【机器学习】【遗传算法】【项目实战】药品分拣的优化策略【附Python源码】
仅供学习、参考使用
一、遗传算法简介
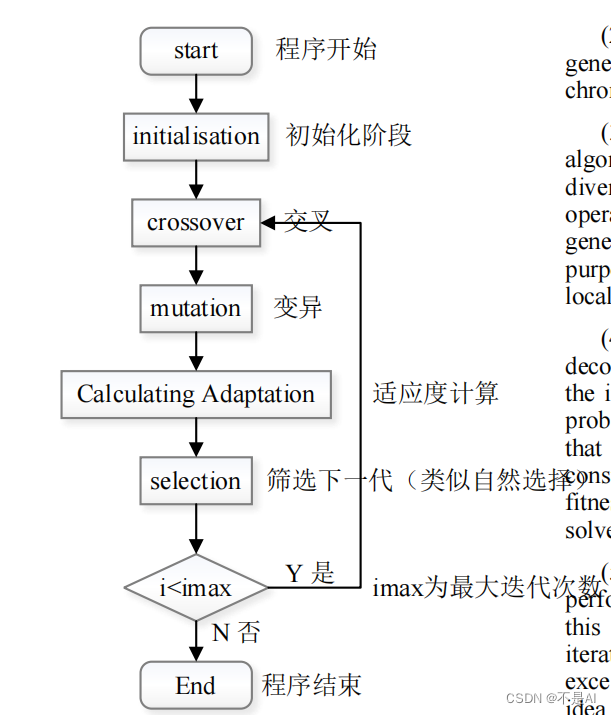
遗传算法(Genetic Algorithm, GA)是机器学习领域中常见的一类算法,其基本思想可以用下述流程图简要表示:
(图参考论文:Optimization of Worker Scheduling at Logistics
Depots Using GeneticAlgorithms and Simulated
Annealing)
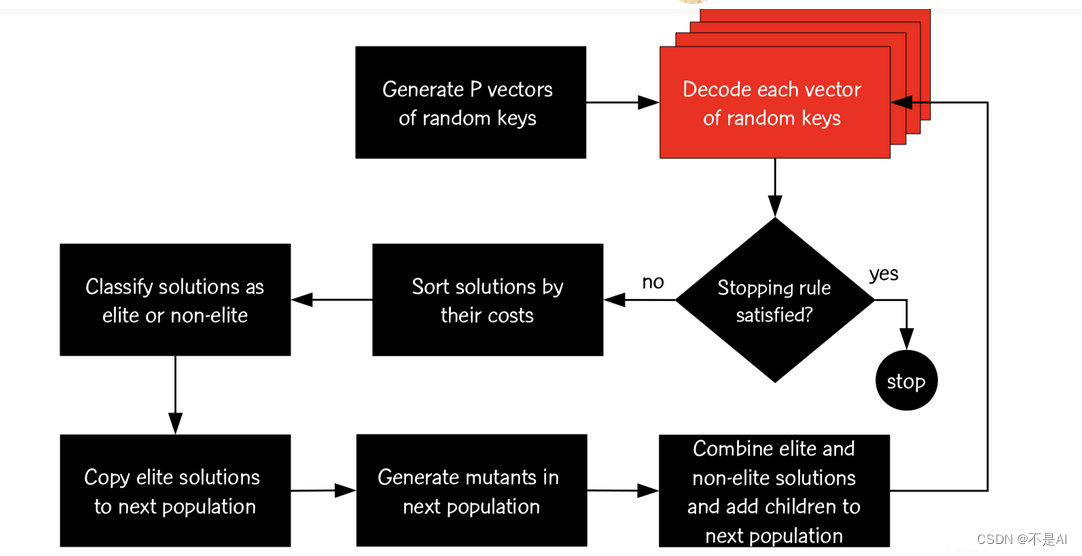
一种常见的遗传算法变例是有偏随机密匙遗传算法 (BRKGA: Biased Random Key Genetic Algorithm) ,参考论文:A BIASED RANDOM-KEY GENETIC ALGORITHM WITH VARIABLE MUTANTS TO
SOLVE A VEHICLE ROUTING PROBLEM,算法流程大致如下:
(图参考博客:Pymoo学习 (11):有偏随机密匙遗传算法 (BRKGA: Biased Random Key Genetic Algorithm) 的使用)
二、项目源码(待进一步完善)
1、导入相关库
import csv
import random
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
2、药品统计
# 统计zone_id=2110的药品
def screen_goods_id(tote_data, zone):zone_goods_id_lists = []for i in range(len(tote_data)):zone_id = tote_data['区段ID'][i]goods_id = tote_data['产品编号'][i]if zone_id == zone:zone_goods_id_lists.append(goods_id)zone_goods_id_lists = list(set(zone_goods_id_lists))return zone_goods_id_lists
3、货位统计
# 统计zone_id=2110的货位
def generate_locations():index_id_0 = [2173, 2174, 2175, 2176, 2177, 2178, 2179, 2180, 2181]index_id_1 = [1, 2, 3, 4, 5, 6, 7, 8]index_id_2 = [21, 22, 23, 24, 25, 31, 32, 33, 34, 35, 41, 42, 43, 44, 45]location_id_data = [f"{aa:04d}{bb:02d}{cc:02d}1" for aa in index_id_0 for bb in index_id_1 for cc in index_id_2]return location_id_data4、缺失货位统计
# 统计zone_id=2110的缺失货位
def del_locations():index_id_0 = [217408, 217507, 217708, 217807, 218008, 218107]index_id_1 = [22, 23, 24, 25, 32, 33, 34, 35, 42, 43, 44, 45]del_loc_data = [f"{aa:06d}{bb:02d}1" for aa in index_id_0 for bb in index_id_1]return del_loc_data
5、生成可使用货位
# 去除缺失货位,生成最终的可使用货位
def screen_location_id():location_id_data = generate_locations()del_loc_data = del_locations()location_id_lists = [loc_id for loc_id in location_id_data if loc_id not in del_loc_data]return location_id_lists
6、个体(单个基因型)生成
# 生成一个个体
def pop_one_combined(list_1, list_2): # list1的长度不能大于list2goods_ids_copy = list_1[:]location_ids_copy = list_2[:]combined_list = []for _ in range(len(list_1)):element = random.choice(location_ids_copy)location_ids_copy.remove(element)combined_list.append(element)return combined_list
生成测试:大小为6的一维数组,生成50个个体(种群类似):
list1 = [1, 2, 3, 4, 5, 6]
list2 = [1, 2, 3, 4, 5, 6]# 个体生成测试(批量生成)for i in range(50):print(pop_one_combined(list1, list2))
7、种群(基因池)生成
# 生成种群
def generate_pop_list(POP_SIZE, zone_goods_id_data, zone_location_id_data):pop_list = []for _ in range(POP_SIZE):pop_individuality = pop_one_combined(zone_goods_id_data, zone_location_id_data)pop_list.append(pop_individuality)return pop_list
生成测试:
# 种群生成测试(样本量50)
print(generate_pop_list(50, list1, list2))

