二叉树的实现(初阶数据结构)
1.二叉树的概念及结构
1.1 概念
一棵二叉树是结点的一个有限集合,该集合:
1.或者为空
2.由一个根结点加上两棵别称为左子树和右子树的二叉树组成
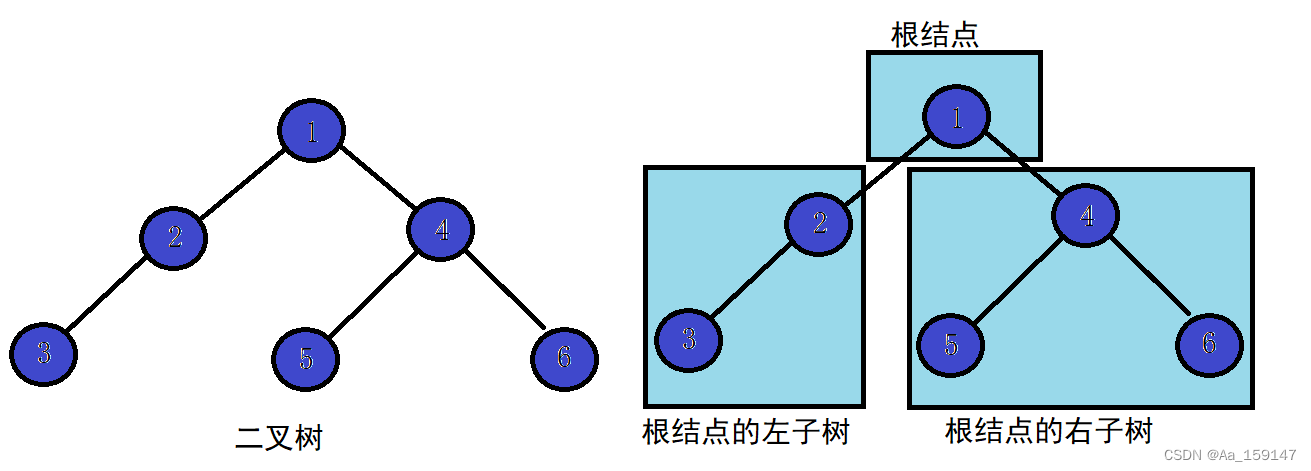
从上图可以看出:
1.二叉树不存在度大于2的结点
2.二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
1.2 特殊二叉树
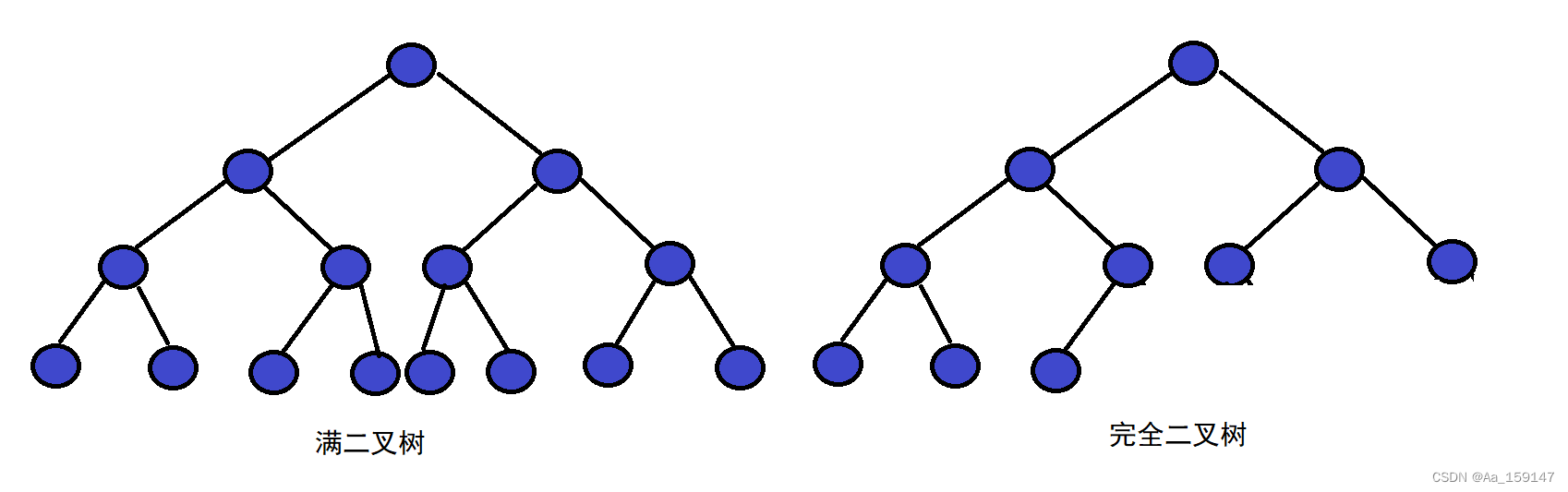
1.满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树,也就是说没如果一个二叉树的层数为K,且结点总数是2^k-1,则它就是满二叉树。
2.完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当每一个结点都与深度为K的满二叉树中编号从1至n的结点——对应时称之为完全二叉树,要注意的是满二叉树是一中特殊的完全二叉树。
1.3二叉树的性质
1.若规定根结点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1)个结点。
2.若规定根结点的层数为1,则深度为h的二叉树的最大结点数是2^h-1。
3.对任何一棵二叉树,如果度为0其叶子结点个数为a,度为2的分支个数为b,则有a=b+1。
4.若规定根结点的层数为1,具有n个结点的满二叉树的深度,h=log2(n+1).(ps:以2为底,n+1为对数)
5.对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从0开始编号,则对于序号为i的结点有:
1.若i>0,i的位置结点的双亲序号:(i-1)/2;i=0,i为根结点编号,无双亲结点
2.2i+1<n,左孩子序号:2i+1,2i+1>=n否则无左孩子
3.2i+2<n,右孩子序号:2i+2,2i+2>=n否则无右孩子
1.4二叉树的存储结构
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
1.顺序存储
顺序结构村塾就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费,而现实中使用只有堆才会使用数组来存储,二叉树顺序存储在物理上是一个数组,在逻辑上是一棵二叉树。

2.链式存储
二叉树的链式存储结构是指用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址。链式结构又分为二叉链和三叉链。
2.二叉树的实现
#pragma once#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef char BTDataType;typedef struct BinaryTreeNode
{BTDataType _data;struct BinaryTreeNode* _left;struct BinaryTreeNode* _right;
}BTNode;// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi);
// 二叉树销毁
void BinaryTreeDestory(BTNode** root);
// 二叉树节点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root);
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root);
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root);
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root);
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root);
//二叉树的高度
int TreeHigh(BTNode* root);2.1创建新的结点
调用函数BuyNode来创建新的结点
BTNode* BuyNode(BTDataType x)
{BTNode* node = (BTNode*)malloc(sizeof(BTNode));if (node == NULL){perror("malloc fail");return NULL;}node->_data = x;node->_left = NULL;node->_right = NULL;return node;
}2.2通过前序遍历数组来构建二叉树
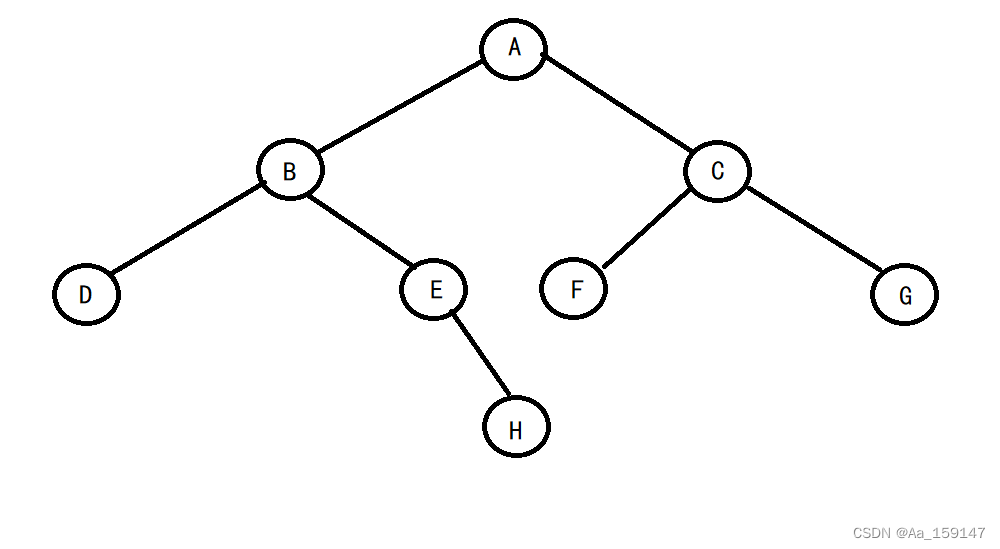
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
//a为我们所要遍历的数组
//n是最大数组的长度
//pi是我们用来遍历数组的指针
//当遍历是遇到‘#’或者指针超出了数组的范围就返回NULL
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi)
{if (a[*pi] == '#' || *pi >= n){printf("NULL ");(*pi)++;return NULL;}//创建一个新的二叉树的节点BTNode* dst = BuyNode(a[*pi]); printf("%c ", dst->_data);(*pi)++;dst->_left = BinaryTreeCreate(a, n, pi);dst->_right = BinaryTreeCreate(a, n, pi);return dst;
}
构建出来的二叉树如下:
2.3二叉树的销毁
实现二叉树的销毁时,我们要正确选择以哪种遍历的方式,这里使用后序遍历,从底层叶子层开始,先释放左子树和右子树的空间,再释放根结点的空间,如果先对根结点释放,就找不到它所对应的左子树和右子树了。
//二叉树的销毁
