FastAPI操作关系型数据库
FastAPI可以和任何数据库和任意样式的库配合使用,这里看一下使用SQLAlchemy的示例。下面的示例很容易的调整为PostgreSQL,MySQL,SQLite,Oracle等。当前示例中我们使用SQLite
ORM对象关系映射
FastAPI可以与任何数据库在任何样式的库中一起与数据库进行通信。一种常见的模式就是“ORM”:对象关系映射。所谓对象关系映射就是,ORM具有在代码和数据库表(“关系型”)中的对象中间转换(“映射”)的工具。即使用ORM,在SQL数据库创建一个代表映射的类,该类的每个数据代表数据表中的一个列,具有名称和类型。约定俗成:类使用大写如Pet,代表SQL为表的pets,该累的每个实例对象标识数据库中的一行数据。比如一个对象orion_cat(Pet的一个实例)可以有一个属性orion_cat.type, 对标数据库中的type列。并且该属性的值可以是其它,例如"cat"
文件结构
假设有个fastapi_sqlalchemy的项目,其下有一个包为sql_app,结构如下所示:
fastapi_sqlalchemy
├── sql_app
│ ├── __init__.py
│ ├── crud.py
│ ├── database.py
│ ├── main.py
│ ├── models.py
│ ├── requirements.txt
│ └── schemas.py
└── sql_app.db既然是sql_app包,肯定少不了__init__.py,这里的初始化函数为空。其中依赖requirement.txt中为
fastapi==0.111.0
pydantic==2.7.4
SQLAlchemy==2.0.30
📢📢:这里使用的SQLAlchemy 为2.0以上版本,如果使用v1,则有些语法不同。
创建SQLAlchemy部件
首先看一下sql_app/database.py
创建SQLAlchemy引擎和初始化Base类
# @File : database.py
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmakerSQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
# SQLALCHEMY_DATABASE_URL = "postgresql://user:password@postgresserver/db"# 来允许SQLite这样
engine = create_engine(SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False}
)SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)# 用于建立数据库SQLAlchemy模型models
Base = declarative_base()创建一个SQLAlchemy 引擎,其中connect_args={“check_same_thread”: False} 仅用于SQLite,其他数据库不需要 。
默认情况下,SQLite 只允许一个线程与其通信,假设有多个线程的话,也只将处理一个独立的请求。这是为了防止意外地为不同的事物(不同的请求)共享相同的连接。但是在 FastAPI 中,使用普通函数(def)时,多个线程可以为同一个请求与数据库交互,所以我们需要使用connect_args={“check_same_thread”: False}来让SQLite允许这样。
此外,我们将确保每个请求都在依赖项中获得自己的数据库连接会话,因此不需要该默认机制。
连接到一个SQLite数据库,该文件在当前目录下的sql_app.db中
创建SessionLocal的时候,每个 SessionLocal 的类的实例都是一个数据库会话,当然该类本身还不是数据库会话。但是一旦我们创建了一个SessionLocal类的实例,这个实例将是实际的数据库会话。我们将它命名为SessionLocal是为了将它与我们从 SQLAlchemy 导入的Session区别开来。稍后我们将使用Session(从 SQLAlchemy 导入的那个)。要创建SessionLocal类,请使用函数sessionmaker
Base = declarative_base(),在后面的会继承这个Base类,来创建每个数据库模型或者类(ORM模型)
创建数据库模型models
在文件sql_app/models.py中,使用上一步创建的Base类派生子类来创建SQLAlchemy模型。
📢📢:
- SQLAlchemy中的“模型”指的的是和数据库交互的类和实例
- Pydantic中的“模型”指的是不同的东西,即数据验证、转换以及文档类和实例
