英伟达SSD视觉算法模型训练、转换与部署
深度学习的训练和推理流程,是先采用高性能图形服务器使用深度学习框架来训练(Training)机器学习算法,研究大量的数据来学习一个特定的场景,完成后得到模型参数,再部署到终端执行机器学习推理(Inference),以训练好的模型从新数据中得出结论。
一般的深度学习项目,训练时为了加快速度,会使用多 GPU 分布式训练。但在部署推理时,为了降低成本,往往使用单个 GPU
机器甚至嵌入式平台进行部署。Jetson Nano 可以完成整个训练和推理流程,但基于 Jetson Nano 的低算力,不推荐在
Jetson Nano 上进行复杂训练,而仅用于推理。
- 在GPU服务器上使用pytorch训练模型得到pth模型文件;
- 将pth模型转化为onnx格式文件;
- Jetson Nano上利用tensorrt加载onnx模型,实现快速推理。
一、安装并编译jetson.inference
详情请看《英伟达SSD视觉算法,jetson.inference在jetson nano中部署》
二、下载PyTorch迁移学习的预训练模型
下载PyTorch迁移学习的预训练模型mobilenet-v1-ssd-mp-0_675.pth(若需要请到主页资源下载)
解压后放在jetson-inference/python/training/detection/ssd/models目录下
三、搭建训练环境
接下来有三种方式搭建训练环境
- 安装conda,然后用conda安装:
1)支持CUDA的pytorch版本,及其附加库(Torchvision、Torchaudio)
2)NVIDIA 提供的一组开发工具CUDA Toolkit,用于在 GPU 上进行高性能计算 - 用docker
torch + torchvision + opencv-python(只能训练模型,不能转换成onnx模型,不能跑模型)
第一种环境搭建方式,用conda搭建环境
创建一个 Conda 环境来运行训练和验证的脚本。Conda 环境可以更好地管理包依赖关系和不同项目之间的隔离。以下是如何使用 Conda 创建环境并安装所需依赖项的详细步骤。
1. 安装 Anaconda 或 Miniconda
Anaconda和Miniconda之间的主要区别体现在包含的软件包数量和种类上。
- Anaconda:
包含了大量的科学计算软件包,如numpy、pandas等,以及数据分析和数据可视化等180多个科学包及其依赖项。
提供了丰富的数据分析和机器学习库,适合数据科学、机器学习和大数据处理的用户。 由于包含了大量的软件包,因此安装文件相对较大。- Miniconda(推荐):
是一个小型的Anaconda,只包含了conda和一些必要的python包,没有包含大多数的科学计算包。
用户可以根据自己的需要安装不同的软件包,从而节省磁盘空间。 由于只包含核心功能,安装文件较小,下载和安装速度更快。总的来说,Anaconda和Miniconda都是基于conda的包管理和环境管理系统,但Anaconda预装了大量的科学计算软件包,适合需要这些软件包的用户;而Miniconda则更为轻量级,只包含核心功能,用户可以根据自己的需求灵活安装软件包。
Miniconda下载链接
Anaconda下载链接
下载的版本要和注意自己系统的架构对应!!!
2. 增加环境变量
1) 找到 Conda 的安装路径
通常,Miniconda 会安装到用户目录下的 Miniconda3 文件夹,例如:
Windows: C:\Users\Miniconda3
Mac/Linux: /home//miniconda3/ 或 /Users//miniconda3/
2)添加 Conda 到系统环境变量
Windows
打开系统属性:
右键点击 “此电脑” 或 “我的电脑”,选择 “属性”。
点击 “高级系统设置”。
点击 “环境变量”。
编辑 Path 变量:
在 “系统变量” 部分,找到并选择 Path 变量,然后点击 “编辑”。
点击 “新建”,然后添加 Miniconda 的安装路径,例如 C:\Users\Miniconda3 和 C:\Users\Miniconda3\Scripts。
确认并保存所有设置。
重新启动终端:
关闭并重新打开命令提示符或 PowerShell,以确保环境变量更新生效。
Mac/Linux
打开终端。
编辑 .bashrc 或 .zshrc 文件:
使用你喜欢的文本编辑器打开你的 shell 配置文件,例如:
nano ~/.bashrc # 如果你使用的是 Bash
nano ~/.zshrc # 如果你使用的是 Zsh
添加以下行:
export PATH="$HOME/miniconda3/bin:$PATH"
保存并关闭文件。
刷新配置文件:
source ~/.bashrc # 如果你使用的是 Bash
source ~/.zshrc # 如果你使用的是 Zsh
3)验证 conda 命令
打开新的终端窗口,并运行以下命令以验证 Conda 是否正确安装:
conda --version
如果一切正常,你应该会看到 Conda 的版本号。
2. 创建并激活 conda 环境:
conda create -n myenv python=3.11 # 选择 Python 版本取决于你的项目需求以及所使用的库的兼容性
conda init # 安装后首次使用conda需要先初始化,然后重新打开命令行窗口!!!
conda activate myenv
3. 用conda安装 PyTorch 和相关库:
conda install pytorch torchvision torchaudio cudatoolkit=11.8.0 -c pytorch -c nvidia
该命令一次性安装了 PyTorch 及其相关的计算机视觉和音频处理库,并且指定了 CUDA Toolkit 11.1 版本,使得这些库能够利用 NVIDIA GPU 进行加速计算。通过使用 -c pytorch 和 -c nvidia 选项,确保了从官方维护的频道安装最新版本的包,这有助于避免兼容性问题。
该命令通过 Conda 安装以下软件包和库:
- PyTorch (
pytorch):
一个开源的深度学习框架,由 Facebook 的人工智能研究团队开发。PyTorch 提供了张量计算(类似于 NumPy)以及强大的 GPU 加速能力,并且特别适合于动态计算图构建。 - Torchvision (
torchvision):
PyTorch 的一个附加库,专门用于处理计算机视觉任务。它包括了常用的数据集、模型结构和图像变换操作。 - Torchaudio (
torchaudio):
PyTorch 的另一个附加库,专门用于音频处理任务。它提供了常用的音频 I/O、信号处理和转换功能。 - CUDA Toolkit (
cudatoolkit=11.1):
NVIDIA 提供的一组开发工具,用于在 GPU 上进行高性能计算。指定cudatoolkit=11.1表示要安装 CUDA Toolkit 11.1 版本,这个工具包提供了运行 GPU 加速代码所需的库和工具。
具体作用
-c pytorch:
指定从pytorch频道安装软件包。这个频道由 PyTorch 官方维护,包含最新的 PyTorch 及其相关库。-c nvidia:
指定从nvidia频道安装软件包。这个频道由 NVIDIA 官方维护,包含 CUDA Toolkit 和其他与 GPU 计算相关的软件包。
安装内容的详细描述
- PyTorch (
pytorch):
核心库,用于深度学习模型的构建、训练和推理。它支持 CPU 和 GPU 计算,并且提供了丰富的 API 进行张量操作、自动微分、优化等。 - Torchvision (
torchvision):
提供了常用的计算机视觉数据集(如 ImageNet、CIFAR-10)、预训练模型(如 ResNet、AlexNet)和图像变换操作(如随机裁剪、归一化)。 - Torchaudio (
torchaudio):
提供了音频数据集(如 LibriSpeech)、音频 I/O 操作(如读取和保存音频文件)和信号处理操作(如频谱分析、重采样)。 - CUDA Toolkit (
cudatoolkit=11.1):
包含用于 GPU 加速计算的库(如 cuBLAS、cuDNN),以及编译和调试 GPU 代码的工具(如 nvcc、cuda-gdb)。
可能出现的问题
1.当前的 Conda 频道中没有找到 cudatoolkit的版本
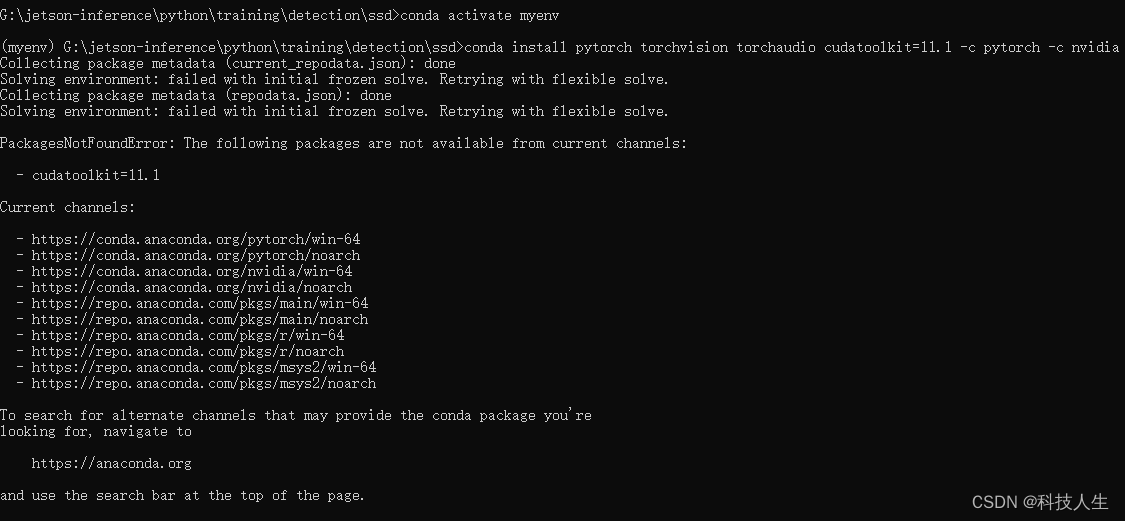
解决方法:检查当前可用的 CUDA Toolkit 版本,看看是否有其他版本可用:
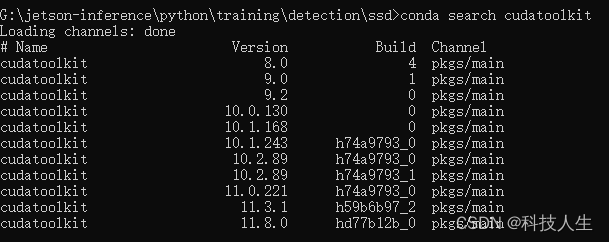
conda search cudatoolkit
2. 长时间等待

