车牌识别(附源代码)
完整项目已上传至github:End-to-end-for-chinese-plate-recognition/License-plate-recognition at master · duanshengliu/End-to-end-for-chinese-plate-recognition · GitHub
整体思路:
1.利用u-net图像分割得到二值化图像
2.再使用cv2进行边缘检测获得车牌区域坐标,并将车牌图形矫正
3.利用卷积神经网络cnn进行车牌多标签端到端识别
环境:python3.11 tensorflow opencv4.6
1.车牌定位
首先贴一下图像分割的效果图:

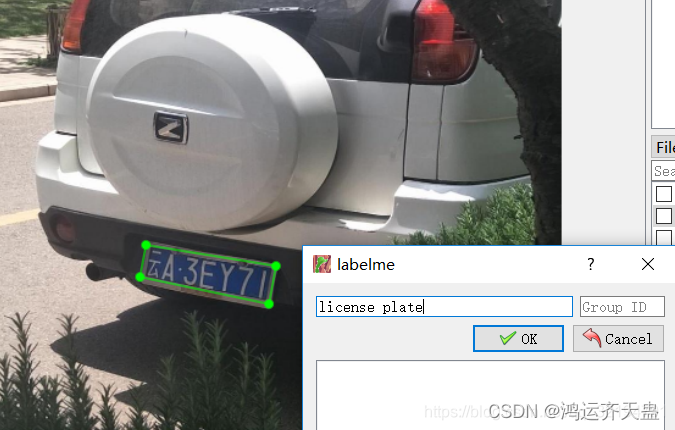
我们可以通过图像分割算法对一张输入图片进行分割,分割后的图形其实是对原图中的区域进行的分类标注,例如这里我们可以将原图标注为2类,一类就是车牌区域,还有一类就是无关的背景区域。说到标注图形就不得不说labelme了,我们可以在cmd界面通过命令 pip install labelme 进行labelme库的安装,安装结束在cmd界面输入labelme即可打开lablem软件的标注界面如下
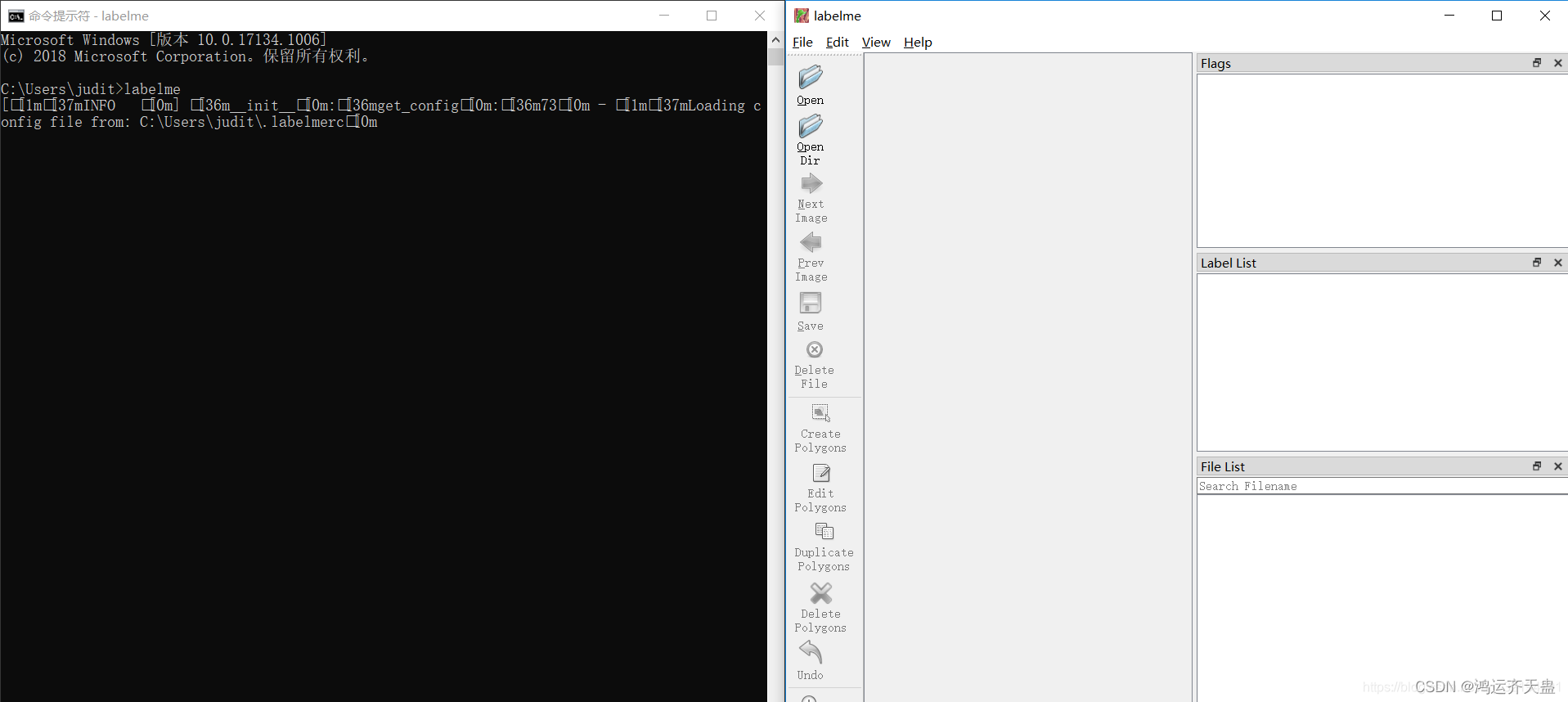
1. 点击OpenDir ,选择我们准备好的车辆数据集(注意:一定要先把图片全都resize为训练时所需的大小,再进行标注。我们知道图片数据的范围是0-255,背景为黑色0,车牌区域为255,我们需要的是标注好的图片即img_mask中值只有{0,255}这2种,如果我们不先resize,标注完再resize会导致一个大问题,就是数据的值并不是二类,会出现{0,1,10,248,251,255}等类似的多值问题,我在之前就遇到这样的问题,不得已又重新标注了300多张图)
2. 点击左上角File—>将Save Automatically勾选上,点击Change Output Dir选择保存路径,我这里是在桌面D:/desktop/下新建了一个文件夹命名为labelme,在labelm文件夹中新建了一个json文件夹用于保存我们标注的json数据,这里我们Change Output Dir的保存路径就选它,还新建了一个data文件夹用于存放后续转换的图片数据,而待标注图片在pic文件中,存放的都是resize好的512×512的图片,命名格式最好像我这样
3. 准备好上述一切就可以开始标注了,点击软件左侧的 这是画任意多边形的按钮,鼠标左键点击进行标注,最后双击鼠标左键会锁定标注区域,出现如下图界面,第一次标注需输入名称,后续标注就自动显示了,点击ok后标注的线条变为红色,同时json文件夹也会相应保存和pic名字对应的json文件
全部标注结束后,使用如下代码将json数据提取出来并保存到train_image和train_label文件夹中,u-net部分的数据集原作者一共标注了1200多张,最终效果很棒,达到了定位的效果
标注好的图片进行分类
把路径改为自己的路径
import os
import cv2
import numpy as np