8、劳累值(特征系数)计算公式
# 拣选劳累值计算公式
def pick_distance_formula(location_id, shelves_num):if location_id[-2] == '4': # 第4层(最高层)distance = 10 * (int(location_id[0:4]) - 2173) + (shelves_num - 1) * 10 + int(location_id[-3]) + 3else: # 第1~3层distance = 10 * (int(location_id[0:4]) - 2173) + (shelves_num - 1) * 10 + int(location_id[-3])return distance
9、一组数据的劳累值计算
# 拣选劳累值计算(一组)
def pick_distance_value(location_id):distance = 0shelves_num = int(location_id[4:6])group_1 = [1, 3, 5, 7]group_2 = [2, 4, 6, 8]if shelves_num in group_1:shelves_num = shelves_num // 2 + 1elif shelves_num in group_2:shelves_num = shelves_num // 2distance = pick_distance_formula(location_id, shelves_num)return distance
10、选择优势个体进入下一代
# 选择优胜个体
def select(pop_list, CROSS_RATE, POP_SIZE):index = int(CROSS_RATE * POP_SIZE) # 一轮筛选后的样本数量return pop_list[0:index] # 返回前xxx个优胜个体
11、遗传变异机制
# 遗传变异
def mutation(MUTA_RATE, child, zone_goods_id_data, zone_location_id_data):if np.random.rand() < MUTA_RATE:mutation_list = [loc_id for loc_id in zone_location_id_data if loc_id not in child]num = np.random.randint(1, int(len(zone_goods_id_data) * MUTA_RATE))for _ in range(num):index = np.random.randint(0, len(zone_goods_id_data))mutation_list.append(child[index])loc_id = random.choice(mutation_list)child[index] = loc_idreturn child
12、子代中0值的替换
# (子代)0值的替换
def obx_count_run(child, parent):for parent_elemental in parent:if parent_elemental not in child:for i in range(len(child)):if child[i] == 0:child[i] = parent_elementalbreakreturn child
13、基于顺序的交叉方式(Order-Based Crossover, OBX)
