feedparser - Python 解析Atom和RSSfeed
文章目录
- 一、关于 feedparser
- 二、安装
- 三、关于文档及构建
- 四、测试
- 五、常见RSS元素
- 访问常见 Channel 元素
- 访问常用项目元素
- 六、常见Atom元素
- 访问常用feed元素
- 访问公共入口元素
- 七、获取Atom元素的详细信息
- Feed元素的详细信息
- 八、测试元素是否存在
- 九、其他功能 & 文档
- 高级功能
- HTTP特性
- 十、Reference
一、关于 feedparser
- github : https://github.com/kurtmckee/feedparser
- 文档:https://feedparser.readthedocs.io/en/latest/
在Python中解析Atom和RSSfeed。
二、安装
可以通过运行pip来安装:
pip install feedparser
三、关于文档及构建
feedparser 文档 :https://feedparser.readthedocs.io/en/latest/
它还包含在docs/目录中的源格式 ReST中。
要构建文档,您需要Sphinx包,下载地址:https://www.sphinx-doc.org/
然后,您可以使用类似于以下命令,构建 HTML 页面:
sphinx-build -b html docs/ fpdocs
这将在fpdocs/目录中,产生HTML文档。
四、测试
Feedparser 有一个广泛的测试套件,由Tox提供支持。要运行它,请键入以下内容:
$ python -m venv venv
$ source venv/bin/activate # or "venv\bin\activate.ps1" on Windows
(venv) $ python -m pip install --upgrade pip
(venv) $ python -m pip install tox
(venv) $ tox
五、常见RSS元素
RSS feeds 中最常用的元素(无论版本如何)是标题、链接、描述、发布日期和条目ID。发布日期来自 pubDate 元素,条目ID 来自guid元素。
此示例RSSfeed位于 https://feedparser.readthedocs.io/en/latest/examples/rss20.xml。
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0">
<channel>
<title>Sample Feed</title>
<description>For documentation <em>only</em></description>
<link>http://example.org/</link>
<pubDate>Sat, 07 Sep 2002 00:00:01 GMT</pubDate>
<!-- other elements omitted from this example -->
<item>
<title>First entry title</title>
<link>http://example.org/entry/3</link>
<description>Watch out for <span style="background-image:
url(javascript:window.location='http://example.org/')">nasty
tricks</span></description>
<pubDate>Thu, 05 Sep 2002 00:00:01 GMT</pubDate>
<guid>http://example.org/entry/3</guid>
<!-- other elements omitted from this example -->
</item>
</channel>
</rss>
通道元素在d.feed中可用。
访问常见 Channel 元素
>>> import feedparser
>>> d = feedparser.parse('https://feedparser.readthedocs.io/en/latest/examples/rss20.xml')
>>> d.feed.title
'Sample Feed'
>>> d.feed.link
'http://example.org/'
>>> d.feed.description
'For documentation <em>only</em>'
>>> d.feed.published
'Sat, 07 Sep 2002 00:00:01 GMT'
>>> d.feed.published_parsed
(2002, 9, 7, 0, 0, 1, 5, 250, 0)
d.entries中的这些项目可用,这是一个列表。
您可以按照它们在原始feed中出现的顺序 访问列表中的项目,因此在d.entries[0]中的第一个项目可用。
访问常用项目元素
>>> import feedparser
>>> d = feedparser.parse('https://feedparser.readthedocs.io/en/latest/examples/rss20.xml')
>>> d.entries[0].title
'First item title'
>>> d.entries[0].link
'http://example.org/item/1'
>>> d.entries[0].description
'Watch out for <span>nasty tricks</span>'
>>> d.entries[0].published
'Thu, 05 Sep 2002 00:00:01 GMT'
>>> d.entries[0].published_parsed
(2002, 9, 5, 0, 0, 1, 3, 248, 0)
>>> d.entries[0].id
'http://example.org/guid/1'
注:您还可以使用Atom术语 从RSSfeed访问数据。有关详细信息,请参阅 Content Normalization 。
六、常见Atom元素
Atomfeed通常比RSSfeed包含更多信息(因为需要更多元素),但最常用的元素仍然是标题、链接、副标题/描述、各种日期和ID。
此示例Atomfeed https://feedparser.readthedocs.io/en/latest/examples/atom10.xml 。
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom"
xml:base="http://example.org/"
xml:lang="en">
