一文者懂LLaMA 2(原理、模型、训练)
引言
LLaMA(Large Language Model Meta AI)是Meta(前身为Facebook)开发的自然语言处理模型家族之一,LLaMA 2作为其最新版本,展示了在语言理解和生成方面的显著进步。本文将详细解读LLaMA 2的基本原理、模型结构和训练方法,帮助读者深入了解这一先进的语言模型。
一、LLaMA 2的基本原理
1.1 Transformer架构
LLaMA 2基于Transformer架构,这是一种在处理序列数据时非常高效的神经网络模型。Transformer架构由编码器(encoder)和解码器(decoder)组成,分别负责处理输入和生成输出。核心机制包括自注意力(self-attention)和前馈神经网络(feed-forward neural network)。
自注意力机制
自注意力机制允许模型在处理每个输入元素时,同时关注序列中的其他所有元素。这种机制通过计算查询(query)、键(key)和值(value)向量之间的点积,实现对序列中相关信息的加权求和,从而捕捉长距离依赖关系。
多头注意力
Transformer模型采用多头注意力(multi-head attention),即在不同的子空间中并行执行多次注意力计算。每个注意力头关注不同的信息,最终将结果合并,增强模型的表达能力。
1.2 预训练与微调
LLaMA 2采用预训练和微调相结合的策略。预训练阶段,模型在大规模无监督文本数据上进行训练,以学习语言的基础结构和模式。微调阶段,模型在特定任务的数据集上进行有监督学习,以优化其在特定应用上的表现。
预训练目标
LLaMA 2的预训练目标是通过最大化条件概率来预测下一个词。模型通过不断调整参数,使其能够生成自然语言文本。这一过程使模型学习到广泛的语言知识和模式。
微调过程
在微调阶段,LLaMA 2在相对较小但更具针对性的任务数据集上进行训练。例如,对于问答任务,模型会在大量的问答对数据上进行微调,使其生成更加准确和相关的回答。
二、LLaMA 2的模型结构
2.1 模型参数
LLaMA 2相比前代模型具有更多的参数,这使得其在语言生成和理解方面表现更加出色。参数的增加使模型能够学习和记忆更多的语言模式和知识。
参数规模
LLaMA 2有多个版本,参数规模从数亿到数百亿不等。不同版本适用于不同的应用场景,小规模模型适合资源受限的环境,大规模模型则在高性能计算平台上表现更佳。
2.2 编码器和解码器
LLaMA 2的核心组件是编码器和解码器,它们共同负责处理输入和生成输出。
编码器
编码器负责将输入序列转换为隐藏表示。每个编码器层包含多头自注意力机制和前馈神经网络。通过多层堆叠,编码器能够逐步提取输入序列的高层次特征。
解码器
解码器根据编码器的输出和先前生成的词,逐步生成输出序列。解码器也包含多头自注意力机制和前馈神经网络。此外,解码器还包含一个额外的注意力机制,用于关注编码器的输出。
2.3 残差连接和层归一化
Transformer模型中的残差连接和层归一化(Layer Normalization)是两个关键的技术细节。残差连接允许梯度在深层网络中更好地传播,避免梯度消失问题。层归一化则有助于加速训练收敛,并提高模型的稳定性。
三、LLaMA 2的训练方法
3.1 数据准备
数据是训练LLaMA 2的基础。训练数据通常包含海量的文本语料,涵盖广泛的主题和领域。数据质量和多样性直接影响模型的性能。
数据收集
训练数据主要来源于互联网,包括新闻文章、博客、社交媒体帖子、维基百科等。为了确保数据的多样性,收集过程会尽量覆盖不同的语言和话题。
数据清洗
数据收集后需要进行清洗和预处理。清洗过程包括去除噪音、过滤低质量文本和处理重复内容。预处理步骤包括分词、去停用词和构建词典等。