# 遗传交叉(交叉算子:基于顺序的交叉(Order-Based Crossover,OBX))
def crossmuta(pop_list, POP_SIZE, MUTA_RATE, zone_goods_id_data, zone_location_id_data):pop_new = []for i in range(len(pop_list)):pop_new.append(pop_list[i][1:])while len(pop_new) < POP_SIZE:parent_1 = random.choice(pop_list)[1:]parent_2 = random.choice(pop_list)[1:]while parent_1 == parent_2:parent_2 = random.choice(pop_list)[1:]child_1 = [0 for _ in range(len(zone_goods_id_data))]child_2 = [0 for _ in range(len(zone_goods_id_data))]for j in range(len(zone_goods_id_data)):genetic_whether = np.random.choice([0, 1])if genetic_whether == 1:child_1[j] = parent_1[j]child_2[j] = parent_2[j]if (child_1 == parent_1) or (child_2 == parent_2):continuechild_1 = obx_count_run(child_1, parent_2)child_1 = mutation(MUTA_RATE, child_1, zone_goods_id_data, zone_location_id_data)child_2 = obx_count_run(child_2, parent_1)child_2 = mutation(MUTA_RATE, child_2, zone_goods_id_data, zone_location_id_data)pop_new.append(child_1)pop_new.append(child_2)return pop_new14、损失曲线图绘制
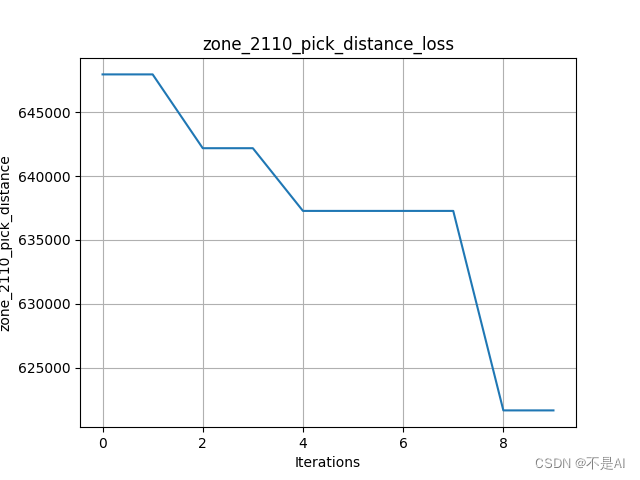
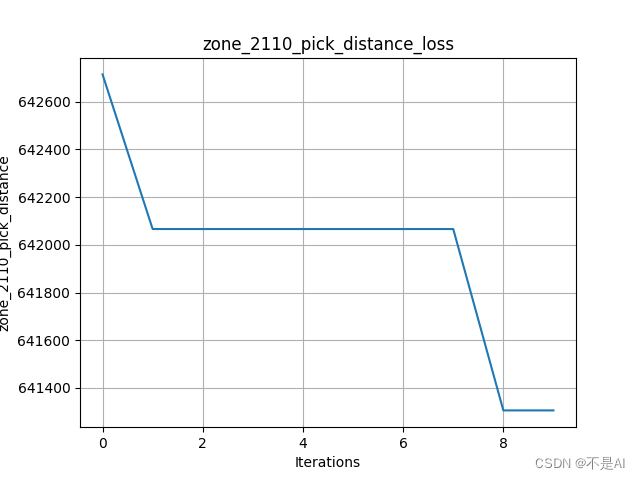
# 每轮总拣选劳累值绘制曲线图
def loss_chart(data):y_values = datax_values = list(range(len(y_values)))plt.plot(x_values, y_values)plt.title("zone_2110_pick_distance_loss")plt.xlabel("Iterations") # 迭代次数plt.ylabel("zone_2110_pick_distance") # 距离plt.grid()plt.savefig('./JS_zone_2110_pick_distance_loss.png')plt.show()
15、结果合成
# 最终结果合成
def goods_location_data_consolidation(zone_goods_id_data, zone_goods_location_id_data):goods_location_data = []for i in range(len(zone_goods_id_data)):goods_location_data.append([zone_goods_id_data[i], zone_goods_location_id_data[i]])return goods_location_data
