Exploring Performance and Cost Optimization with ASIC-Based CXL Memory——论文阅读
EuroSys 2024 Paper CXL论文阅读笔记整理
问题
随着内存密集型应用程序对内存需求的增加,受限于物理限制,如DDR DIMM插槽的可用性和发热问题,以及使用高密度DIMM的成本考虑,现代应用程序的内存需求很容易超过单机的内存容量[2,3]。
计算高速链路(CXL)已成为一种很有前途的互连技术,可实现主机处理器和各种外围设备之间的无缝高速、低延迟通信,通过将外部存储器设备(例如DRAM、闪存或持久存储器)连接到PCIe插槽来显著扩展存储器容量和带宽。CXL在商业上首次推出版本1.1,主要用作内存扩展。例如,AsteraLabs的A1000[7]CXL内存扩展卡最多支持4xDDR5 RDIMM,为单个服务器提供最多2 TB的额外内存。
现有方法据局限性
-
当前的许多文献使用模拟[6,8]或使用基于FPGA的设置[11,12]来评估CXL硬件,而对基于ASIC的CXL硬件的原始性能的研究数量有限[11,13],在理解不同的系统配置如何影响使用CXL内存的应用程序方面仍然存在差距。此外,可以从CXL内存扩展中获得实质性好处的特定应用程序尚未完全确定。
-
虽然现有的研究已经开始探索使用CXL技术的成本影响,例如[14]中提出的内存池成本模型,但在理解将特定类型的应用程序或服务迁移到CXL促进的内存扩展的成本效益方面仍然存在重大差距。
-
鉴于CXL ASIC硬件的可用性有限,研究界面临着开源经验数据的显著短缺。阻碍了充分理解这种硬件的性能或基于经验证据开发性能模型。
本文工作
本文对内存密集型应用程序的CXL 1.1进行详细评估来,探讨了ASIC CXL存储器在各种数据中心场景中的应用性能。
通过精心设计的政策和策略,进一步探讨使用CXL内存的多种潜在影响(例如吞吐量、延迟和成本降低)。
结果显示了CXL内存的高潜力,揭示了CXL存储器的多个观察结果,有助于CXL内存在现实部署环境中的广泛采用。发现:普遍认为CXL内存由于其较高的延迟而应被视为一个单独的、较慢的内存层[8,9],但本文发现,即使本地内存的容量和带宽没有得到充分利用,将一些工作负载转移到CXL内存也可以显著提高性能。因为使用CXL内存可以减少DDR通道上的带宽争用来降低总体内存访问延迟,从而提高应用程序性能。
根据本文对应用程序性能的分析,制定了一个抽象的成本模型,该模型可以估计使用CXL内存的成本效益。
开源数据:GitHub - bytedance/eurosys24-artifacts: Artifacts of EuroSys'24 paper "Exploring Performance and Cost Optimization with ASIC-Based CXL Memory"
硬件支持
由于CXL硬件的稀缺性,对CXL的研究在很大程度上依赖于基于NUMA的仿真[8,9]和FPGA实现[11,12],但每种实现都有固有的局限性:
-
基于NUMA的仿真。考虑到CXL和UPI/xGMI互连的缓存一致性和可比较的传输速度,基于NUMA的仿真以实现快速的应用程序性能分析和软件原型设计。然而,由于与CXL和UPI/xGMI互连[22]的差异,基于NUMA的仿真无法准确捕捉CXL内存的性能特征。
-
基于FPGA的实现。与ASIC相比,基于FPGA的CXL存储器的工作频率较低,无法充分利用存储器芯片的性能[24]。FPGA将灵活性置于性能之上,适用于早期CXL内存验证,但不适用于生产部署。FPGA实现中有性能问题,包括并发线程执行期间内存带宽减少。阻碍了对内存容量和带宽限制应用程序的严格评估,而这些应用程序是CXL内存扩展器的关键用例。
软件支持
-
N:M分层内存节点的交错策略。传统的内存交错策略通常使用1:1的比例在内存组之间均匀地分配数据,对于分层内存系统,无CPU内存节点具有不同的性能特征,需要更细致的策略来优化内存带宽。因此提出N:M交错策略,其中N个页面指向高性能(顶层)节点,M个页面指向较低层节点。需要注意的是,最佳内存分布取决于特定的硬件和应用程序特性。考虑到CXL内存的延迟更高,对性能敏感的应用程序应进行彻底的分析和基准测试,以最大限度地发挥交织的优势。
-
NUMA平衡和热页选择。对于内存分层系统,可容纳各种内存类型,如PMEM和CXL内存。为了优化系统性能,热页应位于DRAM等更快的内存层中,而冷页则应位于CXL内存等较慢的层中。
-
NUMA平衡[26],使用延迟感知页面迁移策略,重点是提升最近访问的页面(MRU)。它扫描NUMA平衡页表并提示页面错误,但由于扫描间隔延长,可能无法准确识别高需求页面,会导致某些工作负载出现延迟问题。
-
热页选择[27],引入了页面提升速率限制(RPRL)机制来控制页面提升和降级的速率。虽然延长了提升/降级时间,但降低了工作负载延迟。热页阈值会动态调整,以与提升速率限制保持一致。
-
实验环境
如图2(b)所示,实验台由三个服务器组成。
两个服务器为CXL服务器,每台都配备了双Intel Xeon第四代CPU(Sapphire Rapids或SPR)、1 TB 4800 MHz DDR5内存、两个1.92 TB SSD和一对AsteraLabs的A1000 CXL Gen5 x16 ASIC内存扩展模块,每个模块具有256 GB 4800MHz内存(每个服务器总共有512 GB内存),两个A1000内存模块均连接到插槽0。
第三台服务器用作基线,其配置与CXL实验服务器相同,只是缺少CXL内存扩展器。用于启动客户端请求和运行在应用程序评估期间严格利用主内存的工作负载。所有服务器都通过100 Gbps以太网链路互连。

