Python记忆组合透明度语言模型
🎯要点
🎯浏览器语言推理识别神经网络 | 🎯不同语言秽语训练识别数据集 | 🎯交互式语言处理解释 Transformer 语言模型 | 🎯可视化Transformer 语言模型 | 🎯语言模型生成优质歌词 | 🎯模型不确定性和鲁棒性深度学习估计基准 | 🎯文本生成神经网络诗歌生成 | 🎯模型透明度 | 🎯验证揭示前馈Transformer 语言模型记忆组合 | 🎯可视化语言模型注意力 | 🎯Transformer语言模型文本解释器和视觉解释器 | 🎯分布式训练和推理模型 | 🎯知识获取模型 | 🎯信息提取模型 | 🎯文本生成模型 | 🎯语音图像视频模型
🍇Python注意力
注意力机制描述了神经网络中最近出现的一组新层,在过去几年中引起了广泛关注,尤其是在序列任务中。文献中对“注意力”有很多不同的定义,但我们在这里使用的定义如下:注意力机制描述了(序列)元素的加权平均值,其权重根据输入查询和元素的键动态计算。那么这到底是什么意思呢?目标是对多个元素的特征取平均值。但是,我们不希望对每个元素赋予相同的权重,而是希望根据它们的实际值赋予它们权重。换句话说,我们希望动态地决定我们更希望“关注”哪些输入。
💦缩放点积注意力
自注意力背后的核心概念是缩放点积注意力。我们的目标是建立一种注意力机制,序列中的任何元素都可以关注任何其他元素,同时仍能高效计算。点积注意力将一组查询 Q ∈ R T × d k Q \in R ^{T \times d_k} Q∈RT×dk、键 K ∈ R T × d k K \in R ^{T \times d_k} K∈RT×dk 和值 V ∈ R T × d v V \in R ^{T \times d_v} V∈RT×dv 作为输入,其中 T T T 是序列长度, d k d_k dk 和 d v d_v dv 分别是查询/键和值的隐藏维度。为了简单起见,我们现在忽略批量维度。从元素 i i i到 j j j的注意力值基于查询 Q i Q_i Qi和键 K j K_j Kj的相似度,使用点积作为相似度度量。在数学中,我们计算点积注意力如下:
注意力 ( Q , K , V ) = softmax ( Q K T d k ) V \text { 注意力 }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V 注意力 (Q,K,V)=softmax(dkQKT)V
其中 Q、K、V 是查询、键和值向量的串联。
矩阵乘法 Q K T Q K^T QKT 对每个可能的查询和键对执行点积,产生形状为 T × T T \times T T×T 的矩阵。每行代表特定元素 i i i 相对于序列中所有其他元素的注意力 logits。对此,我们应用 softmax 并与值向量相乘以获得加权平均值(权重由注意力决定)。这种注意力机制的另一个视角提供了如下所示的计算图。
我们尚未讨论的一方面是缩放因子 1 / d k 1 / \sqrt{d_k} 1/dk。这个比例因子对于在初始化后保持注意力值的适当方差至关重要。请记住,我们初始化层的目的是使整个模型具有相等的方差,因此 Q Q Q 和 K K K 的方差也可能接近 1 。然而,对方差为 σ 2 \sigma^2 σ2 的两个向量执行点积会产生方差为 d k d_k dk 倍的标量:
q i ∼ N ( 0 , σ 2 ) , k i ∼ N ( 0 , σ 2 ) → Var ( ∑ i = 1 d k q i ⋅ k i ) = σ 4 ⋅ d k q_i \sim N \left(0, \sigma^2\right), k_i \sim N \left(0, \sigma^2\right) \rightarrow \operatorname{Var}\left(\sum_{i=1}^{d_k} q_i \cdot k_i\right)=\sigma^4 \cdot d_k qi∼N(0,σ2),ki∼N(0,σ2)→Var(i=1∑dkqi⋅ki)=σ4⋅dk
如果我们不将方差缩小到 ∼ σ 2 \sim \sigma^2 ∼σ2,则 logits 上的 softmax 对于一个随机元素将饱和为 1,对于所有其他元素则饱和为 0。通过 softmax 的梯度将接近于零,因此我们无法正确地学习参数。请注意, σ 2 \sigma^2 σ2 的额外因子,即用 σ 4 \sigma^4 σ4 而不是 σ 2 \sigma^2 σ2,通常不是问题,因为我们保持原始方差 σ 2 \sigma^2 σ2 接近无论如何,到1。
上图中的块 Mask (opt.) 表示对注意力矩阵中的特定条目进行可选屏蔽。例如,如果我们将具有不同长度的多个序列堆叠成一个批次,就会使用此功能。为了仍然受益于 PyTorch 中的并行化,我们将句子填充到相同的长度,并在计算注意力值时屏蔽填充标记。这通常是通过将相应的注意力逻辑设置为非常低的值来实现的。
在讨论了缩放点积注意力块的细节之后,我们可以在下面编写一个函数,在给定查询、键和值三元组的情况下计算输出特征:
def scaled_dot_product(q, k, v, mask=None):d_k = q.size()[-1]attn_logits = torch.matmul(q, k.transpose(-2, -1))attn_logits = attn_logits / math.sqrt(d_k)if mask is not None:attn_logits = attn_logits.masked_fill(mask == 0, -9e15)attention = F.softmax(attn_logits, dim=-1)values = torch.matmul(attention, v)return values, attention
请注意,上面的代码支持序列长度前面的任何附加维度,因此我们也可以将其用于批处理。但是,为了更好地理解,让我们生成一些随机查询、键和值向量,并计算注意力输出:
seq_len, d_k = 3, 2
pl.seed_everything(42)
q = torch.randn(seq_len, d_k)
k = torch.randn(seq_len, d_k)
v = torch.randn(seq_len, d_k)
