【深度强化学习】(1) DQN 模型解析,附Pytorch完整代码
大家好,今天和各位讲解一下深度强化学习中的基础模型 DQN,配合 OpenAI 的 gym 环境,训练模型完成一个小游戏,完整代码可以从我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 算法原理
1.1 基本原理
DQN(Deep Q Network)算法由 DeepMind 团队提出,是深度神经网络和 Q-Learning 算法相结合的一种基于价值的深度强化学习算法。
Q-Learning 算法构建了一个状态-动作值的 Q 表,其维度为 (s,a),其中 s 是状态的数量,a 是动作的数量,根本上是 Q 表将状态和动作映射到 Q 值。此算法适用于状态数量能够计算的场景。但是在实际场景中,状态的数量可能很大,这使得构建 Q 表难以解决。为破除这一限制,我们使用 Q 函数来代替 Q 表的作用,后者将状态和动作映射到 Q 值的结果相同。
由于神经网络擅长对复杂函数进行建模,因此我们用其当作函数近似器来估计此 Q 函数,这就是 Deep Q Networks。此网络将状态映射到可从该状态执行的所有动作的 Q 值。即只要输入一个状态,网络就会输出当前可执行的所有动作分别对应的 Q 值。如下图所示,它学习网络的权重,以此输出最佳 Q 值。
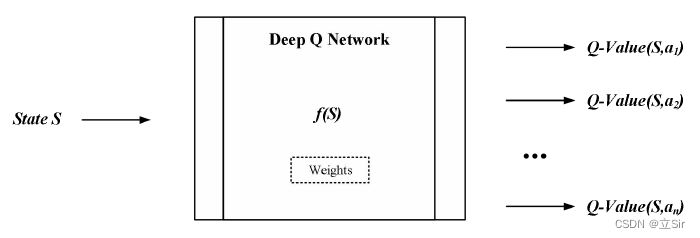
1.2 模型结构
DQN 体系结构主要包含:Q 网络、目标网络,以及经验回放组件。.Q 网络是经过训练以生成最佳状态-动作值的 agent。经验回放单元的作用是与环境交互,生成数据以训练 Q 网络。目标网络与 Q 网络在初始时是完全相同的。DQN 工作流程图如下
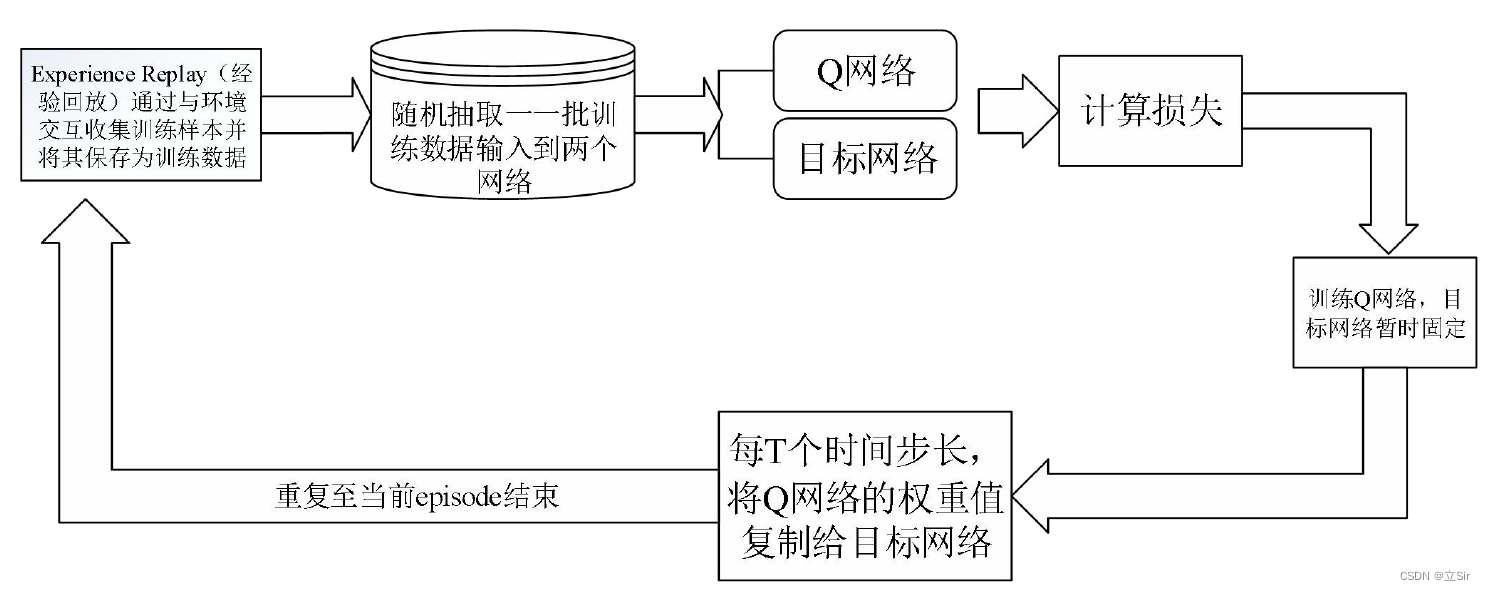
1.2.1 经验回放
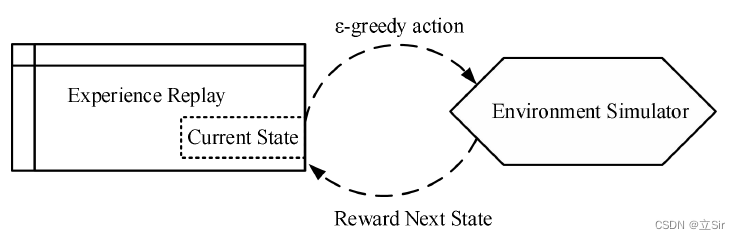
经验回放从当前状态中以贪婪策略 选择一个动作,执行后从环境中获得奖励和下一步的状态,如下图所示。
然后将此观测值另存为用于训练数据的样本,如下图所示。
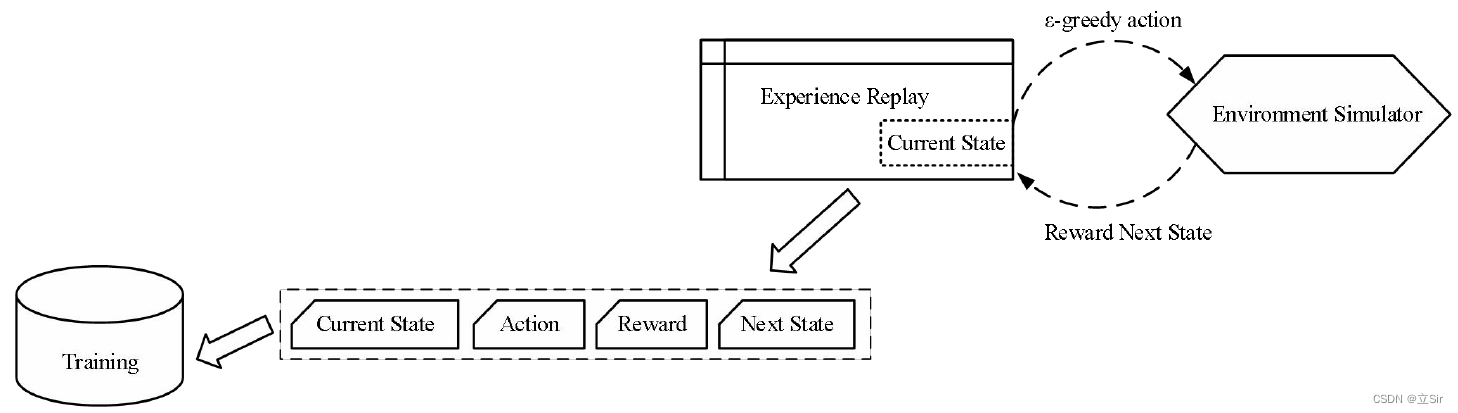
与 Q Learning 算法不同,经验回放组件的存在有其必须性。神经网络通常接受一批数据,如果我们用单个样本去训练它,每个样本和相应的梯度将具有很大的方差,并且会导致网络权重永远不会收敛。
