECT, INSERT, UPDATE, DELETE ON products;-- 使用数据清洗服务来修复数据中的错误
BEGINDBMS_DATAPUMP.START_JOB(job_name => 'DATA_CLEANUP_JOB',operation => 'FULL',job_mode => 'SCHEMA',tables => 'HR.EMPLOYEES');
END;
/
在上述示例中:
- 创建了一个
products表,其中product_id是一个带有主键约束的列,确保每个产品都有一个唯一的标识。 - 创建了一个触发器
product_id_trigger,用于在插入新产品时自动为product_id列生成一个唯一的值。 - 创建了一个只读视图
v_products,保护了产品的基本信息不被直接修改。 - 在
product_price列上使用了一个检查约束,确保产品价格始终大于0。 - 创建了一个索引
idx_product_name,以提高基于产品名称的查询性能。 - 通过
AUDIT语句开启了对products表的审计,以跟踪所有对该表的数据操作。 - 使用
DBMS_DATAPUMP启动了一个数据清洗作业,用于修复HR.EMPLOYEES表中的错误或不一致性。
数据质量管理是一个持续的过程,需要结合多种技术和策略来确保数据的准确性、一致性、完整性和可靠性。在实际应用中,可能还需要结合业务需求、数据类型和业务规则来定制数据质量管理策略。
87. 请解释Oracle数据库中的数据治理方法和技术。
在Oracle数据库中,数据治理是一个全面的流程,它涉及到管理、控制和保障数据的质量、使用和安全性。数据治理的目的是确保数据能够支持组织的业务目标,同时遵守相关的法规和标准。Oracle提供了多种数据治理的功能和技术,包括:
-
数据目录:数据目录是一个中央存储库,用于存储关于数据资产的元数据,如表定义、列信息、数据类型、数据分布等。这有助于用户了解数据资产的全貌。
-
数据字典:数据字典是数据库中的一个系统表,存储了数据库中的所有对象定义,如表、视图、索引等。它对于跟踪数据库中的对象变化和维护数据库文档非常重要。
-
数据分类和标签:数据分类和标签是将数据资产分配到不同的类别和级别的过程,这有助于理解数据的敏感性、业务重要性和管理责任。
-
数据安全:数据安全包括数据加密、网络安全、访问控制和合规性管理等。Oracle提供了透明数据加密、行级安全和列级安全等特性来保护数据。
-
数据审计和合规性:数据审计功能可以监控数据库活动,并记录合规性事件,如对敏感数据的访问或修改。Oracle Advanced Security提供了额外的审计和合规性功能。
-
数据主权:数据主权是指确定数据在何处存储和处理的权利。Oracle提供了数据库链接和数据泵等技术,以便在不同数据库之间移动和共享数据。
-
数据质量管理:如前所述,数据质量管理是确保数据准确性、一致性、完整性和可靠性的过程。Oracle提供了多种数据质量管理的技术,如约束、触发器、检查约束等。
-
主数据管理:主数据管理(MDM)是维护和管理企业核心数据(如客户、供应商、产品等)的过程,它有助于消除数据重复,确保数据的一致性。
-
数据生命周期管理:数据生命周期管理是规划、控制和监控数据从创建到销毁的整个过程,包括数据收集、数据处理、数据存储、数据分析、数据共享和数据归档。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中实施数据治理:
-- 使用数据目录视图查询数据库中的所有表
SELECT * FROM all_tables WHERE owner = 'HR';-- 查询数据字典中关于EMPLOYEES表的信息
SELECT * FROM user_tab_columns WHERE table_name = 'EMPLOYEES';-- 为数据资产分配分类和标签
COMMENT ON TABLE HR.EMPLOYEES IS 'Classification: Confidential | Business Impact: High | Data Owner: HR';-- 启用数据库的透明数据加密
ADMINISTER KEY MANAGEMENT SET KEYSTORE CLOSE;
ADMINISTER KEY MANAGEMENT SET KEYSTORE OPEN IDENTIFIED BY keystore_password;
ADMINISTER KEY MANAGEMENT SET ENCRYPTION KEY IDENTIFIED BY encryption_key_password WITH BACKUP;-- 创建一个用于审计敏感操作的审计策略
BEGINDBMS_FGA.ADD_POLICY (object_schema => 'HR',object_name => 'EMPLOYEES',policy_name => 'SENSITIVE_DATA_AUDIT',audit_condition => 'EMPLOYEE_SALARY > 100000',audit_column => 'SALARY',handler_schema => NULL,handler_module => NULL);
END;
/-- 使用数据泵将数据从一个数据库移动到另一个数据库
DECLAREhandle NUMBER;
BEGINhandle := DBMS_DATAPUMP.OPEN(operation => 'EXPORT', job_mode => 'SCHEMA', remote_link => NULL);DBMS_DATAPUMP.ADD_FILE(handle => handle, filename => 'employees.dmp', directory => 'DATA_PUMP_DIR');DBMS_DATAPUMP.METADATA_FILTER(handle => handle, name => 'SCHEMA_EXPR', value => 'IN (''HR'')');DBMS_DATAPUMP.START_JOB(handle => handle);DBMS_DATAPUMP.WAIT_FOR_JOB(handle => handle);DBMS_DATAPUMP.CLOSE(handle => handle);
END;
/
在上述示例中:
- 使用
all_tables视图查询了HR用户下的所有表。 - 查询了
user_tab_columns视图,以获取EMPLOYEES表的列信息。 - 使用注释为
EMPLOYEES表添加了分类和标签信息。 - 通过一系列
ADMINISTER KEY MANAGEMENT命令配置了数据库的透明数据加密。 - 使用
DBMS_FGA包创建了一个审计策略,用于审计工资超过一定数量的员工操作。 - 使用
DBMS_DATAPUMP包启动了一个数据泵作业,将HR模式下的数据导出到另一个数据库。
数据治理是一个复杂的过程,需要结合多种技术和策略来确保数据的安全、质量、使用和合规性。在实际应用中,数据治理通常需要一个跨职能团队的协作和持续的维护,包括数据库管理员、业务分析师、数据科学家和安全专业人员等。
88. 请解释Oracle数据库中的数据集成方法和技术。
在Oracle数据库中,数据集成是将数据从不同的源收集到数据库中,并使其在数据库内部保持一致性和可访问性的过程。这通常涉及到将来自多个系统或数据库的数据合并到一个中央数据库中,这个过程可能包括数据迁移、数据转换、数据清洗和数据同步等步骤。Oracle提供了多种数据集成的技术和方法:
-
数据迁移:将数据从一个数据库移动到另一个数据库,可能需要使用数据泵(Data Pump)工具或其他Oracle提供的工具。
-
数据转换:在数据迁移过程中,可能需要将数据从一种格式转换为另一种格式,这可以通过Oracle的Data Integrator(ODI)工具来完成。
-
数据同步:数据同步是保持两个或多个数据库之间数据一致性的过程。Oracle GoldenGate和Streams等技术可以用于实现实时数据同步。
-
数据清洗:数据清洗是识别和纠正数据中的错误和不一致性的过程,这可能包括删除重复记录、修复缺失值、纠正数据类型不匹配等。
-
数据集成平台:Oracle提供了Oracle Data Integrator(ODI)和Oracle WebLogic Integration(WLI)等数据集成平台,用于构建复杂的数据集成解决方案。
-
第三方集成工具:除了Oracle自带的集成工具外,市场上还有许多第三方工具可供选择,如Talend, Informatica, Apache NiFi等。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中实施数据集成:
-- 使用数据泵导出数据
DECLAREhandle NUMBER;
BEGINhandle := DBMS_DATAPUMP.OPEN(operation => 'EXPORT', job_mode => 'SCHEMA', remote_link => NULL);DBMS_DATAPUMP.ADD_FILE(handle => handle, filename => 'employees.dmp', directory => 'DATA_PUMP_DIR');DBMS_DATAPUMP.METADATA_FILTER(handle => handle, name => 'SCHEMA_EXPR', value => 'IN (''HR'')');DBMS_DATAPUMP.START_JOB(handle => handle);DBMS_DATAPUMP.WAIT_FOR_JOB(handle => handle);DBMS_DATAPUMP.CLOSE(handle => handle);
END;
/-- 使用数据泵导入数据
DECLAREhandle NUMBER;
BEGINhandle := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => NULL);DBMS_DATAPUMP.ADD_FILE(handle => handle, filename => 'employees.dmp', directory => 'DATA_PUMP_DIR');DBMS_DATAPUMP.METADATA_FILTER(handle => handle, name => 'SCHEMA_EXPR', value => 'IN (''HR'')');DBMS_DATAPUMP.SET_PARAMETER(handle => handle, name => 'TABLE_EXISTS_ACTION', value => 'TRUNCATE');DBMS_DATAPUMP.START_JOB(handle => handle);DBMS_DATAPUMP.WAIT_FOR_JOB(handle => handle);DBMS_DATAPUMP.CLOSE(handle => handle);
