用一个例子告诉你 怎样在spark中创建累加器
目录
1.说明
1.1 什么是累加器
1.2 累加器的功能
2. 使用累加器
3. 累加器和reduce、fold算子的区别
1.说明
1.1 什么是累加器
累加器是Spark提供的一个共享变量(Shared Variables)
默认情况下,如果Executor节点上使用到了Driver端定义的变量(通过算子传递)
算子会将该变量的副本发送的每个Task任务,但是并不会将Task任务对副本变量的修改返回给Driver端
但是Spark为我们提供了一个共享变量(累加器),允许Driver端和Task之间共享一个变量
1.2 累加器的功能
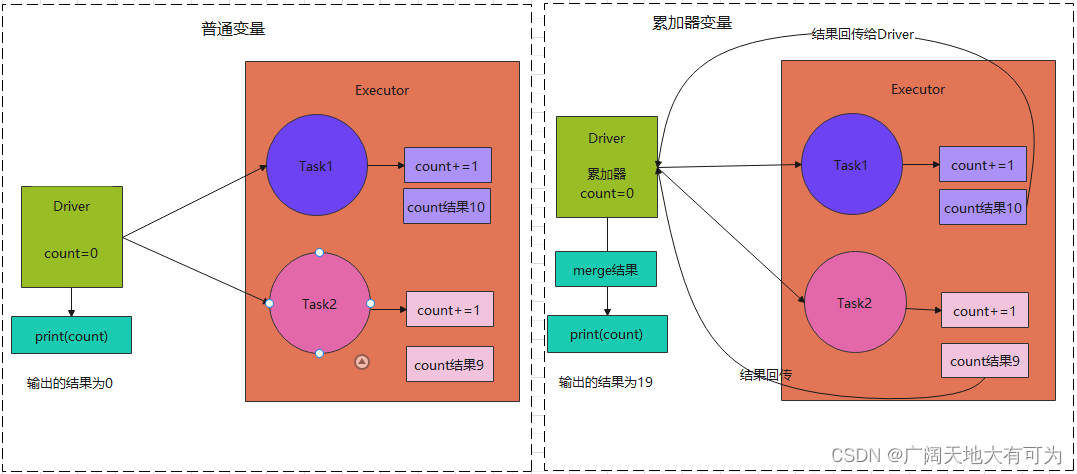
累加器用来将Executor端变量的信息聚合到Driver端
在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一个新的副本,每个Task更新这些副本的值以后,会再返回给Driver端进行merge,得到最终的值
2. 使用累加器
spark中为我们提供了三个常用的累加器,并且支持我们根据自己业务需求来实现自定义累加器类
代码示例:
test("使用spark自带的累加器") {// 初始化 spark配置实例val sparkconf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("")// 初始化 spark环境对象val sc: SparkContext = new SparkContext(sparkconf)/** TODO 使用 LongAccumulator* 功能:* 对 整数类型的元素做累加* */val intRdd: RDD[Int] = sc.makeRDD(List(1, 2, 2, 3, 3, 4, 5, 6, 7, 8, 9))val accum: LongAccumulator = sc.longAccumulator("My LongAccumulator")intRdd.foreach(x => accum.add(x))println(s"LongAccumulator:${accum.value}")/** TODO 使用 DoubleAccumulator* 功能:* 对 浮点类型的元素做累加** */val doubleRdd: RDD[Double] = sc.makeRDD(List(1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1, 9.1))val doubleAccumulator: DoubleAccumulator = sc.doubleAccumulator("My DoubleAccumulator")doubleRdd.foreach(x => doubleAccumulator.add(x))println(s"DoubleAccumulator:${doubleAccumulator.value}")/** TODO 使用 CollectionAccumulator* 将元素添加到list中去* */val collectAccumulator: CollectionAccumulator[Int] = sc.collectionAccumulator[Int]("My ")intRdd.foreach(x => collectAccumulator.add(x))println(s"CollectionAccumulator:${collectAccumulator.value}")/** TODO 使用自定义累加器* 将元素添加到Set中去** 实现步骤:* 1.