解决方法:
长时间等待的情况可能是由于多个原因导致的,包括网络问题、依赖冲突或者 Conda 本身的问题。可以通过检查网络连接、更新 Conda、使用 libmamba solver 或者 mamba 替代 conda,以及创建新的环境,可以提高成功安装的概率。这些方法应能帮助你解决长时间等待的问题,并成功安装所需的包。
以下是一些排查和解决方法:
1. 检查网络连接
确保你的网络是稳定的,可以尝试切换到一个更稳定的网络环境,或者使用 VPN 来加速连接。
2. 更新 Conda
确保你使用的是最新版本的 Conda:
conda update conda
3. 更改 Conda 的 Solver
Conda 提供了两个 solver:classic 和 libmamba。libmamba 通常速度更快,可以尝试切换到 libmamba:
conda install -n base conda-libmamba-solver
conda config --set solver libmamba
然后再尝试安装。
如果你已经切换到 libmamba 作为 Conda 的 solver,但现在希望切换回 classic solver,可以按照以下步骤操作:
打开命令行终端,并确保已经激活了你的 Conda 环境。
使用以下命令将 solver 切换回 classic:
conda config --set solver classic
验证 Solver 切换
你可以通过查看 Conda 配置文件来验证 solver 是否已经切换:
conda config --show solver
如果输出是 classic,则说明切换已经成功。
4. 使用 Mamba
如前所述,mamba 是一个更快、更高效的包管理工具,可以用来替代 conda。你可以先安装 mamba,然后使用它来安装所需的包:
conda install mamba -n base -c conda-forge
mamba install pytorch torchvision torchaudio cudatoolkit=11.8.0 -c pytorch -c nvidia
5. 手动指定包版本
有时候,手动指定所有包的版本可以减少依赖冲突:
conda install pytorch=1.8.0 torchvision=0.9.0 torchaudio=0.8.0 cudatoolkit=9.2 -c pytorch -c nvidia
6. 使用新的环境
如果当前环境有问题,可以尝试创建一个新的 Conda 环境:
conda create -n newenv python=3.8
conda activate newenv
conda install pytorch torchvision torchaudio cudatoolkit=9.2 -c pytorch -c nvidia
下面是更改 Conda 的 Solver解决的例子:
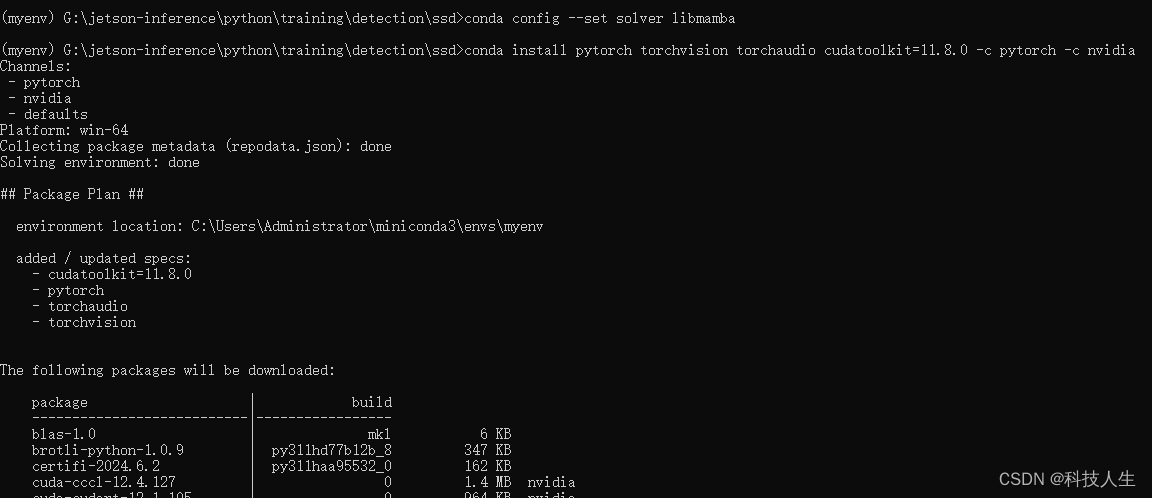
通过上述步骤,你应该能够成功创建 Conda 环境并运行你的脚本。这样可以更好地管理包依赖关系和项目隔离。
用venv和conda两个工具创建的虚拟环境的区别 如:python3 -m venv myenv 和 conda create -n myenv python=3.11
python3 -m venv myenv使用的是 Python 内置的 venv 模块来创建虚拟环境,而conda create -n myenv python=3.11使用的是 Anaconda 或 Miniconda 中的 conda
工具来创建环境。 使用venv创建的虚拟环境是基于标准的 Python 环境,只包含 Python
解释器和标准库,不包含其他第三方包。而使用conda创建的环境是基于 Anaconda 或 Miniconda 发行版,会包含
conda 包管理器以及一些常用的科学计算和数据处理库。- 虚拟环境的管理方式也有所不同。使用
venv创建的虚拟环境需要通过激活脚本来激活,然后使用pip来安装依赖包。而使用conda创建的环境可以通过conda activate命令来激活,使用conda
来安装和管理依赖包。总的来说,如果您只需要一个轻量级的虚拟环境,并且不需要额外的科学计算库,可以使用 python3 -m venv myenv。如果您需要使用
Anaconda 或 Miniconda 提供的额外功能和库,可以使用 conda create -n myenv
python=3.11。选择哪种方式取决于您的具体需求和偏好。
虚拟环境知识拓展
激活并在虚拟环境中安装软件包的方式
-
conda创建的虚拟环境
激活虚拟环境
在 Windows 上,使用conda activate myenv
在 MacOS/Linux 上,使用source activate myenv
安装软件包
使用 conda 安装:conda install opencv-python
使用 pip 安装:pip install opencv-python
查看已安装的包列表:conda list
搜索特定包是否已安装:conda list | grep package_name
退出当前conda环境:conda deactivate -
venv创建的虚拟环境
激活虚拟环境
在 Windows 上,使用/path/to/your/venv/Scripts/activate
在 MacOS/Linux 上,使用source /path/to/your/venv/bin/activate
安装软件包
使用 pip 安装:pip install opencv-python
查看已安装的包列表:pip list
搜索特定包是否已安装:pip list | grep package_name
退出当前venv环境:deactivate
虚拟环境复制
相关文章:
英伟达SSD视觉算法模型训练、转换与部署
深度学习的训练和推理流程,是先采用高性能图形服务器使用深度学习框架来训练(Training)机器学习算法,研究大量的数据来学习一个特定的场景,完成后得到模型参数,再部署到终端执行机器学习推理(Inference),以训练好的模型从新数据中得出结论。 一般的深度学习项目,训练…...