CXL 1.1性能特征
基本延迟和带宽特性
本节概述了对不同内存配置的内存访问延迟和带宽的研究结果:本地套接字主存(MMEM)、远程套接字主存(MMAM-r)、CXL内存(CXL)和远程套接字CXL内存(CXL-r)。

图3(a)显示了MMEM在不同读写混合下的延迟曲线。
-
只读工作负载的峰值带宽约为67 GB/s,达到其理论最大值的87%。随着写入操作的增加,带宽下降,仅写入任务降至54.6 GB/s。
-
初始内存延迟约为97 ns,随着带宽接近满容量,峰值呈指数级增长,这是带宽竞争的迹象[30,31]。
-
延迟在带宽利用率的75%-83%时开始显著增加,超过了早期研究中先前估计的60%[30]。
图3(b)说明了通过远程套接字访问MMEM时的延迟。
-
对于只读任务,延迟从大约130 ns开始,而仅写操作为71.77 ns,这种减少了只写工作负载延迟源于非临时写入,这种写入可以异步进行,而无需等待确认。
-
只读任务实现了与本地MMEM相当的最大带宽,但由于缓存一致性协议需要额外的UPI流量,合并更多的写操作会显著减少带宽。只写工作负载产生的UPI流量最小,但带宽最低,因为它只使用UPI双向功能的一个方向。
-
延迟升级在远程套接字内存访问中发生得比在本地套接字内存访问更早,这主要是由于内存控制器处的队列争用。
图3(c)显示了CXL内存扩展的延迟曲线。
-
最小延迟为250.42 ns。
-
尽管数据路径上有额外的PCIe和CXL内存控制器开销,但访问CXL遵循与MMEM相同的带宽争用趋势。随着带宽的增加,在同一套接字上访问CXL的延迟保持相对稳定,当工作负载为2:1读写比时,最大带宽约为56.7 GB/s。
-
与DRAM相比,最大带宽的减少归因于PCIe开销,例如额外的头。由于PCIe双向性,只读工作负载的最大带宽较小,无法充分利用带宽。
图3(d)显示了远程套接字访问CXL的延迟曲线。
-
最小延迟为485 ns。
-
最大内存带宽减半,在2:1的读写比下仅达到20.4 GB/s,与远程NUMA节点访问MMEM相比,这是一个更严重的性能下降。
-
由于在远程套接字上对CXL Type-3设备运行只读不会产生大量的一致性流量,因此排除了关于缓存一致性的猜测。利用英特尔性能计数器监视器[32]进行的调查还证实,UPI利用率始终低于30%。这种性能瓶颈可能是由于当前CPU平台上的远程监听滤波器(RSF)的限制,预计将在下一代处理器中解决[33]。
不同的读写比率和访问模式
图4(a-f)显示了不同读写比的特定工作负载的顺序访问性能比较【跟图3是一样的,换个画法】。
-
从远程套接字访问CXL会带来异常高的延迟和低带宽。
-
从同一个套接字访问CXL时,延迟是本地DDR的2.4-2.6倍,是远程套接字DDR的1.5-1.92倍。这表明直接在CXL上运行应用程序可能会显著降低性能。当工作负载跨越同一套接字中的多个NUMA节点时,本地访问CXL与访问远程NUMA节点内存相当。
-
随着写操作在工作负载中所占比例的增加,延迟带宽拐点向左移动。
图4(g、h)显示了使用随机访问模式运行只读和仅写工作负载的结果。在这些条件下,没有观察到显著的性能差异。