根据业务逻辑实现自定义累加器实现类* 2.向spark环境中注册自定义累加器* 3.使用自定义累加器** */val setAccumulator = new SetAccumulator[Int]()sc.register(setAccumulator, "My SetAccumulator")intRdd.foreach(x => setAccumulator.add(x))println(s"SetAccumulator:${setAccumulator.value}")sc.stop()}
自定义累加器:
/*
* 自定义累加器
* TODO 并未考虑线程安全的问题,实际使用时需添加这部分的判断
*
* */
class SetAccumulator[T] extends AccumulatorV2[T, collection.mutable.Set[T]] {/* 定义可变Set */var set = collection.mutable.Set[T]()/* 判断 累加器是否为初始状态 */override def isZero: Boolean = set.isEmpty/** 获取当前累加器的 新副本* 每个变量(累加器)的副本会发送到每个Task* */override def copy(): AccumulatorV2[T, mutable.Set[T]] = new SetAccumulator/** 重置累加器(清空累加器)* */override def reset(): Unit = Nil/** TODO 分区内累加规则(Task内)* 获取数据并进行累加* 根据指定的规则,向累加器中添加元素* */override def add(v: T): Unit = {set += v}/** TODO 分区间累加规则* 合并多个累加器副本* */override def merge(other: AccumulatorV2[T, mutable.Set[T]]): Unit = {this.value ++= other.value}override def value: mutable.Set[T] = set
}
执行结果:

3. 累加器和reduce、fold算子的区别
重点关注:
1.累加器并不是调优操作,并不会带来效率上的提升
2.累加器在Executor端做add操作(累加器副本做更新),在Driver端做merge操作(合并多个Task中的累加器副本)
示例代码:
test("对比累加器和reduce、fold算子效率问题") {/** TODO 思考: 累加器和reduce、fold算子的区别* */// 初始化 spark配置实例val sparkconf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("")// 初始化 spark环境对象val sc: SparkContext = new SparkContext(sparkconf)val intRdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9))// 查看每个分区的内容intRdd.mapPartitionsWithIndex((i, iter) => {println(s"分区编号$i :${iter.mkString(" ")}");iter}).collect()val accum: LongAccumulator = sc.longAccumulator("My Accumulator")intRdd.foreach(x => accum.add(x))println(s"累加器结果:${accum.value}")println("----reduce算子----------------------")val resultByReduce = intRdd.reduce((v1, v2) => {println(s"$v1 + $v2 = ${v1 + v2}")v1 + v2})println(s"reduce算子结果:${resultByReduce}")println("----reduce算子----------------------")val resultByFlod = intRdd.fold(0)((v1, v2) => {println(s"$v1 + $v2 = ${v1 + v2}")v1 + v2})println(s"resultByFlod:${resultByFlod}")while (true) {}// http://localhost:4040/stages/stage/?id=1&attempt=0sc.stop()}
执行结果:
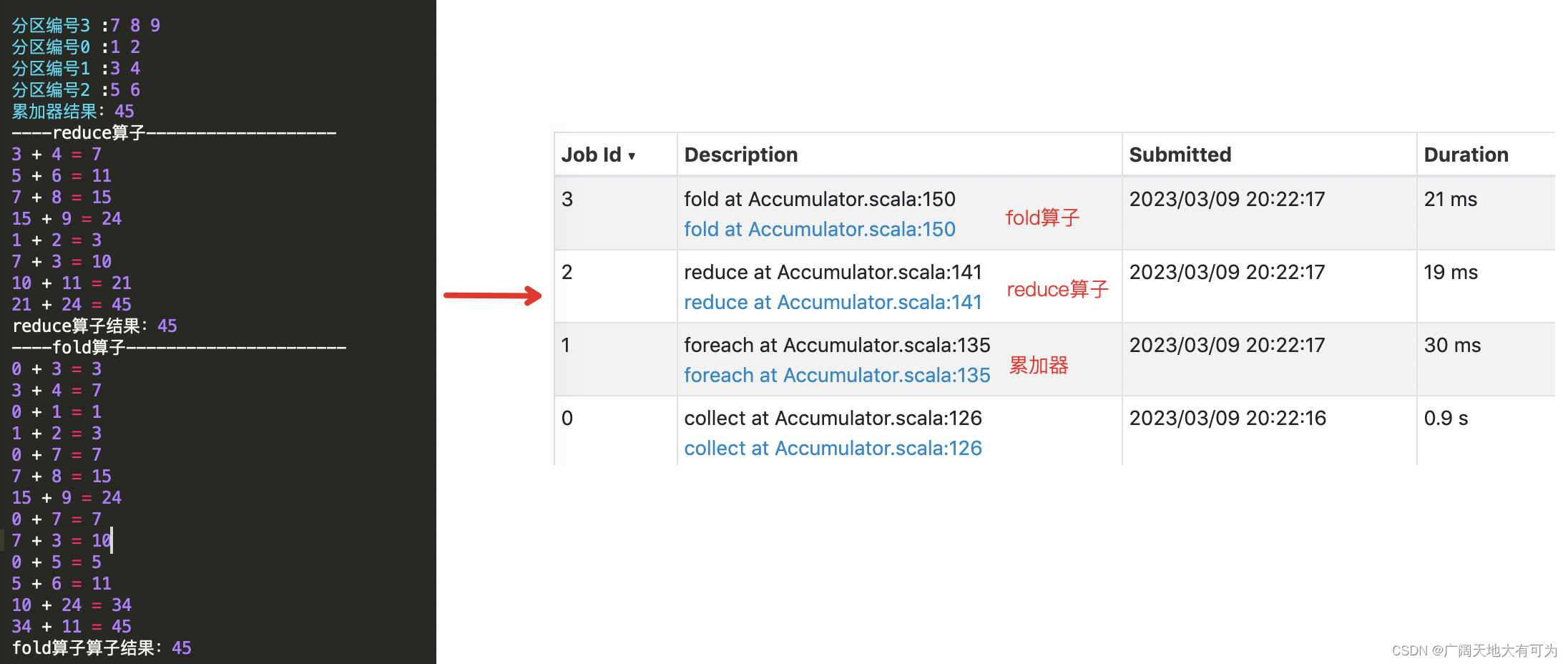
累加器并未对计算效率带来提升
参考链接:
传送门1
传送门2
官网链接
相关文章:
用一个例子告诉你 怎样在spark中创建累加器
目录 1.说明 1.1 什么是累加器 1.2 累加器的功能 2. 使用累加器 3. 累加器和reduce、fold算子的区别 1.说明 1.1 什么是累加器 累加器是Spark提供的一个共享变量(Shared Variables) 默认情况下,如果Executor节点上使用到了Driver端定义的变量(通过算子传…...

ICG-Avidin,吲哚菁绿标记的亲和素,应用:生物成像、生物检测、免疫组织化学、微阵列检测制备纳米胶束或微球或其他纳米粒子装载ICG实现成像。
ICG-Avidin,吲哚菁绿标记的亲和素 中文名称:吲哚菁绿标记的亲和素 英文名称:ICG-Avidin 激发发射波长:785/821nm 性状:绿色粉末 溶剂:水,部分常规有机溶剂 稳定性:-20℃下干燥避光 应用&…...
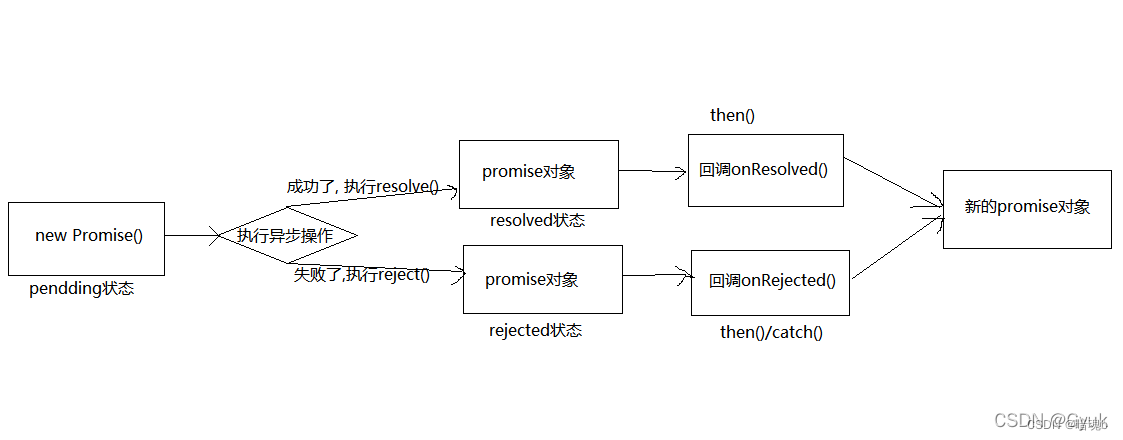
Promise的理解和使用
Promise是什么 抽象表达 promise 是一门新的技术(ES6规范)Promise 是JS中进行异步编程的新解决方案 具体表达 从语法上来说:Promise是一个构造函数从功能上来说:promise对象用来封装一个异步操作并可以获取其成功/失败的结果 回调函数就…...
