在Windows上用Llama Factory微调Llama 3的基本操作
这篇博客参考了一些文章,例如:教程:利用LLaMA_Factory微调llama3:8b大模型_llama3模型微调保存-CSDN博客
也可以参考Llama Factory的Readme:GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMsUnify Efficient Fine-Tuning of 100+ LLMs. Contribute to hiyouga/LLaMA-Factory development by creating an account on GitHub.![]() https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#installation首先将Llama Factory clone到本地:GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs
https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#installation首先将Llama Factory clone到本地:GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs
其次创建一个conda环境:
conda create -n llama_factory python=3.10激活环境后首先安装pytorch,具体参考这个页面:Start Locally | PyTorch,例如:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia而后进入到LLaMA-Factory文件夹,参考其Readme,运行:
pip install -e .[torch,metrics]同时,按照其Readme,在Windows系统上还需要运行:
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl具体原因我就不展开讲了。然后依次运行:
Set CUDA_VISIBLE_DEVICES=0
Set GRADIO_SHARE=1
llamafactory-cli webui就可以看到其webui了。不过这时候还没有模型参数文件,对于国内用户而言,可以在这里https://modelscope.cn/organization/LLM-Research![]() https://modelscope.cn/organization/LLM-Research
https://modelscope.cn/organization/LLM-Research
进行下载,例如可以下载Llama3中文版本(如果没有git lfs可以用前两个命令安装):
conda install git-lfs
git-lfs install
git lfs clone https://www.modelscope.cn/LLM-Research/Llama3-8B-Chinese-Chat.git下载好之后,可以构造自己的微调数据集,具体而言,按照这里的介绍:
https://github.com/hiyouga/LLaMA-Factory/tree/main/data
Llama Factory支持alpaca and sharegpt的格式,前者类似于这种格式:
[{"instruction": "human instruction (required)","input": "human input (optional)","output": "model response (required)","system": "system prompt (optional)","history": [["human instruction in the first round (optional)", "model response in the first round (optional)"],["human instruction in the second round (optional)", "model response in the second round (optional)"]]}
]
我们构造数据集的时候,最简单的方法就是只构造instruction和output。把生成的json文件放到LLaMA-Factory\data目录下,然后打开dataset_info.json文件,增加这个文件名记录即可,例如我这里增加:
"private_train": {
"file_name": "private_train.json"
},
选择自己的私有数据集,可以预览一下,然后就可以开始训练了。
训练完成后切换到Export,然后在上面的“微调方法”——“检查点路径”中选择刚才存储的目录Train_2024_xxxx之类,然后指定导出文件的目录,然后就可以导出了。
导出之后我们可以加载微调之后的模型并测试了。当然,如果训练数据集比较小的话,测试的效果也不会太好。如果大家只是想对微调效果和特定问题进行展示,可以训练模型到过拟合,呵呵呵。
就记录这么多。
相关文章:
在Windows上用Llama Factory微调Llama 3的基本操作
这篇博客参考了一些文章,例如:教程:利用LLaMA_Factory微调llama3:8b大模型_llama3模型微调保存-CSDN博客 也可以参考Llama Factory的Readme:GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100 LLMsUnify Effi…...

01——生产监控平台——WPF
生产监控平台—— 一、介绍 VS2022 .net core(net6版本) 1、文件夹:MVVM /静态资源(图片、字体等) 、用户空间、资源字典等。 2、图片资源库: https://www.iconfont.cn/ ; 1.资源字典Dictionary 1、…...

33、matlab矩阵分解汇总:LU矩阵分解、Cholesky分解和QR分解
1、LU矩阵分解 语法 语法1:[L,U] lu(A) 将满矩阵或稀疏矩阵 A 分解为一个上三角矩阵 U 和一个经过置换的下三角矩阵 L,使得 A L*U。 语法2:[L,U,P] lu(A) 还返回一个置换矩阵 P,并满足 A P*L*U。 语法3:[L,U,P] …...

C语言——使用函数创建动态内存
一、堆和栈的区别 1)栈(Stack): 栈是一种自动分配和释放内存的数据结构,存储函数的参数值、局部变量的值等。栈的特点是后进先出,即最后进入的数据最先出来,类似于我们堆盘子一样。栈的大小和生命周期是由系统自动管理的,不需要程序员手动释放。2)堆(Heap): 堆是由…...

