【大数据hive】hive 函数使用详解
一、前言
在任何一种编程语言中,函数可以说是必不可少的,像mysql、oracle中,提供了很多内置函数,或者通过自定义函数的方式进行定制化使用,而hive作为一门数据分析软件,随着版本的不断更新迭代,也陆续出现了很多函数,以满足日常数据查询与分析的各种场景。
二、hive 函数概述
Hive内建了不少函数,用于满足用户不同使用需求,提高SQL编写效率,查看hive的函数,可以通过下面的方式:
1、show functions —— 查看当下可用的所有函数;
2、describe function extended funcname —— 查看函数的具体使用方式;
show functions 查看当前版本下hive函数
这以上随机截取了一部分,更详细的可以参考官方手册:hive官方文档,里面有hive函数的详细资料;

三、hive 函数分类
Hive函数分为两大类:
- 内置函数(Built-in Functions);
- 用户定义函数UDF(User-Defined Functions);
3.1 内置函数
包括:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等
3.2 用户定义函数
根据输入输出的行数可分为3类:UDF、UDAF、UDTF
用户定义函数UDF分类标准
用户自定义函数根据函数输入输出的行数进行划分,具体来说如下:
UDF(User-Defined-Function)
普通函数,一进一出;
UDAF(User-Defined Aggregation Function)
聚合函数,多进一出;
UDTF(User-Defined Table-Generating Functions)
表生成函数,一进多出;
3.3 UDF分类标准扩大化
UDF分类标准本来针对的是用户自己编写开发实现的函数,UDF分类标准可以扩大到Hive的所有函数中:包括内置函数和用户自定义函数;
因为不管是什么类型的函数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何问题。 千万不要被UD(User-Defined)这两个字母所迷惑,照成视野的狭隘。
四、内置函数
内置函数(build-in)顾名思义,指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数,官方文档地址:hive官方文档,内置函数根据应用归类整体可以分为8大种类型,我们将对其中重要的,使用频率高的函数使用进行详细的说明;
8大类型的内置函数
- 字符串函数;
- 日期函数;
- 数学函数;
- 数据脱敏函数;
- 条件函数;
- 类型转换函数;
- 集合函数;
- 其他杂项函数;
4.1 字符串函数
字符串函数可以说在日常工作中使用的很频繁的了,下面列举一些常用的字符串函数
| 字符串长度函数:length |
| 字符串反转函数:reverse |
| 字符串连接函数:concat |
| 带分隔符字符串连接函数:concat_ws |
| 字符串截取函数:substr,substring |
| 字符串转大写函数:upper,ucase |
| 字符串转小写函数:lower,lcase |
| 去空格函数:trim |
| 左边去空格函数:ltrim |
| 右边去空格函数:rtrim |
| 正则表达式替换函数:regexp_replace |
| 正则表达式解析函数:regexp_extract |
| URL解析函数:parse_url |
| json解析函数:get_json_object |
| 空格字符串函数:space |
| 重复字符串函数:repeat |
| 首字符ascii函数:ascii |
| 左补足函数:lpad |
| 右补足函数:rpad |
| 分割字符串函数: split |
| 集合查找函数: find_in_set |
concat 函数
用于拼接字符串,或者将不同类型的字符串拼接在一起;
select concat("angela","baby");
带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('taobao', 'com'));

字符串截取函数
substr(str, pos[, len]) 或者 substring(str, pos[, len])
select substr("angelababy",-2); --pos是从1开始的索引,如果为负数则倒着数
select substr("angelababy",2,2);
正则表达式替换函数
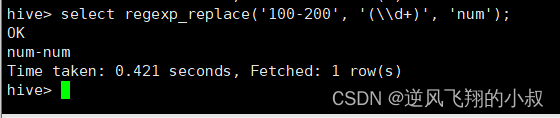
regexp_replace(str, regexp, rep)
select regexp_replace('100-200', '(\\d+)', 'num');
正则表达式解析函数
regexp_extract(str, regexp[, idx]) ,提取正则匹配到的指定组内容
select regexp_extract('100-200', '(\\d+)-(\\d+)', 2);

URL解析函数
parse_url ,注意要想一次解析出多个 可以使用parse_url_tuple这个UDTF函数
select parse_url('http://www.taobao.com/path/p1.action?query=1', 'HOST');

分割字符串函数
split(str, regex)
select split('apache hive', '\\s+');

json解析函数
get_json_object(json_txt, path),其中:json_txt表示json对象;
select get_json_object('[{"website":"www.taobao.com","name":"allenwoon"}, {"website":"cloud.taobao.com","name":"carbondata 中文文档"}]', '$.[1].website');

字符串长度函数
length(str | binary)

字符串反转函数
select reverse("angelababy");
其他字符串函数总结
--字符串连接函数:concat(str1, str2, ... strN)
--字符串转大写函数:upper,ucase
select upper("angelababy");
select ucase("angelababy");
--字符串转小写函数:lower,lcase
select lower("ANGELABABY");
select lcase("ANGELABABY");
--去空格函数:trim 去除左右两边的空格
select trim(" angelababy ");
--左边去空格函数:ltrim
select ltrim(" angelababy ");
--右边去空格函数:rtrim
select rtrim(" angelababy ");
--空格字符串函数:space(n) 返回指定个数空格
select space(4);
--重复字符串函数:repeat(str, n) 重复str字符串n次
select repeat("angela",2);
--首字符ascii函数:ascii
select ascii("angela"); --a对应ASCII 97
--左补足函数:lpad
select lpad('hi', 5, '??'); --???hi
select lpad('hi', 1, '??'); --h
--右补足函数:rpad
select rpad('hi', 5, '??');
--集合查找函数: find_in_set(str,str_array)
select find_in_set('a','abc,b,ab,c,def');4.2 日期函数
日期函数也是一种使用非常频繁的函数,有必要深入的掌握,以下列举常用的日期函数
| 获取当前日期: current_date |
| 获取当前时间戳: current_timestamp |
| UNIX时间戳转日期函数: from_unixtime |
| 获取当前UNIX时间戳函数: unix_timestamp |
| 日期转UNIX时间戳函数: unix_timestamp |
| 指定格式日期转UNIX时间戳函数: unix_timestamp |
| 抽取日期函数: to_date |
| 日期转年函数: year |
| 日期转月函数: month |
| 日期转天函数: day |
| 日期转小时函数: hour |
| 日期转分钟函数: minute |
| 日期转秒函数: second |
| 日期转周函数: weekofyear |
| 日期比较函数: datediff |
| 期增加函数: date_add |
| 日期减少函数: date_sub |
获取当前日期
select current_date();