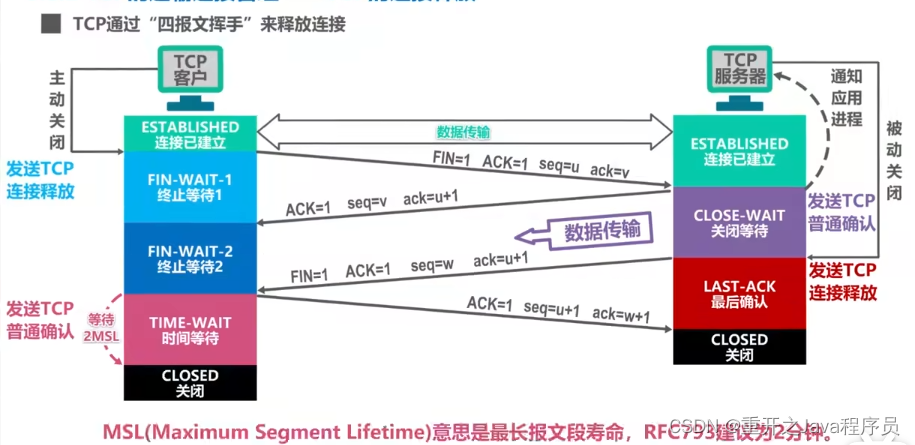
TCP
TCP 流量控制 一般来说,我们希望数据传输的快一些,但如果对方把数据发送的过快,接收方就可能来不及接收,这就会造成数据的丢失 流量控制就是让发送方的发送速率不要太快,让接收方来得及接收 利用滑动窗口机制可以在TCP连接上实现对发送方的流量控制 TCP接收方利用自己的接收…...

Python每日一练(20230310)
目录 1. 爬楼梯 ★ 2. 删除无效的括号 ★★★ 3. 给表达式添加运算符 ★★★ 🌟 每日一练刷题专栏 C/C 每日一练 专栏 Python 每日一练 专栏 1. 爬楼梯 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方…...

LeetCode-1590. 使数组和能被 P 整除【前缀和,哈希表】
LeetCode-1590. 使数组和能被 P 整除【前缀和,哈希表】题目描述:解题思路一:前缀和,具体看注释。解题思路二:在遍历过程中计算前缀和解题思路三:0题目描述: 给你一个正整数数组 nums࿰…...

Java核心类库
Java核心类库类Math(☆☆☆)System(☆☆☆)Object(☆☆☆☆)Objects (☆)BigDecimal(☆☆☆☆)基本类型的包装类(☆☆☆☆☆)算法(☆☆☆☆☆)二分查找冒泡排序递归Arrays(☆☆☆☆)Date (☆☆☆☆☆)SimpleDateFormat(☆☆☆☆☆)LocalDateTime (☆)Throwable 类(☆☆☆☆)Str…...

1110道Java面试题及答案(最新Java初级面试题大汇总)
开篇小叙 现在 Java 面试可以说是老生常谈的一个问题了,确实也是这么回事。面试题、面试宝典、面试手册......各种 Java 面试题一搜一大把,根本看不完,也看不过来,而且每份面试资料也都觉得 Nice,然后就开启了收藏之路…...

DML 添加、修改、删除数据
目录 DML 一、添加数据 1、给指定字段添加数据 2、给全部字段添加数据 3、批量添加数据 二、修改数据 三、删除数据 DML DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。 一、添加数据 1、给指定字…...
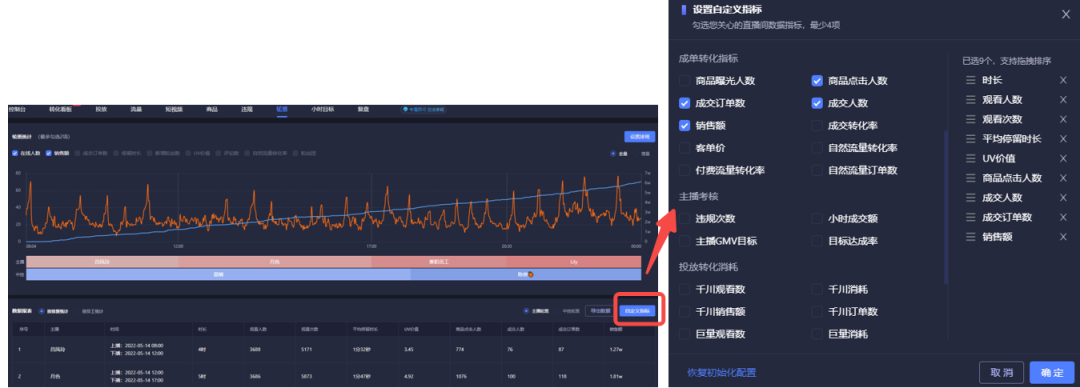
千川投放50问(完)!如何跑出高投产?
第四十一问:计划初期成本很高,是否要关掉重新跑?首先看一下是不是初期回传延迟导致的成本偏高。如果成本没有高的,不建议暂停,先观察一段时间数据,给它一点学习时间。当系统积累过足够的模型之后࿰…...