END;
/-- 使用ODI进行数据集成
-- 在ODI中创建一个项目,并配置数据源、数据目标和数据集成任务-- 使用WLI进行数据集成
-- 在WLI中创建一个集成服务,并配置数据源、数据目标和数据集成流程-- 使用第三方集成工具(例如Talend)进行数据集成
-- 在Talend中创建一个作业,并配置数据源、数据目标和数据集成任务
在上述示例中:
- 使用
DBMS_DATAPUMP包导出了HR模式下的数据。 - 使用同样的
DBMS_DATAPUMP包导入了之前导出的数据。 - 使用ODI和WLI工具的示例代码片段被注释掉了,因为它们需要专门的配置和设置,这里只是提供了一个框架。
- 第三方集成工具的示例(如Talend)同样需要根据具体的工具和需求进行配置。
数据集成是一个关键的过程,因为它为组织提供了统一的视图,帮助做出更好的业务决策。然而,实施有效的数据集成解决方案通常需要详细的规划、专业的技能和与各种数据源的集成经验。
89. 请解释Oracle数据库中的数据标准化方法和技术。
在Oracle数据库中,数据标准化是将数据组织成一种格式,以减少冗余和依赖,从而提高数据库的效率和可维护性的过程。数据标准化通常涉及到创建数据模型,包括表、关系和约束,以确保数据的一致性和准确性。以下是一些常用的数据标准化方法和技术:
-
第一范式(1NF):数据表中的每一列都是不可分割的基本数据项,也就是说,每一列的值都是原子性的。表中的所有条目都是唯一的,避免出现重复的记录。
-
第二范式(2NF):在1NF的基础上,确保表中的所有非主键字段完全依赖于主键。这意味着,表中的每个记录都必须唯一地通过主键与其他记录区分开来。
-
第三范式(3NF):在2NF的基础上,确保所有非主键字段不仅完全依赖于主键,而且非主键字段之间不存在传递依赖。这意味着,表中的字段应该直接依赖于主键,而不是通过另一个非主键字段依赖。
-
第四范式(4NF):在3NF的基础上,确保记录中不存在多值依赖。这意味着,一个表中不应该存在两个或多个独立的多值信息。
-
第五范式(5NF):在4NF的基础上,确保所有的表都是无关的,也就是说,每个表中的信息都是独立的,不依赖于其他表的信息。
-
数据字典:Oracle提供了数据字典视图,如
USER_TAB_COLUMNS,USER_CONSTRAINTS等,用于查看数据库模式的详细信息。 -
规范化工具:Oracle提供了一些工具,如Oracle Data Modeler,可以帮助用户设计和实施数据标准化模型。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中实施数据标准化:
-- 创建一个符合1NF的表
CREATE TABLE employees (employee_id NUMBER PRIMARY KEY,name VARCHAR2(100) NOT NULL,title VARCHAR2(100) NOT NULL,department VARCHAR2(100) NOT NULL
);-- 创建一个符合2NF的表
CREATE TABLE orders (order_id NUMBER PRIMARY KEY,employee_id NUMBER,product_id NUMBER,quantity NUMBER,order_date DATE,FOREIGN KEY (employee_id) REFERENCES employees(employee_id)
);-- 创建一个符合3NF的表
CREATE TABLE product_details (product_id NUMBER PRIMARY KEY,product_name VARCHAR2(100) NOT NULL,supplier_id NUMBER,category_id NUMBER,FOREIGN KEY (supplier_id) REFERENCES suppliers(supplier_id),FOREIGN KEY (category_id) REFERENCES categories(category_id)
);-- 创建一个符合4NF的表(考虑到可能存在多值依赖的情况)
CREATE TABLE order_details (order_id NUMBER,product_id NUMBER,quantity NUMBER,price NUMBER,PRIMARY KEY (order_id, product_id),FOREIGN KEY (order_id) REFERENCES orders(order_id),FOREIGN KEY (product_id) REFERENCES product_details(product_id)
);-- 创建一个符合5NF的表(考虑到去规范化以提高性能)
CREATE TABLE inventory (product_id NUMBER,warehouse_id NUMBER,quantity NUMBER,PRIMARY KEY (product_id, warehouse_id),FOREIGN KEY (product_id) REFERENCES product_details(product_id)
);
在上述示例中:
employees表是1NF的,因为每个字段都是原子性的,并且每个记录都是通过唯一的employee_id主键区分的。orders表是2NF的,因为它有一个外键employee_id依赖于employees表的主键。product_details表是3NF的,因为它有两个外键supplier_id和category_id,它们都直接依赖于主键,而不是通过其他非主键字段依赖。order_details表是4NF的,因为它有一个复合主键(order_id,product_id),避免了多值依赖。inventory表可能不是5NF,因为它似乎包含了一些可以去规范化的信息,比如quantity和warehouse_id。在某些情况下,为了性能优化,可能需要适当地去规范化。
数据标准化是一个持续的过程,通常随着业务需求的变化而演变。良好的数据标准化设计可以显著提高数据库的性能、可维护性和安全性。
90. 请解释Oracle数据库中的数据可视化方法和技术。
在Oracle数据库中,数据可视化是指使用图表、图形和图形界面来展示数据库中的数据,以便用户能够直观地理解和分析数据。Oracle提供了多种工具和技术来实现数据可视化,包括:
-
Oracle SQL Developer Data Modeler:这是一个可视化工具,它允许开发者创建和编辑数据模型,并生成与数据库结构相对应的图形表示。
-
Oracle APEX:这是一个全面的应用开发平台,它允许开发者构建交互式报告和应用程序,而无需编写任何代码。
-
Oracle Analytics:这是一个商业智能和数据可视化产品,它允许用户通过简单的拖放界面来创建和共享交互式报告和仪表板。
-
SQL*Plus:这是Oracle数据库的命令行工具,包含了一个简单的图形界面,可以用来执行SQL查询并查看结果。
-
PL/SQL Developer:这是一个集成的开发环境,专门用于PL/SQL开发,但它也包含了一个基本的图形SQL查询工具。
-
Oracle Exadata Studio:这是一个用于Exadata系统的数据可视化工具,它提供了丰富的图表和报告功能。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中使用数据可视化技术:
-- 使用SQL*Plus图形界面
-- 首先,启动SQL*Plus并连接到数据库
SQL> CONNECT username/password@database-- 然后,执行以下命令以启动图形界面
SQL> SET ECHO OFF
SQL> SET FEEDBACK OFF
SQL> SET VERIFY OFF
SQL> SELECT * FROM departments;-- 使用PL/SQL Developer中的图形SQL查询工具
-- 打开PL/SQL Developer,连接到数据库,然后选择“View” -> “SQL Worksheet”
-- 在SQL Worksheet中,你可以执行SQL查询并查看结果,同时有一个图表按钮可以用来可视化查询结果-- 使用Oracle APEX创建交互式报告
-- 首先,登录到Oracle APEX工作空间,然后创建一个新的应用程序
-- 在应用程序中,你可以通过“Create” -> “Report”来创建一个交互式报告
-- 选择数据源,设计报表的布局和交互元素,并预览报表-- 使用Oracle Analytics创建仪表板
-- 登录到Oracle Analytics,创建一个新的项目
-- 选择数据源,拖放字段到画布上来创建视觉化,然后配置交互和筛选选项
在上述示例中,我们演示了如何使用SQL*Plus和PL/SQL Developer的图形界面来执行和查看SQL查询结果。对于创建交互式报告和仪表板,我们通常会使用专门的工具如Oracle APEX或Oracle Analytics,因为它们提供了更高级和用户友好的界面来设计和共享数据可视化内容。
请注意,为了能够执行这些示例代码,你需要安装并配置适当的Oracle开发工具,如SQL*Plus, PL/SQL Developer, 或者Oracle APEX。如果你需要关于如何安装和配置这些工具的帮助,请告诉我,我可以提供进一步的指导。
91. 请解释Oracle数据库中的数据报告和报表生成方法和技术。
在Oracle数据库中,数据报告和报表生成是指生成结构化和格式化的文档,用于展示数据库中的数据。Oracle提供了多种方法和技术来创建数据报告和报表:
-
Oracle Reports:这是Oracle Forms技术的一部分,它允许开发者创建交互式报告,用户可以通过表单向导航和查询数据库。
-
Oracle APEX:这是一个全面的应用开发平台,它提供了强大的报表工具,允许开发者快速创建和部署交互式报表和复杂的数据分析应用程序。
-
Oracle SQL Developer Reports:这是SQL Developer工具套件的一部分,它提供了一个图形界面来设计和生成报表。
-
Oracle Exadata Studio:这是一个用于Exadata系统的数据可视化工具,它允许用户生成报表和分析数据。
-
PL/SQL Developer:虽然PL/SQL Developer主要是一个PL/SQL开发环境,但它也包含了一个简单的报表生成器,可以用来创建基本的文本报告。
-
SQL*Plus:虽然SQL*Plus主要是一个命令行工具,但它也支持报表格式化输出,可以生成美观的文本报告。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中生成数据报告和报表:
-- 使用SQL*Plus生成文本报告
-- 首先,启动SQL*Plus并连接到数据库
SQL> CONNECT username/password@database-- 使用SET命令设置报表格式
SQL> SET PAGESIZE 50
