Java实现简单词法、语法分析器
1、词法分析器实现
词法分析器是编译器中的一个关键组件,用于将源代码解析成词法单元。
-
词法分析器的结构与组件:
- 通常,词法分析器由两个主要组件构成:扫描器(Scanner)和记号流(Token Stream)。
- 扫描器负责从源代码中读取字符流,并按照预定义的词法规则将字符流解析为词法单元。
- 扫描器通常由一个有限自动机实现,用于根据词法规则进行状态转换,识别出不同的词法单元。
-
有限自动机的代码实现:
- 有限自动机是实现词法分析器的关键技术之一。它根据输入的字符进行状态转换,并输出识别的词法单元。
- 以下是一个用Python实现的简单有限自动机示例:
# 定义有限自动机的状态 def isAlpha(ch):return ch.isalpha()def isDigit(ch):return ch.isdigit()def scan(attr, i, s, n):# 核心子程序(语法分析程序)# 实现词法分析逻辑,根据字符流识别词法单元# ...pass
-
错误处理与诊断:
- 在词法分析过程中,可能会遇到无法识别的字符或不符合词法规则的输入。
- 词法分析器通常需要进行错误处理与诊断,例如跳过无法识别的字符、发出错误提示或错误修复。
import java.io.*;
import java.util.*;/*** 词法分析器实现*/
public class LexicalAnalyzer {private static final Map<String, String> word = new HashMap<>();private static final List<Node> aa = new ArrayList<>();static class Node {String id;String s;Node(String id, String s) {this.id = id;this.s = s;}}public static void mapInit() {word.put("main", "0");word.put("return", "3");word.put("if", "4");word.put("else", "5");word.put("int", "6");word.put("char", "7");word.put("(", "8");word.put(")", "9");word.put("{", "10");word.put("}", "11");word.put(",", "12");word.put(";", "13");word.put("=", "14");word.put("!=", "15");word.put(">", "16");word.put("<", "17");word.put(">=", "18");word.put("<=", "19");word.put("==", "20");word.put("+", "21");word.put("*", "22");word.put("/", "23");}public static void main(String[] args) {mapInit();char ch;int len = 0;StringBuilder word1;String str;System.out.println("-----------------词法分析器-----------------");Scanner scanner = new Scanner(System.in);System.out.println("请输入源文件地址:(路径中请不要包含中文)");String dir = scanner.nextLine();System.out.println("请输入目标文件地址:");String targetDir = scanner.nextLine();try (BufferedReader infile = new BufferedReader(new FileReader(dir));BufferedWriter outfile = new BufferedWriter(new FileWriter(targetDir))) {StringBuilder buf = new StringBuilder();while ((ch = (char) infile.read()) != (char) -1) {buf.append(ch);}str = buf.toString();int csize = str.length();for (int i = 0; i < csize; i++) {while (str.charAt(i) == ' ' || str.charAt(i) == '\n') i++;if (Character.isAlphabetic(str.charAt(i))) {word1 = new StringBuilder(String.valueOf(str.charAt(i++)));while (Character.isAlphabetic(str.charAt(i)) || Character.isDigit(str.charAt(i))) {word1.append(str.charAt(i++));}if (word.containsKey(word1.toString())) {System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else {System.out.println("(1," + word1 + ")");aa.add(new Node("1", word1.toString()));}i--;} else if (Character.isDigit(str.charAt(i))) {word1 = new StringBuilder(String.valueOf(str.charAt(i++)));while (Character.isDigit(str.charAt(i))) {word1.append(str.charAt(i++));}if (Character.isAlphabetic(str.charAt(i))) {System.out.println("error1!");break;} else {System.out.println("(2," + word1 + ")");aa.add(new Node("2", word1.toString()));}i--;} else if (str.charAt(i) == '<') {word1 = new StringBuilder(String.valueOf(str.charAt(i++)));if (str.charAt(i) == '>') {word1.append(str.charAt(i));System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else if (str.charAt(i) == '=') {word1.append(str.charAt(i));System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else if (str.charAt(i) != ' ' || !Character.isDigit(str.charAt(i)) || !Character.isAlphabetic(str.charAt(i))) {System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else {System.out.println("error2!");break;}i--;} else if (str.charAt(i) == '>') {word1 = new StringBuilder(String.valueOf(str.charAt(i++)));if (str.charAt(i) == '=') {word1.append(str.charAt(i));System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else if (str.charAt(i) != ' ' || !Character.isDigit(str.charAt(i)) || !Character.isAlphabetic(str.charAt(i))) {System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else {System.out.println("error3!");break;}i--;} else if (str.charAt(i) == ':') {word1 = new StringBuilder(String.valueOf(str.charAt(i++)));if (str.charAt(i) == '=') {word1.append(str.charAt(i));System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else if (str.charAt(i) != ' ' || !Character.isDigit(str.charAt(i)) || !Character.isAlphabetic(str.charAt(i))) {System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));} else {System.out.println("error4!");break;}i--;} else {word1 = new StringBuilder(String.valueOf(str.charAt(i)));if (word.containsKey(word1.toString())) {System.out.println("(" + word.get(word1.toString()) + "," + word1 + ")");aa.add(new Node(word.get(word1.toString()), word1.toString()));}}}for (Node node : aa) {outfile.write("(" + node.id + "," + node.s + ")\n");}} catch (IOException e) {e.printStackTrace();}System.out.println("输入任意键关闭");scanner.nextLine();}
}
2、语法分析器实现
语法分析器是编译器中的关键组件,用于检查源代码是否遵循编程语言的语法规则。
-
语法分析器的结构与组件:
- 自顶向下语法分析器从文法的开始符号出发,试图推导出与输入单词串相匹配的句子。
- 通常,自顶向下语法分析器由递归下降分析器构成,它根据预定义的文法规则逐步构建语法树。
- 语法树表示源代码的层次结构,其中每个节点对应一个语法规则或终结符。
-
递归下降分析器的代码实现:
- 递归下降分析器是自顶向下语法分析的一种常见方法。
- 以下是一个简单的递归下降分析器示例(使用Python):
# 定义文法规则 def expr():term()while lookahead == '+':match('+')term()def term():factor()while lookahead == '*':match('*')factor()def factor():if lookahead.isdigit():match(lookahead)elif lookahead == '(':match('(')expr()match(')')# 初始化 lookahead = input() # 输入的单词串# 匹配函数 def match(expected):if lookahead == expected:lookahead = input()else:raise SyntaxError("Unexpected token: " + lookahead)# 开始分析 expr()
-
错误处理与诊断:
- 语法分析过程中,可能会遇到不符合文法规则的输入。
- 递归下降分析器通常需要进行错误处理与诊断,例如报告无法识别的符号或缺失的符号。
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.Queue;
import java.util.Scanner;
import java.util.Set;
import java.util.Stack;/*** 语法分析器实现*/
public class Parser {public static final String PATH = "C:\\code\\idea\\CompilePrinciple\\src\\grammar.txt";private static String START;private static HashSet<String> VN, VT;private static HashMap<String, ArrayList<ArrayList<String>>> MAP;private static HashMap<String, String> oneLeftFirst;private static HashMap<String, HashSet<String>> FIRST, FOLLOW;private static HashMap<String, String> preMap;public static void main(String[] args) {init();identifyVnVt(readFile(new File(PATH)));reformMap();findFirst();findFollow();if (isLL1()) {preForm();System.out.println("请输入要分析的单词串:");Scanner in = new Scanner(System.in);printAutoPre(in.nextLine());in.close();}}// 变量初始化private static void init() {VN = new HashSet<>();VT = new HashSet<>();MAP = new HashMap<>();FIRST = new HashMap<>();FOLLOW = new HashMap<>();oneLeftFirst = new HashMap<>();preMap = new HashMap<>();}// 判断是否是LL(1)文法private static boolean isLL1() {System.out.println("\n正在判断是否是LL(1)文法....");boolean flag = true;for (String key : VN) {ArrayList<ArrayList<String>> list = MAP.get(key);if (list.size() > 1)for (int i = 0; i < list.size(); i++) {String aLeft = String.join("", list.get(i).toArray(new String[0]));for (int j = i + 1; j < list.size(); j++) {String bLeft = String.join("", list.get(j).toArray(new String[0]));if (aLeft.equals("ε") || bLeft.equals("ε")) {HashSet<String> retainSet = new HashSet<>(FIRST.get(key));if (FOLLOW.get(key) != null)retainSet.retainAll(FOLLOW.get(key));if (!retainSet.isEmpty()) {flag = false;System.out.println("\tFIRST(" + key + ") ∩ FOLLOW(" + key + ") = {"+ String.join("、", retainSet.toArray(new String[0])) + "}");break;} else {System.out.println("\tFIRST(" + key + ") ∩ FOLLOW(" + key + ") = φ");}} else {HashSet<String> retainSet = new HashSet<>(FIRST.get(key + "→" + aLeft));retainSet.retainAll(FIRST.get(key + "→" + bLeft));if (!retainSet.isEmpty()) {flag = false;System.out.println("\tFIRST(" + aLeft + ") ∩ FIRST(" + bLeft + ") = {"+ String.join("、", retainSet.toArray(new String[0])) + "}");break;} else {System.out.println("\tFIRST(" + aLeft + ") ∩ FIRST(" + bLeft + ") = φ");}}}}}if (flag)System.out.println("\t是LL(1)文法,继续分析!");elseSystem.out.println("\t不是LL(1)文法,退出分析!");return flag;}// 构建预测分析表FORMprivate static void preForm() {HashSet<String> set = new HashSet<>(VT);set.remove("ε");String[][] FORM = new String[VN.size() + 1][set.size() + 2];Iterator<String> itVn = VN.iterator();Iterator<String> itVt = set.iterator();for (int i = 0; i < FORM.length; i++)for (int j = 0; j < FORM[0].length; j++) {if (i == 0 && j > 0) {if (itVt.hasNext()) {FORM[i][j] = itVt.next();}if (j == FORM[0].length - 1)FORM[i][j] = "#";}if (j == 0 && i > 0) {if (itVn.hasNext())FORM[i][j] = itVn.next();}if (i > 0 && j > 0) {String oneLeftKey = FORM[i][0] + "$" + FORM[0][j];FORM[i][j] = oneLeftFirst.get(oneLeftKey);}}for (int i = 1; i < FORM.length; i++) {String oneLeftKey = FORM[i][0] + "$ε";if (oneLeftFirst.containsKey(oneLeftKey)) {HashSet<String> followCell = FOLLOW.get(FORM[i][0]);for (String vt : followCell) {for (int j = 1; j < FORM.length; j++)for (int k = 1; k < FORM[0].length; k++) {if (FORM[j][0].equals(FORM[i][0]) && FORM[0][k].equals(vt))FORM[j][k] = oneLeftFirst.get(oneLeftKey);}}}}// 打印预测表,并存于Map的数据结构中用于快速查找System.out.println("\n该文法的预测分析表为:");for (int i = 0; i < FORM.length; i++) {for (int j = 0; j < FORM[0].length; j++) {if (FORM[i][j] == null)System.out.print(" " + "\t");else {System.out.print(FORM[i][j] + "\t");if (i > 0 && j > 0) {String[] tmp = FORM[i][j].split("→");preMap.put(FORM[i][0] + FORM[0][j], tmp[1]);}}}System.out.println();}System.out.println();}// 输入的单词串分析推导过程public static void printAutoPre(String str) {System.out.println(str + "的分析过程:");Queue<String> queue = new LinkedList<>();for (int i = 0; i < str.length(); i++) {String t = str.charAt(i) + "";if (i + 1 < str.length() && (str.charAt(i + 1) == '\'' || str.charAt(i + 1) == '’')) {t += str.charAt(i + 1);i++;}queue.offer(t);}queue.offer("#");Stack<String> stack = new Stack<>();stack.push("#");stack.push(START);boolean isSuccess = false;int step = 1;while (!stack.isEmpty()) {String left = stack.peek();String right = queue.peek();if (left.equals(right) && right.equals("#")) {isSuccess = true;System.out.println((step++) + "\t#\t#\t" + "分析成功");break;}if (left.equals(right)) {String stackStr = String.join("", stack.toArray(new String[0]));String queueStr = String.join("", queue.toArray(new String[0]));System.out.println((step++) + "\t" + stackStr + "\t" + queueStr + "\t匹配成功" + left);stack.pop();queue.poll();continue;}if (preMap.containsKey(left + right)) {String stackStr = String.join("", stack.toArray(new String[0]));String queueStr = String.join("", queue.toArray(new String[0]));System.out.println((step++) + "\t" + stackStr + "\t" + queueStr + "\t用" + left + "→"+ preMap.get(left + right) + "," + right + "逆序进栈");stack.pop();String tmp = preMap.get(left + right);for (int i = tmp.length() - 1; i >= 0; i--) {String t = "";if (tmp.charAt(i) == '\'' || tmp.charAt(i) == '’') {t = tmp.charAt(i-1)+""+tmp.charAt(i);i--;}else {t=tmp.charAt(i)+"";}if (!t.equals("ε"))stack.push(t);}continue;}break;}if (!isSuccess)System.out.println((step++) + "\t#\t#\t" + "分析失败");}// 符号分类private static void identifyVnVt(ArrayList<String> list) {START = list.get(0).charAt(0) + "";for (String oneline : list) {String[] vnvt = oneline.split("→");String left = vnvt[0].trim();VN.add(left);ArrayList<ArrayList<String>> mapValue = new ArrayList<>();ArrayList<String> right = new ArrayList<>();for (int j = 0; j < vnvt[1].length(); j++) {if (vnvt[1].charAt(j) == '|') {VT.addAll(right);mapValue.add(right);right = null;right = new ArrayList<>();continue;}if (j + 1 < vnvt[1].length() && (vnvt[1].charAt(j + 1) == '\'' || vnvt[1].charAt(j + 1) == '’')) {right.add(vnvt[1].charAt(j) + "" + vnvt[1].charAt(j + 1));j++;} else {right.add(vnvt[1].charAt(j) + "");}}VT.addAll(right);mapValue.add(right);MAP.put(left, mapValue);}VT.removeAll(VN);System.out.println("\nVn集合:\t{" + String.join("、", VN.toArray(new String[0])) + "}");System.out.println("Vt集合:\t{" + String.join("、", VT.toArray(new String[0])) + "}");}// 求每个非终结符号的FIRST集合 和 分解单个产生式的FIRST集合private static void findFirst() {System.out.println("\nFIRST集合:");for (String s : VN) {HashSet<String> firstCell = new HashSet<>();ArrayList<ArrayList<String>> list = MAP.get(s);for (ArrayList<String> listCell : list) {HashSet<String> firstCellOne = new HashSet<>();String oneLeft = String.join("", listCell.toArray(new String[0]));if (VT.contains(listCell.get(0))) {firstCell.add(listCell.get(0));firstCellOne.add(listCell.get(0));oneLeftFirst.put(s + "$" + listCell.get(0), s + "→" + oneLeft);} else {boolean[] isVn = new boolean[listCell.size()];isVn[0] = true;int p = 0;while (isVn[p]) {if (VT.contains(listCell.get(p))) {firstCell.add(listCell.get(p));firstCellOne.add(listCell.get(p));oneLeftFirst.put(s + "$" + listCell.get(p), s + "→" + oneLeft);break;}String vnGo = listCell.get(p);Stack<String> stack = new Stack<>();stack.push(vnGo);while (!stack.isEmpty()) {ArrayList<ArrayList<String>> listGo = MAP.get(stack.pop());for (ArrayList<String> listGoCell : listGo) {if (VT.contains(listGoCell.get(0))) {if (listGoCell.get(0).equals("ε")) {if (!s.equals(START)) {firstCell.add(listGoCell.get(0));firstCellOne.add(listGoCell.get(0));oneLeftFirst.put(s + "$" + listGoCell.get(0), s + "→" + oneLeft);}if (p + 1 < isVn.length) {isVn[p + 1] = true;}} else {firstCell.add(listGoCell.get(0));firstCellOne.add(listGoCell.get(0));oneLeftFirst.put(s + "$" + listGoCell.get(0), s + "→" + oneLeft);}} else {stack.push(listGoCell.get(0));}}}p++;if (p > isVn.length - 1)break;}}FIRST.put(s + "→" + oneLeft, firstCellOne);}FIRST.put(s, firstCell);System.out.println("\tFIRST(" + s + ")={" + String.join("、", firstCell.toArray(new String[0])) + "}");}}private static void findFollow() {System.out.println("\nFOLLOW集合:");Iterator<String> it = VN.iterator();HashMap<String, HashSet<String>> keyFollow = new HashMap<>();ArrayList<HashMap<String, String>> vn_VnList = new ArrayList<>();HashSet<String> vn_VnListLeft = new HashSet<>();HashSet<String> vn_VnListRight = new HashSet<>();keyFollow.put(START, new HashSet<>() {private static final long serialVersionUID = 1L;{add("#");}});while (it.hasNext()) {String key = it.next();ArrayList<ArrayList<String>> list = MAP.get(key);ArrayList<String> listCell;if (!keyFollow.containsKey(key)) {keyFollow.put(key, new HashSet<>());}keyFollow.toString();for (ArrayList<String> strings : list) {listCell = strings;for (int j = 1; j < listCell.size(); j++) {HashSet<String> set = new HashSet<>();if (VT.contains(listCell.get(j))) {set.add(listCell.get(j));if (keyFollow.containsKey(listCell.get(j - 1)))set.addAll(keyFollow.get(listCell.get(j - 1)));keyFollow.put(listCell.get(j - 1), set);}}for (int j = 0; j < listCell.size() - 1; j++) {if (VN.contains(listCell.get(j)) && VN.contains(listCell.get(j + 1))) {HashSet<String> set = new HashSet<>(FIRST.get(listCell.get(j + 1)));set.remove("ε");if (keyFollow.containsKey(listCell.get(j)))set.addAll(keyFollow.get(listCell.get(j)));keyFollow.put(listCell.get(j), set);}}for (int j = 0; j < listCell.size(); j++) {HashMap<String, String> vn_Vn;if (VN.contains(listCell.get(j)) && !listCell.get(j).equals(key)) {boolean