# @File : models.pyfrom sql_app.database import Basefrom sqlalchemy import Boolean, Column, ForeignKey, Integer, String
from sqlalchemy.orm import relationshipclass User(Base):__tablename__ = "users"id = Column(Integer, primary_key=True) # primary_key 为True标识主键email = Column(String, unique=True, index=True) # unique 如果为True表示这列不允许出现重复的值,index=True为这列创建索引,提升查询效率hashed_password = Column(String)is_active = Column(Boolean, default=True) # default=True 为这列设置默认值items = relationship("Item", back_populates="owner")class Item(Base):__tablename__ = "items"id = Column(Integer, primary_key=True)title = Column(String, index=True)description = Column(String, index=True)owner_id = Column(Integer, ForeignKey("users.id"))owner = relationship("User", back_populates="items")- 这个__tablename__属性是用来告诉 SQLAlchemy 要在数据库中为每个模型使用的数据库表的名称
- 使用Column来表示 SQLAlchemy 中的默认值。传递一个 SQLAlchemy “类型”,如Integer、String和Boolean,它定义了数据库中的类型,作为参数,以及其他限定。这些属性中的每一个都代表其相应数据库表中的一列
- 关系或者说内联外联的关系,使用
relationship,当访问 user 中的属性items时,如 中my_user.items,它将有一个ItemSQLAlchemy 模型列表(来自items表),这些模型具有指向users表中此记录的外键。当您访问my_user.items时,SQLAlchemy 实际上会从items表中的获取一批记录并在此处填充进去。同样,当访问 Item中的属性owner时,它将包含表中的UserSQLAlchemy 模型users。使用owner_id属性/列及其外键来了解要从users表中获取哪条记录
创建Pydantic模型
接下来看看sql_app/shchemas.py
📢📢:为了避免 SQLAlchemy模型和 Pydantic模型之间的混淆,我们将有models.py(SQLAlchemy 模型的文件)和schemas.py( Pydantic 模型的文件)。这些 Pydantic 模型或多或少地定义了一个“schema”(一个有效的数据形状)。因此,这将帮助我们在使用两者时避免混淆。
创建初始化Pydantic模式/模型
创建一个ItemBase和UserBase Pydantic模型(或者我们说“schema”),他们拥有创建或读取数据时具有的共同属性。然后创建一个继承自他们的ItemCreate和UserCreate,并添加创建时所需的其他数据(或属性)。因此在创建时也应当有一个password属性。但是为了安全起见,password不会出现在其他同类 Pydantic模型中,例如通过API读取一个用户数据时,它不应当包含在内。
# @File : schemas.py
from pydantic import BaseModelclass ItemBase(BaseModel):title: strdescription: str | None = Noneclass UserBase(BaseModel):email: strclass ItemCreate(ItemBase):passclass Item(ItemBase):id: intowner_id: intclass Config:# orm_mode = Truefrom_attributes = Trueclass UserCreate(UserBase):password: strclass User(UserBase):id: intis_active: boolitems: list[Item] = []class Config:# orm_mode = True# 解决pydantic/_internal/_config.py:334: UserWarning: Valid config keys have changed in V2:# * 'orm_mode' has been renamed to 'from_attributes'from_attributes = True先介绍下Config类的作用
class Config:# orm_mode = Truefrom_attributes = True
