【Spring Boot】过滤敏感词的两种实现
文章目录
- 项目场景
- 前置知识
- 前缀树
- 实现方式
- 解决方案一:读取敏感词文件生成前缀树+构建敏感词过滤器
- 1. 导入敏感词文件 `src/main/resources/sensitive_words.txt`
- 2. 构建敏感词过滤器 `SensitiveFilter`
- 3. 测试与使用
- 解决方案二:使用第三方插件 `houbb/sensitive-word`(推荐)
- 1. 添加依赖
- 2. 测试与使用(使用默认过滤策略)
- 3. 构建配置类`SensitiveWordConfig`(使用自定义过滤策略)
- 4. 测试与使用(使用自定义过滤策略)
- 两种实现方式的对比
项目场景
基于 Spring Boot 的论坛系统:用户发布的内容需进行敏感词过滤。
前置知识
前缀树
- Q:前缀树和普通N叉树的区别?
- A:前缀树(Trie,也称字典树、单词查找树或键树)。
- 设计目的:
- 前缀树:专门设计用于高效地存储和检索字符串集合中的键(字符串)。它的结构允许快速的查找、插入和删除操作,特别适合于字符串前缀匹配,如自动补全、拼写检查、敏感词过滤等场景。
- 普通N叉树:是一种更通用的树形数据结构,其中每个节点可以有任意数量(包括零)的子节点,最多可达N个。它没有特定于字符串处理的特性,广泛应用于各种需要多路分支的数据结构场景,如文件系统的目录结构、表达式树等。
- 节点结构:
- 前缀树:每个节点通常包含一个字符和一个映射到其子节点的字符到节点的映射(如HashMap或数组)。根节点通常不表示任何字符,而从根到任意叶节点的路径上的字符序列组成一个字符串,叶节点或标记为关键词结束的节点代表一个完整的字符串。
- 普通N叉树:节点可能包含数据以及指向其子节点的指针数组或列表,但这些子节点之间的关系不一定有特定的字符关联,节点的数据结构和含义更多样。
- 查找效率:
- 前缀树:由于其特殊的结构设计,前缀树支持高效的前缀匹配,可以在O(L)时间内(L为关键词长度)查找到所有具有相同前缀的字符串,或者确定某个字符串是否在集合中。
- 普通N叉树:查找效率依赖于树的具体形态和查找算法,一般情况下不如前缀树在字符串前缀匹配上的效率高。
- 空间利用率:
- 前缀树:可能会有较高的空间消耗,因为它存储了所有字符串的公共前缀,特别是当存储的字符串有很多相似前缀时。
- 普通N叉树:空间使用更加灵活,取决于树的形状,但通常不会为了存储前缀信息而额外消耗空间。
- 设计目的:
总之,前缀树是一种针对字符串处理优化的特殊N叉树,强调了字符串前缀的高效存储和查询,而普通N叉树则是一种更为通用的结构,适用于多种类型的多路分支数据组织。
实现方式
解决方案一:读取敏感词文件生成前缀树+构建敏感词过滤器
参考:雨下一整晚Real’s Blog - 【Java项目】社区论坛项目 - 敏感词过滤
前缀树
- 名称:Trie 、字典树、查找树
- 特点:查找效率高,消耗内存大
- 应用:字符串检索、词频统计、字符串排序等
敏感词过滤器
- 定义前缀树
- 根据敏感词,初始化前缀树
- 编写过滤敏感词的方法
1. 导入敏感词文件 src/main/resources/sensitive_words.txt
此处为示例文件内容。
元
购物车
fuck
abc
bf
be
2. 构建敏感词过滤器 SensitiveFilter
package com.example.filter;import com.example.constant.SensitiveConstant;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.CharUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;/*** 敏感词过滤器*/
@Slf4j
@Component
public class SensitiveFilter {// 创建前缀树的根节点private final TrieNode rootNode = new TrieNode();/*** 初始化,读取敏感词*/@PostConstruct // 确保在Bean初始化后执行public void init() {// 1. 从类路径加载敏感词文件: 使用文件存储敏感词库可以直接进行一次性读取和处理,无需依赖数据库系统,并且保证离线可用。try (InputStream inputStream = this.getClass().getClassLoader().getResourceAsStream(SensitiveConstant.SENSITIVE_WORDS_FILE);InputStreamReader inputStreamReader = new InputStreamReader(inputStream);BufferedReader bufferedReader = new BufferedReader(inputStreamReader);// Java 7及以后的版本中,引入了一项称为"try-with-resources"的新特性,它允许自动管理资源,确保在try语句块执行完毕后,不论是否发生异常,都会正确关闭或释放资源) {// 2. 逐行读取敏感词并加入到前缀树中String keyword;while ((keyword = bufferedReader.readLine()) != null) {this.addKeyWord(keyword);}} catch (IOException ex) {log.error("敏感词文件读取失败: " + ex.getMessage());}}/*** 将敏感词添加到前缀树中* @param keyword 待添加的敏感词*/private void addKeyWord(String keyword) {// 1. 初始化操作,将当前处理节点设为根节点TrieNode tempNode = rootNode;// 2. 将待添加的敏感词字符串转换为字符数组以便遍历char[] chars = keyword.toCharArray();// 3. 遍历字符数组,逐个字符构建前缀树for (int i = 0; i < chars.length; i++) {// 3.1. 从当前处理节点的子节点Map中获取当前字符对应的节点TrieNode childrenNode = tempNode.getChildrenNode(chars[i]);// 3.1.1 若当前字符没有对应的节点,则创建一个新节点,并放入当前处理节点的子节点Map中if (childrenNode == null) {childrenNode = new TrieNode();tempNode.setChildrenNode(chars[i], childrenNode);}// 3.2. 若当前字符为敏感词字符串的最后一个字符,则标记当前字符的对应节点为敏感词的结尾节点if (i == chars.length - 1) {childrenNode.setKeywordEnd(true);}// 3.3. 移动到下一层,使当前字符对应的节点成为新的当前处理节点,继续构建或遍历过程tempNode = childrenNode;}}/*** 过滤文本,移除或替换其中的敏感词,并返回处理后的文本* @param text 待过滤的文本* @return 过滤后的文本*/public String filter(String text) {// 1. 检查输入文本是否为空或仅包含空白字符,如果是,则直接返回null,表示无内容无需过滤if (StringUtils.isBlank(text)) {return null;}// 2. 初始化变量TrieNode tempNode = rootNode; // 2.1. 初始化为前缀树的根节点,用于遍历查找。int begin = 0, end = 0; // 2.2. 分别用于标记待检查文本区间的起始和结束位置StringBuilder result = new StringBuilder(); // 2.3. 累积过滤后的文本// 3. 遍历整个文本进行过滤处理while (begin < text.length()) {char c = text.charAt(end);// 3.1. 