#将json文件label转换为到data文件夹
n=1200#n为总共标注的图片数
for i in range(n):os.system('labelme_json_to_dataset D:/desktop/labelme/json/%d.json -o D:/desktop/labelme/data/%d_json'%(i,i))
#dst_w=512
#dst_h=512
#dst_shape=(dst_w,dst_h,3)
train_image = 'D:/desktop/labelme/train_image/'
if not os.path.exists(train_image):os.makedirs(train_image)
train_label = 'D:/desktop/labelme/train_label/'
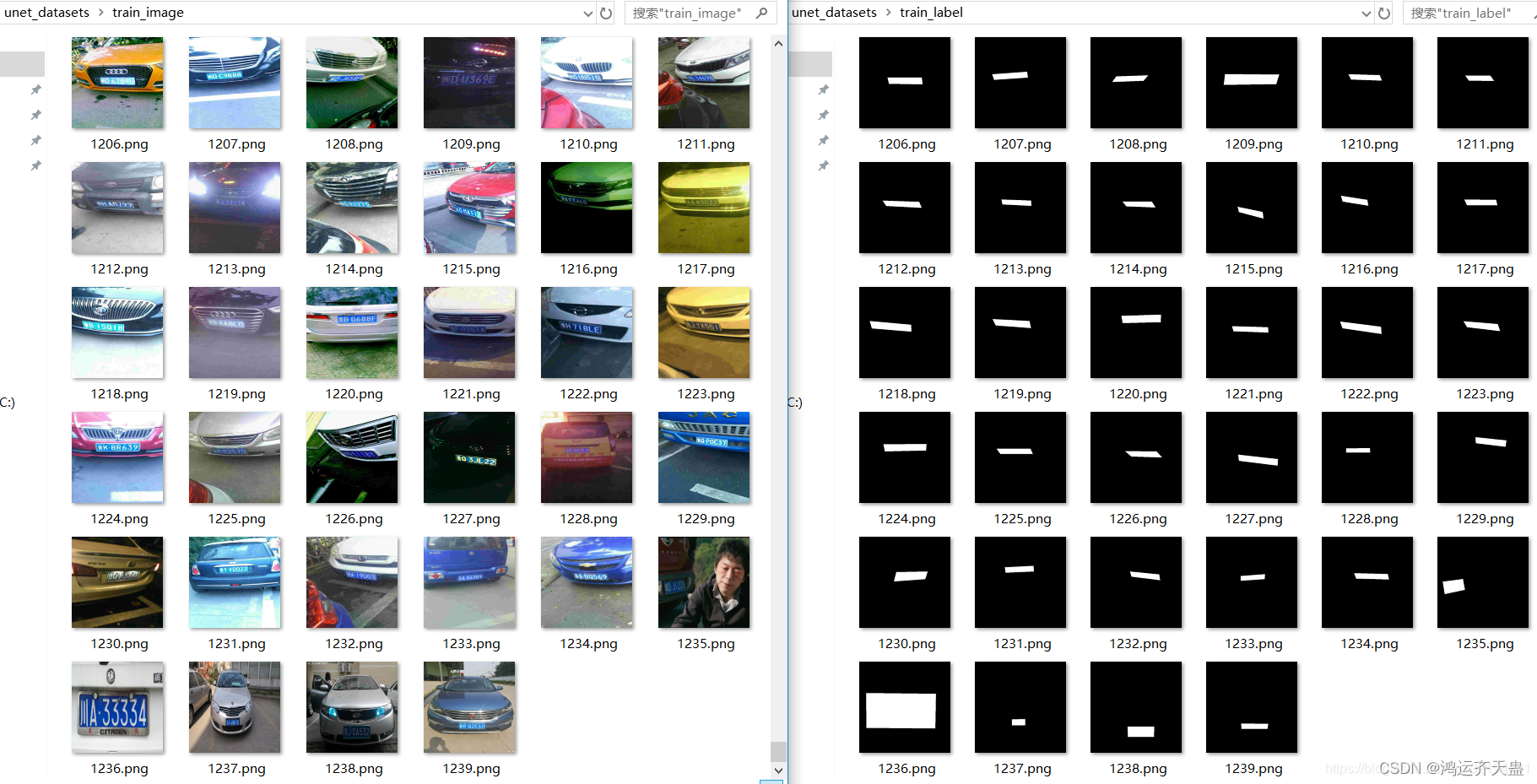
if not os.path.exists(train_label):os.makedirs(train_label)for i in range(n):print(i)img=cv2.imread('D:/desktop/labelme/data/%d_json/img.png'%i)label=cv2.imread('D:/desktop/labelme/data/%d_json/label.png'%i)print(img.shape)label=label/np.max(label[:,:,2])*255label[:,:,0]=label[:,:,1]=label[:,:,2]print(np.max(label[:,:,2]))# cv2.imshow('l',label)# cv2.waitKey(0)print(set(label.ravel()))cv2.imwrite(train_image+'%d.png'%i,img)cv2.imwrite(train_label+'%d.png'%i,label)这样一来,标注好的u-net训练图片就准备好了,分别在train_image和train_label文件夹中,一并放在unet_datasets文件夹内,如下图所示
接下来是u-net模型搭建和训练,使用tensorflow的keras实现,贴一下我训练u-net用的代码
def unet_train():height = 512width = 512path = 'D:/desktop/unet_datasets/'input_name = os.listdir(path + 'train_image')n = len(input_name)print(n)X_train, y_train = [], []for i in range(n):print("正在读取第%d张图片" % i)img = cv2.imread(path + 'train_image/%d.png' % i)label = cv2.imread(path + 'train_label/%d.png' % i)X_train.append(img)y_train.append(label)X_train = np.array(X_train)y_train = np.array(y_train)def Conv2d_BN(x, nb_filter, kernel_size, strides=(1, 1), padding='same'):x = layers.Conv2D(nb_filter, kernel_size, strides=strides, padding=padding)(x)x = layers.BatchNormalization(axis=3)(x)x = layers.LeakyReLU(alpha=0.1)(x)return xdef Conv2dT_BN(x, filters, kernel_size, strides=(2, 2), padding='same'):x = layers.Conv2DTranspose(filters, kernel_size, strides=strides, padding=padding)(x)x = layers.BatchNormalization(axis=3)(x)x = layers.LeakyReLU(alpha=0.1)(x)return xinpt = layers.Input(shape=(height, width, 3))conv1 = Conv2d_BN(inpt, 8, (3, 3))conv1 = Conv2d_BN(conv1, 8, (3, 3))pool1 = layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv1)conv2 = Conv2d_BN(pool1, 16, (3, 3))conv2 = Conv2d_BN(conv2, 16, (3, 3))pool2 = layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv2)conv3 = Conv2d_BN(pool2, 32, (3, 3))conv3 = Conv2d_BN(conv3, 32, (3, 3))pool3 = layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv3)conv4 = Conv2d_BN(pool3, 64, (3, 3))conv4 = Conv2d_BN(conv4, 64, (3, 3))pool4 = layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(conv4)conv5 = Conv2d_BN(pool4, 128, (3, 3))conv5 = layers.Dropout(0.5)(conv5)conv5 = Conv2d_BN(conv5, 128, (3, 3))conv5 = layers.Dropout(0.5)(conv5)convt1 = Conv2dT_BN(conv5, 64, (3, 3))concat1 = layers.concatenate([conv4, convt1], axis=3)concat1 = layers.Dropout(0.5)(concat1)conv6 = Conv2d_BN(concat1, 64, (3, 3))conv6 = Conv2d_BN(conv6, 64, (3, 3))convt2 = Conv2dT_BN(conv6, 32, (3, 3))concat2 = layers.concatenate([conv3, convt2], axis=3)concat2 = layers.Dropout(0.5)(concat2)conv7 = Conv2d_BN(concat2, 32, (3, 3))conv7 = Conv2d_BN(conv7, 32, (3, 3))convt3 = Conv2dT_BN(conv7, 16, (3, 3))concat3 = layers.concatenate([conv2, convt3], axis=3)concat3 = layers.Dropout(0.5)(concat3)conv8 = Conv2d_BN(concat3, 16, (3, 3))conv8 = Conv2d_BN(conv8, 16, (3, 3))convt4 = Conv2dT_BN(conv8, 8, (3, 3))concat4 = layers.concatenate([conv1, convt4], axis=3)concat4 = layers.Dropout(0.5)(concat4)conv9 = Conv2d_BN(concat4, 8, (3, 3))conv9 = Conv2d_BN(conv9, 8, (3, 3))conv9 = layers.Dropout(0.5)(conv9)outpt = layers.Conv2D(filters=3, kernel_size=(1, 1), strides=(1, 1), padding='same', activation='relu')(conv9)model = models.Model(inpt, outpt)model.compile(optimizer='adam',loss='mean_squared_error',metrics=['accuracy'])model.summary()print(np.max(X_train))print(np.max(y_train))print(X_train.shape)model.fit(X_train, y_train, epochs=100, batch_size=15)#epochs和batch_size看个人情况调整,batch_size不要过大,否则内存容易溢出#我11G显存也只能设置15-20左右,我训练最终loss降低至250左右,acc约95%左右model.save('unet.h5')print('unet.h5保存成功!!!')上述代码关键部分是要获取车牌四边形的四个顶点,一开始只使用cont中坐标到外接矩形四个端点的距离,发现对于倾斜度很高的车牌效果可能不佳,见下图,可以观察到,计算得到的4个黄色坐标中,左右有2个黄色点并不处在四边形的顶点位置,这样矫正效果大打折扣,同时也会影响后续的识别效果

