Fluid 1.0 版发布,打通云原生高效数据使用的“最后一公里”
作者:顾荣
前言
得益于云原生技术在资源成本集约、部署运维便捷、算力弹性灵活方面的优势,越来越多企业和开发者将数据密集型应用,特别是 AI 和大数据领域应用,运行于云原生环境中。然而,云原生计算与存储分离架构虽然带来了资源经济性与扩容灵活性方面的优势,但也引入了数据访问延迟高、带宽开销大等方面的使用问题。
在数据访问接口层面,Kubernetes 只提供了传统数据访问接入层面的接口,即异构存储服务接入和管理标准接口(CSI,Container Storage Interface),对应用如何在容器集群中高效使用和灵活管理数据并没有定义。然而,这是很多数据密集型应用依赖这样的高层数据访问和管理接口,例如:在运行 AI 模型训练任务时,数据科学家需要能够管理数据集版本、控制访问权限、数据集预处理、动态数据源更新、加速异构数据读取等。但是,在 Fluid 开源项目诞生之前,Kubernetes 开源生态社区中还没有这样的标准方案,这是云原生环境拥抱大数据与 AI 应用的一块重要拼图。
为了应对这些挑战,由来自学术界的南京大学,工业界的阿里云团队和 Alluxio 开源社区共同发起了 Fluid 开源项目,通过对“计算任务使用数据的过程”进行抽象,提出了云原生弹性数据抽象概念(如:DataSet),并作为“一等公民”在 Kubernetes 中实现。围绕弹性数据集 Dataset,我们创建了云原生数据编排与加速系统 Fluid,来实现 Dataset 管理(CRUD 操作)、权限控制和访问加速等能力。在 2021 年 4 月份进入云原生计算基金会(CNCF)之后,经过 36 个月的不断研发迭代和生产环境验证,现在正式发布了其成熟稳定的 v1.0 大版本。
Fluid 开源项目网站:
https://fluid-cloudnative.github.io/
Fluid 项目 Github 开源 repo:
https://github.com/fluid-cloudnative/fluid
开源驱动发展,生产环境验证
Fluid 的测试体系涵盖了每日进行的单元测试、功能测试、兼容性测试、安全测试以及实际应用场景测试。每次版本发布前,Fluid 会在不同的 Kubernetes 版本中进行兼容性测试。
Fluid 技术源自校企科研合作,项目正式开源后,吸引了来自不同行业,不同规模的社区用户将 Fluid 应用到更广泛的场景中:AIGC,大模型,大数据,混合云,云上开发机管理,自动驾驶数据仿真等。Fluid 在支撑云上真实应用中不断迭代改进,并应用到生产环境中,系统的稳定性,性能和规模也变得成熟。
据公有云和私有云环境的统计,目前已有上千个 Kubernetes 集群在持续使用 Fluid,其中在用户机器学习平台可以支持最大上万节点规模。每天在云原生环境中创建 Fluid 的用户主要来自互联网、科技、金融、电信、教育、自动驾驶与机器人、智能制造等领域。Fluid 开源社区用户包括有小米、阿里巴巴集团、阿里云 PAI 机器学习平台、中国电信、微博、B 站、360、乾象、作业帮、赢彻、虎牙、Oppo、云知声、云刻行、深势科技等。更多使用信息请查看注册用户列表。
部分用户也在 Fluid 开源社区分享了他们在不同场景的实践:
- 小米机器学习平台:基于 Fluid 的高效 Serverless 混合云容器 AI 平台 [ 1]
- 从资源弹性到数据弹性,乾象如何将云上量化研究效率提升 40%?
- 深势科技基于 Serverless 容器为科研人员打造高效的开发平台
- 阿里集团基于 Fluid+JindoCache 加速大模型训练的实践
- 作业帮检索服务基于 Fluid 的计算存储分离实践 [ 2]
Fluid 1.0 新增核心功能速览
Fluid v1.0 的发布,带来了以下几项核心功能:
1. 可灵活配置的多级数据亲和性调度机制
Fluid 的多级数据亲和性调度能力允许用户根据数据集缓存的位置信息对任务进行调度,而无需深入了解底层数据缓存的具体排布。Fluid 通过以下方式实现这一调度策略:
a. 数据缓存本地性级别: Fluid 根据数据缓存的本地性,即数据与计算任务的距离,将数据访问划分为不同的级别。这可能包括同一个节点(Node)、机架(Rack)、可用区(Availability Zone)、区域(Region)等不同级别。
b. 优先调度策略: Fluid 优先将计算任务调度到数据缓存所在的节点,实现最佳的数据本地性。如果无法实现最佳本地性,Fluid 会根据数据的传输距离,将任务调度到不同级别的节点上。
c. 灵活配置性: 考虑到不同云服务提供商和对亲和性定义的各不相同,Fluid 支持基于 label 进行自定义配置。用户可以根据具体的云环境和集群配置,调整调度策略,以适应不同的需求。
功能详见:Fluid 支持分层数据缓存本地性调度(Tiered Locality Scheduling) [ 3]

