微服务之负载均衡器
1、负载均衡介绍
负载均衡就是将负载(工作任务,访问请求)进行分摊到多个操作单元(服务器,组件)上 进行执行。
根据负载均衡发生位置的不同, 一般分为服务端负载均衡和客户端负载均衡。
服务端负载均衡指的是发生在服务提供者一方,例如Nginx,通过Nginx进行负载均衡,先发送请求,然后通过负载均衡算法,在多个服务 器之间选择一个进行访问;即在服务器端再进行负载均衡算法分配。
客户端负载均衡指的是发生在服务请求的一方,也就是在发送请求之前已经选好了由哪个实例处理请 求。例如spring cloud中的ribbon,客户端会有一个服务器地址列表,在发送请求前通过负载 均衡算法选择一个服务器,然后进行访问,这是客户端负载均衡;即在客户端就进行负载均 衡算法分配。
常见的负载均衡算法

自定义公共接口
package com.example.consumer.loadbalance;import org.springframework.cloud.client.ServiceInstance;import java.util.List;/*** @author* @ClassName LoadBalance* @addres www.boyatop.com*/
public interface LoadBalance {/*** 负载均衡算法 给我多个地址 负载均衡 取出一个地址返回使用*/ServiceInstance getInstances(String serviceId);
}
1)轮询算法
轮询算法实现思路:
例如在集合中 多个接口地址
[192.168.110.1:8080,192.168.110.2:8081]
0 1
第一次访问:1%2=1
第二次访问:2%2=0
第三次访问:3%2=1
第四次访问:4%2=0
[192.168.110.1:8080,192.168.110.2:8081,192.168.110.2:8082]
0 1 3
第一次访问:1%3=1
第二次访问:2%3=2
第三次访问:3%3=0
第四次访问:4%3=1
第五次访问:5%3=2第六次访问:6%3=0
package com.example.consumer.loadbalance;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.stereotype.Component;import java.util.List;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;/*** 轮询算法** @author* @ClassName RoundLoadBalance* @addres www.boyatop.com*/
@Component
public class RoundLoadBalance implements LoadBalance {@Autowiredprivate DiscoveryClient discoveryClient;//记录第几次访问private AtomicInteger atomicCount = new AtomicInteger(0);@Overridepublic ServiceInstance getInstances(String serviceId) {//1.根据服务的名称 获取 该服务集群地址列表List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);//2.判断是否nullif (instances == null || instances.size() == 0) {return null;}//3.使用负载均衡算法int index = atomicCount.incrementAndGet() % instances.size();// 0+1return instances.get(index);}
}
2)随机算法
package com.example.consumer.loadbalance;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Random;/*** 随机算法** @author* @ClassName RandomLoadBalance* @addres www.boyatop.com*/
@Component
public class RandomLoadBalance implements LoadBalance {@Autowiredprivate DiscoveryClient discoveryClient;@Overridepublic ServiceInstance getInstances(String serviceId) {//1.根据服务的名称 获取 该服务集群地址列表List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);//2.判断是否nullif (instances == null || instances.size() == 0) {return null;}// 生成随机 范围Random random = new Random();//3 0 1 2int index = random.nextInt(instances.size());return instances.get(index);}
}
3)故障转移算法
@RequestMapping("/orderToMember3")public String orderToMember3() {/***模拟其中的服务器宕机*/
// ServiceInstance serviceInstance = randomLoadBalance.getInstances("producer");List<ServiceInstance> instances = discoveryClient.getInstances("producer");//ServiceInstance serviceInstance = instances.get(0);for (int i = 0; i <instances.size(); i++) {ServiceInstance serviceInstance = instances.get(i);// 会员服务的ip和端口String memberUrl = "http://" + serviceInstance.getHost() + ":" + serviceInstance.getPort() + "/" + "getMember";//调用的过程当中可能会出现服务宕机的情况 此刻应该实现故障转移机制try {//将获取请求服务的结果换成获取服务访问成功的对象 目的:验证服务是否宕机ResponseEntity<String> response = restTemplate.getForEntity(memberUrl, String.class);if (response == null) {continue;}return "订单服务调用会员服务:" + response.getBody();}catch (Exception e){log.error("<e:{}>", e);}}return "fail";}4)权重算法