遇到符号字符if (isSymbol(c)) {// 3.1.1. 如果当前处于根节点,即没有匹配到任何敏感词的开始,直接保留符号,并移动beginif (tempNode == rootNode) {result.append(c);begin++;}// 3.1.2. 跳过当前符号,并继续检查下一个字符end++;continue;}// 3.2. 检查当前字符区间text[begin...end]是否是某个敏感词的一部分tempNode = tempNode.getChildrenNode(c);// 3.2.1. 如果当前字符没有对应的子节点,即text[begin...end]不是敏感词的组成部分if (tempNode == null) {result.append(text.charAt(begin)); // 3.2.1.1. 保存begin位置的字符到结果end = ++begin; // 3.2.1.2. 移动begin和end指针,准备检查下一个可能的敏感词 begin++; end = begin;tempNode = rootNode; // 3.2.1.3. 重置tempNode为根节点准备下一轮匹配}// 3.2.2. 如果当前字符路径已到达一个敏感词的结尾,即text[begin...end]是敏感词else if (tempNode.isKeywordEnd()) {result.append(StringUtils.repeat(SensitiveConstant.REPLACEMENT, end - begin + 1)); // 3.2.2.1. 替换敏感词区间begin = ++end; // 3.2.2.2. 移动begin和end指针,准备检查下一个可能的敏感词 end++; begin = end;tempNode = rootNode; // 3.2.2.3. 重置tempNode为根节点准备下一轮匹配}// 3.2.3. 如果当前字符区间text[begin...end]是潜在敏感词的一部分但不是结尾,继续匹配下一个字符else {// 3.2.3.1. 检查下一个字符是否存在,存在则移动end指针;否则,回退begin到当前位置,准备重新匹配if (end < text.length() - 1) {end++;} else {end = begin;}}}// 4. 将剩余未检查的文本(若有)添加到结果中result.append(text.substring(begin));// 5. 返回过滤后的文本return result.toString();}/*** 判断字符是否为符号字符* @param character 待判断的字符* @return true表示是符号字符,需要跳过;false表示不是符号字符,不跳过*/private boolean isSymbol(Character character) {// 0x2E80~0x9FFF是东亚文字: 判断字符是否不属于ASCII字母数字且不在东亚文字范围内return !CharUtils.isAsciiAlphanumeric(character) && (character < 0x2E80 || character > 0x9FFF);}/*** 内部类,定义前缀树的节点*/private static class TrieNode {private boolean isKeywordEnd = false; // 当前节点是否为敏感词的末尾节点private final Map<Character, TrieNode> childrenNode = new HashMap<>(); // 当前节点的子节点// Getter和Setter方法public boolean isKeywordEnd() {return isKeywordEnd;}public void setKeywordEnd(boolean keywordEnd) {isKeywordEnd = keywordEnd;}public TrieNode getChildrenNode(Character c) {return childrenNode.get(c);}public void setChildrenNode(Character c, TrieNode node) {childrenNode.put(c, node);}}}
这里我把敏感词过滤器的相关常量都写到一个常量类里了,也可以直接写在过滤器里。
package com.example.constant;/*** 敏感词过滤器的相关常量*/
public class SensitiveConstant {/*** 敏感词文件名称*/public static final String SENSITIVE_WORDS_FILE = "sensitive_words.txt";/*** 用于替换敏感词的字符*/public static final Character REPLACEMENT = '*';
}
3. 测试与使用
创建一个测试类测一下就行。
package com.example.filter;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import static org.junit.jupiter.api.Assertions.*;@SpringBootTest
class SensitiveFilterTest {@Autowiredprivate SensitiveFilter sensitiveFilter;@Testvoid filter() {String result = sensitiveFilter.filter("accfuckxx元bitch购物车bitchjwbc");System.out.println(result);}
}
运行结果:
acc****xx*bitch***bitchjwbc
可以实现过滤,但是完全基于敏感词文件内容,需要自行完善文件。也许可以结合正则表达式扩展?不是很灵活,没研究过了。
解决方案二:使用第三方插件 houbb/sensitive-word(推荐)
参考(更多介绍见):常见的敏感词过滤方案汇总以及高效工具sensitive-word快速实践!
houbb/sensitive-word项目源码:https://github.com/houbb/sensitive-word
1. 添加依赖
<dependency><groupId>com.github.houbb</groupId><artifactId>sensitive-word</artifactId><version>0.17.0</version>
</dependency>
2. 测试与使用(使用默认过滤策略)
package com.example.filter;import com.github.houbb.sensitive.word.core.SensitiveWordHelper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import static org.junit.jupiter.api.Assertions.*;@SpringBootTest
class SensitiveFilterTest {@Autowiredprivate SensitiveFilter sensitiveFilter;@Testvoid filter() {String result = sensitiveFilter.filter("accfuckxx元bitch购物车bitchjwbc");System.out.println(result);System.out.println("-------------------------------");result = SensitiveWordHelper.replace("accfuckxx元bitch购物车bitchjwbc");System.out.println(result);result = SensitiveWordHelper.replace("Ⓕⓤc⒦ the bad words");System.out.println(result);result = SensitiveWordHelper.replace("ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦ the bad words");System.out.println(result);result = SensitiveWordHelper.replace("fffuuck the bad words");System.out.println(result);}