主函数及运行:
def main():list1 = [1, 2, 3, 4, 5, 6]list2 = [1, 2, 3, 4, 5, 6]# 个体生成测试(批量生成)for i in range(50):print(pop_one_combined(list1, list2))# 种群生成测试(样本量50)print(generate_pop_list(50, list1, list2))print("Genetic algorithm run start")print(f"start_time --> {datetime.now()}")zone_2110_pick_distance = []tote_goods_data_2403 = pd.read_csv('./tote_goods_data_2024_03.csv') # 读取数据集POP_SIZE = 20 # 种群大小CROSS_RATE = 0.9 # 交叉率MUTA_RATE = 0.05 # 变异率Iterations = 10 # 迭代次数zone_2110_goods_id_lists = screen_goods_id(tote_goods_data_2403, 2110)zone_2110_location_id_lists = screen_location_id()POP = generate_pop_list(POP_SIZE, zone_2110_goods_id_lists, zone_2110_location_id_lists)for i in range(Iterations):POP = getfitness(POP, 2110, tote_goods_data_2403, zone_2110_goods_id_lists)POP = select(POP, CROSS_RATE, POP_SIZE)zone_2110_pick_distance.append(POP[0][0])POP = crossmuta(POP, POP_SIZE, MUTA_RATE, zone_2110_goods_id_lists, zone_2110_location_id_lists)loss_chart(zone_2110_pick_distance)Updated_goods_location_data = goods_location_data_consolidation(zone_2110_goods_id_lists, POP[0])with open('./zone_2110_goods_location_data.csv', 'w', newline='') as csvfile:writer = csv.writer(csvfile)writer.writerow(['goods_id', 'location_id'])for row in Updated_goods_location_data:writer.writerow(row)print(f"end_time --> {datetime.now()}")print("Genetic algorithm run end")if __name__ == "__main__":main()三、算法测试
1、pop_size=20, iterations=10
cross_rate=0.5, muta_rate=0.05:
交叉率不变,增加变异率到0.1:
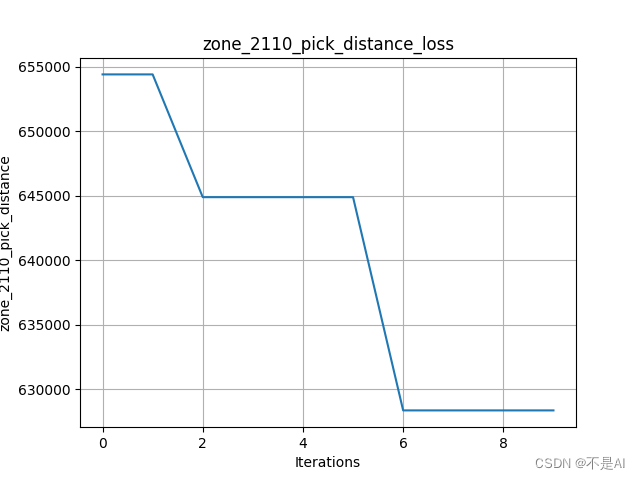