每日学术速递3.10
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 Subjects: cs.RO 1.Diffusion Policy: Visuomotor Policy Learning via Action Diffusion 标题:扩散策略:通过动作扩散进行视觉运动策略学习 作者:Cheng Chi, Si…...

[C/C++]_[初级]_[声明和使用字符串常量和字节常量]
场景 我们需要存储常量的字节数组,并且数组里的字节数据可以是任意数值0-255。怎么存储? 说明 任意字节数组可以使用char或者unsigned char作为数据类型。比如以下的字符串声明。这种字符串数据可以通过strlen(buf)来计算它的长度,它会遇到…...
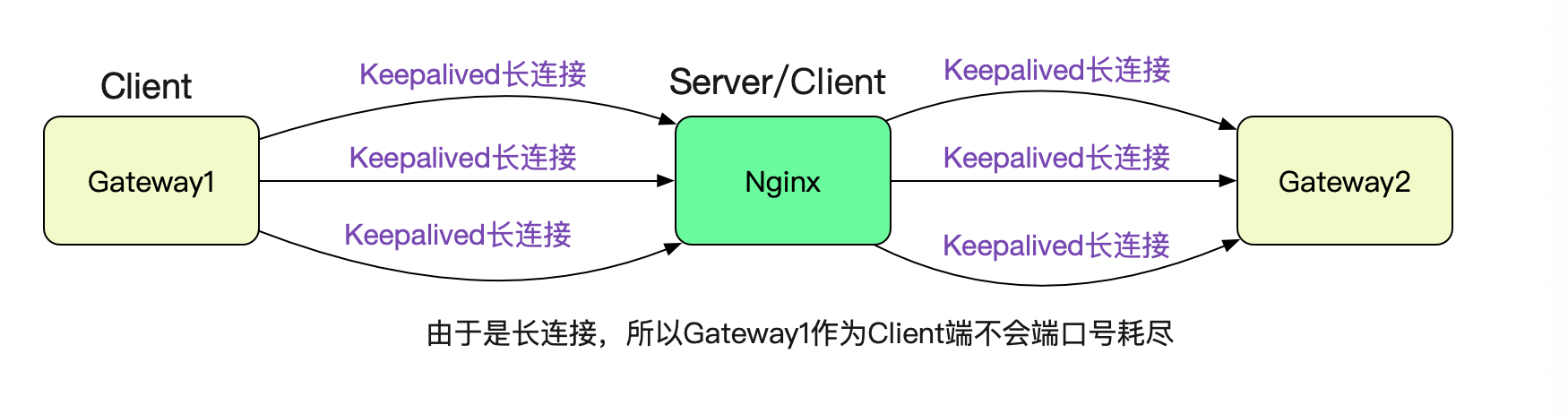
解Bug之路-Nginx 502 Bad Gateway
前言 事实证明,读过Linux内核源码确实有很大的好处,尤其在处理问题的时刻。当你看到报错的那一瞬间,就能把现象/原因/以及解决方案一股脑的在脑中闪现。甚至一些边边角角的现象都能很快的反应过来是为何。笔者读过一些Linux TCP协议栈的源码…...

目标检测 pytorch复现R-CNN目标检测项目
目标检测 pytorch复现R-CNN目标检测项目1、R-CNN目标检测项目基本流程思路2、项目实现1 、数据集下载:2、车辆数据集抽取3、创建分类器数据集3、微调二分类网络模型4、分类器训练5、边界框回归器训练6、效果测试目标检测 R-CNN论文详细讲解1、R-CNN目标检测项目基本…...
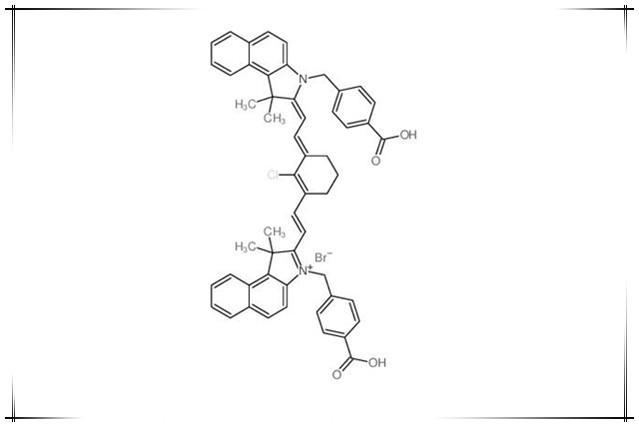
荧光染料IR-825 NHS,IR825 NHS ester,IR825 SE,IR-825 活性酯
IR825 NHS理论分析:中文名:新吲哚菁绿-琥珀酰亚胺酯,IR-825 琥珀酰亚胺酯,IR-825 活性酯英文名:IR825 NHS,IR-825 NHS,IR825 NHS ester,IR825 SECAS号:N/AIR825 NHS产品详…...
