【传知代码】DETR[端到端目标检测](论文复现)
前言:想象一下,当自动驾驶汽车行驶在繁忙的街道上,DETR能够实时识别出道路上的行人、车辆、交通标志等目标,并准确预测出它们的位置和轨迹。这对于提高自动驾驶的安全性、减少交通事故具有重要意义。同样,在安防监控、医疗影像分析等领域,DETR也展现出了巨大的应用潜力,如今,一项名为DETR(Detection Transformer)的创新技术,犹如一股清流,为这一领域带来了革命性的变革。DETR,这个听起来有些神秘而高深的名词,实际上是一种基于Transformer架构的端到端目标检测模型。它摒弃了传统方法中繁琐的锚框和候选区域生成步骤,直接通过Transformer的强大能力,将图像中的目标信息与上下文信息相融合,实现了对目标的精准定位和分类。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
在进行目标检测时,需要大量手动设计的组件,比如非极大值抑制(NMS)和基于人工经验生成的先验框(Anchor)等。DETR在其文章中,将目标检测视为一个直接的集合预测任务,从而减少了对人工组件设计的依赖,并使目标检测流程更为简洁。当提供一组固定的、可学习的目标查询DETR来推断目标与全局图像之间的上下文关系时,由于DETR没有先验框的限制,这将使其在预测较大物体时表现得更为出色。
如下图展示的是DETR的核心框架。由于直接使用了transformer的结构,这导致模型的计算需求增加。因此,DETR首先利用CNN卷积神经网络来提取特征,这种方法生成的特征图通常会降低32倍的采样。接下来,我们将提取出的特征图传输到Transformer的encoder结构中,以实现自注意力的交互,从而揭示特征图中每一个像素与其他像素的相互关系。decoder首先为用户预设了N个查询。这些查询首先通过自注意力机制去除模型中的多余框,然后与来自Encoder的特征交互,生成数量为N的查询。这些查询通过线性层生成模型预测的类别和相应的边界框输出,最终完成预测:
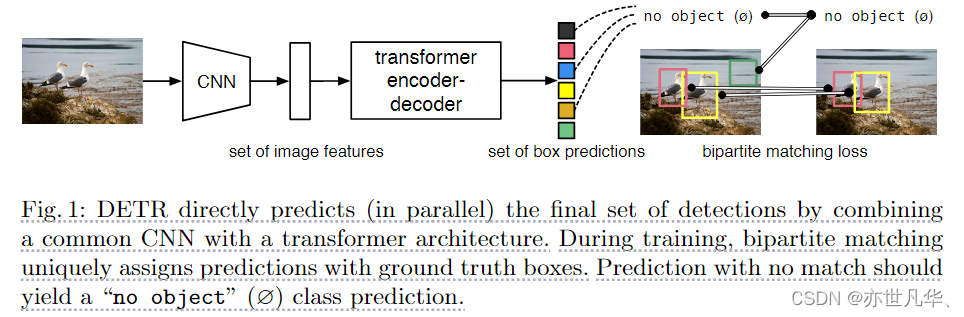
实验中N个数据比一幅图包含全部对象更多,计算损失函数时DETR先用匈牙利算法找到合适匹配方式。然后去算bbox及分类损失值。鉴于L1L1损失函数对不同尺寸的边界框产生的误差存在差异,我们决定使用GIoUGIoU损失函数来补偿这些误差。如下图,为DETR更为详尽的图示:

主干网络方面:
针对于一张通道数大小为3的图片,首先经过CNN的骨干网络,得到一个通道数为2048(这个数据由我们手动设定),长宽分别为原始图像大小132321的特征图f∈RC×H×Wf∈RC×H×。
Transformer编码器:
首先,通过1×11×1的卷积方法,我们将特征图ff的通道维数从CC减少到了更低的dd维度,并据此生成了一个新的特征图z0∈Rd×H×Wz0∈Rd×H×W,编码器希望有序列做输入,所以我们把z0z0̈个空间维度压缩成1维,生成d×HWd×HW特征图。
每一个编码器层都配备了一个统一的架构,该架构由一个多头自注意力模块和一个前馈网络(FFN)共同构成。由于Transformer架构具有置换不变性(对输入序列进行排序更改而不会对输出结果进行更改),我们用维度大小相同的位置编码来弥补这个缺点,位置编码被添加到每个注意力层的输入中。Transformer解码器:
DETR与标准Transformer架构中的decoder有所不同,因为它并未使用掩码技术,这意味着N个预测的边界框可以被同时输出。
鉴于解码器依然保持置换不变性,我们选择了可学习的位置编码作为其输入嵌入方式,并将其命名为object query。这种object query经由若干层结构最后被转换到输出边界框上并经由FFN结构产生N个坐标点以及分类后之物体。
下图所示是模型Transformer的主要结构,来自CNN主干网络的图像特征被送到transformer编码器中,在每个多头自注意力机制中与空间位置编码相加作为多头自注意力机制的键和查询,(生成q,k,v需要矩阵相乘,并不是一个直接的结果)。作为在解码器和编码器进行注意力机制计算之前,首先object query需要进行一个自注意力机制,该步骤是为了去除模型中的冗余框:

演示效果
使用一个GPU进行模型训练、验证和可视化,命令如下:
# 模型训练
python -m torch.distributed.launch --nproc_per_node=1 --use_env main.py --coco_path data/coco # 模型验证
python main.py --batch_size 2 --no_aux_loss --eval --resume ckpt/detr-r50-e632da11.pth --coco_path data/coco# 模型可视化
python imshow.py部署项目方式如下:
# 首先安装相应版本的PyTorch 1.5+和torchvision 0.6+ ,如果有GPU则安装GPU版本的,没有安装相应cpu版本的,注意linux和window之间的区别
conda install -c pytorch pytorch torchvision
# 安装pycococtools(在COCO数据集上进行预测)和scipy(为了训练)
conda install cython scipy
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'从http://cocodataset.org下载COCO2017的train和val图像,相应地annotation,具体如下截图所示:

将数据集按照下面的形式进行摆放:
data/coco/annotations/ # annotation json filestrain2017/ # train imagesval2017/ # val images从detr-r50-e632da11.pth下载相应的权重,并命名为ckpt/detr-r50-e632da11.pth,放在ckpt文件夹下,如下图所示:

使用DETR进行目标检测,效果如下:

使用DETR交叉注意力机制可视化如下:

DETR自注意力机制可视化,query表示当前物体的标号,下方对应的是相应的名称,下方显示的点可以人工手动调整:

核心代码
下面这段代码实现了一个目标检测模型 DETR(DEtection TRansformer),它使用了 Transformer 架构进行目标检测,在 __init__ 函数中,模型接受了一个 backbone 模型、一个 transformer 模型、目标类别数 num_classes、最大检测框个数 num_queries 和一个参数 aux_loss。其中,backbone 模型用于提取特征,transformer 模型用于处理特征和进行目标检测。模型的输出包括分类 logits 和检测框坐标,以及可选的辅助损失。
在 forward 函数中,模型接受了一个 NestedTensor,其中 samples.tensor 是一个批次的图像,samples.mask 是一个二进制掩码,表示每个图像中的有效像素。首先,模型使用 backbone 模型提取特征和位置编码。然后,模型使用 transformer 模型对特征和位置编码进行处理,得到分类 logits 和检测框坐标。最后,模型将分类 logits 和检测框坐标输出为字典,其中 pred_logits 表示分类 logits,pred_boxes 表示检测框坐标。
在 _set_aux_loss 函数中,模型处理辅助损失。这里使用了一个 workaround,将输出的字典转换为一个列表,每个元素包含分类 logits 和检测框坐标。这样做是为了让 torchscript 能够正常工作,因为它不支持非同构值的字典。
class DETR(nn.Module):""" This is the DETR module that performs object detection """def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):""" Initializes the model.Parameters:backbone: torch module of the backbone to be used. See backbone.pytransformer: torch module of the transformer architecture. See transformer.pynum_classes: number of object classesnum_queries: number of object queries, ie detection slot. This is the maximal number of objectsDETR can detect in a single image. For COCO, we recommend 100 queries.aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used."""super().__init__()self.num_queries = num_queriesself.transformer = transformerhidden_dim = transformer.d_modelself.class_embed = nn.Linear(hidden_dim, num_classes + 1)self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)self.query_embed = nn.Embedding(num_queries, hidden_dim)self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)self.backbone = backboneself.aux_loss = aux_lossdef forward(self, samples: NestedTensor):""" The forward expects a NestedTensor, which consists of:- samples.tensor: batched images, of shape [batch_size x 3 x H x W]- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixelsIt returns a dict with the following elements:- "pred_logits": the classification logits (including no-object) for all queries.Shape= [batch_size x num_queries x (num_classes + 1)]- "pred_boxes": The normalized boxes coordinates for all queries, represented as(center_x, center_y, height, width). These values are normalized in [0, 1],relative to the size of each individual image (disregarding possible padding).See PostProcess for information on how to retrieve the unnormalized bounding box.- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list ofdictionnaries containing the two above keys for each decoder layer."""if isinstance(samples, (list, torch.Tensor)):samples = nested_tensor_from_tensor_list(samples)# backbone 网络进行了两个操作,分别是获取特征图和位置编码features, pos = self.backbone(samples)src, mask = features[-1].decompose()assert mask is not None# input_proj: src: [2,2048,28,38]->[2,256,28,38] 改变特征图的通道维数# mask: [2,28,38] mask的通道维数为1 pos: [2,256,28,38] query表示查询,也就是图片里面可能有多少物体的个数hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]outputs_class = self.class_embed(hs)outputs_coord = self.bbox_embed(hs).sigmoid()# 都只使用最后一层decoder输出的结果out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}if self.aux_loss:out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)return out@torch.jit.unuseddef _set_aux_loss(self, outputs_class, outputs_coord):# this is a workaround to make torchscript happy, as torchscript# doesn't support dictionary with non-homogeneous values, such# as a dict having both a Tensor and a list.return [{'pred_logits': a, 'pred_boxes': b}for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]下面这段代码实现了一个 Transformer 模型,用于对输入特征进行编码和解码,首先,模型将输入特征和位置编码展平,并进行转置,得到形状为 [HW, N, C] 的张量。然后,模型将查询编码重复 N 次,并将掩码展平,以便在解码器中使用。接下来,模型使用编码器对输入特征进行编码,并使用解码器对编码后的特征进行解码。最后,模型将解码器的输出进行转置,得到形状为 [batch_size, num_queries, d_model] 的张量,并将编码器的输出进行转置和重构,得到与输入特征相同的形状,如下:
class Transformer(nn.Module):def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,activation="relu", normalize_before=False,return_intermediate_dec=False):super().__init__()encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)encoder_norm = nn.LayerNorm(d_model) if normalize_before else Noneself.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,dropout, activation, normalize_before)decoder_norm = nn.LayerNorm(d_model)self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,return_intermediate=return_intermediate_dec)self._reset_parameters()self.d_model = d_modelself.nhead = nheaddef _reset_parameters(self):for p in self.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)def forward(self, src, mask, query_embed, pos_embed):# flatten NxCxHxW to HWxNxC [2,256,28,38]bs, c, h, w = src.shape# src: [2,256,28,38]->[2,256,28*38]->[1064,2,256]# pos_embed: [2,256,28,38]->[2,256,28*38]->[1064,2,256]src = src.flatten(2).permute(2, 0, 1)pos_embed = pos_embed.flatten(2).permute(2, 0, 1)# query_embed:[100,256]->[100,1,256]->[100,2,256]query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)# mask: [2,28,38]->[2,1064]mask = mask.flatten(1)# 其实也是一个位置编码,表示目标的信息,一开始被初始化为0 [100,2,256]tgt = torch.zeros_like(query_embed)# memory的shape和src的一样是[1064,2,256]memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,pos=pos_embed, query_pos=query_embed)# hs 不止输出最后一层的结构,而是输出解码器所有层结构的输出情况# hs: [6,100,2,256]->[6,2,100,256] [depth,batch_size,num_query,channel]# 一般只使用最后一层特征所以未hs[-1]return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)写在最后
DETR以其独特的视角和创新的架构,彻底改变了目标检测的传统流程。它摒弃了复杂的预处理步骤,如锚框生成和非极大值抑制,转而采用了一种简洁而高效的设计。通过Transformer的自注意力机制,DETR能够捕捉图像中各个部分之间的长距离依赖关系,从而更准确地预测目标的位置和类别。
DETR的成功并非偶然。它基于Transformer的强大能力,将图像特征提取、目标定位和分类任务全部整合在一个模型中,实现了真正的端到端训练。这种设计不仅简化了检测过程,还提高了模型的整体优化效果。更重要的是,DETR的“集合预测”机制允许模型以并行的方式预测所有目标,无需繁琐的排序或筛选操作,进一步提升了检测效率。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
相关文章:
【传知代码】DETR[端到端目标检测](论文复现)
前言:想象一下,当自动驾驶汽车行驶在繁忙的街道上,DETR能够实时识别出道路上的行人、车辆、交通标志等目标,并准确预测出它们的位置和轨迹。这对于提高自动驾驶的安全性、减少交通事故具有重要意义。同样,在安防监控、…...
Edge浏览器十大常见问题,一次性解决!
Edge曾被称为最好用的浏览器,拳打Chrome脚踢firefox, 可如今却隐藏着像是播放卡顿、下载缓慢、广告繁多等诸多问题,不知道各位还在用吗? 今天小编收集整理了Edge浏览器十大烦人问题,并提供简单有效的解决办法,让你的E…...