isAllNull = false;if (j + 1 < listCell.size())for (int k = j + 1; k < listCell.size(); k++) {if ((FIRST.containsKey(listCell.get(k)) && FIRST.get(listCell.get(k)).contains("ε"))) {isAllNull = true;} else {isAllNull = false;break;}}if (j == listCell.size() - 1) {isAllNull = true;}if (isAllNull) {vn_VnListLeft.add(key);vn_VnListRight.add(listCell.get(j));boolean isHaveAdd = false;for (int x = 0; x < vn_VnList.size(); x++) {HashMap<String, String> vn_VnListCell = vn_VnList.get(x);if (!vn_VnListCell.containsKey(key)) {vn_VnListCell.put(key, listCell.get(j));vn_VnList.set(x, vn_VnListCell);isHaveAdd = true;break;} else {if (vn_VnListCell.get(key).equals(listCell.get(j))) {isHaveAdd = true;break;}}}if (!isHaveAdd) {vn_Vn = new HashMap<>();vn_Vn.put(key, listCell.get(j));vn_VnList.add(vn_Vn);}}}}}}keyFollow.toString();vn_VnListLeft.removeAll(vn_VnListRight);Queue<String> keyQueue = new LinkedList<>(vn_VnListLeft);while (!keyQueue.isEmpty()) {String keyLeft = keyQueue.poll();for (int t = 0; t < vn_VnList.size(); t++) {HashMap<String, String> vn_VnListCell = vn_VnList.get(t);if (vn_VnListCell.containsKey(keyLeft)) {HashSet<String> set = new HashSet<>();if (keyFollow.containsKey(keyLeft))set.addAll(keyFollow.get(keyLeft));if (keyFollow.containsKey(vn_VnListCell.get(keyLeft)))set.addAll(keyFollow.get(vn_VnListCell.get(keyLeft)));keyFollow.put(vn_VnListCell.get(keyLeft), set);keyQueue.add(vn_VnListCell.get(keyLeft));vn_VnListCell.remove(keyLeft);vn_VnList.set(t, vn_VnListCell);}}}FOLLOW = keyFollow;for (String key : keyFollow.keySet()) {HashSet<String> f = keyFollow.get(key);System.out.println("\tFOLLOW(" + key + ")={" + String.join("、", f.toArray(new String[0])) + "}");}}private static void reformMap() {boolean isReForm = false;Set<String> keys = new HashSet<>(MAP.keySet());Iterator<String> it = keys.iterator();ArrayList<String> nullSign = new ArrayList<>();nullSign.add("ε");while (it.hasNext()) {String left = it.next();boolean flag = false;ArrayList<ArrayList<String>> rightList = MAP.get(left);ArrayList<String> oldRightCell = new ArrayList<>();ArrayList<ArrayList<String>> newLeftNew = new ArrayList<>();for (ArrayList<String> strings : rightList) {ArrayList<String> newRightCell = new ArrayList<>();if (strings.get(0).equals(left)) {for (int j = 1; j < strings.size(); j++) {newRightCell.add(strings.get(j));}flag = true;newRightCell.add(left + "'");newLeftNew.add(newRightCell);} else {oldRightCell.addAll(strings);oldRightCell.add(left + "'");}}if (flag) {isReForm = true;newLeftNew.add(nullSign);MAP.put(left + "'", newLeftNew);VN.add(left + "'");VT.add("ε");ArrayList<ArrayList<String>> newLeftOld = new ArrayList<>();newLeftOld.add(oldRightCell);MAP.put(left, newLeftOld);}}if (isReForm) {System.out.println("消除文法的左递归:");Set<String> kSet = new HashSet<>(MAP.keySet());for (String k : kSet) {ArrayList<ArrayList<String>> leftList = MAP.get(k);System.out.print("\t" + k + "→");for (int i = 0; i < leftList.size(); i++) {System.out.print(String.join("", leftList.get(i).toArray(new String[0])));if (i + 1 < leftList.size())System.out.print("|");}System.out.println();}}MAP.toString();}public static ArrayList<String> readFile(File file) {System.out.println("从文件读入的文法为:");ArrayList<String> result = new ArrayList<>();try {BufferedReader br = new BufferedReader(new FileReader(file));String s = null;while ((s = br.readLine()) != null) {System.out.println("\t" + s);result.add(s.trim());}br.close();} catch (Exception e) {e.printStackTrace();}return result;}
}
E→TE'
E'→+E|ε
T→FT'
T'→T|ε
F→PF'
F'→*F'|ε
P→(E)|^|a|b
相关文章:

Java实现简单词法、语法分析器
1、词法分析器实现 词法分析器是编译器中的一个关键组件,用于将源代码解析成词法单元。 词法分析器的结构与组件: 通常,词法分析器由两个主要组件构成:扫描器(Scanner)和记号流(Token Stream&a…...

