【数据结构】 -- 堆 (堆排序)(TOP-K问题)
引入
要学习堆,首先要先简单的了解一下二叉树,二叉树是一种常见的树形数据结构,每个节点最多有两个子节点,通常称为左子节点和右子节点。它具有以下特点:
- 根节点(Root):树的顶部节点,没有父节点。
- 子节点(Children):每个节点最多有两个子节点,分别称为左子节点和右子节点。
- 叶子节点(Leaf):没有子节点的节点称为叶子节点。
- 父节点(Parent):每个节点都有一个父节点,除了根节点。
- 深度(Depth):从根节点到某个节点的唯一路径的长度,根节点的深度为0。
- 高度(Height):从某个节点到它的最远叶子节点的路径长度,叶子节点的高度为0。
- 遍历(Traversal):遍历二叉树是指按照一定顺序访问树中的每个节点,常见的遍历方式包括前序遍历、中序遍历和后序遍历。
二叉树的应用非常广泛,在后面我会详细介绍。
满二叉树:除了叶子结点外,每个结点都有两个子结点
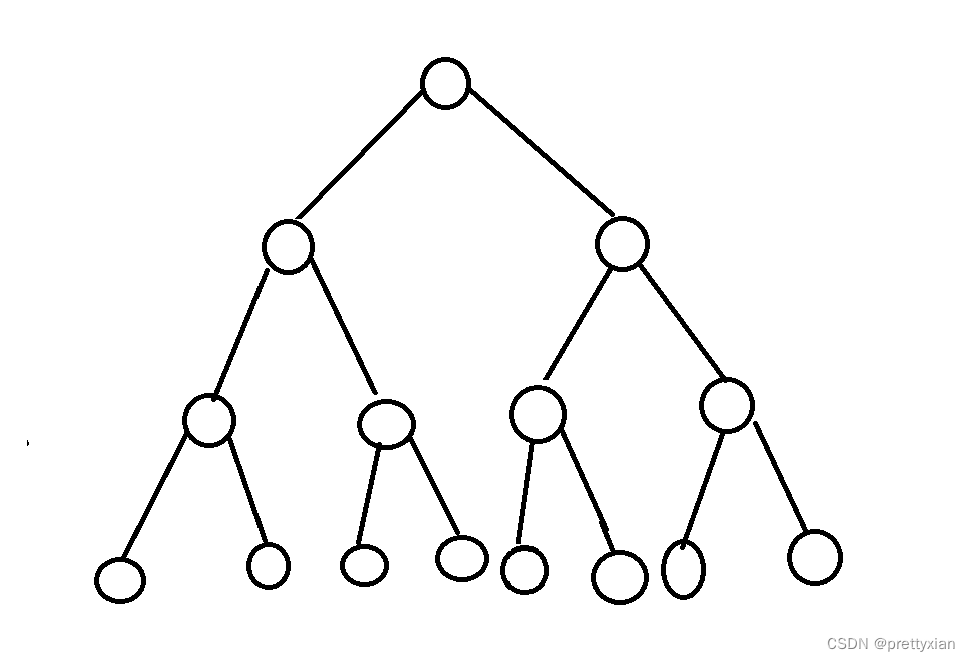
一个深度为k的满二叉树有2的k次方减一个节点。
完全二叉树:除了最底层可能不是满的外,其它每一层从左到右都是满的。
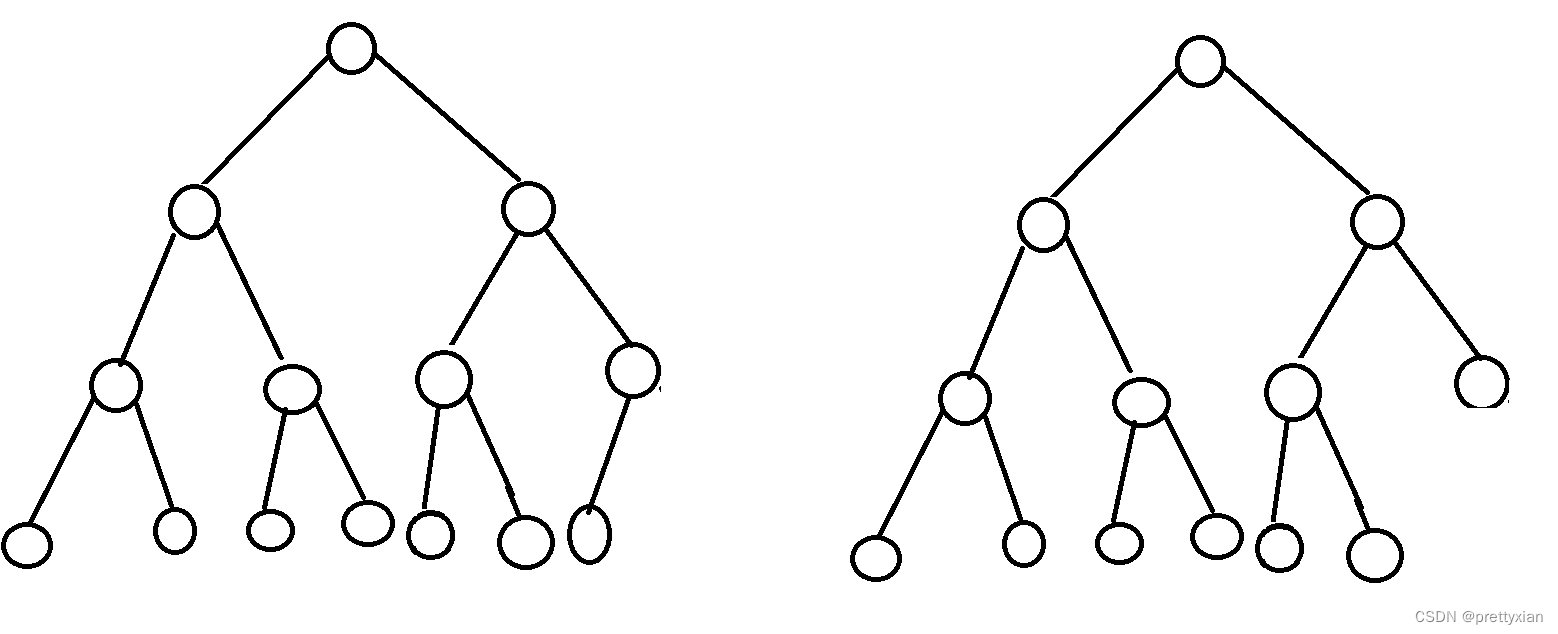
满二叉树是完全二叉树的子集,满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
堆就是一种完全二叉树。
二叉树的储存
逻辑结构和物理结构
逻辑结构和物理结构是计算机科学中两个重要的概念,它们描述了数据在计算机中的不同组织方式。
-
逻辑结构:
- 逻辑结构是指数据元素之间的相互关系和操作规则。它关注的是数据之间的逻辑关联,而不考虑数据在计算机内部的存储方式。
- 常见的逻辑结构包括线性结构、树形结构和图形结构。
- 线性结构中的数据元素之间是一对一的关系,例如线性表、栈、队列等。
- 树形结构中的数据元素之间存在一对多的关系,例如二叉树、B树等。
- 图形结构中的数据元素之间是多对多的关系,例如图、网络等。
-
物理结构:
- 物理结构描述了数据在计算机内部存储的方式和组织形式,也称为存储结构。
- 物理结构与计算机的存储器相关,它包括了数据元素在内存中的存储位置和存储方式。
- 常见的物理结构包括顺序存储结构和链式存储结构。
- 顺序存储结构是将数据元素连续地存储在内存中的一块连续的存储空间中,例如数组。
- 链式存储结构是通过指针将数据元素存储在内存中的不同位置,并通过指针将它们串联起来,例如链表。
逻辑结构关注数据之间的逻辑关系和操作规则,而物理结构关注数据在计算机内部的实际存储方式和组织形式。
二叉树的储存
二叉树有多种存储方式,常见的包括顺序存储和链式存储。
-
顺序存储: 顺序存储通常使用数组来表示二叉树。假设树的根节点存储在数组下标为0的位置,则对于任意一个下标为i的节点:
- 其左子节点的下标为2i + 1
- 其右子节点的下标为2i + 2 例如,如果要存储二叉树的节点值为[1, 2, 3, 4, 5, 6, 7]的完全二叉树,可以使用数组[1, 2, 3, 4, 5, 6, 7]进行存储。