void BinaryTreeDestory(BTNode** root)
{if (*root == NULL){return;}BinaryTreeDestory(&((*root)->_left));BinaryTreeDestory(&((*root)->_right));free(*root);*root = NULL;return;}2.4计算二叉树的结点个数
这里我罗列了两种方法:
一种是用一个静态变量通过size++的形式来计算结点的个数(局部的静态变量只能初始化一次)
另一种是递归遍历二叉树通过放回: 左子树+右子树+1
int BinaryTreeSize(BTNode* root)
{//方法一://用静态变量(在堆上,不在栈上)改变局部变量 -> 使得递归的size可以累加起来,但是局部的静态只能初始化一次/*static int size = 0;if (root == NULL){return 0;}else++size;BinaryTreeSize(root->_left);BinaryTreeSize(root->_right);*///方法二://如果我们当前的节点为空,也就是说我们已经到了叶子节点的左右节点,也就是没有节点//所以我们需要返回0if (root == NULL){return 0;}//如果我们当前的节点的左指针和右指针都是空的话,也就是说这是我们的叶子节点//就返回1,也就是只有一个节点if (root->_left == NULL && root->_right == NULL){return 1;}//使用递归遍历我们的二叉树,即分别统计我们左子树的节点个数再加上右子树中的节点个数再加上1//因为我们需要将我们当前所指的节点算上return BinaryTreeSize(root->_left) + BinaryTreeSize(root->_right) + 1;}2.5计算二叉树叶子结点的个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}//如果我们的节点的左右指针全部都为空,那就是我们的叶子节点if (root->_left == NULL && root->_right == NULL){return 1;}//返回我们左子树中的叶子节点和右子树中的叶子节点之和return BinaryTreeLeafSize(root->_left) + BinaryTreeLeafSize(root->_right);
}2.6二叉树第k层的结点个数
二叉树第一层结点个数为1,第k层结点是第一层结点往下找k-1层,第二层的结点往下找k-2层,当k为1的时候返回的结果就是找的k层的结点的个数的总和。
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}//分别遍历我们的左右子树,并且将我们的k的参数--,当我们的k为1时,就到达了我们所想要查找对应的层return BinaryTreeLevelKSize(root->_left, k - 1) + BinaryTreeLevelKSize(root->_right, k - 1);
}2.7查找值为x的结点
查找第一个指定值为x的结点,同过前序遍历的方法来寻找第一个值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return NULL;}if (root->_data == x){return root;}BTNode* ret1 = BinaryTreeFind(root->_left, x);if (ret1){return ret1;}/*BTNode* ret2 = BinaryTreeFind(root->_right, x);if (ret2){return ret2;}return NULL;*/return BinaryTreeFind(root->_right, x);
}
2.8二叉树前序遍历
前序遍历的顺序是根 - 左子树 - 右子树
void BinaryTreePrevOrder(BTNode* root)
{if (root == NULL){return;}printf("%c ", root->_data);BinaryTreePrevOrder(root->_left);BinaryTreePrevOrder(root->_right);}2.9二叉树中序遍历
中序遍历的顺序是左子树 - 根 - 右子树
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreeInOrder(root->_left);printf("%c ", root->_data);BinaryTreeInOrder(root->_right);}2.10二叉树后序遍历
后序遍历的顺序是左子树 - 右子树 - 根
void BinaryTreePostOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreePostOrder(root->_left);BinaryTreePostOrder(root->_right);printf("%c ", root->_data);}
2.11二叉树层序遍历
需要使用一个队列实现层序遍历,先将指向根结点的指针入队,当根结点出队列的时候,将它的左右子树的结点的指针入队,就达到了层层遍历的效果
void BinaryTreeLevelOrder(BTNode* root)
{Queue q;QueueInit(&q);if (root){QueuePush(&q, root);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);printf("%c ", front->_data);if (front->_left)QueuePush(&q, front->_left);if (front->_right)QueuePush(&q, front->_right);}QueueDestroy(&q);
}2.12判断二叉树是否为完全二叉树