获取当前时间戳
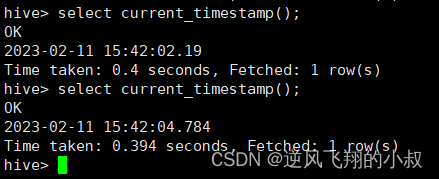
current_timestamp,同一查询中对current_timestamp的所有调用均返回相同的值
select current_timestamp();
获取当前UNIX时间戳函数
select unix_timestamp();

日期比较函数
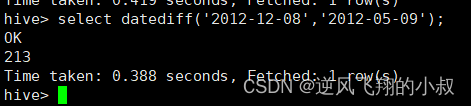
datediff ,日期格式要求为:'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08','2012-05-09');
其他日期函数
--日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp("2011-12-07 13:01:03");--指定格式日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');--UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');--日期增加函数: date_add
select date_add('2012-02-28',10);--日期减少函数: date_sub
select date_sub('2012-01-1',10);--抽取日期函数: to_date
select to_date('2009-07-30 04:17:52');--日期转年函数: year
select year('2009-07-30 04:17:52');--日期转月函数: month
select month('2009-07-30 04:17:52');--日期转天函数: day
select day('2009-07-30 04:17:52');--日期转小时函数: hour
select hour('2009-07-30 04:17:52');--日期转分钟函数: minute
select minute('2009-07-30 04:17:52');--日期转秒函数: second
select second('2009-07-30 04:17:52');--日期转周函数: weekofyear 返回指定日期所示年份第几周
select weekofyear('2009-07-30 04:17:52');
4.3 数学函数
当需要对数据进行一些特殊的运算,比如取整,随机数等,就需要用到hive中的熟悉函数,以下列举常用的一些数学函数;
| 取整函数: round |
| 指定精度取整函数: round |
| 向下取整函数: floor |
| 向上取整函数: ceil |
| 取随机数函数: rand |
| 二进制函数: bin |
| 进制转换函数: conv |
| 绝对值函数: abs |
取整函数
round 返回double类型的整数值部分 (遵循四舍五入)

指定精度取整函数
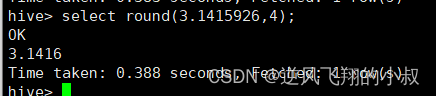
round(double a, int d) ,返回指定精度d的double类型
select round(3.1415926,4);
取随机数函数
rand ,每次执行都不一样 返回一个0到1范围内的随机数
select rand();
其他数学函数
--向下取整函数: floor
select floor(3.1415926);
select floor(-3.1415926);
--向上取整函数: ceil
select ceil(3.1415926);
select ceil(-3.1415926);--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);--二进制函数: bin(BIGINT a)
select bin(18);
--进制转换函数: conv(BIGINT num, int from_base, int to_base)
select conv(17,10,16);
--绝对值函数: abs
select abs(-3.9);4.4 集合函数
集合元素size函数
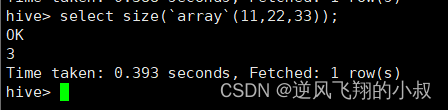
size(Map<K.V>) size(Array<T>)
select size(`array`(11,22,33));
select size(`map`("id",10086,"name","zhangsan","age",18));
取map集合keys函数
map_keys(Map<K.V>),获取集合中map的key列表
select map_keys(`map`("id",10086,"name","zhangsan","age",18));

取map集合values函数
map_values(Map<K.V>)
select map_values(`map`("id",10086,"name","zhangsan","age",18));

判断数组是否包含指定元素
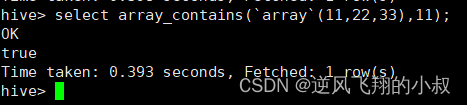
array_contains(Array<T>, value)
select array_contains(`array`(11,22,33),11);
select array_contains(`array`(11,22,33),66);
数组排序函数
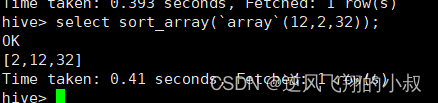
sort_array(Array<T>)
select sort_array(`array`(12,2,32));
4.5 条件函数
if条件判断
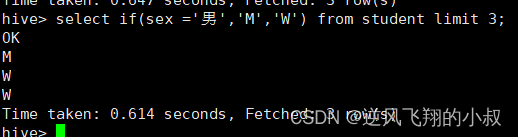
if(boolean testCondition, T valueTrue, T valueFalseOrNull) ,有没有觉得这个语法和 mybatis 中的动态sql有点类似呢?
select if(1=2,100,200);
select if(sex ='男','M','W') from student limit 3;
空判断函数
isnull( a )
select isnull("allen");
select isnull(null);