交叉率不变,增加变异率到0.2:
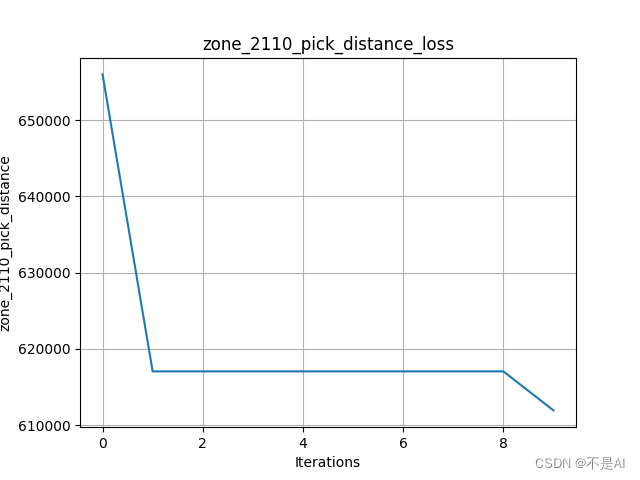
变异率不变,增加交叉率到0.9:
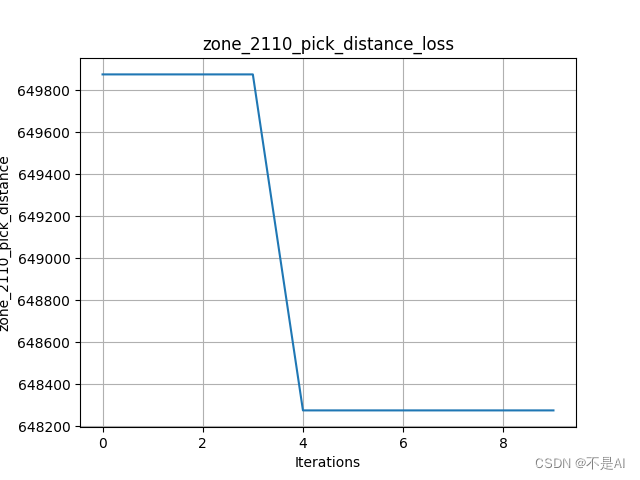
2、在另一个数据集上进行测试
采用初始参数设定:
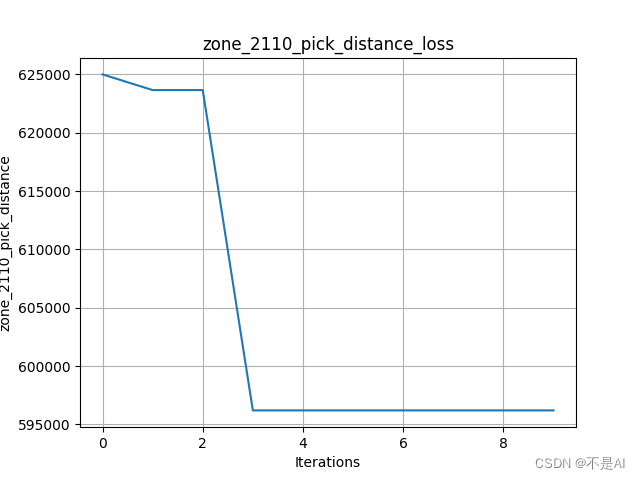
交叉率提高至0.9:
四、算法优化
GA(遗传)算法优化可行性分析
一、优化算法核心步骤参数
GA(Genetic Algorithm,遗传算法)的主要流程可以用下图进行简要描述:
在初始化阶段,需要确定imax(最大迭代次数)的值用于主循环的迭代。除这个值外,在算法的“交叉”步骤中,需要确定交叉方法(常用的交叉方法包括单点交叉、两点交叉、多点交叉、部分匹配交叉、均匀交叉、顺序交叉、基于位置的交叉、基于顺序的交叉、循环交叉、子路径交换交叉等),并指定参数cross_rate(交叉率)的值;在“变异”步骤中,需要指定参数muta_rate(变异率)的值;在“适应度计算”步骤中,需要自定义适应度(fitness)计算公式。故而可以进行优化的参数包括:
(1)最大迭代次数;
(2)交叉方法;(待验证)
(3)交叉率;
(4)变异率;(结论:提高变异率可以显著提高损失函数的收敛速度)
(5)适应度计算公式(涉及到按比例缩放的问题)。可能的策略:使用二次或者高次函数?如何提高损失函数的收敛速度?
二、采用GA的常见变式
上述流程图为GA的最基本的形式(基础GA),常见的优化变式包括:
(1)GA+SA——遗传算法结合模拟退火(Simulated Annealing)算法;
见论文:《Optimization of Worker Scheduling at Logistics
Depots Using Genetic Algorithms and Simulated
Annealing》
(2)AQDE(Adaptive Quantum Differential Evolution)算法(适应性量子差分进化算法);
见论文:《Z. Sun, Z. Tian, X. Xie, Z. Sun, X. Zhang, and G. Gong, “An metacognitive based logistics human resource modeling and optimal
scheduling,”》
(3)BRKGA(Biased Random-Key Genetic Algorithm)算法(有偏随机密钥遗传算法);
见论文:《A Biased Random-Key Genetic Algorithm With Variable Mutants To Solve a Vehicle Routing Problem》
三、结合深度学习或者强化学习
todo
四、其他可行方法
其他可行方法主要包括:
(1)向量化(vectorization);
(2)多线程(multithreading);
(3)并行计算(multiprocessing);
(4)带缓存的多级计算(cached computation)。
并行计算方面,可以使用Python中的joblib库:
相关文章:
【机器学习】【遗传算法】【项目实战】药品分拣的优化策略【附Python源码】
仅供学习、参考使用 一、遗传算法简介 遗传算法(Genetic Algorithm, GA)是机器学习领域中常见的一类算法,其基本思想可以用下述流程图简要表示: (图参考论文:Optimization of Worker Scheduling at Logi…...