当我们训练神经网络时,最好的做法是在随机打乱的训练数据中选择一批样本。这确保了训练数据有足够的多样性,使网络能够学习有意义的权重,这些权重可以很好地泛化并且可以处理一系列数据值。如果我们以顺序动作传递一批数据,则不会达到此效果。
所以可得出结论:顺序操作彼此高度相关,并且不会像网络所希望的那样随机洗牌。这导致了一个 “灾难性遗忘” 的问题,网络忘记了它不久前学到的东西。
以上是引入经验回放组件的原因。智能体在内存容量范围内从一开始就执行的所有动作和观察都将被存储。然后从此存储器中随机选择一批样本。这确保了批次是经过打乱,并且包含来自旧样品和较新样品的足够多样性,这样能保证训练过的网络具有能处理所有场景的权重。
# --------------------------------------- #
# 经验回放池
# --------------------------------------- #class ReplayBuffer():def __init__(self, capacity):# 创建一个先进先出的队列,最大长度为capacity,保证经验池的样本量不变self.buffer = collections.deque(maxlen=capacity)# 将数据以元组形式添加进经验池def add(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))# 随机采样batch_size行数据def sample(self, batch_size):transitions = random.sample(self.buffer, batch_size) # list, len=32# *transitions代表取出列表中的值,即32项state, action, reward, next_state, done = zip(*transitions)return np.array(state), action, reward, np.array(next_state), done# 目前队列长度def size(self):return len(self.buffer)1.2.2 Q 网络预测 Q 值
所有之前的经验回放都将保存为训练数据。现在从此训练数据中随机抽取一批样本,以便它包含较旧样本和较新样本的混合。随后将这批训练数据输入到两个网络。Q 网络从每个数据样本中获取当前状态和操作,并预测该特定操作的 Q 值,这是“预测 Q 值”。如下图所示。

