AI大模型在健康睡眠监测中的深度融合与实践案例

文章目录
- 1. 应用方案
- 2. 技术实现
- 2.1 数据采集与预处理
- 2.2 构建与训练模型
- 2.3 个性化建议生成
- 3. 优化策略
- 4. 应用示例:多模态数据融合与实时监测
- 4.1 数据采集
- 4.2 实时监测与反馈
- 5. 深入分析模型选择和优化
- 5.1 LSTM模型的优势和优化策略
- 5.2 CNN模型的优势和优化策略
- 5.3 Transformer模型的优势和优化策略
- 6. 数据隐私与安全策略
- 7. 深入探讨未来发展方向
- 7.1. 多模态数据融合
- 7.2. 自适应学习
- 7.3. 跨平台集成
- 8. 深度学习模型优化
- 9. 总结
随着穿戴设备的普及和AI技术的发展,利用AI大模型在睡眠监测中的应用成为可能。这种深度融合应用能够提供更准确、更个性化的睡眠分析与建议,帮助用户更好地管理睡眠健康。以下是AI大模型在穿戴设备睡眠监测中的应用方案、技术实现和优化策略。
1. 应用方案
-
多模态数据融合:
- 生理数据:心率、呼吸率、体温等。
- 环境数据:光照、噪音、温度等。
- 行为数据:运动数据、睡眠姿势等。
-
高级数据分析:
- 睡眠阶段分类:利用深度学习模型对数据进行分析,分类出浅睡、深睡、REM睡眠等阶段。
- 异常检测:检测睡眠呼吸暂停、失眠等异常情况。
-
个性化建议:
- 基于用户的历史数据和模型分析结果,提供个性化的睡眠改善建议。
-
实时监测与反馈:
- 实时监测用户睡眠状态,及时提供反馈和建议。
2. 技术实现
2.1 数据采集与预处理
首先,需要从穿戴设备中获取各类数据,并进行预处理。
import numpy as np
import pandas as pd# 模拟数据采集
heart_rate_data = np.random.normal(60, 5, 1000)
respiration_rate_data = np.random.normal(16, 2, 1000)
temperature_data = np.random.normal(36.5, 0.5, 1000)
movement_data = np.random.normal(0, 1, 1000) # 假设为运动强度数据# 创建DataFrame
data = pd.DataFrame({'heart_rate': heart_rate_data,'respiration_rate': respiration_rate_data,'temperature': temperature_data,'movement': movement_data
})# 数据预处理
def preprocess_data(data):# 归一化处理data_normalized = (data - data.mean()) / data.std()return data_normalizeddata_preprocessed = preprocess_data(data)
2.2 构建与训练模型
利用深度学习模型(如LSTM)对预处理后的数据进行训练,识别睡眠阶段。
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout# 构建LSTM模型
model = Sequential()
model.add(LSTM(64, return_sequences=True, input_shape=(None, 4))) # 输入为4维数据
model.add(Dropout(0.2))
model.add(LSTM(64, return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(3, activation='softmax')) # 输出为3类:浅睡、深睡、REMmodel.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 模拟训练数据
X_train = np.expand_dims(data_preprocessed.values, axis=0)
y_train = np.random.randint(0, 3, (1, 1000)) # 假设标签数据# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
2.3 个性化建议生成
根据模型输出的睡眠阶段和用户历史数据,生成个性化的睡眠建议。
def generate_sleep_advice(sleep_data):# 分析睡眠数据deep_sleep_ratio = np.sum(sleep_data == 1) / len(sleep_data)rem_sleep_ratio = np.sum(sleep_data == 2) / len(sleep_data)advice = "您的睡眠分析结果如下:\n"advice += f"深睡比例: {deep_sleep_ratio:.2f}\n"advice += f"REM睡眠比例: {rem_sleep_ratio:.2f}\n"if deep_sleep_ratio < 0.2:advice += "建议增加深睡时间,保持规律的作息,避免在睡前使用电子设备。\n"if rem_sleep_ratio < 0.2:advice += "建议改善睡眠质量,尝试放松训练,如冥想或听轻音乐。\n"return advice# 模拟生成睡眠阶段数据
predicted_sleep_stages = model.predict(X_train)[0]
advice = generate_sleep_advice(predicted_sleep_stages)
print(advice)
3. 优化策略
-
模型优化与压缩:
- 使用模型量化和剪枝技术,减少模型的计算量和内存占用,以适应穿戴设备的资源限制。
-
个性化与自适应学习:
- 根据用户的历史数据和反馈,不断调整和优化模型,提高个性化分析的准确性。
-
实时性与延迟优化:
- 通过边缘计算和高效的数据处理技术,减少数据传输和处理的延迟,提升实时监测的效果。
-
数据隐私与安全:
- 采用数据加密和隐私保护技术,确保用户数据的安全性和隐私性。
4. 应用示例:多模态数据融合与实时监测
4.1 数据采集