3.2 预训练过程
预训练是LLaMA 2学习语言基础结构的关键阶段。通过在大规模无监督文本数据上训练,模型能够捕捉广泛的语言模式和知识。
训练策略
预训练采用自监督学习策略,目标是通过最大化条件概率来预测下一个词。模型在训练过程中不断调整参数,使其生成的文本更加自然和连贯。
计算资源
预训练需要大量计算资源,通常在高性能计算平台上进行。分布式训练和并行计算技术是提升训练效率的关键。模型的参数规模越大,训练所需的计算资源也越多。
3.3 微调过程
微调是优化LLaMA 2在特定任务上表现的重要阶段。通过在有监督的数据集上进行训练,模型能够更好地适应具体应用场景。
任务定义
微调阶段的任务定义取决于具体应用。例如,在问答任务中,输入是问题,输出是答案;在文本生成任务中,输入是提示词,输出是生成的文本。
数据集选择
选择合适的数据集进行微调是确保模型性能的关键。数据集应尽量覆盖目标任务的多样性和复杂性。常用的数据集包括SQuAD(问答)、GLUE(文本分类)和OpenAI的GPT-3 benchmark(文本生成)等。
超参数调整
微调过程中,超参数的选择和调整对模型性能有重要影响。常见的超参数包括学习率、批量大小、优化器等。通过实验和验证,选择最优的超参数配置,以获得最佳的微调效果。
四、LLaMA 2的应用场景
4.1 对话系统
LLaMA 2在对话系统中表现出色。通过预训练和微调,模型能够生成连贯、自然的对话回复,应用于客服、虚拟助手等场景。
4.2 内容生成
LLaMA 2可以用于自动生成高质量的文本内容,包括新闻报道、博客文章、产品描述等。通过提供合适的提示词和主题,模型能够快速生成连贯的文本。
4.3 翻译与语言学习
LLaMA 2支持多语言处理,能够在翻译和语言学习中发挥重要作用。模型能够提供高质量的翻译服务,并用于语言学习的辅助工具,如生成练习题和测试题。
4.4 数据分析与信息提取
LLaMA 2在数据分析和信息提取方面也具有广泛应用。通过自然语言处理技术,模型能够从海量文本中提取关键信息,辅助数据分析和决策。
五、LLaMA 2的优势与挑战
5.1 优势
- 高质量文本生成:LLaMA 2能够生成连贯、自然的文本,适用于多种应用场景。
- 强大的上下文理解:通过Transformer架构和自注意力机制,LLaMA 2能够理解复杂的上下文关系。
- 多语言支持:LLaMA 2支持多种语言的处理和生成,适应全球用户的需求。
- 灵活的应用场景:LLaMA 2可以应用于对话系统、内容生成、翻译、数据分析等多个领域,具有广泛的实用性。
5.2 挑战
- 计算资源需求高:大规模模型的训练和推理需要大量计算资源,带来高昂的成本。
- 数据偏见与伦理问题:模型训练依赖于大量文本数据,可能包含偏见和错误信息,导致生成的文本存在潜在问题。
- 安全与隐私:在处理用户数据时,需要确保数据的安全性和隐私保护,防止数据泄露和滥用。
结论
LLaMA 2作为Meta开发的先进语言模型,展示了在语言理解和生成方面的强大能力。通过深入理解其基本原理、模型结构和训练方法,用户可以更好地利用这一工具,实现高效、智能的文本处理。尽管面临计算资源、数据偏见和伦理等方面的挑战,LLaMA 2的应用前景依然广阔。未来的研究和应用需要在提高模型性能的同时,解决这些问题,推动自然语言处理技术发展。
相关文章:
)
一文者懂LLaMA 2(原理、模型、训练)
引言 LLaMA(Large Language Model Meta AI)是Meta(前身为Facebook)开发的自然语言处理模型家族之一,LLaMA 2作为其最新版本,展示了在语言理解和生成方面的显著进步。本文将详细解读LLaMA 2的基本原理、模型…...