1.2.3 目标网络预测目标 Q 值
目标网络从每个数据样本中获取下一个状态,并可以从该状态执行的所有操作中预测最佳 Q 值,这是“目标 Q 值”。如下图所示。
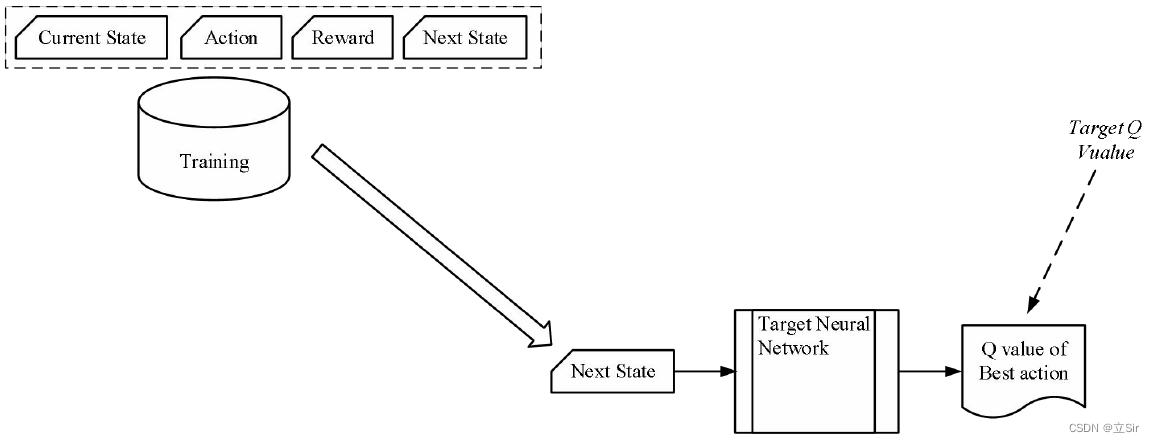
DQN 同时用到两个结构相同参数不同的神经网络,区别是一个用于训练,另一个不会在短期内得到训练,这样设置是从考虑实际效果出发的必然需求。
如果构建具有单个 Q 网络且不存在目标网络的 DQN,假设此网络应该如下工作:通过 Q 网络执行两次传递,首先输出 “预测 Q 值”,然后输出 “目标 Q 值”。这可能会产生一个潜在的问题:Q 网络的权重在每个时间步长都会更新,从而改进了对“预测 Q 值”的预测。但是,由于网络及其权重相同,因此它也改变了我们预测的“目标 Q 值”的方向。它们不会保持稳定,在每次更新后可能会波动,类似一直追逐一个移动着的目标。
通过采用第二个未经训练的网络,可以确保 “目标 Q 值” 至少在短时间内保持稳定。但这些“目标 Q 值”毕竟只是预测值,这是为改善它们的数值做出的妥协。所以在经过预先配置的时间步长后,需将 Q 网络中更新的权重复制到目标网络。
可以得出,使用目标网络可以带来更稳定的训练。
1.2.2 和 1.2.3 代码对应如下:
# -------------------------------------- #
# 构造深度学习网络,输入状态s,得到各个动作的reward
# -------------------------------------- #class Net(nn.Module):# 构造只有一个隐含层的网络def __init__(self, n_states, n_hidden, n_actions):super(Net, self).__init__()# [b,n_states]-->[b,n_hidden]self.fc1 = nn.Linear(n_states, n_hidden)# [b,n_hidden]-->[b,n_actions]self.fc2 = nn.Linear(n_hidden, n_actions)# 前传def forward(self, x): # [b,n_states]x = self.fc1(x)x = self.fc2(x)return x# -------------------------------------- #
# 构造深度强化学习模型
# -------------------------------------- #class DQN:#(1)初始化def __init__(self, n_states, n_hidden, n_actions,learning_rate, gamma, epsilon,target_update, device):# 属性分配self.n_states = n_states # 状态的特征数self.n_hidden = n_hidden # 隐含层个数self.n_actions = n_actions # 动作数self.learning_rate = learning_rate # 训练时的学习率self.gamma = gamma # 折扣因子,对下一状态的回报的缩放self.epsilon = epsilon # 贪婪策略,有1-epsilon的概率探索self.target_update = target_update # 目标网络的参数的更新频率self.device = device # 在GPU计算# 计数器,记录迭代次数self.count = 0# 