发现上述问题后,我又想了个方法就是加入了上述的point_to_line_distance函数,即还计算坐标点到上下两条边的距离,并添加了权重,经过调整权重设置为0.975倍的点线距离,0.025点到端点距离时整体效果较佳,最终矫正效果如下图:

矫正效果大大改善后,识别率也将大大提高。
最终运行后上述代码后,提取的license文件夹中的车牌图如下:

2.车牌识别
我们的输入图片就是上述的宽240,高80的车牌图片,要实现车牌的端到端识别,显然是多标签分类问题,每张输入图片有7个标签,模型输出前的结构都是可以共享的,只需将输出修改为7个即可,7个输出对应了7个loss,总loss就是7个loss的和,使用keras可以很方便地实现,训练cnn的代码如下
def cnn_train():char_dict = {"京": 0, "沪": 1, "津": 2, "渝": 3, "冀": 4, "晋": 5, "蒙": 6, "辽": 7, "吉": 8, "黑": 9, "苏": 10,"浙": 11, "皖": 12, "闽": 13, "赣": 14, "鲁": 15, "豫": 16, "鄂": 17, "湘": 18, "粤": 19, "桂": 20,"琼": 21, "川": 22, "贵": 23, "云": 24, "藏": 25, "陕": 26, "甘": 27, "青": 28, "宁": 29, "新": 30,"0": 31, "1": 32, "2": 33, "3": 34, "4": 35, "5": 36, "6": 37, "7": 38, "8": 39, "9": 40,"A": 41, "B": 42, "C": 43, "D": 44, "E": 45, "F": 46, "G": 47, "H": 48, "J": 49, "K": 50,"L": 51, "M": 52, "N": 53, "P": 54, "Q": 55, "R": 56, "S": 57, "T": 58, "U": 59, "V": 60,"W": 61, "X": 62, "Y": 63, "Z": 64}# 读取数据集path = 'home/cnn_datasets/' # 车牌号数据集路径(车牌图片宽240,高80)pic_name = sorted(os.listdir(path))n = len(pic_name)X_train, y_train = [], []for i in range(n):print("正在读取第%d张图片" % i)img = cv2.imdecode(np.fromfile(path + pic_name[i], dtype=np.uint8), -1) # cv2.imshow无法读取中文路径图片,改用此方式label = [char_dict[name] for name in pic_name[i][0:7]] # 图片名前7位为车牌标签X_train.append(img)y_train.append(label)X_train = np.array(X_train)y_train = [np.array(y_train)[:, i] for i in range(7)] # y_train是长度为7的列表,其中每个都是shape为(n,)的ndarray,分别对应n张图片的第一个字符,第二个字符....第七个字符# cnn模型Input = layers.Input((80, 240, 3)) # 车牌图片shape(80,240,3)x = Inputx = layers.Conv2D(filters=16, kernel_size=(3, 3), strides=1, padding='same', activation='relu')(x)x = layers.MaxPool2D(pool_size=(2, 2), padding='same', strides=2)(x)for i in range(3):x = layers.Conv2D(filters=32 * 2 ** i, kernel_size=(3, 3), padding='valid', activation='relu')(x)x = layers.Conv2D(filters=32 * 2 ** i, kernel_size=(3, 3), padding='valid', activation='relu')(x)x = layers.MaxPool2D(pool_size=(2, 2), padding='same', strides=2)(x)x = layers.Dropout(0.5)(x)x = layers.Flatten()(x)x = layers.Dropout(0.3)(x)Output = [layers.Dense(65, activation='softmax', name='c%d' % (i + 1))(x) for i in range(7)] # 7个输出分别对应车牌7个字符,每个输出都为65个类别类概率model = models.Model(inputs=Input, outputs=Output)model.summary()model.compile(optimizer='adam',loss='sparse_categorical_crossentropy', # y_train未进行one-hot编码,所以loss选择sparse_categorical_crossentropymetrics=['accuracy'])# 模型训练print("开始训练cnn")model.fit(X_train, y_train, epochs=35) # 总loss为7个loss的和model.save('cnn.h5')print('cnn.h5保存成功!!!')
最终,训练集上准确率acc1(即车牌省份字符)为97%,其余字符均为99%左右,本地测试集准确率为97%,识别效果较佳。
最后放一下整体的效果图



转载于
基于u-net,cv2以及cnn的中文车牌定位,矫正和端到端识别软件_车牌图像增强-CSDN博客
相关文章:
车牌识别(附源代码)
完整项目已上传至github:End-to-end-for-chinese-plate-recognition/License-plate-recognition at master duanshengliu/End-to-end-for-chinese-plate-recognition GitHub 整体思路: 1.利用u-net图像分割得到二值化图像 2.再使用cv2进行边缘检测获得车牌区域坐…...

