python数据分析--- ch6-7 python容器类型的数据及字符串
python数据分析---ch6-7 python容器类型的数据及字符串
- 1. Ch6--容器类型的数据
- 1.1 序列
- 1.1.1 序列的索引操作
- 1.1.2 加和乘操作
- 1.1.3 切片操作
- 1.1.4 成员测试
- 1.2 列表
- 1.2.1 创建列表
- 1.2.2 追加元素
- 1.2.3 插入元素
- 1.2.4 替换元素
- 1.2.5 删除元素
- 1.2.6 列表排序
- (1)sorted() 函数
- (2)list.sort() 方法
- (3)逆序排序
- (4)自定义排序规则
- (5)多关键字排序
- 1.2.7 列表内容提取
- (1)索引访问
- (2)切片操作
- (3)遍历列表
- (4)列表推导式
- (5)条件筛选
- (6)map函数
- 1.3 元组
- 1.3.1 创建元组
- 1.3.2 元组拆包
- 1.4 集合
- 1.4.1 创建集合
- 1.4.2 修改集合
- 1.4.3 集合的操作
- 1.5 字典
- 1.5.1 字典的创建
- 1.5.2 字典内容的提取
- 1.5.3 字典的修改
- (1)添加新的键值对
- (2)替换已有的键对应的值
- (3)删除键值对
- 2. Ch7--字符串
- 2.1 字符串的表示方式
- 2.1.1 常用转义符
- (1)常用转义符:
- (2)其它转义符
- 2.1.2 原始字符串
- 2.1.3 长字符串
- 2.2 字符串与数字的相互转化
- 2.2.1 将字符串转换为数字
- 2.2.2 将数字转换为字符串
- 2.3 格式化字符串
- 2.3.1 使用占位符
- 2.3.2 格式化控制符
- 2.4 操作字符串
- 2.4.1 字符串查找
- 2.4.2 字符串替换
- 2.4.3 字符串分割
1. Ch6–容器类型的数据