SQL> SET LINESIZE 100
SQL> SET COLSEP ' | '-- 执行查询并生成报表
SQL> SELECT employee_id, last_name, salary FROM employees ORDER BY salary DESC;-- 使用PL/SQL Developer的报表生成器
-- 打开PL/SQL Developer,连接到数据库
-- 创建一个新的PL/SQL块,编写逻辑来查询数据并格式化输出
DECLARECURSOR emp_cursor ISSELECT employee_id, last_name, salary FROM employees ORDER BY salary DESC;emp_rec emp_cursor%ROWTYPE;
BEGINDBMS_OUTPUT.PUT_LINE('EMPLOYEE ID | LAST NAME | SALARY');DBMS_OUTPUT.PUT_LINE('-------------------------------------');FOR emp_rec IN emp_cursor LOOPDBMS_OUTPUT.PUT_LINE(emp_rec.employee_id || ' | ' || emp_rec.last_name || ' | ' || emp_rec.salary);END LOOP;
END;
/-- 在SQL Developer中生成报表
-- 打开SQL Developer,连接到数据库
-- 执行查询,右键点击结果网格 -> 选择“Create Report”来创建一个报表-- 使用Oracle APEX创建交互式报表
-- 登录到Oracle APEX工作空间,创建一个新的应用程序
-- 在应用程序中,通过“Create” -> “Report”来设计报表,选择数据源和布局-- 使用Oracle Exadata Studio生成报表
-- 登录到Oracle Exadata Studio,选择数据源和数据集
-- 使用向导来设计报表布局和格式,然后预览和导出报表
在上述示例中,我们演示了如何使用SQL*Plus和PL/SQL Developer的报表功能来生成简单的文本报告。对于创建交互式报表和更复杂的报表,通常会使用专门的工具如Oracle APEX或Oracle SQL Developer Reports。
请注意,为了能够执行这些示例代码,你需要安装并配置适当的Oracle开发工具,如SQL*Plus, PL/SQL Developer, 或者Oracle APEX。如果你需要关于如何安装和配置这些工具的帮助,请告诉我,我可以提供进一步的指导。
92. 请解释Oracle数据库中的数据预测和建模方法和技术。
在Oracle数据库中,数据预测和建模是使用统计分析和机器学习技术来预测未来的趋势、行为或结果。Oracle提供了多种方法来实现数据预测和建模:
-
Oracle Data Miner:这是一个强大的数据挖掘和预测分析工具,它允许数据库管理员和数据科学家在不离开数据库环境的情况下,创建预测模型。
-
Oracle Advanced Analytics:这是一套高级分析和机器学习功能,提供了一系列算法和工具,用于数据探索、特征工程、模型构建和预测。
-
Oracle Autonomous Data Warehouse (ADW):ADW提供了一系列内置的机器学习功能,如数据挖掘、预测分析和数据可视化,使其成为进行数据预测和建模的理想选择。
-
Oracle SQL Developer Data Modeler:SQL Developer Data Modeler是一个图形工具,它允许开发者创建和管理数据模型,包括预测模型。
-
PL/SQL Packages and Functions:通过编写PL/SQL代码,可以实现自定义的预测逻辑和算法。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中使用数据预测和建模技术:
-- 使用Oracle Data Miner创建预测模型
-- 首先,你需要在SQL Developer Data Miner中创建一个数据挖掘模型,选择适当的算法,如时间序列预测等。-- 使用Oracle Advanced Analytics的Time Series模型
-- 在Oracle ADW中,可以使用高级分析功能来创建时间序列预测模型。
-- 以下是一个简化的示例,展示如何创建一个时间序列模型并进行预测。-- 首先,创建一个时间序列模型的表
CREATE TABLE sales_history (sale_date DATE,sales_amount NUMBER
);-- 插入一些示例数据
INSERT INTO sales_history VALUES (TO_DATE('01-JAN-2021', 'DD-MON-YYYY'), 1000);
INSERT INTO sales_history VALUES (TO_DATE('02-JAN-2021', 'DD-MON-YYYY'), 1100);
-- ... 更多数据 ...-- 使用Oracle ADW的TIME_SERIES_FORECAST函数进行预测
SELECT * FROM TABLE(TIME_SERIES_FORECAST(ON sales_history (sale_date, sales_amount),EXTRAPOLATE_USING 'LINEAR',FORECAST_PERIODS => 10)
);-- 使用PL/SQL进行简单线性回归预测
-- 假设我们有一个销售数据表,我们想要预测下个月的销售额
CREATE OR REPLACE PROCEDURE simple_linear_regression ISl_slope NUMBER;l_intercept NUMBER;
BEGIN-- 计算斜率和截距SELECT REGR_SLOPE(sales_amount, TO_CHAR(sale_date, 'YYYYMMDD')) INTO l_slopeFROM sales_history;SELECT REGR_INTERCEPT(sales_amount, TO_CHAR(sale_date, 'YYYYMMDD')) INTO l_interceptFROM sales_history;-- 输出预测结果DBMS_OUTPUT.PUT_LINE('Next month sales prediction: ' || (l_slope * TO_CHAR(ADD_MONTHS(SYSDATE, 1), 'YYYYMMDD') + l_intercept));
END;
/-- 执行存储过程来获取预测值
EXEC simple_linear_regression;
在上述示例中,我们演示了如何使用Oracle Data Miner和Oracle Advanced Analytics来创建预测模型。对于更复杂的预测需求,可能需要编写自定义的PL/SQL代码或使用特定的机器学习库和算法。
请注意,为了能够执行这些示例代码,你需要安装并配置适当的Oracle开发工具,如SQL Developer Data Miner或Oracle ADW。如果你需要关于如何安装和配置这些工具的帮助,请告诉我,我可以提供进一步的指导。
93. 请解释Oracle数据库中的数据归档和清理方法和技术。
在Oracle数据库中,数据归档和清理是数据库管理的重要组成部分,它涉及到将旧数据从在线数据库中移出,以便于存储和管理。Oracle提供了多种方法来实现数据归档和清理:
-
归档表空间:这是Oracle数据库中一种特殊类型的表空间,用于存储历史数据。它允许快速地备份和恢复数据,并且可以配置为自动归档到磁盘或其他位置。
-
闪回查询:Oracle闪回技术允许用户查询在特定时间点上的数据状态。这对于数据归档和恢复非常有用。
-
数据泵:数据泵是一个强大的工具,可以用来将数据从一个数据库转移到另一个数据库,它支持在线和脱机归档。
-
Expdp和Impdp:Oracle的导出和导入工具可以用来创建物理或逻辑的备份和恢复。
-
删除和截断:可以使用
DELETE语句来删除特定条件下的数据行,或者使用TRUNCATE TABLE语句来快速移除整个表中的数据。 -
分区:通过分区表,可以根据时间或其他条件将数据分散存储在不同的表空间或文件组中,这有助于更容易地管理和归档旧数据。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中使用数据归档和清理技术:
-- 创建一个归档表空间
CREATE TABLESPACE archive_dataDATAFILE 'archive_data.dbf'SIZE 10M AUTOEXTEND ON;-- 将现有表移动到归档表空间
ALTER TABLE sales MOVE TABLESPACE archive_data;-- 使用闪回查询来查询历史数据
SELECT * FROM sales AS OF TIMESTAMP TO_TIMESTAMP('2021-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS');-- 使用数据泵进行归档操作
-- 首先,需要创建一个数据泵作业
CREATE OR REPLACE DIRECTORY exp_dump_dir AS '/path/to/export/directory';DECLAREhandle NUMBER;
BEGINhandle := DBMS_DATAPUMP.OPEN(operation => 'EXPORT', job_mode => 'FULL', job_name => 'archive_job');DBMS_DATAPUMP.ADD_FILE(handle => handle, filename => 'archive.dmp', directory => 'EXP_DUMP_DIR', filetype => DBMS_DATAPUMP.KU$_FILE_TYPE_DUMP_FILE);DBMS_DATAPUMP.METADATA_FILTER(handle => handle, name => 'SCHEMA_EXPR', value => 'IN (''SALES'')');DBMS_DATAPUMP.START_JOB(handle => handle);
END;
/-- 使用Expdp进行物理备份
EXPDP userid=system/password@database DIRECTORY=exp_dump_dir DUMPFILE=expdp_sales.dmp LOGFILE=expdp_sales.log SCHEMAS=sales-- 使用Impdp进行恢复
IMPDP userid=system/password@database DIRECTORY=exp_dump_dir DUMPFILE=expdp_sales.dmp LOGFILE=impdp_sales.log-- 删除特定条件的数据