在VSCode中安装python
引言 Python 是一种广泛使用的高级编程语言,因其易学、易用、强大而受到欢迎。它由 Guido van Rossum 于 1991 年首次发布,并以简洁的语法和丰富的库生态系统而著称。 以下是 Python 的一些关键特点和优势: 关键特点 易于学习和使用&#x…...

StarkNet架构之L1-L2消息传递机制
文章目录 StarkNet架构之L1-L2消息传递机制L2 → L1消息L2 → L1消息结构L2 → L1消息哈希L1 → L2消息L1 → L2消息取消L1 → L2报文费用L1 → L2哈希额外资源StarkNet架构之L1-L2消息传递机制 原文地址:https://docs.starknet.io/architecture-and-concepts/network-archit…...

19.2 HTTP客户端-定制HTTP请求、调试HTTP、响应超时
1. 定制HTTP请求 如果需要对向服务器发送的HTTP请求做更多超越于默认设置的定制化。 client : http.Client{} 使用net/http包提供的导出类型Client,创建一个表示客户端的变量。request, err : http.NewRequest("GET", "https://ifconfig.io/ip&quo…...

KafkaQ - 好用的 Kafka Linux 命令行可视化工具
软件效果前瞻 ~ 鉴于并没有在网上找到比较好的linux平台的kafka可视化工具,今天为大家介绍一下自己开发的在 Linux 平台上使用的可视化工具KafkaQ 虽然简陋,主要可以实现下面的这些功能: 1)查看当前topic的分片数量和副本数量 …...

不愧是字节,图像算法面试真细致
这本面试宝典是一份专为大四、研三春招和研二暑假实习生准备的珍贵资料。 涵盖了图像算法领域的核心知识和常见面试题,包括卷积神经网络、实例分割算法、目标检测、图像处理等多个方面。不论你是初学者还是有经验的老手,都能从中找到实用的内容。 通过…...

14、C++中代码重用
1、C模板的主要作用是允许编写通用代码,即能够在不同数据类型或数据结构上工作而无需重复编写代码。通过模板,可以实现代码的复用性和灵活性,从而提高开发效率和程序的可维护性。 typename关键字: 在C中,typename关键…...
剖析框架代码结构的系统方法(下)
当面对Dubbo、Spring Cloud、Mybatis等开源框架时,我们可以采用一定的系统性的方法来快速把握它们的代码结构。这些系统方法包括对架构演进过程、核心执行流程、基础架构组成和可扩展性设计等维度的讨论。 在上一讲中,我们已经讨论了架构演进过程和核心执行流程这两个系统方法…...
C语言学习笔记之结构体(一)
目录 什么是结构体? 结构体的声明 结构体变量的定义和初始化 结构体成员的访问 结构体传参 什么是结构体? 在现实生活中的很多事物无法用单一类型的变量就能描述清楚,如:描述一个学生,需要姓名,年龄&a…...

