Hive的存储格式和压缩算法的特点和选择
1、数据存储格式:
①TEXTFILE
HIVE 中默认的存储格式;
一般使用在数据贴源层(ODS 或 STG) ,针对需要使用脚本 LOAD 加载数据到 HIVE 数仓表中的情况;需要把表里数据导出或直接可以查看等场景,作为BI供数
易读性要比 ORC 高很多;
数据存储时不压缩,因此磁盘的开销和数据解析开销比较大;
TEXTFILE 可以结合 Gzip、Bzip2 等压缩算法使用(系统自动检查,执行查询时自动解压),但使用这种方式,HIVE 不会对数据进行切分,从而无法对数据进行并行操作;
在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比 SequenceFile 高几十倍;
可以直接通过 LOAD 的方式从文件中加载数据到 HIVE 表中;
当用户的数据文件格式不能被当前 HIVE 所识别的时候,可以自定义文件格式
通过实现 inputformat 和 outputformat 来自定义输入输出格式
②SEQUENCE FILE
HADOOP API 提供的一种二进制文件,以 key-value 的形式序列化到文件中;
支持切片;
数据加载导入方式可以通过INSERT方式加载数据;
③PARQUET
面向列的二进制文件格式,所以是不可以直接读取的;
文件中包括该文件的数据和元数据,因此 Parquet 格式文件是自解析的;
使用场景在 Impala 和 Hive 共享数据和元数据的场景;
④ORCFILE
运用 ORC 可以提高 HIVE 的读、写、计算的性能,主要使用在 DWD、DWB、DWS 层
数据按行分块,每块按照列存储;
压缩快、快速列存取;
效率比 rcfile 高,是 rcfile 的改良版本;
不考虑 ORC 的场景:需要通过 LOAD 方式加载数据到表里;需要把表里数据导出或直接可以查看等场景,这两种场景更适合使用 TEXTFILE ,易读性要比 ORC 高很多;
ORC 文件格式可以使用 HIVE 自带的命令 concatenate 快速合并小文件
在 Hive 中使用 ORC 文件格式时,是自动实现文件的分割(splitting)。这是因为 ORC 文件格式是为优化大规模数据处理而设计的,其中包括了有效的数据分割机制以支持并行处理。以下是一些关于 ORC 文件分割的关键点:
1. 块与条带(Stripes)
ORC 文件将数据分成多个条带(Stripes),每个条带都是自包含的数据集合,包括其自己的索引、数据和行索引。这些条带是分割数据的物理单位,可以独立于其他条带处理,支持并行读取和查询。
2. 文件的索引
每个 ORC 文件包含一个轻量级的文件尾部索引,其中包含有关文件中数据的统计信息和条带位置的详细信息。这使得查询引擎能够有效地确定哪些条带需要读取以满足特定的查询条件,从而实现快速的数据访问。
3. 分割与并行处理
当 Hive 执行查询时,它会根据数据的存储位置和条带信息自动对 ORC 文件进行分割。每个数据分割可以分配给不同的处理节点进行并行处理。这种分割机制允许 Hive 在多个处理节点上有效地分配工作,从而优化查询性能和减少数据处理时间。
4. 设置条带大小和行索引间隔
虽然分割机制自动运作,但你可以通过设置条带大小和行索引间隔来优化性能。例如,可以在创建表时通过以下方式设置条带大小和行索引间隔:
CREATE TABLE my_table (column1 INT,column2 STRING
)
STORED AS ORC
TBLPROPERTIES ("orc.stripe.size"="67108864", -- 设置条带大小为64MB"orc.row.index.stride"="10000", -- 设置行索引间隔"orc.compress"="SNAPPY" -- 设置压缩算法为SNAPPY
);| 存储格式 | 是否默认 | 存储方式 | 支持压缩算法 |
|---|---|---|---|
| TextFile | 是 | 行式存储 | Gzip、Bzip2 |
| SequenceFile | 否 | 行式存储 | NONE、RECORD、BLOCK |
| Parquet | 否 | 列式存储 | Uncompress(默认)、Snappy、Gzip、Lzo |
| RCFile | 否 | 数据按行分块,每块按列存储 | - |
| (RCFile的优化)ORCFile | 否 | 数据按行分块,每块按列存储 | NONE、ZLIB(默认)、SNAPPY |
2、压缩算法