[192.168.110.1:8080,192.168.110.1:8081]
Index=0=192.168.110.1:8080
Index=1=192.168.110.1:8081
权重算法如何 比例:
1:1
第一次访问 192.168.110.1:8080
第二次访问 192.168.110.1:8081
轮询机制 默认权重1:1
2:1
[192.168.110.1:8080,192.168.110.1:8081]
权重比例 2:1
Index=0 192.168.110.1:8080 权重=2
Index=1 192.168.110.1:8081 权重=1
2(index=0):1(index=1)
第一次访问 192.168.110.1:8080
第二次访问 192.168.110.1:8080
第三次访问 192.168.110.1:8081
第四次访问 192.168.110.1:8080
第五次访问 192.168.110.1:8080
第六次访问 192.168.110.1:8081
Index=0 192.168.110.1:8080 权重=2
Index=1 192.168.110.1:8081 权重=1
2(index=0):1(index=1)
权重的底层实现逻辑
【192.168.110.1:8080,192.168.110.1:8080
192.168.110.1:8081】
第一次访问1%3=1 ===192.168.110.1:8080
第二次访问2%3=2 ===192.168.110.1:8081
第三次访问3%3=0 ===192.168.110.1:8080
第四次访问4%3=1 ===192.168.110.1:8080
第五次访问5%3=2 ===192.168.110.1:8081
第六次访问6%3=0 ===192.168.110.1:8080
第七次访问7%3=1 ===192.168.110.1:8080
第八次访问8%3=1 ===192.168.110.1:8081
package com.example.consumer.loadbalance;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.stereotype.Component;import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;/*** @author* @ClassName WeightLoadBalance* @addres www.boyatop.com*/
@Component
public class WeightLoadBalance implements LoadBalance {@Autowiredprivate DiscoveryClient discoveryClient;private AtomicInteger countAtomicInteger = new AtomicInteger(0);@Overridepublic ServiceInstance getInstances(String serviceId) {// 1.根据服务的id名称 获取该接口多个实例List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);if (instances == null) {return null;}/*** 192.168.75.1:8080 权重比例 2* 192.168.75.1:8081 权重比例 1* [192.168.75.1:8080,192.168.75.1:8080,192.168.75.1:8081]*/ArrayList<ServiceInstance> newInstances = new ArrayList<>();// 循环遍历该服务名称 对应的多个实例instances.forEach((service) -> {// 获取该服务实例对应的权重比例Double weight = Double.parseDouble(service.getMetadata().get("nacos.weight"));for (int i = 0; i < weight; i++) {newInstances.add(service);}});// 线程安全性 i++return newInstances.get(countAtomicInteger.incrementAndGet() % newInstances.size());}
}
@Autowired
private WeightLoadBalance weightLoadBalance;
@RequestMapping("/orderToMember4")
public String orderToMember4() {/***使用权重的方式*///1.根据服务的名称 获取 该服务集群地址列表//List<ServiceInstance> instances = discoveryClient.getInstances("producer");// 如何服务实例的获取权重比例呢?ServiceInstance serviceInstance = weightLoadBalance.getInstances("producer");// 会员服务的ip和端口String memberUrl = "http://" + serviceInstance.getHost() + ":" + serviceInstance.getPort() + "/" + "getMember";return "订单服务调用会员服务:" + restTemplate.getForObject(memberUrl, String.class);