MySQL 存储函数及调用
1.mysql 存储函数及调用 在MySQL中,存储函数(Stored Function)是一种在数据库中定义的特殊类型的函数,它可以从一个或多个参数返回一个值。存储函数在数据库层面上封装了复杂的SQL逻辑,使得在应用程序中调用时更加简单…...

设计模式七大原则-单一职责原则SingleResponsibility
七大原则是在设计“设计模式”的时候需要用到的原则,它们的存在是为了保证设计模式达到以下几种目的: 1.代码重用性 2.可读性 3.可拓展性 4.可靠性(增加新的功能后,对原来的功能没有影响) 5.使程序呈现高内聚、低耦合的…...
msfconsole利用Windows server2008cve-2019-0708漏洞入侵
一、环境搭建 Windows系列cve-2019-0708漏洞存在于Windows系统的Remote Desktop Services(远程桌面服务)(端口3389)中,未经身份验证的攻击者可以通过发送特殊构造的数据包触发漏洞,可能导致远程无需用户验…...
)
Reinforcement Learning学习(三)
前言 最近在学习Mujoco环境,学习了一些官方的Tutorials以及开源的Demo,对SB3库的强化学习标准库有了一定的了解,尝试搭建了自己的环境,基于UR5E机械臂,进行了一个避障的任务,同时尝试接入了图像大模型API,做了一些有趣的应用,参考资料如下: https://mujoco.readthedo…...

hw meta10 adb back up DCIM
1. centos install adb 2. HW enable devlepment mode & enalbe adb debug 3. add shell root/zt/adb-sync python3 ./adb-sync --reverse /sdcard/DCIM/Camera /root/zt/meta10...

Unity2D游戏制作入门 | 12(之人物受伤和死亡的逻辑动画)
上期链接:Unity2D游戏制作入门 | 11(之人物属性及伤害计算)-CSDN博客 上期我们聊到了人物的自身属性和受伤时的计算,我们先给人物和野猪挂上属性和攻击属性的代码,然后通过触发器触发受伤的事件。物体(人物也好敌人也行ÿ…...

从河流到空气,BL340工控机助力全面环保监测网络构建
在环保监测领域,智能化、高效率的监测手段正逐步成为守护绿水青山的新常态。其中,ARMxy工业计算机BL340凭借其强大的处理能力、高度的灵活性以及广泛的兼容性,在水质监测站、空气质量检测、噪音污染监控等多个环保应用场景中脱颖而出…...
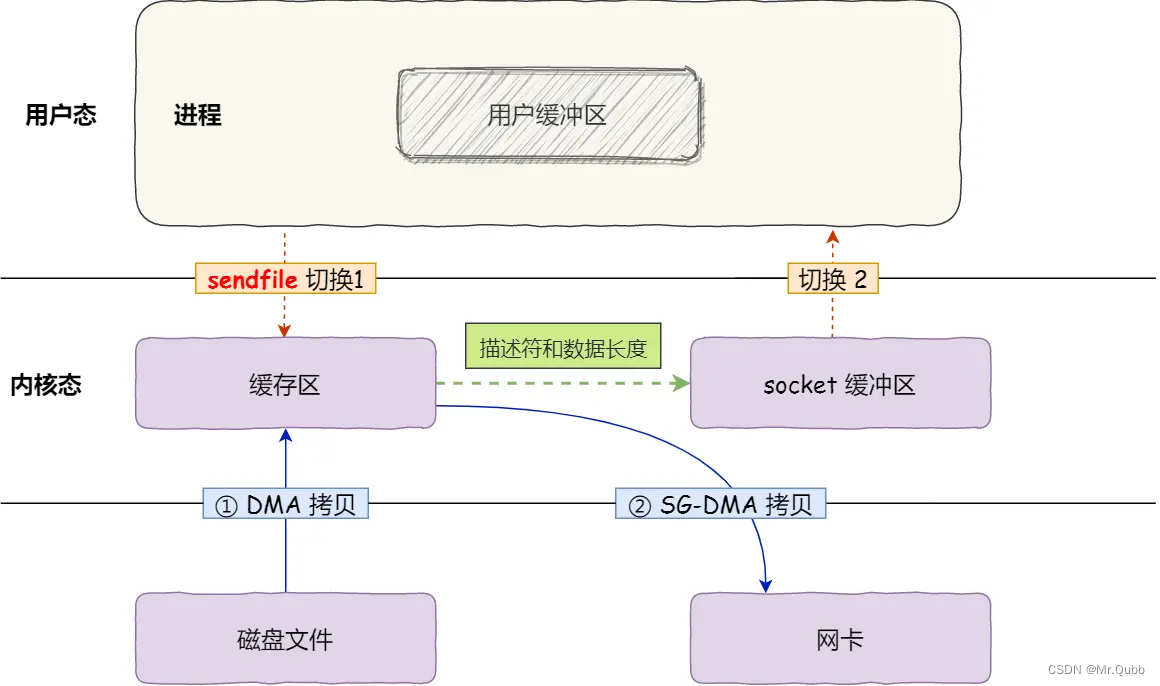
零拷贝技术
背景 磁盘可以说是计算机系统重最慢的硬件之一,读写速度相对内存10以上,所以针对优化磁盘的技术非常的多,比如:零拷贝、直接I/O、异步I/O等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统内核中的…...