DELETE FROM sales WHERE sale_date < TO_DATE('2021-01-01', 'YYYY-MM-DD');-- 截断表以移除所有数据
TRUNCATE TABLE sales;-- 使用分区来归档数据
-- 首先,创建一个按时间分区的表
CREATE TABLE sales_partitioned (sale_id NUMBER,sale_date DATE,sales_amount NUMBER
)
PARTITION BY RANGE (sale_date) (PARTITION sales_p2021 VALUES LESS THAN (TO_DATE('2022-01-01', 'YYYY-MM-DD')),PARTITION sales_p2022 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD'))
);-- 将旧数据移动到相应的分区
INSERT INTO sales_partitioned SELECT * FROM sales WHERE sale_date < TO_DATE('2022-01-01', 'YYYY-MM-DD');
DELETE FROM sales WHERE sale_date < TO_DATE('2022-01-01', 'YYYY-MM-DD');
在上述示例中,我们演示了如何使用Oracle的归档和清理功能。对于大规模的数据归档,通常建议使用数据泵或Expdp/Impdp工具,因为它们提供了更多的灵活性和控制。对于简单的数据删除和截断操作,标准的SQL语句就足够用了。
请注意,在执行数据归档和清理操作之前,应该仔细考虑数据保留策略,确保不会丢失关键数据,并且满足法规要求。如果你需要更详细的指导或有特定的需求,请告诉我,我可以提供进一步的帮助。
94. 请解释Oracle数据库中的数据保护和加密方法和技术。
在Oracle数据库中,数据保护和加密是确保数据安全的重要措施。以下是一些常见的数据保护和加密方法和技术:
-
用户权限管理:通过Oracle的角色和权限系统,可以控制用户对数据库的访问。只有授权的用户才能访问和修改数据。
-
数据库审计:Oracle提供审计功能,可以记录所有对数据库的访问和操作,这有助于检测和追踪潜在的安全威胁。
-
透明数据加密(TDE):TDE允许对数据库的敏感数据在保存到磁盘之前进行自动加密和解密,提供了数据静态保护。
-
网络加密:使用SSL/TLS等协议,可以对数据库网络通信进行加密,保护数据在传输中的安全。
-
加密函数和算法:Oracle提供了多种加密函数和算法,如
DBMS_CRYPTO包,允许开发者在应用程序中实现自定义加密逻辑。 -
列级加密:在Oracle12c及以上版本中,可以对特定的表列进行加密,保证了列数据的安全。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中使用数据保护和加密技术:
-- 创建一个用户并授予权限
CREATE USER data_guard IDENTIFIED BY password;
GRANT CONNECT, RESOURCE TO data_guard;-- 启用审计
AUDIT SELECT, INSERT, UPDATE, DELETE ON sales;-- 使用TDE来加密一个表
CREATE TABLESPACE encrypted_dataDATAFILE 'encrypted_data.dbf'SIZE 10M AUTOEXTEND ONENCRYPTION USING 'AES256'SEGMENT SPACE MANAGEMENT AUTO;CREATE TABLE encrypted_sales (sale_id NUMBER,sale_data VARCHAR2(100)
) TABLESPACE encrypted_data;-- 插入加密数据
INSERT INTO encrypted_sales VALUES (1, 'Confidential Sale Data');-- 使用网络加密配置数据库
ALTER SYSTEM SET SSL_CIPHER_SUITES='AES256_GCM_SHA384';
ALTER SYSTEM SET SSL_SERVER_DN='"CN=My Server, OU=My Department, O=My Company, L=My City, ST=My State, C=US"';-- 在应用程序中使用加密函数
DECLAREencrypted_text RAW(2000);decrypted_text VARCHAR2(200);encryption_key VARCHAR2(200) := 'MySecretKey';
BEGINencrypted_text := DBMS_CRYPTO.ENCRYPT(src => UTL_I18N.STRING_TO_RAW('Hello, World!', 'AL32UTF8'),typ => DBMS_CRYPTO.DES_CBC_PKCS5,key => UTL_I18N.STRING_TO_RAW(encryption_key, 'AL32UTF8'));decrypted_text := UTL_I18N.RAW_TO_STRING(DBMS_CRYPTO.DECRYPT(src => encrypted_text,typ => DBMS_CRYPTO.DES_CBC_PKCS5,key => UTL_I18N.STRING_TO_RAW(encryption_key, 'AL32UTF8')),'AL32UTF8');DBMS_OUTPUT.PUT_LINE('Encrypted Text: ' || encrypted_text);DBMS_OUTPUT.PUT_LINE('Decrypted Text: ' || decrypted_text);
END;
/
在上述示例中,我们展示了如何使用TDE来加密一个表,如何在网络层面上启用SSL加密,以及如何在Oracle中使用加密函数。
请注意,实施数据保护和加密需要仔细规划,并确保所有的密钥和证书都是安全的。如果需要更详细的指导或有特定的需求,请告诉我,我可以提供进一步的帮助。
95. 请解释Oracle数据库中的数据审计和合规性检查方法和技术。
在Oracle数据库中,数据审计和合规性检查是确保数据遵守法规和行业标准的重要措施。以下是一些常见的数据审计和合规性检查方法和技术:
-
Oracle审计:Oracle提供了强大的审计功能,可以记录和报告数据库中的所有活动,包括对数据的访问、修改和其他操作。审计记录可以帮助识别潜在的安全威胁和合规性问题。
-
Oracle VPD(虚拟私有数据库):VPD允许数据库管理员为特定的用户或角色定义数据的可见性和访问权限,从而保护敏感数据。
-
Oracle的标签安全:通过使用标签和策略,可以控制敏感数据的分类和处理,确保遵守数据分类和分级法规。
-
合规性报告:Oracle提供了合规性报告工具,如Oracle Advanced Security,用于分析数据库的安全状态,并生成合规性报告。
-
数据库控制文件:数据库控制文件包含了关于数据库的关键配置信息,这些信息可以用来验证数据库是否符合特定的合规性标准。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中进行数据审计和合规性检查:
-- 启用审计特性
ALTER SYSTEM SET AUDIT_TRAIL = DB SCOPE;-- 审计特定用户的活动
AUDIT SELECT ON hr.employees BY access;
AUDIT INSERT, UPDATE, DELETE ON hr.employees BY access;-- 查看审计记录
SELECT * FROM DBA_AUDIT_TRAIL;-- 使用VPD限制数据访问
CREATE OR REPLACE PACKAGE emp_access_pkg ASPROCEDURE set_emp_dept_access(p_deptno NUMBER);
END emp_access_pkg;
/CREATE OR REPLACE PACKAGE BODY emp_access_pkg ASPROCEDURE set_emp_dept_access(p_deptno NUMBER) ISBEGINDBMS_SESSION.SET_CONTEXT('emp_dept_ctx', 'deptno', p_deptno);END set_emp_dept_access;
END emp_access_pkg;
/BEGINemp_access_pkg.set_emp_dept_access(10);SELECT * FROM hr.employees; -- 只会看到部门号为10的员工记录
END;
/-- 使用标签和策略
CREATE CONTEXT emp_label_ctx USING hr.emp_label_pkg;SELECT * FROM user_context$; -- 查看创建的上下文-- 假设我们有一个标签函数,用于根据员工的工资分类数据
CREATE OR REPLACE FUNCTION salary_classification(p_sal NUMBER)
RETURN VARCHAR2 AS
BEGINIF p_sal < 5000 THENRETURN 'Low';ELSIF p_sal BETWEEN 5000 AND 10000 THENRETURN 'Medium';ELSERETURN 'High';END IF;
END salary_classification;
/-- 为表列设置标签
BEGINDBMS_RLS.ADD_POLICY(object_schema => 'HR',object_name => 'EMPLOYEES',policy_name => 'salary_class_policy',function_schema => 'HR',policy_function => 'salary_classification',statement_types => 'SELECT',sec_relevant_cols => 'SALARY',sec_relevant_cols_opt => DBMS_RLS.ALL_ROWS);
END;
/-- 检查合规性报告
BEGINDBMS_COMPLIANCE.CREATE_COMPLIANCE_POLICY(policy_name => 'my_policy',compliance_scope => DBMS_COMPLIANCE.AS_COMPLIANCE_SCOPE_DBA,standard_name => 'GDPR');DBMS_COMPLIANCE.EVALUATE_COMPLIANCE(policy_name => 'my_policy',compliance_details => TRUE);
END;