如果是Pydantic 是v1版本,则使用orm=True, 本机环境安装的是v2+版本。这个类是一个Pydantic配置项。orm_mode或者from_attributes 会告诉Pydantic模型读取数据,而不仅仅是字典,而是一个ORM模型(或者说一个具有属性的对象)。这样,而不是仅仅试图从dict上 id 中获取值,如下所示:
id = data["id"]
它还会尝试从属性中获取它,如:
id = data.id有了这个,Pydantic模型与 ORM 兼容,您只需在路径操作response_model的参数中声明它即可。将能够返回一个数据库模型,它将从中读取数据
📢📢:SQLAlchemy 风格和 Pydantic 风格¶
请注意,SQLAlchemy模型使用 =来定义属性,并将类型作为参数传递给Column,例如:
name = Column(String)
虽然 Pydantic模型使用: 声明类型,但新的类型注释语法/类型提示是:
name: str
请牢记这一点,这样您在使用:还是=时就不会感到困惑
CRUD工具
现在让我们看看文件sql_app/crud.py。在这个文件中,我们将编写可重用的函数用来与数据库中的数据进行交互。
CRUD分别为:增加(Create)、查询(Read)、更改(Update)、删除(Delete),即增删改查。
…虽然在这个例子中我们只是新增和查询。
读取数据¶
从 sqlalchemy.orm中导入Session,这将允许您声明db参数的类型,并在您的函数中进行更好的类型检查和完成。导入之前的models(SQLAlchemy 模型)和schemas(Pydantic模型/模式)。
创建一些工具函数来完成:
- 通过 ID 和电子邮件查询单个用户。
- 查询多个用户。
- 查询多个项目
# @File : crud.py
from sqlalchemy.orm import Sessionfrom sql_app import models, schemasdef get_user(db: Session, user_id: int):return db.query(models.User).filter(models.User.id == user_id).first()def get_user_by_email(db: Session, email: str):return db.query(models.User).filter(models.User.email == email).first()def get_users(db: Session, skip: int = 0, limit: int = 100):return db.query(models.User).offset(skip).limit(limit).all()def create_user(db: Session, user: schemas.UserCreate):fake_hashed_password = user.password + "notreallyhashed"db_user = models.User(email=user.email, hashed_password=fake_hashed_password)db.add(db_user)db.commit()db.refresh(db_user)return db_userdef get_items(db: Session, skip: int = 0, limit: int = 100):return db.query(models.Item).offset(skip).limit(limit).all()def create_user_item(db: Session, item: schemas.ItemCreate, user_id: int):db_item = models.Item(**item.dict(), owner_id=user_id)db.add(db_item)db.commit()db.refresh(db_item)return db_item📢📢:Tip
这里不是将每个关键字参数传递给Item并从Pydantic模型中读取每个参数,而是先生成一个字典,其中包含Pydantic模型的数据:
item.dict()
然后我们将dict的键值对 作为关键字参数传递给 SQLAlchemy Item:
Item(**item.dict())
然后我们传递 Pydantic模型未提供的额外关键字参数owner_id:
Item(**item.dict(), owner_id=user_id)
因此创建数据的步骤即为:
现在创建工具函数来创建数据。
- 使用您的数据创建一个 SQLAlchemy 模型实例。
- 使用add来将该实例对象添加到数据库会话。
- 使用commit来将更改提交到数据库(以便保存它们)。
- 使用refresh来刷新您的实例对象(以便它包含来自数据库的任何新数据,例如生成的 ID)
FastAPI应用程序
现在在sql_app/main.py文件中 让我们集成和使用我们之前创建的所有其他部分。