}2、Ribbon(第一代)
1)Ribbon负载均衡介绍及实现
Spring Cloud Ribbon是基于Netflix Ribbon 实现的一套客户端的负载均衡工具,Ribbon 客户端组件提供一系列的完善的配置,如超时,重试等。通过Load Balancer获取到服务提 供的所有机器实例,Ribbon会自动基于某种规则(轮询,随机)去调用这些服务。Ribbon也可以实现我们自己的负载均衡算法
RestTemplate 添加@LoadBalanced注解
让RestTemplate在请求时拥有客户端负载均衡的能力
@Configuration
public class RestConfig {@Bean@LoadBalanced //开启负载均衡public RestTemplate restTemplate() {return new RestTemplate();}
}
调用实现
//springcloud中Ribbon负载均衡的使用@Autowiredprivate LoadBalancerClient loadBalancerClient;@RequestMapping("/orderToMember6")public String orderToMember6() {ServiceInstance serviceInstance = loadBalancerClient.choose("producer");//默认采用轮询机制String memberUrl = "http://" + serviceInstance.getHost() + ":" + serviceInstance.getPort() + "/" + "getMember";return "订单服务调用会员服务:" + restTemplate.getForObject(memberUrl, String.class);
// return "订单服务调用会员服务:" + restTemplate.getForObject("http://producer/getMember", String.class);}2)Ribbon底层实现原理
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求
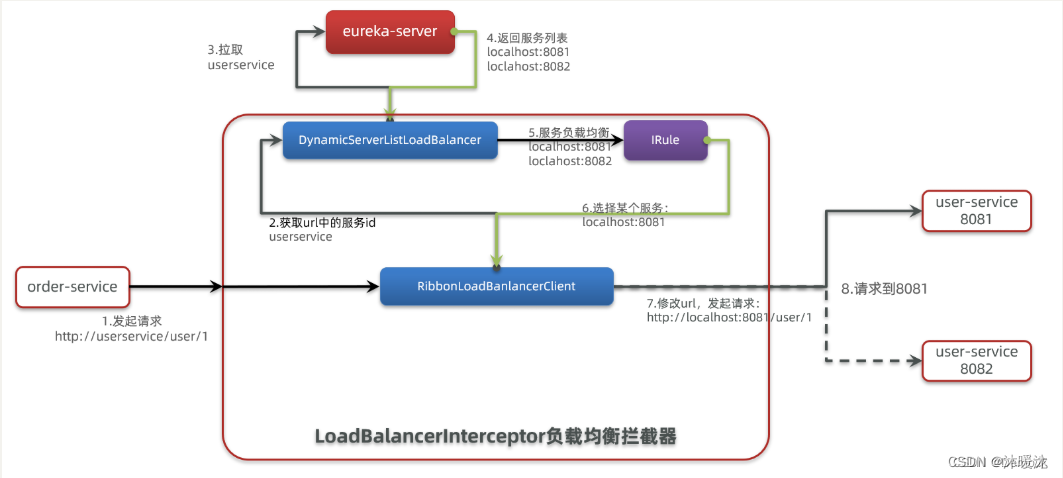
基本流程如下:
拦截我们的RestTemplate请求http://userservice/user/1
RibbonLoadBalancerClient会从请求url中获取服务名称,也就是user-service
DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
eureka返回列表,localhost:8081、localhost:8082
IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,发起真实请求
3)Ribbon负载均衡策略
Ribbon内置了七种负载均衡规则,每种规则都有其特定的应用场景和策略。以下是这些规则的详细介绍:
RoundRobinRule(轮询策略)
-
- 策略描述:这是Ribbon的默认负载均衡策略。通过简单的轮询服务列表来选择服务器。在没有可用服务的情况下,RoundRobinRule最多会轮询10轮,若最终没有找到可访问的服务,则返回NULL。
- 特点:每个服务器依次被调用,确保每个服务器都能得到相等的负载。
- 实现说明:轮询index,选择index对应位置的server
AvailabilityFilteringRule(可用性筛选策略)
-
- 策略描述:先过滤掉非健康的服务实例,比如连接失败的服务,以及并发数过高的服务,然后再从剩余的服务中选择连接数较小的服务实例。
- 特点:忽略无法连接的服务器,以及并发数过高的服务器,确保选择的服务都是可用的且负载较低的。
- 参数配置:
- 可以通过niws.loadbalancer..connectionFailureCountThreshold属性配置连接失败的次数。
- 可以通过.ribbon.ActiveConnectionsLimit属性设定最高并发数。
- 实现说明:使用一个AvailabilityPredicate来包含过滤server的逻辑,其实就就是检查status里记录的各个server的 运行状态
WeightedResponseTimeRule(权重策略)
-
- 策略描述:为每个服务器赋予一个权重值,服务器的响应时间越长,该权重值就越少。这个规则会随机选择服务器,但权重值会影响服务器的选择。
- 特点:响应快的服务器权重更高,被选中的概率也更大。
- 实现说明:一个后台线程定期的从status里面 读取评价响应时间,为每个server 计算一weight。Weight的计算也 比较简单responsetime减去每个server自己平均的responsetime是 server的权重。当刚开始运行,没 有形成statas时,使用roubine策略 选择server
ZoneAvoidanceRule(区域回避策略)
-
- 策略描述:根据服务所在区域(zone)的性能和服务的可用性来选择服务实例。如果在一个区域内有多台服务实例,并且区域内服务可用,那么只会在区域内进行选择;如果区域内服务不可用,才会选择其他区域的服务。
- 特点:优先选择同区域的服务实例,以提高访问速度和可用性。
- 实现说明:使用ZoneAvoidancePredicate和AvailabilityPredicate来判断是否选 择某个server,前一个判断判定一个zone的运行性能是否可用,剔除不可用的zone(的所有server), Availability Predicate用于过滤掉连 接数过多的Server。
BestAvailableRule(最佳可用策略)
-
- 策略描述:忽略那些处于“短路”状态的服务器,并选择并发数较低的服务器。
- 特点:确保选择的服务都是可用的,并且并发数较低,以提供最佳的服务性能。
- 实现说明:逐个考察Server,如果Server被tripped了,则忽略,在选择其中ActiveRequestsCount最小的server
RandomRule(随机策略)
-
- 策略描述:随机选择一个可用的服务器。
- 特点:随机性较强,适用于对服务器性能要求不高的场景。
- 实现说明:在index上随机,选择index对应位 置的server