2. 增加自定义数据操作 DataProcess 和触发策略的丰富
Fluid 负责在 Kubernetes 中编排数据和使用数据的计算任务,不仅包括上文提到的空间上的编排,也包括时间上的编排。空间上的编排意味着计算任务会优先调度到有缓存数据和临近缓存的节点上,这样能够提升数据密集型应用的性能。而时间上的编排则允许同时提交数据操作和任务,但在任务执行之前,要进行一些数据迁移和预热操作,以确保任务在无人值守的情况下顺利运行,提升工程效率。
为此,在最新版本的 Fluid 里提供一种新的数据操作类型 DataProcess,为数据科学家提供自定义数据处理逻辑的抽象;并且在此基础针对所有的 Fluid 数据操作提供不同的触发机制,包括:once, onEvent, Cron。
以下例子为每 2 分钟运行一次数据预热。
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:name: cron-dataload
spec:dataset:name: demonamespace: defaultpolicy: Cronschedule: "*/2 * * * *" # Run every 2 min
3. 数据流 DataFlow
进一步地,Fluid 提供 DataFlow 数据流功能,允许用户通过 Fluid 提供的 API 定义自动化的数据处理流程:DataFlow 支持 Fluid 的全部数据操作,包括缓存预热(DataLoad),数据迁移(DataMigrate),数据备份(DataBackup)等面向运维侧人员的自动化数据操作和面向数据科学家的数据处理(DataProcess)相结合,实现简单的数据操作。
以该图为例,整个的顺序是:
a. 将需要消费的数据从云上低速存储(例如:OSS、HDFS)迁移到高速存储(例如:JuiceFS,GPFS)
b. 启动 AI 模型训练
c. AI 模型训练完成后将数据迁移回低速存储

注:DataFlow 数据流仅支持串联多个数据操作,根据定义的先后顺序一个一个执行。不支持多步骤并行执行、循环执行、按条件选择性执行等高级语义, 如果用户有明确此类需求,推荐使用 Argo Workflow 或者 Tekton。
4. 通过 Python SDK 使用 Fluid
在实践中,我们发现数据科学家更倾向于应该用代码(Python)而不是 YAML 来定义。为此 Fluid 提供更高层次的 Python 接口来简化数据集的自动化操作和数据流的编写,下面是上面流程的 Python 实现:
flow = dataset.migrate(path="/data/", \migrate_direction=constants.DATA_MIGRATE_DIRECTION_FROM) \.load("/data/1.txt") \.process(processor=create_processor(train)) \.migrate(path="/data/", \migrate_direction=constants.DATA_MIGRATE_DIRECTION_TO) run = flow.run()
样例详见以下链接:https://github.com/fluid-cloudnative/fluid-client-python/blob/master/examples/02_ml_train_pipeline/pipeline.ipynb
5. 新增 Vineyard 对象缓存引擎支持
Fluid 支持以插件的方式接入分布式缓存,目前已经支持 Alluixo, JindoFS, JuiceFS 等针对文件系统的分布式缓存引擎。在 Fluid 1.0 版本接入了分布式内存数据管理引擎 Vineyard,结合了 Vineyard 的高效数据共享机制和 Fluid 的数据任务编排能力,为数据科学家提供了以 Python 作为操作接口的方式,让他们能以熟悉的方式高效地进行 Kubernetes 上的中间数据管理。