Python实现半双工的实时通信SSE(Server-Sent Events)
Python实现半双工的实时通信SSE(Server-Sent Events) 1 简介 实现实时通信一般有WebSocket、Socket.IO和SSE(Server-Sent Events)三种方法。WebSocket和Socket.IO是全双工的实时双向通信技术,适合用于聊天和会话等&a…...
)
python中的解包操作(*和**)
在Python中,* 和 ** 用于函数定义和函数调用时的参数解包和传递,它们有不同的用途和作用。以下是它们的详细解释和区别: 单星号 (*) 1. 位置参数解包(函数调用) 在函数调用时,* 用于将列表或元组解包成位…...

Lua 时间工具类
目录 一、前言 二、函数介绍 1.DayOfWeek 枚举定义 2.GetTimeUntilNextTarget 3.GetSpecificWeekdayTime 三、完整代码 四、总结 一、前言 当我们编写代码时,我们经常会遇到需要处理日期和时间的情况。为了更方便地处理这些需求,我们可以创建一个…...
)
Qt——Qt网络编程之TCP通信客户端的实现(使用QTcpSocket实现一个TCP客户端例程)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C++语言开发基础总结》 《从0到1学习嵌入式Linux开发》 《QT开发实战》 《Android开发实战》 《实用硬件方案设计》 《结构建模设…...

Qt信号槽与函数直接调用性能对比
1. 测试方法 定义一个类Recv,其中包含一个成员变量num和一个成员函数add(),add()实现num的递增。 另一个类Send通过信号槽或直接调用的方法调用Recv的add函数。 单独开一个线程Watcher,每秒计算num变量的增长数值,作为add函数被调…...

Python中的异常处理:try-except-finally详解与自定义异常类
Python中的异常处理:try-except-finally详解与自定义异常类 在Python编程中,异常处理是确保程序健壮性和可靠性的重要部分。当程序遇到无法预料的错误时,异常处理机制能够防止程序崩溃,并允许我们采取适当的措施来解决问题。本文…...
vscode软件上安装 Fitten Code插件及使用
一. 简介 前面几篇文章学习了 Pycharm开发工具上安装 Fitten Code插件,以及 Fitten Code插件的使用。 Fitten Code插件是是一款由非十大模型驱动的 AI 编程助手,它可以自动生成代码,提升开发效率,帮您调试 Bug,节省…...

人工智能小作业
1.问题 将下列句子用一阶谓词形式表示: (1)雪是白的。 (2)数a和数b之和大于数c。 (3)201班的学生每人都有一台笔记本电脑。 2.答案 句子(1)“雪是白的”可以表示为: White(雪)。 句子(2)“数a和数b…...

程序员搞副业一些会用到的工具
微信号采集(爬虫)技术的选型 那么,我们应该使用什么技术来从庞大的网页内容中自动筛选和提取微信号呢?答案就是:数据采集技术,也就是爬虫技术。 然而,数据采集技术种类繁多,我们具体应该采用哪一个呢&…...

k8s更改master节点IP
背景 搭建集群的同事未规划网络,导致其中有一台master ip是192.168.7.173,和其他集群节点的IP192.168.0.x或192.168.1.x相隔太远,现在需要对网络做整改,方便管理配置诸如绑定限速等操作。 master节点是3节点的。此博客属于事后记…...

c++【入门】已知一个圆的半径,求解该圆的面积和周长?
限制 时间限制 : 1 秒 内存限制 : 128 MB 已知一个圆的半径,求解该圆的面积和周长 输入 输入只有一行,只有1个整数。 输出 输出只有两行,一行面积,一行周长。(保留两位小数)。 令pi3.1415926 样例…...

c#通过sqlsugar查询信息并日期排序
c#通过sqlsugar查询信息并日期字段排序 public static List<Sugar_Get_Info_Class> Get_xml_lot_xx(string lot_number){DBContext<Sugar_Get_Info_Class> db_data DBContext<Sugar_Get_Info_Class>.OpDB();Expression<Func<Sugar_Get_Info_Class, b…...