智能变电站网络报文记录及故障录波分析装置
是基于Intel X86、PowerPC、FPGA等技术的高度集成化的硬件平台,采用了高性能CPU无风扇散热、网络数据采集、高速数据压缩存储加密等多种技术,实现了高性能计算、多端口同步高速数据采集、数据实时分析、大容量数据存储等功能。 ● 在满足工业标准的同时&…...

npm ERR! code E404 npm ERR! 404 Not Found - GET https://registry.npmjs.org/
npm ERR! code E404 npm ERR! 404 Not Found - GET https://registry.npmjs.org/ 📜 智能合约依赖下载失败的解决方案摘要引言正文内容1. 场景描述 🤔2. 可能原因分析2.1 包不存在或名称错误2.2 网络问题2.3 npm配置错误 3. 解决方案🛠️3.1 …...
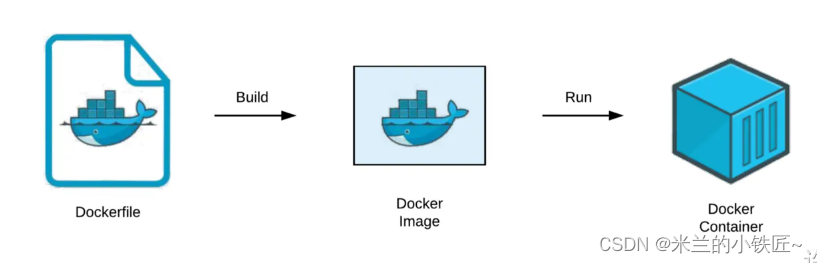
Dockerfille解析
用于构建Docker镜像的文本,由一条条指令构成 Docker执行Dockerfile的流程 1. Docker从基础镜像执行一个容器 2. 执行一条指令并对容器进行修改 3. 执行类型Docker commit的命令添加一个新的镜像层 4. Docker再基于新的镜像执行一个新的容器 5. 执行Dockerfile中…...