# 模拟实时数据采集
def collect_real_time_data():heart_rate = np.random.normal(60, 5)respiration_rate = np.random.normal(16, 2)temperature = np.random.normal(36.5, 0.5)movement = np.random.normal(0, 1)return np.array([heart_rate, respiration_rate, temperature, movement])# 模拟实时数据采集
real_time_data = collect_real_time_data()
print("实时数据采集:", real_time_data)
4.2 实时监测与反馈
# 实时监测和睡眠阶段预测
def real_time_sleep_monitor(model):data_window = []while True:new_data = collect_real_time_data()data_window.append(new_data)if len(data_window) > 100:data_window.pop(0) # 保持固定窗口大小if len(data_window) == 100:data_window_array = np.expand_dims(np.array(data_window), axis=0)sleep_stage = model.predict(data_window_array)print(f"当前睡眠阶段: {np.argmax(sleep_stage)}")# 提供实时反馈if np.argmax(sleep_stage) == 2: # 假设2代表深睡print("进入深睡状态,请保持安静环境。")elif np.argmax(sleep_stage) == 0: # 假设0代表浅睡print("浅睡状态,建议放松。")time.sleep(1) # 模拟每秒采集一次数据# 启动实时监测
# real_time_sleep_monitor(model)
5. 深入分析模型选择和优化
5.1 LSTM模型的优势和优化策略
优势:
- LSTM擅长处理时间序列数据,能够记住长期依赖关系,适合用于分析连续的生理数据,如心率和呼吸率。
- 在睡眠监测中,LSTM能够准确捕捉不同睡眠阶段的特征。
优化策略:
- 减小模型大小:通过剪枝和量化技术减少模型参数数量,减小模型大小,适应穿戴设备的计算资源限制。
- 改进架构:采用双向LSTM(BiLSTM)或多层LSTM结构,提升模型的表达能力和准确性。
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout, Bidirectionaldef build_optimized_lstm_model(input_shape):model = Sequential()model.add(Bidirectional(LSTM(64, return_sequences=True), input_shape=input_shape))model.add(Dropout(0.2))model.add(Bidirectional(LSTM(64, return_sequences=False)))model.add(Dropout(0.2))model.add(Dense(3, activation='softmax'))model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])return modelinput_shape = (None, 4) # 4个特征:心率、呼吸率、体温、运动
optimized_model = build_optimized_lstm_model(input_shape)
5.2 CNN模型的优势和优化策略
优势:
- CNN能够高效地提取局部特征,适用于检测睡眠数据中的特定模式,如呼吸暂停和心率变化。
- CNN的参数共享机制减少了模型参数量,提升计算效率。
优化策略:
- 卷积核优化:通过实验选择最优的卷积核大小和池化策略,提高特征提取能力。
- 深层网络:构建更深的卷积网络(如ResNet、DenseNet),提升模型的表达能力和准确性。
from keras.models import Sequential
from keras.layers import Conv1D, MaxPooling1D, Flatten, Densedef build_optimized_cnn_model(input_shape):model = Sequential()model.add(Conv1D(64, kernel_size=3, activation='relu', input_shape=input_shape))model.add(MaxPooling1D(pool_size=2))model.add(Conv1D(128, kernel_size=3, activation='relu'))model.add(MaxPooling1D(pool_size=2))model.add(Flatten())model.add(Dense(128, activation='relu'))model.add(Dense(3, activation='softmax'))model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])return modelinput_shape = (100, 4) # 100个时间步,4个特征
optimized_cnn_model = build_optimized_cnn_model(input_shape)
5.3 Transformer模型的优势和优化策略
优势:
- Transformer模型擅长捕捉长时间序列中的复杂依赖关系,适用于分析多模态生理数据。
- 多头注意力机制能够同时关注不同时间步的特征,提高模型的表达能力。
优化策略:
- 多头注意力机制优化:调整注意力头的数量和尺寸,找到最佳配置,提升模型性能。
- 层次优化:通过实验选择最优的Transformer层数和平行化策略,提高模型的效率和准确性。
from keras.models import Model