values, attention = scaled_dot_product(q, k, v)
print("Q\n", q)
print("K\n", k)
print("V\n", v)
print("Values\n", values)
print("Attention\n", attention)
Qtensor([[ 0.3367, 0.1288],[ 0.2345, 0.2303],[-1.1229, -0.1863]])
Ktensor([[ 2.2082, -0.6380],[ 0.4617, 0.2674],[ 0.5349, 0.8094]])
Vtensor([[ 1.1103, -1.6898],[-0.9890, 0.9580],[ 1.3221, 0.8172]])
Valuestensor([[ 0.5698, -0.1520],[ 0.5379, -0.0265],[ 0.2246, 0.5556]])
Attentiontensor([[0.4028, 0.2886, 0.3086],[0.3538, 0.3069, 0.3393],[0.1303, 0.4630, 0.4067]])
💦多头注意力
缩放点积注意力允许网络参与序列。然而,序列元素通常需要关注多个不同方面,并且单个加权平均值并不是一个好的选择。这就是为什么我们将注意力机制扩展到多个头,即相同特征上的多个不同的查询键值三元组。具体来说,给定一个查询、键和值矩阵,我们将它们转换为 h h h 子查询、子键和子值,并独立地通过缩放的点积注意力。然后,我们连接头部并将它们与最终的权重矩阵组合起来。从数学上来说,我们可以将此操作表示为:
多头 ( Q , K , V ) = Concat ( head 1 , … , head h ) W O 其中 head i = Attention ( Q W i Q , K W i K , V W i V ) \begin{aligned} \text { 多头 }(Q, K, V) & =\operatorname{Concat}\left(\text { head }_1, \ldots, \text { head }_h\right) W^O \\ \text { 其中 head }_i & =\text { Attention }\left(Q W_i^Q, K W_i^K, V W_i^V\right) \end{aligned} 多头 (Q,K,V) 其中 head i=Concat( head 1,…, head h)WO= Attention (QWiQ,KWiK,VWiV)
在没有任意查询、键和值向量作为输入的情况下,我们如何在神经网络中应用多头注意力层?查看批量大小, T T T 序列长度, d model d_{\text {model }} dmodel X X X 的隐藏维度)。连续的权重矩阵 W Q 、 W K W^Q、W^K WQ、WK 和 W V W^V WV 可以将 X X X 转换为表示输入的查询、键和值的相应特征向量。使用这种方法,我们可以实现下面的多头注意力模块。
def expand_mask(mask):assert mask.ndim >= 2, "Mask must be at least 2-dimensional with seq_length x seq_length"if mask.ndim == 3:mask = mask.unsqueeze(1)while mask.ndim < 4:mask = mask.unsqueeze(0)return mask
class MultiheadAttention(nn.Module):def __init__(self, input_dim, embed_dim, num_heads):super().__init__()assert embed_dim % num_heads == 0, "Embedding dimension must be 0 modulo number of heads."self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsself.qkv_proj = nn.Linear(input_dim, 3*embed_dim)self.o_proj = nn.Linear(embed_dim, embed_dim)self._reset_parameters()def _reset_parameters(self):nn.init.xavier_uniform_(self.qkv_proj.weight)self.qkv_proj.bias.data.fill_(0)nn.init.xavier_uniform_(self.o_proj.weight)self.o_proj.bias.data.fill_(0)def forward(self, x, mask=None, return_attention=False):batch_size, seq_length, _ = x.size()if mask is not None:mask = expand_mask(mask)qkv = self.qkv_proj(x)qkv = qkv.reshape(batch_size, seq_length, self.num_heads, 3*self.head_dim)qkv = qkv.permute(0, 2, 1, 3) # [Batch, Head, SeqLen, Dims]q, k, v = qkv.chunk(3, dim=-1)values, attention = scaled_dot_product(q, k, v, mask=mask)values = values.permute(0, 2, 1, 3) # [Batch, SeqLen, Head, Dims]values = values.reshape(batch_size, seq_length, self.embed_dim)o = self.o_proj(values)if return_attention:return o, attentionelse:return o
👉参阅一:计算思维
👉参阅二:亚图跨际
相关文章:

Python记忆组合透明度语言模型
🎯要点 🎯浏览器语言推理识别神经网络 | 🎯不同语言秽语训练识别数据集 | 🎯交互式语言处理解释 Transformer 语言模型 | 🎯可视化Transformer 语言模型 | 🎯语言模型生成优质歌词 | 🎯模型不确…...
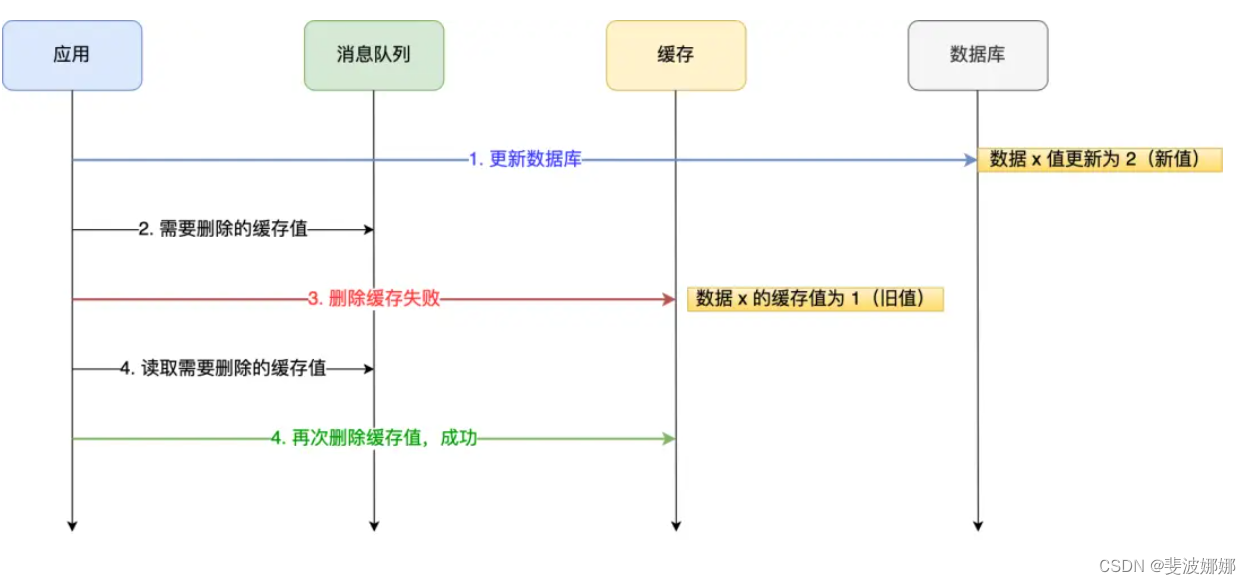
如何保证数据库和缓存的一致性
背景:为了提高查询效率,一般会用redis作为缓存。客户端查询数据时,如果能直接命中缓存,就不用再去查数据库,从而减轻数据库的压力,而且redis是基于内存的数据库,读取速度比数据库要快很多。 更新…...