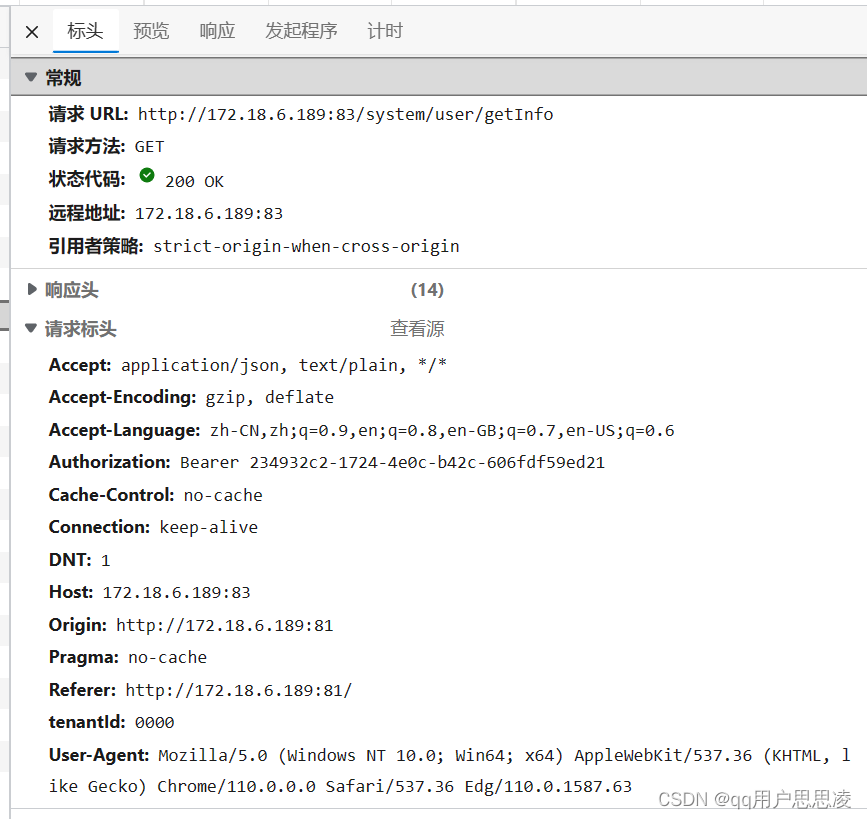
利用Postman的简单运用解决小问题的过程
这几天在修改一个前后端分离的商城项目。项目前端向后端发出数据请求之后,收到的却是504网关超时错误。 但是控制台却不止报错了网关超时,还有跨域请求的问题: 根本搞不清是哪个问题导致了另外一个问题还是独立的两个问题。 直接点击网址访…...
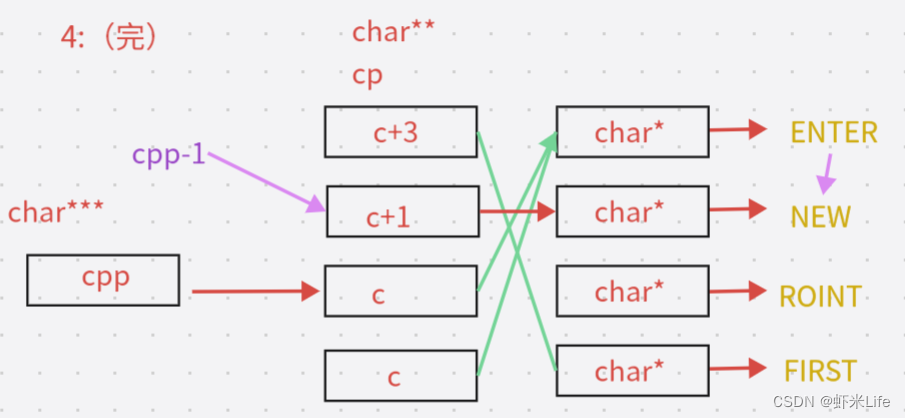
【C语言】8道经典指针笔试题(深度解剖)
上一篇我们也介绍了指针的笔试题,这一篇我们趁热打铁继续讲解8道指针更有趣的笔试题,,让大家更加深刻了解指针,从而也拿下【C语言】指针这个难点! 本次解析是在x86(32位)平台下进行 文章目录所需储备知识笔…...