/
在上述示例中,我们展示了如何启用和使用审计功能,如何使用VPD来限制数据访问,以及如何使用标签和策略来分类和控制数据访问。此外,我们还展示了如何创建和评估合规性报告。
数据审计和合规性检查是一个持续的过程,需要与时俱进,并且需要根据具体的法规和标准进行调整。如果您有任何特定的需求或问题,我可以提供更详细的解释或进一步的帮助。
96. 请解释Oracle数据库中的数据迁移和转换方法和技术。
在Oracle数据库中,数据迁移和转换是将数据从一个系统或结构迁移到另一个系统或结构的过程,同时可能需要改变数据的格式、结构或模式以适应新的需求或系统。以下是一些常见的数据迁移和转换方法和技术:
-
导出/导入工具:Oracle提供了多种导出和导入工具,如
EXP和IMP工具,用于将数据从Oracle数据库导出到平面文件中,然后再将这些文件导入到另一个Oracle数据库中。 -
数据泵(Data Pump):Data Pump是一个强大的工具,用于高速大规模地导出和导入数据。它支持导出和导入表空间、数据库、模式和表的数据。
-
SQL*Loader:SQL*Loader是一个命令行工具,用于将数据从平面文件或其他数据源导入Oracle数据库。
-
使用PL/SQL编写自定义脚本:当内置的迁移工具无法满足需求时,可以编写自定义的PL/SQL脚本来处理数据迁移。
-
第三方工具:市场上有许多第三方工具可用于Oracle数据库的数据迁移,如Talend, Informatica, AWS DMS等。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中进行数据迁移和转换:
-- 使用EXP工具导出数据
EXP userid=system/password file=employees.dmp tables=hr.employees-- 使用IMP工具导入数据
IMP userid=system/password file=employees.dmp fromuser=hr touser=hr-- 使用Data Pump导出表结构和数据
EXPDP system/password DIRECTORY=data_pump_dir DUMPFILE=employees.dmp LOGFILE=employees.log SCHEMAS=hr-- 使用Data Pump导入表结构和数据
IMPDP system/password DIRECTORY=data_pump_dir DUMPFILE=employees.dmp LOGFILE=employees_import.log-- 使用SQL*Loader导入数据
CREATE TABLE employees_load (employee_id NUMBER,first_name VARCHAR2(50),last_name VARCHAR2(50),email VARCHAR2(100),hire_date DATE
);CONTROL_FILE employees.ctl
LOAD DATA
INFILE 'employees.csv'
INTO TABLE employees_load
FIELDS TERMINATED BY ','
TRAILING NULLCOLS (employee_id,first_name,last_name,email,hire_date
)-- 使用PL/SQL编写自定义迁移脚本
DECLARECURSOR c_employees ISSELECT * FROM hr.employees;v_employee c_employees%ROWTYPE;
BEGINFOR v_employee IN c_employees LOOP-- 转换逻辑,例如将数据插入到新的表结构中INSERT INTO new_employees (emp_id, first_name, last_name, email, start_date)VALUES (v_employee.employee_id, v_employee.first_name, v_employee.last_name, v_employee.email, v_employee.hire_date);END LOOP;COMMIT;
EXCEPTIONWHEN OTHERS THENROLLBACK;RAISE;
END;
/
在上述示例中,我们展示了如何使用EXP和IMP工具,Data Pump导出和导入工具,以及SQL*Loader来进行数据迁移。这些工具和方法可以根据不同的数据量和需求进行选择和调整。
数据迁移和转换可能是一个复杂的过程,涉及到数据清洗、转换和加载。如果您需要更详细的指导或在特定环境下的迁移和转换方案,请随时向我咨询。
97. 请解释Oracle数据库中的数据同步和复制方法和技术。
在Oracle数据库中,数据同步和复制是为了保持两个或多个数据库之间的数据一致性而采取的措施。同步通常是指在不同数据库之间实时地复制数据变更,而复制则是指在特定时间点或事件发生时,将数据从一个数据库复制到另一个数据库。以下是一些常见的数据同步和复制方法和技术:
-
物理同步:物理同步通常指的是在不同地理位置的数据库之间进行同步,如通过高速网络连接。
-
逻辑同步:逻辑同步通常使用数据库触发器、存储过程或其他逻辑来在数据库间同步数据。
-
数据库链接(Database Linking):Oracle数据库链接允许你在一个数据库中查询另一个数据库的表,就像它们是在同一个数据库中一样。
-
GoldenGate:GoldenGate是一个全面的数据集成和复制解决方案,它支持实时数据同步和事务复制。
-
Streams:Oracle Streams是一种高性能的数据同步技术,允许你在数据库之间同步实时事件。
-
使用PL/SQL编写同步脚本:当简单的数据库链接或触发器无法满足需求时,可以编写自定义的PL/SQL脚本来同步数据。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中进行数据同步和复制:
-- 创建数据库链接
CREATE DATABASE LINK remote_db
CONNECT TO remote_user IDENTIFIED BY remote_password
USING 'remote_db_instance';-- 使用数据库链接进行查询
SELECT * FROM employees@remote_db;-- 创建触发器来同步数据插入
CREATE OR REPLACE TRIGGER sync_employees_insert
AFTER INSERT ON hr.employees
FOR EACH ROW
BEGININSERT INTO remote_db.hr.employees@remote_db (employee_id, first_name, last_name, email, hire_date)VALUES (:new.employee_id, :new.first_name, :new.last_name, :new.email, :new.hire_date);
END;
/-- 创建触发器来同步数据更新
CREATE OR REPLACE TRIGGER sync_employees_update
AFTER UPDATE ON hr.employees
FOR EACH ROW
BEGINUPDATE remote_db.hr.employees@remote_dbSET first_name = :new.first_name,last_name = :new.last_name,email = :new.email,hire_date = :new.hire_dateWHERE employee_id = :new.employee_id;
END;
/-- 创建触发器来同步数据删除
CREATE OR REPLACE TRIGGER sync_employees_delete
AFTER DELETE ON hr.employees
FOR EACH ROW
BEGINDELETE FROM remote_db.hr.employees@remote_dbWHERE employee_id = :old.employee_id;
END;
/-- 使用GoldenGate进行实时同步
-- 配置GoldenGate复制服务器和提取进程
-- 配置GoldenGate复制服务器和回放进程
-- 启动复制服务器和进程-- 使用Streams进行数据同步
-- 创建Streams高级队列
CREATE ADVANCED QUEUEING q_streams_sync;-- 创建Streams订阅者
CREATE SUBSCRIBER sub_streams_sync
CONNECT TO user_streams IDENTIFIED BY password
SUBSCRIBE q_streams_sync WITH PUSH;-- 在源数据库中创建Streams发布者
CREATE PUBLISHER p_streams_sync
CONNECT TO user_streams IDENTIFIED BY password
PUBLISH q_streams_sync WITH PUSH;-- 在源数据库中定义Streams规则
RULE r_streams_sync AS
ON INSERT OR UPDATE OR DELETE ON hr.employees
DO (ENQUEUE INTO q_streams_sync VALUES (NEW.employee_id, NEW.first_name, NEW.last_name, NEW.email, NEW.hire_date);
);-- 在目标数据库中创建触发器来处理Streams数据
CREATE OR REPLACE TRIGGER sync_streams_insert
AFTER INSERT ON q_streams_sync
FOR EACH ROW
BEGININSERT INTO hr.employees (employee_id, first_name, last_name, email, hire_date)VALUES (:new.msg_data.employee_id, :new.msg_data.first_name, :new.msg_data.last_name, :new.msg_data.email, :new.msg_data.hire_date);
END;
/
在上述示例中,我们展示了如何使用数据库链接、触发器、GoldenGate和Streams来实现数据同步和复制。这些方法可以根据不同的业务需求和技术栈进行选择和调整。
请注意,进行数据同步和复制时,需要考虑数据的一致性、性能、可靠性和错误处理等因素。如果您需要更详细的指导或在特定环境下的数据同步和复制方案,请随时向我咨询。
98. 请解释Oracle数据库中的数据压缩和去重方法和技术。