定个小目标之刷LeetCode热题(14)
了解股票的都知道,只需要选择股票最低价格那天购入,在股票价格与最低价差值最大时卖出即可获取最大收益,总之本题只需要维护两个变量即可,minPrice和maxProfit,收益 prices[i] - minPrice,直接用代码描述如下 class …...
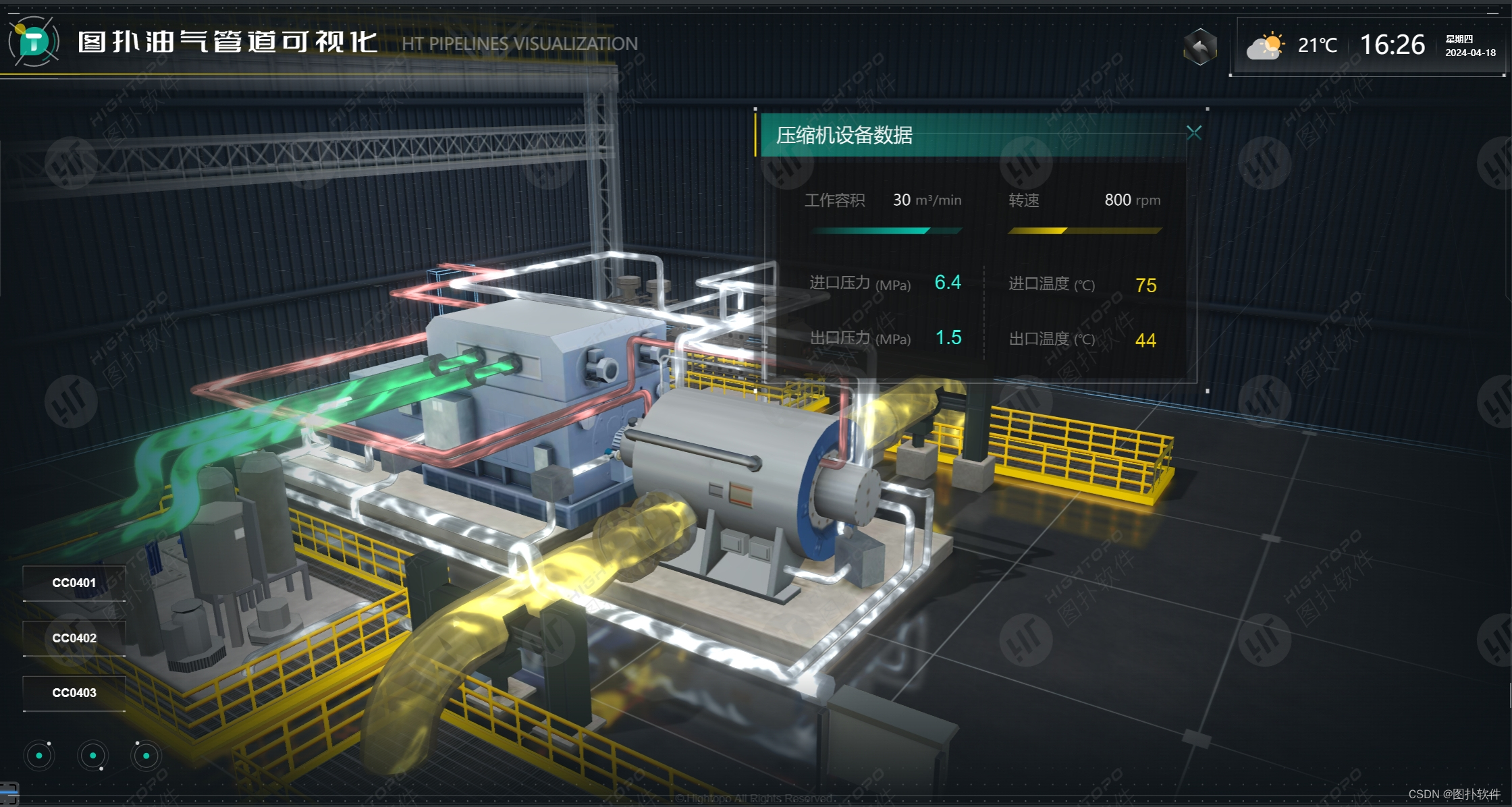
智慧管道管理:油气管道可视化的领先应用
通过图扑油气管道可视化技术,实现实时监控与数据分析,快速识别潜在风险,有效提升管道维护效率和安全性能。...