思路是通过层序遍历的方法,二叉树的叶子结点的下一层节点全部都是NULL,那么在根出队列,左右子树进队列的情况下:
当出队列出到空的时候,判断队列里面的结点是否有非空结点,如果有则证明不是完全二叉树,
反之队列里面都是空结点,则是完全二叉树。
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);if (root){QueuePush(&q, root);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);//遇到第一个空,就可以开始判断,如果队列中还有非空,就不是完全二叉树if (front == NULL){break; }QueuePush(&q, front->_left);QueuePush(&q, front->_right);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);//如果有非空,就不是完全二叉树if (front){QueueDestroy(&q);printf("不是完全二叉树\n");return 0;}}QueueDestroy(&q);printf("是完全二叉树\n");return 1;
}2.13求二叉树的高度
int TreeHigh(BTNode* root)
{if (root == NULL){return 0;}int lefthigh = TreeHigh(root->_left);int righthigh = TreeHigh(root->_right);return lefthigh > righthigh ? lefthigh + 1 : righthigh + 1;//return TreeHigh(root->_left) > TreeHigh(root->_right) ? TreeHigh(root->_left) + 1 : TreeHigh(root->_right) + 1;
}3.二叉树总代码
3.1 Tree.h
#pragma once#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>
typedef char BTDataType;typedef struct BinaryTreeNode
{BTDataType _data;struct BinaryTreeNode* _left;struct BinaryTreeNode* _right;
}BTNode;// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi);
// 二叉树销毁
void BinaryTreeDestory(BTNode** root);
// 二叉树节点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root);
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root);
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root);
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root);
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root);
//二叉树的高度
int TreeHigh(BTNode* root);3.2 Tree.c
#define _CRT_SECURE_NO_WARNINGS 1#include"Tree.h"
#include"Queue.h"BTNode* BuyNode(BTDataType x)
{BTNode* node = (BTNode*)malloc(sizeof(BTNode));if (node == NULL){perror("malloc fail");return NULL;}node->_data = x;node->_left = NULL;node->_right = NULL;return node;
}// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi)
{//这里我们的a为我们的数组//n为我们数组的最大长度//pi为我们遍历数组的指针//这里我们使用'#'来表示NULL//当我们所指向的位置的元素为#或者我们的指针已经超过了数组的范围的时候,我们就需要返回NULL//并且将我们的指针后移if (a[*pi] == '#' || *pi >= n){printf("NULL ");(*pi)++;return NULL;}//创建一个新的二叉树的节点BTNode* dst = BuyNode(a[*pi]); printf("%c ", dst->_data);(*pi)++;//将我们之前开创的节点的左右指针指向数组中所对应的节点//如果我们的对应数组中的数据不为空的话,我们的左右指针都会指向新的对应的节点//如果我们的节点为空的话,我们会得到的返回值为NULLdst->_left = BinaryTreeCreate(a, n, pi);dst->_right = BinaryTreeCreate(a, n, pi);return dst;
}//二叉树的销毁
void BinaryTreeDestory(BTNode** root)
{if (*root == NULL){return;}BinaryTreeDestory(&((*root)->_left));BinaryTreeDestory(&((*root)->_right));free(*root);*root = NULL;return;}//计算二叉树的节点个数int BinaryTreeSize(BTNode* root)