from keras.layers import Input, Dense, MultiHeadAttention, LayerNormalization, Dropoutdef build_optimized_transformer_model(input_shape, num_heads=4, ff_dim=64):inputs = Input(shape=input_shape)attention_output = MultiHeadAttention(num_heads=num_heads, key_dim=ff_dim)(inputs, inputs)attention_output = LayerNormalization(epsilon=1e-6)(attention_output)ffn_output = Dense(ff_dim, activation='relu')(attention_output)ffn_output = Dense(input_shape[-1])(ffn_output)outputs = LayerNormalization(epsilon=1e-6)(ffn_output)model = Model(inputs, outputs)model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])return modelinput_shape = (100, 4)
optimized_transformer_model = build_optimized_transformer_model(input_shape)
6. 数据隐私与安全策略
在使用穿戴设备监测用户睡眠数据时,确保数据的隐私与安全至关重要。以下是一些关键策略:
- 数据加密:在数据传输和存储过程中,使用加密技术保护数据安全。
from cryptography.fernet import Fernet# 生成密钥
key = Fernet.generate_key()
cipher_suite = Fernet(key)# 加密数据
data = b"Sensitive user data"
encrypted_data = cipher_suite.encrypt(data)# 解密数据
decrypted_data = cipher_suite.decrypt(encrypted_data)
- 数据匿名化:在数据处理和分析过程中,去除或模糊化用户身份信息,保护用户隐私。
import pandas as pd# 模拟用户数据
data = pd.DataFrame({'user_id': ['user1', 'user2', 'user3'],'heart_rate': [70, 65, 80],'sleep_stage': ['deep', 'light', 'REM']
})# 匿名化处理
data['user_id'] = data['user_id'].apply(lambda x: 'user_' + str(hash(x)))
print(data)
- 访问控制:限制对数据的访问权限,确保只有授权人员和系统能够访问用户数据。
from flask import Flask, request, jsonify
from functools import wrapsapp = Flask(__name__)# 模拟用户数据存储
user_data = {'user_1': {'heart_rate': 70, 'sleep_stage': 'deep'},'user_2': {'heart_rate': 65, 'sleep_stage': 'light'}
}# 模拟访问控制
def requires_auth(f):@wraps(f)def decorated(*args, **kwargs):auth = request.headers.get('Authorization')if auth != 'Bearer secret-token':return jsonify({"message": "Unauthorized"}), 403return f(*args, **kwargs)return decorated@app.route('/api/data', methods=['GET'])
@requires_auth
def get_data():user_id = request.args.get('user_id')return jsonify(user_data.get(user_id, {"message": "User not found"}))if __name__ == '__main__':app.run()
7. 深入探讨未来发展方向
7.1. 多模态数据融合
现状与挑战:
当前的穿戴设备主要依赖心率、呼吸率、体温和运动数据进行睡眠监测。虽然这些数据已经能够提供较为全面的睡眠分析,但仍存在一些局限,如对睡眠环境的考虑不足、对其他生理信号(如脑电波)的利用较少。
未来发展:
未来的穿戴设备可以通过集成更多类型的传感器,实现多模态数据融合。这不仅包括更多的生理数据(如皮肤电反应、血氧饱和度),还可以包含环境数据(如噪音、光照、温度)和行为数据(如作息时间、日常活动)。通过这些数据的综合分析,能够更准确地判断用户的睡眠质量,并提供更加个性化的建议。
示例:
# 模拟多模态数据采集
def collect_multimodal_data():heart_rate = np.random.normal(60, 5)respiration_rate = np.random.normal(16, 2)temperature = np.random.normal(36.5, 0.5)movement = np.random.normal(0, 1)skin_conductance = np.random.normal(5, 1) # 皮肤电反应blood_oxygen = np.random.normal(98, 1) # 血氧饱和度noise_level = np.random.normal(30, 5) # 噪音水平return np.array([heart_rate, respiration_rate, temperature, movement, skin_conductance, blood_oxygen, noise_level])# 模拟数据采集