Flutter_Android上架GooglePlay_问题
上架GooglePlay权限问题 问题描述 REQUEST_INSTALL_PACKAGES 权限问题解决方式 方式1 找到所有使用该权限的库修改删除该权限引用 方式2 打开项目 ~/andoird/app/src/main/AndroidMainfest.xml 添加文本<uses-permission android:name"android.permission.REQUES…...

【Java】解决Java报错:NumberFormatException
文章目录 引言1. 错误详解2. 常见的出错场景2.1 字符串包含非数字字符2.2 空字符串或 null 字符串2.3 数值超出范围 3. 解决方案3.1 验证字符串格式3.2 使用异常处理3.3 处理空字符串和 null 4. 预防措施4.1 数据验证4.2 编写防御性代码4.3 单元测试 结语 引言 在Java编程中&a…...
视觉大模型(VLLM)学习笔记
视觉多模态大模型(VLLM) InternVL 1.5 近日,上海人工智能实验室 OpenGVLab 团队、清华大学、商汤科技合作推出了开源多模态大语言模型项目InternVL 1.5,它不仅挑战了商业模型巨头例如 GPT-4V 的霸主地位,还让我们不禁…...

【软考的系统分析师的考题考点解析2025】
2024-2025系统分析师考试(简称软考)是计算机技术与软件专业技术资格(水平)考试中的高级资格考试,主要考察考生在系统分析、系统设计、项目管理等方面的知识和技能。以下是软考系统分析师的常见考点、考题和重点&#x…...

JavaScript前端技术入门教程
引言 在前端开发的广阔天地中,JavaScript无疑是最耀眼的一颗明星。它赋予了网页动态交互的能力,让网页从静态的文本和图片展示,进化为可以与用户进行实时交互的丰富应用。本文将带您走进JavaScript的世界,为您提供一个入门级的教…...

