【因果推断python】26_双重稳健估计1
目录
不要把所有的鸡蛋放在一个篮子里
双重稳健估计
关键思想
不要把所有的鸡蛋放在一个篮子里
我们已经学会了如何使用线性回归和倾向得分加权来估计 。但是我们应该在什么时候使用哪一个呢?在不明确的情况下,请同时使用两者!双重稳健估计是一种将倾向得分和线性回归相结合的方法,您不必依赖它们中的任何一种。
为了了解这是如何工作的,让我们考虑一下心态实验。这是一项在美国公立高中进行的随机研究,旨在发现成长心态的影响。它的工作方式是学校邀请学生参加一个研讨会,向他们灌输一种成长的心态。然后,他们跟踪学生在大学期间的表现,并衡量他们在学业上的表现。这个衡量结果被编译为标准化的成就分数。为了保护学生的隐私,这项研究的真实数据没有公开。但是,我们有一个与 Athey 和 Wager 提供的统计属性相同的模拟数据集,因此我们将改为使用这个数据来进行分析。
import warnings
warnings.filterwarnings('ignore')import pandas as pd
import numpy as np
from matplotlib import style
from matplotlib import pyplot as plt
import seaborn as sns%matplotlib inlinestyle.use("fivethirtyeight")
pd.set_option("display.max_columns", 6)
data = pd.read_csv("./data/learning_mindset.csv")
data.sample(5, random_state=5)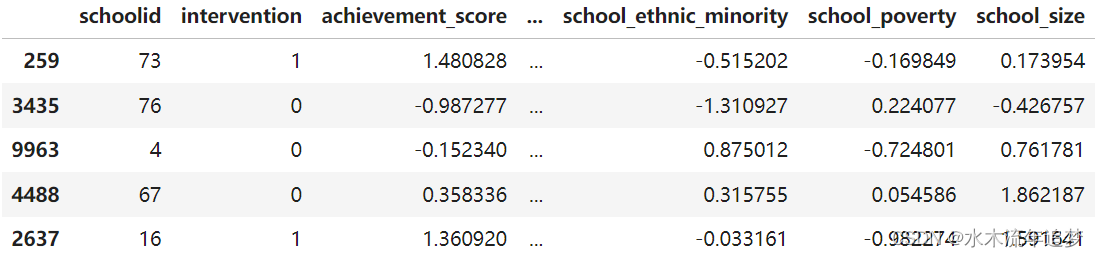 虽然这项研究做了随机化处理,但这些数据并不是没有出现混淆的情况。其中一个可能的原因是,干预变量是通过学生是否收到研讨会邀请来衡量的。因此,尽管被邀请参与的机会是随机的,但是否真的参与却不是。我们在这里处理一个不服从(non-compliance)的情况。这方面的一个证据是学生对成功的期望是如何与是否参加研讨会相关联的。自我报告中期望较高的学生更有可能参加成长心态研讨会。
虽然这项研究做了随机化处理,但这些数据并不是没有出现混淆的情况。其中一个可能的原因是,干预变量是通过学生是否收到研讨会邀请来衡量的。因此,尽管被邀请参与的机会是随机的,但是否真的参与却不是。我们在这里处理一个不服从(non-compliance)的情况。这方面的一个证据是学生对成功的期望是如何与是否参加研讨会相关联的。自我报告中期望较高的学生更有可能参加成长心态研讨会。
data.groupby("success_expect")["intervention"].mean()
正如已经学习到的,我们可以通过使用线性回归或者逻辑回归估计倾向得分模型的方法来调整不服从的情况。在做回归之前,我们需要将份类变量转化为虚拟变量。
categ = ["ethnicity", "gender", "school_urbanicity"]
cont = ["school_mindset", "school_achievement", "school_ethnic_minority", "school_poverty", "school_size"]data_with_categ = pd.concat([data.drop(columns=categ), # dataset without the categorical featurespd.get_dummies(data[categ], columns=categ, drop_first=False) # categorical features converted to dummies
], axis=1)print(data_with_categ.shape)
(10391, 32)我们现在已经准备好了解双重稳健估计的工作原理。
双重稳健估计