multimodal_data = collect_multimodal_data()
print("多模态数据采集:", multimodal_data)
7.2. 自适应学习
现状与挑战:
目前的模型通常基于固定的数据集进行训练,模型更新和优化需要重新训练并部署。用户的个体差异和动态变化难以实时反映到模型中。
未来发展:
通过自适应学习,可以实现模型的持续优化和个性化调整。自适应学习包括在线学习和增量学习,能够在接收到新的数据和用户反馈后,自动调整模型参数,提升模型的准确性和个性化程度。
示例:
from sklearn.linear_model import SGDClassifier
import numpy as np# 模拟数据
X_train = np.random.rand(100, 7) # 7个特征
y_train = np.random.randint(0, 3, 100) # 3个睡眠阶段# 初始训练
model = SGDClassifier()
model.fit(X_train, y_train)# 模拟新的数据
X_new = np.random.rand(10, 7)
y_new = np.random.randint(0, 3, 10)# 在线学习更新模型
model.partial_fit(X_new, y_new)
7.3. 跨平台集成
现状与挑战:
当前的穿戴设备和睡眠监测系统多为独立运行,缺乏与其他健康管理系统的集成。用户需要分别查看和管理不同平台的数据,不利于全面的健康管理。
未来发展:
通过跨平台集成,可以实现不同健康数据的互通和综合分析。例如,将睡眠数据与日常活动、饮食、心理状态等数据进行关联分析,提供更全面的健康管理服务。跨平台集成还可以实现数据的共享和协同,提高健康管理的整体效果。
示例:
from flask import Flask, request, jsonifyapp = Flask(__name__)# 模拟多平台数据
sleep_data = {'user_1': {'heart_rate': 70, 'sleep_stage': 'deep'},'user_2': {'heart_rate': 65, 'sleep_stage': 'light'}
}activity_data = {'user_1': {'steps': 10000, 'calories_burned': 500},'user_2': {'steps': 8000, 'calories_burned': 400}
}# 跨平台数据集成
@app.route('/api/health_data', methods=['GET'])
def get_health_data():user_id = request.args.get('user_id')if user_id in sleep_data and user_id in activity_data:combined_data = {**sleep_data[user_id], **activity_data[user_id]}return jsonify(combined_data)else:return jsonify({"message": "User not found"}), 404if __name__ == '__main__':app.run()
8. 深度学习模型优化
现状与挑战:
深度学习模型通常计算量大,资源消耗高,难以在资源受限的穿戴设备上高效运行。
未来发展:
通过模型压缩、知识蒸馏等技术,减少模型的计算复杂度和存储需求。此外,使用边缘计算,将部分计算任务下放到设备端,提高实时性和响应速度。
模型压缩和知识蒸馏示例:
from tensorflow_model_optimization.sparsity import keras as sparsity
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 构建一个简单的神经网络模型
def build_model():model = Sequential([Dense(128, activation='relu', input_shape=(7,)),Dense(64, activation='relu'),Dense(3, activation='softmax')])model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])return modelmodel = build_model()# 使用模型剪枝技术
pruning_schedule = sparsity.PolynomialDecay(initial_sparsity=0.30, final_sparsity=0.70, begin_step=1000, end_step=2000)
model_for_pruning = sparsity.prune_low_magnitude(model, pruning_schedule=pruning_schedule)model_for_pruning.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model_for_pruning.summary()
9. 总结
1、通过AI大模型与穿戴设备的深度融合,可以实现更加智能和个性化的睡眠监测与管理。多模态数据融合、实时监测与反馈、个性化建议生成等技术的应用,能够帮助用户更好地理解和改善自己的睡眠质量。未来,随着技术的不断进步,这种智能化的睡眠监测系统将会越来越普及,为用户提供更全面的健康管理服务。
2、通过详细分析AI大模型在穿戴设备睡眠监测中的技术架构、模型选择、数据处理、实时性要求和隐私保护,可以更好地理解其深度融合应用。选择适合的模型并进行优化,确保数据隐私和安全,是实现智能化睡眠监测系统的关键。未来,随着技术的不断进步,这种智能化的睡眠监测系统将会越来越普及,为用户提供更全面和个性化的健康管理服务。
3、AI大模型在穿戴设备睡眠监测中的深度融合应用,是通过多模态数据融合、自适应学习、跨平台集成以及模型优化等多种技术的综合应用,来实现更加智能和个性化的睡眠管理。未来,随着技术的不断进步和数据的积累,这种智能化的睡眠监测系统将会越来越普及,为用户提供更全面、更科学的健康管理服务。
| 欢迎点赞|关注|收藏|评论,您的肯定是我创作的动力 |