类和对象(上续)
前言:本文介绍类和对象中的一些比较重要的知识点,为以后的继续学习打好基础。 目录 拷贝构造 拷贝构造的特征: 自定义类型的传值传参 自定义类型在函数中的传值返回 如果返回值时自定义的引用呢? 在什么情况下使用呢&#…...
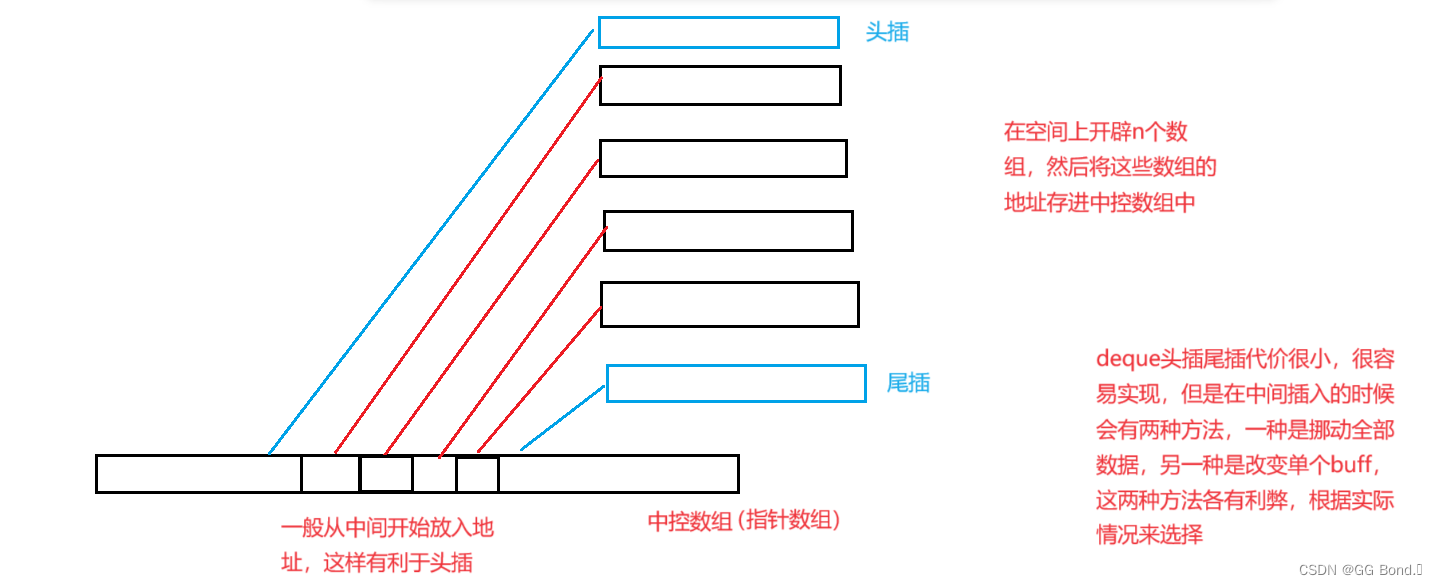
【C++初阶学习】第十三弹——优先级队列及容器适配器
C语言栈:数据结构——栈(C语言版)-CSDN博客 C语言队列:数据结构——队列(C语言版)-CSDN博客 C栈与队列:【C初阶学习】第十二弹——stack和queue的介绍和使用-CSDN博客 前言: 在前面,我们已经…...
Java(十七)---ArrayList的使用
文章目录 前言1.ArrayList的简介2. ArrayList使用2.1.ArrayList的构造2.2.ArrayList的扩容机制(JDK17) 3.ArrayList的常见操作4. ArrayList的具体使用4.1.[杨辉三角](https://leetcode.cn/problems/pascals-triangle/description/)4.2.简单的洗牌游戏 5.ArrayList的问题及思考 …...
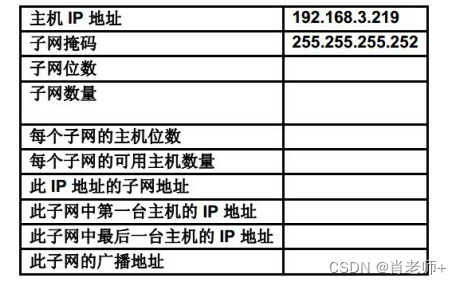
实验六、IPv4 地址的子网划分,第 2 部分《计算机网络》
你有没有发现,困的时候真的清醒不了。 目录 一、实验目的 二、实验内容 三、实验小结 一、实验目的 完成本练习之后,您应该能够确定给定 IP 地址和子网掩码的子网信息。 知道 IP 地址、网络掩码和子网掩码后,您应该能够确定有关该 IP 地…...

定个小目标之刷LeetCode热题(12)
这是一道简单题,使用位运算中的异或运算即可,异或运算有以下性质: 1、任何数异或 0 结果仍然是原来的数,即 a⊕0a 2、任何数和其自身做异或运算,结果是 0 所以我们只需要让数组里的所有元素进行异或运算得到的结果就…...