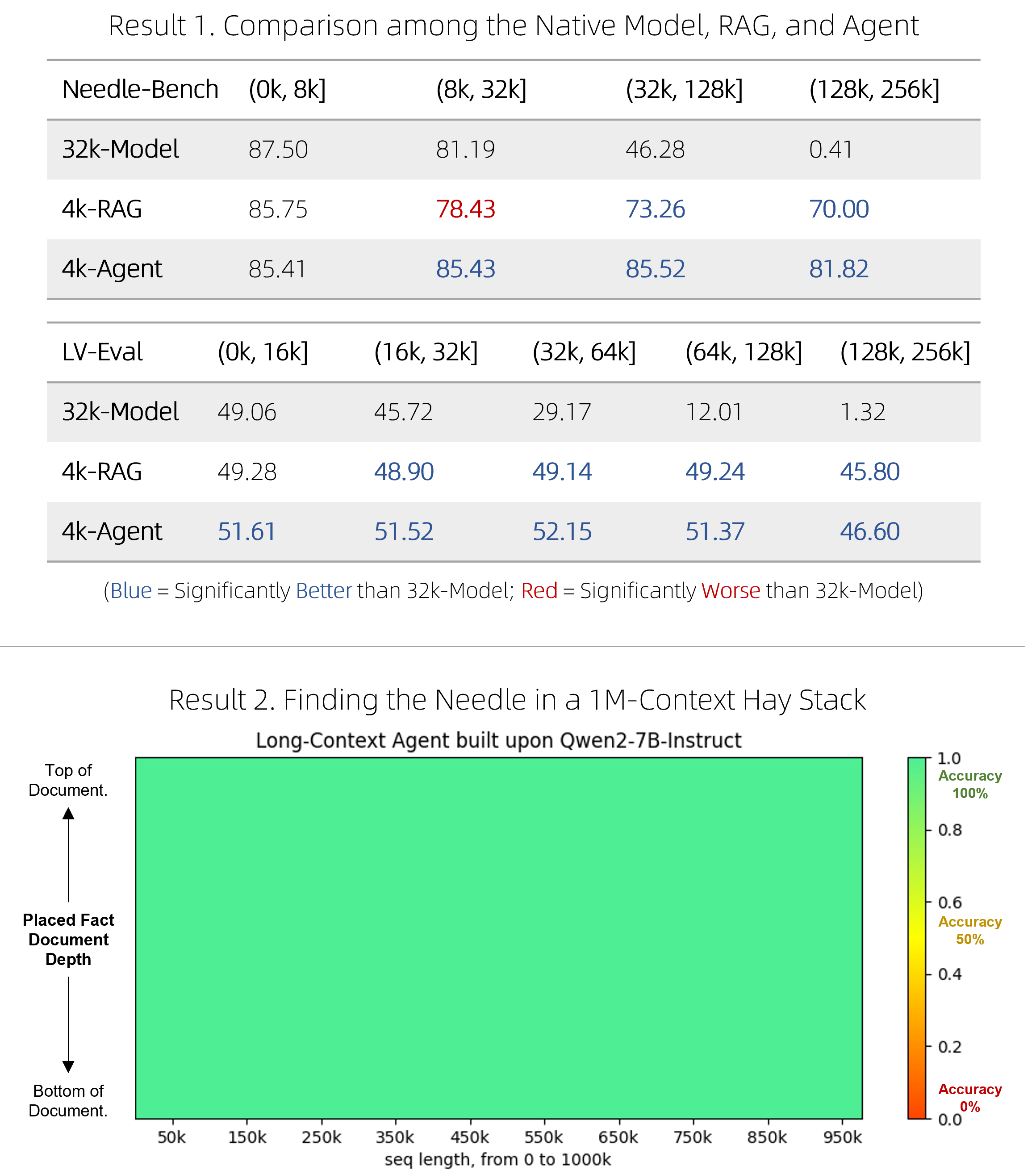
使用 Qwen-Agent 将 8k 上下文记忆扩展到百万量级
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。 针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。 汇总合集…...

Vyper重入漏洞解析
什么是重入攻击 Reentrancy攻击是以太坊智能合约中最具破坏性的攻击之一。当一个函数对另一个不可信合约进行外部调用时,就会发生重入攻击。然后,不可信合约会递归调用原始函数,试图耗尽资金。 当合约在发送资金之前未能更新其状态时&#…...