-
链式存储: 链式存储则是通过节点之间的引用来表示二叉树的结构,每个节点包含数据域和左右子节点指针域。
链式储存我们放在后边更新,在这里我们先学习顺序储存。
顺序储存
顺序储存用数组来储存,顺序存储一般只适合用来存储完全二叉树(堆),用顺序储存再存储非完全的二叉树会存在空间浪费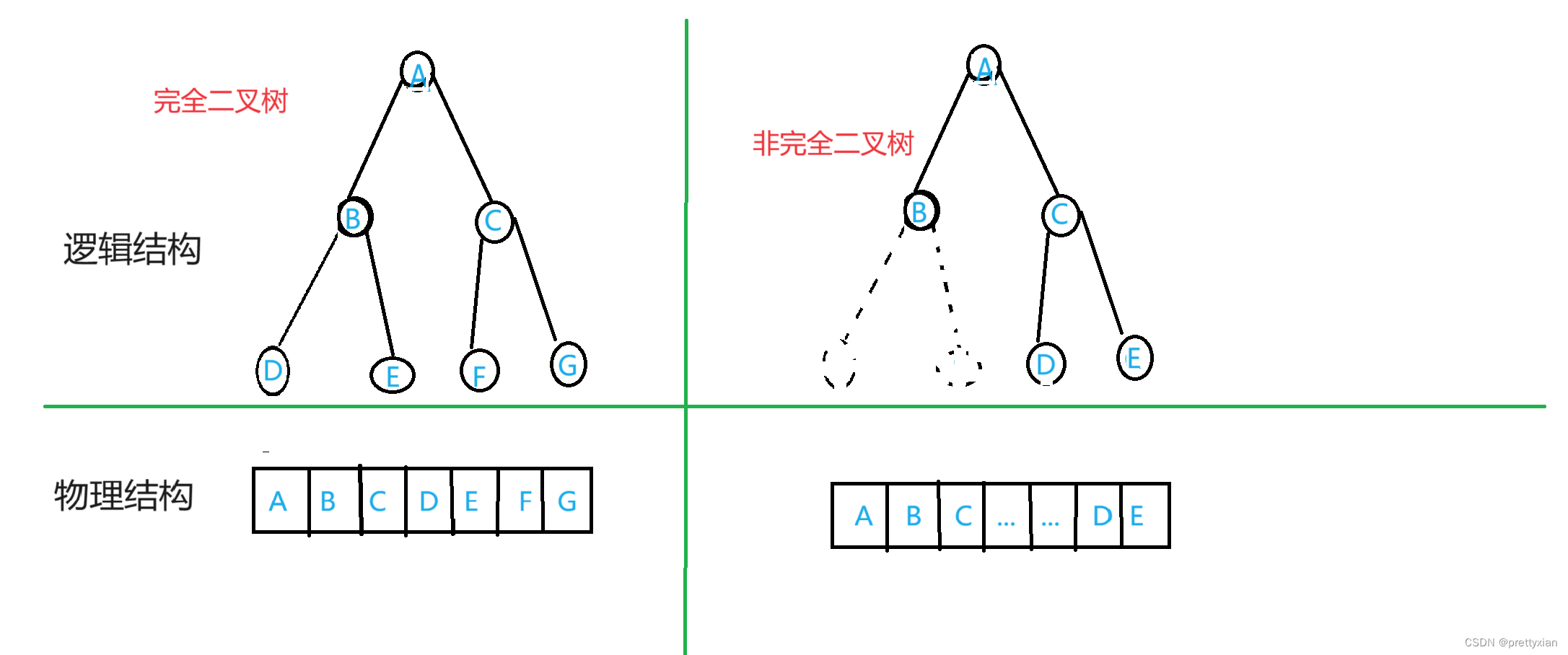
堆的实现
头文件:
#define _CRT_SECURE_NO_WARNINGS 1#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <stdbool.h>typedef int HPDatatype;typedef struct Heap
{HPDatatype * a;int size;int capacity;}HP;//初始化
void HPInit(HP* php);//插入数据
void HPPush(HP* php, HPDatatype x);//交换
void Swap(HPDatatype* a,HPDatatype * b);//销毁
void HPDestroy(HP* php);//向上调整
void AdjustUp(HPDatatype* a, int child);//向下调整
void AdjustDown(HPDatatype* a,int n, int parent);//删除顶部数据
void HPPop(HP* php);//返回顶部数据
HPDatatype* HPTop(HP* php);//判空
bool HPEmpty(HP* php);实现文件:
#define _CRT_SECURE_NO_WARNINGS 1
#include "Heap.h"// 初始化
void HPInit(HP* php)
{assert(php);php->a = NULL;php->capacity = php->size = 0;}//插入数据
void HPPush(HP* php, HPDatatype x)
{assert(php);//判断空间够不够if (php->capacity == php->size){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDatatype* tmp = (HPDatatype* )realloc(php->a,newcapacity * sizeof(HPDatatype));if (tmp == NULL){perror("realloc fail");exit(-1);}php->capacity = newcapacity;php->a = tmp;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size - 1);
}//交换
void Swap(HPDatatype* a, HPDatatype* b)