关键发现
-
避免远程套接字CXL访问【但这应该是硬件设计的缺陷,不应该是通用的结论】。有了对CXL 1.1协议的充分支持,预计跨套接字访问CXL内存时可获得的最大带宽,接近跨套接字访问MMEM时的带宽。
-
带宽争用。虽然延迟在中低带宽利用率下保持相对稳定,但随着带宽接近更高水平,延迟呈指数级增加,这主要是由于内存控制器中的排队延迟[30]。此外,当工作负载中有更高比例的写操作时,延迟的拐点会转移到更低的内存带宽。因此,分配器和内核级页面放置策略应考虑MMEM中的可用带宽。即使MMEM中很大一部分内存带宽未使用,例如30%,将一部分工作负载(例如20%)卸载到CXL内存也可以提高整体性能。
-
与基于FPGA的CXL实现的比较。英特尔公布了其基于FPGA的CXL原型的延迟和带宽性能指标[11],虽然提供了对软IP和硬IP实现的相对延迟和带宽效率的深入了解,但负载下的性能并没有共享。本文测量结果表明,与MMEM相比,ASIC CXL的访问延迟开销为2.5倍,超过了英特尔的大多数测量结果。由于内存控制器的低效率,基于FPGA的解决方案仅实现了60%的PCIe带宽,而Asteralabs A1000原型的带宽效率达到了73.6%,明显优于基于FPGA的方案。
内存容量受限的应用程序
将CXL内存集成到现代计算系统中最显著的优势之一是有机会获得更大的内存容量。本文重点关注三个特定的用例:(1)键值存储;(2)大数据分析应用;(3)云提供商提供的弹性计算。
内存键值存储
方法和软件配置
研究了在KeyDB服务器上最大化内存利用率的性能影响。在配置了七个服务器线程的支持CXL的服务器上部署了一个KeyDB实例。禁用SNC和Transparent Hugepages,并在内核中启用内存过度使用,以最大限度地减少操作系统配置的潜在开销。对于KeyDB FLASH,取消RocksDB中所有形式的压缩,以最大限度地减少软件开销。
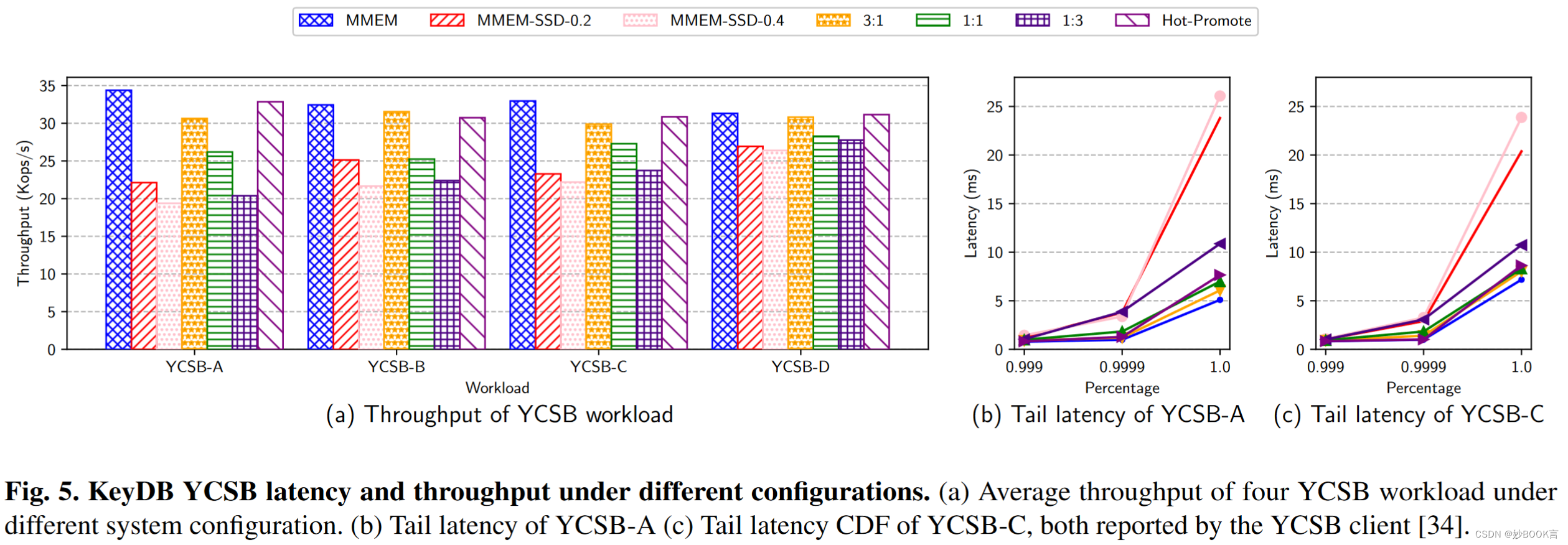
使用四种不同工作负载的YCSB基准:(1)YCSB-A(50%读取,50%更新)用于更新密集型场景;(2) YCSB-B(95%读取,5%更新),用于重读取操作;(3) YCSB-C(100%读取),用于只读任务;(4)YCSB-D(95%读取,5%插入)模拟读取最新数据。实验使用1 KB的键值大小(YCSB默认值),工作负载A-C采用Zipfian分布,工作负载D采用最新分布,工作集数据总量为512 GB。系统配置如表1所示。