构建2个神经网络,相同的结构,不同的参数# 实例化训练网络 [b,4]-->[b,2] 输出动作对应的奖励self.q_net = Net(self.n_states, self.n_hidden, self.n_actions)# 实例化目标网络self.target_q_net = Net(self.n_states, self.n_hidden, self.n_actions)# 优化器,更新训练网络的参数self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=self.learning_rate)#(3)网络训练def update(self, transition_dict): # 传入经验池中的batch个样本# 获取当前时刻的状态 array_shape=[b,4]states = torch.tensor(transition_dict['states'], dtype=torch.float)# 获取当前时刻采取的动作 tuple_shape=[b],维度扩充 [b,1]actions = torch.tensor(transition_dict['actions']).view(-1,1)# 当前状态下采取动作后得到的奖励 tuple=[b],维度扩充 [b,1]rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1)# 下一时刻的状态 array_shape=[b,4]next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float)# 是否到达目标 tuple_shape=[b],维度变换[b,1]dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1)# 输入当前状态,得到采取各运动得到的奖励 [b,4]==>[b,2]==>[b,1]# 根据actions索引在训练网络的输出的第1维度上获取对应索引的q值(state_value)q_values = self.q_net(states).gather(1, actions) # [b,1]# 下一时刻的状态[b,4]-->目标网络输出下一时刻对应的动作q值[b,2]--># 选出下个状态采取的动作中最大的q值[b]-->维度调整[b,1]max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1,1)# 目标网络输出的当前状态的q(state_value):即时奖励+折扣因子*下个时刻的最大回报q_targets = rewards + self.gamma * max_next_q_values * (1-dones)# 目标网络和训练网络之间的均方误差损失dqn_loss = torch.mean(F.mse_loss(q_values, q_targets))# PyTorch中默认梯度会累积,这里需要显式将梯度置为0self.optimizer.zero_grad()# 反向传播参数更新dqn_loss.backward()# 对训练网络更新self.optimizer.step()# 在一段时间后更新目标网络的参数if self.count % self.target_update == 0:# 将目标网络的参数替换成训练网络的参数self.target_q_net.load_state_dict(self.q_net.state_dict())self.count += 1
DQN 模型伪代码:

2. 实例演示
接下来我们用 GYM 库中的车杆稳定小游戏来验证一下我们构建好的 DQN 模型,导入最基本的库,设置参数。有关 GYM 强化学习环境的内容可以查看官方文档:
https://www.gymlibrary.dev/#

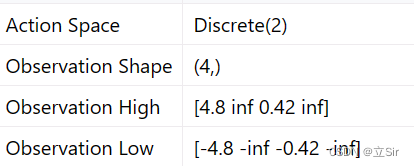
环境的状态 state 包含四个:位置、速度、角度、角速度;动作 action 包含 2 个:小车左移和右移;目的是保证杆子竖直。环境交互与模型训练如下:
import gym
from RL_DQN import DQN, ReplayBuffer
import torch
from tqdm import tqdm
import matplotlib.pyplot as plt# GPU运算
device = torch.device("cuda") if torch.cuda.is_available() \else torch.device("cpu")# ------------------------------- #
# 全局变量
# ------------------------------- #capacity = 500 # 经验池容量
lr = 2e-3 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.9 # 贪心系数
target_update = 200 # 目标网络的参数的更新频率
batch_size = 32
n_hidden = 128 # 隐含层神经元个数
min_size = 200 # 经验池超过200后再训练
return_list = [] # 记录每个回合的回报# 加载环境
env = gym.make("CartPole-v1", render_mode="human")
n_states = env.observation_space.shape[0] # 4
n_actions = env.action_space.n # 2# 实例化经验池
replay_buffer = ReplayBuffer(capacity)
# 实例化DQN
agent = DQN(n_states=n_states,n_hidden=n_hidden,n_actions=n_actions,learning_rate=lr,gamma=gamma,epsilon=epsilon,target_update=target_update,device=device,)# 训练模型
for i in range(500): # 100回合# 每个回合开始前重置环境state = env.reset()[0] # len=4# 记录每个回合的回报episode_return = 0done = False# 打印训练进度,一共10回合with tqdm(total=10, desc='Iteration %d' % i) as pbar:while True:# 获取当前状态下需要采取的动作action = agent.take_action(state)# 更新环境next_state, reward, done, _, _ = env.step(action)# 添加经验池replay_buffer.add(state, action, reward, next_state, done)# 更新当前状态state = next_state# 更新回合回报episode_return += reward# 当经验池超过一定数量后,训练网络if replay_buffer.size() > min_size:# 从经验池中随机抽样作为训练集s, a, r, ns, d = replay_buffer.sample(batch_size)# 构造训练集transition_dict = {'states': s,'actions': a,'next_states': ns,'rewards': r,'dones': d,}# 网络更新agent.update(transition_dict)# 找到目标就结束if done: break# 记录每个回合的回报return_list.append(episode_return)# 更新进度条信息pbar.set_postfix({'return': '%.3f' % return_list[-1]})pbar.update(1)# 绘图
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN Returns')
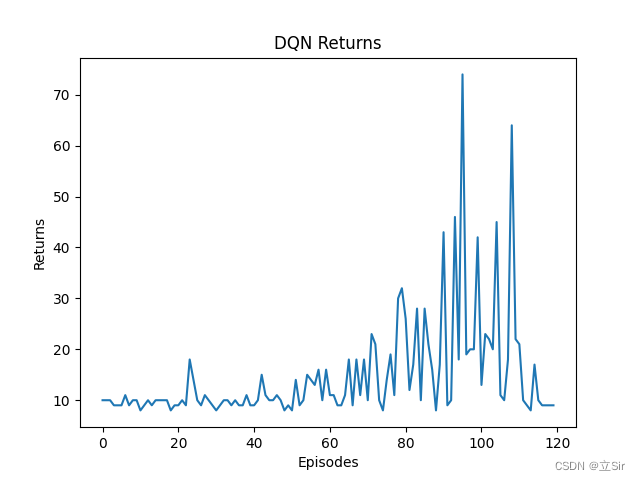
plt.show()我简单训练了100轮,每回合的回报 returns 绘图如下。若各位发现代码有误,请及时反馈。
相关文章:
【深度强化学习】(1) DQN 模型解析,附Pytorch完整代码
大家好,今天和各位讲解一下深度强化学习中的基础模型 DQN,配合 OpenAI 的 gym 环境,训练模型完成一个小游戏,完整代码可以从我的 GitHub 中获得: https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Mod…...