嵌入式仪器模块:示波器模块和自动化测试软件
示波器模块 • 32 位分辨率 • 125 MSPS 采样率 • 支持单通道/双通道模块选择 • 低速模式可实现实时功率分布和整机功率检测 • 高速模式可实现信号分析和上电时序测量 应用场景 • 抓取并分析波形的周期、幅值、异常信号等指标 • 电源纹波与噪声分析 • 信号模板比…...
组装服务器重装linux系统【idrac集成戴尔远程控制卡】
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专…...

景区ar互动大屏游戏化体验提升营销力度
从20世纪60年代的初步构想,到如今全球范围内无数企业的竞相投入,AR增强现实技术已成为引领科技潮流的重要力量。而在这一浪潮中,中国的AR公司正以其独特的魅力和创新力,崭露头角。 中国的AR市场正在迎来前所未有的发展机遇。如今&…...
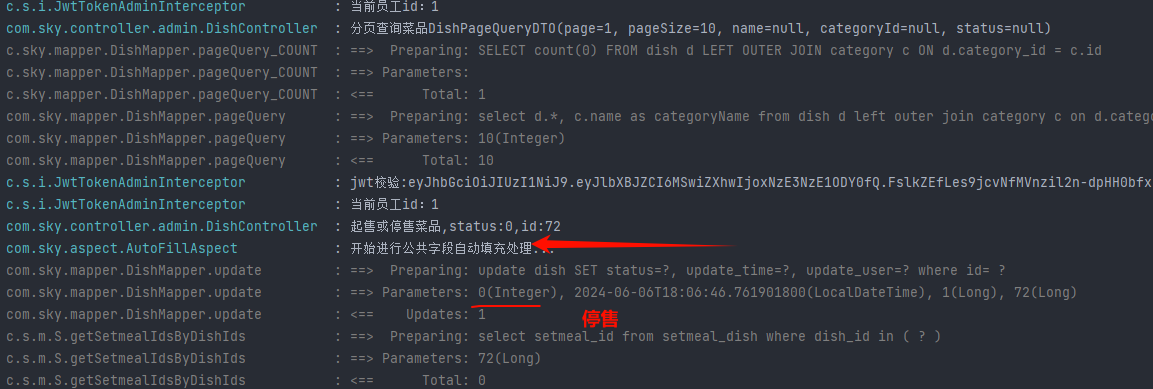
苍穹外卖笔记-07-菜品管理-增加、删除、修改、查询分页还有菜品起售或停售状态
菜品管理 1 新增菜品1.1 需求分析与设计1.2 代码开发文件上传新增菜品实现 1.3 功能测试 2 菜品分页查询2.1 需求分析和设计2.2 代码开发设计DTO类设计VO类Controller层Service层Mapper层 2.3 功能测试 3 删除菜品3.1 需求分析和设计3.2 代码开发Controller层Service层Mapper层…...

oracle dataguard 从库 MRP 进程的状态是 WAIT_FOR_GAP
因主库归档日志未备份直接删除后,从库不能更新,19c版本以上,之前未打补丁,使用 RECOVER STANDBY DATABASE FROM SERVICE PRM180;之后,在执行 alter database recover managed standby database using current logfil…...