结果分析
-
在各种情况下,在MMEM上运行整个工作负载都能产生最高的吞吐量,因为工作负载的性质,主要受内存容量而非内存带宽的限制。
-
热升级配置利用Zipfian分发将频繁访问的密钥标识为热页,并将它们从CXL迁移到MMEM,其性能几乎与完全在MMEM上运行接近。
-
CXL和MMEM之间的交错数据访问会导致显著的性能下降,与直接在MMEM中运行工作负载相比,速度会降低1.2到1.5倍。性能下降主要由于较高的访问延迟,如工作负载A和工作负载C的尾部延迟图所示,图5(b、C)。
-
MMEM-SSD-0.2和MMEMSSD-0.4的性能最差,与纯MMEM相比,速度减慢了近1.8倍,与CXL交织解决方案相比速度减慢了1.55倍。这种较差的性能主要归因于从SSD检索数据所需的高访问延迟。
结论
CXL提供的额外内存容量可以改善受MMEM容量限制的键值存储等应用程序。智能调度策略进一步突出了优势,为优化利用多种内存类型的系统提供了途径,同时节省了操作成本。
Spark SQL
大部分结果近似。
区别:尽管热升级补丁在键值存储工作负载方面表现出显著优势,但其性能在Spark中明显不足。由于数据局部性差热页升级效果有限。
虚拟机备用核心
结果近似。
内存带宽受限的应用程序
CXL内存扩展的另一个优点是其额外的内存带宽。以大型语言模型(LLM)推理为例,同时对内存容量和带宽有较高需求,测试基于CPU的LLM推理任务。
方法和软件配置
使用SNC-4配置将单个CPU划分为四个子NUMA节点,每个节点都配备了两个DDR5-4800内存通道,有助于67 GB/s的内存带宽饱和。测试三种不同的交织策略(3:1、1:1、1:3),如表1。CPU推理后端配置有12个CPU线程,内存分配严格绑定到一个子NUMA域。此域包括两个DDR5-4800通道和一个通过PCIe的256 GB A1000 CXL内存扩展模块。通过将分配绑定到单个节点,确保DDR5通道的初始饱和。
实验利用了Alpaca 7B模型[60],需要4.1GB的内存。工作负载来源于LightLLM框架[56],包括一系列面向聊天的问题。基线服务器上的单线程客户端机器通过各种LLM查询发送HTTP请求,以模拟真实世界的条件。客户端通过保持恒定的请求流来确保CPU推理后端的连续操作。提示上下文设置为2048字节,以保证最小的推理响应大小。我们逐步增加CPU推理后端计数,以监控LLM推理服务速率(以令牌/s为单位)。
结果分析
-
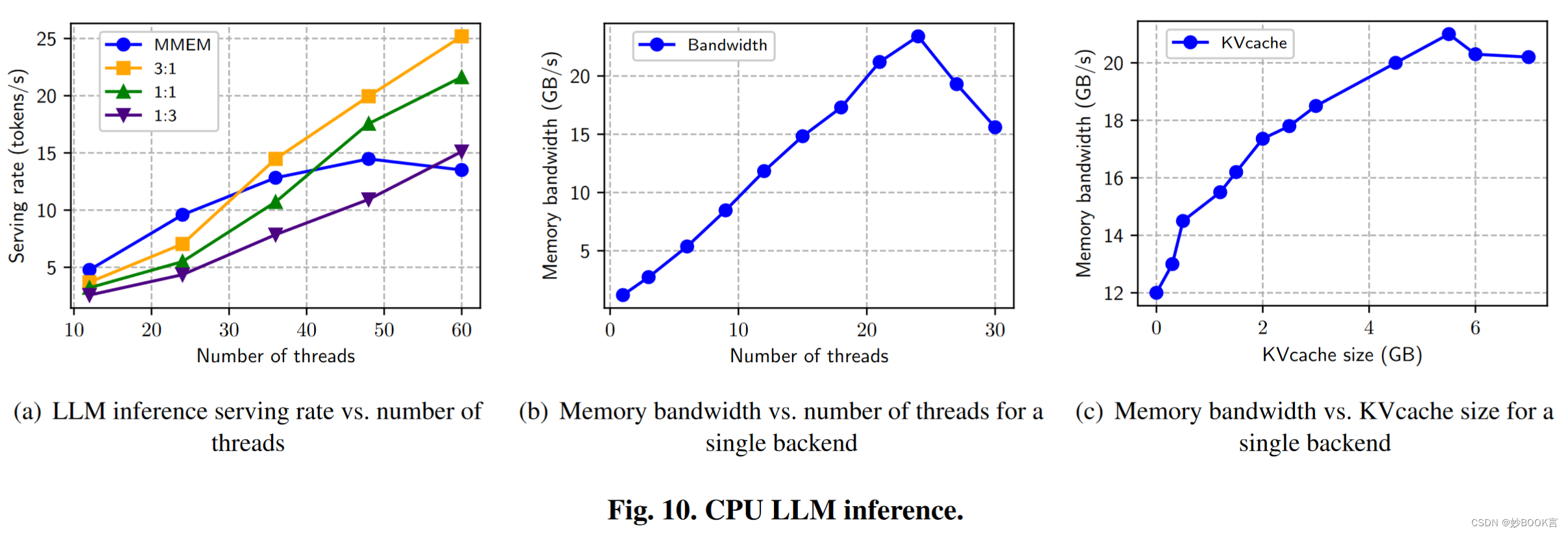