Nginx服务优化与防盗链
目录 1.隐藏nginx版本号 1.查看版本号 2.隐藏版本信息 2.修改用户与组 3.缓存时间 4.日志分割 5.连接超时 6.更改进程数 7.网页压缩 8.配置防盗链 1.配置web源主机(192.168.156.10 www.lhf.com) 2.配置域名映射关系 3.配置盗链主机 ࿰…...

npm与yarn常用命令
npm npm -v:查看 npm 版本npm init:初始化后会出现一个 Package.json 配置文件,可以在后面加上 -y,快速跳到问答界面npm install:会根据项目中的 package.json 文件自动给下载项目中所需的全部依赖npm insall 包含 --…...

【C++】C++11新特性——右值引用
文章目录一、左值引用、 右值引用1.1 左值与右值1.2 左值引用1.3 右值引用二、右值引用的意义三、移动语句3.1 移动构造3.2 移动赋值3.3 总结四、move问题五、完美转发5.1 万能引用与折叠5.2 完美转发std::forward一、左值引用、 右值引用 1.1 左值与右值 我们经常能听到左值…...

C#基础教程21 正则表达式
文章目录 简介正则表达式语法字符集元字符转义字符量词贪婪匹配和非贪婪匹配正则表达式类Regex类Match方法Matches方法简介 正则表达式是一种描述字符串模式的语言,它可以用来匹配、查找、替换字符串中的模式。在C#中,我们可以使用System.Text.RegularExpressions命名空间下的…...