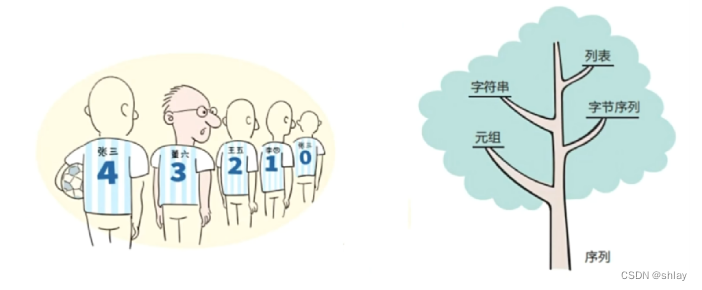
1.1 序列
序列(sequence)是一种可迭代的、元素有序的容器类型的数据。
1.1.1 序列的索引操作
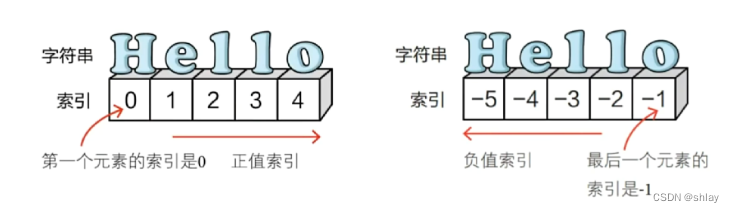
squ = 'hello'
print(squ[0])
print(squ[-1])
print(squ[-5])
output
h
o
h
print(squ[1:3])
print(squ[0:5:2])
output
el
hlo
1.1.2 加和乘操作
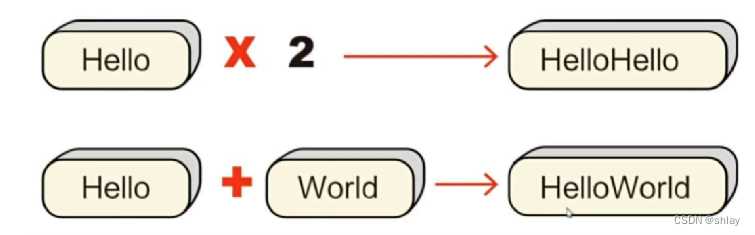
print(squ*2)
squ1=(1,3,5,7)
squ1*2
output
hellohello
(1, 3, 5, 7, 1, 3, 5, 7)
print('hello'+','+'world')
print(squ1+squ1)
squ2 = 'world'
print(squ+squ2)
output
hello,world
(1, 3, 5, 7, 1, 3, 5, 7)
helloworld
1.1.3 切片操作
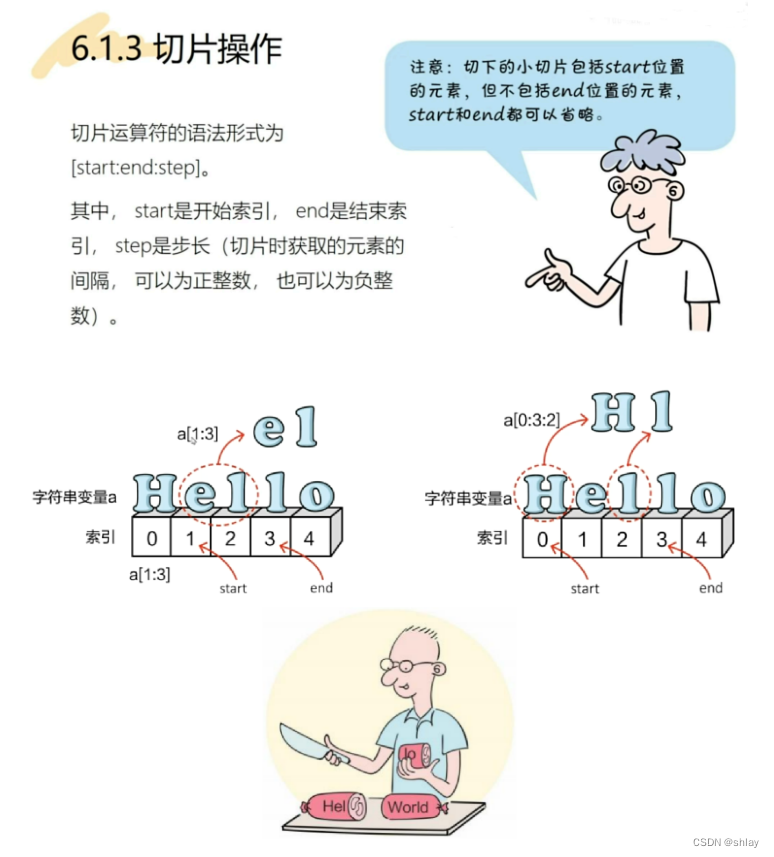
print(squ[0:3])
print(squ[:3])
print(squ[0:-1])output
hel
hel
hell
print(squ[:-1:2])
print(squ[:5:2])
output
hl
hlo
1.1.4 成员测试
print('h'in squ)
print('H'in squ)
print('H'not in squ)
output
True
False
True
1.2 列表
1.2.1 创建列表
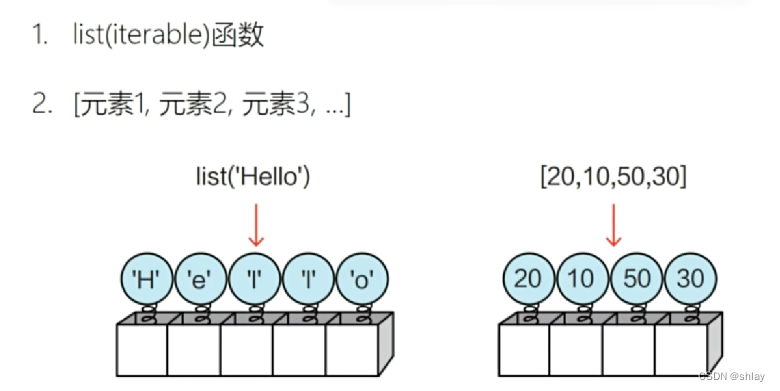
list1 = list('hello')
print(list1)
list2 = list((2,3,4,5,6))
print(list2)
list3 = []
print(type(list3))
list4 = [2,3,4,5,6]
print(list4)
output
[‘h’, ‘e’, ‘l’, ‘l’, ‘o’]
[2, 3, 4, 5, 6]
<class ‘list’>
[2, 3, 4, 5, 6]
1.2.2 追加元素
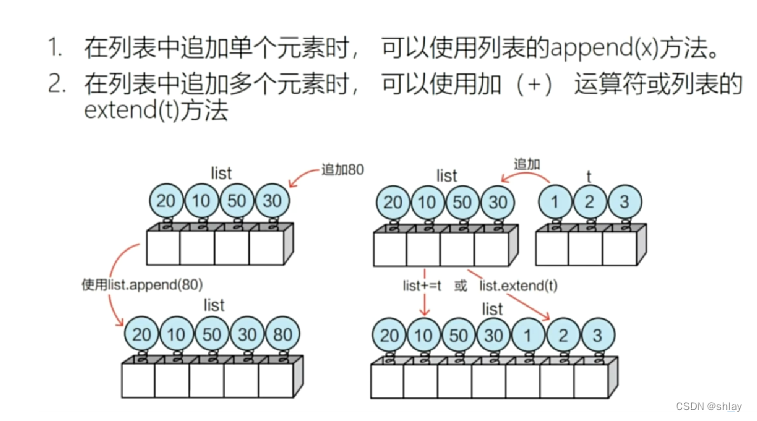
list4.append(80)#添加单个元素
list4
output
[2, 3, 4, 5, 6, 80]
list5 = list4+[90,100,200]#添加多个元素
print(list5)
list4.extend([90,100,200])
print(list4)
output
[2, 3, 4, 5, 6, 80, 90, 100, 200]
[2, 3, 4, 5, 6, 80, 90, 100, 200]
1.2.3 插入元素
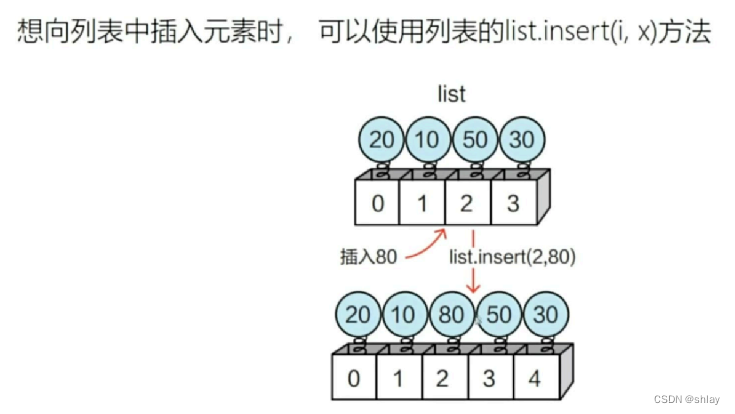
list6 = [1,2,3,4]
list6.insert(2,80)
print(list6)
output
[1, 2, 80, 3, 4]
1.2.4 替换元素
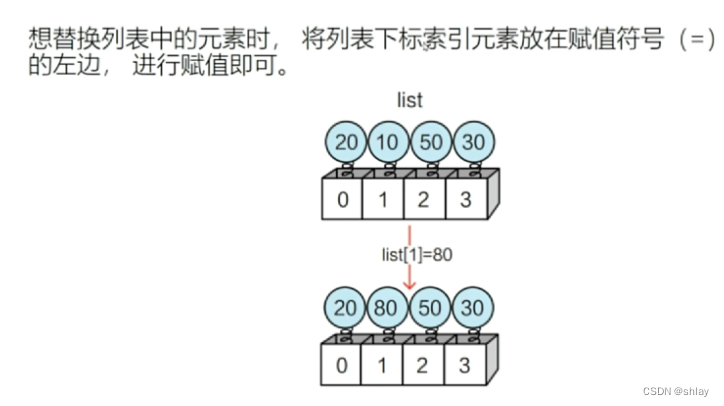
list6[1]=100
print(list6)
output
[1, 100, 80, 3, 4]
1.2.5 删除元素
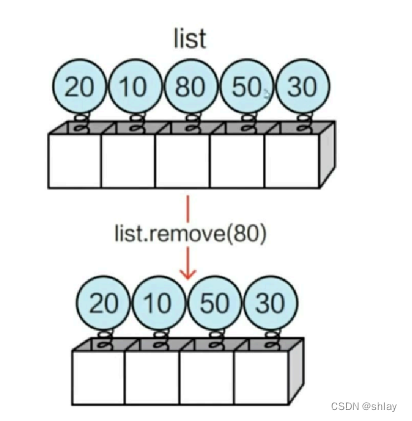
list6.remove(80)
print(list6)
output
[1, 100, 3, 4]
list6.append(100)
print(list6)output
[1, 3, 4, 100, 100, 100]
list6.remove(100)
print(list6)
output
[1, 3, 4, 100, 100]
1.2.6 列表排序
默认排序、逆序排序、自定义排序、多关键字排序
-
1.sorted() 函数:这是Python中最常用的排序工具,它可以对列表进行排序,并且返回一个新的排序后的列表。默认情况下,sorted()函数按照元素的自然顺序进行排序,但也可以指定key函数来进行复杂的排序。
-
2.list.sort() 方法:与sorted()不同,list.sort()方法会直接修改原列表,而不是创建一个新的列表。这个方法也有一个key参数,允许指定自定义的排序规则。
-
3.逆序排序:可以通过在sorted()或list.sort()中设置参数来实现逆序排序。
-
4.自定义排序规则:可以通过提供key函数来实现自定义的排序规则。例如,可以根据元素的长度、元素中的某个属性等进行排序。
-
5.多关键字排序:可以同时使用多个排序关键字,Python会根据这些关键字的优先级进行排序。
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
(1)sorted() 函数
这是Python中最常用的排序工具,它可以对列表进行排序,并且返回一个新的排序后的列表。默认情况下,sorted()函数按照元素的自然顺序进行排序,但也可以指定key函数来进行复杂的排序。
# 1.使用sorted()进行默认排序
sorted_num = sorted(numbers)
print(sorted_num)
output
[1, 1, 2, 3, 4, 5, 6, 9]
numbers
output
[3, 1, 4, 1, 5, 9, 2, 6]
(2)list.sort() 方法