{//用静态变量(在堆上,不在栈上)改变局部变量 -> 使得递归的size可以累加起来,但是局部的静态只能初始化一次/*static int size = 0;if (root == NULL){return 0;}else++size;BinaryTreeSize(root->_left);BinaryTreeSize(root->_right);*///如果我们当前的节点为空,也就是说我们已经到了叶子节点的左右节点,也就是没有节点//所以我们需要返回0if (root == NULL){return 0;}//如果我们当前的节点的左指针和右指针都是空的话,也就是说这是我们的叶子节点//就返回1,也就是只有一个节点if (root->_left == NULL && root->_right == NULL){return 1;}//使用递归遍历我们的二叉树,即分别统计我们左子树的节点个数再加上右子树中的节点个数再加上1//因为我们需要将我们当前所指的节点算上return BinaryTreeSize(root->_left) + BinaryTreeSize(root->_right) + 1;}//统计二叉树叶子节点的个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}//如果我们的节点的左右指针全部都为空,那就是我们的叶子节点if (root->_left == NULL && root->_right == NULL){return 1;}//返回我们左子树中的叶子节点和右子树中的叶子节点之和return BinaryTreeLeafSize(root->_left) + BinaryTreeLeafSize(root->_right);
}// 二叉树第k层节点个数int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}//分别遍历我们的左右子树,并且将我们的k的参数--,当我们的k为1时,就到达了我们所想要查找对应的层return BinaryTreeLevelKSize(root->_left, k - 1) + BinaryTreeLevelKSize(root->_right, k - 1);
}// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL){return NULL;}if (root->_data == x){return root;}BTNode* ret1 = BinaryTreeFind(root->_left, x);if (ret1){return ret1;}/*BTNode* ret2 = BinaryTreeFind(root->_right, x);if (ret2){return ret2;}return NULL;*/return BinaryTreeFind(root->_right, x);
}// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root)
{if (root == NULL){return;}printf("%c ", root->_data);BinaryTreePrevOrder(root->_left);BinaryTreePrevOrder(root->_right);}// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreeInOrder(root->_left);printf("%c ", root->_data);BinaryTreeInOrder(root->_right);}// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreePostOrder(root->_left);BinaryTreePostOrder(root->_right);printf("%c ", root->_data);}// 层序遍历
void BinaryTreeLevelOrder(BTNode* root)
{Queue q;QueueInit(&q);if (root){QueuePush(&q, root);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);printf("%c ", front->_data);if (front->_left)QueuePush(&q, front->_left);if (front->_right)QueuePush(&q, front->_right);}QueueDestroy(&q);
}// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);if (root){QueuePush(&q, root);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);//遇到第一个空,就可以开始判断,如果队列中还有非空,就不是完全二叉树if (front == NULL){break; }QueuePush(&q, front->_left);QueuePush(&q, front->_right);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);//如果有非空,就不是完全二叉树if (front){QueueDestroy(&q);printf("不是完全二叉树\n");return 0;}}QueueDestroy(&q);printf("是完全二叉树\n");return 1;
}int TreeHigh(BTNode* root)
{if (root == NULL){return 0;}int lefthigh = TreeHigh(root->_left);int righthigh = TreeHigh(root->_right);return lefthigh > righthigh ? lefthigh + 1 : righthigh + 1;//return TreeHigh(root->_left) > TreeHigh(root->_right) ? TreeHigh(root->_left) + 1 : TreeHigh(root->_right) + 1;
}3.3 Queue.h