图10(a)显示了随着线程(即CPU推理后端的数量)的增加,各种内存配置的推理服务率。最初,服务速率随着可用存储器带宽几乎线性地提高。但在48个线程处,MMEM带宽饱和限制了服务速率,而交织配置利用额外的CXL带宽进行持续扩展。在具有大量推理线程(60)的情况下,MMEM:CXL=3:1交织超过仅MMEM的方法95%。
-
在60个线程时,完全在MMEM上操作的效率比MMEM:CXL比例为1:3低14%。考虑到CXL固有的更高延迟和减少的内存带宽和图10b的结果,证实了带宽竞争会导致性能下降。
-
带宽争用可能源于加载LLM模型或访问KV高速缓存。图10c说明了KV缓存大小和内存带宽消耗之间的相关性。大约12GB/s的初始内存带宽源于I/O线程从内存加载模型。当在KV高速缓存中存储较大令牌序列的信息时,内存使用率最初线性增加。但是,带宽利用率在超过大约21 GB/s时停止增长。
结论
内核中现有的分层内存管理不考虑内存带宽争用。考虑到使用高主内存带宽(例如70%)的工作负载,现有的页面迁移策略倾向于将数据从较慢的分层内存(CXL)移动到MMEM,假设仍有足够的内存容量。随着更多的数据被写入主存储器,存储器带宽将继续增加(例如,90%)。在这种情况下,访问延迟将呈指数级增长,从而导致工作负载的实际放缓。因此,分层存储器的定义需要重新思考。
总结
针对CXL硬件的测试,测试不同软件在CXL硬件上的性能变化。本文在ASIC CXL 1.1存储器上进行评估,测试不同类型应用的性能表现。(1)CXL 1.1性能特征。带宽争用:延迟在中低带宽利用率下相对稳定,随着带宽接近高水平,延迟呈指数级增加,这主要是由于内存控制器中的排队延迟。与本地主存相比,ASIC CXL的访问延迟为2.5倍,实现了73.6%的PCIe带宽。(2)内存容量受限应用,如键值存储、大数据分析、弹性计算。CXL提供的额外内存容量可以改善受主存容量限制的应用程序。通过智能调度策略,如热页升级,可以使性能几乎与完全在MMEM上运行接近,但对数据局部性差的应用效果有限。(3)内存带宽受限应用,如LLM推理。发现即使部分(30%)本地内存的容量和带宽没有得到充分利用,将一些工作负载转移到CXL内存也可以显著提高性能。因为使用CXL内存可以减少DDR通道上的带宽争用,降低总体内存访问延迟,从而提高应用程序性能。
相关文章:
Exploring Performance and Cost Optimization with ASIC-Based CXL Memory——论文阅读
EuroSys 2024 Paper CXL论文阅读笔记整理 问题 随着内存密集型应用程序对内存需求的增加,受限于物理限制,如DDR DIMM插槽的可用性和发热问题,以及使用高密度DIMM的成本考虑,现代应用程序的内存需求很容易超过单机的内存容量[2&a…...