我不会推导出估算器,而是首先向您展示它,然后才告诉您为什么它很棒。
其中 是对倾向得分的估计(例如,使用逻辑回归),
是对倾向得分的估计
(例如使用线性回归),而
是对
。正如您可能已经猜到的那样,双重稳健估计器的第一部分估计
,第二部分估计
。让我们检查第一部分,因为所有直觉也将通过类比适用于第二部分。
因为我一开始就知道这个公式很吓人(但别担心,你会看到它超级简单),我将首先展示如何编写这个估计器。我觉得有些人对代码的恐惧不如对公式的恐惧。让我们看看这个估计器在实践中是如何工作的,好吗?
from sklearn.linear_model import LogisticRegression, LinearRegressiondef doubly_robust(df, X, T, Y):ps = LogisticRegression(C=1e6).fit(df[X], df[T]).predict_proba(df[X])[:, 1]mu0 = LinearRegression().fit(df.query(f"{T}==0")[X], df.query(f"{T}==0")[Y]).predict(df[X])mu1 = LinearRegression().fit(df.query(f"{T}==1")[X], df.query(f"{T}==1")[Y]).predict(df[X])return (np.mean(df[T]*(df[Y] - mu1)/ps + mu1) -np.mean((1-df[T])*(df[Y] - mu0)/(1-ps) + mu0))
T = 'intervention'
Y = 'achievement_score'
X = data_with_categ.columns.drop(['schoolid', T, Y])doubly_robust(data_with_categ, X, T, Y)
0.3882222817222756双重稳健估计者说,就成就而言,我们应该期望参加心态研讨会的个人比未经治疗的同伴高 0.388 个标准差。 再一次,我们可以使用 bootstrap 来构建置信区间。
from joblib import Parallel, delayed # for parallel processingnp.random.seed(88)
# run 1000 bootstrap samples
bootstrap_sample = 1000
ates = Parallel(n_jobs=4)(delayed(doubly_robust)(data_with_categ.sample(frac=1, replace=True), X, T, Y)for _ in range(bootstrap_sample))
ates = np.array(ates)
print(f"ATE 95% CI:", (np.percentile(ates, 2.5), np.percentile(ates, 97.5)))
sns.distplot(ates, kde=False)
plt.vlines(np.percentile(ates, 2.5), 0, 20, linestyles="dotted")
plt.vlines(np.percentile(ates, 97.5), 0, 20, linestyles="dotted", label="95% CI")
plt.title("ATE Bootstrap Distribution")
plt.legend();现在我们已经了解了双重稳健估计器,让我们来看看为什么它如此出色。首先,它被称为双重鲁棒,因为它只需要模型之一,或
是正确的指定的。要了解这一点,请查看估计
的第一部分并仔细查看它。
假设 是正确的。如果倾向得分模型是错误的,我们不需要担心。因为如果
是正确的,那么
。那是因为
的乘法只选择了被处理的,并且
在被处理的残差上,根据定义,均值为零。这导致整个公式等于
,这是通过假设正确估计的
。所以,你看,通过正确,
消除了倾向得分模型的相关性。我们可以应用相同的推理来理解
的估计量。
但不要相信我的话。让代码告诉你方向!在下面的估计器中,我用一个从 0.1 到 0.9 的随机统一变量替换了估计倾向得分的逻辑回归(我不希望非常小的权重破坏我的倾向得分方差)。由于这是随机的,所以它不可能是一个好的倾向得分模型,但我们将看到双重稳健估计器仍然设法产生一个非常接近于使用逻辑回归估计倾向得分时的估计值。