lubuntu / ubuntu 配置静态ip
一、查看原始网络配置信息 1、获取网卡名称 ifconfig 2、查询网关IP route -n 二、编辑配置文件 去/etc/netplan目录找到配置文件,配置文件名一般为01-network-manager-all.yaml sudo vim /etc/netplan/01-network-manager-all.yaml文件打开后内容如下 # This …...
15、matlab绘图汇总(图例、标题、坐标轴、线条格式、颜色和散点格式设置)
1、plot()函数默认格式画图 代码: x0:0.1:20;%绘图默认格式 ysin(x); plot(x,y) 2、X轴和Y轴显示范围/axis()函数 代码: x0:0.1:20;%绘图默认格式 ysin(x); plot(x,y) axis([0 21 -1.1 1.1])%设置范围 3、网格显示/grid on函数 代码: …...

调试环境搭建(Redis 6.X 版本)
今儿,我们来搭建一个 Redis 调试环境,目标是: 启动 Redis Server ,成功断点调试 Server 的启动过程。使用 redis-cli 启动一个 Client 连接上 Server,并使用 get key 指令,发起一次 key 的读取。 视频可见…...

postgres数据库报错无法写入文件 “base/pgsql_tmp/pgsql_tmp215574.97“: 设备上没有空间
解决思路: base/pgsql_tmp下临时表空间不够 需要新建一个临时表空间指定到根目录之外的其他目录 并且修改默认临时表空间参数 解决方法: select * from pg_settings where name temp_tablespaces;mkdir /home/postgres/tbs_tmp CREATE TABLESPACE tbs_t…...

力扣2762. 不间断子数组
力扣2762. 不间断子数组 multiset法 multiset:元素从小到大排序 begin()返回头指针 (最小)rbegin()返回尾指针 (最大) class Solution {public:long long continuousSubarrays(vector<int>& nums) {int n nums.size();long long res 0;multiset<…...

OpenCV学习(4.8) 图像金字塔
1.目的 在这一章当中, 我们将了解图像金字塔。我们将使用图像金字塔创建一个新的水果,“Orapple”我们将看到这些功能: cv.pyrUp() , cv.pyrDown() 在通常情况下我们使用大小恒定…...