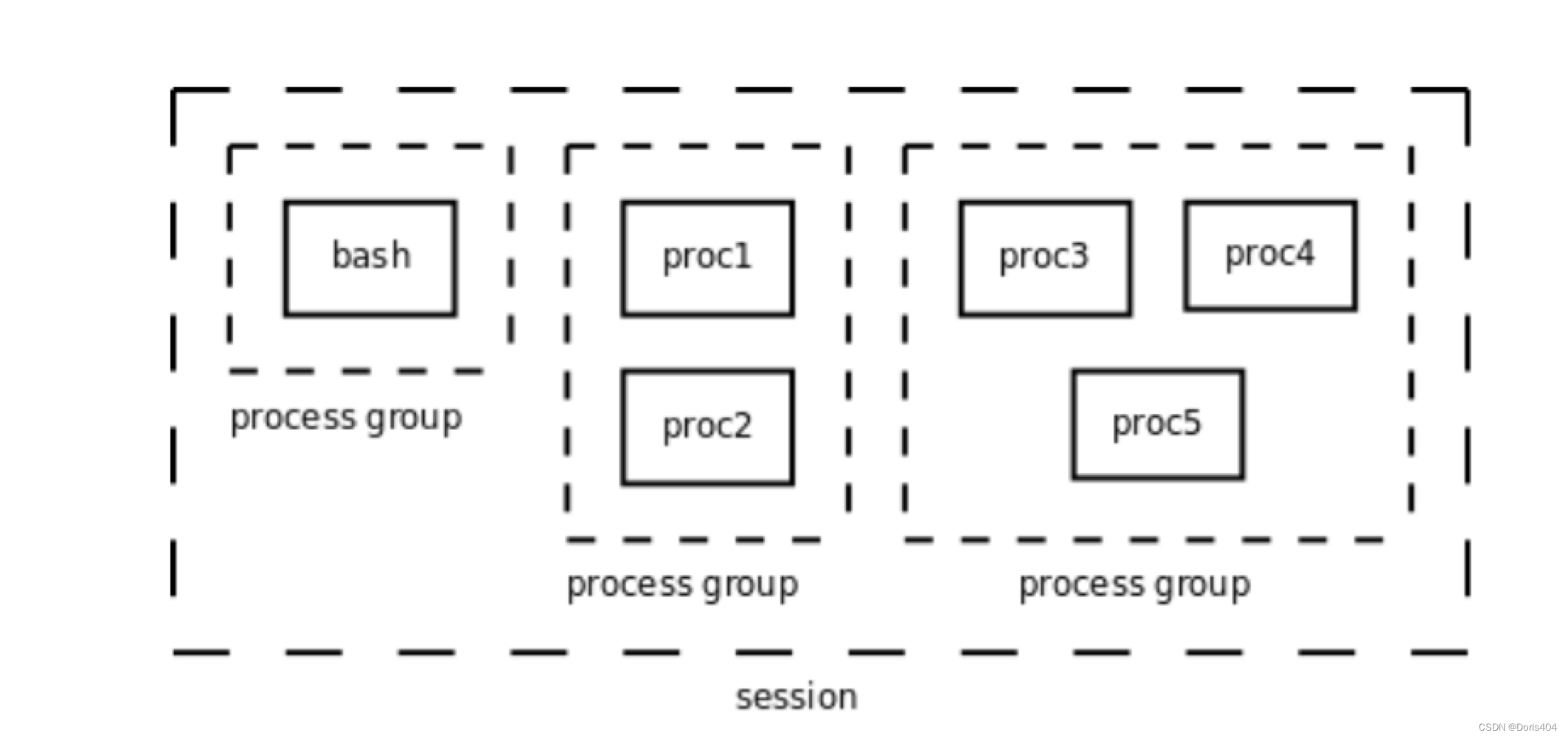
操作系统内核与安全分析课程笔记【2】进程管理与调度
文章目录基本概念与关键数据结构进程管理进程生命周期进程的关系进程家族树线程组进程组与会话进程的创建与终止Linux中的线程基本概念与关键数据结构 进程:静态的,存储在磁盘上的代码与数据。 程序:动态的,执行程序的动态过程&am…...

看完书上的栈不过瘾,为什么不动手试试呢?
一.栈的基本概念1.栈的定义栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。其中注意几点:栈顶(Top):线性表…...