#pragma once#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <assert.h>typedef struct BinaryTreeNode* QDataType;typedef struct QueueNode
{struct QueueNode* next;QDataType val;
}QNode;typedef struct Queue
{QNode* phead;QNode* ptail;int size;
}Queue;void QueueInit(Queue* pq);
void QueueDestroy(Queue* pq);
//队尾插入
void QueuePush(Queue* pq, QDataType x);//队头删除
void QueuePop(Queue* pq);//队头和队尾的数据
QDataType QueueFront(Queue* pq);
QDataType QueueBack(Queue* pq);bool QueueEmpty(Queue* pq);
int QueueSize(Queue* pq);
3.4 Queue.c
#define _CRT_SECURE_NO_WARNINGS 1#include"Queue.h"void QueueInit(Queue* pq)
{assert(pq);pq->phead = NULL;pq->ptail = NULL;pq->size = 0;
}
void QueueDestroy(Queue* pq)
{assert(pq);QNode* cur = pq->phead;while (cur){QNode* next = cur->next;free(cur);cur = next;}pq->phead = pq->ptail = NULL;pq->size = 0;
}//队尾插入
void QueuePush(Queue* pq, QDataType x)
{assert(pq);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail");return;}newnode->next = NULL;newnode->val = x;if (pq->ptail == NULL){pq->phead = pq->ptail = newnode;}else{pq->ptail->next = newnode;pq->ptail = newnode;}pq->size++;
}int QueueSize(Queue* pq)
{assert(pq);return pq->size;
}//队头删除
void QueuePop(Queue* pq)
{assert(pq);assert(QueueSize(pq) != 0);//一个节点if (pq->phead == pq->ptail){free(pq->phead);pq->phead = pq->ptail = NULL;}//多个节点else{QNode* next = pq->phead->next;free(pq->phead);pq->phead = next;}pq->size--;
}QDataType QueueFront(Queue* pq)
{assert(pq);assert(pq->phead);return pq->phead->val;
}QDataType QueueBack(Queue* pq)
{assert(pq);assert(pq->ptail);return pq->ptail->val;
}bool QueueEmpty(Queue* pq)
{assert(pq);return pq->size == 0;
}3.5 Test.c
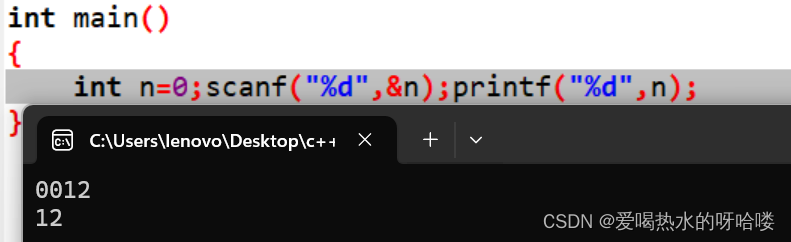
#define _CRT_SECURE_NO_WARNINGS 1#include "Tree.h"int main()
{char a[] = { 'A','B','D','#','#','E','#','H','#','#','C','F','#','#','G','#','#' };int b = 0;int* pi = &b;BTNode* Btree = BinaryTreeCreate(a, 16, pi);printf("\n");//前序遍历BinaryTreePrevOrder(Btree);printf("\n");//中序遍历BinaryTreeInOrder(Btree);printf("\n");//后序遍历BinaryTreePostOrder(Btree);printf("\n");//层次遍历BinaryTreeLevelOrder(Btree);printf("\n");int number = BinaryTreeSize(Btree);printf("%d", number);printf("\n");//查找为x的节点BTNode* find = BinaryTreeFind(Btree, 'A');printf("%c", find->_data);printf("\n");//查询第K层的节点个数int W = BinaryTreeLevelKSize(Btree, 3);printf("%d\n", W);//查询叶子节点的个数int count = BinaryTreeLeafSize(Btree);printf("%d\n", count);//判断当前是否为一颗完全二叉树int ret = BinaryTreeComplete(Btree);int x = TreeHigh(Btree);printf("%d\n", x);BinaryTreeDestory(&Btree);return 0;
}相关文章:
二叉树的实现(初阶数据结构)
1.二叉树的概念及结构 1.1 概念 一棵二叉树是结点的一个有限集合,该集合: 1.或者为空 2.由一个根结点加上两棵别称为左子树和右子树的二叉树组成 从上图可以看出: 1.二叉树不存在度大于2的结点 2.二叉树的子树有左右之分,次序不能…...