【PL理论】(16) 形式化语义:语义树 | <Φ, S> ⇒ M | 形式化语义 | 为什么需要形式化语义 | 事实:部分编程语言的设计者并不会形式化语义
💭 写在前面:本章我们将继续探讨形式化语义,讲解语义树,然后我们将讨论“为什么需要形式化语义”,以及讲述一个比较有趣的事实(大部分编程语言设计者其实并不会形式化语义的定义)。 目录 0x00…...

前端杂谈-警惕仅引入一行代码言论
插入一行 JavaScript 代码似乎是一种无受害者犯罪。这只是一个小脚本,对吧?但 JavaScript 可以导入更多 JavaScript。-杰里米基思 “这只是一行代码”是我们经常听到的宣传语。这也可能是我们对自己和他人说的最大的谎言。 “仅用一行添加样式”&#x…...

有关cookie配置的一点记录
Domain:可以用在什么域名下,按最小化原则设Path:可以用在什么路径下,按最小化原则Max-Age和Expires:过期时间,只保留必要时间Http-Only:设置为true,这个浏览器上的JS代码将无法使用这…...

Oracle如何定位硬解析高的语句?
查询subpool 情况 select KSMDSIDX supool,round(sum(KSMSSLEN)/1024/1024,2) SQLA_size_mb from x$ksmss where KSMDSIDX<>0 and KSMSSNAMSQLA group by KSMDSIDX;查询subpool top5 SELECT *FROM (SELECT KSMDSIDX subpool,KSMSSNAM name,ROUND(KSMSSLEN / 102…...
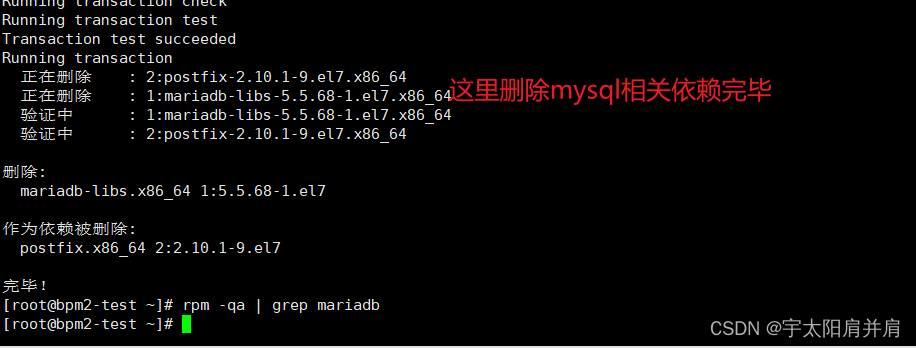
Linux卸载残留MySQL【带图文命令巨详细】
Linux卸载残留MySQL 1、检查残留mysql2、检查并删除残留mysql依赖3、检查是否自带mariadb库 1、检查残留mysql 如果残留mysql组件,使用命令 rpm -e --nodeps 残留组件名 按顺序进行移除操作 #检查系统是否残留过mysql rpm -qa | grep mysql2、检查并删除残留mysql…...

4句话学习-k8s节点是如何注册到k8s集群并且kubelet拿到k8s证书的
一、kubelet拿着CSR(签名请求)使用的是Bootstrap token 二、ControllerManager有一个组件叫CSRAppprovingController,专门来Watch有没有人来使用我这个api. 三、看到有人拿着Bootstrap token的CSR来签名请求了,CSRAppprovingContr…...

2024全国大学生数学建模竞赛优秀参考资料分享
0、竞赛资料 优秀的资料必不可少,优秀论文是学习的关键,视频学习也非常重要,如有需要请点击下方名片获取。 一、赛事介绍 全国大学生数学建模竞赛(以下简称竞赛)是中国工业与应用数学学会主办的面向全国大学生的群众性科技活动,旨…...