非空判断函数
isnotnull ( a )
select isnotnull("allen");
select isnotnull(null);
空值转换函数
nvl(T value, T default_value)
select nvl("allen","baidu");
select nvl(null,"baidu");
非空查找函数
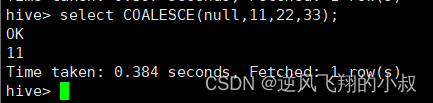
COALESCE(T v1, T v2, ...) ,返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL;
select COALESCE(null,11,22,33);
select COALESCE(null,null,null,33);
select COALESCE(null,null,null);
条件转换函数
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'male' else 'female' end from student limit 3;
其他条件函数
--nullif( a, b ):
-- 如果a = b,则返回NULL,否则返回一个
select nullif(11,11);
select nullif(11,12);--assert_true(condition)
--如果'condition'不为真,则引发异常,否则返回null
SELECT assert_true(11 >= 0);
SELECT assert_true(-1 >= 0);类型转换函数
任意数据类型之间转换:cast
select cast(12.14 as bigint);
select cast(12.14 as string);
select cast("hello" as int);
4.6 数据脱敏函数
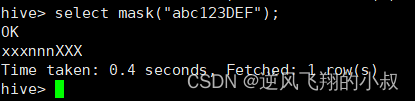
mask
将查询回的数据,大写字母转换为X,小写字母转换为x,数字转换为n
select mask("abc123DEF");
select mask("abc123DEF",'-','.','^'); --自定义替换的字母
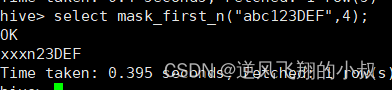
mask_first_n(string str[, int n])
对前n个进行脱敏替换
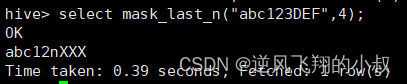
mask_last_n(string str[, int n])
对后n个进行脱敏替换
select mask_last_n("abc123DEF",4);
mask_show_first_n(string str[, int n])
除了前n个字符,其余进行掩码处理
select mask_show_first_n("abc123DEF",4);
mask_show_last_n(string str[, int n])
除了后n个字符,其余进行掩码处理
select mask_show_last_n("abc123DEF",4);
mask_hash(string|char|varchar str)
返回字符串的hash编码
select mask_hash("abc123DEF");
4.7 其他杂项函数
如果你要调用的java方法所在的jar包,而不是hive自带的 ,可以使用add jar 的方式添加进来,hive调用java方法格式为:java_method(class, method[, arg1[, arg2..]]);
调用Java的max函数
select java_method("java.lang.Math","max",11,22);

五、自定义函数
用户自定义函数简称UDF,源自于英文user-defined function,在系统内置的函数无法满足实际的业务场景需求时,可以考虑使用自定义函数 ,关于自定义函数的概念在本文开头有过介绍;
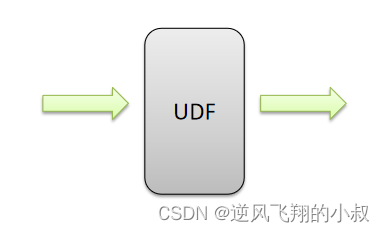
UDF 普通函数
特点是一进一出,也就是输入一行输出一行,比如round这样的取整函数,接收一行数据,输出的还是一行数据;
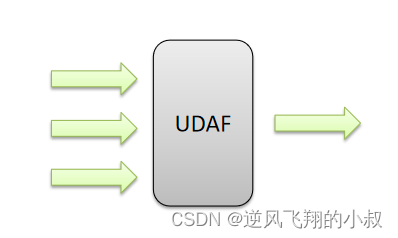
UDAF 聚合函数
UDAF 聚合函数,A所代表的单词就是Aggregation聚合的意思,多进一出,也就是输入多行输出一行;
如下图
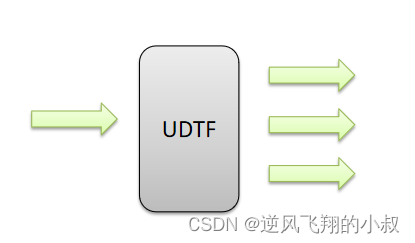
UDTF 表生成函数
- UDTF 表生成函数,T所代表的单词是Table-Generating表生成的意思;
- 特点是一进多出,也就是输入一行输出多行;
这类型的函数作用返回的结果类似于表,同时,UDTF函数也是我们接触比较少的函数,比如explode函数;
如下图所示
使用explode函数就可以得到一进多出的效果;
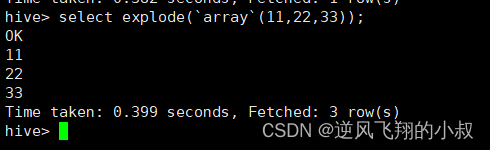
六、explode 函数
6.1 explode 函数功能介绍
explode 函数属于UDTF类型函数,explode接收map、array类型的数据作为输入,然后把输入数据中的每个元素拆开变成一行数据,一个元素一行,explode执行效果正好满足于输入一行输出多行,所有叫做UDTF函数;
1、一般情况下,explode函数可以直接单独使用即可;
2、也可以根据业务需要结合lateral view侧视图一起使用;
使用示例
explode(array) ,将array里的每个元素生成一行;
explode(map) ,将map里的每一对元素作为一行,其中key为一列,value为一列;