RetryRule(重试策略)
-
- 策略描述:在一个配置的时间段内,如果选择的服务器不可用,则一直尝试选择一个可用的服务器。
- 特点:具有重试机制,确保在服务器不可用时能够继续提供服务。
- 实现说明:在一个配置时间段内当选择server 不成功,则一直尝试使用subRule 的方式选择一个可用的server
4)自定义负载均衡策略
通过定义IRule实现可以修改负载均衡规则,有两种方式:
① 代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
@Bean
public IRule randomRule(){return new RandomRule();
}
② 配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务ribbon:NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
5)饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:eager-load:enabled: trueclients: userservice3、Loadbalancer(第二代)
Spring Cloud LoadBalancer是由SpringCloud官方提供的一个开源的、简单易用的客户端负载均衡器,它包含在SpringCloud-commons中用它来替换了以前的Ribbon组件。相比较于Ribbon,SpringCloud LoadBalancer不仅能够支持RestTemplate,还支持WebClient(WeClient是Spring Web Flux中提供的功能,可以实现响应式异步请求)
导入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>Loadbalancer提供的的负载均衡策略
- RandomLoadBalancer - 随机策略
- RoundRobinLoadBalancer - 轮询策略(默认)
算法切换
@Configuration // 标记为配置类
@LoadBalancerClient(value = "producer", configuration = RestTemplateConfig.class) // 使用负载均衡器客户端注解,指定服务名称和配置类
public class RestTemplateConfig {@Bean // 定义一个Bean@LoadBalanced // 使用@LoadBalanced注解赋予RestTemplate负载均衡的能力public RestTemplate restTemplate() {return new RestTemplate(); // 返回一个新的RestTemplate实例}@Bean // 定义一个BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, // 注入环境变量LoadBalancerClientFactory loadBalancerClientFactory) { // 注入负载均衡器客户端工厂String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME); // 获取负载均衡器的名称// 创建并返回一个随机负载均衡器实例return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);}
}4、Ribbon和Loadbalancer的比较
Ribbon
1. 定义和用途
- Ribbon是一个客户端负载均衡器,它是一个Java库,可以在客户端应用程序中使用。
- 通过在客户端应用程序中维护服务实例列表,并使用负载均衡算法来选择要请求的服务实例,从而实现负载均衡。
2. 特点和优势
- 适用于客户端负载均衡,将负载均衡逻辑集成到消费方进程中。
- 消费者通过Ribbon来获取到服务提供方的地址。
- Ribbon提供了多种负载均衡算法,如轮询、随机、加权轮询等。
- 它还可以进行故障检查,检测服务器的健康状态,并自动从故障服务器中移除。
3. 与微服务的关系
- 在微服务架构中,Ribbon常被用于Spring Cloud等Java微服务框架中,以提供客户端负载均衡和高可用支持。
LoadBalancer
1. 定义和用途
- LoadBalancer是一个服务器端负载均衡器,它是一个独立的服务,可以在服务器集群中运行。
- 通过接收客户端请求,并使用负载均衡算法来选择要处理请求的服务器实例,从而实现负载均衡。
2. 特点和优势
- 适用于服务器端负载均衡,如常见的负载均衡工具有nginx、LVS,硬件上F5等集中式负载均衡设施。
- 能够处理大量的并发请求,并根据服务器的负载情况动态分配请求。
- 可以实现故障处理、实例健康检查、SSL转换、跨区域负载均衡等高级功能。
3. 与微服务的关系
- 在微服务架构中,LoadBalancer通常被部署在服务提供者之前,作为客户端和服务提供者之间的代理。
- 它可以根据配置的策略将请求分发到不同的服务实例上,从而确保服务的高可用性和可扩展性。
总结
- Ribbon和LoadBalancer在微服务架构中都扮演着重要的角色,但它们的应用场景和实现方式有所不同。
- Ribbon更侧重于客户端负载均衡,通过在客户端应用程序中集成负载均衡逻辑来实现;而LoadBalancer则更侧重于服务器端负载均衡,作为一个独立的服务来处理客户端请求。
5、loadbalancer本地负载均衡客户端 VS Nginx服务端负载均衡区别
Nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求,即负载均衡是由服务端实现的。
loadbalancer本地负载均衡,在调用微服务接口时候,会在注册中心上获取注册信息服务列表之后缓存到JVM本地,从而在本地实现RPC远程服务调用技术。
应用场景的:
Nginx属于服务器负载均衡,应用于Tomcat/Jetty服务器等,而我们的本地负载均衡器,应用于在微服务架构中rpc框架中:openfeign、dubbo等。
相关文章:
微服务之负载均衡器
1、负载均衡介绍 负载均衡就是将负载(工作任务,访问请求)进行分摊到多个操作单元(服务器,组件)上 进行执行。 根据负载均衡发生位置的不同, 一般分为服务端负载均衡和客户端负载均衡。 服务端负载均衡指的是发生在服务提供者一方ÿ…...