相关文章:
AI大模型在健康睡眠监测中的深度融合与实践案例
文章目录 1. 应用方案2. 技术实现2.1 数据采集与预处理2.2 构建与训练模型2.3 个性化建议生成 3. 优化策略4. 应用示例:多模态数据融合与实时监测4.1 数据采集4.2 实时监测与反馈 5. 深入分析模型选择和优化5.1 LSTM模型的优势和优化策略5.2 CNN模型的优势和优化策略…...

【西瓜书】9.聚类
聚类任务是无监督学习的一种用于分类等其他任务的前驱过程,作为数据清洗,基于聚类结果训练分类模型 1.聚类性能度量(有效性指标) 分类任务的性能度量有错误率、精度、准确率P、召回率R、F1度量(P-R的调和平均)、TPR、FPR、AUC回归…...

使用jemalloc实现信号驱动的程序堆栈信息打印
使用jemalloc实现信号驱动的程序堆栈信息打印 本文介绍应用如何集成jemalloc,在接收到SIGUSR1信号10时打印程序的堆栈信息。 1. 编译jemalloc 首先,确保你已经编译并安装了启用prof功能的jemalloc。以下是ubuntu18.04上的编译步骤: git c…...

树的4种遍历
目录 树的四种遍历方式的总结 1. 前序遍历(Pre-order Traversal) 2. 中序遍历(In-order Traversal) 3. 后序遍历(Post-order Traversal) 4. 层序遍历(Level-order Traversal 或 广度优先遍…...

深入探讨5种单例模式
文章目录 一、对比总览详细解释 二、代码1. 饿汉式2. 饱汉式3. 饱汉式-双检锁4. 静态内部类5. 枚举单例 三、性能对比 一、对比总览 以下是不同单例模式实现方式的特性对比表格。表格从线程安全性、延迟加载、实现复杂度、反序列化安全性、防反射攻击性等多个方面进行考量。 …...

SPOOL
-----How to Pass UNIX Variable to SPOOL Command (Doc ID 1029440.6) setenv只有csh才有不行啊PROBLEM DESCRIPTION: You would like to put a file name in Unix and have SQL*Plus read that file name, instead of hardcoding it, because it will change.You want to pa…...

挑战绝对不可能:再证有长度不同的射线
黄小宁 一空间坐标系中有公共汽车A,A中各座位到司机处的距离h是随着座位的不同而不同的变数,例如5号座位到司机处的距离是h3,…h5,…。A移动了一段距离变为汽车B≌A,B中5号座位到司机处的距离h’h3,…h’h5…...

【机器学习】Python与深度学习的完美结合——深度学习在医学影像诊断中的惊人表现
🔥 个人主页:空白诗 文章目录 一、引言二、深度学习在医学影像诊断中的突破1. 技术原理2. 实际应用3. 性能表现 三、深度学习在医学影像诊断中的惊人表现1. 提高疾病诊断准确率2. 辅助制定治疗方案 四、深度学习对医疗行业的影响和推动作用 一、引言 随着…...
MapStruct的用法总结及示例
MapStruct是一个代码生成器,它基于约定优于配置的原则,使用Java注解来简化从源对象到目标对象的映射过程。它主要用于减少样板代码,提高开发效率,并且通过编译时代码生成来保证性能。 我的个人实践方面是在2021年前那时候在项目中…...

redis 05 复制 ,哨兵
01.redis的复制功能,使用命令slaveof 2. 2.1 2.2 3. 3.1 3.1.1 3.1.2 3.1.3 4 4.1 4.2 例子 5.1 这里是从客户端发出的指令 5.2 套接字就是socket 这里是和redis事件相关的知识 5.3 ping一下...