在Oracle数据库中,数据压缩和去重是两种优化数据存储和提高性能的技术。数据压缩减少了数据库表中数据所占用的存储空间,而数据去重则是识别并移除重复的记录。以下是一些常见的数据压缩和去重方法和技术:
-
行级压缩(Row Level Compression):Oracle支持对表和索引进行行级压缩。行级压缩通过减少数据块中存储的重复值来减少空间占用。
-
块级压缩(Block Level Compression):块级压缩适用于大对象(BLOB、CLOB)数据类型,它将多个数据块合并成一个较小的数据块。
-
字典压缩(Dictionary Compression):字典压缩使用一个共享的字典来存储数据库中重复的字符串值。
-
去重操作:去重通常涉及到识别数据中的重复行,并只保留一个副本。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中进行数据压缩和去重:
-- 行级压缩示例
-- 创建一个行级压缩的表
CREATE TABLE compressed_employees (employee_id NUMBER,first_name VARCHAR2(100),last_name VARCHAR2(100),email VARCHAR2(255),hire_date DATE
) COMPRESS FOR ALL OPERATIONS;-- 插入一些数据
INSERT INTO compressed_employees
SELECT * FROM employees;-- 查看压缩后的表结构
SELECT table_name, compression
FROM user_tables
WHERE table_name = 'COMPRESSED_EMPLOYEES';-- 去重操作示例
-- 创建一个去重的表
CREATE TABLE unique_employees AS
SELECT DISTINCT * FROM employees;-- 或者使用ROWID去重
DELETE FROM employees
WHERE ROWID NOT IN (SELECT MIN(ROWID)FROM employeesGROUP BY employee_id, first_name, last_name, email, hire_date
);-- 字典压缩示例
-- 在Oracle 12c之前,字典压缩是自动管理的,但在12c及更高版本中,您需要手动启用字典压缩
BEGINDBMS_COMPRESSION.CREATE_DICTIONARY('my_dictionary', 'TABLESPACE_NAME');
END;-- 对一个表启用字典压缩
ALTER TABLE employees COMPRESS FOR QUERY HIGH WITH ROWID ROW STORE COMPRESS ADVANCED ROW LEVEL;-- 查看字典压缩状态
SELECT table_name, compression, compression_type
FROM user_tables
WHERE table_name = 'EMPLOYEES';
在上述示例中,我们展示了如何使用行级压缩和去重操作来优化数据存储。对于字典压缩,请注意在Oracle 12c及更高版本中,您需要手动创建和管理字典。
数据压缩和去重操作应该根据数据的特点和使用模式来选择最合适的方法。如果您需要更详细的指导或在特定环境下的数据压缩和去重方案,请随时向我咨询。
99. 请解释Oracle数据库中的数据缓存和预取方法和技术。
在Oracle数据库中,数据缓存和预取是两种提高数据库性能的技术,它们涉及到数据库缓冲区和数据预取策略。数据缓存是指将数据从数据库存储设备(如磁盘)读入内存(缓冲区缓存)的过程,这样可以快速访问数据,减少对磁盘的I/O操作。预取是指在数据库执行查询时,提前将将要访问的数据从磁盘读入缓冲区的过程。
以下是一些数据缓存和预取的方法和技术:
-
数据库缓冲区缓存(Database Buffer Cache):这是Oracle数据库中最主要的数据缓存区域,它存储了数据库块的副本以便快速访问。
-
共享池(Shared Pool):共享池包括库缓存(Library Cache)和数据字典缓存(Data Dictionary Cache)。库缓存存存储了SQL语句和PL/SQL代码的执行计划,而数据字典缓存存储了数据库元数据,如表和索引的定义。
-
数据预取(Data Prefetching):数据预取策略包括自动预取、手动预取和基于SQL语句的预取。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中进行数据缓存和预取的配置:
-- 查看数据库缓冲区缓存的参数
SHOW PARAMETER buffer_cache_size;-- 调整数据库缓冲区缓存的大小
ALTER SYSTEM SET buffer_cache_size = 400M SCOPE = SPFILE;-- 手动将数据加载到缓冲区缓存中
ALTER SYSTEM FLUSH BUFFER_CACHE;-- 查看共享池的大小
SHOW PARAMETER shared_pool_size;-- 调整共享池的大小
ALTER SYSTEM SET shared_pool_size = 500M SCOPE = SPFILE;-- 启用数据预取
ALTER SYSTEM SET db_file_multiblock_read_count = 16;-- 查看数据预取的参数
SHOW PARAMETER db_file_multiblock_read_count;-- 使用SQL语句启用基于SQL语句的预取
SELECT /*+ FULL(e) */ * FROM employees e WHERE employee_id = 123;
在上述示例中,我们展示了如何调整数据库缓冲区缓存和共享池的大小,以及如何手动刷新缓冲区缓存。对于数据预取,我们演示了如何启用自动和基于SQL语句的预取。
数据缓存和预取的配置需要根据数据库的工作负载和性能要求来进行调整。如果您需要更详细的指导或在特定环境下的缓存和预取策略,请随时向我咨询。
100. 请解释Oracle数据库中的数据生命周期管理方法和技术。
在Oracle数据库中,数据生命周期管理(Data Life Cycle Management, DLM)是指在数据存储和处理过程中对数据进行跟踪、分类、控制和自动化处理的过程,以确保数据的有效性、可用性和安全性。以下是一些数据生命周期管理的方法和技术:
-
数据归档(Data Archiving):定期将不经常访问的旧数据移动到较便宜的存储介质上,如磁带或其他归档系统。
-
数据压缩(Data Compression):减少数据存储空间的技术,通过压缩重复和无关的信息来优化空间使用。
-
数据删除(Data Purging):定期从数据库中删除过时的、无用的或敏感数据,以减少数据库的大小和维护成本。
-
数据备份和恢复(Backup and Recovery):定期备份数据,并确保在发生故障时能够恢复数据,以减少数据丢失的风险。
-
闪回技术(Flashback Technology):允许用户查询和恢复在特定时间点上的数据状态。
-
分区(Partitioning):将数据库表分割成更小、更易管理的部分,可以提高性能和可用性。
-
索引组织表(Index-Organized Tables):通过索引结构直接存储和访问数据行,减少了I/O操作。
示例SQL代码
以下是一些示例SQL代码,用于演示如何在Oracle数据库中实施数据生命周期管理:
-- 创建表空间用于归档
CREATE TABLESPACE archive_dataDATAFILE 'archive_data.dbf'SIZE 10MAUTOEXTEND ON;-- 启用表的归档特性
ALTER TABLE employees ARCHIVETABLE;-- 设置归档策略
ALTER TABLE employees ARCHIVE ON;-- 压缩表中的数据
ALTER TABLE employees COMPRESS FOR OLTP;-- 删除过时的数据
DELETE FROM employees WHERE hire_date < SYSDATE - INTERVAL '5' YEAR;
COMMIT;-- 备份整个数据库
BEGINDBMS_BACKUP_JOB.BACKUP_DATABASE(backup_type => 'FULL',backup_directory => '/backup/database');
END;
/-- 使用闪回查询表中的数据
SELECT * AS OF TIMESTAMP TO_TIMESTAMP('2023-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')
FROM employees
WHERE employee_id = 123;-- 分区表
CREATE TABLE sales_partitioned
(sale_id NUMBER,sale_date DATE,product_id NUMBER,quantity NUMBER
)
PARTITION BY RANGE (sale_date)
(PARTITION sales_2022 VALUES LESS THAN (TO_DATE('01-01-2023', 'DD-MM-YYYY')),PARTITION sales_2023 VALUES LESS THAN (TO_DATE('01-01-2024', 'DD-MM-YYYY'))
);-- 索引组织表
CREATE TABLE iot_employees
(employee_id NUMBER PRIMARY KEY,first_name VARCHAR2(50),last_name VARCHAR2(50),email VARCHAR2(100),hire_date DATE,job_id VARCHAR2(10),salary NUMBER(8,2)
)
ORGANIZATION INDEX;
在上述示例中:
- 我们创建了一个归档表空间
archive_data,并将employees表设置为使用归档。 - 我们对
employees表启用了压缩,以便减少其存储空间。 - 我们删除了5年前雇用的员工数据,以维护数据库的有效性。
- 我们执行了一个全数据库备份到指定的目录。
- 我们使用了闪回技术来查询特定时间点的员工数据。
- 我们创建了一个按
sale_date分区的sales_partitioned表,以提高查询效率。 - 最后,我们创建了一个索引组织表
iot_employees,它通过索引结构直接存储数据行,从而优化了查询性能。
相关文章:

Oracle数据库面试题-9
81. 请解释Oracle数据库中的林业数据处理方法。 Oracle数据库中的林业数据处理 在Oracle数据库中处理林业数据涉及到存储、管理、分析和可视化与林业相关的数据。以下是林业数据处理的一些关键方面以及如何使用Oracle数据库进行示例性的SQL说明: 数据库设计&#…...