from sklearn.linear_model import LogisticRegression, LinearRegressiondef doubly_robust_wrong_ps(df, X, T, Y): # wrong PS model np.random.seed(654) ps = np.random.uniform(0.1, 0.9, df.shape[0]) mu0 = LinearRegression().fit(df.query(f"{T}==0")[X], df.query(f"{T}==0")[Y]).predict(df[X]) mu1 = LinearRegression().fit(df.query(f"{T}==1")[X], df.query(f"{T}==1")[Y]).predict(df[X]) return ( np.mean(df[T](df[Y] - mu1)/ps + mu1) - np.mean((1-df[T])(df[Y] - mu0)/(1-ps) + mu0) )doubly_robust_wrong_ps(data_with_categ, X, T, Y)如果我们使用自助采样法,我们可以看到,相比基于逻辑回归的倾向得分,方差会稍高一点。
np.random.seed(88)
parallel_fn = delayed(doubly_robust_wrong_ps)
wrong_ps = Parallel(n_jobs=4)(parallel_fn(data_with_categ.sample(frac=1, replace=True), X, T, Y)for _ in range(bootstrap_sample))
wrong_ps = np.array(wrong_ps)
print(f"ATE 95% CI:", (np.percentile(ates, 2.5), np.percentile(ates, 97.5)))这涵盖了倾向模型错误但结果模型正确的情况。其他情况呢?让我们再好好看看估计器的第一部分,但让我们重新排列一些术语
现在,假设正确指定了倾向得分 。在这种情况下,
,它消除了依赖于
的部分。这使得双重鲁棒估计器减少为倾向得分加权估计器
,假设是正确的。因此,即使
是错误的,只要正确指定了倾向得分,估计器仍然是正确的。
再一次,如果你更相信代码而不是公式,这里就是实际验证。在下面的代码中,我用随机正态变量替换了两个回归模型。毫无疑问 是错误的。尽管如此,我们仍将看到双重稳健估计仍设法恢复我们之前看到的大约 0.38 的相同
。
from sklearn.linear_model import LogisticRegression, LinearRegressiondef doubly_robust_wrong_model(df, X, T, Y):np.random.seed(654)ps = LogisticRegression(C=1e6).fit(df[X], df[T]).predict_proba(df[X])[:, 1]# wrong mu(x) modelmu0 = np.random.normal(0, 1, df.shape[0])mu1 = np.random.normal(0, 1, df.shape[0])return (np.mean(df[T]*(df[Y] - mu1)/ps + mu1) -np.mean((1-df[T])*(df[Y] - mu0)/(1-ps) + mu0))
doubly_robust_wrong_model(data_with_categ, X, T, Y)同样的,我们可以通过使用自助采样法看到方差还是相对高一点。
np.random.seed(88)
parallel_fn = delayed(doubly_robust_wrong_model)
wrong_mux = Parallel(n_jobs=4)(parallel_fn(data_with_categ.sample(frac=1, replace=True), X, T, Y)for _ in range(bootstrap_sample))
wrong_mux = np.array(wrong_mux)print(f"ATE 95% CI:", (np.percentile(ates, 2.5), np.percentile(ates, 97.5)))我希望我已经让你相信双重稳健估计的力量。它之所以神奇,是因为在因果推理中,有两种方法可以从我们的因果估计中消除偏见:您可以对干预机制或结果机制进行建模。如果这些模型中的任何一个都是正确的,那么您就可以开始了。
一个需要警惕的地方是,在实践中,很难对其中任何一个进行精确建模。更常见的情况是,倾向得分和结果模型都不是 100% 正确的。他们都错了,但方式不同。发生这种情况时, 是使用单一模型最好还是使用双重稳健估计更佳,目前还没有一个定论[1] [2] [3]。至于我,我仍然喜欢对两种方法都考虑一下,因为至少给了我两种正确的可能性。
关键思想
在这里,我们看到了一种将线性回归与倾向得分相结合的简单方法,以产生双重稳健的估计量。这个估计器之所以有这个名字,是因为它只需要一个模型是正确的。如果倾向得分模型是正确的,即使结果模型是错误的,我们也能够识别因果效应。另一方面,如果结果模型是正确的,即使倾向评分模型是错误的,我们也能够识别因果效应。
相关文章:
【因果推断python】26_双重稳健估计1
目录 不要把所有的鸡蛋放在一个篮子里 双重稳健估计 关键思想 不要把所有的鸡蛋放在一个篮子里 我们已经学会了如何使用线性回归和倾向得分加权来估计 。但是我们应该在什么时候使用哪一个呢?在不明确的情况下,请同时使用两者!双重稳健估计…...