Java基础 - 多线程
多线程 创建新线程 实例化一个Thread实例,然后调用它的start()方法 Thread t new Thread(); t.start(); // 启动新线程从Thread派生一个自定义类,然后覆写run()方法: public class Main {public static void main(String[] args) {Threa…...

云顶之弈-测试报告
一. 项目背景 个人博客系统采用前后端分离的方法来实现,同时使用了数据库来存储相关的数据,同时将其部署到云服务器上。前端主要有四个页面构成:登录页、列表页、详情页以及编辑页,以上模拟实现了最简单的个人博客系统。其结合后…...
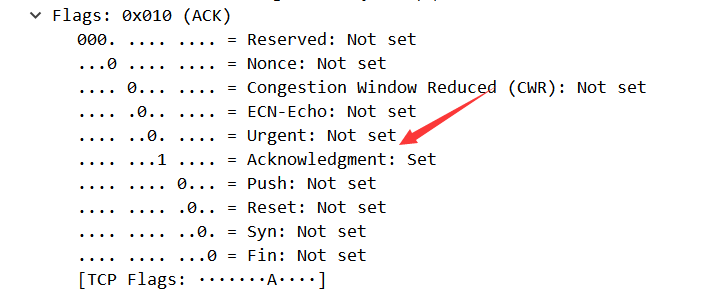
TCP/IP协议分析实验:通过一次下载任务抓包分析
TCP/IP协议分析 一、实验简介 本实验主要讲解TCP/IP协议的应用,通过一次下载任务,抓取TCP/IP数据报文,对TCP连接和断开的过程进行分析,查看TCP“三次握手”和“四次挥手”的数据报文,并对其进行简单的分析。 二、实…...
)
Python项目开发实战:企业QQ小程序(案例教程)
一、引言 在当今数字化快速发展的时代,企业对于线上服务的需求日益增长。企业QQ小程序作为一种轻量级的应用形态,因其无需下载安装、即开即用、占用内存少等优势,受到了越来越多企业的青睐。本文将以Python语言为基础,探讨如何开发一款企业QQ小程序,以满足企业的实际需求。…...

list模拟与实现(附源码)
文章目录 声明list的简单介绍list的简单使用list中sort效率测试list的简单模拟封装迭代器insert模拟erase模拟头插、尾插、头删、尾删模拟自定义类型迭代器遍历const迭代器clear和析构函数拷贝构造(传统写法)拷贝构造(现代写法) 源…...

