集成学习 #数据挖掘 #Python
集成学习是一种机器学习方法,它通过结合多个模型的预测结果来提高整体性能和稳定性。这种方法的主要思想是“集合智慧”,通过将多个模型(比如决策树、随机森林、梯度提升机等)的预测集成起来,可以减少单个模型的过拟合风险,同时提高对未知数据的泛化能力。
集成学习主要有两种主要形式:
- bagging(自助法/Bootstrap aggregating):这种方法创建多个训练集,每个训练集由原始数据随机抽取并保持数据的多样性。然后,对每个子集训练独立的模型,最后将它们的预测结果取平均或投票来得出最终结果。
- boosting:这是一种迭代过程,每次训练时专注于那些被前一轮错误分类的样本。 AdaBoost、Gradient Boosting Machine (GBM) 等就是典型的 boosting 方法。它们逐步提高弱模型的权重,形成一个强健的组合模型。
优点:
- 提高准确性和稳定性:通过集成多个模型,降低了单个模型失效带来的影响。
- 减少过拟合:由于模型之间有竞争,它们可能不会过度拟合特定的训练数据。
- 可以处理各种类型的数据:包括数值型、分类型和非结构化数据。
集成学习在以下情况下特别有效:
- 处理复杂数据:当数据集包含多个特征和复杂的非线性关系时,集成方法如随机森林或梯度提升机能够通过组合多个模型的结果提高预测精度。
- 减少过拟合:通过结合多个基础模型,集成学习可以降低单个模型过拟合的风险,因为每个模型可能学习到数据的不同部分。
- 提高稳定性和鲁棒性:集成学习模型通常比单个模型更稳定,即使其中一个模型表现不佳,整体性能也往往不会受到太大影响。
- 利用不同学习算法的优势:可以将弱学习器组合成强学习器,如AdaBoost将弱分类器逐步调整以关注难以分类的数据。
- 数据不平衡问题:集成方法能更好地处理类别分布不均的数据,通过加权或平衡采样等方式,提高少数类别的预测能力。
- 模型融合:例如,通过投票、平均等方式,将不同的模型预测结果整合起来,提高最终决策的可靠性。
应用案例:信用卡还贷情况预测。
数据获取(UCI_Credit_Card.csv) 30000 行客户等还款记录,有 25 列,包含客户的基本信息,每月的 还款记录,以及需要我们预测的目标—是否违约。
首先加载数据集,查看数据集概况,并做数据清洗:
1)EDUCATION(教育背景):将其中值为 0,5,6 的样本对应值修改为 4
2)MARRIAGE(婚姻状况):0 值的样本修改为 3
#加载数据
import pandas as pd
data = pd.read_csv('UCI_Credit_Card.csv')
#查看数据概况
data.info()
#数据清洗
#将'EDUCATION'列中值为0,5,6,改为4
data['EDUCATION'].replace({0:4,5:4,6:4},inplace=True)
#将'MARRIAGE'列中值为0,改为3
data['MARRIAGE'].replace({0:3},inplace=True)#划分特征集和类别集
x = data.iloc[:,1:-1]
y = data.iloc[:,-1]
#划分数据集
from sklearn import model_selection
x_train,x_test,y_train,y_test = model_selection.train_test_split(x,y,test_size=0.2,random_state=1)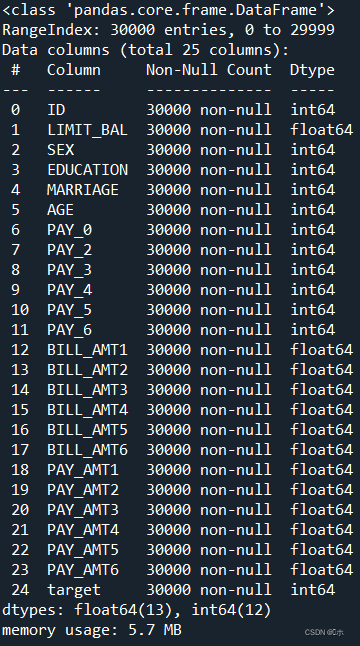
通过.info查看数据集概况可知,该数据集有25个属性列,共30000个样本数据。没有缺失值,最后一个属性列“target”为下个月还款违约情况
建立预测集成训练模型:
1、Bagging集成模型
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import BaggingClassifier
bagging = BaggingClassifier(KNeighborsClassifier(),max_samples=0.5,max_features=0.5)
bagging.fit(x_train,y_train)
pred1 = bagging.predict(x_test)
from sklearn.metrics import classification_report
#输出:Accuracy、Precisio、Recall、F1分数等信息