跟着小白学linux的基础命令
小白学习记录: 前情提要:Linux命令基础格式!查看 lsLinux 的7种文件类型及各颜色代表含义 进入指定目录 cd查看当前工作目录 pwd创建一个新的目录(文件夹) mkdir创建文件 touch查看文件内容 cat、more操作文件、文件夹- 复制 cp- 移动 mv- 删…...

2024-06-08 Unity 编辑器开发之编辑器拓展9 —— EditorUtility
文章目录 1 准备工作2 提示窗口2.1 双键窗口2.2 三键窗口2.3 进度条窗口 3 文件面板3.1 存储文件3.2 选择文件夹3.3 打开文件3.4 打开文件夹 4 其他内容4.1 压缩纹理4.2 查找对象依赖项 1 准备工作 创建脚本 “Lesson38Window.cs” 脚本,并将其放在 Editor 文件…...
Mac下删除系统自带输入法ABC,正解!
一、背景说明 MacOS 在 14.2 以下的系统存在中文输入法 BUG,会造成系统卡顿,出现彩虹圆圈。如果为了解决这个问题,有两种方法: 升级到最新的 14.5 系统使用第三方输入法 在使用第三方输入法的时候,会发现系统自带的 …...
redis学习路线
待更新… 一、nosql讲解 1. 为什么要用nosql? 用户的个人信息,社交网络,地理位置,自己产生的数据,日志等等爆发式增长!传统的关系型数据库已无法满足这些数据处理的要求,这时我们就需要使用N…...

数据库练习题
1行程和用户 表:Trips ----------------------- | Column Name | Type | ----------------------- | id | int | | client_id | int | | driver_id | int | | city_id | int | | status | enum | | request_at…...

【每日一函数】uname 函数介绍及代码演示
Linux uname 函数介绍及代码演示 引言 Linux 系统中,uname 是一个常用的命令行工具,用于显示系统信息。然而,在编程过程中,我们有时需要在程序中获取这些信息,此时就可以使用 uname 函数。本文将对 uname 函数进行详…...

linux:命令别名,文件描述符及重定向
命令别名 命令别名是Shell提供的一种快捷方式,允许为命令创建简短的替代名称。,可以通过输入较短的别名来执行较长的命令,从而提高效率。 1.查看所有别名: [rootlocalhost ~]# alias 2.创建临时别名,当前会话关闭即清除 alias 别名完整命令…...
前端开发之中svg图标的使用和实例
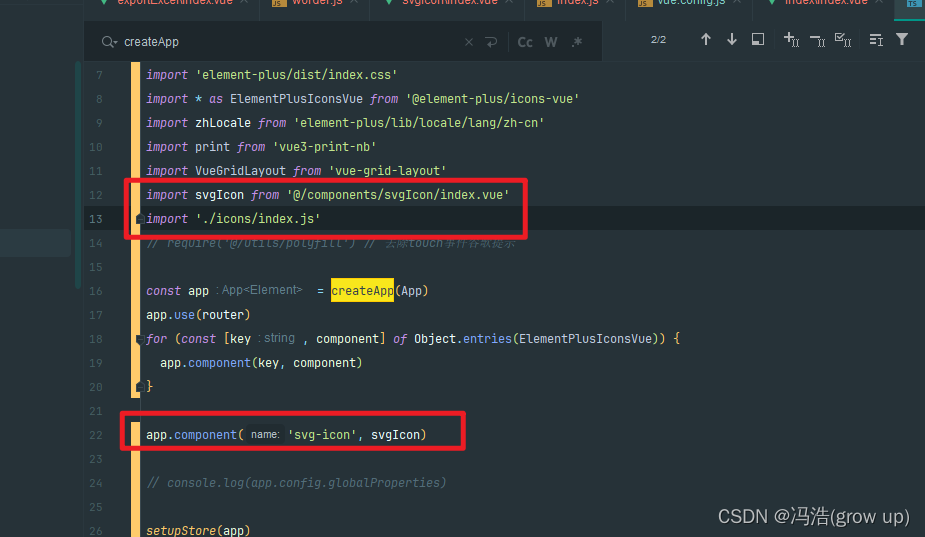
svg图标的使用和实例 前言效果图1、安装插件2、vue3中使用2.1、 在components文件夹中,创建公共类SvgIcon/index.vue2.2、创建icons文件,存放svg图标和将所有的svg图标进行引用并注册成全局组件2.3、在man.js 中注册2.4、在vue.config.js中配置svg2.5、在vue中的调用svg图标3…...
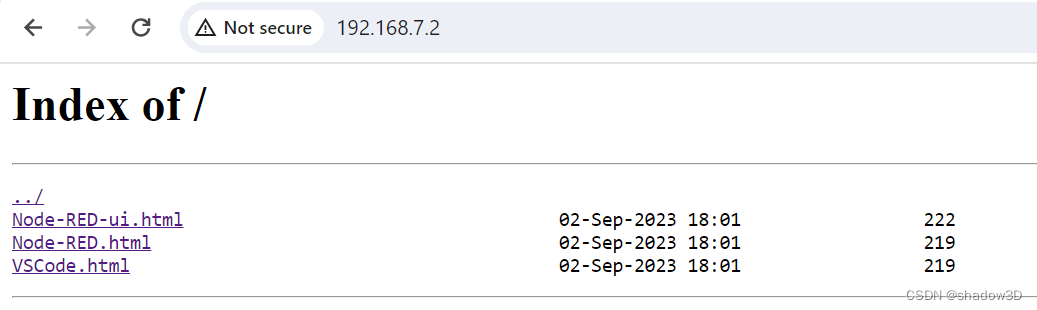
BeagleBone Black入门总结
文章目录 参考连接重要路径系统镜像下载访问 BeagleBone 参考连接 镜像下载启动系统制作:SD卡烧录工具入门书籍推荐:BeagleBone cookbookBeagleBone概况? 重要路径 官方例程及脚本路径:/var/lib/cloud9 系统镜像下载 疑问&am…...

笔记:Mysql的安全策略
1,安装安全插件 1.检查是否已安装该插件 SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME validate_password;2.安装插件 INSTALL PLUGIN validate_password SONAME validate_password.so;3.修改配置文件 vi /etc/my.cn…...

AI绘画中的图像格式技术
在数字艺术的广阔天地里,AI绘画作为一种新兴的艺术形式,正在逐渐占据一席之地。不同于传统绘画,AI绘画依赖于复杂的算法和机器学习模型来生成图像,而这一切的背后,图像格式技术发挥着至关重要的作用。图像格式不仅关系…...

前端如何封装自己的npm包并且发布到npm注册源
前言 在前端开发中,复用代码是一种常见且高效的实践。通过封装和发布自己的npm包,你可以轻松地在多个项目之间共享代码,并且贡献给社区。以下是一步一步指导你如何封装自己的npm包并发布到npm注册源。 步骤一:创建并设置项目 首…...

vue油色谱画 大卫三角形|大卫五边形|PD图
大卫三角形 大卫五边形 PD图...

【React】前端插件 uuidjs 的使用 --随机生成id
文档1 文档2 使用 1.安装 npm install uuid2.Create a UUID import { v4 as uuidv4 } from uuid; uuidv4(); // ⇨ 9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6d3.或使用 CommonJS语法 const { v4: uuidv4 } require(uuid); uuidv4(); // ⇨ 1b9d6bcd-bbfd-4b2d-9b5d-ab8dfbbd4…...
ctfshow-web入门-信息搜集(web11-web20)
目录 1、web11 2、web12 3、web13 4、web14 5、web15 6、web16 7、web17 8、web18 9、web19 10、web20 1、web11 域名其实也可以隐藏信息,比如flag.ctfshow.com 就隐藏了一条信息 查询域名的 DNS 记录,类型为 TXT(域名的说明&#…...