与sorted()不同,list.sort()方法会直接修改原列表,而不是创建一个新的列表。这个方法也有一个key参数,允许指定自定义的排序规则。
# 2.使用list.sort()进行默认排序
numbers.sort()
print(numbers)
output
[1, 1, 2, 3, 4, 5, 6, 9]
(3)逆序排序
可以通过在sorted()或list.sort()中设置参数reverse来实现逆序排序。
# 使用sorted()进行逆序排序
reverse_num = sorted(numbers,reverse=True)
print(reverse_num)
output
[9, 6, 5, 4, 3, 2, 1, 1]
# 使用list.reverse()进行逆序排序
numbers.reverse()
print(numbers)
output
[9, 6, 5, 4, 3, 2, 1, 1]
(4)自定义排序规则
可以通过提供key函数来实现自定义的排序规则。例如,可以根据元素的长度、元素中的某个属性等进行排序。
# 假设有一个字符串列表,我们想根据字符串的长度进行排序
strings = ['apple','kiwi','banana','cherry','grape']
sorted_str = sorted(strings)
print(sorted_str)
sorted_str1 = sorted(strings,key=len)
print(sorted_str1)
output
[‘apple’, ‘banana’, ‘cherry’, ‘grape’, ‘kiwi’]
[‘kiwi’, ‘apple’, ‘grape’, ‘banana’, ‘cherry’]
(5)多关键字排序
可以同时使用多个排序关键字,Python会根据这些关键字的优先级进行排序。
# 假设有一个字典列表,我们想先根据年龄升序,然后根据名字的字典序进行排序
people = [{'name': 'Alice', 'age': 30},{'name': 'Bob', 'age': 25},{'name': 'Lucky', 'age': 30},{'name': 'Lily', 'age': 18},
]sorted_people = sorted(people,key=lambda p:(p['age'],p['name']))
print(sorted_people)
output
[{‘name’: ‘Lily’, ‘age’: 18}, {‘name’: ‘Bob’, ‘age’: 25}, {‘name’: ‘Alice’, ‘age’: 30}, {‘name’: ‘Lucky’, ‘age’: 30}]
1.2.7 列表内容提取
索引访问、切片操作、遍历列表、列表推导式、条件筛选、map函数
-
1.索引访问:可以通过列表的索引来访问或提取特定的元素。Python的索引从0开始,负数索引从列表末尾开始。
-
2.切片操作:切片可以用来提取列表中的一段连续元素。切片的语法是[start:stop:step],其中start是切片开始的索引,stop是切片结束的索引(不包括该索引的元素),step是步长,表示每次跳过的元素数量。
-
3.遍历列表:可以使用循环结构(如for循环)或enumerate()函数来逐个访问列表中的元素,从而进行内容提取。
-
4.列表推导式:列表推导式是一种优雅且简洁的创建列表的方法,可以用来根据已有列表生成新的列表,同时实现内容的提取和转换。
-
5.条件筛选:可以使用条件表达式结合遍历或列表推导式、filter()函数来提取满足特定条件的元素。
-
6.map函数:使用map函数可以将一个函数应用于列表的所有元素,从而实现对列表内容的提取、转换或过滤。
(1)索引访问
可以通过列表的索引来访问或提取特定的元素。Python的索引从0开始,负数索引从列表末尾开始。
# 假设有一个数字列表
numbers1 = [10, 20, 30, 40, 50]# 提取第一个元素
first_num = numbers1[0]
print(first_num)
# 提取最后一个元素
last_num = numbers1[-1]
print(last_num)
output
10
50
(2)切片操作
切片可以用来提取列表中的一段连续元素。切片的语法是[start:stop:step],
其中start是切片开始的索引,stop是切片结束的索引(不包括该索引的元素),step是步长,表示每次跳过的元素数量。
# 使用切片提取列表中的一段元素
sliced_num = numbers1[1:4]
print(sliced_num)
output
[20, 30, 40]
sliced_num1 = numbers1[:3]
print(sliced_num1)sliced_num2 = numbers1[2:]
print(sliced_num2)
sliced_num3 = numbers1[2:len(numbers1)]
print(sliced_num3)
output
[10, 20, 30]
[30, 40, 50]
[30, 40, 50]
(3)遍历列表
- 基本循环遍历:可以使用循环结构(如for循环)来逐个访问列表中的元素,从而进行内容提取。
- 使用enumerate()函数:如果你需要在遍历时获取元素的索引,可以使用 enumerate() 函数。
# 遍历列表并打印每个元素
for num in numbers1:print(num)
output
10
20
30
40
50
# 使用enumerate遍历列表,并打印索引和元素
for index,num in enumerate(numbers1):print(f'Index:{index},Value:{num}')