C语言 图形化界面方式连接MySQL【C/C++】【图形化界面组件分享】
博客主页:花果山~程序猿-CSDN博客 文章分栏:MySQL之旅_花果山~程序猿的博客-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长! 目录 一.配置开发环境 二…...
Unity DOTS技术(十五) 物理系统
要解决性能的瓶颈问题,在DOTS中我们将不再使用Unity自带的物理组件. 下面来分享一下在DOTS中当如何使用物理插件. 一.导入插件 在使用DOTS系创建的实体我们会发现,游戏物体无法受物理系统影响进行运动.于是我们需要添加物理系统插件. 1.打开Package Manager > 搜索插件Uni…...

Java线程安全
线程安全 线程安全:线程安全:synchronized同步代码块:同步方法:成员同步方法:静态同步方法: Lock:应用: 单例模式:懒汉式:饿汉式:枚举饿汉式:双重检验锁: 线程…...

Solidity选择使用 require 语句还是条件语句结合手动触发 revert 操作?回滚交易和抛出异常如何选择?
文章目录 Solidity选择使用 require 语句还是条件语句结合手动触发 revert 操作?场景举例:回滚交易和抛出异常如何选择? Solidity选择使用 require 语句还是条件语句结合手动触发 revert 操作? IERC721 nft IERC721(nftAddress)…...

SpringCloud 网关配置websocket
一、nginx https://域名.com location /websocket/ { proxy_pass http://172.1.1.173:8181/; #内网网关IP proxy_http_version 1.1; proxy_read_timeout 360s; proxy_redirect off; proxy_set_header Upgrade $http_upgrade; …...

基于JavaScript 实现近邻算法以及优化方案
前言 近邻算法(K-Nearest Neighbors,简称 KNN)是一种简单的、广泛使用的分类和回归算法。它的基本思想是:给定一个待分类的样本,找到这个样本在特征空间中距离最近的 k 个样本,这 k 个样本的多数类别作为待…...

移动端适配和响应式页面中的常用单位
在移动端适配和响应式页面中,一般采用以下几种单位: 百分比(%):百分比单位是相对于父元素的大小计算的。它可以用于设置宽度、高度、字体大小等属性,使得元素能够随着父元素的大小自动调整。百分比单位在响…...

麒麟v10系统arm64架构openssh9.7p1的rpm包
制作openssh 说明 理论上制作的多个rpm在arm64架构(aarch64)都适用 系统信息:4.19.90-17.ky10.aarch64 GNU/Linux 升级前备份好文件/etc/ssh、/etc/pam.d等以及开启telnet 升级后确认正常后关闭telnet 在之前制作过openssh-9.5p1基础上继续…...

刚刚❗️德勤2025校招暑期实习测评笔试SHL测评题库已发(答案)
📣德勤 2024暑期实习测评已发,正在申请的小伙伴看过来哦👀 ㊙️本次暑期实习优先考虑2025年本科及以上学历的毕业生,此次只有“审计及鉴定”“税务与商务咨询”两个部门开放了岗位~ ⚠️测评注意事项: ὄ…...

python对视频进行帧处理以及裁减部分区域
视频截取帧 废话不多说直接上代码: from cv2 import VideoCapture from cv2 import imwrite# 定义保存图片函数 # image:要保存的图片名字 # addr;图片地址与相片名字的前部分 # num: 相片,名字的后缀。int 类型 def save_image(image, add…...

Python栈的编程题目
你好,我是悦创。 下面是三道关于栈的编程题目,适合不同难度级别的练习: 1. 有效的括号(简单) 题目描述: 给定一个只包括 (,),{,},[ 和 ] 的字符串…...
ROS云课三分钟外传之CoppeliaSim_Edu_V4_1_0_Ubuntu16_04
三分钟热度试一试吧,走过路过不要错过。 参考之前: 从云课五分钟到一分钟之v-rep_pro_edu_v3_6_2-CSDN博客 git clone https://gitcode.net/ZhangRelay/v-rep_pro_edu_v3_6_2_ubuntu16_04.gittar -xf v-rep_pro_edu_v3_6_2_ubuntu16_04/V-REP_PRO_EDU…...

day28回溯算法part04| 93.复原IP地址 78.子集 90.子集II
**93.复原IP地址 ** 本期本来是很有难度的,不过 大家做完 分割回文串 之后,本题就容易很多了 题目链接/文章讲解 | 视频讲解 class Solution { public:vector<string> result;// pointNum记录加入的点的数量,其等于3的时候停止void b…...

SpringBoot项目启动时“jar中没有主清单属性”异常
资料参考 Spring Boot 启动时 “jar中没有主清单属性” 异常 - spring 中文网 (springdoc.cn) 实际解决 更详细的参考以上,我这边的话只需要在 pom文件 中加上 spring-boot-maven-plugin 插件就能解决该异常,具体如下: <build><p…...

vAttention:用于在没有Paged Attention的情况下Serving LLM
文章目录 0x0. 前言(太长不看版)0x1. 摘要0x2. 介绍&背景0x3. 使用PagedAttention模型的问题0x3.1 需要重写注意力kernel0x3.2 在服务框架中增加冗余0x3.3 性能开销0x3.3.1 GPU上的运行时开销0x3.3.2 CPU上的运行时开销 0x4. 对LLM服务系统的洞察0x5…...