MATLAB入门知识
目录 原教程链接:数学建模清风老师《MATLAB教程新手入门篇》https://www.bilibili.com/video/BV1dN4y1Q7Kt/ 前言 历史记录 脚本文件(.m) Matlab帮助系统 注释 ans pi inf无穷大 -inf负无穷大 i j虚数单位 eps浮点相对精度 0/&a…...
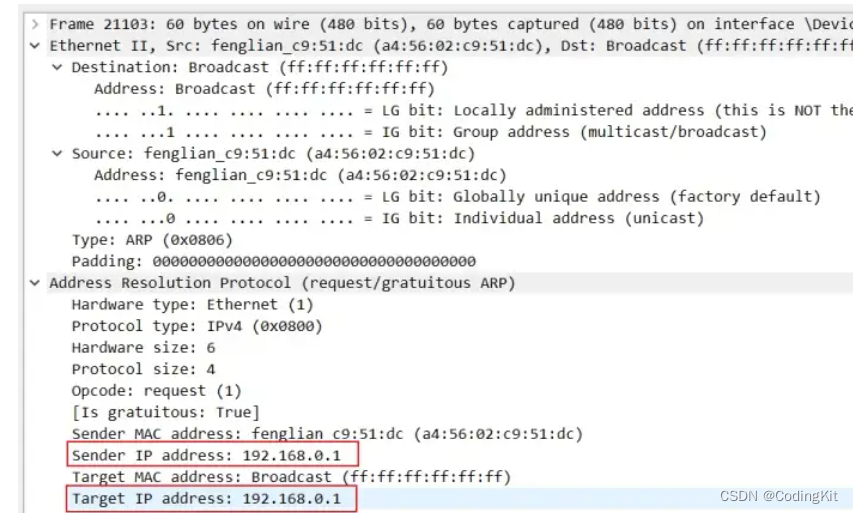
计算机网络(5) ARP协议
什么是ARP 地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定…...

美团的 AI 面试有点简单
刷到一个美团的 AI 实习生的面试帖子,帖子虽然不长,但是把美团 AI 评测算法实习生面试的问题都po出来了。 单纯的看帖子中面试官提出的问题,并不是很难,大部分集中在考察AI项目和对AI模型的理解上,并没有过多的考察AI算…...

编程软件怎么给机器人编程:深入探索编程与机器人技术的融合
编程软件怎么给机器人编程:深入探索编程与机器人技术的融合 随着科技的飞速发展,机器人技术已经深入到我们生活的方方面面。而要让机器人按照我们的意愿执行任务,就需要借助编程软件对机器人进行编程。那么,编程软件究竟是如何给…...

unity2d Ugui--Image城市道路汽车行驶
目录 1.车辆生成与回收 2.路径点控制 3.车辆控制 1.车辆生成与回收 using System.Collections.Generic; using UnityEngine;public class RoadContr : MonoBehaviour {public WayPoint[] wayPoints; //出生点public Transform pare;[SerializeField]private Car[] fabCar;pu…...

【深度学习】【Prompt】使用GPT的一些提示词
f翻译论文用这个提示词: # 翻译规则## 翻译规则1 请在翻译这篇学术论文时,严格保留所有专业术语的原始英文表述,不要尝试将它们翻译成中文,而不是专业术语的部分,需要翻译为中文。保持所有文章引用格式和内容的完整无…...

如何在centos中和windows server中找到挖矿木马和消灭挖矿木马
在 CentOS 和 Windows Server 中查找和消灭挖矿木马涉及多个步骤,包括检测、清理和预防。以下是具体的步骤和命令。 在 CentOS 中查找和消灭挖矿木马 步骤 1:检测木马 检查异常进程: ps aux | grep -E miner|cryptonight|xmrig查找进程列表…...

Slice用法举例Python
Slice用法举例Python 在Python中,slice(切片)是一个强大的工具,用于处理序列类型的数据,如列表、元组、字符串等。slice提供了一种简洁而高效的方式来获取序列的子集或修改序列的某些部分。下面,我们将从四…...

响应式网页开发方法与实践
随着移动设备的普及和多样化,响应式网页开发已成为现代网页设计的主流趋势。响应式网页(Responsive Web Design, RWD)是一种网页设计技术,其核心思想是通过灵活的布局和媒体查询,使网页能够适应不同设备和屏幕尺寸&…...

feedparser - Python 解析Atom和RSSfeed
文章目录 一、关于 feedparser二、安装三、关于文档及构建四、测试五、常见RSS元素访问常见 Channel 元素访问常用项目元素 六、常见Atom元素访问常用feed元素访问公共入口元素 七、获取Atom元素的详细信息Feed元素的详细信息 八、测试元素是否存在九、其他功能 & 文档高级…...

ARM32开发--IIC时钟案例
知不足而奋进 望远山而前行 目录 文章目录 前言 目标 内容 需求 开发流程 移植驱动 修改I2C实现 测试功能 总结 前言 在现代嵌入式系统开发中,移植外设驱动并测试其功能是一项常见的任务。本次学习的目标是掌握移植方法和测试方法,以实现对开…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...