}
运行结果:
acc****xx*bitch***bitchjwbc
-------------------------------
acc****xx元bitch购物车bitchjwbc
**** the bad words
ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦ the bad words
fffuuck the bad words
可以实现基础过滤。比读取文件更方便。
(忽略掉这里的“元”和“购物车”。只是为了文章过审把一些很offensive的词换成了随便写的词嗯。)
如果要设置更多需要过滤的内容,可以参考以下步骤。
3. 构建配置类SensitiveWordConfig(使用自定义过滤策略)
自己按照需求调一下就好。
package com.example.config;import com.github.houbb.sensitive.word.bs.SensitiveWordBs;
import com.github.houbb.sensitive.word.support.ignore.SensitiveWordCharIgnores;
import com.github.houbb.sensitive.word.support.resultcondition.WordResultConditions;
import com.github.houbb.sensitive.word.support.tag.WordTags;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** 配置类,用于设置敏感词过滤器的自定义过滤策略* 更多配置见 https://github.com/houbb/sensitive-word*/
@Configuration
public class SensitiveWordConfig {/*** 初始化引导类* @return 初始化引导类* @since 1.0.0*/@Beanpublic SensitiveWordBs sensitiveWordBs() {SensitiveWordBs wordBs = SensitiveWordBs.newInstance().ignoreCase(true) // 忽略大小写,默认值为true.ignoreWidth(true) // 忽略半角圆角,默认值为true.ignoreNumStyle(true) // 忽略数字的写法,默认值为true.ignoreChineseStyle(true) // 忽略中文的书写格式,默认值为true.ignoreEnglishStyle(true) // 忽略英文的书写格式,默认值为true.ignoreRepeat(false) // 忽略重复词,默认值为false.enableNumCheck(false) // 是否启用数字检测,默认值为false.enableEmailCheck(false) // 是有启用邮箱检测,默认值为false.enableUrlCheck(false) // 是否启用链接检测,默认值为false.enableIpv4Check(false) // 是否启用IPv4检测,默认值为false.enableWordCheck(true) // 是否启用敏感单词检测,默认值为true.numCheckLen(8) // 数字检测,自定义指定长度,默认值为8.wordTag(WordTags.none()) // 词对应的标签,默认值为none.charIgnore(SensitiveWordCharIgnores.defaults()) // 忽略的字符,默认值为none.wordResultCondition(WordResultConditions.alwaysTrue()) // 针对匹配的敏感词额外加工,比如可以限制英文单词必须全匹配,默认恒为真.init();return wordBs;}
}
4. 测试与使用(使用自定义过滤策略)
在刚刚的配置类中已经启用了数字检测。
.enableNumCheck(true) // 是否启用数字检测,默认值为false
测一下。
package com.example.filter;import com.github.houbb.sensitive.word.bs.SensitiveWordBs;
import com.github.houbb.sensitive.word.core.SensitiveWordHelper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import static org.junit.jupiter.api.Assertions.*;@SpringBootTest
class SensitiveFilterTest {...@Autowiredprivate SensitiveWordBs sensitiveWordBs;...@Testvoid test() {String result = sensitiveWordBs.replace("accfuckxx元bitch购物车bitchjwbc");System.out.println(result);result = sensitiveWordBs.replace("Ⓕⓤc⒦ the bad words");System.out.println(result);result = sensitiveWordBs.replace("ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦ the bad words");System.out.println(result);result = sensitiveWordBs.replace("fffuuck the bad words");System.out.println(result);result = sensitiveWordBs.replace("12345678dwnoxcw");System.out.println(result);result = sensitiveWordBs.replace("123456789dwnoxcw");System.out.println(result);result = sensitiveWordBs.replace("一二三四五六七八九dwnoxcw");System.out.println(result);result = sensitiveWordBs.replace("这个是我的微信:9⓿二肆⁹₈③⑸⒋➃㈤㊄");System.out.println(result);}
}
运行结果:
acc****xx元bitch购物车bitchjwbc
**** the bad words
*********** the bad words
******* the bad words
********dwnoxcw
*********dwnoxcw
*********dwnoxcw
这个是我的微信:************
就很好用了。
(忽略掉这里的“元”和“购物车”。只是为了文章过审把一些很offensive的词换成了随便写的词嗯。)
两种实现方式的对比
- 自行构建前缀树过滤器:
- 优势:高度定制,易于理解与维护,无外部依赖。
- 劣势:开发耗时,需优化性能,学习成本。
- 使用第三方开源项目:
- 优势:快速集成,功能成熟,社区支持。
- 劣势:依赖管理,安全风险,定制受限。
根据项目需求紧迫性、定制化需求及团队技术背景综合选择。简单需求或有定制化要求倾向自建;追求快速、功能全面则推荐使用现成开源方案。
最后。全文仅做学习交流使用,参考来源均已标明。
感谢提供开源的大佬们。
相关文章:

【Spring Boot】过滤敏感词的两种实现
文章目录 项目场景前置知识前缀树 实现方式解决方案一:读取敏感词文件生成前缀树构建敏感词过滤器1. 导入敏感词文件 src/main/resources/sensitive_words.txt2. 构建敏感词过滤器 SensitiveFilter3. 测试与使用 解决方案二:使用第三方插件 houbb/sensit…...
吗)
在 Zustand 中管理状态能使用类(Class)吗
在 Zustand 中,通常不推荐使用类(Class)来管理状态,因为 Zustand 的设计理念是基于函数式编程和 React Hooks 的。然而,仍然可以在 Zustand 中间接地使用类,但这并不是 Zustand 的典型用法。 如果确实想要…...

MoreTable 方法selectWithFun,count 使用实例
ORM Bee, example for MoreTable methods:selectWithFun,count ORM Bee时, MoreTable 方法selectWithFun,count 使用实例 package org.teasoft.exam.bee.osql;import org.teasoft.bee.osql.BeeException; import org.teasoft.bee.osql.FunctionType; import org.teasoft.be…...

【SpringBoot】在Spring中使用自定义条件类在Java声明Bean时实现条件注入
在Spring框架中,通过实现org.springframework.context.annotation.Condition接口并重写matches()方法,可以根据自定义条件来控制Bean的注入。这种机制非常灵活,可以帮助开发人员根据环境或配置来有选择地启用或禁用某些Bean。本文将详细介绍如…...