【TB作品】msp430f5529单片机,dht22,温湿度传感器,OLED显示屏
使用DHT22温湿度传感器和OLED显示屏的单片机项目 博客名称 利用MSP430单片机读取DHT22并显示温湿度 作品功能 本项目利用MSP430单片机读取DHT22温湿度传感器的数据,并将温湿度信息显示在OLED显示屏上。通过这个项目,您可以学习如何使用单片机与传感器…...

Kotlin 异常处理
文章目录 什么是异常抛出异常通过异常信息解决异常捕获异常 什么是异常 我们在运行程序时,如果代码出现了语法问题或逻辑问题,会导致程序编译失败或退出,称为异常。运行结果会给出一个一长串的红色字,通常会给出异常信息…...

nltk下载报错
捣鼓voice_clone时报错: 报错信息: mport nltk nltk.download(‘cmudict’)For more information see: https://www.nltk.org/data.htmlAttempted to load tokenizers/punkt/PY3/english.pickleSearched in: - ‘/home/zhangshuai/nltk_data’ - ‘/hom…...

Vulnhub-DC5
靶机IP:192.168.20.139 kaliIP:192.168.20.128 网络有问题的可以看下搭建Vulnhub靶机网络问题(获取不到IP) 信息收集 nmap扫下端口及版本 dirsearch扫下目录 LinuxphpNginx 环境 我们再去看前端界面,发现在contact界面有能提交的地方,但是经过测试不…...

pytorch 笔记:pytorch 优化内容(更新中)
1 Tensor创建类 1.1 直接创建Tensor,而不是从Python或Numpy中转换 不要使用原生Python或NumPy创建数据,然后将其转换为torch.Tensor直接用torch.Tensor创建或者直接:torch.empty(), torch.zeros(), torch.full(), torch.ones(), torch.…...

vue 创建一个新项目 以及 手动配置选项
【Vue】3.0 项目创建 自定义配置_vue3.0-CSDN博客...

c#快速获取超大文件夹文件名
c#快速获取超大文件夹文件名 枚举集合速度快:(10万个文件) //by txwtech IEnumerable<string> files2 Directory.EnumerateFiles("d:\aa", "*.xml", SearchOption.TopDirectoryOnly);//过滤指定查询xml文件 慢: var fi…...

华为OD技术面试-最小异或-2024手撕代码真题
题目:最小异或 给你两个正整数 num1 和 num2 ,找出满足下述条件的正整数 x : x 的置位数和 num2 相同,且 x XOR num1 的值 最小 注意 XOR 是按位异或运算。 返回整数 x 。题目保证,对于生成的测试用例, x 是 唯一确定 的。 整数的 置位数 是其二进制表示中 1 的数目。 示…...

基于SpringBoot+Vue单位考勤系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝1W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还…...

Anaconda软件:安装、管理python相关包
Anaconda的作用 一个python环境中需要有一个解释器, 和一个包集合. 解释器: 根据python的版本大概分为2和3. python2和3之间无法互相兼容, 也就是说用python2语法写出来的脚本不一定能在python3的解释器中运行. 包集合:包含了自带的包和第三方包, 第三…...

pinia 重置状态插件
一、前言 测试提出,登出登录后,再次进入页面后。页面的查询项非初始状态。检查后发现,是因为查询项的值存到了store呢,从store中获取,故需要一个重置store的方法 二、pinia 查阅pinia官网后,发现pinia提…...
)
一千题,No.0049(跟奥巴马一起编程)
美国总统奥巴马不仅呼吁所有人都学习编程,甚至以身作则编写代码,成为美国历史上首位编写计算机代码的总统。2014 年底,为庆祝“计算机科学教育周”正式启动,奥巴马编写了很简单的计算机代码:在屏幕上画一个正方形。现在…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...
热烈祝贺埃文科技正式加入可信数据空间发展联盟
2025年4月29日,在福州举办的第八届数字中国建设峰会“可信数据空间分论坛”上,可信数据空间发展联盟正式宣告成立。国家数据局党组书记、局长刘烈宏出席并致辞,强调该联盟是推进全国一体化数据市场建设的关键抓手。 郑州埃文科技有限公司&am…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...