C++笔试强训day41
目录 1.棋子翻转 2.宵暗的妖怪 3.过桥 1.棋子翻转 链接https://www.nowcoder.com/practice/a8c89dc768c84ec29cbf9ca065e3f6b4?tpId128&tqId33769&ru/exam/oj (简单题)对题意进行简单模拟即可: class Solution { public:int dx[…...
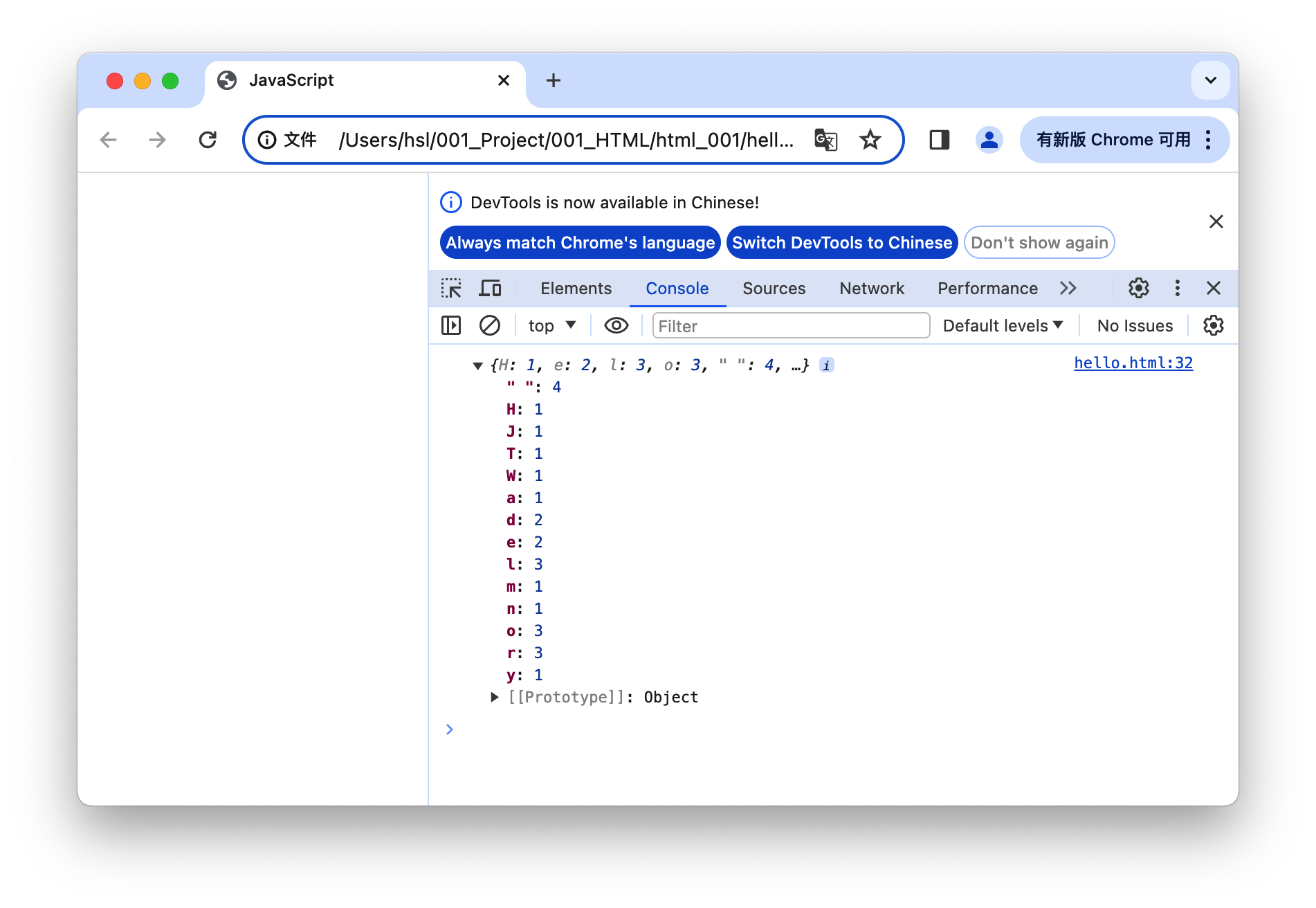
【JavaScript】内置对象 - 字符串对象 ⑤ ( 判断对象中是否有某个属性 | 统计字符串中每个字符出现的次数 )
文章目录 一、判断对象中是否有某个属性1、获取对象属性2、判定对象是否有某个属性 二、统计字符串中每个字符出现的次数1、算法分析2、代码示例 String 字符串对象参考文档 : https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String 一、判…...

Linux环境下测试服务器的DDR5内存性能
要在Linux环境下测试服务器的DDR5内存性能,可以采用以下几种方法和工具: ### 测试原理 内存性能测试主要关注以下几个关键指标: - **带宽**:内存每秒能传输的数据量。 - **延迟**:内存访问请求从发出到完成所需的时间…...