聚观早报|谷歌发布最大视觉语言模型;王兴投资王慧文ChatGPT项目
今日要闻:谷歌发布全球最大视觉语言模型;马斯克预计Twitter下季度现金流转正;王兴投资王慧文ChatGPT项目;美国拟明年 11 月开展载人绕月飞行;慧与科技宣布收购Athonet谷歌发布全球最大视觉语言模型 近日,来…...
java Spring5 xml配置文件方式实现声明式事务
在java Spring5通过声明式事务(注解方式)完成一个简单的事务操作中 我们通过注解方式完成了一个事务操作 那么 下面 我还是讲一下 基于xml实现声明式事务的操作 其实在开发过程中 大家肯定都喜欢用注解 因为他方便 这篇文章中的xml方式 大家做个了解就好 还是 我们的这张表 记…...
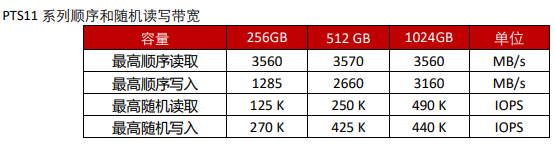
常用存储芯片-笔记本上固态硬盘PTS11系列推荐
在存储领域中,除了存储颗粒之外,还有一种极其重要的芯片:存储控制芯片。存储控制芯片是CPU与存储器之间数据交换的中介,决定了存储器最大容量、存取速度等多个重要参数。特别是在AI、5G、自动驾驶时代,对于数据处理及存…...
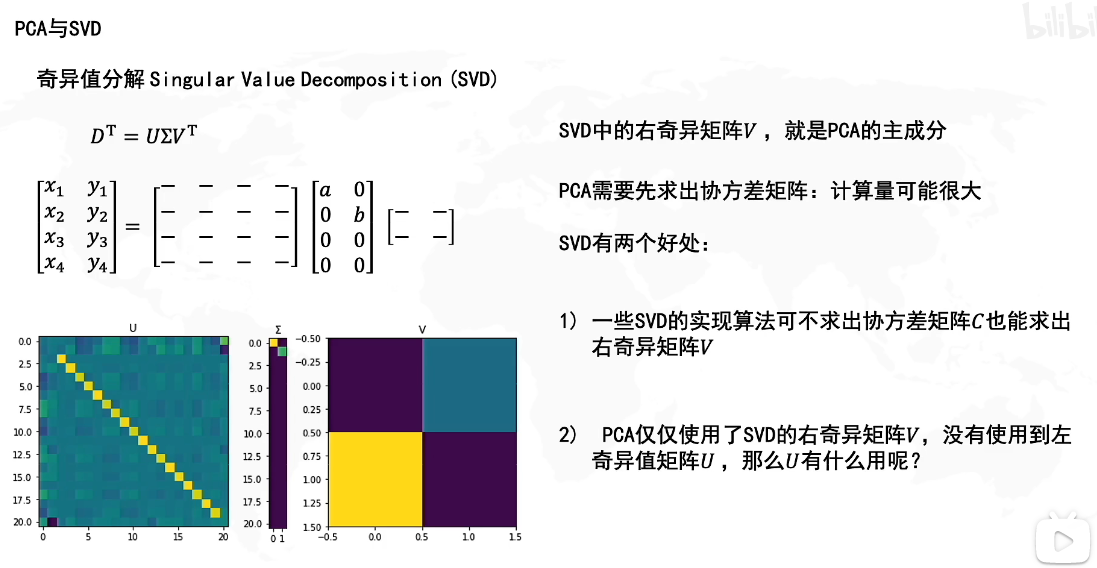
【AI绘图学习笔记】奇异值分解(SVD)、主成分分析(PCA)
这节的内容需要一些线性代数基础知识,如果你没听懂本文在讲什么,强烈建议你学习【官方双语/合集】线性代数的本质 - 系列合集 文章目录奇异值分解线性变换特征值和特征向量的几何意义什么是奇异值分解?公式推导SVD推广到任意大小矩阵如何求SV…...

【设计模式】模板方法模式和门面模式
模板方法模式和门面模式模板方法模式代码示例门面模式代码示例门面模式的应用场景模板方法模式 模板方法模式非常简单,就是定义了一个固定的公共流程,整个流程有哪些步骤是事先定义好的,具体的步骤则交由子类去实现。属于行为型设计模式。 简…...

Kubernetes未来十年的四大发展趋势
作者:李翔 跟大家已经感受到的一样,Kubernetes已经成为了云计算领域最具统治力的平台,成为了云原生开发的绝对标准,而伴随Kubernetes诞生的CNCF (Cloud Native Computing Foundation) 也因此成为了业界影响力巨大的组织。在成为云…...