<title type="text">Sample Feed</title>
<subtitle type="html">
For documentation <em>only</em>
</subtitle>
<link rel="alternate" href="/"/>
<link rel="self"
type="application/atom+xml"
href="http://www.example.org/atom10.xml"/>
<rights type="html">
<p>Copyright 2005, Mark Pilgrim</p><
</rights>
<id>tag:feedparser.org,2005-11-09:/docs/examples/atom10.xml</id>
<generator
uri="http://example.org/generator/"
version="4.0">
Sample Toolkit
</generator>
<updated>2005-11-09T11:56:34Z</updated>
<entry>
<title>First entry title</title>
<link rel="alternate"
href="/entry/3"/>
<link rel="related"
type="text/html"
href="http://search.example.com/"/>
<link rel="via"
type="text/html"
href="http://toby.example.com/examples/atom10"/>
<link rel="enclosure"
type="video/mpeg4"
href="http://www.example.com/movie.mp4"
length="42301"/>
<id>tag:feedparser.org,2005-11-09:/docs/examples/atom10.xml:3</id>
<published>2005-11-09T00:23:47Z</published>
<updated>2005-11-09T11:56:34Z</updated>
<summary type="text/plain" mode="escaped">Watch out for nasty tricks</summary>
<content type="application/xhtml+xml" mode="xml"
xml:base="http://example.org/entry/3" xml:lang="en-US">
<div xmlns="http://www.w3.org/1999/xhtml">Watch out for
<span style="background: url(javascript:window.location='http://example.org/')">
nasty tricks</span></div>
</content>
</entry>
</feed>
feed 元素在d.feed中可用。
访问常用feed元素
>>> import feedparser
>>> d = feedparser.parse('https://feedparser.readthedocs.io/en/latest/examples/atom10.xml')
>>> d.feed.title
'Sample feed'
>>> d.feed.link
'http://example.org/'
>>> d.feed.subtitle
'For documentation <em>only</em>'
>>> d.feed.updated
'2005-11-09T11:56:34Z'
>>> d.feed.updated_parsed
(2005, 11, 9, 11, 56, 34, 2, 313, 0)
>>> d.feed.id
'tag:feedparser.org,2005-11-09:/docs/examples/atom10.xml'
条目在d.entries中可用,这是一个列表。
您可以在 它们在原始feed中出现的顺序,因此第一个条目是 d.entries[0]。
访问公共入口元素
>>> import feedparser
>>> d = feedparser.parse('https://feedparser.readthedocs.io/en/latest/examples/atom10.xml')
>>> d.entries[0].title
'First entry title'
>>> d.entries[0].link
'http://example.org/entry/3
>>> d.entries[0].id
'tag:feedparser.org,2005-11-09:/docs/examples/atom10.xml:3'
>>> d.entries[0].published
'2005-11-09T00:23:47Z'
>>> d.entries[0].published_parsed
(2005, 11, 9, 0, 23, 47, 2, 313, 0)
>>> d.entries[0].updated
'2005-11-09T11:56:34Z'
>>> d.entries[0].updated_parsed
(2005, 11, 9, 11, 56, 34, 2, 313, 0)
>>> d.entries[0].summary
'Watch out for nasty tricks'
>>> d.entries[0].content
[{'type': 'application/xhtml+xml',
'base': 'http://example.org/entry/3',
'language': 'en-US',
'value': '<div>Watch out for <span>nasty tricks</span></div>'}]
注:解析后的摘要和内容 与它们出现在 原始feed 不用。原始元素包含危险的超文本标记语言标记,已被清理。详见 Sanitization 。
因为Atom条目可以有多个内容元素, d.entries[0].content是字典的列表。
每个字典包含 关于单个内容元素的元信息。
字典中最重要的两个值是 内容类型(在d.entries[0].content[0].type中)和 实际内容值(在d.entries[0].content[0].value中)。
您也可以在其他Atom元素上获得此详细级别。
七、获取Atom元素的详细信息
几个Atom元素共享Atom内容模型:标题、副标题、权利、摘要,当然还有内容。(Atom 0.3也有一个共享此内容模型的info元素。)
通用Feed Parser 捕获关于这些元素的所有相关元信息,最重要的是体裁和值本身。