文件存储格式不同对应不同的压缩算法,从而带来不同的性能,我们根据实际使用考虑压缩算法的性能,
主要通过以下 3 个指标:
① 压缩比
压缩比越高,压缩后文件越小,所以压缩比越高越好;
压缩比越高,存储磁盘空间占用越小,可以降低单节点的磁盘IO,同时可以减少占用的带宽;
② 压缩时间
越快越好,加快数据在Hadoop集群流动的速度和磁盘 IO 的速度
③ 压缩后的文件是否可以再分割
可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的 并行化
| 压缩方式 | 压缩比 | 压缩速度 | 解压缩速度 | 是否可分割 |
| gzip | 13.4% | 21 MB/s | 118 MB/s | 否,无法并行处理 |
| bzip2 | 13.2% | 2.4MB/s | 9.5MB/s | 是,并行处理 |
| LZO | 20.5% | 135 MB/s | 410 MB/s | 是,并行处理 |
| snappy | 22.2% | 172 MB/s | 409 MB/s | 否,无法并行处理 |
3、使用场景
ODS 贴源层 : TextFile + Gzip
DWD : ORC + SNAPPY
DWS : ORC + SNAPPY
① 数据量较大
如果单个文件比较大,可以使用 Parquet 存储,LZO压缩,可以避免由于读取不可分割大文件引发的数据倾斜。
Parquet 的特性:
更高效的压缩和编码策略:Parquet 对于数据的编码和压缩有着高度优化,特别是对于重复数据的处理。
它使用多种压缩技术和编码策略,如字典编码、RLE(Run-Length Encoding)和Delta 编码,这些都有助于减少数据存储量并提升读取性能。
这种优化使得即使是大文件,数据的物理存储尺寸也可能相对更小,且读取效率更高。
更细粒度的索引:Parquet 文件提供了详尽的元数据和索引,例如 min/max 索引,这可以极大地加速查询性能,因为它允许在读取数据前快速跳过不符合查询条件的数据块。
这对于大文件尤为重要,因为它减少了需要处理的数据量,从而提高了处理速度。
更灵活的列裁剪和数据访问:由于 Parquet 是列式存储,它允许只加载查询所需的列,这称为列裁剪。
这种能力在处理含有大量列的大文件时非常有用,因为它可以显著减少I/O负载和提升查询响应时间。
更好的集成和优化支持:Parquet 在现代数据处理框架中,如 Apache Spark 和 Databricks 等,获得了广泛的支持和优化。
这些框架针对 Parquet 进行了大量优化,使其在这些环境中处理大型数据文件时表现更佳。
效率与性能的平衡:虽然 Parquet 的写操作可能比 ORC 慢,它在读取操作上通常更高效,特别是在需要高度优化查询的分析型工作负载中。
这种读取性能上的优势在处理大数据文件时尤为重要,因为它可以显著减少查询时间和计算资源的消耗。
因此,尽管 ORC 和 Parquet 都有各自的优势和使用场景,但在处理单个大文件方面,Parquet 在很多情况下因其更精细的数据访问控制、更有效的数据压缩和编码,以及更好的读取性能而更受青睐。这使得它在数据分析和大规模数据处理中,尤其是在需要频繁读取的场景中,成为更合适的选择。
② 计算逻辑比较少
使用 ORC 存储 + ZLIB 压缩,可以尽量减少占用存储空间
③ 计算逻辑比较多
使用 ORC 存储 + SNAPPY 压缩,可以提高读写速度,从而提高整体计算性能
在 Hive 中,对于计算逻辑比较多且要求计算速度达到最佳状态的场景,选择 ORC 存储格式是明智的,因为 ORC 格式具备高效的列存储和强大的压缩功能,能够显著提高查询性能。
然而,在压缩算法的选择上,虽然 SNAPPY 和 LZO 各有优劣,但选择的依据需要综合考虑多个因素。
3.1 ORC + SNAPPY 的优势
快速压缩和解压缩:
SNAPPY 以其快速的压缩和解压缩速度著称。对于频繁的读写操作,快速的解压缩可以减少查询延迟,从而提高整体计算性能。
低 CPU 开销:
SNAPPY 的压缩和解压缩操作对 CPU 资源的消耗较低。对于计算密集型任务,低 CPU 开销有助于将更多的 CPU 资源用于计算本身,而不是浪费在压缩和解压缩过程中。
适合查询优化:
ORC 文件格式支持谓词下推(predicate pushdown)、列裁剪(column pruning)和其他查询优化技术。SNAPPY 的低延迟特性使得这些优化技术能够更快地生效,从而提高查询性能。
在 ORC 文件格式中使用 SNAPPY 压缩时,压缩是在分割(条带创建)之后进行的。
下面是 ORC 文件结构处理数据的一般流程:
-
数据组织与条带创建:首先,数据被组织成多个条带(Stripes)。每个条带包含一部分数据,通常是几千到几万行,具体取决于配置的条带大小和数据的实际特性。
-
列式存储:在 ORC 文件中,数据按列而非按行存储。这意味着每个条带中的数据会按列组织,这有助于提高数据访问的效率并优化查询性能。
-
压缩:数据在条带级别被组织好之后,每个条带的数据会根据配置的压缩算法进行压缩。如果选择了 SNAPPY 压缩,每个条带的数据会被 SNAPPY 压缩算法压缩。压缩是独立于每个条带进行的,这允许在读取数据时可以并行解压缩不同的条带。
-
索引和元数据写入:ORC 文件还会包含每个条带的索引信息和整个文件的元数据,包括每个列的统计信息,如最大值、最小值等。这些信息也存储在文件的尾部,并可以用来优化读取操作,因为它们可以帮助快速确定是否需要读取某个条带来满足查询条件。
因此,SNAPPY 压缩在 ORC 文件的条带创建之后执行,这样做的好处是可以保持压缩数据的独立性,支持高效的并行处理。每个条带压缩后仍可独立解压,这有利于分布式处理和快速数据访问。
3.2 ORC + LZO 的情况
并行处理:
LZO 支持并行处理和分片(splitting),这在写入大规模数据时是一个优势,因为它能够充分利用多核 CPU 进行并行压缩,缩短写入时间。
压缩率:
LZO 的压缩率可能会比 SNAPPY 高一些,这意味着在相同的数据量下,LZO 压缩后的文件会更小,可以节省存储空间和 I/O 开销。
综合考虑:
尽管 LZO 支持并行处理和分片,适合大规模数据的写入,但在大多数计算密集型场景下,查询性能的提升往往比写入性能更为重要。
SNAPPY 在读取时的快速解压缩和低 CPU 开销,使得它在读取和计算过程中表现更优。这些优势在以下方面尤为明显:
查询性能:SNAPPY 的快速解压缩速度有助于加快数据加载和处理,特别是对于复杂查询和计算逻辑多的场景。
CPU 利用率:低 CPU 开销意味着更多的计算资源可以用于执行实际的查询和分析任务,而不是消耗在解压缩过程中。
实际表现:实际测试和基准测试往往显示,对于计算密集型任务,SNAPPY 的整体表现(包括读取和计算阶段)优于 LZO。
因此,在大多数需要高计算性能的 Hive 使用场景中,推荐使用 ORC + SNAPPY 作为存储和压缩组合,尽管 SNAPPY 不支持并行处理,但当与 ORC 文件格式配合使用时,实际情况可能有所不同。
有几个关键因素说明为什么在某些情况下使用 ORC 存储格式配合 SNAPPY 压缩依然能实现高效的计算速度:
1. ORC 文件的结构特性
ORC 文件是一种高效的列式存储格式,它自带索引和分区数据的功能。即使在使用 SNAPPY 压缩时,ORC 文件格式还是可以支持有效的数据拆分(split)和并行处理。ORC 文件将数据存储在多个块中,每个块可以独立压缩和解压缩。这意味着在处理时,每个数据块可以被独立加载和解码,允许并行处理。
2. SNAPPY 压缩的性能优势
SNAPPY 压缩提供了快速的压缩和解压速度,这是其设计的主要目标。虽然它不支持压缩数据的拆分,但其快速的解压速度对于计算密集型任务来说非常重要,因为它可以快速地将数据送入处理流程。对于需要频繁读取的应用,这种快速的解压速度可以显著提高数据处理的效率。
3. 计算和 I/O 开销的平衡
在使用 ORC 和 SNAPPY 的组合时,可以实现对计算资源和 I/O 开销的良好平衡。由于 SNAPPY 提供了快速的解压缩,它可以减少从磁盘读取数据所需的时间,从而允许更多的资源被用于执行计算逻辑。这种快速的数据流转对于计算密集型任务尤其重要。
4. 总体系统性能
在选择压缩算法时,还需要考虑到整个数据平台的架构和性能。虽然 LZO 提供了并行压缩的能力,但其解压速度通常不如 SNAPPY 快。此外,如果大部分时间都在进行数据读取和计算而不是写入,那么解压缩性能将更为关键。
结论:
因此,尽管 SNAPPY 不支持拆分压缩数据,但由于 ORC 的结构使得数据可以在块级别进行并行处理,再加上 SNAPPY 的高解压速度,使得这种组合在很多场景下仍然可以实现非常高效的查询和计算性能。当然,这种选择也应基于具体的使用场景和性能测试来确定,以确保满足特定的性能和成本效益需求。
相关文章:

Hive的存储格式和压缩算法的特点和选择
1、数据存储格式: ①TEXTFILE HIVE 中默认的存储格式; 一般使用在数据贴源层(ODS 或 STG) ,针对需要使用脚本 LOAD 加载数据到 HIVE 数仓表中的情况;需要把表里数据导出或直接可以查看等场景,作为BI供数 易读性…...