网卡聚合链路配置
创建名为mybond0的绑定,使用示例如下: # nmcli con add type bond con-name mybond0 ifname mybond0 mode active-backup添加从属接口,使用示例如下: # nmcli con add type bond-slave ifname enp3s0 master mybond0要添加其他从…...
PlantSimulation导入cad图作为背景
PlantSimulation导入cad图作为背景 首先要整理cad文件,正常的工艺规划总图中存在较多杂乱文件,这些信息是不需要的,如果直接导入,会非常卡。 1、打开cad软件,使用layon命令打开所有的隐藏图层,删除不需要…...

【大模型】个人对大模型选择的见解
选择大模型产品时,需要考虑多个因素,包括但不限于以下几点: 需求匹配度:首先,要明确你的需求是什么。不同的大模型产品可能在功能、性能、应用场景等方面有所侧重。例如,有的模型擅长自然语言处理ÿ…...

java的反射和python的鸭子类型
Java的反射(Reflection)和Python的鸭子类型(Duck Typing)感觉相似但又说不出具体的细节,本文借助kimi试图给出总结。 相似之处: 动态性:Java的反射允许程序在运行时查询、创建和修改类和对象的…...
爬虫工具yt-dlp
yt-dlp是youtube-dlp的一个fork,youtube-dlp曾经也较为活跃,但后来被众多网站屏蔽,于是大家转而在其基础上开发yt-dlp。yt-dlp的github项目地址为:GitHub - yt-dlp/yt-dlp: A feature-rich command-line audio/video downloaderA …...

【代码随想录训练营】【Day 50】【动态规划-9】| Leetcode 198, 213, 337
【代码随想录训练营】【Day 50】【动态规划-9】【需二刷】| Leetcode 198, 213, 337 需强化知识点 需二刷,打家劫舍系列 题目 198. 打家劫舍 class Solution:def rob(self, nums: List[int]) -> int:if len(nums) 1:return nums[0]dp [0] * (len(nums))dp…...
)
源码讲解kafka 如何使用零拷贝技术(zero-copy)
前言 kafka 作为一个高吞吐量的分布式消息系统,广泛应用与实时应用场景中。为了实现高效的数据传输,kafka使用了零拷贝技术(zero-copy)显著提高了性能。本文将详细讲解 Kafka 如何利用零拷贝技术优化数据传输。 什么是零拷贝 零拷贝技术目的是减少数据传输的效率。在传统…...

Ubuntu20.04配置qwen0.5B记录
环境简介 Ubuntu20.04、 NVIDIA-SMI 545.29.06、 Cuda 11.4、 python3.10、 pytorch1.11.0 开始搭建 python环境设置 创建虚拟环境 conda create --name qewn python3.10预安装modelscope和transformers pip install modelscope pip install transformers安装pytorch co…...
java自学阶段二:JavaWeb开发--day80(项目实战2之苍穹外卖)
《项目案例—黑马苍穹外卖》 目录: 学习目标项目介绍前端环境搭建(前期直接导入老师的项目,后期自己敲)后端环境搭建(导入初始项目,新建仓库使用git管理项目,新建数据库,修改登录功能ÿ…...