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy.orm import Sessionfrom sql_app import schemas, crud, models
from sql_app.database import SessionLocal, enginemodels.Base.metadata.create_all(bind=engine)app = FastAPI()# Dependency
def get_db():db = SessionLocal()try:yield dbfinally:db.close()@app.post("/users/", response_model=schemas.User)
def create_user(user: schemas.UserCreate, db: Session = Depends(get_db)):db_user = crud.get_user_by_email(db, email=user.email)if db_user:raise HTTPException(status_code=400, detail="Email already registered")return crud.create_user(db=db, user=user)@app.get("/users/", response_model=list[schemas.User])
def read_users(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):users = crud.get_users(db, skip=skip, limit=limit)return users@app.get("/users/{user_id}", response_model=schemas.User)
def read_user(user_id: int, db: Session = Depends(get_db)):db_user = crud.get_user(db, user_id=user_id)if db_user is None:raise HTTPException(status_code=404, detail="User not found")return db_user@app.post("/users/{user_id}/items/", response_model=schemas.Item)
def create_item_for_user(user_id: int, item: schemas.ItemCreate, db: Session = Depends(get_db)
):return crud.create_user_item(db=db, item=item, user_id=user_id)@app.get("/items/", response_model=list[schemas.Item])
def read_items(skip: int = 0, limit: int = 100, db: Session = Depends(get_db)):items = crud.get_items(db, skip=skip, limit=limit)return items现在使用我们在sql_app/database.py文件中创建的SessionLocal来创建依赖项。我们需要每个请求有一个独立的数据库会话/连接(SessionLocal),在整个请求中使用相同的会话,然后在请求完成后关闭它。然后将为下一个请求创建一个新会话。为此,我们将创建一个包含yield的依赖项,正如前面关于Dependencies with yield的部分中所解释的那样。我们的依赖项将创建一个新的 SQLAlchemy SessionLocal,它将在单个请求中使用,然后在请求完成后关闭它。
📢📢:参数db实际上是 type SessionLocal,但是这个类(用 创建sessionmaker())是 SQLAlchemy 的“代理” Session,所以,编辑器并不真正知道提供了哪些方法。
但是通过将类型声明为Session,编辑器现在可以知道可用的方法(.add()、.query()、.commit()等)并且可以提供更好的支持(比如完成)。类型声明不影响实际对象。
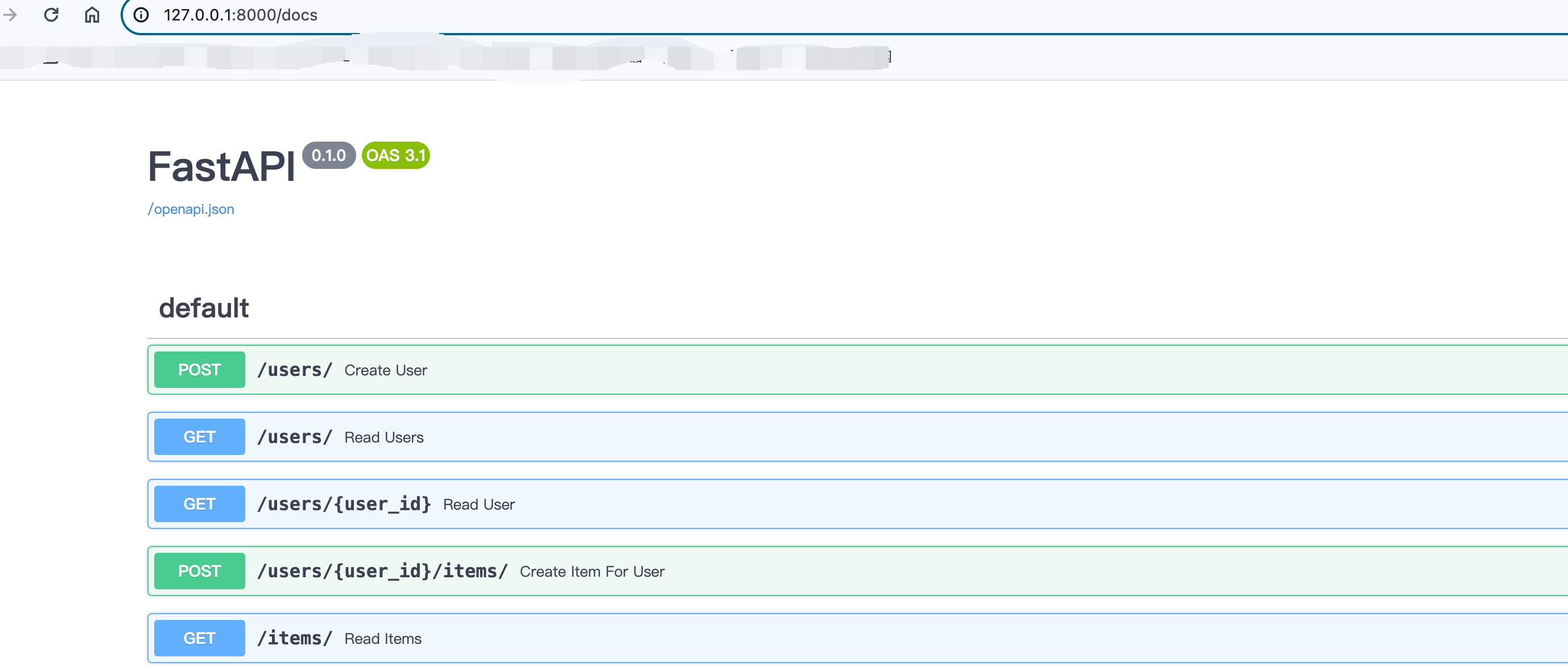
运行
# 执行命令
% uvicorn sql_app.main:app --reload

打开浏览器:http://127.0.0.1:8000/docs
相关文章:
FastAPI操作关系型数据库
FastAPI可以和任何数据库和任意样式的库配合使用,这里看一下使用SQLAlchemy的示例。下面的示例很容易的调整为PostgreSQL,MySQL,SQLite,Oracle等。当前示例中我们使用SQLite ORM对象关系映射 FastAPI可以与任何数据库在任何样式…...