output
Index:0,Value:10
Index:1,Value:20
Index:2,Value:30
Index:3,Value:40
Index:4,Value:50
(4)列表推导式
列表推导式是一种优雅且简洁的创建列表的方法,可以用来根据已有列表生成新的列表,同时实现内容的提取和转换。
for num in numbers:if num%2==0:print(num)for index,num in enumerate(numbers):if num%2==0:print(f"Index:{index},Value:{num}")
output
6
4
2
Index:1,Value:6
Index:3,Value:4
Index:5,Value:2
# 示例1:使用列表推导式提取偶数元素
even_numbers = [num for num in numbers if num%2==0]
print(even_numbers)
output
[6, 4, 2]
# 示例2:
# 列表推导式可以用一行代码完成循环和条件判断的操作,使得代码更加简洁和易于理解。
records = [{'id': 1, 'status': 'success'},{'id': 2, 'status': 'fail'},{'id': 3, 'status': 'success'},{'id': 4, 'status': 'fail'},{'id': 5, 'status': 'success'},{'id': 6, 'status': 'fail'},# ... 更多记录
]# 使用列表推导式提取状态为'success'的记录
success_records = [x for x in records if x['status']=='success']
print(success_records)
output
[{‘id’: 1, ‘status’: ‘success’}, {‘id’: 3, ‘status’: ‘success’}, {‘id’: 5, ‘status’: ‘success’}]
(5)条件筛选
可以使用条件表达式结合遍历或列表推导式、filter()函数来提取满足特定条件的元素。
numbers2 = [-3,-2,-1,0,1, 2, 3, 4, 5, 6]
# 使用for循环筛选出正数
res = []
for n in numbers2:if n>0:res.append(n)
print(res)
output
[1, 2, 3, 4, 5, 6]
# 条件表达式结合遍历:提取大于3的元素
res1 = [n for n in numbers2 if n>3]
print(res1)
output
[4, 5, 6]
# 使用filter()筛选出奇数
odd_nums = list(filter(lambda x:abs(x%2)==1,numbers2))
print(odd_nums)
output
[-3, -1, 1, 3, 5]
(6)map函数
使用map函数可以将一个函数应用于列表的所有元素,从而实现对列表内容的提取、转换或过滤。
# 示例1:使用map函数将每个元素转换为字符串
str_number =list( map(str,numbers2))
print(str_number)
output
[‘-3’, ‘-2’, ‘-1’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’]
# 示例2:使用map()和filter()筛选出列表元素乘以2后能被3整除的数
res3 = list(filter(lambda x: x%3==0,map(lambda x:x*2, numbers2)))
print(res3)
output
[-6, 0, 6, 12]
1.3 元组
1.3.1 创建元组
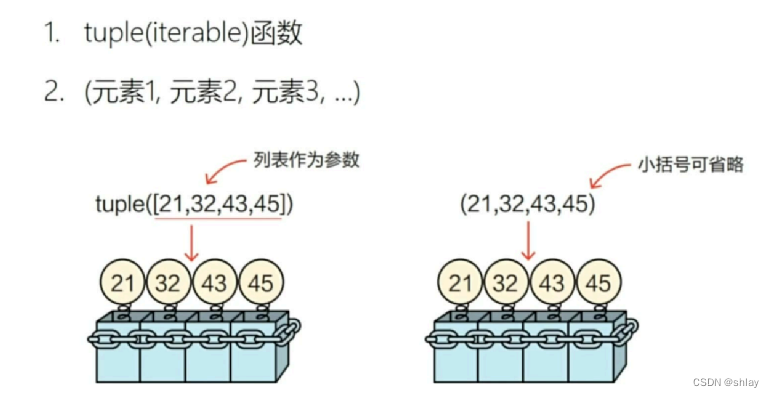
tp1 = tuple([21,32,43,54])
print(type(tp1))tp2=(21,32,43,54)
print(type(tp2),tp2)lst3 = list(tp2)
print(type(lst3),lst3)set3 = set(tp2)
print(type(set3),set3)
output
<class ‘tuple’>
<class ‘tuple’> (21, 32, 43, 54)
<class ‘list’> [21, 32, 43, 54]
<class ‘set’> {32, 43, 21, 54}
1.3.2 元组拆包
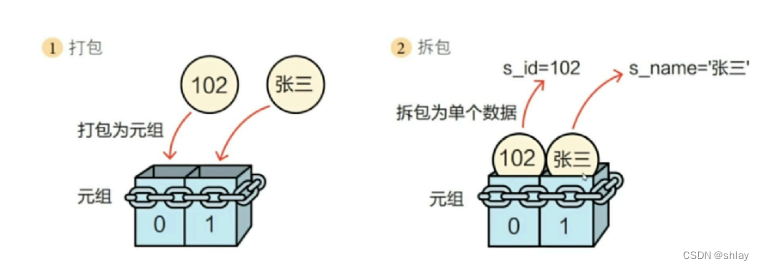
tp3 = (102,'张三')
print(tp3)
s_id,s_name = tp3
print(s_id)
print(s_name)
output
(102, ‘张三’)
102
张三
tp3 = ([102,106,108],['张三','李四','王五'])
print(tp3)
s_id,s_name = tp3
print(s_id)
print(s_name)
output
([102, 106, 108], [‘张三’, ‘李四’, ‘王五’])
[102, 106, 108]
[‘张三’, ‘李四’, ‘王五’]
1.4 集合
1.4.1 创建集合
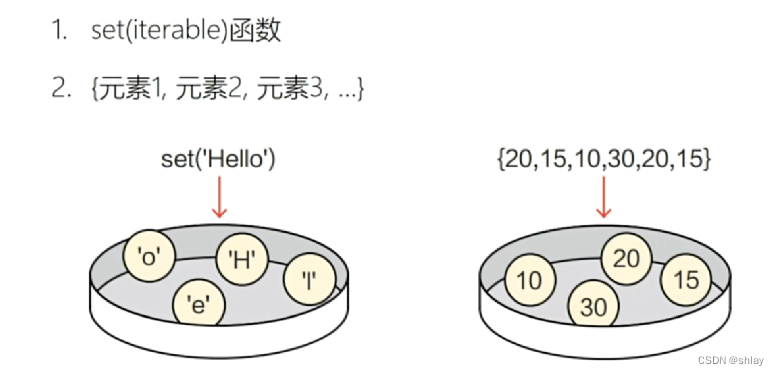
set1 = {20,15,10,30,20,15}
set1
output
{10, 15, 20, 30}
1.4.2 修改集合