计算机网络(4) 最长前缀匹配(路由转发表)
一.路由转发 网络数据包IP段只包含源地址与目的地址,经过数据链路层包装与物理层信号形式转换,最终经由不同的链路节点到达目的地址。这个过程是一步一步(hop by hop)进行的,路过一个路由节点则称为一跳。每个路由节点…...

向https地址发送请求失败报错
错误1: 10:13:47.520 [main] DEBUG org.apache.http.conn.ssl.SSLConnectionSocketFactory - Starting handshake 10:13:47.523 [main] DEBUG org.apache.http.impl.conn.DefaultManagedHttpClientConnection - http-outgoing-0: Shutdown connection 10:13:47.523…...

生信技能47 - Shell程序和R程序并行执行处理方法
Linux shell和R程序并行化执行程序方法。 1. 使用do{…} &;done;wait语句并行执行Shell 并行执行总运行时间不再是task数量*单个任务消耗时间,而是取决于单个耗时最长的任务。 # while循环,遍历test.txt文件每行 cat test.txt|while read i; dotime_stamp=$(date &quo…...

java+SimpleRegression 线性模型,针对采集到的大数据设备温度,对设备温度做出预测
首先,让我们通过以下表格展示预测模型开发 Java 的整体流程: 步骤 描述 1 数据收集与清洗 2 特征工程处理 3 模型选择与训练 4 模型评估与调优 5 模型应用与部署 然后引入java的类库 org.apache.commons.math3 math使用原则 math3可谓是轻量级自容器…...

面对失业,不得不做出改变了
有没有发现最近挣钱很难,生活压力很大 大批企业纷纷裁员,大量的就业岗位被机器人机械臂取代 很多的传统职业也将被AI替代, 比如工厂螺丝钉、司机、客服、甚至程序员、医生、等等 众多大厂开发无人驾驶出租车,让本来处在底层的网约车司机无…...

MT2093 活动安排
贪心策略: 每次选择结束时间最早的活动 代码: #include <bits/stdc.h> using namespace std; const int N 5e5 10; int n; struct pp {int a, b; } p[N]; bool cmp(pp x, pp y) {return x.b < y.b; } int ans 0;int main() {cin >>…...

动态javaweb 建立-准备阶段
一、实验内容: 1.定义一个inputjsp页面接收数据输入的长和宽。 2.创建一个javaBean,包含长、宽和面积三个成员变量,分别有对应的get方法和set方法。 3.定义一个业务模型calculate.java,用来计算矩形的面积。 4.定义一个…...

web前端网页设计参考:深度剖析与设计思路探索
web前端网页设计参考:深度剖析与设计思路探索 在Web前端开发领域,网页设计占据着举足轻重的地位。一个优秀的网页设计不仅能提升用户体验,还能有效传达品牌价值和信息。本文将从四个方面、五个方面、六个方面和七个方面,深入剖析…...

node使用http-proxy-middleware做代理,解决跨域问题
const express require(express) const history require(connect-history-api-fallback) const { createProxyMiddleware } require(http-proxy-middleware)let app express()app.use(history())// //匹配api开头的请求,实际转发的请求保api这三个字母 // app.u…...