Feed元素的详细信息
>>> import feedparser
>>> d = feedparser.parse('https://feedparser.readthedocs.io/en/latest/examples/atom10.xml')
>>> d.feed.title_detail
{'type': 'text/plain',
'base': 'http://example.org/',
'language': 'en',
'value': 'Sample Feed'}
>>> d.feed.subtitle_detail
{'type': 'text/html',
'base': 'http://example.org/',
'language': 'en',
'value': 'For documentation <em>only</em>'}
>>> d.feed.rights_detail
{'type': 'text/html',
'base': 'http://example.org/',
'language': 'en',
'value': '<p>Copyright 2004, Mark Pilgrim</p>'}
>>> d.entries[0].title_detail
{'type': 'text/plain',
'base': 'http://example.org/',
'language': 'en',
'value': 'First entry title'}
>>> d.entries[0].summary_detail
{'type': 'text/plain',
'base': 'http://example.org/',
'language': 'en',
'value': 'Watch out for nasty tricks'}
>>> len(d.entries[0].content)
1
>>> d.entries[0].content[0]
{'type': 'application/xhtml+xml',
'base': 'http://example.org/entry/3',
'language': 'en-US'
'value': '<div>Watch out for <span> nasty tricks</span></div>'}
八、测试元素是否存在
现实世界中的Feeds可能缺少元素,甚至是规范要求的元素。
在获取元素值之前,您应该始终测试元素的存在。永远不要假设元素存在。
要测试元素是否存在,可以使用标准Python字典习语。
>>> import feedparser
>>> d = feedparser.parse('https://feedparser.readthedocs.io/en/latest/examples/atom10.xml')
>>> 'title' in d.feed
True
>>> 'ttl' in d.feed
False
>>> d.feed.get('title', 'No title')
'Sample feed'
>>> d.feed.get('ttl', 60)
60
九、其他功能 & 文档
高级功能
- 日期解析
- 日期格式的历史
- 识别日期格式
- 支持其他日期格式
- Sanitization
- HTML Sanitization
- SVG Sanitization
- MathML Sanitization
- CSS Sanitization
- 列入白名单,不要列入黑名单
- 内容标准化
- 将Atom feed 作为RSS feed 访问
- 将RSS feed 作为Atom feed 访问
- 命名空间处理
- 访问命名空间元素
- 使用非标准前缀 访问命名空间元素
- Relative Link Resolution
- 哪些值是URI
- 如何解决相对URI
- 禁用相对URI解析
- Feed Type and Version Detection feed类型和版本检测
- 访问feed版本
- 字符编码检测
- 字符编码简介
- 处理 Incorrectly-Declared 编码
- 处理 Incorrectly-Declared 媒体类型
- Bozo 检测
- 检测格式不正确的反馈
HTTP特性
- ETag 和最后修改的头文件
- 使用ETags减少带宽
- 使用Last-Modified 头文件来减少带宽
- User-Agent和Referer 头文件
- 自定义 User-Agent
- 永久自定义 User-Agent
- 自定义 referrer
- HTTP重定向
- 注意临时重定向
- 注意永久重定向
- 注意标记为“gone”的feeds
- 受密码保护的feed
- 下载 受基本鉴权保护 的 feed(简单方法)
- 下载 受摘要鉴权保护的feed(简单但非常不安全的方式)
- 下载受HTTP基本鉴权保护的feed(硬方法)
- 下载受HTTP摘要鉴权保护的feed(安全方式)
- 确定feed受密码保护
- 其他HTTP 头文件
- 发送自定义HTTP请求 头文件
- 访问其他HTTP响应 头文件
十、Reference
bozobozo_exceptionencodingentriesentries[i\].authorentries[i].author_detailentries[i\].author_detail.nameentries[i\].author_detail.hrefentries[i\].author_detail.email
entries[i\].commentsentries[i].contententries[i\].content[j].valueentries[i\].content[j].typeentries[i\].content[j].languageentries[i\].content[j].base
entries[i].contributorsentries[i\].contributors[j].nameentries[i\].contributors[j].hrefentries[i\].contributors[j].email
entries[i\].createdentries[i\].created_parsedentries[i].enclosuresentries[i\].enclosures[j].hrefentries[i\].enclosures[j].lengthentries[i\].enclosures[j].type
entries[i\].expiredentries[i\].expired_parsedentries[i\].identries[i\].licenseentries[i\].linkentries[i].linksentries[i\].links[j].relentries[i\].links[j].typeentries[i\].links[j].hrefentries[i\].links[j].title