HPUX系统Oracle RAC如何添加ASM磁盘
前言 HPUX简介 HP-UX (Hewlett-Packard Unix) 是惠普公司开发的类 Unix 操作系统。自 1980 年代问世以来,HP-UX 在技术和功能上不断发展,适应了多种硬件平台和企业计算需求。以下是 HP-UX 的发展历史概述: 1980 年代:起源与早期…...
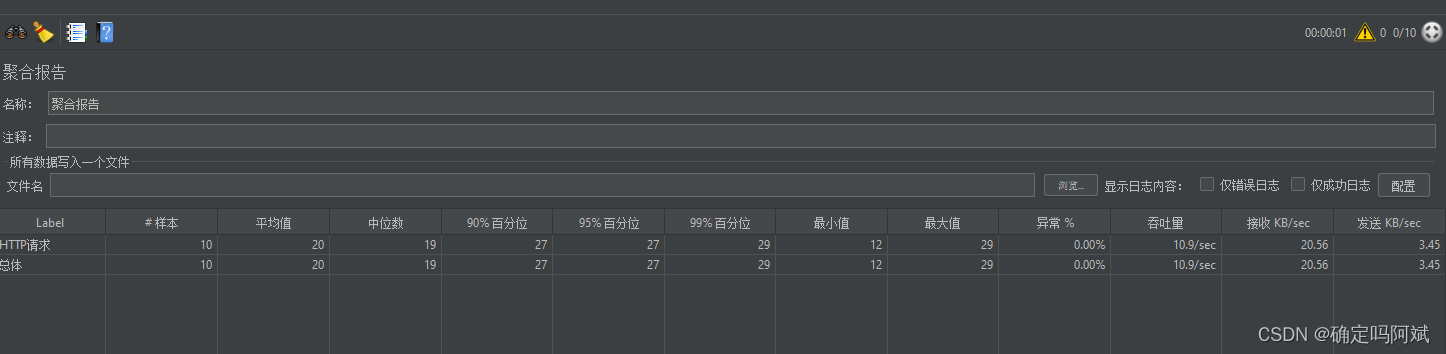
Jmeter 压力测测试的简单入门
下载安装 官方网站:Apache JMeter - Download Apache JMeter 下载完成解压即可。 配置 1. 找到 bin 目录下的 ApacheJMeter.jar 包,直接打开 如果向图片这样不能直接打开,就在此路径运行 CMD,然后输入下面的命令即可启动。 ja…...

N叉树的层序遍历-力扣
本题同样是二叉树的层序遍历的扩展,只不过二叉树每个节点的子节点只有左右节点,而N叉树的子节点是一个数组,层序遍历到一个节点时,需要将这个节点的子节点数组的每个节点都入队。 代码如下: /* // Definition for a N…...
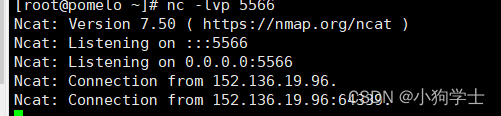
解决阿里云的端口添加安全组仍然无法扫描到
发现用线上的网站扫不到这个端口,这个端口关了,但是没有更详细信息了 我用nmap扫了一下我的这个端口,发现主机是活跃的,但是有防火墙,我们列出云服务器上面的这个防火墙list,发现确实没有5566端口 参考&a…...
【因果推断python】26_双重稳健估计1
目录 不要把所有的鸡蛋放在一个篮子里 双重稳健估计 关键思想 不要把所有的鸡蛋放在一个篮子里 我们已经学会了如何使用线性回归和倾向得分加权来估计 。但是我们应该在什么时候使用哪一个呢?在不明确的情况下,请同时使用两者!双重稳健估计…...