【C语言】轻松拿捏-联合体
谢谢观看!希望以下内容帮助到了你,对你起到作用的话,可以一键三连加关注!你们的支持是我更新地动力。 因作者水平有限,有错误还请指出,多多包涵,谢谢! 联合体 一、联合体类型的声明二…...

基于Python定向爬虫技术对微博数据可视化设计与实现
基于Python定向爬虫技术对微博数据可视化设计与实现 Design and Implementation of Weibo Data Visualization Based on Python Web Scraping Techniques 完整下载链接:基于Python定向爬虫技术对微博数据可视化设计与实现 文章目录 基于Python定向爬虫技术对微博数据可视化设…...

【QT5】<总览三> QT常用控件
文章目录 前言 一、QWidget---界面 二、QPushButton---按钮 三、QRadioButton---单选按钮 四、QCheckBox---多选、三选按钮 五、margin&padding---边距控制 六、QHBoxLayout---水平布局 七、QVBoxLayout---垂直布局 八、QGridLayout---网格布局 九、QSplitter---…...
)
Python中的生成器表达式(generator expression)
Python中的生成器表达式(generator expression)是一种类似于列表解析(list comprehension)的语法结构,但它返回的是一个生成器(generator)对象,而不是一个完整的列表。生成器对象是一…...
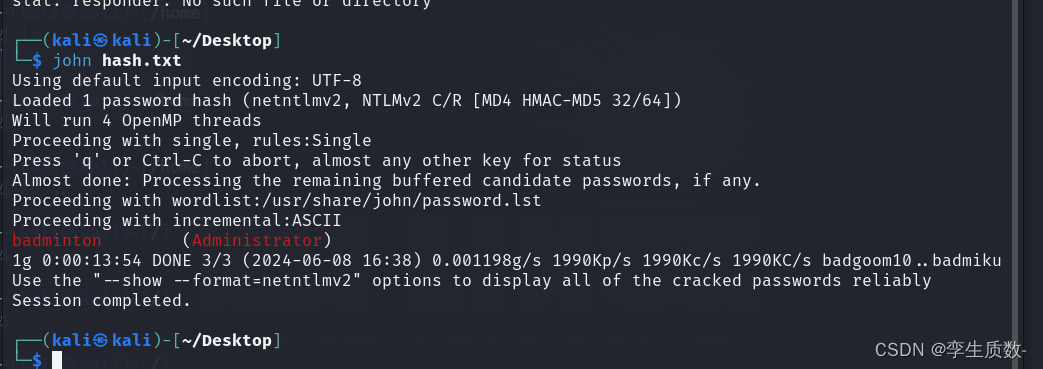
Responder工具
简介 Responder是一种网络安全工具,用于嗅探和抓取网络流量中的凭证信息(如用户名、密码等)。它可以在本地网络中创建一个伪造的服务(如HTTP、SMB等),并捕获客户端与该服务的通信中的凭证信息。 Responder工…...
gitblit 环境搭建,服务器迁移记录
下载 Gitblit: http://www.gitblit.com/ JDK:gitblit网站显示需要jdk1.7,这里用的1.8。 Git:到官网下载最新版本安装 1). 分别安装JDK,Git,配置环境变量,下载并解压Gitblit 2). 创建代码仓库 …...
硬盘坏了数据能恢复吗 硬盘数据恢复一般多少钱
在数字化时代,我们的生活和工作离不开电脑和硬盘。然而,硬盘故障是一个常见的问题,可能会导致我们的数据丢失。当我们的硬盘坏了,还能恢复丢失的数据吗?今天我们就一起来探讨关于硬盘坏了数据能恢复吗,硬盘…...
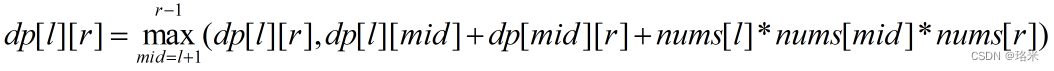
312. 戳气球 Hard
有 n 个气球,编号为0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。 现在要求你戳破所有的气球。戳破第 i 个气球,你可以获得 nums[i - 1] * nums[i] * nums[i 1] 枚硬币。 这里的 i - 1 和 i 1 代表和 i 相邻…...