print('bagging模型评估报告:\n',classification_report(y_test,pred1))
print('bagging模型的准确率为:',bagging.score(x_test,y_test))#计算AUC得分
y_predict_proba_1 = bagging.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_1, tpr_1, thretholds_1 = roc_curve(y_test, y_predict_proba_1[:,1])
from sklearn.metrics import auc
AUC_1 = auc(fpr_1,tpr_1)
print('ROC曲线下面积AUC为:',AUC_1)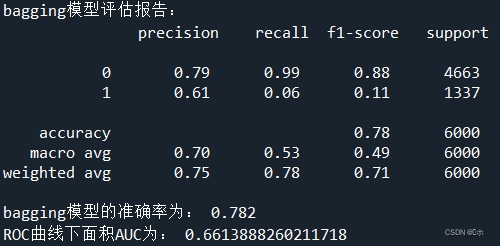
指标说明:
Accuracy:准确率
Precisio:查准率 、精确率
Recall:查全率 、召回率、敏感率、真正例率
F1分数:衡量分类模型精确度的一个指标,可视为精确率和召回率的一种调和平均
2、Random Forest集成模型
from sklearn.ensemble import RandomForestClassifier
RF = RandomForestClassifier()
RF.fit(x_train,y_train)
pred2 = RF.predict(x_test)
print('RandomFore模型评估报告:\n',classification_report(y_test,pred2))
print('RandomFore模型的准确率为:',RF.score(x_test,y_test))#计算AUC得分
y_predict_proba_2 = RF.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_2, tpr_2, thretholds_2 = roc_curve(y_test, y_predict_proba_2[:,1])
from sklearn.metrics import auc
AUC_2 = auc(fpr_2,tpr_2)
print('ROC曲线下面积AUC为:',AUC_2)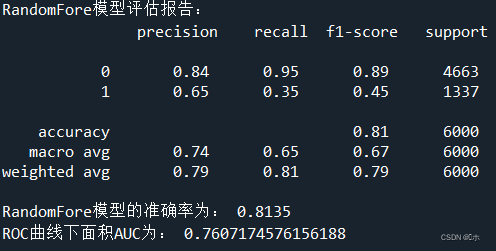
3、AdaBoost集成模型
from sklearn.ensemble import AdaBoostClassifier
AB = AdaBoostClassifier(n_estimators = 10)
AB.fit(x_train,y_train)
pred3 = AB.predict(x_test)
print('AdaBoost模型评估报告:\n',classification_report(y_test,pred3))
print('AdaBoost模型的准确率为:',AB.score(x_test,y_test))#计算AUC得分
y_predict_proba_3 = AB.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_3, tpr_3, thretholds_3 = roc_curve(y_test, y_predict_proba_3[:,1])
from sklearn.metrics import auc
AUC_3 = auc(fpr_3,tpr_3)
print('ROC曲线下面积AUC为:',AUC_3)
#特征重要性
impotrances = RF.feature_importances_
#模型参数
RF.get_params()#模型验证交叉验证
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import cross_val_score
clf = AdaBoostClassifier(n_estimators=30)
scores = cross_val_score(clf,x,y,cv=10)
scores.mean()
4、决策树
from sklearn.tree import DecisionTreeClassifier
dct = DecisionTreeClassifier()
dct.fit(x_train,y_train)
pred4 = dct.predict(x_test)