Python实现Stack
你好,我是悦创。 Python 中的栈结构是一种后进先出(LIFO, Last In, First Out)的数据结构,这意味着最后添加到栈中的元素将是第一个被移除的。栈通常用于解决涉及到反转、历史记录和撤销操作等问题。在 Python 中,你可…...
分布式存储)
Helm在线部署Longhorn(1.6.0版本)分布式存储
环境依赖: k8s (版本大于等于v1.21版本)、helm工具 安装前准备 k8s worker 节点都需要执行 yum -y --setopttsflagsnoscripts install iscsi-initiator-utils echo "InitiatorName$(/sbin/iscsi-iname)" > /etc/iscsi/initiatorname.iscsi systemctl …...
算法题目学习汇总
1、二叉树前中后序遍历:https://blog.csdn.net/cm15835106905/article/details/124699173 2、输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。 public class Solution {private Tr…...
DockerCompose中部署Jenkins(Docker Desktop在windows上数据卷映射)
场景 DockerJenkinsGiteeMaven项目配置jdk、maven、gitee等拉取代码并自动构建以及遇到的那些坑: DockerJenkinsGiteeMaven项目配置jdk、maven、gitee等拉取代码并自动构建以及遇到的那些坑_jenkins的安装以及集成jdkgitmaven 提示警告-CSDN博客 Windows10(家庭版…...

消费电子贴膜的光学技术革新:圆偏振光与磁控溅射AR的原理解析
摘要随着用户对屏幕使用健康关注的提升,消费电子贴膜行业正在经历从“物理防护”到“光学级视觉守护”的技术升级。本文从光学原理出发,解析圆偏振光柔光标准与磁控溅射AR抗眩镀膜两项核心技术的工作机制,并分析其在屏幕保护场景中的应用逻辑…...

ElevenLabs河南话合成效果翻车?5大本地化陷阱与97.3%可听度提升实测方案
更多请点击: https://codechina.net 第一章:ElevenLabs河南话语音合成效果翻车现象全景扫描 近期多位河南本地开发者及方言内容创作者反馈,ElevenLabs官方API在调用其“multilingual v2”模型尝试生成河南话(中原官话郑开片&…...

如何用openpilot升级你的驾驶体验:让300+车型秒变智能座驾
如何用openpilot升级你的驾驶体验:让300车型秒变智能座驾 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tren…...

股票打分制方法论
人工列提纲做评审,AI丰富内容AI模型:Deepseek仅供参考,市场有风险,投资需谨慎打分制股票算法:构建系统化、多维度的股票评估体系在股票投资领域,面对纷繁复杂的市场信息和海量数据,如何科学、客…...

2026年同步网盘哪个好?10款支持本地文件夹自动同步与实时备份工具盘点
在 2026 年,数据即资产。传统“手动上传”已难以满足高频办公:文件一多就容易漏传、版本混乱、协作效率下降。本地文件夹自动同步(落盘即上云)正在成为衡量网盘生产力的核心指标——既能防止硬盘故障导致的数据丢失,也…...

claudecode用户如何通过taotoken解决封号与token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 claudecode用户如何通过taotoken解决封号与token不足的痛点 1. 场景与核心挑战 对于深度使用 Claude Code 编程助手的开发者而言&…...

百度网盘下载加速终极指南:3步实现高速下载的完整教程
百度网盘下载加速终极指南:3步实现高速下载的完整教程 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB/s的龟速下载而烦恼吗?作为…...

如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南
如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南 【免费下载链接】OOTDiffusion [AAAI 2025] Official implementation of "OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on" 项目地址: https://…...

通过TaotokenCLI工具一键配置多开发环境提升团队协作效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置多开发环境提升团队协作效率 在团队协作开发中,一个常见的挑战是确保所有成员都能快速、…...

反向传播:从轮廓到精雕细琢
反向传播:从轮廓到精雕细琢模型知道损失值之后,怎么调整自己的参数?上一篇文章我们讲了损失函数——它像一个指南针,告诉模型"你离正确答案还有多远"。 那知道偏了之后,模型该怎么调整自己的参数?…...