C语言 图形化界面方式连接MySQL【C/C++】【图形化界面组件分享】
博客主页:花果山~程序猿-CSDN博客 文章分栏:MySQL之旅_花果山~程序猿的博客-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长! 目录 一.配置开发环境 二…...
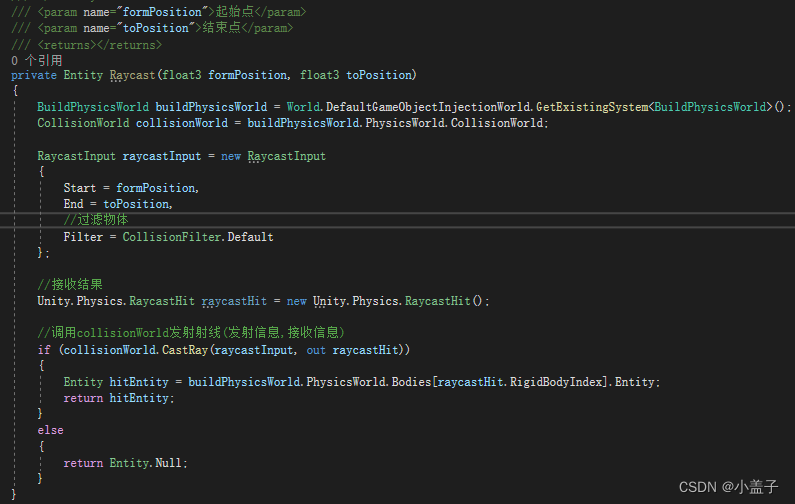
Unity DOTS技术(十五) 物理系统
要解决性能的瓶颈问题,在DOTS中我们将不再使用Unity自带的物理组件. 下面来分享一下在DOTS中当如何使用物理插件. 一.导入插件 在使用DOTS系创建的实体我们会发现,游戏物体无法受物理系统影响进行运动.于是我们需要添加物理系统插件. 1.打开Package Manager > 搜索插件Uni…...
)
BLE 协议栈(GAP,GATT;HCI,LL,PHY)
文章目录 蓝牙发展历程 蓝牙协议分层 蓝牙协议栈架构 一、主协议层(Host) 1.1 GAP(Generic Access Profile,通用访问规范) 1.2 GATT(Generic Attribute Profile,通用属性规范) 1.3 SM(Security Manager,安全管理) 1.4 ATT(Attribute Protocol,属性协议) 1.5 L2CA…...

PowerPaint-V1 Gradio Java开发实战:SpringBoot微服务集成指南
PowerPaint-V1 Gradio Java开发实战:SpringBoot微服务集成指南 1. 引言 如果你正在寻找一种将PowerPaint-V1 Gradio图像修复能力集成到Java微服务中的方法,那么你来对地方了。作为Java开发者,你可能已经注意到大多数AI模型都提供Python接口…...

论文阅读:ICLR 2026 RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Env
总目录 大模型安全研究论文整理 2026年版:https://blog.csdn.net/WhiffeYF/article/details/159047894 RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Environments https://arxiv.org/pdf/2505.21936 https://openreview…...

文脉定序保姆级教程:Mac M2/M3芯片本地部署BGE-Reranker-v2-m3
文脉定序保姆级教程:Mac M2/M3芯片本地部署BGE-Reranker-v2-m3 你是否遇到过这样的烦恼?用自己搭建的知识库或者搜索引擎提问,它确实返回了一堆结果,但最相关的答案往往不在最前面,你需要像淘金一样在一堆信息里费力筛…...

Vue3如何扩展WebUploader支持汽车设计图纸的跨平台断点续传与状态同步?
(抱着键盘在宿舍转圈圈版) 各位大佬好呀!我是福州某大学网络工程大三刚学会console.log()的编程小白秃头预备役。最近被导师按头要求搞个"能上传10G文件还带加密的文件夹传输系统",现在每天的状态be like: …...
)
MaixPy3开发环境搭建避坑指南:从驱动安装到板子连接(MAIX-ll-DOCK实测)
MaixPy3开发环境搭建避坑指南:从驱动安装到板子连接(MAIX-ll-DOCK实测) 当你第一次拿到MAIX-ll-DOCK开发板,准备开始你的嵌入式AI开发之旅时,最令人头疼的往往不是代码本身,而是环境搭建这个看似简单却暗藏…...

计算机毕业设计springboot校园智能卡管理系统设计与实现 高校一卡通数字化管理平台的设计与实现 基于Spring Boot框架的校园智慧卡服务系统开发
计算机毕业设计springboot校园智能卡管理系统设计与实现8wbp89(配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着高校信息化建设的深入推进,传统校园卡管理模式已难…...

java基于微信小程序的物流仓储管理系统 可视化
目录系统架构设计核心功能模块划分技术实现路径性能优化策略测试验证方案部署运维建议项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作系统架构设计 采用前后端分离架构,前端使用微信小程序…...

基于单片机的药品分拣系统
一、系统介绍 目前,随着当今社会老龄化进程的逐步加剧,我们在新闻中经常能看到老人跌倒了,无人扶,进而导致老人的死亡。对于这种悲剧,我们也很无奈,因为怕扶了老人,可能会被讹,老年人…...

java微信小程序的会议室预约系统的设计与实现
目录需求分析技术选型数据库设计关键功能实现微信集成测试与部署扩展优化项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析 明确系统核心功能,包括用户角色(普通用户、管…...