entries[i\].publishedentries[i\].published_parsedentries[i\].publisherentries[i].publisher_detailentries[i\].publisher_detail.nameentries[i\].publisher_detail.hrefentries[i\].publisher_detail.email
entries[i].sourceentries[i\].source.authorentries[i\].source.author_detailentries[i\].source.contributorsentries[i\].source.iconentries[i\].source.identries[i\].source.linkentries[i\].source.linksentries[i\].source.logoentries[i\].source.rightsentries[i\].source.rights_detailentries[i\].source.subtitleentries[i\].source.subtitle_detailentries[i\].source.titleentries[i\].source.title_detailentries[i\].source.updatedentries[i\].source.updated_parsed
entries[i\].summaryentries[i].summary_detailentries[i\].summary_detail.valueentries[i\].summary_detail.typeentries[i\].summary_detail.languageentries[i\].summary_detail.base
entries[i].tagsentries[i\].tags[j].termentries[i\].tags[j].schemeentries[i\].tags[j].label
entries[i\].titleentries[i].title_detailentries[i\].title_detail.valueentries[i\].title_detail.typeentries[i\].title_detail.languageentries[i\].title_detail.base
entries[i\].updatedentries[i\].updated_parsedetagfeedfeed.authorfeed.author_detailfeed.author_detail.namefeed.author_detail.hreffeed.author_detail.email
feed.cloudfeed.cloud.domainfeed.cloud.portfeed.cloud.pathfeed.cloud.registerProcedurefeed.cloud.protocol
feed.contributorsfeed.contributors[i\].namefeed.contributors[i\].hreffeed.contributors[i\].email
feed.docsfeed.errorreportstofeed.generatorfeed.generator_detailfeed.generator_detail.namefeed.generator_detail.hreffeed.generator_detail.version
feed.iconfeed.idfeed.imagefeed.image.titlefeed.image.hreffeed.image.linkfeed.image.widthfeed.image.heightfeed.image.description
feed.infofeed.info_detailfeed.info_detail.valuefeed.info_detail.typefeed.info_detail.languagefeed.info_detail.base
feed.languagefeed.licensefeed.linkfeed.linksfeed.links[i\].relfeed.links[i\].typefeed.links[i\].hreffeed.links[i\].title
feed.logofeed.publishedfeed.published_parsedfeed.publisherfeed.publisher_detailfeed.publisher_detail.namefeed.publisher_detail.hreffeed.publisher_detail.email
feed.rightsfeed.rights_detailfeed.rights_detail.valuefeed.rights_detail.typefeed.rights_detail.languagefeed.rights_detail.base
feed.subtitlefeed.subtitle_detailfeed.subtitle_detail.valuefeed.subtitle_detail.typefeed.subtitle_detail.languagefeed.subtitle_detail.base
feed.tagsfeed.tags[i\].termfeed.tags[i\].schemefeed.tags[i\].label
feed.textinputfeed.textinput.titlefeed.textinput.linkfeed.textinput.namefeed.textinput.description
feed.titlefeed.title_detailfeed.title_detail.valuefeed.title_detail.typefeed.title_detail.languagefeed.title_detail.base
feed.ttlfeed.updatedfeed.updated_parsedheadershrefmodifiednamespacesstatusversion
2024-06-07(五)
相关文章:

feedparser - Python 解析Atom和RSSfeed
文章目录 一、关于 feedparser二、安装三、关于文档及构建四、测试五、常见RSS元素访问常见 Channel 元素访问常用项目元素 六、常见Atom元素访问常用feed元素访问公共入口元素 七、获取Atom元素的详细信息Feed元素的详细信息 八、测试元素是否存在九、其他功能 & 文档高级…...