一、sql 基础知识、函数和子查询
MySQL 是一种流行的关系型数据库管理系统,使用 SQL 语言进行数据管理和操作。在 MySQL 中,常用的语句包括 SELECT 查询语句、WHERE 条件语句、算术表达式、函数、聚合函数、自定义函数、逻辑表达式、子查询和连接。这些语句可以帮助用户快速地进行数据查…...

产品射频认证笔记
文章目录1. 射频监管认证的目的:1.1 确保 RF 产品在其预期环境中按预期运行1.2 确保射频产品不会干扰其他电子或射频设备2. 射频认证地区规范3. FCC简介4. FCC认证需要准备的内容:5. 射频监管测量会话期间测量以下射频属性:6. 调整射频参数6.…...
做了个springboot接口参数解密的工具,我给它命名为万能钥匙(已上传maven中央仓库,附详细使用说明)
前言:之前工作中做过两个功能,就是之前写的这两篇博客,最近几天有个想法,给它做成一个springboot的start启动器,直接引入依赖,写好配置就能用了 springboot使用自定义注解实现接口参数解密,普通…...

【Flutter从入门到入坑】Flutter 知识体系
学习 Flutter 需要掌握哪些知识? 终端设备越来越碎片化,需要支持的操作系统越来越多,从研发效率和维护成本综合考虑,跨平台开发一定是未来大前端的趋势,我们应该拥抱变化。而 Flutter 提供了一套彻底的移动跨平台方案…...

顺序表的基本操作
目录 一.什么是顺序表 二.顺序表的基本操作 1.初始化 2.增容 3.尾插 4.头插 5.尾删 6.头删 7.指定位置插入 8.指定位置删除 9.打印 10.查找 11.销毁 一.什么是顺序表 顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组…...
设计模式——创建型模型——单列模式(8种实现)
前言: 👏作者简介:我是笑霸final,一名热爱技术的在校学生。 📝个人主页:个人主页1 || 笑霸final的主页2 📕系列专栏:计算机基础专栏 📧如果文章知识点有错误的地方&#…...

【软考中级】软件设计师笔记
计算机系统的性能一般包括两个方面:一方面是它的可用性,也就是计算机系统能正常工作的时间,其指标可以是能够持续工作的时间长度,也可以是在一段时间内,能正常工作的时间所占的百分比 另一方面是处理能力,又…...

包教包会的ES6
自学参考:http://es6.ruanyifeng.com/ 一、ECMAScript 6 简介 ECMAScript 6.0(以下简称 ES6)是 JavaScript 语言的下一代标准,已经在 2015 年 6 月正式发布了。它的目标,是使得 JavaScript 语言可以用来编写复杂的大…...
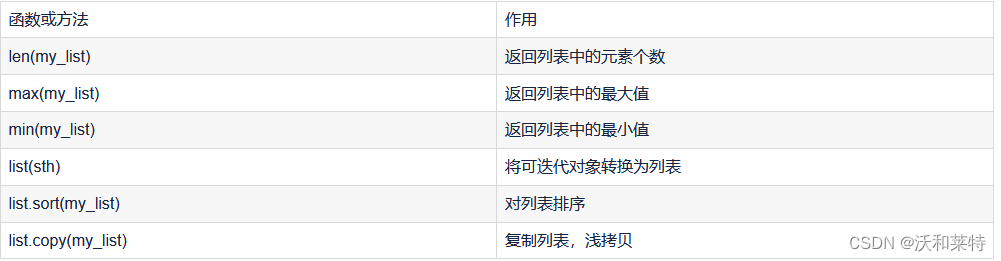
python学习——【第四弹】
前言 上一篇文章 python学习——【第三弹】 中学习了python中的流程控制语句,这篇文章我们接着学习python中的序列。先给大家介绍不可变序列 字符串和可变序列 列表,下一篇文章接着补充元组,集合和字典。 序列 指的是一块可以存放多个值的…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...