# set1.add(10)
# print(set1)
# set1.clear()set1.add(20)
print(set1)
output
{20}
1.4.3 集合的操作
并集、交集、差集和对称差集等
set1 = {1, 2, 3,4}
set2 = {3, 4, 5,6}
# 交集(intersection)
print(set1&set2)
print(set1.intersection(set2))
output
{3, 4}
# 并集(union)
print(set1|set2)
print(set1.union(set2))
output
{1, 2, 3, 4, 5, 6}
{1, 2, 3, 4, 5, 6}
# 差集(difference)
print(set1-set2)
print(set1.difference(set2))
output
{1, 2}
{1, 2}
print(set2-set1)
print(set2.difference(set1))
output
{5, 6}
{5, 6}
# 对称差集(symmetric difference):两集合中交集之外的元素
print(set1^set2)
output
{1, 2, 5, 6}
1.5 字典

1.5.1 字典的创建
在Python中,可以使用一对花括号 {} 来创建一个字典,或者使用内置的dict()函数来创建一个字典。字典由键-值对(key-value pairs)组成,每个键都唯一且不可变(通常是字符串或数字),对应一个值。以下是一些示例:
# 创建一个空字典
empty_dict = {}
print(empty_dict)
print(type(empty_dict))
output
{}
<class ‘dict’>
# 创建一个包含三个键,值为空列表的字典
subject_scores={"小红":None,"小明":None,"小亮":None,
}
print(subject_scores)
output
{‘小红’: None, ‘小明’: None, ‘小亮’: None}
# 创建一个包含三个键值对的字典
subject_scores={"小红":90,"小明":80,"小亮":95,
}
print(subject_scores)
output
{‘小红’: 90, ‘小明’: 80, ‘小亮’: 95}
# 通过 dict() 函数创建字典
empty_dict1 = dict()
print(empty_dict1)subject_scores1=dict(小红=90,小明=80,小亮=95)
print(subject_scores1)
output
{}
{‘小红’: 90, ‘小明’: 80, ‘小亮’: 95}
# 使用列表推导式创建字典
students = ["小红","小明","小亮"]
scores = [90,80,95]
subject_scores2={students[i]:scores[i] for i in range(len(students))}
print(subject_scores2)
output
{‘小红’: 90, ‘小明’: 80, ‘小亮’: 95}
1.5.2 字典内容的提取
在Python中,字典(dictionary)是一种内置的数据结构,用于存储键(key)和值(value)的对应关系。字典的键(key)必须是唯一的,而值(value)则可以是任何数据类型。以下是字典内容的键(key)和值(value)的提取方法:
my_dict = {"小明":269,"小红":243,"小亮":227}
print(my_dict)
output
{‘小明’: 269, ‘小红’: 243, ‘小亮’: 227}
# 提取所有键(keys):使用 `keys()` 方法可以获取字典中所有的键。
keys = my_dict.keys()
print(keys)
output
dict_keys([‘小明’, ‘小红’, ‘小亮’])
# 提取所有值(values):使用 `values()` 方法可以获取字典中所有的值。
values = my_dict.values()
print(values)
output
dict_values([269, 243, 227])
# 提取键值对(items):使用 `items()` 方法或字典的 `items` 属性可以获取字典中的所有键值对。# 使用 items() 方法
items1 = my_dict.items()
print(items1)
print(list(items1)[0])
output
dict_items([(‘小明’, 269), (‘小红’, 243), (‘小亮’, 227)])
(‘小明’, 269)
for k,v in items1:print('names = ',k)print('scores = ', v)
output
names = 小明
scores = 269
names = 小红
scores = 243
names = 小亮
scores = 227
# 提取特定键的值:使用方括号 `[]` 并提供键名可以获取特定键对应的值。
scores0 = my_dict['小明']
print(scores0)
output
269
# 如果键不存在,将会抛出 KeyError
scores1 = my_dict['小白']
print(scores1)
output
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)~\AppData\Local\Temp\ipykernel_14716\3599480679.py in <module>1 # 如果键不存在,将会抛出 KeyError
----> 2 scores1 = my_dict['小白']3 print(scores1)KeyError: '小白'
# 为了安全地提取特定键的值,可以使用 `get()` 方法,它允许您为不存在的键提供一个默认值。
scores2 = my_dict.get('小白',0)
print(scores2)
output
0
1.5.3 字典的修改
Python中的字典(dict)是一种可变的数据结构,可以轻松地进行修改。这些修改包括添加新的键值对、替换已有的键对应的值、以及删除键值对。
下面是对这三种操作的示例:
(1)添加新的键值对
my_dict[‘new_key’] = ‘new_value’
如果添加的键已经存在于字典中,那么它的值将被新值覆盖。
my_dict = {"小明":269,"小红":243,"小亮":227}
my_dict['小白']=300
print(my_dict)output
{‘小明’: 269, ‘小红’: 243, ‘小亮’: 227, ‘小白’: 300}
{‘小明’: 269, ‘小红’: 243, ‘小亮’: 227, ‘小白’: 299}
(2)替换已有的键对应的值
如果键已经存在于字典中,你可以直接通过键来赋予它一个新的值。
my_dict['小白']=299
print(my_dict)
(3)删除键值对
你可以使用 del 语句或者 pop() 方法来删除字典中的键值对。
print(f"原字典》》{my_dict}")
del my_dict['小明']
print(f"新字典》》{my_dict}")
output