强大的.NET的word模版引擎NVeloDocx
在Javer的世界里,存在了一些看起来还不错的模版引擎,比如poi-tl看起来就很不错,但是那是人家Javer们专属的,与我们.Neter关系不大。.NET的世界里Word模版引擎完全是一个空白。 很多人不得不采用使用Word XML结合其他的模版引擎来…...
MySQL中所有常见知识点汇总
存储引擎 这一张是关于整个存储引擎的汇总知识了。 MySQL体系结构 这里是MySQL的体系结构图: 一般将MySQL分为server层和存储引擎两个部分。 其实MySQL体系结构主要分为下面这几个部分: 连接器:负责跟客户端建立连 接、获取权限、维持和管理…...
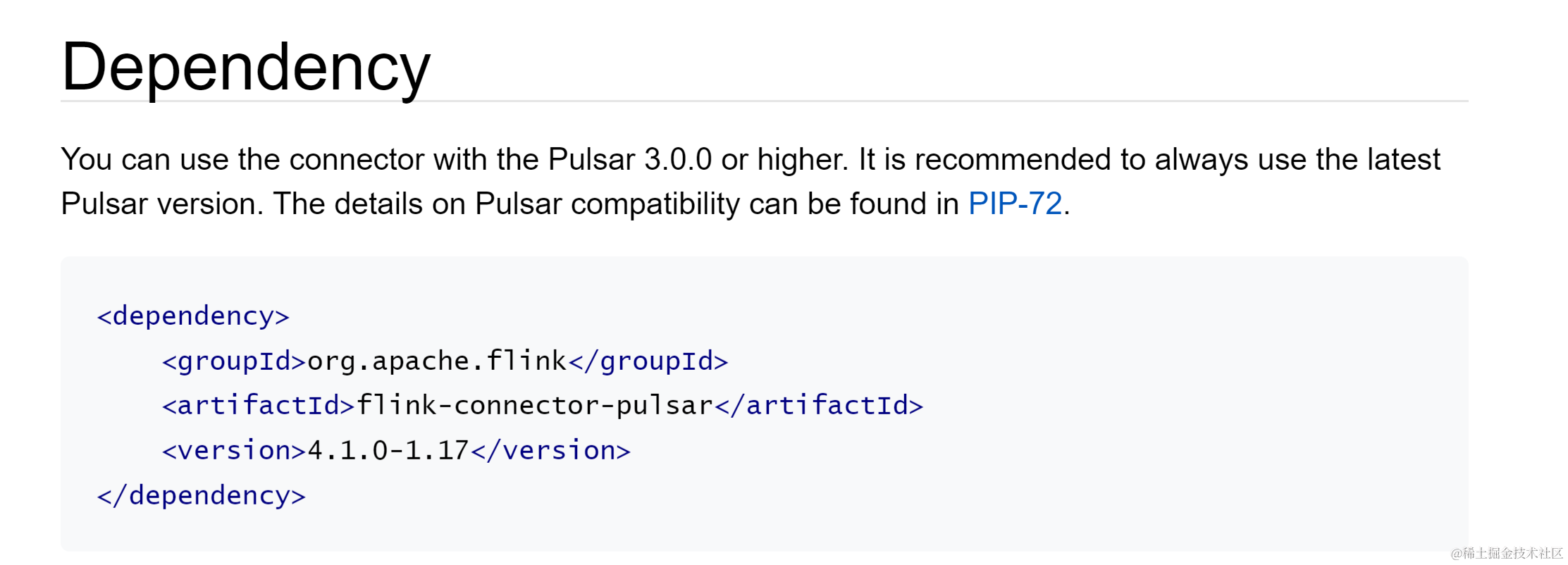
Flink 基于 TDMQ Apache Pulsar 的离线场景使用实践
背景 Apache Flink 是一个开源的流处理和批处理框架,具有高吞吐量、低延迟的流式引擎,支持事件时间处理和状态管理,以及确保在机器故障时的容错性和一次性语义。Flink 的核心是一个分布式流数据处理引擎,支持 Java、Scala、Pytho…...
远程访问及控制
SSH协议 是一种安全通道协议 对通信数据进行了加密处理,用于远程管理 OpenSSH(SSH由OpenSSH提供) 服务名称:sshd 服务端控制程序: /usr/sbin/sshd 服务端配置文件: /etc/ssh/sshd_config ssh存放的客户端的配置文件 ssh是服务端额…...