6.2 explode 函数操作演示
业务需求描述
有如下的数据
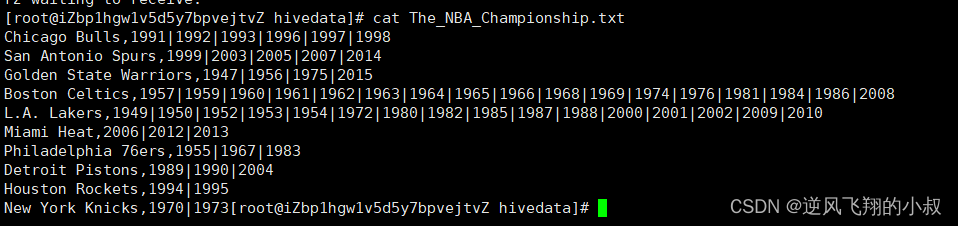
现在需要把这份数据最终转换成下面的表的数据

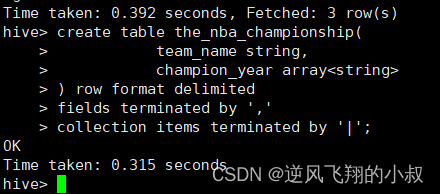
建表
create table the_nba_championship(team_name string,champion_year array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';执行上面的sql建表
加载数据文件到表中
load data local inpath '/usr/local/soft/hivedata/The_NBA_Championship.txt' into table the_nba_championship;

检查数据
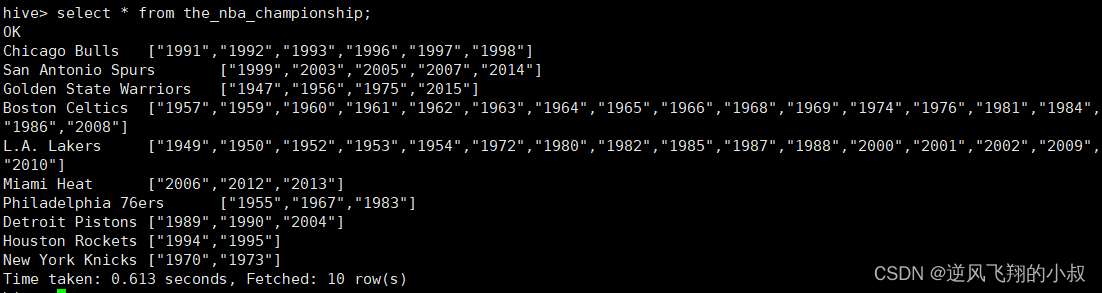
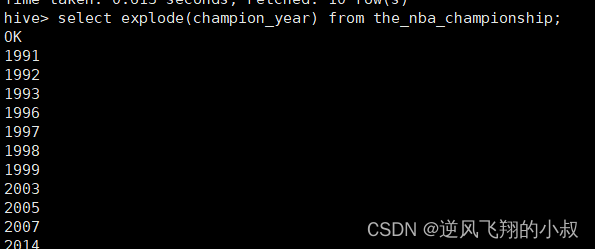
使用explode函数对champion_year进行拆分
俗称炸开
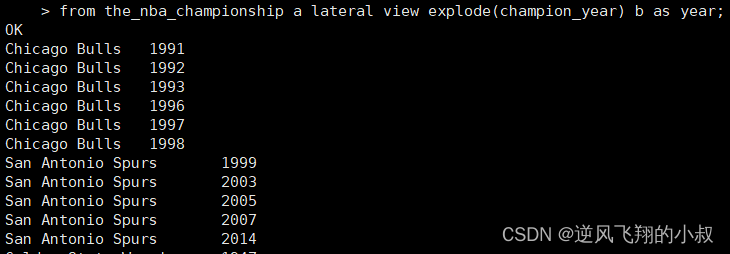
select explode(champion_year) from the_nba_championship;
执行结果,可以看到就把年份分成了一行行数据;
使用lateral view(侧输出流/视图) + explode
select a.team_name,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;
执行结果
可能有同学想,为什么不使用下面的sql呢?
select team_name,explode(champion_year) from the_nba_championship;
其实这个是错误的,执行一下就会报错,这就要解释下UDTF的语法限制了;
UDTF语法限制
- explode函数属于UDTF表生成函数,explode执行返回的结果可以理解为一张虚拟的表,其数据来源于源表;
- 在select中只查询源表数据没有问题,只查询explode生成的虚拟表数据也没问题,但是不能在只查询源表的时候,既想返回源表字段又想返回explode生成的虚拟表字段;通俗点讲,有两张表,不能只查询一张表但是又想返回分别属于两张表的字段;
UDTF语法限制解决
- 从SQL层面上来说上述问题的解决方案是:对两张表进行join关联查询;
- Hive专门提供了语法lateral View侧视图,专门用于搭配explode这样的UDTF函数,以满足上述需要;
七、Hive Lateral View 侧视图
Lateral View 侧视图概述
Lateral View是一种特殊的语法,主要搭配UDTF类型函数一起使用,用于解决UDTF函数的一些查询限制的问题,一般只要使用UDTF,就会固定搭配lateral view使用;
官方链接地址:hive侧视图地址
Lateral View 原理
- 将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题;
- 使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询;
可以对照下图进行理解;