原字典》》{‘小明’: 269, ‘小红’: 243, ‘小亮’: 227, ‘小白’: 299}
新字典》》{‘小红’: 243, ‘小亮’: 227, ‘小白’: 299}
# 使用pop()方法删除一个键值对,并返回被删除的值
print(f"原字典》》{my_dict}")
my_dict1 = my_dict.pop('小白')
print(my_dict1)
print(f"新字典》》{my_dict}")
output
原字典》》{‘小红’: 243, ‘小亮’: 227, ‘小白’: 299}
299
新字典》》{‘小红’: 243, ‘小亮’: 227}
2. Ch7–字符串
2.1 字符串的表示方式
- 普通字符串:指用单引号(‘’)或双引号(“”)括起来的字符串。
- 原始字符串:
- 长字符串
a = 'hello'
b = "world"
print(a+" "+b)
output
hello world
2.1.1 常用转义符
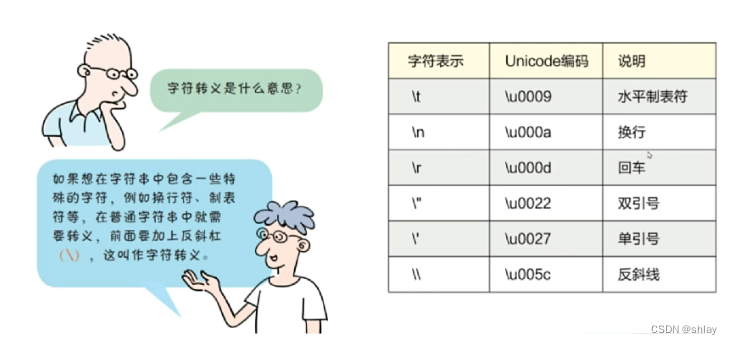
在Python中,字符串中的转义符用于表示那些无法直接包含在字符串中的字符,或者用于表示特殊的含义。
(1)常用转义符:
print("hello\tworld\tgood\tluck")
output
hello world good luck
print("hello world\ngood luck")
output
hello world
good luck
print("hello world \r good luck")
output
hello world
good luck
print('hello "童鞋"')
print('hello,Tom\'s dog')
output
hello “童鞋”
hello,Tom’s dog
print("hello\\world")
output
hello\world
(2)其它转义符
- Unicode字符 (
\u):表示Unicode字符,后面跟随4个十六进制数字。 - 十六进制字符 (
\x):表示十六进制的字符,后面跟随2个十六进制数字。 - 响铃符 (
\a):发出系统的响铃声。 - 退格符 (
\b):删除光标前的一个字符(在大多数文本输出中不起作用)。 - 空字符 (
\0):表示ASCII码表中的空字符(NULL,值为0)。 - 垂直制表符 (
\v):在字符串中插入一个垂直制表符。
print("\u4F60\u597D")
output
你好
print("\x58")
output
X
print('\a')#cmd窗口操作
output
print("hello\bworld")
output
helloworld
print("hello\vworld\vgood luck")
output
helloworldgood luck
2.1.2 原始字符串
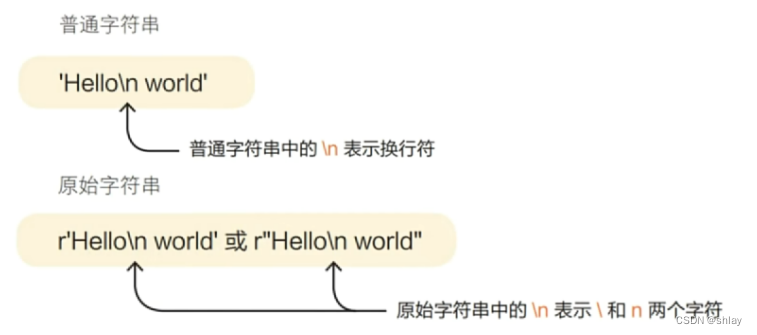
print(r"hello \n world")
output
hello \n world
2.1.3 长字符串
- 1.使用三个单引号 ‘’’ 或三个双引号 “”" 来定义,这两种方式在Python中是等价的。
- 2.使用普通的单引号 ’ 或双引号 ",并在字符串中的适当位置使用反斜杠 \n 进行行续。
str00 = "《咏鹅》 鹅鹅鹅,曲项向天歌。白毛浮绿水,红掌拨清波。"
print(str00)
output
《咏鹅》 鹅鹅鹅,曲项向天歌。白毛浮绿水,红掌拨清波。
str0="
《咏鹅》
鹅鹅鹅,
曲项向天歌。
白毛浮绿水,
红掌拨清波。
"
print(str0)
output
File “C:\Users\SHEN HL\AppData\Local\Temp\ipykernel_17364\1236353306.py”, line 1
str0="
^
SyntaxError: EOL while scanning string literal
str1="""
《咏鹅》
鹅鹅鹅,
曲项向天歌。
白毛浮绿水,
红掌拨清波。
"""
print(str1)
***output***
《咏鹅》
鹅鹅鹅,
曲项向天歌。
白毛浮绿水,
红掌拨清波。
str2 = "《咏鹅》\n 鹅鹅鹅,\n曲项向天歌。\n白毛浮绿水,\n红掌拨清波。"
print(str2)
output
《咏鹅》
鹅鹅鹅,
曲项向天歌。
白毛浮绿水,
红掌拨清波。
2.2 字符串与数字的相互转化
2.2.1 将字符串转换为数字
将字符串转换为数字,可以使用int()和float()实现,如果成功则返回数字,否则引发异常。
int("80")
output
80
float("80.0")
output
80.0
2.2.2 将数字转换为字符串
将数字转换为字符串,可以使用str()函数,str()函数可以将很多类型的数据都转换为字符串。
str(123)
output
‘123’
str(123.456)
output
‘123.456’
2.3 格式化字符串
使用字符串的format()方法,它不仅可以实现字符串的拼接,还可以格式化字符串。
2.3.1 使用占位符
要想将表达式的计算结果插入字符串中,则需要用到占位符({})。
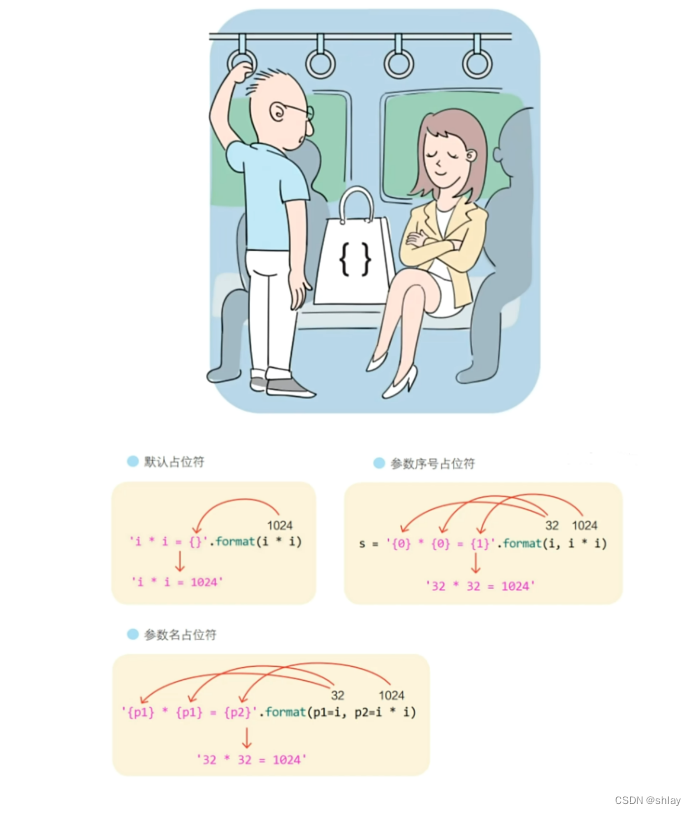
i=9
print("i*i={}".format(i*i))
output
i*i=81
i=9
print("{}*{}={}".format(i,i,i*i))
output
9*9=81
i=9
print("{0}*{0}={1}".format(i,i*i))
output
9*9=81
i=9
print("{n1}*{n1}={n2}".format(n1=i,n2=i*i))
output
9*9=81
i=9
print("{n1}*{n3}={n2}".format(n2=i*i,n1=i,n3=5))
output
9*5=81
2.3.2 格式化控制符
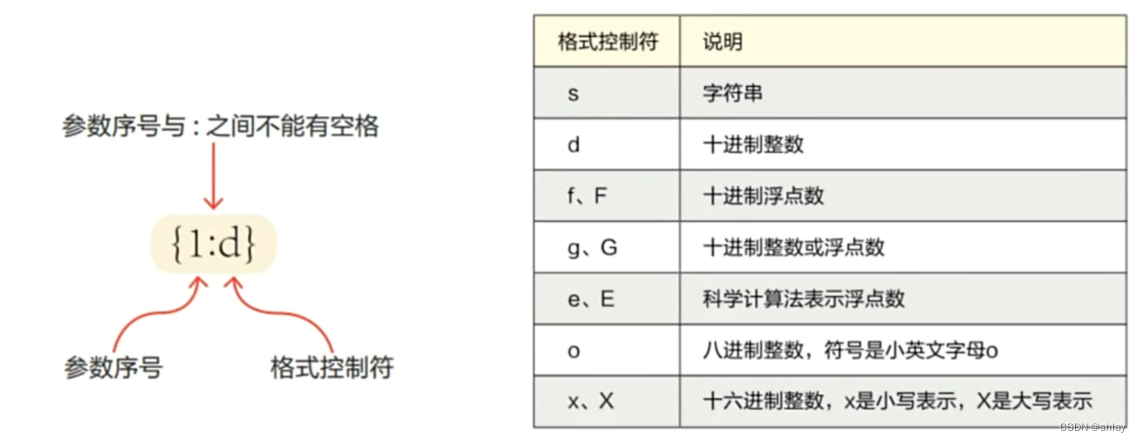
money = 15089.67
name = 'Kitty'
age = 26
print("{}今年{}岁,她的工资是{}".format(name,age,money))
output
Kitty今年26岁,她的工资是15089.67
money = 15089.67
name = 'Kitty'
age = 26
print("{0}今年{1}岁,她的工资是{2:0.1f}".format(name,age,money))
output
Kitty今年26岁,她的工资是15089.7
money = 1508900.67
name = 'Kitty'
age = 26
print("{0:s}今年{1:d}岁,她的工资是{2:e}".format(name,age,money))
output
Kitty今年26岁,她的工资是1.508901e+06
2.4 操作字符串
2.4.1 字符串查找
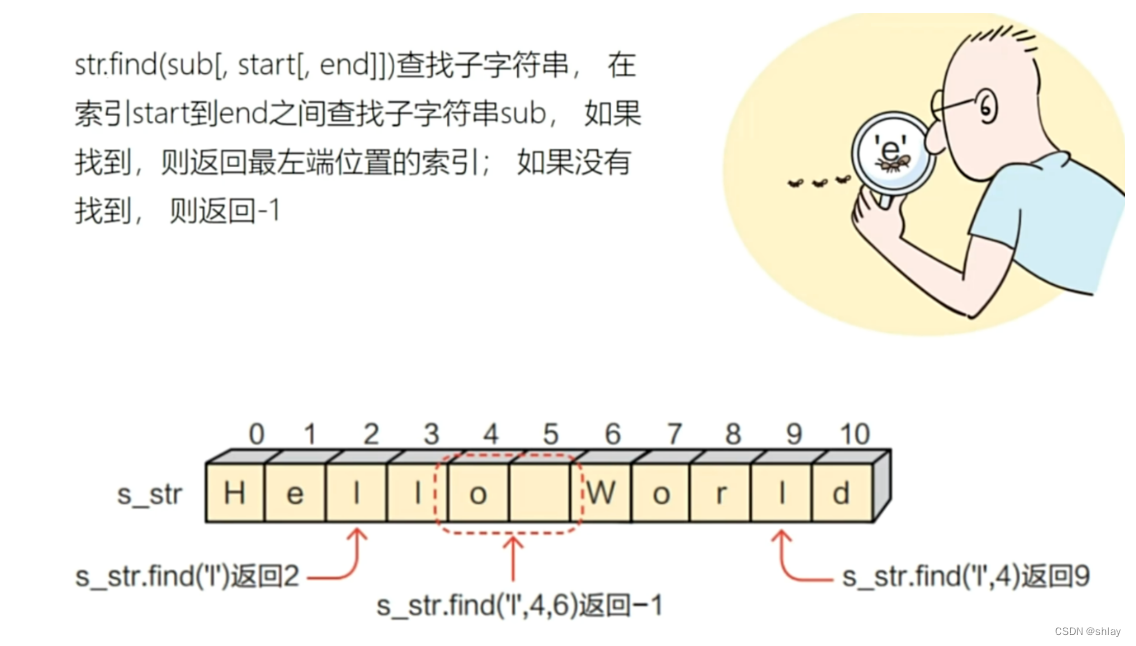
str5 = "hello world"
print(str5.find('e'))
print(str5.find('l'))
print(str5.find('l',4,8))
print(str5.find('l',4))
output
1
2
-1
9
2.4.2 字符串替换