MYSQL内存占用查询语句
可以通过以下 SQL 语句查询相关配置参数的当前值: InnoDB 缓冲池大小 (innodb_buffer_pool_size): SHOW VARIABLES LIKE innodb_buffer_pool_size;最大连接数 (max_connections): SHOW VARIABLES LIKE max_connections;临时表大小 (tmp_table…...

python flask django网络在线选课成绩管理系统
目录系统架构设计数据库模型设计核心功能模块成绩管理模块系统安全措施部署方案测试计划开发路线图项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作系统架构设计 采用前后端分离架构,前端使…...

ST7789驱动实战:从SPI时序到RGB565显示的完整配置解析
1. ST7789驱动芯片初探:从数据手册到实战准备 第一次拿到ST7789的数据手册时,我完全被里面密密麻麻的时序图和寄存器描述搞懵了。这玩意儿看起来就像天书,但别担心,跟着我的步骤走,你也能轻松搞定。ST7789是一款240x32…...

PyTorch稀疏张量实战:COO与CSR格式高效存储与计算指南
1. 稀疏张量入门:为什么需要特殊存储格式? 第一次接触稀疏张量这个概念时,我也曾疑惑:为什么普通的张量存储方式不够用?直到处理一个自然语言处理的词向量矩阵时,我才真正理解它的价值。想象一下࿰…...

mT5分类增强版中文-base入门必看:零样本文本增强API调用完整指南
mT5分类增强版中文-base入门必看:零样本文本增强API调用完整指南 1. 引言:什么是零样本文本增强? 想象一下,你手头有一篇文案,想让它变得更生动、更有吸引力,或者想为同一个意思生成几种不同的表达方式。…...

【cuda】deepep 学习 cudaHostGetDevicePointer cudaHostAllocMapped
https://blog.csdn.net/KIDGIN7439/article/details/146131893?spm1001.2014.3001.5502 notify_dispatch过程中会计算其他所有rank发送给当前rank多少token,写入到host的moe_recv_counter_mapped,还会计算其他所有rdma_rank发送给当前rank多少token&am…...
)
Nuclei Studio新手必看:从编译到GD-Link调试的完整流程(附常见问题解决)
Nuclei Studio新手必看:从编译到GD-Link调试的完整流程(附常见问题解决) 第一次打开Nuclei Studio时,面对密密麻麻的菜单选项和复杂的配置界面,很多RISC-V开发新手都会感到手足无措。作为GD32VF103系列MCU的官方推荐开…...
在多输出数据回归预测中的应用及Matlab代码实现)
基于金枪鱼群算法优化BP神经网络(TSO-BP)在多输出数据回归预测中的应用及Matlab代码实现
基于金枪鱼群算法优化BP神经网络(TSO-BP)的多输出数据回归预测TSO-BP多输出数据回归 matlab代码注:暂无Matlab版本要求--推荐2018B版本及以上金枪鱼群算法(TSO)遇上BP神经网络会发生什么化学反应?最近在折腾多输出数据回归预测时发…...

联合循环——33 油罐,水罐,凝汽器和地下管道阴极保护
一、阴极保护一般有两种方式: 在电厂、化工装置及管道系统的阴极保护(Cathodic Protection)技术中,常用的两种方法为: 牺牲阳极法(Sacrificial Anode Cathodic Protection)外加电源法࿰…...

Hasktorch优化器全解析:从SGD到Adam的高效参数更新策略
Hasktorch优化器全解析:从SGD到Adam的高效参数更新策略 【免费下载链接】hasktorch Tensors and neural networks in Haskell 项目地址: https://gitcode.com/gh_mirrors/ha/hasktorch Hasktorch作为Haskell生态中专注于张量和神经网络的深度学习库ÿ…...

cv_resnet101_face-detection_cvpr22papermogface保姆级教程:Windows/Linux双平台部署指南
cv_resnet101_face-detection_cvpr22papermogface保姆级教程:Windows/Linux双平台部署指南 你是不是也遇到过这样的烦恼?想在自己的电脑上跑一个人脸检测模型,结果被各种环境配置、依赖安装、路径设置搞得焦头烂额。网上的教程要么太简单&am…...