print('决策树 模型评估报告:\n',classification_report(y_test,pred4))
print('决策树 模型的准确率为:',dct.score(x_test,y_test))#计算AUC得分
y_predict_proba_4 =dct.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_4, tpr_4, thretholds_4 = roc_curve(y_test, y_predict_proba_4[:,1])
from sklearn.metrics import auc
AUC_4 = auc(fpr_4,tpr_4)
print('ROC曲线下面积AUC为:',AUC_4)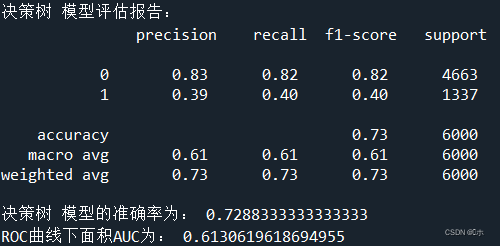
对四个模型测试结果ROC曲线对比:
import matplotlib
import matplotlib.pyplot as pltplt.rcParams['font.family'] = ['SimHei'] #用来显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示符号matplotlib.rc('axes', facecolor = 'white') #设置背景颜色是白色
matplotlib.rc('font', size = 14) #全局设置字体
matplotlib.rc('figure', figsize = (12, 8)) #全局设置大小
matplotlib.rc('axes', grid = True) #显示网格fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(fpr_1,tpr_1,'d:y',linestyle = 'dashed',label = 'bagging--AUC=%0.4f'%auc(fpr_1,tpr_1))
ax.plot(fpr_2,tpr_2,'s:r',linestyle = 'dashed',label = 'RandomFore --AUC=%0.4f'%auc(fpr_2,tpr_2))
ax.plot(fpr_3,tpr_3,'v:b',linestyle = 'dashed',label = 'AdaBoost--AUC=%0.4f'%auc(fpr_3,tpr_3))
ax.plot(fpr_4,tpr_4,'o:k',linestyle = 'dashed',label = 'decision tree--AUC=%0.4f'%auc(fpr_4,tpr_4))
ax.legend(loc = 'best')
plt.title('测试结果 ROC曲线对比')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.savefig('测试结果 ROC曲线对比.png')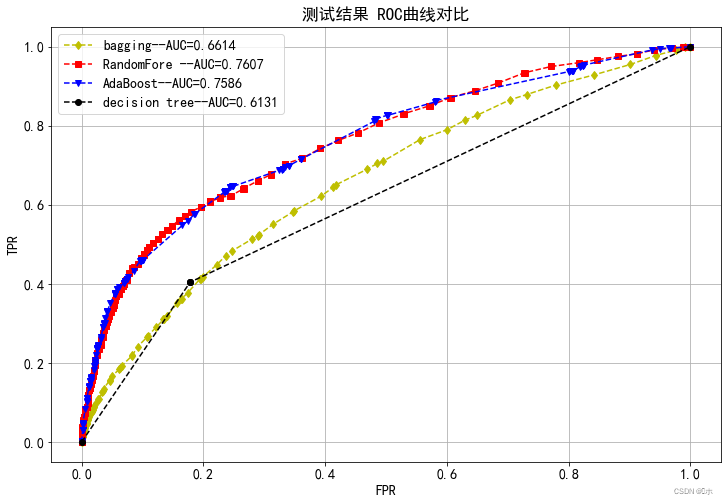
通过以上结果可以总结出:
| 模型 | 测试结果 | |||
| accuracy | precision(macro avg) | recall(macro avg) | AUC | |
| bagging | 0.78 | 0.7 | 0.53 | 0.6587 |
| Random Forest | 0.81 | 0.74 | 0.65 | 0.7594 |
| AdaBoost | 0.81 | 0.76 | 0.63 | 0.7586 |
| 决策树 | 0.72 | 0.6 | 0.61 | 0.609 |
可以看出四种模型中,随机森林和AdaBoost两个模型得到的结果在各个性能评估指标上都明显地优于baging和决策树。
随机森林和AdaBoost两个模型的各个指标都十分的相近,两模型之间的性能几乎没有什么差别;而baging和决策树两个模型之间,bagging的各个性能评估指标略微地优于决策树。
由此得出:最优的模型是随机森林和AdaBoost,其次是bagging,最后是决策树。
相关文章:
集成学习 #数据挖掘 #Python
集成学习是一种机器学习方法,它通过结合多个模型的预测结果来提高整体性能和稳定性。这种方法的主要思想是“集合智慧”,通过将多个模型(比如决策树、随机森林、梯度提升机等)的预测集成起来,可以减少单个模型的过拟合…...