数字化那点事:一文读懂智慧城市
一、智慧城市的定义 一个城市信息化发展历程主要包括数字城市、信息城市、智慧城市、互联城市等阶段,现就我们当前所处的智慧城市阶段做个简要介绍。 智慧城市是利用先进的信息和通信技术(ICT)、物联网(IoT)、大数据分…...

RabbitMQ-topic exchange使用方法
RabbitMQ-默认读、写方式介绍 RabbitMQ-发布/订阅模式 RabbitMQ-直连交换机(direct)使用方法 目录 1、概述 2、topic交换机使用方法 2.1 适用场景 2.2 解决方案 3、代码实现 3.1 源代码实现 3.2 运行记录 4、小结 1、概述 topic 交换机是比直连交换机功能更加强大的…...

6-11 函数题:某范围中的最小值
6-11 函数题:某范围中的最小值 分数 5 全屏浏览 作者 雷丽兰 单位 宜春学院 有n(n<1000)个整数,从这n个整数中找到值落在(60至100之间)的最小整数。 函数接口定义: int min ( int arr[], int n); 说明…...
Flask基础2-Jinja2模板
目录 1.介绍 2.模板传参 1.变量传参 2.表达式 3.控制语句 4.过滤器 5.自定义过滤器 6.测试器 7.块和继承 flask基础1 1.介绍 Jinja2:是Python的Web项目中被广泛应用的模板引擎,是由Python实现的模板语言,Jinja2 的作者也是 Flask 的作 者。他的设计思想来源于Django的模…...
Serverless 使用OOS将http文件转存到对象存储
目录 背景介绍 系统运维管理OOS 文件转存场景 前提条件 实践步骤 附录 示例模板 背景介绍 系统运维管理OOS 系统运维管理OOS(CloudOps Orchestration Service)提供了一个高度灵活和强大的解决方案,通过精巧地编排阿里云提供的OpenAPI…...
AcWing 477:神经网络 ← 拓扑排序+链式前向星
【题目来源】https://www.acwing.com/problem/content/479/【题目描述】 人工神经网络(Artificial Neural Network)是一种新兴的具有自我学习能力的计算系统,在模式识别、函数逼近及贷款风险评估等诸多领域有广泛的应用。 对神经网络的研究…...

鲁教版八年级数学下册-笔记
文章目录 第六章 特殊平行四边形1 菱形的性质与判定2 矩形的性质与判定3 正方形的性质与判定 第七章 二次根式1 二次根式2 二次根式的性质3 二次根式的加减二次根式的乘除 第八章 一元二次方程1 一元二次方程2 用配方法解一元二次方程3 用公式法解一元二次方程4 用因式分解法解…...

Web前端栅格:深入解析与实战应用
Web前端栅格:深入解析与实战应用 在Web前端开发中,栅格系统是一种重要的布局工具,它能够帮助我们快速构建响应式、灵活且美观的页面布局。然而,对于许多初学者和从业者来说,栅格系统的概念、原理以及实际应用却常常令…...

mysql Innodb引擎常见问题
问题 1:InnoDB 引擎的主要特点有哪些? 答:支持事务、行级锁、外键约束,具有较好的数据完整性和并发性。 问题 2:InnoDB 如何实现事务的 ACID 特性? 答:通过原子性(事务要么全部成功要…...