19、matlab信号预处理中的中值滤波(medfilt1()函数)和萨维茨基-戈雷滤波滤(sgolayfilt()函数)
1、中值滤波:medfilt1()函数 说明:一维中值滤波 1)语法 语法1:y medfilt1(x) 将输入向量x应用3阶一维中值滤波器。 语法2:y medfilt1(x,n) 将一个n阶一维中值滤波器应用于x。 语法3:y medfilt1(x,n…...
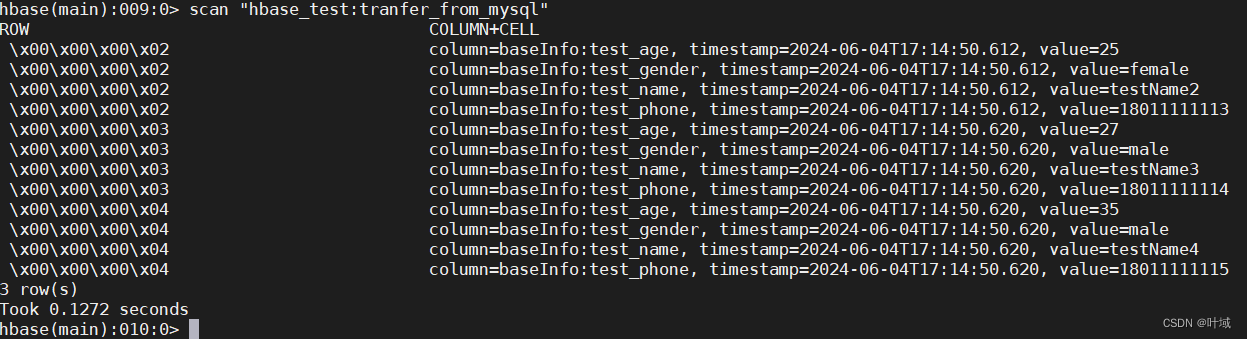
Scala 练习一 将Mysql表数据导入HBase
Scala 练习一 将Mysql表数据导入HBase 续第一篇:Java代码将Mysql表数据导入HBase表 源码仓库地址:https://gitee.com/leaf-domain/data-to-hbase 一、整体介绍二、依赖三、测试结果四、源码 一、整体介绍 HBase特质 连接HBase, 创建HBase执行对象 初始化…...

前端工程化:基于Vue.js 3.0的设计与实践
这里写目录标题 《前端工程化:基于Vue.js 3.0的设计与实践》书籍引言本书概述主要内容作者简介为什么选择这本书?结语 《前端工程化:基于Vue.js 3.0的设计与实践》书籍 够买连接—>https://item.jd.com/13952512.html 引言 在前端技术日…...
Linux☞进程控制
在终端执行命令时,Linux会建立进程,程序执行完,进程会被终止;Linux是一个多任务的OS,允许多个进程并发运行; Linxu中启动进程的两种途径: ①手动启动(前台进程(命令gedit)...后台进程(命令‘&’)) ②…...

mybatis离谱bug乱转类型
字符串传入的参数被转成了int: Param("online") String online<if test"online 0">and (heart_time is null or heart_time <![CDATA[ < ]]> UNIX_TIMESTAMP(SUBDATE(now(),INTERVAL 8 MINUTE)) )</if><if test"…...

视频监控管理平台LntonCVS视频汇聚平台充电桩视频监控应用方案
随着新能源汽车的广泛使用,公众对充电设施的安全性和可靠性日益重视。为了提高充电桩的安全管理和站点运营效率,LntonCVS公司推出了一套全面的新能源汽车充电桩视频监控与管理解决方案。 该方案通过安装高分辨率摄像头,对充电桩及其周边区域进…...

VS环境Python:深度探索与实用指南
VS环境Python:深度探索与实用指南 在编程领域,VS环境(Visual Studio环境)与Python的结合,为开发者们提供了一种强大而灵活的开发体验。这种结合不仅提升了开发效率,还增强了代码的可读性和可维护性。然而&…...