IDEA 中设置 jdk 的版本
本文介绍一下 IDEA 中设置 jdk 版本的步骤。 一共有三处需要配置。 第一处 File --> Project Structure Project 和 Modules 下都需要指定一下。 第二处 File --> Settings 第三处 运行时的配置...

AI日报|Luma推出AI视频模型,又一Sora级选手登场?SD3 Medium发布,图中文效果改善明显
文章推荐 AI日报|仅三个月就下架?微软GPT Builder出局AI竞争赛;马斯克将撤回对奥特曼的诉讼 谁是最会写作文的AI“考生”?“阅卷老师”ChatGPT直呼惊艳! ⭐️搜索“可信AI进展“关注公众号,获取当日最新…...

嵌入式系统复习(一)
第一章 嵌入式系统的定义、特点 嵌入式系统是以应用为中心,以计算机技术为基础,软件硬件可裁剪,适应应用系统对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。 特点:嵌入性 专用性 计算机系统 嵌入式系统典型组成…...
一次搞定:Java中数组拷贝VS数组克隆
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一…...

Java多线程编程与并发处理
引言 在现代编程中,多线程和并发处理是提高程序运行效率和资源利用率的重要方法。Java提供了丰富的多线程编程支持,包括线程的创建与生命周期管理、线程同步与锁机制、并发库和高级并发工具等。本文将详细介绍这些内容,并通过表格进行总结和…...

C++ 35 之 对象模型基础
#include <iostream> #include <string.h> using namespace std;class Students05{ public:// 只有非静态成员变量才算存储空间,其他都不算int s_a; // 非静态成员变量,算对象的存储空间double s_c;// 成员函数 不算对象的存储空间void f…...

PHP超级全局变量:功能、应用及最佳实践
PHP中的超级全局变量(Superglobal Variables)是预定义的数组,它们在脚本的全部作用域内都可以访问,无需使用global关键字。超级全局变量包含了关于请求、会话、服务器等各种信息,常见的有$_GET、$_POST、$_REQUEST、$_…...

python在windows创建的文件,换成linux系统格式
python在windows创建的文件,换成linux系统格式 dos2unix.exe的下载(下载的文件放入路径下:C:\Windows\System32) 链接:https://pan.baidu.com/s/10fC2tfvUtbh-axJ21cj_Xw?pwdm3zc 提取码:m3zc 批量修改文件格式 import subpr…...

最新区块链论文速读--CCF A会议 ICSE 2024 共13篇 附pdf下载 (2/2)
Conference:International Conference on Software Engineering (ICSE) CCF level:CCF A Categories:Software Engineering/System Software/Programming Languages Year:2024 Num:13 第1~7篇区块链文章请点击此处…...

C++ 34 之 单例模式
#include <iostream> #include <string.h> using namespace std;class King{// 公共的函数,为了让外部可以获取唯一的实例 public:// getInstance 获取单例 约定俗成static King* getInstance(){return true_king;}private: // 私有化// 构造函数设置为…...