ARM32开发--IIC时钟案例
知不足而奋进 望远山而前行 目录 文章目录 前言 目标 内容 需求 开发流程 移植驱动 修改I2C实现 测试功能 总结 前言 在现代嵌入式系统开发中,移植外设驱动并测试其功能是一项常见的任务。本次学习的目标是掌握移植方法和测试方法,以实现对开…...
[深度学习]基于C++和onnxruntime部署yolov10的onnx模型
基于C和ONNX Runtime部署YOLOv10的ONNX模型,可以遵循以下步骤: 准备环境:首先,确保已经下载后指定版本opencv和onnruntime的C库。 模型转换:按照官方源码:https://github.com/THU-MIG/yolov10 安装好yolov…...
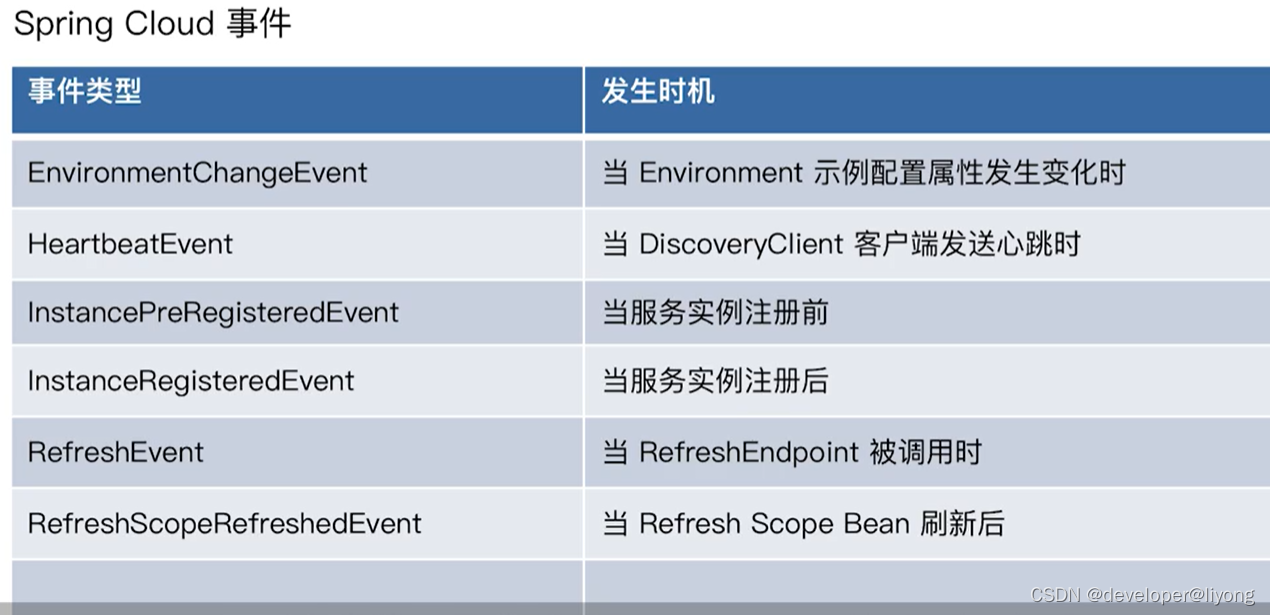
Spring-事件
Java 事件/监听器编程模型 设计模式-观察者模式的拓展 可观察者对象(消息发送者) Java.util.Observalbe观察者 java.util.Observer 标准化接口(标记接口) 事件对象 java.util.EventObject事件监听器 java.util.EventListener public class ObserverDemo {public static vo…...