lateral view侧视图基本语法
select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……;操作演示
获取球队的名称,以及荣获冠军的年份
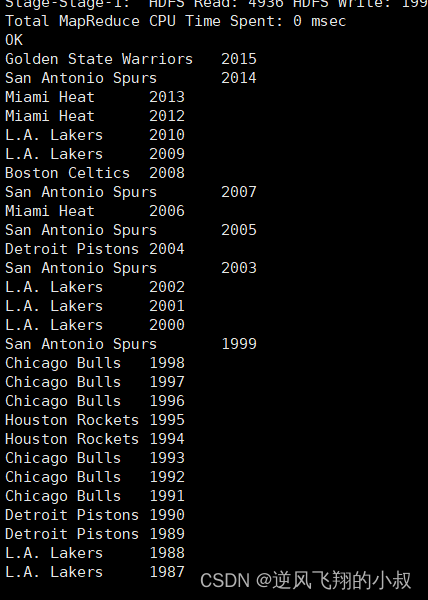
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year;执行结果
上述结果根据年份倒序排序
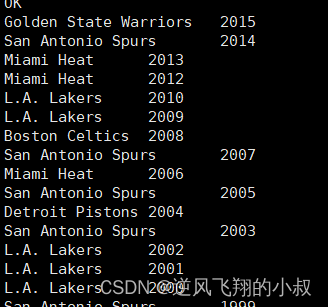
select a.team_name ,b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;执行结果
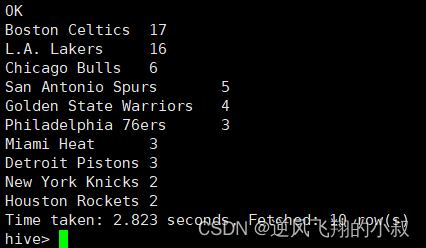
统计每个球队获取总冠军的次数 并且根据倒序排序
select a.team_name ,count(*) as nums
from the_nba_championship a lateral view explode(champion_year) b as year
group by a.team_name
order by nums desc;执行结果
八、聚合函数
在很多业务场景下,需要对表的数据进行汇总(聚合),得到一个聚合的结果或者分组聚合的结果进行报表展示等,比如我们熟悉的mysql,mongodb,es等都提供了丰富的聚合函数对数据进行聚合统计分析。
8.1 hive聚合函数概述
hive 聚合函数的功能是:对一组值执行计算并返回单一的值
1、聚合函数是典型的输入多行输出一行,使用Hive的分类标准,属于UDAF类型函数;
2、通常搭配Group By语法一起使用,分组后进行聚合操作;
8.2 基础聚合
- HQL提供了几种内置的UDAF聚合函数,例如max(...),min(...)和avg(...)。这些我们把它称之为基础的聚合函数;
- 通常情况下聚合函数会与GROUP BY子句一起使用。如果未指定GROUP BY子句,默认情况下,它会汇总所有行数据;
8.3 数据准备
建一张数据表
drop table if exists student;
create table student(num int,name string,sex string,age int,dept string)
row format delimited
fields terminated by ',';执行sql建表
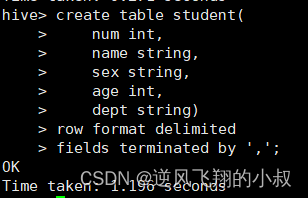
加载数据到表中

8.4 操作演示
没有group by子句的聚合操作
--count(*):所有行进行统计,包括NULL行
--count(1):所有行进行统计,包括NULL行
--count(column):对column中非Null进行统计
执行下面的sql
select count(*) as cnt1,count(1) as cnt2 from student;
执行结果

带有group by子句的聚合操作
这个同mysql的操作基本一致,这里注意group by语法限制
select sex,count(*) as cnt from student group by sex;
执行结果

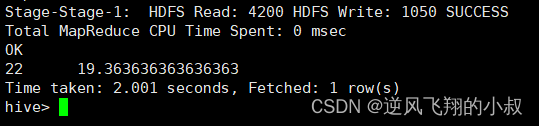
select时多个聚合函数一起使用
select count(*) as cnt1,avg(age) as cnt2 from student;
执行结果
聚合函数搭配其他条件函数一起使用
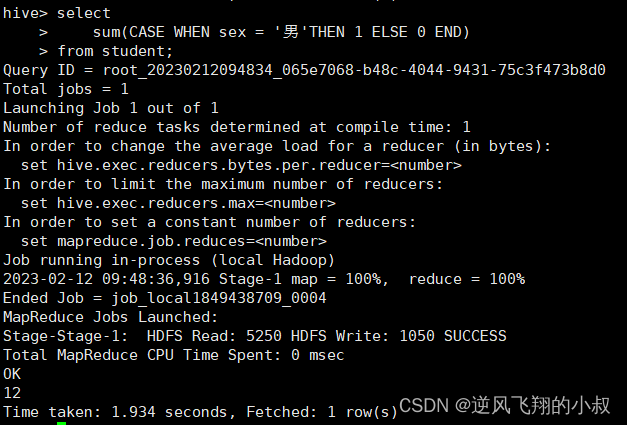
与case when条件转换函数、coalesce函数、if函数使用
selectsum(CASE WHEN sex = '男'THEN 1 ELSE 0 END)
from student;selectsum(if(sex = '男',1,0))
from student;执行结果
聚合参数不支持嵌套聚合函数