SAP BW:传输转换源系统-源系统映射关系
最近有朋友再问问我源系统映射关系怎么配置,想着写一个怕以后忘了。 简单说下这个是干嘛的,其实就是配置一个源系统到目标系统的一个映射,这样传输的时候才知道传过来的数据源要变成目标系统的数据源。 比如下图,在开发环境&…...
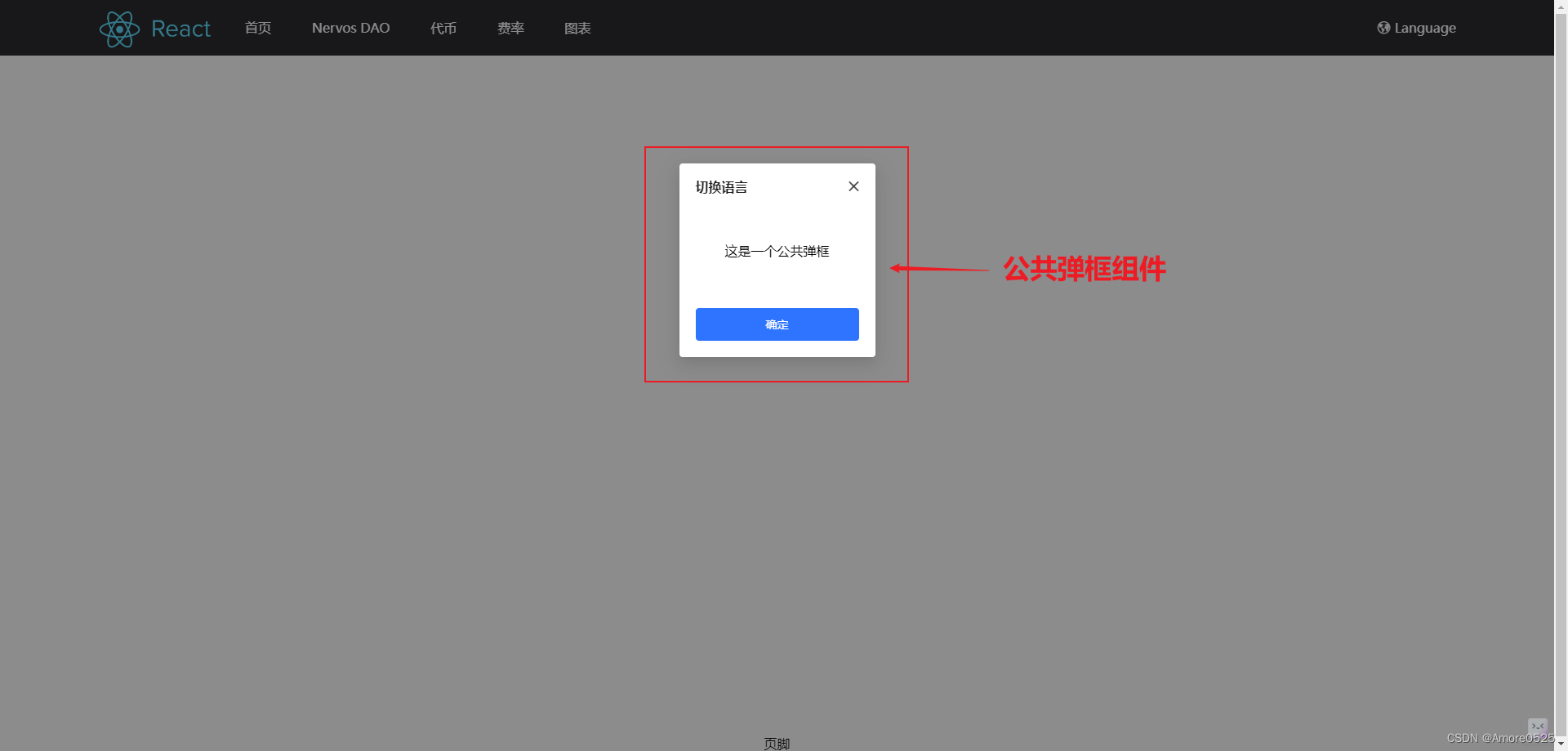
React+TS前台项目实战(九)-- 全局常用组件弹窗Dialog封装
文章目录 前言Dialog公共弹窗组件1. 功能分析2. 代码详细注释3. 使用方式4. 效果展示 总结 前言 今天这篇主要讲全局公共弹窗Dialog组件封装,将用到上篇封装的模态框Modal组件。有时在前台项目中,偶尔要用到一两个常用的组件,如 弹窗&#x…...

利用视觉分析技术提升水面漂浮物、水面垃圾检测效率
随着城市化进程的加速和工业化的发展,水体污染问题日益严重,水面漂浮物成为水环境治理的一大难题。传统的水面漂浮物检测方法主要依赖人工巡查和简单的传感器检测,存在着效率低、准确率不高等问题。为了提升水面漂浮物检测的效率和准确性&…...

NFT 智能合约实战-快速开始(1)NFT发展历史 | NFT合约标准(ERC-721、ERC-1155和ERC-998)介绍
文章目录 NFT 智能合约实战-快速开始(1)NFT发展历史国内NFT市场国内NFT合规性如何获得NFT?如何查询NFT信息?在 OpenSea 上查看我们的 NFT什么是ERC721NFT合约标准ERC-721、ERC-1155和ERC-998 对比ERC721IERC721.sol 接口内容关于合约需要接收 ERC721 资产 onERC721Received…...

Linux知识整理说明
最近学校Linux课程刚刚结课,但还是有其他课程在继续。 所以接下来我会抽时间,根据笔记以及网络资料,整理和Linux相关的知识文档,各位可以后续留意. 完整的章目录我会先发出来,后续补充完整。 所有的内容会在 下周三(6…...

诊所管理系统哪家会好一点
随着医疗行业的快速发展和信息化进程的加速,诊所作为医疗服务的重要基层单位,其运营管理效率与服务质量的提升愈发依赖于现代化的管理工具。诊所管理系统应运而生,旨在通过集成化、智能化的技术手段,帮助诊所实现诊疗流程优化、资…...

前端根据权限生成三级路由
三级菜单和后端返回数组对比获取有权限的路由 数组: //后端返回的数组 const arr1 [sale.management, sale.order, sale.detail]; //前端路由 const arr2 [{path: "/sale-manage",redirect: "/sale-manage/sale-order/sale-list",name: sale…...