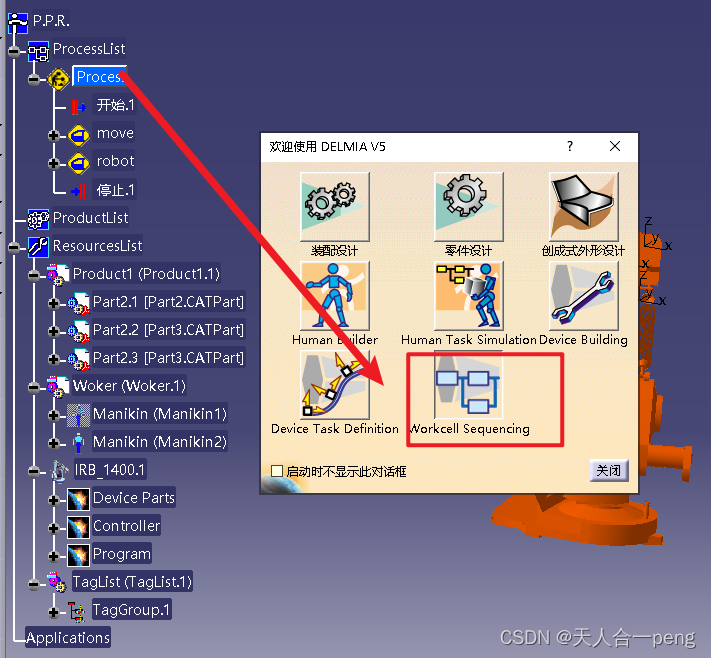
delmia的工序设置
process的设置需要在workcell sequuencing里面去设置...

【JavaEE精炼宝库】多线程(5)单例模式 | 指令重排序 | 阻塞队列
目录 一、单例模式: 1.1 饿汉模式: 1.2 懒汉模式: 1.2.1 线程安全的懒汉模式: 1.2.2 线程安全的懒汉模式的优化: 二、指令重排序 三、阻塞队列 3.1 阻塞队列的概念: 3.2 生产者消费者模型…...

[图解]《分析模式》漫谈03-Party是什么
1 00:00:00,790 --> 00:00:03,930 今天我们来看一下,Party是什么 2 00:00:05,710 --> 00:00:07,470 当然我们这里说的不是政治的 3 00:00:07,880 --> 00:00:08,350 Party 4 00:00:09,230 --> 00:00:11,110 是《分析模式》里面的一个用词 5 00:00:14…...

【Numpy】一文向您详细介绍 np.abs()
【Numpy】一文向您详细介绍 np.abs() 下滑即可查看博客内容 🌈 欢迎莅临我的个人主页 👈这里是我静心耕耘深度学习领域、真诚分享知识与智慧的小天地!🎇 🎓 博主简介:985高校的普通本硕,曾…...

【AI绘画】Stable Diffusion 3开源
Open Release of Stable Diffusion 3 Medium 主要内容 Stable Diffusion 3是Stability AI目前为止最先进的文本转图像开放源代码算法。 这款模型的小巧设计使其完美适合用于消费级PC和笔记本电脑,以及企业级图形处理单元上运行。它已经满足了标准化的文字转图像模…...
使用ant-design/cssinjs向plasmo浏览器插件的内容脚本content中注入antd的ui组件样式
之前写过一篇文章用来向content内容脚本注入antd的ui:https://xiaoshen.blog.csdn.net/article/details/136418199,但是方法就是比较繁琐,需要将antd的样式拷贝出来,然后贴到一个单独的css样式文件中,然后引入到内容脚…...

南京威雅学校:初中转轨国际化教育,她们打开了成长的另一种可能
“上了大学就轻松了。” 又是一年高考季,每每回想起十八岁前那些没日没夜埋头学习的日子,已经为人父母的你是不是也忍不住想要孩子气地吐槽一句,“骗人”——人不会在一场考试后瞬间长大,试卷里也没有人生的全部答案。 三年前&a…...

Linux | 标准IO编程
Linux | 标准IO编程 时间:2024年6月8日23:03:43 文章目录 `Linux` | 标准`IO`编程1.标准`IO`编程1-1.流的打开函数fopen()1-2.流的关闭函数fclose()1-3.错误处理函数perror()函数strerror()errno 变量总结1-4.流的读写1-4-1.按字符(字节)输入/输出实例1-4-2.按行输入/输出1-…...