Java应用中文件上传安全性分析与安全实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一. 文件上传的风险 二. 使用合适的框架和库 1. Spr…...
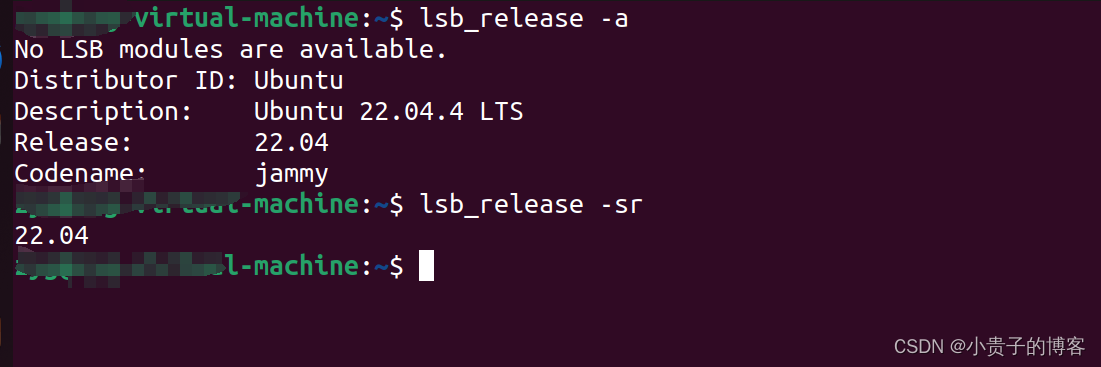
noVNC 小记
1. 怎么查看Ubuntu版本...
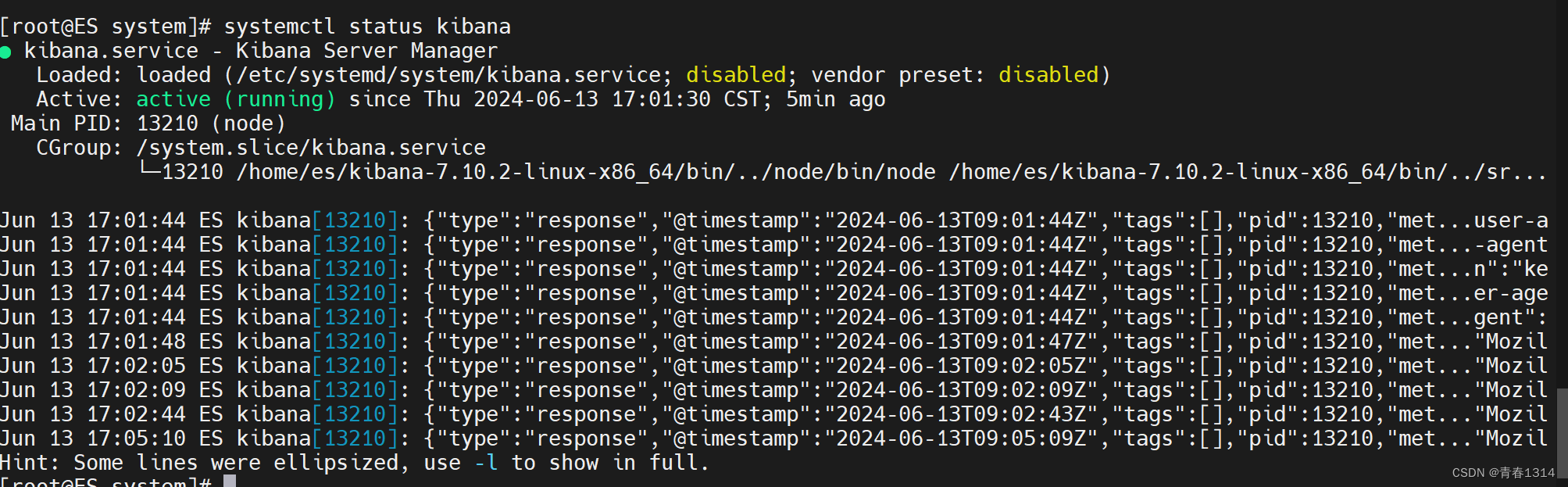
设置systemctl start kibana启动kibana
1、编辑kibana.service vi /etc/systemd/system/kibana.service [Unit] DescriptionKibana Server Manager [Service] Typesimple Useres ExecStart/home/es/kibana-7.10.2-linux-x86_64/bin/kibana PrivateTmptrue [Install] WantedBymulti-user.target 2、启动kibana # 刷…...

PostgreSQL:在CASE WHEN语句中使用SELECT语句
CASE WHEN语句是一种条件语句,用于多条件查询,相当于java的if/else。它允许我们根据不同的条件执行不同的操作。你甚至能在条件里面写子查询。而在一些情况下,我们可能需要在CASE WHEN语句中使用SELECT语句来检索数据或计算结果。下面是一些示…...