聚合操作时针对null的处理
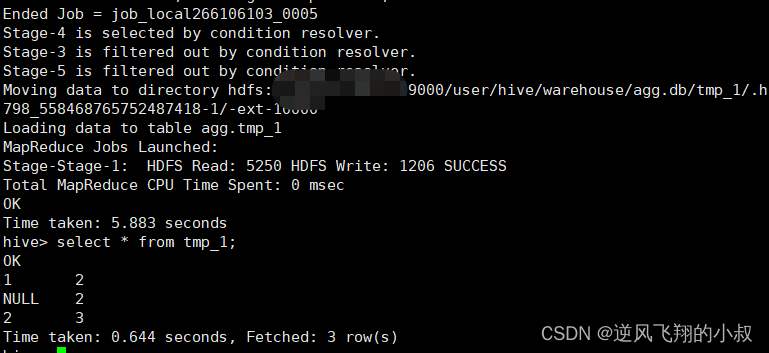
CREATE TABLE tmp_1 (val1 int, val2 int);
INSERT INTO TABLE tmp_1 VALUES (1, 2),(null,2),(2,3);
select * from tmp_1;依次执行上面的sql观察结果
在存在null数据的情况下,进行下面的聚合看看效果如何
select sum(val1), sum(val1 + val2) from tmp_1;
从执行结果来看,第二行数据(NULL, 2) 在进行sum(val1 + val2)的时候会被忽略;
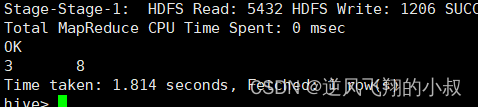
这个可以使用coalesce函数解决
selectsum(coalesce(val1,0)),sum(coalesce(val1,0) + val2)
from tmp_1;这时执行上面的sql就能得到期望的结果了
配合distinct关键字去重聚合
此场景下,会编译期间会自动设置只启动一个reduce task处理数据 可能造成数据拥堵,如下的聚合:
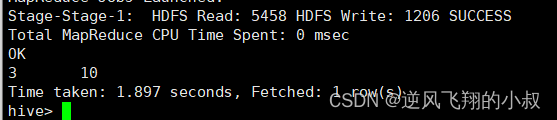
select count(distinct sex) as cnt1 from student;
在这种情况下,可以考了先去重 在聚合 通过子查询完成,因为先执行distinct的时候 可以使用多个reducetask来跑数据,改进后的sql如下:
select count(*) as gender_uni_cnt
from (select distinct sex from student) a;
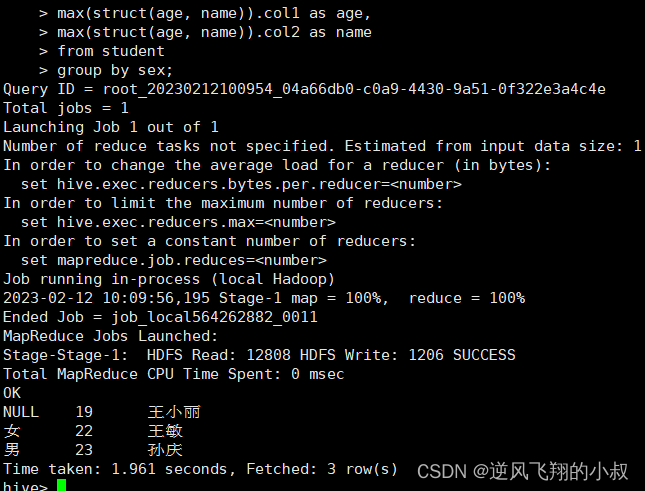
找出student表中男女学生年龄最大的及名字
这里使用了struct来构造数据 然后针对struct应用max找出最大元素 然后取值 select sex
select sex,
max(struct(age, name)).col1 as age,
max(struct(age, name)).col2 as name
from student
group by sex;执行上面的sql观察结果
8.5 增强聚合
常用的增强聚合函数包括:grouping_sets、cube、rollup这几个函数,它们主要适用于OLAP多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度,接下来通过操作演示下增强聚合的使用。
8.6 数据准备
建表并加载数据
CREATE TABLE cookie_info(month STRING,day STRING,cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';load data local inpath '/usr/local/soft/selectdata/cookie_info.txt' into table cookie_info;查询数据是否加载成功

8.7 操作演示group sets
group sets 操作1
-- grouping_id —— 表示这一组结果属于哪个分组集合;
-- 根据grouping sets中的分组条件month,day,1是代表month,2是代表day;
SELECTmonth,day,COUNT(DISTINCT cookieid) AS nums,GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day) --这里是关键
ORDER BY GROUPING__ID;执行结果