{HPDatatype cmp = *a;*a = *b;*b = cmp;
}//销毁
void HPDestroy(HP* php)
{assert(php);free(php->a);php->a = NULL;php->capacity = php->size = 0;
}//向上调整
void AdjustUp(HPDatatype* a, int child)
{int parent = (child - 1) / 2;while (child > 0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}//向下调整
void AdjustDown(HPDatatype* a, int n, int parent)
{int child = 2 * parent + 1;//先假设左边的小while (child < n){if (child + 1 < n && a[child + 1] < a[child])//规避chlid + 1 越界的风险{child++;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}else{break;}}}//删除顶部数据
void HPPop(HP* php)
{assert(php);assert(php->size > 0);Swap(&php->a[0], &php->a[php->size - 1]);php->size--; AdjustDown(php->a, php->size,0);
}//返回顶部数据
HPDatatype* HPTop(HP* php)
{assert(php);assert(php->size > 0);return php->a[0];
}//判空
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}TOP-K问题
一般来说,堆分为两类
-
大堆(Max Heap):在最大堆中,每个节点的值都大于或等于其子节点的值。换句话说,堆顶部的元素是整个堆中的最大值。最大堆常用于实现优先队列,其中具有最高优先级的元素始终位于堆顶。
-
小堆(Min Heap):在最小堆中,每个节点的值都小于或等于其子节点的值。因此,堆顶部的元素是整个堆中的最小值。最小堆也常用于优先队列,其中具有最低优先级的元素位于堆顶。
简单来说大堆中,同一个分支中大的在上;小堆中,同一分支小的在上。
在这里以小堆为例:
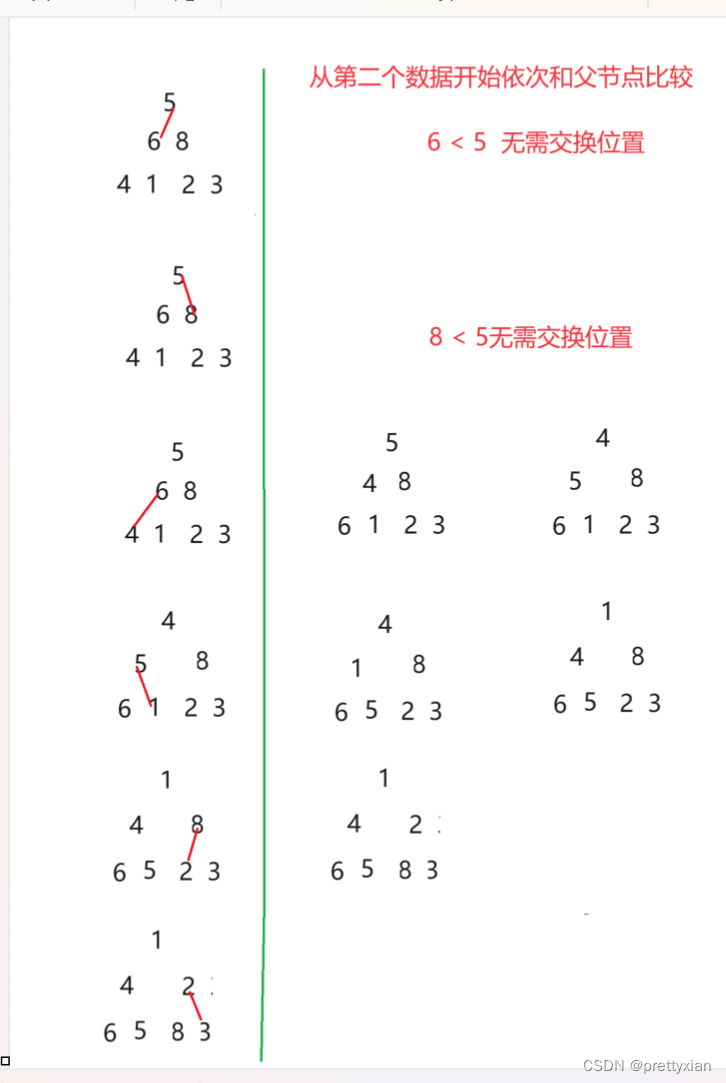
向上调整算法
往堆中插入一个数据时,先将插入的数据放到堆的最后一个节点,然后利用向上调整算法依次调整。
图示:
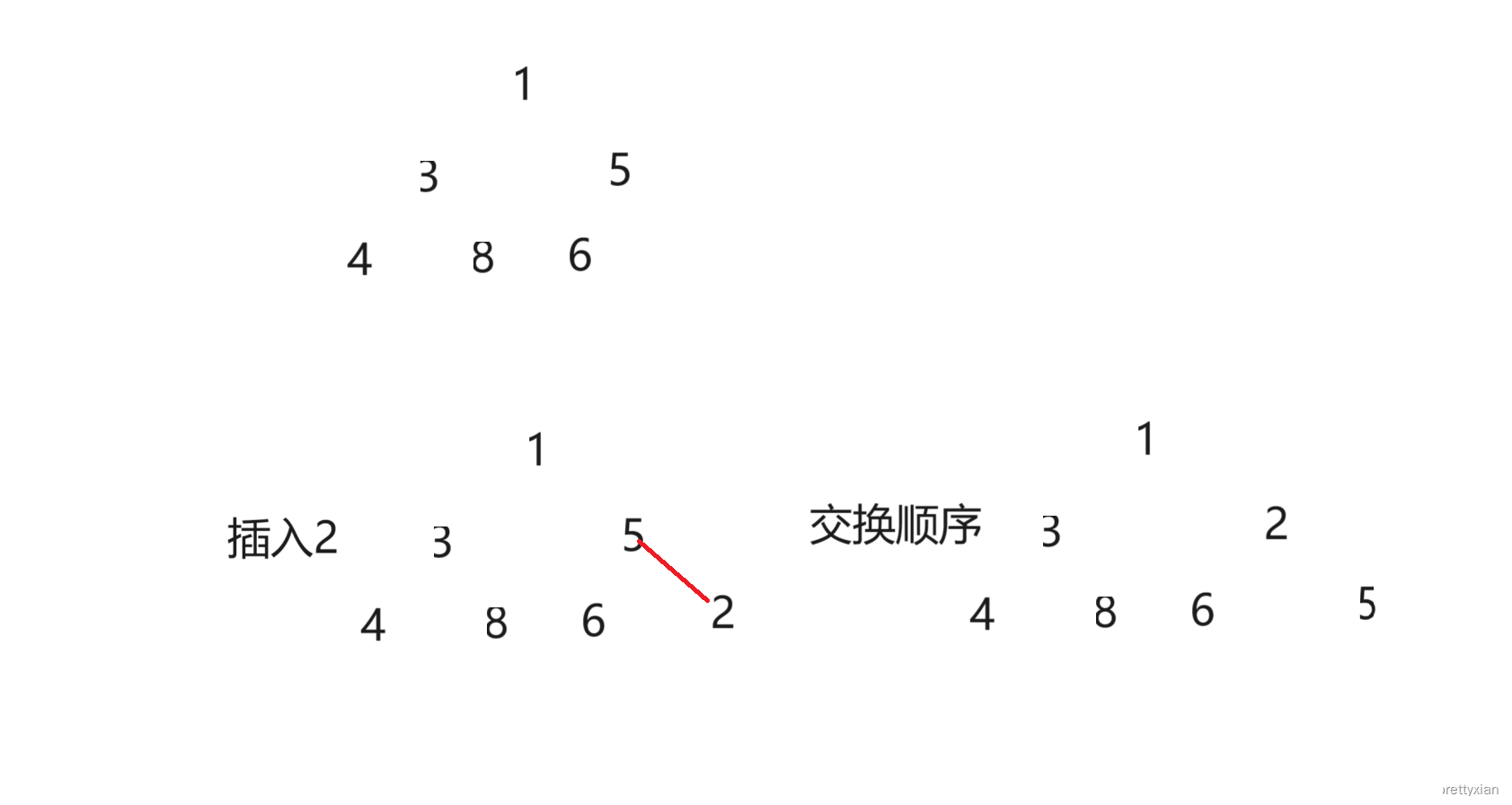
只要子节点不越界循环一直进行,当字节点不小于父节点时跳出if()语句进入else,跳出循环。
//向上调整
void AdjustUp(HPDatatype* a, int child)