创建 MFC DLL-使用关键字_declspec(dllexport)
本文仅供学习交流,严禁用于商业用途,如本文涉及侵权请及时联系本人将于及时删除 从MFC DLL中导出函数的另一种方法是在定义函数时使用关键字_declspec(dllexport)。这种情况下,不需要DEF文件。 导出函数的形式为: declspec(dll…...
机器学习笔记 - 用于3D数据分类、分割的Point Net的网络实现
上一篇,我们大致了解了Point Net的原理,这里我们要进行一下实现。 机器学习笔记 - 用于3D数据分类、分割的Point Net简述-CSDN博客文章浏览阅读3次。在本文中,我们将了解Point Net,目前,处理图像数据的方法有很多。从传统的计算机视觉方法到使用卷积神经网络到Transforme…...

C#知识|基于实体类对象,返回实体集合封装介绍。
哈喽,你好啊,我是雷工! 前面通过实体类封装传递了零散的参数,打包后给数据访问方法。 但当查询结果是数据集,要把查询到的数据返回给UI时,我们也可以把返回的多条零散数据封装到实体类中。 此次练习可以使用实体容器:泛型集合List<T>,当把每条数据封装成实体对…...
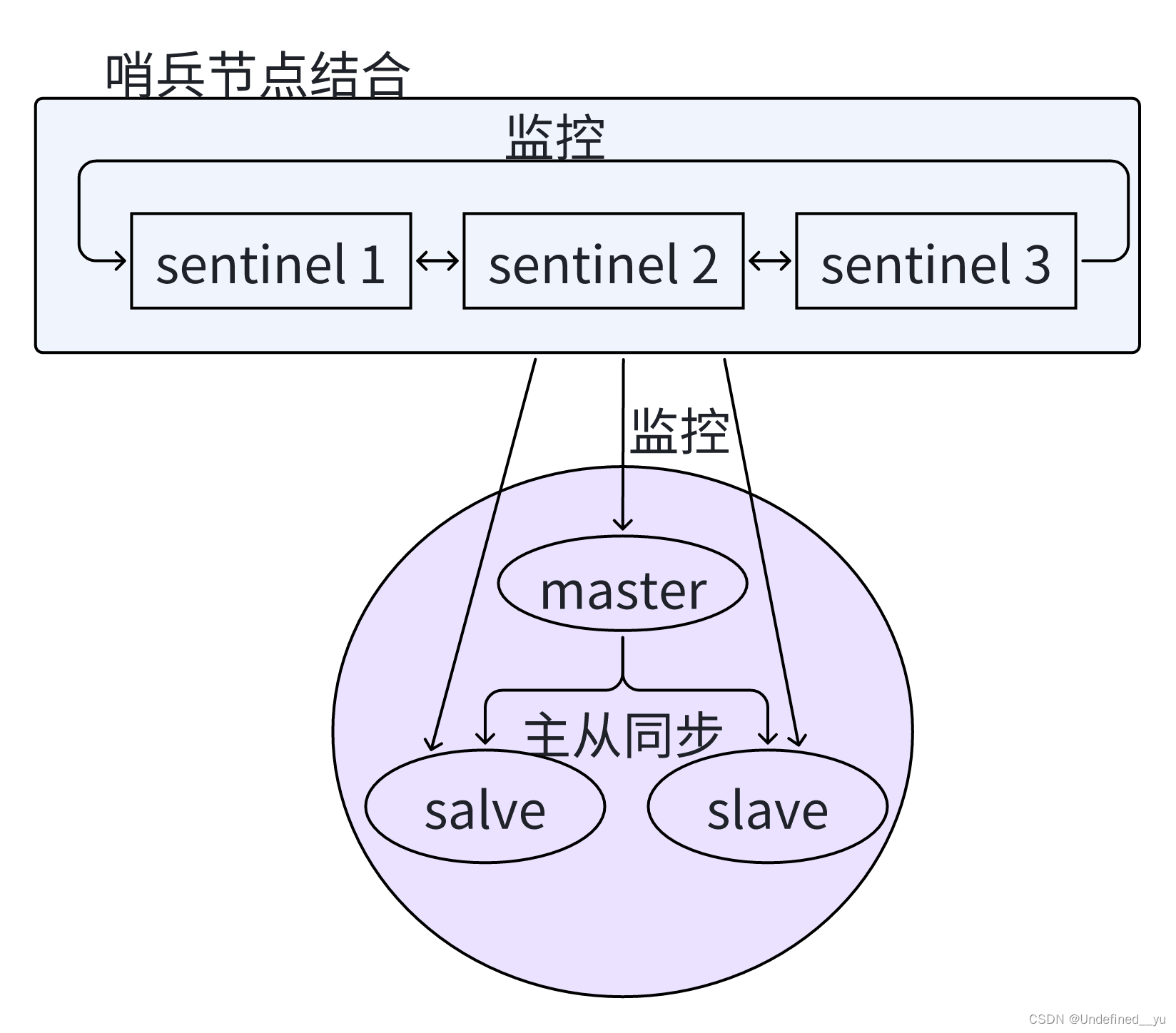
关于Redis中哨兵(Sentinel)
Redis Sentinel 相关名词解释 名词 逻辑结构 物理结构 主节点 Redis 主服务 一个独立的 redis-server 进程 从节点 Redis 从服务 一个独立的 redis-server 进程 Redis 数据节点 主从节点 主节点和从节点的进程 哨兵节点 监控 Redis 数据节点的节点 一个独立的 re…...

论文阅读:H-ViT,一种用于医学图像配准的层级化ViT