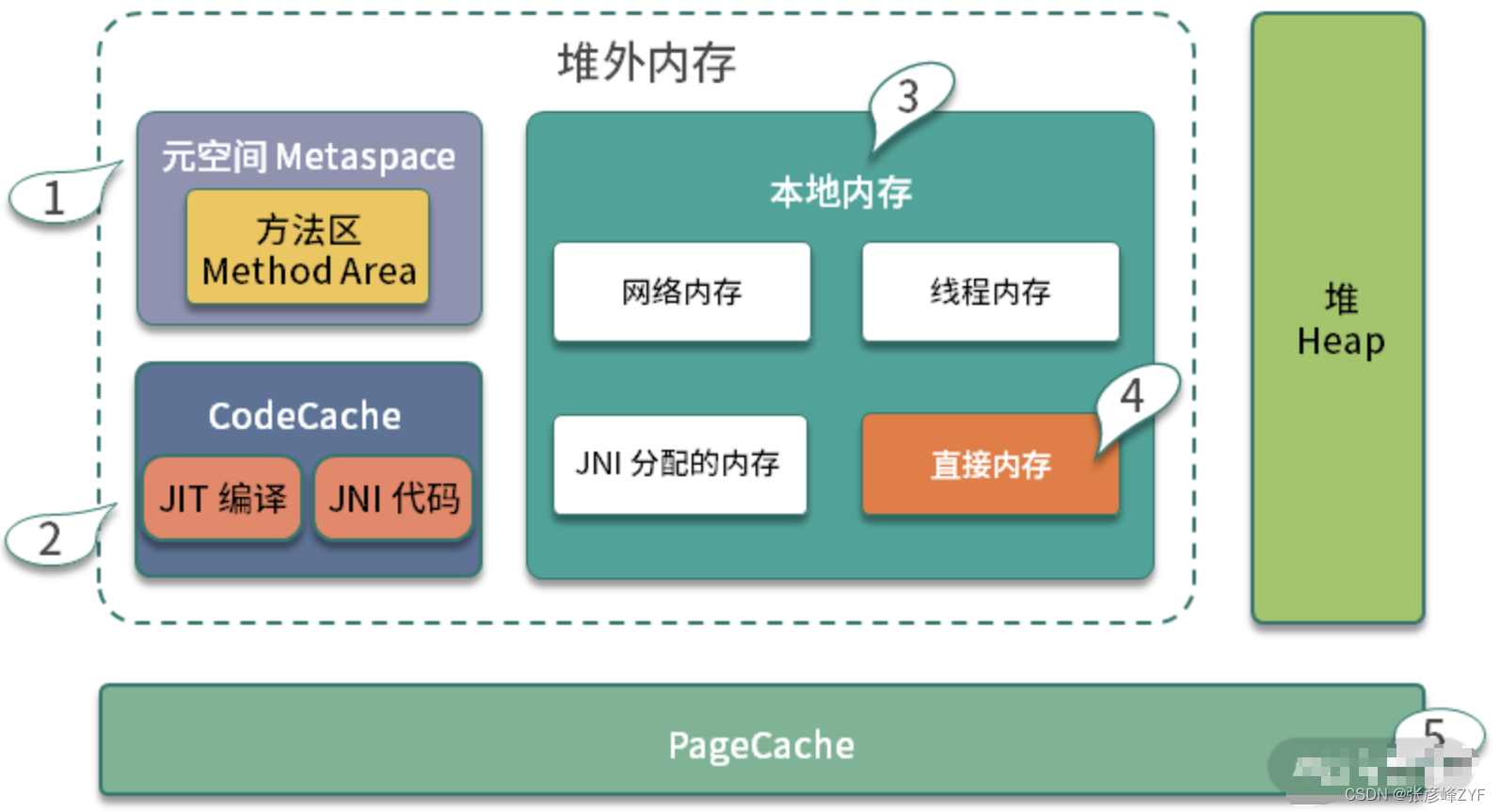
从ES的JVM配置起步思考JVM常见参数优化
目录 一、真实查看参数 (一)-XX:PrintCommandLineFlags (二)-XX:PrintFlagsFinal 二、堆空间的配置 (一)默认配置 (二)配置Elasticsearch堆内存时,将初始大小设置为…...