从这个执行结果来看,其实group sets的操作相当于是把两种聚合结果做了union操作,等价于下面的sql;
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day;group sets 操作2
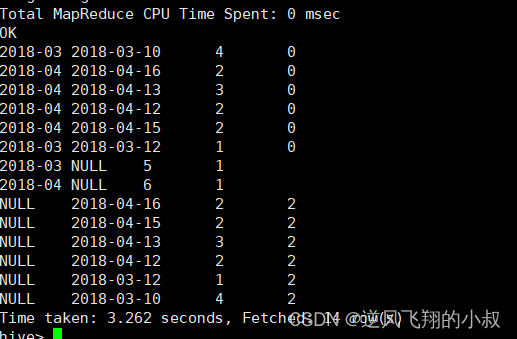
从上一个操作对照理解这个sql就很好理解了
SELECTmonth,day,COUNT(DISTINCT cookieid) AS nums,GROUPING__ID
FROM cookie_info
GROUP BY month,day
GROUPING SETS (month,day,(month,day)) --1 month 2 day 3 (month,day)
ORDER BY GROUPING__ID;执行sql观察结果
总结来说:grouping sets是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同维度的GROUP BY结果集进行UNION ALL。GROUPING__ID表示结果属于哪一个分组集合。
8.8 增强聚合 -- cube与ROLLUP
cube表示根据GROUP BY的维度的所有组合进行聚合。对于cube来说,如果有n个维度,则所有组合的总个数是:2^n;
比如cube有a,b,c 3个维度,则所有组合情况是: (a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),()
cube 的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合,rollup是cube的子集,以最左侧的维度为主,从该维度进行层级聚合;
比如ROLLUP有a,b,c3个维度,则所有组合情况是:(a,b,c),(a,b),(a),()
8.9 cube 操作演示
with cube
按照上面的理论说明,使用cube进行聚合下面的sql;
SELECTmonth,day,COUNT(DISTINCT cookieid) AS nums,GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;执行sql,观察执行结果;
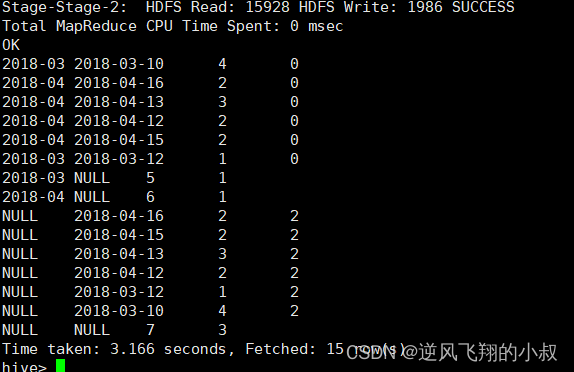
从结果来看,得到了多个维度的聚合统计结果,其实就等价于下面的sql;
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS nums,0 AS GROUPING__ID FROM cookie_info
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;
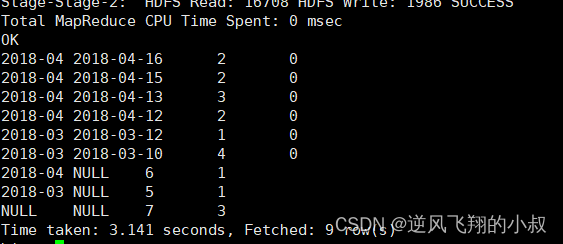
with rollup
以month维度进行层级聚合;
SELECTmonth,day,COUNT(DISTINCT cookieid) AS nums,GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;执行结果;
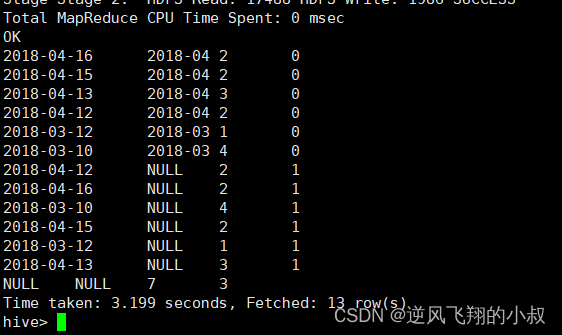
再把month和day调换顺序,则以day维度进行层级聚合;
SELECTday,month,COUNT(DISTINCT cookieid) AS uv,GROUPING__ID
FROM cookie_info
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;执行结果
本篇通过大量的篇幅展示了hive中各类函数的详细使用,希望对看到的小伙们有用,不足之处,敬请执教,本篇到此结束,谢谢观看!
相关文章:
【大数据hive】hive 函数使用详解
一、前言 在任何一种编程语言中,函数可以说是必不可少的,像mysql、oracle中,提供了很多内置函数,或者通过自定义函数的方式进行定制化使用,而hive作为一门数据分析软件,随着版本的不断更新迭代,…...
彻底搞懂分布式系统服务注册与发现原理
目录 引入服务注册与发现组件的原因 单体架构 应用与数据分离...

安卓Camera2用ImageReader获取NV21源码分析
以前如何得到Camera预览流回调 可以通过如下方法,得到一路预览回调流 Camera#setPreviewCallbackWithBuffer(Camera.PreviewCallback),可以通过如下方法,设置回调数据的格式,比如 ImageFormat.NV21 Camera.Parameters#setPreview…...

24. 两两交换链表中的节点
文章目录题目描述迭代法递归法参考文献题目描述 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入&a…...

linux006之帮助命令
linux帮助命令简介: linux的命令是非常多的,光靠人是记不住的,在工作中一般都会去网上查,这是有外网的情况下,如果项目中不允许访问外网,那么linux的帮助命令就可以派上用场了, linux帮助命令是…...

【C++初阶】十三、模板进阶(总)|非类型模板参数|模板的特化|模板分离编译|模板总结(优缺点)
目录 一、非类型模板参数 二、模板的特化 2.1 模板特化概念 2.2 函数模板特化 2.3 类模板特化 2.3.1 全特化 2.3.2 偏特化 三、模板分离编译 四、模板总结(优缺点) 前言:之前模板初阶并没有把 C模板讲完,因为当时没有接触…...
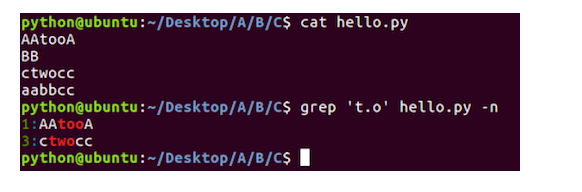
Linux之文本搜索命令
文本搜索命令学习目标能够知道文本搜索使用的命令1. grep命令的使用命令说明grep文本搜索grep命令效果图:2. grep命令选项的使用命令选项说明-i忽略大小写-n显示匹配行号-v显示不包含匹配文本的所有行-i命令选项效果图:-n命令选项效果图:-v命令选项效果图:3. grep命令结合正则表…...

微信小程序Springboot 校园拼车自助服务系统java
系统管理员: 管理员账户管理:在线对管理员的账户信息进行管理,包括对管理员信息的增加修改以及密码的修改等。 站内新闻管理:在后台对站内新闻信息进行发布,并能够对站内新闻信息进行删除修改等。 论坛版块管理&#x…...

【Unity3D 常用插件】Haste插件
一,Haste介绍 Haste插件是一款针对 Unity 3D 的 Everthing软件,可以实现基于名称快速定位对象的功能。Unity 3D 编辑器也自带了搜索功能,但是在 project视图 和 Hierarchy视图 中的对象需要分别查找,不支持模糊匹配。Haste插件就…...

【c++面试问答】全局变量和局部变量的区别
问题 C中的全局变量和局部变量有什么区别? 注:内容全部参考自文末的参考资料 全局变量和局部变量的区别 可以从以下4个角度来区分: 区别全局变量局部变量作用域全局作用域局部作用域内存分配全局变量在静态数据区静态局部变量在静态数据区…...