爱奇艺视频怎么转换成mp4格式,爱奇艺qsv转换mp4最简单方法
在数字化时代,视频格式的转换成为了我们日常生活中常见的需求。特别是对于那些经常从各大视频平台下载视频的朋友来说,将特定格式的视频转换为更通用的格式,如MP4,变得尤为重要。其中,qsv格式的视频转换就是一项常见的…...

HandyControl的属性编辑器如何绑定自定义控件,并集成到自定义编辑器
第一步:自定义控件的TypeDescription描述。 为了扩展.NET的类型描述系统(Type Descriptor System),在运行时动态地更改对象的属性,使得这些属性在PropertyGrid上下文中不会被显示。 1.CLTypeDescriptionProvider:这是一个TypeDesc…...
的水印)
【Python】使用 Python 检测图像中(色差对比度较大)的水印
我已经从你的 全世界路过 像一颗流星 划过命运 的天空 很多话忍住了 不能说出口 珍藏在 我的心中 只留下一些回忆 🎵 牛奶咖啡《从你的全世界路过》 前言 在图像处理领域中,检测图像中的水印是一项重要任务。水印通常用于保护图像…...

最短路:Bellman-Ford
最短路:Bellman-Ford 题目描述参考代码 题目描述 输入样例 3 3 1 1 2 1 2 3 1 1 3 3输出样例 3参考代码 #include <iostream> #include <cstring> #include <algorithm>using namespace std;const int N 510, M 10010;int n, m, k; int dist…...

深度学习的分类网络
深度学习的分类网络 深度学习的分类网络(Classification Networks)是用于将输入数据分配到预定义类别的神经网络。它们广泛应用于图像分类、文本分类、语音识别等任务。以下是对深度学习分类网络的详细介绍,包括其基本概念、主要架构、常见模…...
Si24R05—高度集成的低功耗 2.4G+125K SoC 芯片
Si24R05是一款高度集成的低功耗SoC芯片,具有低功耗、Low Pin Count、宽电压工作范围,集成了13/14/15/16位精度的ADC、LVD、UART、SPI、I2C、TIMER、WUP、IWDG、RTC、无线收发器、3D低频唤醒接收器等丰富的外设。内核采用RISC-V RV32IMAC(2.6 …...

layuimini框架实现点击菜单栏回到起始页
在layui页面中,如果使用了 window.location.href""进行了页面跳转,再点击菜单栏是不会显示起始页,而是跳转后的页面, 解决: 在miniTab.js文件中找到:listen方法 将其中修改为: if …...
【ubuntu22.04~mysql-MHA-mycat】
ubuntu22.04~mysql-MHA-mycat 前言一、安装指定版本mysql-server(8.0.23)1、安装mysql2、启用修改mysql配置1、安装3、修改权限3.1、用户密码存放位置,3.2、创建用户root@%4、mysql配置文件my.cnf修改1、主节点my.cnf2、slave1~my.cnf修改项3、slave2~my.cnf修改项5、重启mys…...

Java Reflection 反射使用 完全指南
前言 Java 中的反射大家都不陌生,有很多很好的文章都进行了讲解,但是很难找到一篇文章能完全解释反射的所有用法,特别是反射获取这个对象的注解的信息和泛型信息,往往都停留在了获取类的函数、方法,构造上。所以这篇文…...

2024年适合学生写作业的台灯推荐:五款公认好用的护眼台灯
儿童的视力健康是每一个家庭都极为关注的问题。目前中国近视率居高不下,且呈现出年轻化、低龄化的趋势。儿童近视的问题愈发严重,如何才能让孩子在学习的同时,眼睛也能得到充分的保护?答案就是护眼台灯。护眼台灯通常拥有柔和的光…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

React核心概念:State是什么?如何用useState管理组件自己的数据?
系列回顾: 在上一篇《React入门第一步》中,我们已经成功创建并运行了第一个React项目。我们学会了用Vite初始化项目,并修改了App.jsx组件,让页面显示出我们想要的文字。但是,那个页面是“死”的,它只是静态…...

【java面试】微服务篇
【java面试】微服务篇 一、总体框架二、Springcloud(一)Springcloud五大组件(二)服务注册和发现1、Eureka2、Nacos (三)负载均衡1、Ribbon负载均衡流程2、Ribbon负载均衡策略3、自定义负载均衡策略4、总结 …...