更多细节请查看:Fluid 携手 Vineyard,打造 Kubernetes 上的高效中间数据管理
6. 更多其他更新
在生产环境使用开源软件,稳定,规模和安全一直是重中之重。因此这也是 Fluid 持续关注和加强的领域。
a. 服务于大规模 Kubernetes 场景
在大规模的 Kubernetes 生产环境中,Fluid 的性能和扩展性已得到了很好验证。在真实的用户环境中,Fluid 能够稳定地支持有超过一万个节点的集群。在每天 24 小时的运行周期内,Fluid 负责处理超过 2500 个数据集的全生命周期管理和超过 6000 个通过 Fluid 挂载数据集访问数据的 AI 工作负载(总共约有 12 万个 Pods)。
考虑到 Fluid 已被广泛地部署在几个大规模的生产级 Kubernetes 集群中,我们对 Fluid 的控制平面组件进行了压力测试。测试结果显示,Fluid 的 Webhook 在 3 个副本的情况下能够以每秒 125 个请求(QPS)的速度处理 Pods 的调度请求,而 Webhook 处理请求的 90% 的延迟少于 25 毫秒。针对于 Fluid 的控制器,测试结果表明,每分钟能支持配置 500 个 Fluid 数据集以上的自定义资源。以上结果充分证明了 Fluid 可以满足规模化集群的使用场景。
b. FUSE 挂载点自动恢复增强的生产可用
在大规模的模型训练和推理任务场景下,FUSE 进程可能因为内存资源不足以及其他原因崩溃重启,造成业务容器内 FUSE 挂载点断联,出现数据访问异常并影响在线业务可用性。基于 FUSE 的存储客户端更容易发生这样的问题,一旦这些问题无法自动修复,则可能中断任务和服务,同时人工修复的复杂度和工作量也是巨大的。针对此问题,Fluid 1.0 优化了自恢复机制,并且已经在多个规模化用户场景下上线。
c. 收敛 Fluid 组件的安全权限
在 1.0 版本中,为了实践“权限最小化”的原则,Fluid 移除了不必要的 RBAC 资源访问和权限。
更多的更新可以查看:https://github.com/fluid-cloudnative/fluid/releases/tag/v1.0.0
后续版本规划
帮助 AI/大数据的用户在 Kubernetes 中更加高效、灵活、经济、安全地使用数据,这是 Fluid 开源项目的目标和愿景:
在 1.0 版本,Fluid 进一步打破了数据和计算的壁垒,实现了用户可以从异构 Kubernetes 环境(包括 runC 和 KataContainer)灵活使用异构数据源(对象存储,传统分布式存储,可编程的内存对象), 同时通过 Alluxio,JuiceFS,JindoFS,Vineyard 等多种分布式缓存引擎和数据亲和性调度提升应用访问数据的效率。
在未来版本中, Fluid 会继续与 Kubernetes 云原生生态紧密结合,同时更加关注数据科学家的效率和体验,我们计划专注解决以下问题:
-
针对大模型推理场景的优化,面向多种场景提升大模型加载效率。
-
与 Kubernetes 调度器相结合,自适应地实现根据 Kubernetes 调度器的调度结果,选择合适的数据访问方式(CSI 模式和 sidecar 模式的自动识别)。
-
除了面向运行环境,支持数据科学家在使用开发环境中更灵活地使用 Fluid,例如:解决数据源变更带来的容器重新启动,易造成临时数据丢失方面的问题。
致谢
我们感谢所有为 Fluid 1.0 版本发布付出努力的开源项目贡献者!详细贡献内容和贡献者信息请参见 Fluid 开源项目 1.0 版本 release note:https://github.com/fluid-cloudnative/fluid/releases/tag/v1.0.0
我们感谢 Fluid 开源社区用户给与的开源项目验证反馈和支持!Fluid 开源社区用户公开信息登记列表请参见:https://github.com/fluid-cloudnative/fluid/blob/master/ADOPTERS.md
参考链接:
[1] 小米机器学习平台:基于 Fluid 的高效 Serverless 混合云容器 AI 平台
https://www.infoq.cn/article/kco7hi5TcVE08ySwNIw7
[2] 作业帮检索服务基于 Fluid 的计算存储分离实践
https://www.infoq.cn/article/W65RcTI8AUhmoHVLkzWo?utm_source=tuicool&utm_medium=referral
[3] Fluid 支持分层数据缓存本地性调度(Tiered Locality Scheduling)
https://developer.aliyun.com/article/1382880
点击此处,查看 Fluid 1.0 Release Note!
相关文章:
Fluid 1.0 版发布,打通云原生高效数据使用的“最后一公里”
作者:顾荣 前言 得益于云原生技术在资源成本集约、部署运维便捷、算力弹性灵活方面的优势,越来越多企业和开发者将数据密集型应用,特别是 AI 和大数据领域应用,运行于云原生环境中。然而,云原生计算与存储分离架构虽…...

软件测试--第十一章 设计和维护测试用例
1.单选题 (2分) 下面有关测试设计的叙述,说法不正确的是( )。 A 测试用例的设计是一项技术性强.智力密集型的活动 B 在开展测试用例设计前,必须将测试需求进行详细展开 C 在一般的测试组织内,测试用例的评审可能不是正式的评审会 D 在测试用例设计时,只设计覆盖正常流程和操…...