milvus的GPU索引
前言 milvus支持多种GPU索引类型,它能加速查询的性能和效率,特别是在高吞吐量,低延迟和高召回率的场景。本文我们将介绍milvus支持的各种GPU索引类型以及它们适用的场景、性能特点。 下图展示了milvus的几种索引的查询性能对比,…...

CleanMyMac2024最新免费电脑Mac系统优化工具
大家好,我是你们的好朋友——软件评测专家,同时也是一名技术博主。今天我要给大家种草一个超级实用的Mac优化工具——CleanMyMac! 作为一个长期使用macOS的用户,我深知系统运行时间长了,缓存文件、日志、临时文件等都会…...
catia/delmia的快捷图标模式最多12个
这儿最多显示12个 根据官方文档 If you installed a configuration containing more than 12 workbenches (such as the "AL2" configuration), only the first 12 workbenches are displayed in the Favorites list. The other workbenches do not appear in the l…...

磁盘性能概述与磁盘调度算法
目录 1. 磁盘性能概述 1. 数据传输速率 2. 寻道时间 3. 旋转延迟 4. 平均访问时间 2. 早期的磁盘调度算法 1. FIFO(First-In-First-Out)调度算法 2. SSTF(Shortest Seek Time First)调度算法 3. SCAN(Elevator…...

chrome浏览器设置--disable-web-security解决跨域
在开发人员于后台进行接口测试的时候,老是遇到跨域问题,这时前端总是会让后台添加跨域请求头来允许跨域请求,今天介绍一个简单的方法跨过这一步操作的设置。 –disable-web-security参数,禁用同源策略,利于开发人员本…...

Android中蓝牙设备的状态值管理
在Android中,蓝牙状态可以通过多种方式来描述,主要包括蓝牙适配器状态、蓝牙设备连接状态以及蓝牙广播状态,其关键的蓝牙状态实现类有BluetoothAdapter、BluetoothDevicePairer、BluetoothDevice、BluetoothProfile,详细介绍如下&…...

关于ReactV18的页面跳转传参和接收
一、使用路由方式进行传参和接收(此处需使用 useNavigate 和 useParams 两个hooks) 1 首先需要配置好路由形式如下 :id(参数) { path: "/articleDetail/:id", element: lazyElement(<ArticleDetail />), }, 2 传递参数 使用 useNaviga…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...
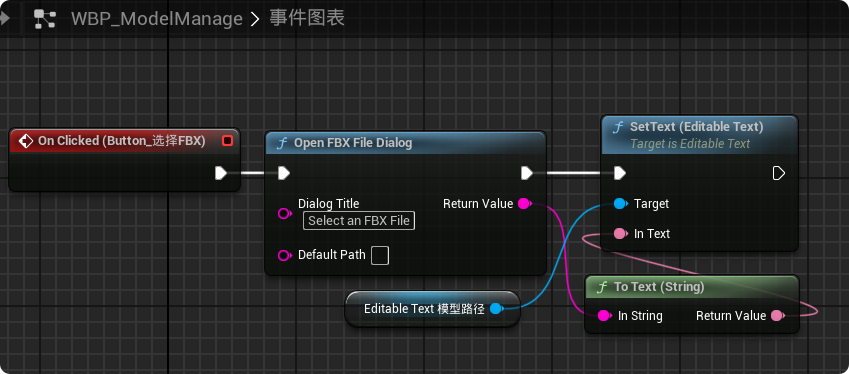
【UE5 C++】通过文件对话框获取选择文件的路径
目录 效果 步骤 源码 效果 步骤 1. 在“xxx.Build.cs”中添加需要使用的模块 ,这里主要使用“DesktopPlatform”模块 2. 添加后闭UE编辑器,右键点击 .uproject 文件,选择 "Generate Visual Studio project files",重…...