Databricks超10亿美元收购Tabular;Zilliz 推出 Milvus Lite ; 腾讯云支持Redis 7.0
重要更新 1. Databricks超10亿美元收购Tabular,Databricks将增强 Delta Lake 和 Iceberg 社区合作,以实现 Lakehouse 底层格式的开放与兼容([1] [2])。 2. Zilliz 推出 Milvus Lite 轻量级向量数据库,支持本地运行;Milvus Lite 复…...

算法day29
第一题 695. 岛屿的最大面积 本题解法:采用bfs的算法; 本题使用象限数组的遍历方法和定义布尔数组vis来遍历每一个元素的上下左右元素,防治被遍历的元素被二次遍历; 本题具体分析如上题故事,但是由于要求区域的最大面…...

替换背景颜色怎么操作?2026年最全免费工具推荐与详细教程
最近有很多粉丝问我:替换背景颜色怎么操作?特别是做电商、制作证件照、处理产品图的朋友,都在寻找一个既简单又好用的解决方案。今天我就把自己用过的所有工具和方法整理出来,手把手教你替换背景颜色,让你的图片瞬间变…...

2025届学术党必备的六大AI辅助写作工具推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 一类基于自然语言处理技术的智能工具,是AI写作软件,它能够辅助用户自…...

别再为组图排版发愁了!用AI+PS搞定SCI论文配图,附赠期刊常用尺寸模板
科研论文组图排版实战:从零到期刊标准的AIPS全流程指南 第一次准备SCI论文投稿的研究生们,往往会在实验数据和图表制作上花费大量精力,却在最后的组图排版环节手足无措。我曾见过一位同学,花了三个月完成的精美实验结果图…...

PX4-Autopilot系统调用与API接口深度解析:构建自主飞行系统的技术架构
PX4-Autopilot系统调用与API接口深度解析:构建自主飞行系统的技术架构 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot PX4-Autopilot作为开源无人机飞控软件的标杆,其核心价…...

Elasticsearch Ruby 安全配置:API Key 认证与权限控制
Elasticsearch Ruby 安全配置:API Key 认证与权限控制 【免费下载链接】elasticsearch-ruby Ruby integrations for Elasticsearch 项目地址: https://gitcode.com/gh_mirrors/el/elasticsearch-ruby Elasticsearch Ruby 客户端是连接 Ruby 应用与 Elasticse…...

手把手教你用EWSA汉化版破解WiFi密码:从抓包到跑包的完整避坑指南
无线网络安全实践:从零掌握WPA/WPA2密码验证原理与防护策略 在数字化生活高度普及的今天,无线网络已成为我们日常生活和工作中不可或缺的基础设施。无论是家庭环境中的智能设备互联,还是咖啡厅里的移动办公,稳定的WiFi连接都扮演着…...

STM32F103ZE标准库SPI驱动PMW3901光流模块:从硬件连接到数据读取的保姆级教程
STM32F103ZE标准库SPI驱动PMW3901光流模块实战指南 第一次接触STM32和光流模块时,面对密密麻麻的引脚和寄存器配置,确实容易让人望而生畏。但别担心,这篇教程会带你从零开始,一步步完成硬件连接、SPI配置、寄存器初始化到最终数据…...

LangBot:企业级智能对话机器人构建平台实战指南
1. 项目概述:从零到一,构建企业级智能对话机器人如果你正在为 Slack、Discord 或者企业微信里的客服问题头疼,或者想给团队内部搞一个能查文档、能跑流程的智能助手,但又不想从零开始造轮子,那你来对地方了。LangBot 这…...

通过 OpenClaw 配置快速接入 Taotoken 开启你的 AI Agent 工作流
通过 OpenClaw 配置快速接入 Taotoken 开启你的 AI Agent 工作流 1. 准备工作 在开始配置之前,请确保已安装 OpenClaw 工具并拥有 Taotoken 平台的 API Key。您可以在 Taotoken 控制台的「API 密钥」页面创建新的密钥,并在「模型广场」查看可用的模型 …...

Docker容器化RouterOS部署指南:从原理到实战应用
1. 项目概述与核心价值最近在折腾家庭网络和边缘计算环境,一个绕不开的需求就是需要一个稳定、可编程、且资源占用极低的网络核心。无论是想搭建一个软路由,还是需要一个轻量级的网络测试沙盒,又或者是在云服务器上模拟复杂的网络拓扑&#x…...