《时间管理九段》前四阶段学习笔记
文章目录 0.何谓时间管理九段0.1 第一段--把一件事做好0.2 第二段--把一天过好0.3 第三段--掌控两周内的固定日程0.4 第四段--掌控两周内的弹性时间0.5 第五段--科学管理3个月的项目事件0.6 第六段--实现一年的梦想0.7 第七段--明确一生的愿景0.8 第八段--正确补充和释放自身能…...
LLVM Cpu0 新后端5 静态重定位 动态重定位
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章: LLVM 后端实践笔记 代码在这里(还没来得及准备,先用网盘暂存一下): 链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?…...

旅游卡是项目还是骗局?还是实实在在的旅游项目?
旅游卡是一个实实在在的旅游项目,而非骗局。以下是我对旅游卡项目的几点分析: 项目实质: 旅游卡项目是由国内外多条旅游线路整合而成的卡片,为旅游者提供方便、实惠的旅游方式。持有旅游卡,可以完全抵销跟团游线路中的…...

大模型+RAG,全面介绍!
1 、介绍 大型语言模型(LLMs)在处理特定领域或高度专业化的查询时存在局限性,如生成不正确信息或“幻觉”。缓解这些限制的一种有前途的方法是检索增强生成(RAG),RAG就像是一个外挂,将外部数据…...

智能合约中存储和计算效率漏洞
存储和计算效率 不当的存储结构或计算密集型操作可能导致高Gas费用和性能瓶颈。示例场景:频繁读取和写入大数组 假设你正在构建一个投票系统,其中每个提案都有一个独立的计票器。为了实现这一点,你可能最初会考虑使用一个映射(m…...