{int parent = (child - 1) / 2;while (child > 0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
求一堆数据(储存在小堆中)中最最小的前几个数据:将数据插入堆中,小堆的堆顶中储存的就是堆中最小的数据,把堆顶的数据取下来,再将堆顶的数据释放;用向上调整算法调整堆,再依次取堆顶,重复。
//TOP-K
void HPtest02()
{int a[] = { 5,6,1,4,2,8 };HP s;HPInit(&s);for (size_t i = 0; i < sizeof(a) / sizeof(int); i++){HPPush(&s, a[i]);}int k = 0;scanf("%d", &k);while (k--){printf("%d ", HPTop(&s));HPPop(&s);}HPDestroy(&s);
}int main()
{HPtest02();return 0;
}演示:
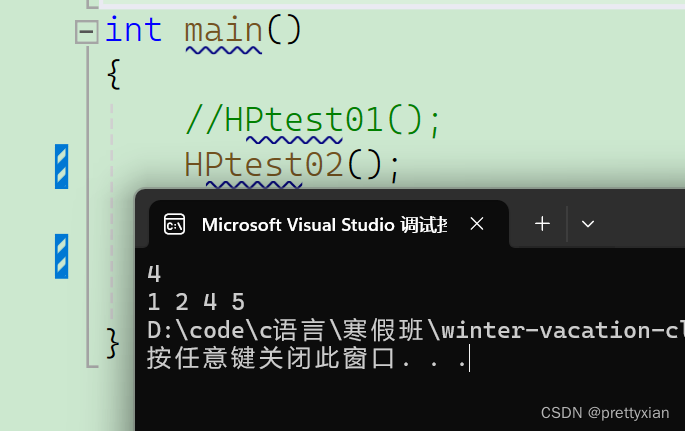
在TOP-K问题中,我们会发现,输出的数据是按顺序拍好的,那么我们可不可以在此基础上进行排序呢。 把数据储存到堆中之后,再依次拿出来。
//排序
void HPtest03()
{int a[] = { 5,6,1,4,2,8 };HP s;HPInit(&s);for (size_t i = 0; i < sizeof(a) / sizeof(int); i++){HPPush(&s, a[i]);}int i = 0;while (!HPEmpty(&s)){a[i++] = HPTop(&s);HPPop(&s);}HPDestroy(&s);
}
int main()
{HPtest03();return 0;
}这样我们就可以对数据进行排序。
这个算法的时间复杂度非常低 。 一个有k个节点的对的深度为log(k),一条分支最多交换log (k) - 1次,所以
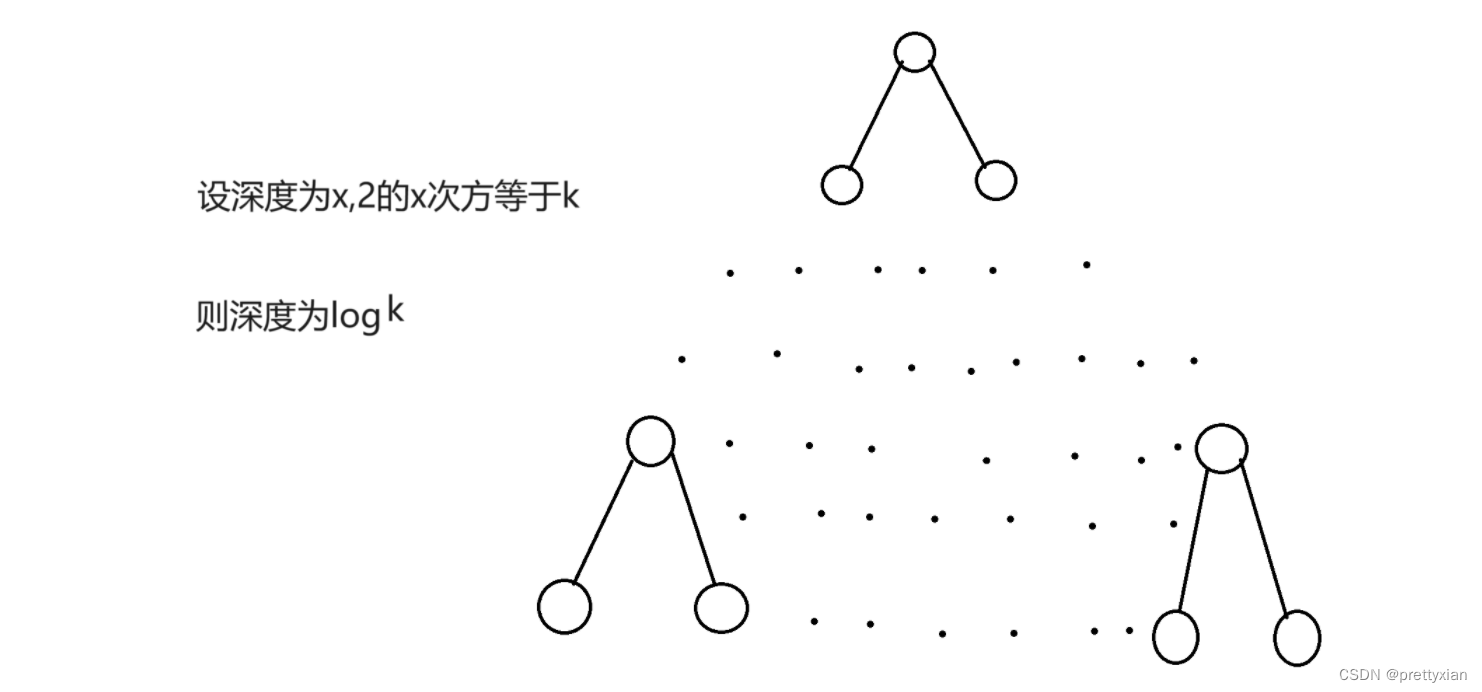
算法的时间复杂度为log N。 但是这并不能称作真正的排序,因为它在原数组的基础上开辟了新的空间。
堆排序
建堆算法
//堆排序
void HeapSort(int* a, int n)
{//建堆for (int i = 1; i < n; i++){AdjustUp(a, i);}
}void Heaptset()
{int a[] = { 5,6,8,4,1,2,3 };HeapSort(a, 7);
}
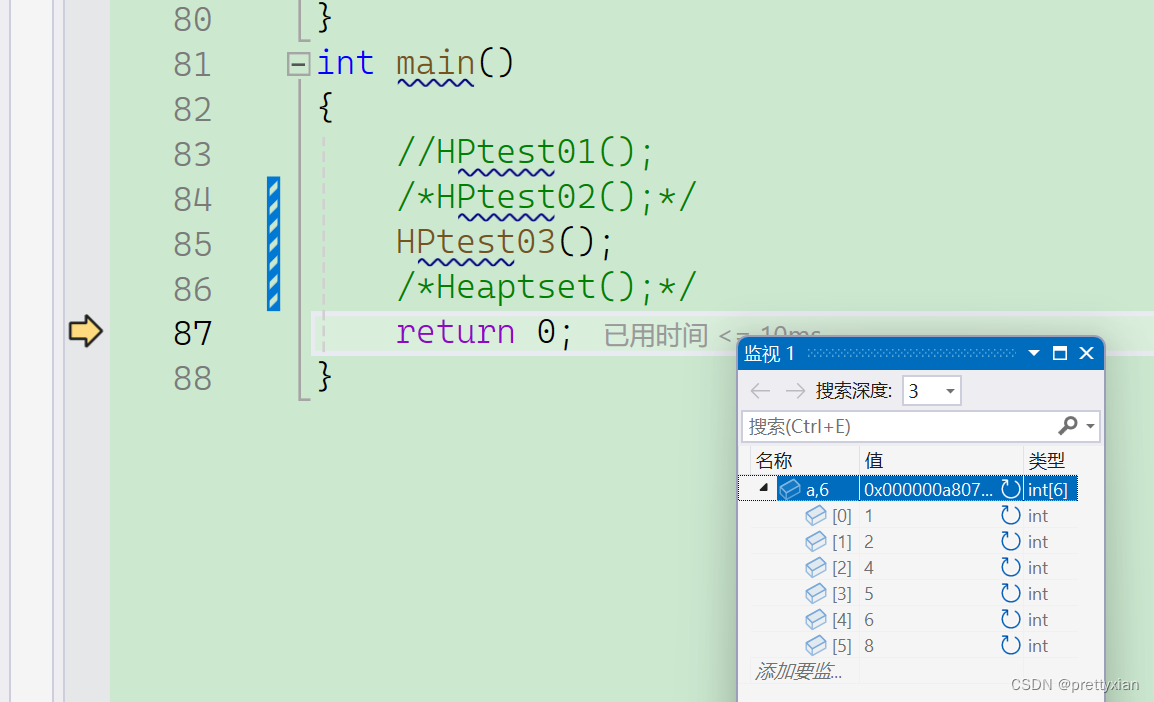
int main()
{//HPtest01();/*HPtest02();*///HPtest03();Heaptset();return 0;
}
排序
在惯性思维中,要排降序应该会建大堆,排升序会建小堆。但这样会导致一个问题(以建排降序 为建小堆为例)