QPS,平均时延和并发数
我们当前有两个服务A和B,想要知道哪个服务的性能更好,该用什么指标来衡量呢? 1. 单次请求时延 一种最简单的方法就是使用同一请求体同时请求两个服务,性能越好的服务时延越短,即 R T 返回结果的时刻 − 发送请求的…...
【Python核心数据结构探秘】:元组与字典的完美协奏曲
文章目录 🚀一、元组⭐1. 元组查询的相关方法❤️2. 坑点🎬3. 修改元组 🌈二、集合⭐1. 集合踩坑❤️2. 集合特点💥无序性💥唯一性 ☔3. 集合(交,并,补)🎬4. …...

Golang | Leetcode Golang题解之第137题只出现一次的数字II
题目: 题解: func singleNumber(nums []int) int {a, b : 0, 0for _, num : range nums {b (b ^ num) &^ aa (a ^ num) &^ b}return b }...

Spring和SpringBoot的特点
1.Spring的特点 1.IOC和AOP是Spring的两大核心特性,即控制反转和依赖注入。 2.松耦合:IOC和AOP两大特性可以尽可能地将对象之间的关系解耦 3.可配置:提供外部化配置的方式,可以灵活地配置容器及容器中的Bean 4.一站式:…...

怎么使用join将数组转为逗号分隔的字符串
在JavaScript中,你可以使用Array.prototype.join()方法将一个数组转换为逗号分隔的字符串。join()方法接受一个可选的参数,该参数指定了数组元素之间的分隔符。如果不提供参数,则默认使用逗号(,)作为分隔符。 下面是一…...

Web前端博客论坛:构建、运营与用户体验的深度解析
Web前端博客论坛:构建、运营与用户体验的深度解析 在数字化浪潮的推动下,Web前端博客论坛成为了广大开发者交流技术、分享经验的重要平台。如何构建一个功能齐全、运营有序的博客论坛,以及如何提升用户体验,是摆在每一位前端开发…...

Java从入门到放弃
线程池的主要作用 线程池的设计主要是为了管理线程,为了让用户不需要再关系线程的创建和销毁,只需要使用线程池中的线程即可。 同时线程池的出现也为性能的提升做出了很多贡献: 降低了资源的消耗:不会频繁的创建、销毁线程&…...
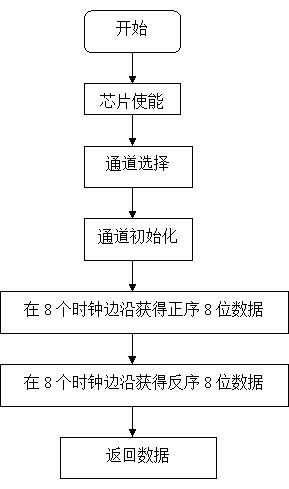
基于51单片机的车辆动态称重系统设计
一 动态称重 所谓动态称重是指通过分析和测量车胎运动中的力,来计算该运动车辆的总重量、轴重、轮重和部分重量数据的过程。动态称重系统按经过车辆行驶的速度划分,可分为低速动态称重系统与高速动态称重系统。因为我国高速公路的限速最高是120,所以高速动态称重系统在理论…...
C语言之常用字符串函数总结、使用和模拟实现
文章目录 目录 一、strlen 的使用和模拟实现 二、strcpy 的使用及模拟实现 三、strcat 的使用和模拟实现 四、strcmp 的使用和模拟实现 五、strncpy 的使用和模拟实现 六、strncat 的使用和模拟实现 七、strncmp 的使用和模拟实现 八、strstr 的使用和模拟实现 九、st…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...
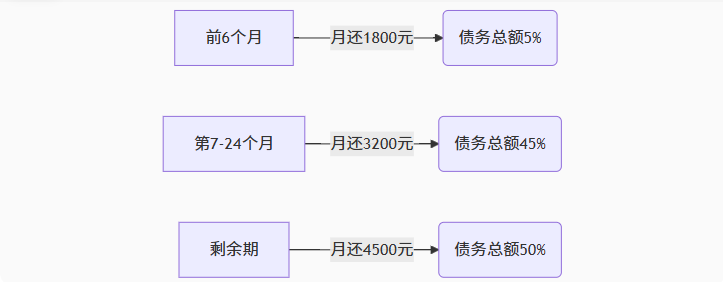
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...