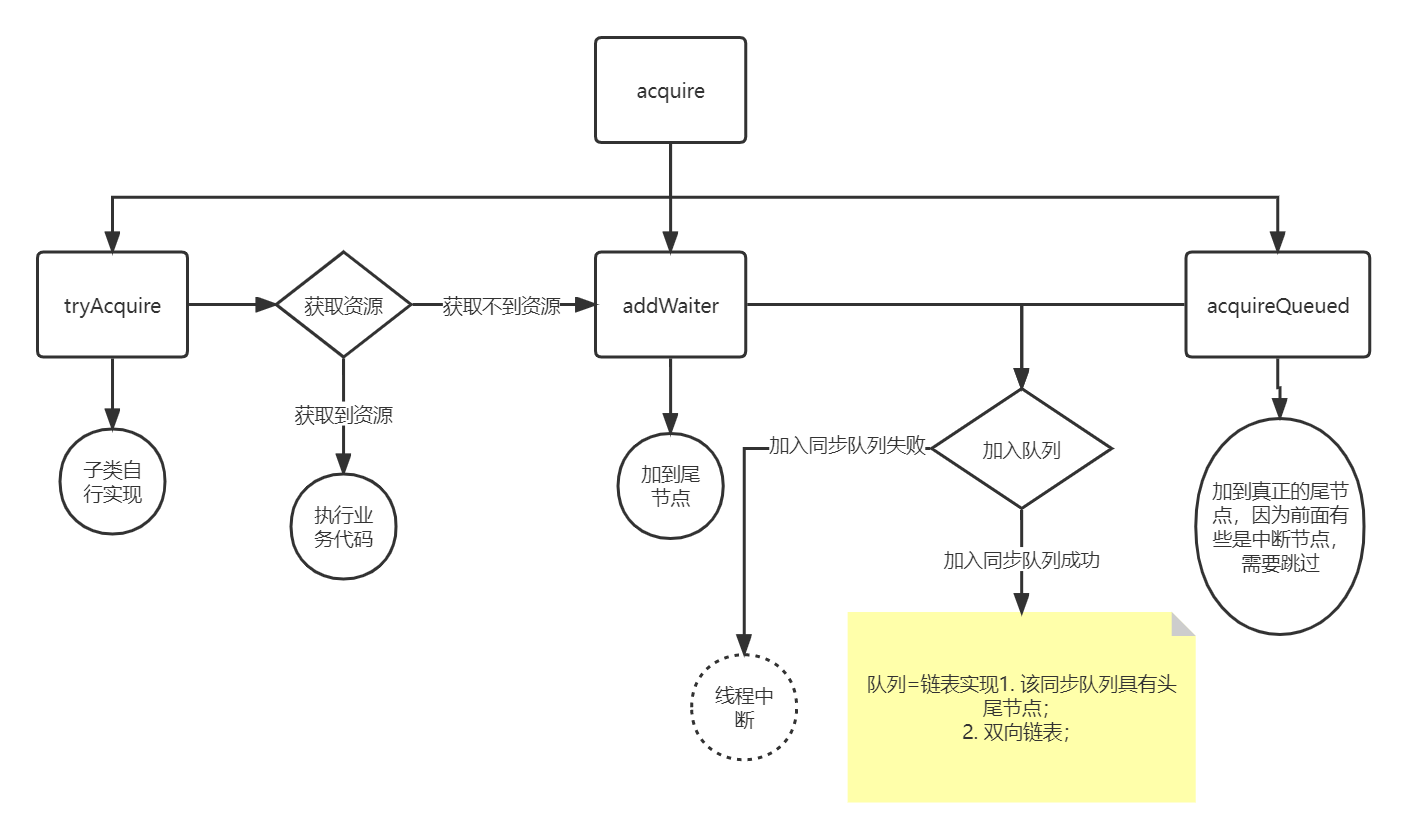
AbstractQueuedSynchronizer从入门到踹门
概念设计初衷:该类利用 状态队列 实现了一个同步器,更多的是提供一些模板方法(子类必须重写,不然会抛错)。 设计功能:独占、共享模式两个核心,state、Queue2.1 statesetState、compareAndSetSta…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

GitFlow 工作模式(详解)
今天再学项目的过程中遇到使用gitflow模式管理代码,因此进行学习并且发布关于gitflow的一些思考 Git与GitFlow模式 我们在写代码的时候通常会进行网上保存,无论是github还是gittee,都是一种基于git去保存代码的形式,这样保存代码…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...

Python竞赛环境搭建全攻略
Python环境搭建竞赛技术文章大纲 竞赛背景与意义 竞赛的目的与价值Python在竞赛中的应用场景环境搭建对竞赛效率的影响 竞赛环境需求分析 常见竞赛类型(算法、数据分析、机器学习等)不同竞赛对Python版本及库的要求硬件与操作系统的兼容性问题 Pyth…...