小堆的堆顶为这组数据中最小的数,我们将它取出,作为排序的第一个数
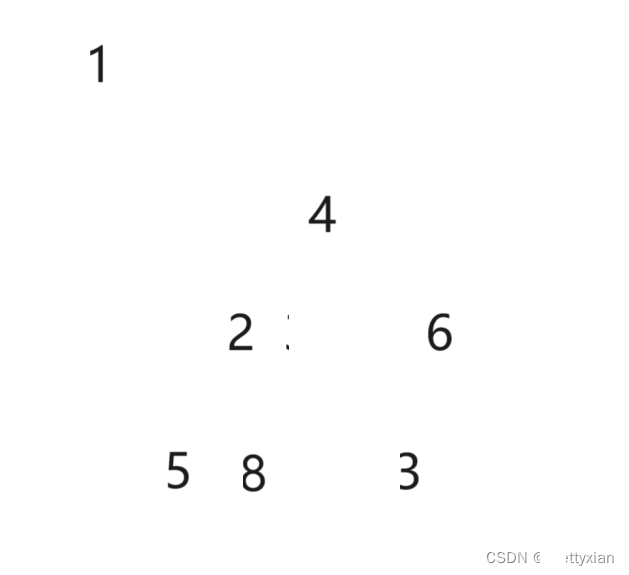
取出堆顶后,找出第二小的数据, 但是此时的堆各个节点已经不满足之前的大小关系了,4之前是6和5的父节点,比6和5大,但是与2为兄弟节点,兄弟节点之间的大小关系原来并不清楚,无法直接找出第二大的数据(可以重新把剩下的数据建堆,但是没必要,时间成本大)。在堆排序中不能让第一个数据直接拿出去,这样会改变节点之间的父子关系,不能确定大小关系,无法找出需要的节点。
接下来以排降序排降序为例演示过程。
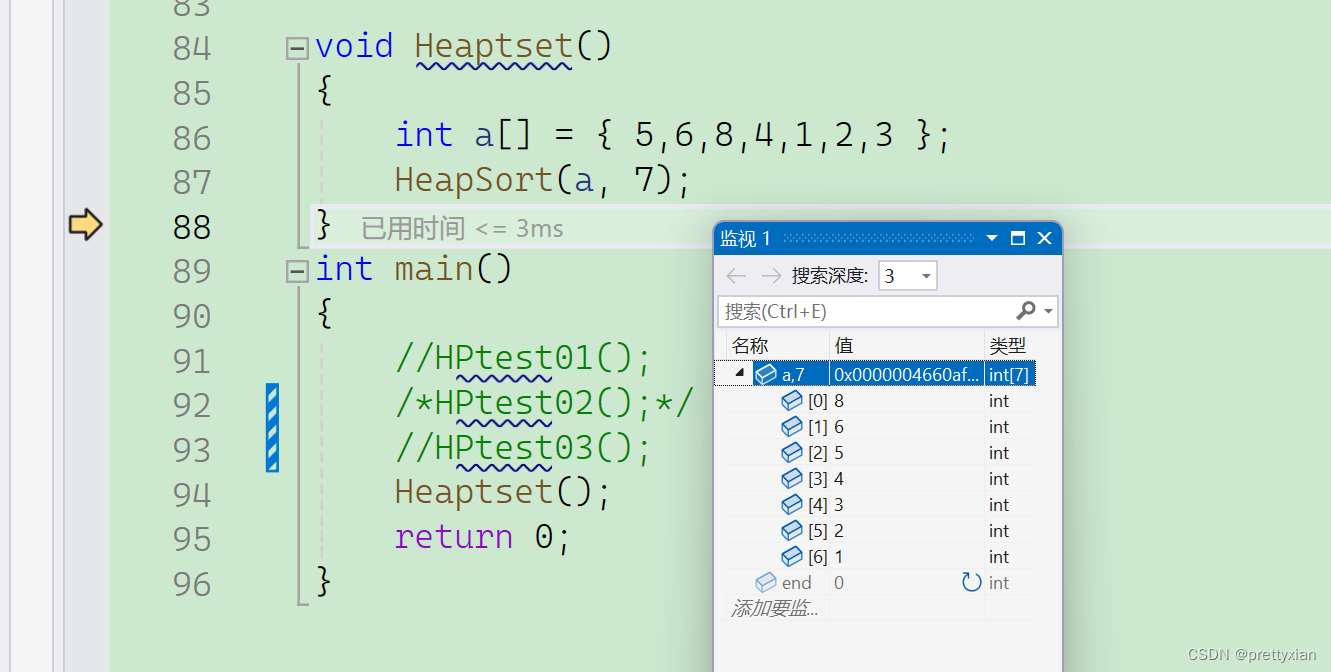
//堆排序
void HeapSort(int* a, int n)
{//建堆for (int i = 1; i < n; i++){AdjustUp(a, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}void Heaptset()
{int a[] = { 5,6,8,4,1,2,3 };HeapSort(a, 7);
}
int main()
{//HPtest01();/*HPtest02();*///HPtest03();Heaptset();return 0;
}调试:
向下调整算法的时间复杂度为log N,堆排序在最坏的情况下N个数据要排N次,所以堆排序的时间复杂度为N log N。可以极大的提高程序的效率。
相关文章:
【数据结构】 -- 堆 (堆排序)(TOP-K问题)
引入 要学习堆,首先要先简单的了解一下二叉树,二叉树是一种常见的树形数据结构,每个节点最多有两个子节点,通常称为左子节点和右子节点。它具有以下特点: 根节点(Root):树的顶部节…...