电子电气架构 ---车载安全防火墙
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

解决selenium加载网页过慢影响程序运行时间的问题
在用selenium爬取动态加载网页时,发现网页内容都全部加载完了,但是页面还在转圈,并且获取页面内容的代码也没有执行,后面了解到selenium元素操作等方法是需要等待页面所有元素完全加载完成后才开始执行的,所以在页面未…...

何为云防护?有何作用
云防护又称云防御。随着Internet互联网络带宽的增加和多种DDOS 黑客工具的不断发布,云计算越演越热,DDOS拒绝服务攻击的实施越来越容易,DDOS攻击事件正在成上升趋势。出于商业竞争、打击报复和网络敲诈等多种因素,导致很多IDC 托管…...

2024050402-重学 Java 设计模式《实战责任链模式》
重学 Java 设计模式:实战责任链模式「模拟618电商大促期间,项目上线流程多级负责人审批场景」 一、前言 场地和场景的重要性 射击🏹需要去靶场学习、滑雪🏂需要去雪场体验、开车🚗需要能上路实践,而编程…...
centos7安装字体
1.安装命令 yum install fontconfig #字体库命令 yum install mkfontscale #更新字体命令2.安装字体(注意权限问题) 进入目录 /usr/share/fonts ,该目录是 centos7 字体库的默认安装目录。在该目录下创建一个文件夹 ekp (名字…...

Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集
LlaMA 3 系列博客 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (三) 基于 LlaMA…...
学习Canvas过程中2D的方法、注释及感悟一(通俗易懂)
1.了解Canvas: Canvas是前端一个很重要的知识点,<canvas>标签用于创建画布绘制图形,通过JavaScript进行操作。它为开发者提供一个动态绘制图形的区域,用于创建图标、游戏动画、图像处理等。 对于能够熟练使用Canvas的开发者…...