软件测试基础知识总结
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、软件测试概述 1、什么是软件 定义:计算机系统中与硬件相互依存的一部分&#x…...
C语言 | Leetcode C语言题解之第143题重排链表
题目: 题解: struct ListNode* middleNode(struct ListNode* head) {struct ListNode* slow head;struct ListNode* fast head;while (fast->next ! NULL && fast->next->next ! NULL) {slow slow->next;fast fast->next-&g…...
探寻性能优化:如何衡量?如何决策?
目录 一、衡量指标说明 (一)响应时间(Response Time) 平均响应时间(Average Response Time) 百分位数响应时间(Percentile Response Time) (二)吞吐量&a…...

Python Django 5 Web应用开发实战
Django 是一个高级 Python Web 框架,它鼓励快速开发和简洁、务实的设计。下面是一个关于如何使用 Django 开发一个包含五个基本页面的 Web 应用的实战指南。请注意,这里仅提供一个概述,实际开发中会有更多细节和步骤。 1. 安装 Django 首先,你需要安装 Django。你可以使用…...

H.264官方文档下载
H.264是ITU(International Telecommunication Union,国际通信联盟)和MPEG(Motion Picture Experts Group,运动图像专家组)联合制定的视频编码标准。其官方文档可以在ITU官网上下载:https://www.…...

minio多节点部署
MinIO 是一个高性能的分布式对象存储服务,它可以配置为多节点(或多服务器)模式以提供高可用性和数据冗余。以下是一个基本的多节点MinIO部署示例: 确保你有多个服务器或虚拟机。在每个节点上安装MinIO。使用minio server命令启动多…...

2024年工业设计与制造工程国际会议(ICIDME 2024)
2024年工业设计与制造工程国际会议 2024 International Conference on Industrial Design and Manufacturing Engineering 会议简介 2024年工业设计与制造工程国际会议是一个集结全球工业设计与制造工程领域精英的盛会。本次会议旨在为业界专家、学者、工程技术人员提供一个分享…...
一次曝 9 个大模型,「字节 AI」这一年都在做什么?
字节跳动的大模型家族,会长出下一个抖音吗? 整个 2023 年,字节并没有对外官宣其内部自研的大模型。外界一度认为,大模型这一技术变革,字节入场晚了。梁汝波在去年底的年会上也提到了这一点,他表示「字节对…...

PR基本概念数学知识
1、2基本概念 监督学习与非监督学习期望风险与经验风险结构风险最小化(SRM)与经验风险最小化(ERM)期望风险的上界过拟合数据预处理模型评价方法分类与聚类 数学知识 矩阵求逆、矩阵乘法协方差矩阵的计算特征值、特征向量的计算…...

信驰达蓝牙数字钥匙方案持续创新,助推智慧汽车生态发展
随着汽车智能化的加速发展,数字钥匙正成为全球化的新趋势,它通过数字化的手段连接人、车以及更广泛的生态,引领着出行方式的革命和用户体验的转变。数字钥匙不仅仅是一个简单的访问工具,它重新定义了人与车的互动方式,…...
校园生活服务平台的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,用户管理,跑腿管理,文娱活动管理,活动申请管理,备忘录管理 前台账户功能包括:系统首页,个人中心ÿ…...
gerrit 使用
添加ssh 点击 蓝色方框 复制ssh 添加即可...
【GD32F303红枫派使用手册】第十二节 ADC-双轴按键摇杆多通道循环采样实验
12.1 实验内容 本实验是通过ADC规则组多通道循环采样方式实现双轴按键摇杆传感器x和y轴电压值的读取,通过本实验主要学习以下内容: 双轴按键摇杆传感器工作原理 DMA原理 规则组多通道循环采样 12.2 实验原理 12.2.1 双轴按键摇杆传感器工作原理 摇…...

Rust-03-数据类型
在 Rust 中,每一个值都属于某一个 数据类型,这告诉 Rust 它被指定为何种数据,以便明确数据处理方式。Rust 是 静态类型语言,也就是说在编译时就必须知道所有变量的类型。根据值及其使用方式,编译器通常可以推断出我们想…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...