C#面:XML与 HTML 的主要区别是什么
C# XML与HTML有以下几个主要区别: 用途不同:XML(eXtensible Markup Language)是一种用于存储和传输数据的标记语言,它的主要目的是描述数据的结构和内容。HTML(HyperText Markup Language)是一…...

java并发-如何保证线程按照顺序执行?
【readme】 使用只有单个线程的线程池(最简单)Thread.join() 可重入锁 ReentrantLock Condition 条件变量(多个) ; 原理如下: 任务1执行前在锁1上阻塞;执行完成后在锁2上唤醒;任务…...

PyCharm中 Fitten Code插件的使用说明一
一. 简介 Fitten Code插件是是一款由非十大模型驱动的 AI 编程助手,它可以自动生成代码,提升开发效率,帮您调试 Bug,节省您的时间,另外还可以对话聊天,解决您编程碰到的问题。 前一篇文章学习了 PyCharm…...
Polar Web【简单】PHP反序列化初试
Polar Web【简单】PHP反序列化初试 Contents Polar Web【简单】PHP反序列化初试思路EXP手动脚本PythonGo 运行&总结 思路 启动环境,显示下图中的PHP代码,于是展开分析: 首先发现Easy类中有魔术函数 __wakeup() ,实现的是对成员…...
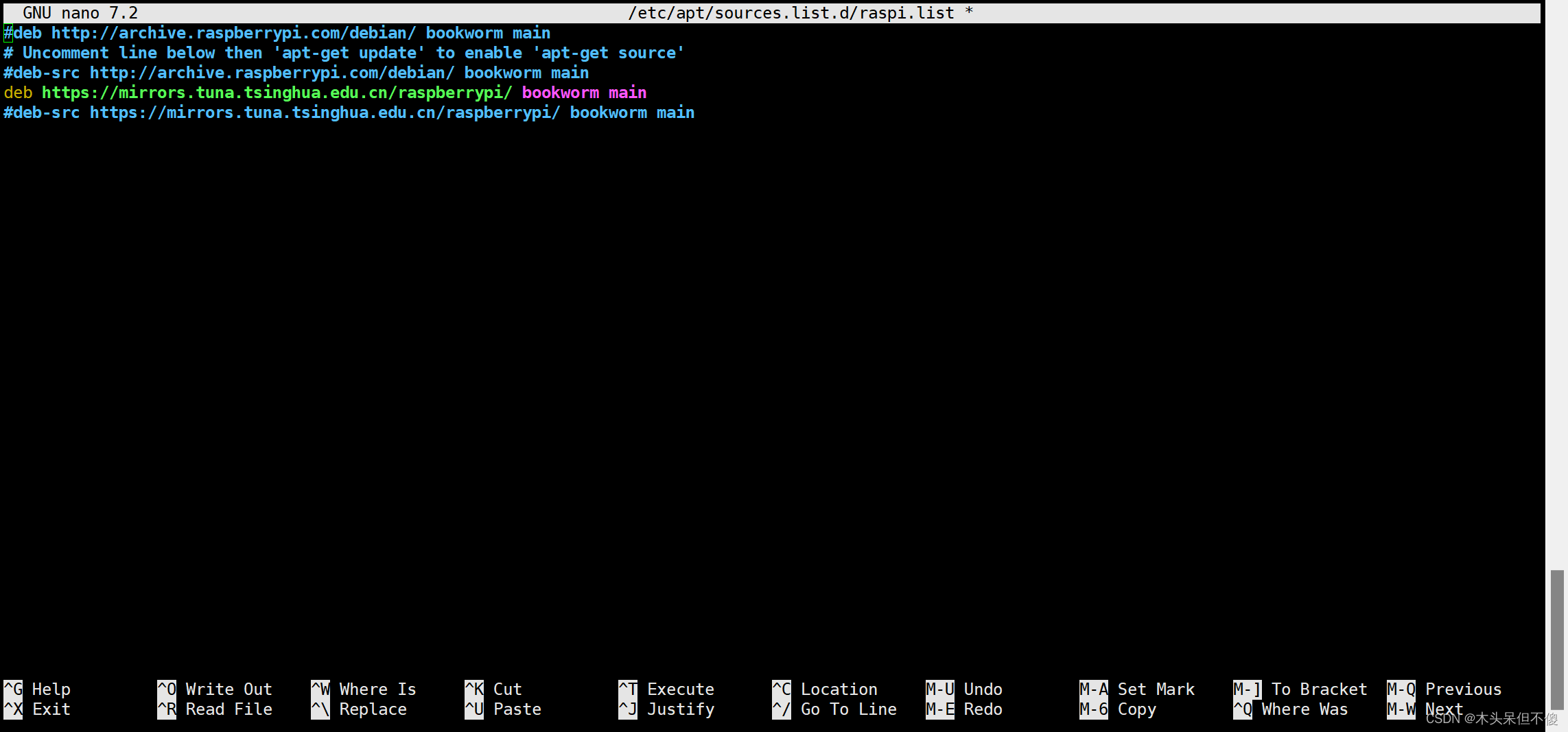
树莓派4B 零起点(二) 树莓派 更换软件源和软件仓库
目录 一、准备工作,查看自己的树莓派版本 二、安装HTTPS支持 三、更换为清华源 1、更换Debian软件源 2,更换Raspberrypi软件仓库 四、进行软件更新 接前章,我们的树莓派已经启动起来了,接下来要干的事那就是更换软件源和软件…...
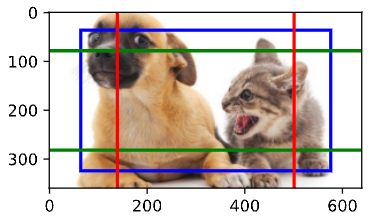
Pytorch 实现目标检测二(Pytorch 24)
一 实例操作目标检测 下面通过一个具体的例子来说明锚框标签。我们已经为加载图像中的狗和猫定义了真实边界框,其中第一个 元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的(x, y)轴坐标(范围…...
进行高效列表操作)
如何使用Python中的列表解析(list comprehension)进行高效列表操作
Python中的列表解析(list comprehension)是一种创建列表的简洁方法,它可以在单行代码中执行复杂的循环和条件逻辑。列表解析提供了一种快速且易于阅读的方式来生成新的列表。 以下是一些使用列表解析进行高效列表操作的示例: 1.…...