前端只允许一次函数调用
如果你正在进行前端开发,并且只想允许一次函数调用,你可以使用JavaScript的闭包结构创建一个只能被调用一次的函数。这样的函数有时被称为单次调用函数(“one-time call” functions)或一次性函数(“once” functions&…...

visdom使用时所遇的问题及解决方法
最近在用visdom进行可视化的过程中,虽然可有效的避免主机拒绝访问(该问题的解决方法,请参考深度学习可视化工具visdom使用-CSDN博客)即在终端输入python -m visom.server 1.训练过程中visdom出现ValueError: too many file descr…...
)
密封类(sealed class)
在 Kotlin 中,密封类(sealed class)是一种受限的类层次结构,允许您定义一个封闭的类层次结构,其中类的所有可能子类都已知并且位于同一文件中。密封类的主要作用是提供类型安全的受限层次结构,使得 when 表…...
私域引流宝PHP源码 以及搭建教程
私域引流宝PHP源码 以及搭建教程...
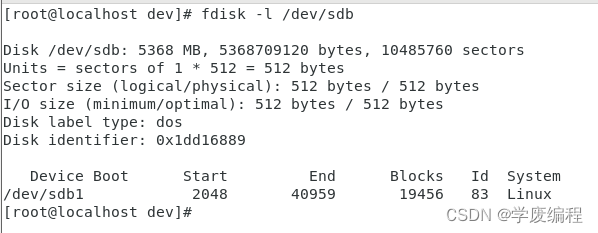
磁盘管理 以及磁盘的分区 详细版
磁盘管理 track:磁道,就是磁盘上同心圆,从外向里,依次1号、2号磁道sector:扇区,将磁盘分成一个一个扇形区域,每个扇区大小是512字节,从外向里,依次是1号扇区、2号扇区cylinder&…...

加码多肤色影像技术 这是传音找到的“出海利器“?
全球化时代,市场竞争愈演愈烈,产品差异化已然成为了企业脱颖而出的关键。在黄、白肤色长期占据人像摄影主赛道的背景下,传音就凭借独一无二的多肤色影像技术走出非洲,走向了更广阔的新兴市场。 聚焦深肤色人群拍照痛点,…...

C++方法封装成dll及C#调用示例
1,编译生成dll时可能出现错误,解决办法:pch.h文件头部,添加声明 #define _CRT_SECURE_NO_WARNINGS 2, c头文件声明 extern "C" __declspec(dllexport) char* getvalue(const char * param1, const char * param2); 3, c方法实现…...

定时清理Linux服务器缓存shell脚本
服务器内存占用过高,如何定时清理一下服务器内存呢?写一个清理缓存脚本,加入到定时任务中。 一、编写脚本 clear_cache.sh 脚本,放到home目录下。 #!/bin/bash# 清除页面缓存、目录项和 inode 缓存 sudo sync echo 3 | sudo tee /proc/sys/vm/drop_caches# 记录执行时间到日…...

Guava常用方法
目录 一、数学和数值操作 二、并发库 三、缓存 四、集合 五、I/O 与文件操作 六、网络 七、时间处理 八、事件总线 九、反射 十、范围和集合操作 十一、随机数和测试 十二、注解处理 十三、比较器和排序 十四、哈希和散列 Guava 是 Google 开源的一个 Java 工具库ÿ…...

干货分享:宏集物联网HMI通过S7 MPI协议采集西门子400PLC数据
前言 为了实现和西门子PLC的数据交互,宏集物联网HMI集成了S7 PPI、S7 MPI、S7 Optimized、S7 ETH等多个驱动来适配西门子200、300、400、1200、1500、LOGO等系列PLC。 本文主要介绍宏集HMI通过S7 MPI协议采集西门子400PLC数据的操作步骤,其他协议的操作…...
【Web API DOM11】节点操作
目录 一:DOM节点 1 什么是DOM节点 2 DOM节点分类 二:节点查找(元素节点) 1 节点关系 父节点 子节点 兄弟节点 三:增加节点 1 创建节点 2 追加节点 2 案例:渲染数据 案例中核心代码块 样式 四…...

Unity 设置窗口置顶超级详解版
目录 前言 一、user32.dll 1.什么是user32.dll 2.如何使用user32.dll 二、句柄Handle 1.句柄 2.句柄的功能 3.拿句柄的方法 三、窗口置顶 1.窗口置顶的方法 2.参数说明 3.使用方法 四、作者的碎碎念 前言 up依旧挑战全网讲解最详细版本~~ 本篇文章讲解的是unity…...