【代码随想录训练营】【Day 44】【动态规划-4】| 卡码 46, Leetcode 416
【代码随想录训练营】【Day 44】【动态规划-4】| 卡码 46, Leetcode 416 需强化知识点 背包理论知识 题目 卡码 46. 携带研究材料 01 背包理论基础01 背包理论基础(滚动数组)01 背包 二维版本:dp[i][j] 表示从下标为[0-i]的物…...

html5实现个人网站源码
文章目录 1.设计来源1.1 网站首页页面1.2 个人工具页面1.3 个人日志页面1.4 个人相册页面1.5 给我留言页面 2.效果和源码2.1 动态效果2.2 目录结构 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/139564407 ht…...

【内存管理】内存布局
ARM32位系统的内存布局图 32位操作系统的内存布局很经典,很多书籍都是以32位系统为例子去讲解的。32位的系统可访问的地址空间为4GB,用户空间为1GB ~ 3GB,内核空间为3GB ~ 4GB。 为什么要划分为用户空间和内核空间呢? 一般处理器…...

软件试运行方案(Word)
软件试运行方案(直接套用实际项目,原件获取通过本文末个人名片直接获取。) 一、试运行目的 二、试运行的准备 三、试运行时间 四、试运行制度 五、试运行具体内容与要求...
Redis原理篇——哨兵机制
Redis原理篇——哨兵机制 1.Redis哨兵2.哨兵工作原理2.1.哨兵作用2.2.状态监控2.3.选举leader2.4.failover 1.Redis哨兵 主从结构中master节点的作用非常重要,一旦故障就会导致集群不可用。那么有什么办法能保证主从集群的高可用性呢? 2.哨兵工作原理 …...

web前端的MySQL:跨领域之旅的探索与困惑
web前端的MySQL:跨领域之旅的探索与困惑 在数字化浪潮的推动下,web前端与MySQL数据库似乎成为了两个不可或缺的领域。然而,当我们将这两者放在一起,尝试探索web前端与MySQL之间的交互与关联时,却发现这是一次充满困惑…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

【DeepSeek事件驱动架构实战指南】:20年架构师亲授5大核心陷阱与避坑清单
更多请点击: https://kaifayun.com 第一章:DeepSeek事件驱动架构全景认知 DeepSeek事件驱动架构(Event-Driven Architecture, EDA)并非单一技术组件的堆叠,而是一种以事件为第一公民、强调松耦合与异步协作的系统设计…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...

理想二极管控制器:用MOSFET实现毫伏级压降的电源管理方案
1. 理想二极管控制器:告别传统二极管的压降损耗 在电源设计、电池保护、太阳能板并联这些领域里,二极管是个再常见不过的元件。我们用它来防反接、做整流、实现“或”逻辑供电,几乎不假思索。但如果你设计过一个需要处理大电流、低电压的系统…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...

解锁你的音乐收藏:浏览器端音频解密完整指南
解锁你的音乐收藏:浏览器端音频解密完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gitcod…...
——仅限首批500名开发者开放》)
企业级Veo 2提示词治理框架(含合规校验/版本回溯/效果归因三模块)——仅限首批500名开发者开放》
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词治理框架的核心定位与演进逻辑 Veo 2提示词治理框架并非单纯的技术工具升级,而是面向AIGC生产环境规模化、合规化与可审计化需求的战略性基础设施重构。其核心定位在于将离散、经…...