str6 = "AB-CD-EF-GH"
print(str6.replace('-','#'))
output
AB#CD#EF#GH
str6 = "AB-CD-EF-GH"
print(str6.replace('-','#',2))
output
AB#CD#EF-GH
2.4.3 字符串分割

str7='E://tjfx/ch7/img/7-1.png'#需要在自己的某个路径放一张名为“7-1.png”的图片,否则会报错
file_name = str7.split('.')
save_file = file_name[0]+'.pdf'
print(save_file)
output
E://tjfx/ch7/img/7-1.pdf
str6.split('-')
output
[‘AB’, ‘CD’, ‘EF’, ‘GH’]
相关文章:
python数据分析--- ch6-7 python容器类型的数据及字符串
python数据分析---ch6-7 python容器类型的数据及字符串 1. Ch6--容器类型的数据1.1 序列1.1.1 序列的索引操作1.1.2 加和乘操作1.1.3 切片操作1.1.4 成员测试 1.2 列表1.2.1 创建列表1.2.2 追加元素1.2.3 插入元素1.2.4 替换元素1.2.5 删除元素1.2.6 列表排序(1&…...

【Linux取经路】守护进程
文章目录 一、前台进程和后台进程二、Linux 的进程间关系三、setsid——将当前进程设置为守护进程四、daemon——设置为守护进程五、结语 一、前台进程和后台进程 Linux 中每一次用户登录都是一个 session,一个 session 中只能有一个前台进程在运行,键盘…...