java使用websocket遇到的问题
java使用websocket的bug 1 websocket连接正常但是收不到服务端发出的消息java的websocket并发的时候导致连接断开(看着连接是正常的,但是实际上已经断开) 1 websocket连接正常但是收不到服务端发出的消息 java的websocket并发的时候导致连接断…...

[Cloud Networking] Layer 2
文章目录 1. 什么是Mac Address?2. 如何查找MAC地址?3. 二层数据交换4. [Layer 2 Protocol](https://blog.csdn.net/settingsun1225/article/details/139552315) 1. 什么是Mac Address? MAC 地址是计算机的唯一48位硬件编码,嵌入到网卡中。 MAC地址也…...
)
[240609] qwen2 发布,在 Ollama 已可用 | 采用语言模型构建通用 AGI(2020年8月)
目录 qwen2 发布,在 Ollama 已可用Qwen2 模型概览 (基于 Ollama 网站信息)一、模型介绍二、模型参数三、支持语言 (除英语和中文外)四、模型性能五、许可证六、数据支撑: 采用语言模型构建通用 AGI qwen2 发布,在 Ollama 已可用 Qwen2 模型概览 (基于 O…...
)
赶紧收藏!2024 年最常见 20道分布式、微服务面试题(五)
上一篇地址:赶紧收藏!2024 年最常见 20道分布式、微服务面试题(四)-CSDN博客 九、在分布式系统中,如何保证数据一致性? 在分布式系统中保证数据一致性是一个复杂的问题,因为分布式系统由多个独…...

为什么Kubernetes(K8S)弃用Docker:深度解析与未来展望
为什么Kubernetes弃用Docker:深度解析与未来展望 🚀 为什么Kubernetes弃用Docker:深度解析与未来展望摘要引言正文内容(详细介绍)什么是 Kubernetes?什么是 Docker?Kubernetes 和 Docker 的关系…...
软件游戏提示msvcp120.dll丢失的解决方法,总结多种靠谱的解决方法
在电脑使用过程中,我们可能会遇到一些错误提示,其中之一就是“找不到msvcp120.dll”。那么,msvcp120.dll是什么?它对电脑有什么影响?有哪些解决方法?本文将从以下几个方面进行探讨。 一,了解msv…...
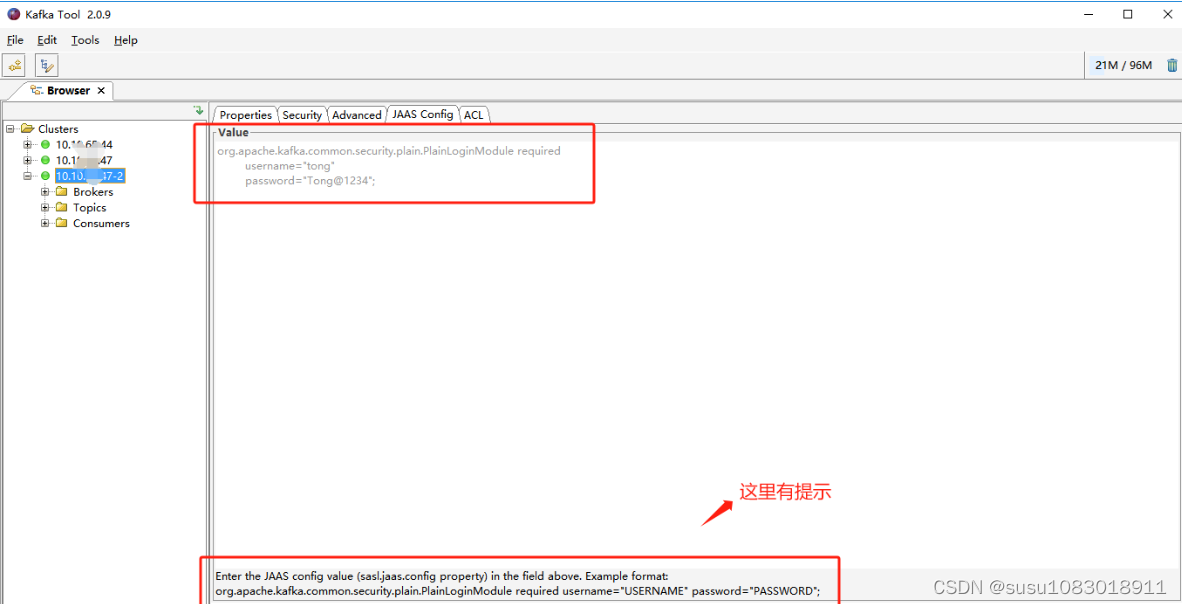
使用kafka tools工具连接带有用户名密码的kafka
使用kafka tools工具连接带有用户名密码的kafka 创建kafka连接,配置zookeeper 在Security选择Type类型为SASL Plaintext 在Advanced页面添加如下图红框框住的内容 在JAAS_Config加上如下配置 需要加的配置: org.apache.kafka.common.security.plain.Pla…...