Java List集合
6 List集合 List系列集合:添加的元素是有序,可重复,有索引 ArrayList: 添加的元素是有序,可重复,有索引LinkedList: 添加的元素是有序,可重复,有索引Vector :是线程安全的ÿ…...

linux服务器挂载硬盘/磁盘
1. 查看机器所挂硬盘个数及分区情况:fdisk -l可以看出来目前/dev/vda 目前有300G可用.内部有两个分区(/dev/vda1,/dev/vda2)。2. 格式化磁盘格式化磁盘命令为【mkfs.磁盘类型格式 目录路径组成】查看磁盘文件格式:df -T格式化磁盘…...

Java 抽象类
文章目录1、抽象方法和抽象类2、抽象类的作用当编写一个类时,常常会为该类定义一些方法,用于描述该类的行为方式,这些方法都有具体的方法体。但在某些情况下,某个基类只是知道其子类应该包含那些方法,但不知道子类是如…...
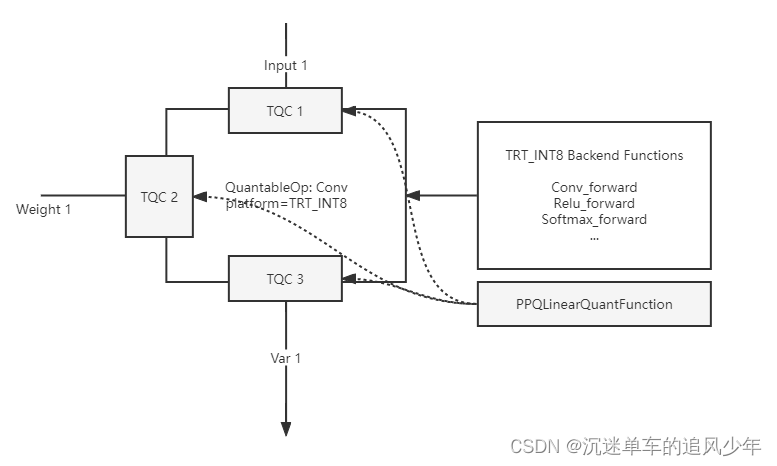
OpenPPL PPQ量化(5):执行引擎 源码剖析
目录 PPQ Graph Executor(PPQ 执行引擎) PPQ Backend Functions(PPQ 算子库) PPQ Executor(PPQ 执行引擎) Quantize Delegate (量化代理函数) Usage (用法示例) Hook (执行钩子函数) 前面四篇博客其实就讲了下面两行代码: ppq_ir load_onnx_graph(onnx_impor…...
【脚本开发】运维人员必备技能图谱
脚本(Script)语言是一种动态的、解释性的语言,依据一定的格式编写的可执行文件,又称作宏或批处理文件。脚本语言具有小巧便捷、快速开发的特点;常见的脚本语言有Windows批处理脚本bat、Linux脚本语言shell以及python、…...
N字形变换-力扣6-java
一、题目描述将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:P A H NA P L S I I GY I R之后,你的输出需要从左往右逐行读…...
)
概论_第5章_中心极限定理1__定理2(棣莫弗-拉普拉斯中心极限定理)
在概率论中, 把有关论证随机变量和的极限分布为正态分布的一类定理称为中心极限定理称为中心极限定理称为中心极限定理。 本文介绍独立同分布序列的中心极限定理。 一 独立同分布序列的中心极限定理 定理1 设X1,X2,...Xn,...X_1, X_2, ...X_n,...X1,X2,...Xn…...
详细解读503服务不可用的错误以及如何解决503服务不可用
文章目录1. 问题引言2. 什么是503服务不可用错误3 尝试解决问题3.1 重新加载页面3.2 检查该站点是否为其他人关闭3.3 重新启动设备3.3 联系网站4. 其他解决问的方法1. 问题引言 你以前遇到过错误503吗? 例如,您可能会收到消息,如503服务不可…...

【前端vue2面试题】2023前端最新版vue模块,高频17问(上)
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的关于vue2面试题(上) 目录 vue2面试题 1、$route 和 $router的区别 2、一个…...
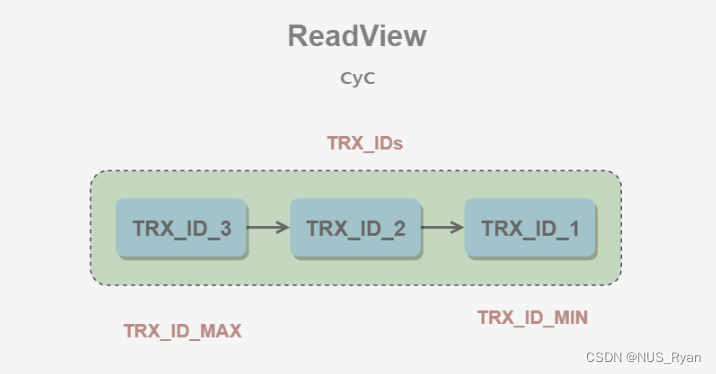
数据库(三):多版本并发控制MVCC,行锁的衍生版本,记录锁,间隙锁, Next-Key锁(邻键锁)
文章目录前言一、MVCC以及MVCC的缺点1.1 MVCC可以为数据库解决什么问题1.2 MVCC的基本思想1.3 版本号1.4 Undo日志1.5 ReadView1.6 快照读和当前读1.6.1 快照读1.6.2 当前读二、记录锁三、间隙锁四、邻键锁总结前言 一、MVCC以及MVCC的缺点 MVCC,即多版本并发控制…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...