推荐4个好用有趣的软件
MyComic——漫画聚合软件 MyComic是一款界面简洁、分类详尽的漫画阅读软件,专为动漫爱好者设计。它提供了丰富的高清漫画资源,支持在线免费阅读,并且可以一键下载到书架,方便随时离线观看,节省流量。用户可以轻松找到喜…...

【Blender进阶】VSCode调试大型项目:从模块导入到参数解析的实战避坑指南
1. 为什么需要VSCode调试Blender大型项目 当你刚开始接触Blender脚本开发时,可能习惯直接在Blender内置的文本编辑器中编写和测试代码。这种方式对于简单的单文件脚本还算方便,但随着项目规模扩大,你会遇到几个明显的痛点: 首先&a…...
-波士顿房价预测与加州房价预测对比)
学习记录:机器学习入门案例——波士顿房价预测(三)-波士顿房价预测与加州房价预测对比
2026年4月7日波士顿房价预测与加州房价预测都已经运行成功,不禁疑惑,二者都是线性回归模型,有什么区别呢。一、核心共同点:骨架完全相同从代码层面看,这两个例子本质上执行的是同一套工作流程,这也是任何机…...
)
SAP ME21N采购订单增强报错?手把手教你调试ME_PROCESS_PO_CUST(附完整代码)
SAP ME21N采购订单增强报错全流程诊断指南 当SAP系统中的ME21N采购订单增强突然报错时,那种面对红色错误消息却无从下手的挫败感,每个ABAP开发者都深有体会。不同于普通的程序错误,ME_PROCESS_PO_CUST这类标准增强点的报错往往涉及采购订单核…...
)
团队协作效率提升:用私有NuGet仓库+自定义路径管理.NET组件依赖(实战演示)
团队协作效率提升:用私有NuGet仓库自定义路径管理.NET组件依赖(实战演示) 在现代化软件开发中,依赖管理是团队协作的核心痛点之一。想象一下:当五位开发者分别使用不同路径的NuGet包,或者CI/CD流水线因为路…...

SEO 优化自学常见的误区有哪些
SEO 优化自学常见的误区有哪些 在互联网时代,SEO(搜索引擎优化)已经成为了提升网站流量和品牌知名度的关键。对于很多自学SEO的人来说,常常会犯一些错误,导致他们的努力难以见到实际效果。本文将详细探讨SEO 优化自学…...

手把手教你用GrsAi的Webhook和轮询,搞定GPT Image 1.5的异步图片生成任务
实战指南:基于GrsAi构建高可靠异步图像生成系统 当你的应用需要处理大量图像生成请求时,同步调用API往往会遇到超时、连接不稳定等问题。我曾在一个电商项目中使用同步调用,结果在促销高峰期系统频繁崩溃——直到改用异步架构才彻底解决问题。…...

艾尔登法环帧率解锁终极指南:告别60FPS限制的完整方案
艾尔登法环帧率解锁终极指南:告别60FPS限制的完整方案 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Eld…...

物联网新手避坑指南:用MQTT.fx 1.7.1连接OneNET平台,从数据上报到命令下发的完整流程
物联网开发实战:MQTT.fx与OneNET平台深度对接指南 第一次打开MQTT.fx时,面对密密麻麻的配置项和晦涩的协议术语,大多数物联网初学者都会感到无从下手。这就像刚拿到驾照就让你开F1赛车——工具很强大,但学习曲线陡峭。本文将带你用…...

2026年SCI论文AI率要求5%以下?这3款降AI工具期刊场景亲测
投了一篇SCI二区,被审稿人指出AI率超标,编辑直接打回来要求修改。那是去年的事,折腾了我快两个月。 事情的起因很简单:我用DeepSeek辅助写了大量段落,初稿AI率检测下来68%,远超期刊要求的10%以下。降下去的…...

别再死记硬背背包问题公式了!用‘小偷逛博物馆’的故事带你手写递归C++代码
当小偷逛博物馆遇上背包问题:用故事解锁递归思维 推开厚重的博物馆大门,昏暗的灯光下陈列着五件稀世珍宝。作为一名"专业"小偷,你只有一个承重20公斤的背包,每件藏品都有独特的重量和价值。如何在有限负重下最大化收益&…...