来自CVPR的一篇文章,用CNNTransformer混合模型做图像配准。可变形图像配准是一种在相同视场内比较或整合单模态或多模态视觉数据的技术,它旨在找到两幅图像之间的非线性映射关系。 1,模型结构 首先,使用类似特征金字塔网络&#…...
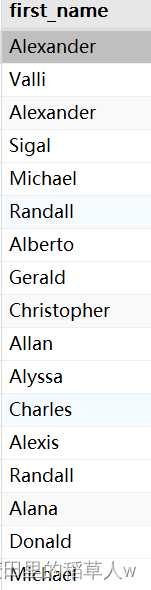
【MySQL】(基础篇七) —— 通配符和正则表达式
通配符和正则表达式 本章介绍什么是通配符、如何使用通配符以及怎样使用LIKE操作符进行通配搜索,以便对数据进行复杂过滤;如何使用正则表达式来更好地控制数据过滤。 目录 通配符和正则表达式LIKE操作符百分号(%)通配符下划线(_)通配符 通配符使用技巧正…...

HTML静态网页成品作业(HTML+CSS)—— 名人霍金介绍网页(6个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有6个页面。 二、作品演示 三、代…...
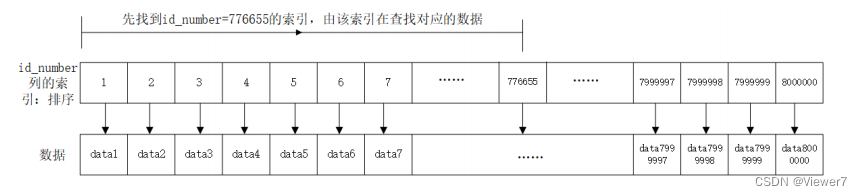
MySQL: 索引与事务
文章目录 1. 索引 (Index)1.1 概念1.2 作用1.3 使用场景1.4 索引的使用1.5 索引的使用案例 (不要轻易尝试)1.6 索引背后的数据结构1.7 重点总结 2.事务2.1 为什么要使用事务2.2 事务的概念2.3 事务的使用2.4 对事务的理解2.5 事务的基本特性 1. 索引 (Index) 1.1 概念 索引是…...

2024年最新Microsoft Edge关闭自动更新的方法分享
这里写自定义目录标题 打开【服务】 打开【服务】 windows中搜索服务,如下图: 打开服务界面,找到“Microsoft Edge Update Service (edgeupdate)” 及 “Microsoft Edge Update Service (edgeupdatem)” 两个服务,设置为禁用...