《TCP/IP网络编程》(第十三章)多种I/O函数(2)
使用readv和writev函数可以提高数据通信的效率,它们的功能可以概括为**“对数据进行整合传输及发送”**。 即使用writev函数可以将分散在多个缓冲中的数据一并发送,使用readv函数可以由多个缓冲分别接受,所以适当使用他们可以减少I/O函数的调…...

Java集合汇总
Java中的集合框架是Java语言的核心部分,提供了强大的数据结构来存储和操作对象集合。集合框架位于java.util包中,主要可以分为两大类:Collection(单列集合)和Map(双列集合)。下面是对它们的总结…...
度小满金融大模型的应用创新
XuanYuan/README.md at main Duxiaoman-DI/XuanYuan GitHub...
Android WebView上传文件/自定义弹窗技术,附件的解决方案
安卓内核开发 其实是Android的webview默认是不支持<input type"file"/>文件上传的。现在的前端页面需要处理的是: 权限 文件路径AndroidManifest.xml <uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE"/&g…...

selenium 输入框、按钮,输入点击,获取元素属性等简单例子
元素操作 nput框 输入send_keys, input框 清除clear(), 按钮 点击click() 按钮 提交submit() 获取元素 tag_name、 class属性值、 坐标尺寸 """ input框 输入1次,再追加输入一次, 清除, 再重新输入&…...

结构体构造函数
【知识点:结构体构造函数】下面两段代码等价。 (1)结构体构造函数写法 struct LinkNode {int data;LinkNode* next;LinkNode(int x):data(x),next(NULL) {} }; LinkNode* Lnew LinkNode(123); (2)非结构体构造函数写…...

基于单片机的电子万年历设计
摘要: 本设计以 AT89C51 单片机为主控器,使用 DS1302 时钟芯片、DS18B20 温度芯片、LCD1602 显示模块,利用Proteus 仿真软件和 Keil 编译软件进行了基于单片机的电子万年历仿真,设计的万年历可以在液晶上显示时间,同时还具有时间校准、温度显示等功能。 关键词 :单片机…...

大厂真实面试题(一)
滴滴大数据sql 取出累计值与1000差值最小的记录 1.题目 已知有表t_cost_detail包含id和money两列,id为自增,请累加计算money值,并求出累加值与1000差值最小的记录。 2.分析 本题主要是想找到累加值域1000差距最小的记录,也就是我们要对上述按照id进行排序并且累加,并…...
Docker搭建ELKF日志分析系统
Docker搭建ELKF日志分析系统 文章目录 Docker搭建ELKF日志分析系统资源列表基础环境一、系统环境准备1.1、创建所需的映射目录1.2、修改系统参数1.3、单击创建elk-kgc网络桥接 二、基于Dockerfile构建Elasticsearch镜像2.1、创建Elasticsearch工作目录2.2、上传资源到指定工作路…...
把系统引导做到U盘,实现插上U盘才能开机
前言 有个小伙伴提出了这样一个问题:能不能把U盘制作成电脑开机的钥匙? 小白稍微思考了一下,便做了这样一个回复:可以。 至于为什么要思考一下,这样会显得我有认真思考他提出的问题。 Windows7或以上系统均支持UEF…...
【计算机网络基础知识】
首先举一个生活化的例子,当你和朋友打电话时,你可能会使用三次握手和四次挥手的过程进行类比: 三次握手(Three-Way Handshake): 你打电话给朋友:你首先拨打你朋友的电话号码并等待他接听。这就…...

个股场外期权个人如何参与买卖?
个股场外期权作为一种金融衍生品,为个人投资者提供了多样化的投资选择和风险管理工具。想要参与个股场外期权的买卖,以下是一些关键步骤和考虑因素。 文章来源/:财智财经 第一步:选择合适的金融机构 首先,个人投资者需…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...