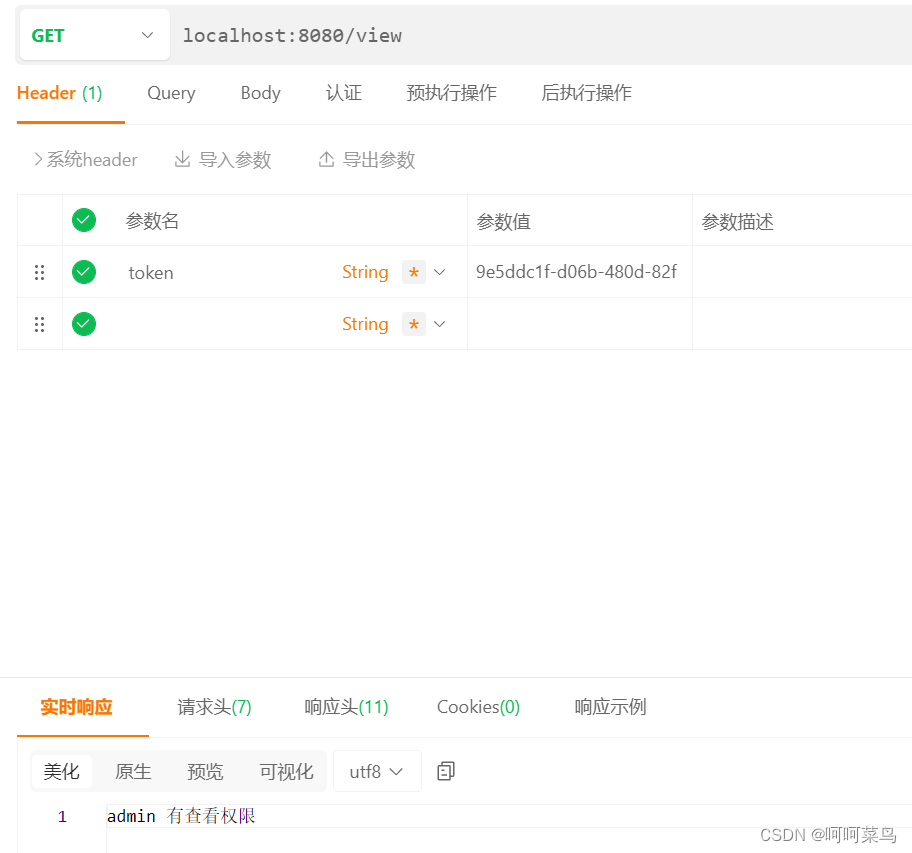
SpringBoot整合SpringSecurit(二)通过token进行访问
在文章:SpringBoot整合SpringSecurit(一)实现ajax的登录、退出、权限校验-CSDN博客 里面,使用的session的方式进行保存用户信息的,这一篇文章就是使用token的方式。 在其上进行的改造,可以先看SpringBoot…...

【算法训练 day50 打家劫舍、打家劫舍Ⅱ、打家劫舍Ⅲ】
目录 一、打家劫舍-LeetCode 198思路 二、打家劫舍Ⅱ-LeetCode 213思路 三.打家劫舍Ⅲ-LeeCode 337思路 一、打家劫舍-LeetCode 198 Leecode链接: leetcode 198 思路 dp数组含义为:当前数组范围下能偷到的最多的钱。递推公式为:dp[j] max(dp[j-2]nums[j],dp[j-1…...

YOLOv8改进 | 卷积模块 | 在主干网络中添加/替换蛇形卷积Dynamic Snake Convolution
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 蛇形动态卷积是一种新型的卷积操作,旨在提高对细长和弯曲的管状结构的特征提取能力。它通过自适应地调整卷积核的权重࿰…...
)
深入解析力扣183题:从不订购的客户(LEFT JOIN与子查询方法详解)
关注微信公众号 数据分析螺丝钉 免费领取价值万元的python/java/商业分析/数据结构与算法学习资料 在本篇文章中,我们将详细解读力扣第183题“从不订购的客户”。通过学习本篇文章,读者将掌握如何使用SQL语句来解决这一问题,并了解相关的复杂…...

牛客NC32 求平方根【简单 二分 Java/Go/C++】
题目 题目链接: https://www.nowcoder.com/practice/09fbfb16140b40499951f55113f2166c 思路 Java代码 import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可*** para…...

王道408数据结构CH3_栈、队列
概述 3.栈、队列和数组 3.1 栈 3.1.1 基本操作 3.1.2 顺序栈 #define Maxsize 50typedef struct{ElemType data[Maxsize];int top; }SqStack;3.1.3 链式栈 typedef struct LinkNode{ElemType data;struct LinkNode *next; }*LiStack;3.2 队列 3.2.1 基本操作 3.2.2 顺序存储…...

Angular 由一个bug说起之六:字体预加载
浏览器在加载一个页面时,会解析网页中的html和css,并开始加载字体文件。字体文件可以通过css中的font-face规则指定,并使用url()函数指定字体文件的路径。 比如下面这样: css font-face {font-family: MyFont;src: url(path/to/font.woff2…...

并查集进阶版
过关代码如下 #define _CRT_SECURE_NO_WARNINGS #include<bits/stdc.h> #include<unordered_set> using namespace std;int n, m; vector<int> edg[400005]; int a[400005], be[400005]; // a的作用就是存放要摧毁 int k; int fa[400005]; int daan[400005]…...
贪心(不相交的开区间、区间选点、带前导的拼接最小数问题)
目录 1.简单贪心 2.区间贪心 不相交的开区间 1.如何删除? 2.如何比较大小 区间选点问题 3.拼接最小数 1.简单贪心 比如:给你一堆数,你来构成最大的几位数 2.区间贪心 不相交的开区间 思路: 首先,如果有两个…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...