[个人感悟] Java基础问题应该考察哪些问题?
前言 “一切代码无非是数据结构和算法流程的结合体.” 忘了最初是在何处看见这句话了, 这句话, 对于Java基础的考察也是一样. 正如这句话所说, 我们对于基础的考察主要考察, 数据结构, 集合类型结构, 异常类型, 已经代码的调用和语法关键字. 其中数据结构和集合类型结构是重点…...
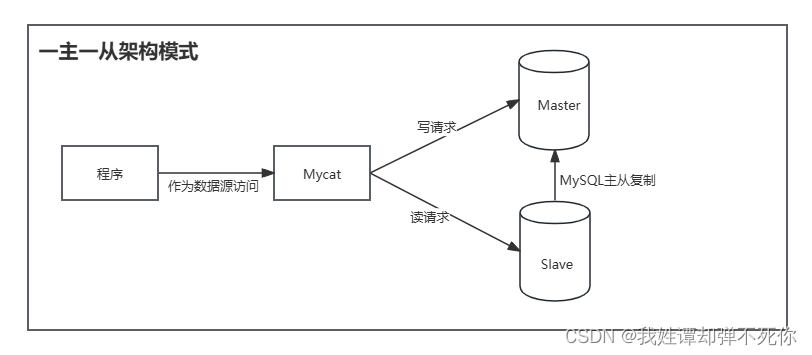
MySQL-主从复制
1、主从复制的理解 在工作用常见Redis作为缓存与MySQL一起使用。当有请求时,首先会从缓存中进行查找,如果存在就直接取出,否则访问数据库,这样 提升了读取的效率,也减少了对后台数据库的访问压力。Redis的缓存架构时高…...

开发没有尽头,尽力既是完美
最近遇到了一些难题,开发系统总有一些地方没有考虑周全,偏偏用户使用的时候“完美复现”了这个隐藏的Bug...... 讲道理创业一年之久为了生存,我一直都有在做复盘,复盘的核心就是:如何提升营收、把控开发质量࿰…...

【手推公式】如何求SDE的解(附录B)
【手推公式】如何求SDE的解(附录B) 核心思路:不直接求VE和VP的SDE的解xt,而是求xt的期望和方差,从而写出x0到xt的条件分布形式(附录B) 论文:Score-Based Generative Modeling throug…...
STM32F103单片机工程移植到航顺单片机HK32F103注意事项
一、简介 作为国内MCU厂商中前三阵营之一的航顺芯片,建立了世界首创超低功耗7nA物联网、万物互联核心处理器浩瀚天际10X系列平台,接受代理商/设计企业/方案商定制低于自主研发十倍以上成本,接近零风险自主品牌产品,芯片设计完成只…...

健身与猝死的关系
## 延迟性肌肉酸痛(DOMS)定义:延迟性肌肉酸痛(DOMS)是一种在进行了非常规或强度较大的体育锻炼后,特别是力量训练后出现的肌肉酸痛现象。这种痛感通常在锻炼后24到48小时内出现,最严重时可持续数…...

OpenClaw语音交互方案:千问3.5-27B对接Whisper实现听写
OpenClaw语音交互方案:千问3.5-27B对接Whisper实现听写 1. 为什么需要语音交互自动化 上个月帮朋友整理一场3小时的行业访谈录音时,我对着逐字稿反复暂停播放、标记重点、提炼观点,整整花了6小时才完成笔记。这种机械劳动让我开始思考&…...

C语言核心特性与工程实践详解
1. C语言核心特性解析C语言作为一门经典的编程语言,其核心特性决定了它在系统编程和嵌入式开发中的不可替代地位。让我们从底层机制开始剖析:1.1 静态类型与编译执行C语言采用静态类型系统,这意味着所有变量必须在编译前明确声明其类型。这种…...

国产DSP
1. 知识关联图(Mermaid)1.1 中断层级图graph LR A[Input Event<br>(SRIO/DMA/定时器等)] --> B[CIC中断分发控制器] B --> C[核内INTC中断控制器] C --> D[CorePac DSP核心] style B fill:#f0f0ff,stroke:#333 note right of B: …...

2025届毕业生推荐的六大降重复率网站推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 针对用户试图降低文本里人工智能生成内容的可识别度,降AIGC工具发挥作用…...
)
Atlas 800I A2实战:5小时搞定DeepSeek V3 W4A8量化全流程(含显存优化技巧)
Atlas 800I A2实战:5小时搞定DeepSeek V3 W4A8量化全流程(含显存优化技巧) 在AI模型部署领域,量化技术正成为突破硬件限制的关键手段。当我们面对Atlas 800I A2这样的高性能服务器时,如何充分发挥其64GB显存优势&#…...

Kubernetes中的StatefulSet应用实践
Kubernetes中的StatefulSet应用实践 引言:StatefulSet的重要性 哥们,别整那些花里胡哨的!作为一个前端开发兼摇滚鼓手,我最烦的就是有状态应用的部署问题。在云原生时代,StatefulSet是管理有状态应用的关键。今天&…...

Windows家庭版开启原生远程桌面
最近有小伙伴问:怎样才能远程控制Windows家庭版的电脑? 小白回答:用向日葵。 哈哈哈哈……这逻辑也是很正确的,毕竟只要安装个第三方远程桌面就能搞定的事情,为啥要弄得那么复杂呢? 不过,他说…...

解锁论文新境界:书匠策AI——你的毕业论文超级助手
在学术的征途中,毕业论文无疑是每位学子必须跨越的一道重要门槛。它不仅是对你四年学习成果的全面检验,更是你学术生涯的一次重要启航。然而,面对繁琐的选题、海量的文献、复杂的结构搭建以及无尽的文字雕琢,许多学子常常感到力不…...

用Python模拟随机游走:从一维到三维,直观理解马尔可夫链的常返性
用Python模拟随机游走:从一维到三维,直观理解马尔可夫链的常返性 随机游走是概率论中最迷人的概念之一,它像一面镜子,映照出微观粒子运动、金融市场波动甚至社交网络传播的底层规律。当我第一次在Jupyter Notebook中模拟出随机游走…...