Nginx之文件下载服务器
1.概述 在对外分享文件时,利用Nginx搭建一个简单的下 载文件管理服务器,文件分享就会变得非常方便。利 用Nginx的诸多内置指令可实现自动生成下载文件列表 页、限制下载带宽等功能。配置样例如下: server {listen 8080;server_name localhos…...

OpenCV学习(4.11) OpenCV中的图像转换
1. 目标 在本节中,我们将学习 使用OpenCV查找图像的傅立叶变换利用Numpy中可用的FFT功能傅立叶变换的一些应用我们将看到以下函数:**cv.dft()** ,**cv.idft()** 等 理论 傅立叶变换用于分析各种滤波器的频率特性。对于图像,使用…...

2024.6.13每日一题
LeetCode 子序列最大优雅度 题目链接:2813. 子序列最大优雅度 - 力扣(LeetCode) 题目描述 给你一个长度为 n 的二维整数数组 items 和一个整数 k 。 items[i] [profiti, categoryi],其中 profiti 和 categoryi 分别表示第 i…...

Linux命令详解(2)
文本处理是Linux命令行的重要应用之一。通过一系列强大的命令,用户可以轻松地对文本文件进行编辑、查询和转换。 cat: 这个命令用于查看文件内容。它可以一次性显示整个文件,或者分页显示。此外,cat 还可以用于合并多个文件的内容…...

iOS ReactiveCocoa MVVM
学习了在MVVM中如何使用RactiveCocoa,简单的写上一个demo。重点在于如何在MVVM各层之间使用RAC的信号来更方便的在各个层之间进行响应式数据交互。 demo需求:一个登录界面(登录界面只有账号和密码都有输入,登录按钮才可以点击操作)࿰…...

图文解析ASN.1中BER编码:结构类型、编码方法、编码实例
本文将详细介绍ASN.1中的BER编码规则,包括其编码机制、数据类型表示、以及如何将复杂的数据结构转换为二进制数据。通过本文的阅读,读者将对ASN.1中的BER编码有一个全面的理解。 目录 一.引言 二.BER编码基本结构 ▐ 1. 类型域(Type&#…...

jQuery如何停止动画队列
在jQuery中,你可以使用.stop()方法来停止动画队列。.stop()方法有几个可选的参数,可以用来控制停止动画的方式。 以下是.stop()方法的基本用法和一些参数选项: 无参数:立即停止当前动画,并跳到最后的状态。后续的动画…...

vue3+electron搭建桌面软件
vue3electron开发桌面软件 最近有个小项目, 客户希望像打开 网易云音乐 那么简单的运行起来系统. 前端用 Vue 会比较快一些, 因此决定使用 electron 结合 Vue3 的方式来完成该项目. 然而, 在实施过程中发现没有完整的博客能够记录从创建到打包的流程, 摸索一番之后, 随即梳理…...

oracle常用经典SQL查询
oracle常用经典SQL查询(转贴) oracle常用经典SQL查询 常用SQL查询: 1、查看表空间的名称及大小 select t.tablespace_name, round(sum(bytes/(1024*1024)),0) ts_size from dba_tablespaces t, dba_data_files d where t.tablespace_name d.tablespace_name grou…...

Android shell 常用 debug 命令
目录 1、查看版本2、am 命令3、pm 命令4、dumpsys 命令5、sed命令6、log定位查看APK进程号7、log定位使用场景 1、查看版本 1.1、Android串口终端执行 getprop ro.build.version.release #获取Android版本 uname -a #查看linux内核版本信息 uname -r #单独查看内核版本 1.2、…...

Unity3D Shader数据传递语法详解
在Unity3D中,Shader是用于渲染图形的一种程序,它定义了物体在屏幕上的外观。Shader通过接收输入数据(如顶点位置、纹理坐标、光照信息等)并计算像素颜色来工作。为了使得Shader能够正确运行并产生期望的视觉效果,我们需…...

计算机组成原理(五)
一、链式查询方式 接口的优先级固定不变 在链式查询的情况下,设备的优先级通常与其在链中的位置有关。具体来说,越靠近查询链的起始位置的设备通常具有较高的优先级,而越靠近链的末尾位置的设备优先级较低。 优点: 简单实现&am…...
后端项目实战--瑞吉外卖项目软件说明书
瑞吉外卖项目软件说明书 一、项目概述 瑞吉外卖项目是一个外卖服务平台,用户可以通过该平台浏览餐厅菜单、下单、支付以及追踪订单状态。产品原型就是一款产品成型之前的一个简单的框架,就是将页面的排版布局展现出来,使产品得初步构思有一…...
LeetCode | 27.移除元素
这道题的思路和26题一模一样,由于要在元素组中修改,我们可以设置一个index表示目前要修改原数组的第几位,由于遍历,访问原数组永远会在我们修改数组之前,所以不用担心数据丢失的问题,一次遍历数组ÿ…...

为什么要选择AWS?AWS的优势有哪些?
亚马逊云服务器(Amazon Web Services,AWS)是全球领先的云计算服务提供商之一,其提供的云服务器是在全球范围内可用的弹性计算服务。对于很多用户来说,他们可能会担心亚马逊云服务器是否会对服务器的使用进行限制。以下…...

【Intel CVPR 2024】通过图像扩散模型生成高质量360度场景,只需要一个语言模型
在当前人工智能取得突破性进展的时代,从单一输入图像生成全景场景仍是一项关键挑战。大多数现有方法都使用基于扩散的迭代或同步多视角内绘。然而,由于缺乏全局场景布局先验,导致输出结果存在重复对象(如卧室中的多张床࿰…...

postman教程-21-Newman运行集合生成测试报告
上一小节我们Postman Newman的安装方法,本小节我们讲解一下Postman Newman的具体使用方法。 使用Newman运行集合 1、导出Postman集合: 在Postman中,选择你想要运行的集合,然后点击“导出”按钮,选择导出为“Collect…...
基于条件谱矩的时间序列分析(以轴承故障诊断为例,MATLAB)
谱矩方法可以对数据的表面形貌做较为细致的描述.它以随机过程为理论基础,用各阶谱矩及统计不变量等具体的参数表征表面的几何形态,算术平均顶点曲率是一种基于四阶谱矩的统计不变量。 鉴于此,采用条件谱矩方法对滚动轴承进行故障诊…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...
java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流 前情提要文章介绍一、函数伊始1.1 合格的函数1.2 有形的函数2. 函数对象2.1 函数对象——行为参数化2.2 函数对象——延迟执行 二、 函数编程语法1. 函数对象表现形式1.1 Lambda表达式1.2 方法引用(Math::max) 2 函数接口…...