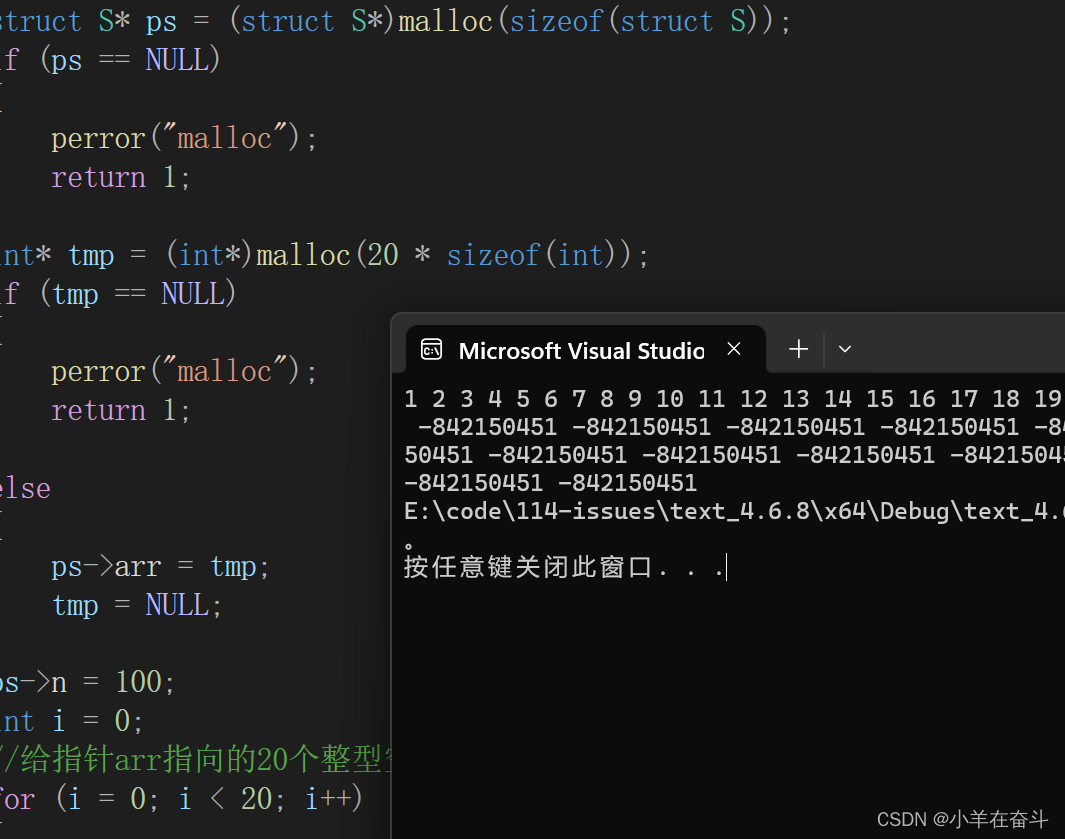
C语言详解(动态内存管理)2
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...
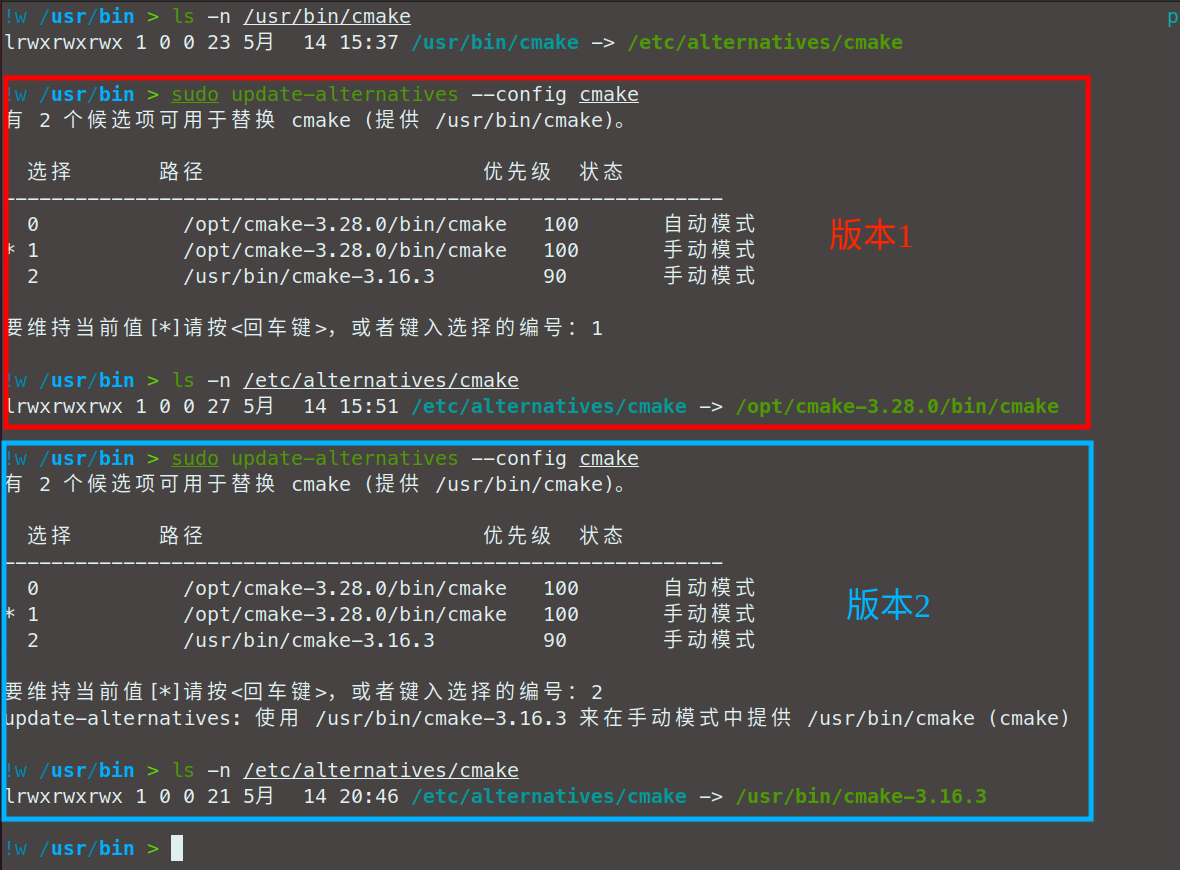
【ubuntu软件版本管理】利用update-alternatives管理ubuntu软件
我们有的时候希望在安装了新软件之后保留旧版本的软件,比如希望保留旧版本的gcc,以防以前写的C编译出问题,这时候就需要版本管理软件update-alternatives。 在此之前我们需要先弄清楚,什么是ubuntu的软件?拿C源…...

如何把linux安装到单片机中
1.如何把linux安装到单片机中 将Linux安装到单片机中通常不是一个直接的过程,因为单片机(如51系列、STC系列等)的硬件资源和处理能力有限,而Linux是一个为更强大硬件平台(如个人电脑、服务器)设计的操作系…...

Ubuntu bash按Table不联想
Ubuntu bash按Table不联想 bash-completion包未安装或损坏: 自动补全功能依赖于bash-completion包。首先,需要确保这个包已经安装。可以通过下面的命令安装或重新安装它: sudo apt install --reinstall bash-completion安装完成后,…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...

【Veristand】Veristand环境安装教程-Linux RT / Windows
首先声明,此教程是针对Simulink编译模型并导入Veristand中编写的,同时需要注意的是老用户编译可能用的是Veristand Model Framework,那个是历史版本,且NI不会再维护,新版本编译支持为VeriStand Model Generation Suppo…...
实现跳一跳小游戏)
鸿蒙(HarmonyOS5)实现跳一跳小游戏
下面我将介绍如何使用鸿蒙的ArkUI框架,实现一个简单的跳一跳小游戏。 1. 项目结构 src/main/ets/ ├── MainAbility │ ├── pages │ │ ├── Index.ets // 主页面 │ │ └── GamePage.ets // 游戏页面 │ └── model │ …...
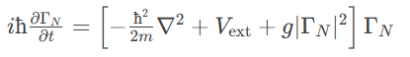
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...

HTML中各种标签的作用
一、HTML文件主要标签结构及说明 1. <!DOCTYPE html> 作用:声明文档类型,告知浏览器这是 HTML5 文档。 必须:是。 2. <html lang“zh”>. </html> 作用:包裹整个网页内容,lang"z…...