编程后端:深入探索其所属的行业领域
编程后端:深入探索其所属的行业领域 在数字化浪潮席卷全球的今天,编程后端作为技术领域的重要分支,其所属的行业领域一直备受关注。本文将从四个方面、五个方面、六个方面和七个方面,深入剖析编程后端所属的行业,并揭…...
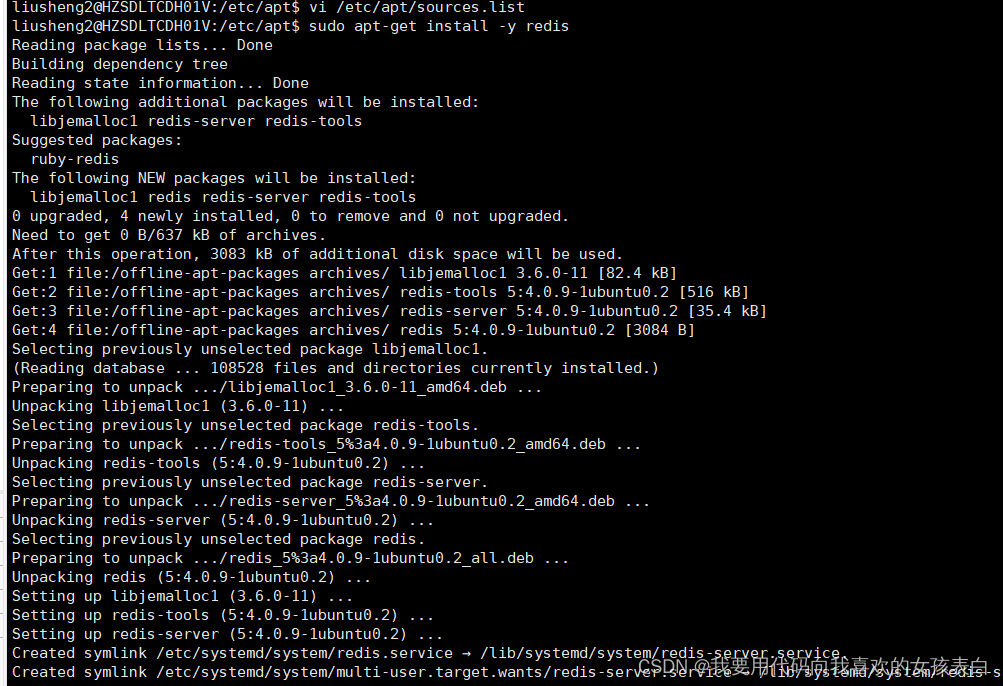
ubuntu18.04离线源制作
给客户部署有时需要纯内网环境,那这样就连不了网络。 一些包就下载不下来,而大家都知道用deb离线安装是非常麻烦的,各种依赖让你装不出来。 这里教大家打包源。 我准备2台机器,42和41 42可以联网,41不能联网。我想在…...

【DPDK学习路径】八、轮询
前面我们已经了解了如何使用DPDK创建线程并绑定核心,以及如何申请内存池并创建 RX/TX 队列。 接下来我们将了解DPDK的核心内容之一:以轮询的方式从网卡中收取报文。 下面直接给出一个实例,此实例使用核心1及核心2创建了两个线程用于报文处理&…...
Mac环境下,简单反编译APK
一、下载jadx包 https://github.com/skylot/jadx/releases/tag/v1.4.7 下载里面的这个:下载后,找个干净的目录解压,我是放在Downloads下面 二、安装及启动 下载和解压 jadx: 下载 jadx-1.4.7.zip 压缩包。将其解压到你希望的目…...

027、工具_redis-benchmark
redis-benchmark可以为Redis做基准性能测试 1.-c -c(clients)选项代表客户端的并发数量(默认是50)。 2.-n -n(num)选项代表客户端请求总量(默认是100000)。 例如redis-benchmark-c100-n20000代表100各个客户端同时请求Redis,一 共执行20000次。 redis-benchmark会…...

京准电钟 | 对比GPS,北斗卫星授时的场景有哪些?
京准电钟 | 对比GPS,北斗卫星授时的场景有哪些? 京准电钟 | 对比GPS,北斗卫星授时的场景有哪些? 对比国外的GPS,我国北斗卫星授时由于其高精度和稳定性,在各个领域都有广泛的应用场景。 以下是一些单北斗卫…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...

【WebSocket】SpringBoot项目中使用WebSocket
1. 导入坐标 如果springboot父工程没有加入websocket的起步依赖,添加它的坐标的时候需要带上版本号。 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId> </dep…...