Unity3D TextMeshPro组件使用及优化详解
在Unity3D游戏开发中,文本渲染是一个不可或缺的部分。而TextMeshPro作为Unity的一个插件,提供了更高质量、更灵活的文本渲染功能,为开发者带来了极大的便利。本文将详细介绍TextMeshPro组件的使用技巧以及优化方法,并通过代码实例…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

前端中slice和splic的区别
1. slice slice 用于从数组中提取一部分元素,返回一个新的数组。 特点: 不修改原数组:slice 不会改变原数组,而是返回一个新的数组。提取数组的部分:slice 会根据指定的开始索引和结束索引提取数组的一部分。不包含…...
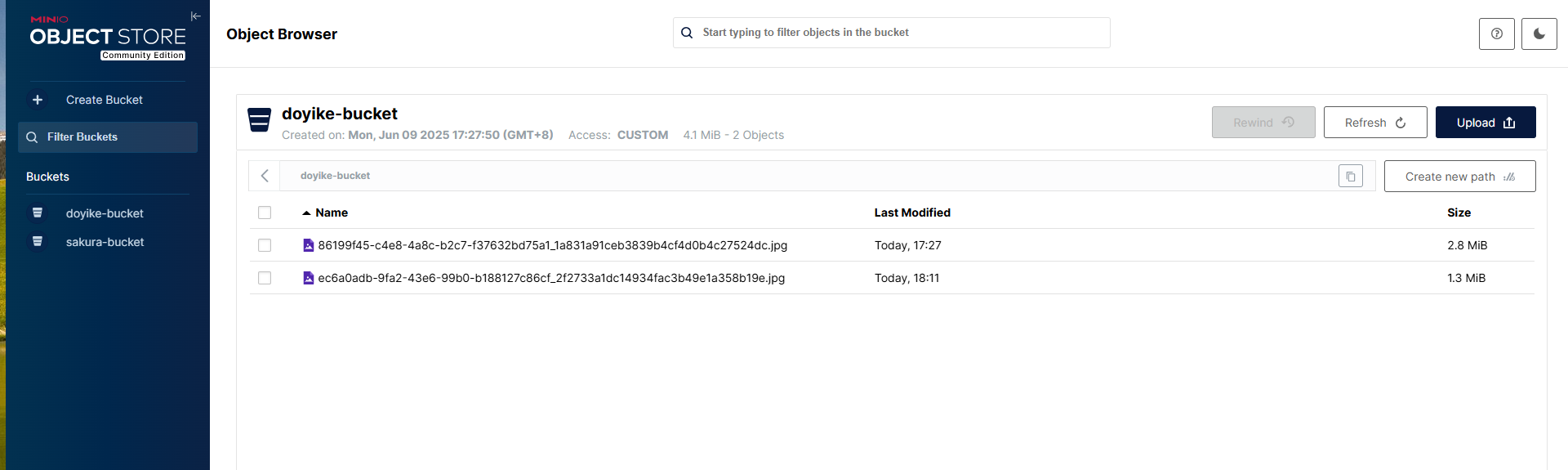
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...
)
stm32进入Infinite_Loop原因(因为有系统中断函数未自定义实现)
这是系统中断服务程序的默认处理汇编函数,如果我们没有定义实现某个中断函数,那么当stm32产生了该中断时,就会默认跑这里来了,所以我们打开了什么中断,一定要记得实现对应的系统中断函数,否则会进来一直循环…...

JavaScript 标签加载
目录 JavaScript 标签加载script 标签的 async 和 defer 属性,分别代表什么,有什么区别1. 普通 script 标签2. async 属性3. defer 属性4. type"module"5. 各种加载方式的对比6. 使用建议 JavaScript 标签加载 script 标签的 async 和 defer …...
——统计抽样学习笔记(考试用))
统计学(第8版)——统计抽样学习笔记(考试用)
一、统计抽样的核心内容与问题 研究内容 从总体中科学抽取样本的方法利用样本数据推断总体特征(均值、比率、总量)控制抽样误差与非抽样误差 解决的核心问题 在成本约束下,用少量样本准确推断总体特征量化估计结果的可靠性(置…...