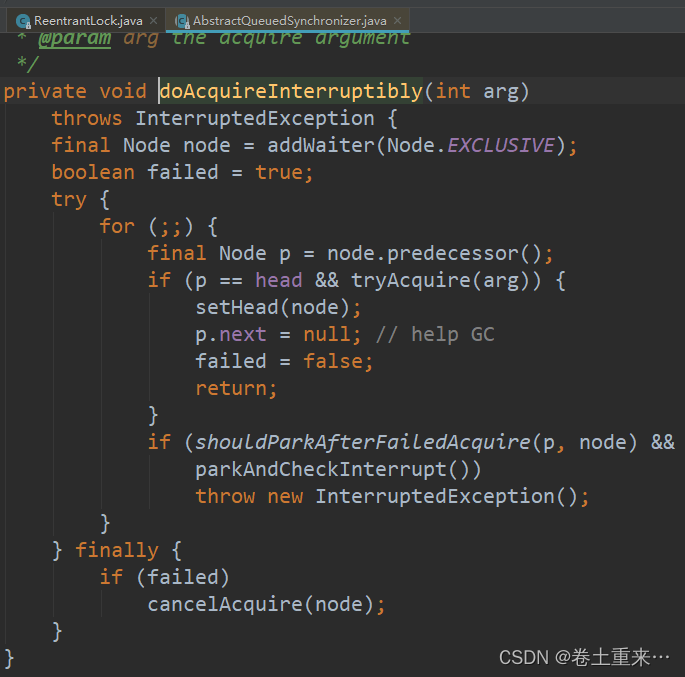
53.ReentrantLock原理
ReentrantLock使用 ReentrantLock 实现了Lock接口, 内置了Sync同步器继承了AbstractQueuedSynchronizer。 Sync是抽象类,有两个实现NonfairSync非公平,FairSync公平。 所以ReentrantLock有公平锁和非公平锁。默认是非公平锁。 public sta…...

“论边缘计算及应用”必过范文,突击2024软考高项论文
论文真题 边缘计算是在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力的分布式开放平台(架构),就近提供边缘智能服务。边缘计算与云计算各有所长,云计算擅长全局性、非实时、长周期的大数据处理与分析,能够在…...
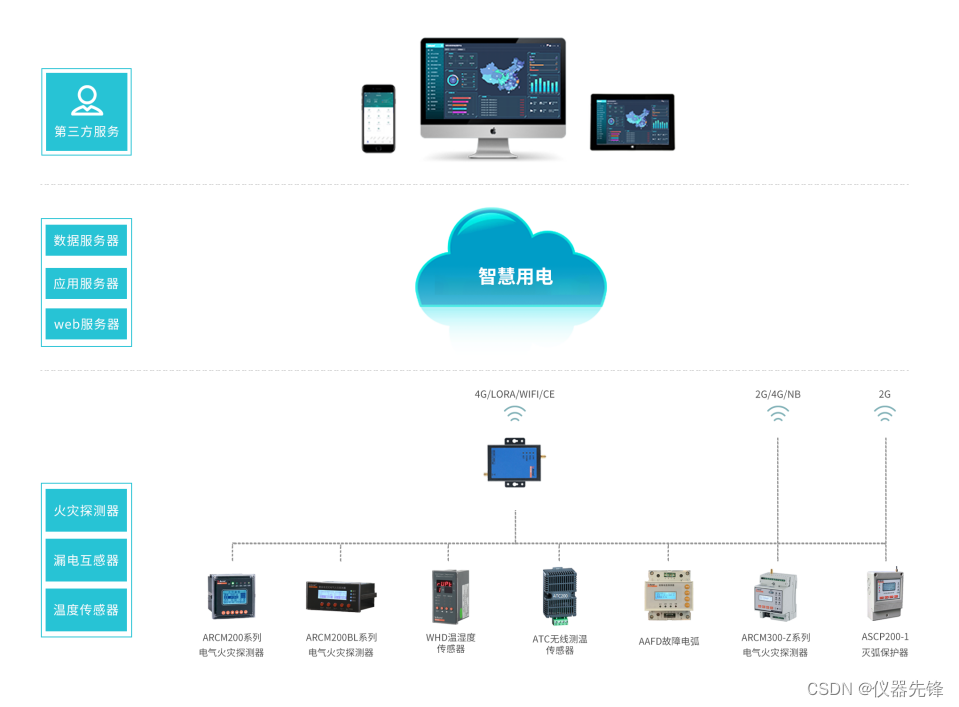
浅谈安全用电管理系统对重要用户的安全管理
1用电安全管理的重要性 随着社会经济的不断发展,电网建设力度的不断加大,供电的可靠性和供电质量日益提高,电网结构也在不断完善。但在电网具备供电的条件下,部分高危和重要电力用户未按规定实现双回路电源线路供电࿱…...

Docker的资源限制
文章目录 一、什么是资源限制1、Docker的资源限制2、内核支持Linux功能3、OOM异常4、调整/设置进程OOM评分和优先级4.1、/proc/PID/oom_score_adj4.2、/proc/PID/oom_adj4.3、/proc/PID/oom_score 二、容器的内存限制1、实现原理2、命令格式及指令参数2.1、命令格式2.2、指令参…...

MongoDB $rename 给字段一次重新命名的机会
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第58篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。 在日常编写程序过程中,命名错误是经常出现的错误。拼写错误的单词,大小写字…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...