游戏心理学Day13
游戏成瘾 成瘾的概念来自于药物依赖,表现为为了感受药物带来的精神效应,或是为了避免由于断药所引起的不适和强迫性,连续定期使用该药的 行为现在成瘾除了药物成瘾外,还包括行为成瘾。成瘾的核心特征是不知道成瘾的概念来自于药…...

GitLab中用户权限
0 Preface/Foreword 1 权限介绍 包含5种权限: Guest(访客):可以创建issue、发表comment,不能读写版本库Reporter(报告者):可以克隆代码,不能提交。适合QA/PMDeveloper&…...

RunMe_About PreparationForDellBiosWUTTest
:: ***************************************************************************************************************************************************************** :: 20240613 :: 该脚本可以用作BIOS WU测试前的准备工作,包括:自动检测"C:\DellB…...

C++中变量的使用细节和命名方案
C中变量的使用细节和命名方案 C提倡使用有一定含义的变量名。如果变量表示差旅费,应将其命名为cost_of_trip或 costOfTrip,而不要将其命名为x或cot。必须遵循几种简单的 C命名规则。 在名称中只能使用字母字符、数字和下划线()。 名称的第一个字符不能是数字。 区分…...

[ACTF新生赛2020]SoulLike
两个文件 ubuntu运行 IDA打开 清晰的逻辑 很明显,我们要sub83a 返回ture 这里第一个知识点来了 你点开汇编会发现 这里一堆xor巨多 然后IDA初始化设置的函数,根本不能分析这么多 我们要去改IDA的设置 cfg 里面的 hexrays文件 在max_funsize这 修改为1024,默认是64 等待一…...

C#——析构函数详情
析构函数 C# 中的析构函数(也被称作“终结器”)同样是类中的一个特殊成员函数,主要用于在垃圾回收器回收类实例时执行一些必要的清理操作。 析构函数: 当一个对象被释放的时候执行 C# 中的析构函数具有以下特点: * 析构函数只…...

探索重要的无监督学习方法:K-means 聚类模型
在数据科学和机器学习领域,聚类分析是一种重要的无监督学习方法,用于将数据集中的对象分成多个组(簇),使得同一簇中的对象相似度较高,而不同簇中的对象相似度较低。K-means 聚类是最广泛使用的聚类算法之一,它以其简单、快速和易于理解的特点受到了广泛关注。本文将深入…...

将web项目打包成electron桌面端教程(二)vue3+vite+ts
说明:我用的demo项目是vue3vitets,如果是vue2/cli就不用往下看啦,建议找找其他教程哦~下依赖npm下载不下来的,基本换成cnpm/pnpm/yarn就可以了 一、项目准备 1、自己新创建一个,这里就不过多赘述了 2、将需要打包成…...

Linux下的/etc/resolv.conf
Linux下的/etc/resolv.conf 文件用于配置域名解析器的设置,告诉系统在解析域名时要查询哪些DNS服务器。nameserver:指定DNS服务器的IP地址。你可以列出多个nameserver,系统将按顺序尝试它们,直到找到可用的DNS服务器。 nameserve…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

ubuntu22.04 安装docker 和docker-compose
首先你要确保没有docker环境或者使用命令删掉docker sudo apt-get remove docker docker-engine docker.io containerd runc安装docker 更新软件环境 sudo apt update sudo apt upgrade下载docker依赖和GPG 密钥 # 依赖 apt-get install ca-certificates curl gnupg lsb-rel…...

游戏开发中常见的战斗数值英文缩写对照表
游戏开发中常见的战斗数值英文缩写对照表 基础属性(Basic Attributes) 缩写英文全称中文释义常见使用场景HPHit Points / Health Points生命值角色生存状态MPMana Points / Magic Points魔法值技能释放资源SPStamina Points体力值动作消耗资源APAction…...

【Ftrace 专栏】Ftrace 参考博文
ftrace、perf、bcc、bpftrace、ply、simple_perf的使用Ftrace 基本用法Linux 利用 ftrace 分析内核调用如何利用ftrace精确跟踪特定进程调度信息使用 ftrace 进行追踪延迟Linux-培训笔记-ftracehttps://www.kernel.org/doc/html/v4.18/trace/events.htmlhttps://blog.csdn.net/…...