是如何定义的)
C语言中的枚举类型(enum)是如何定义的
在C语言中,枚举类型(enum)是一种用户定义的数据类型,它允许为整数值指定一个易读的名字。枚举类型通常用于表示固定数量的可能值,例如一周的七天或颜色的集合。 枚举类型的定义使用关键字 enum,后面跟着枚…...
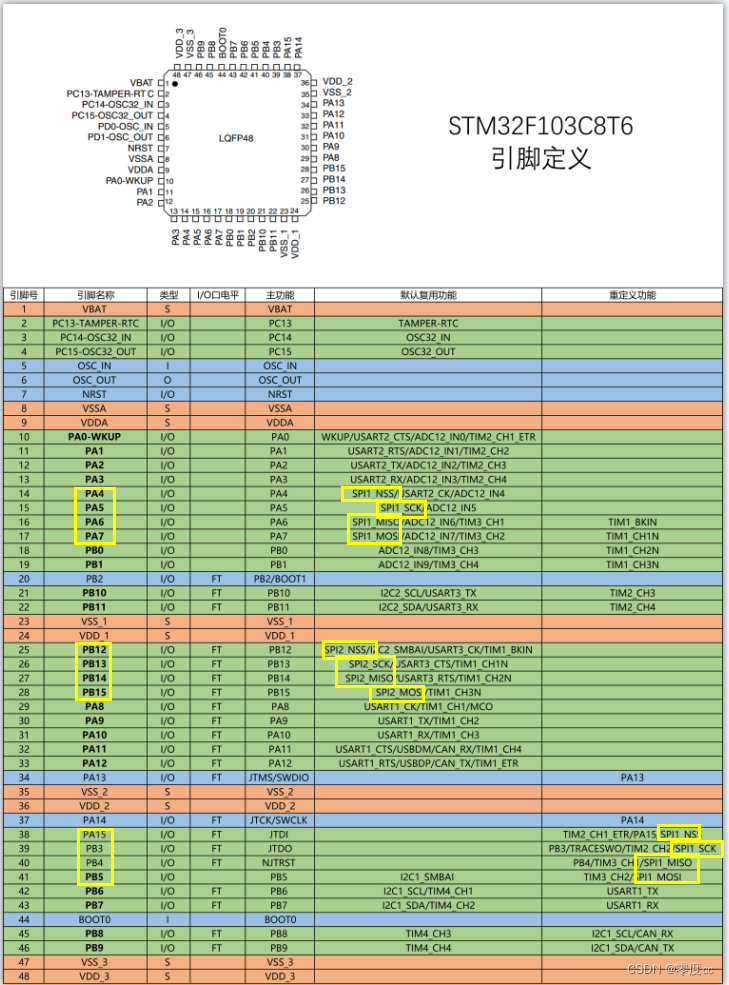
SPI通信协议
一、SPI通信 1、SPI(Serial Peripheral Interface)是由Motorola公司开发的一种通用数据总线 2、四根通信线:SCK(Serial Clock)、MOSI(Master Output Slave Input)、MISO(Master In…...
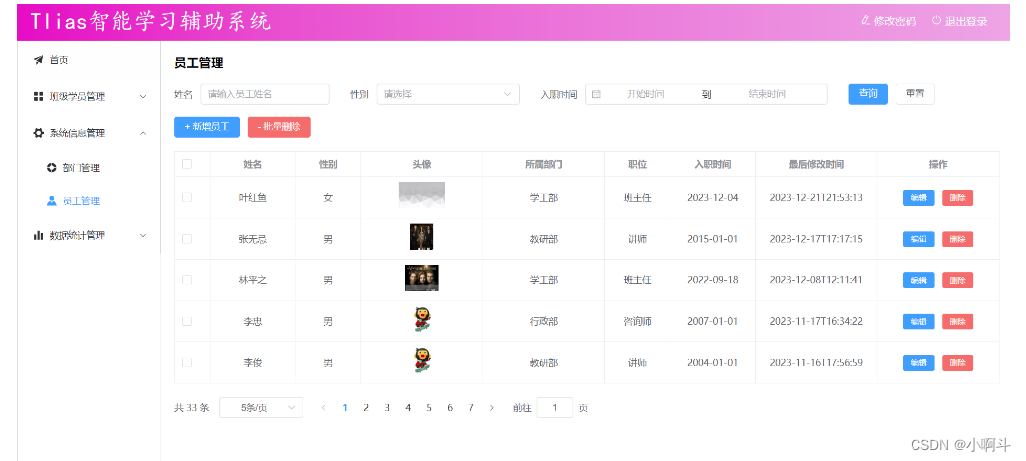
【免费Web系列】大家好 ,今天是Web课程的第二一天点赞收藏关注,持续更新作品 !
这是Web第一天的课程大家可以传送过去学习 http://t.csdnimg.cn/K547r 员工管理 1. 条件分页查询 1.1 概述 在页面原型中,我们可以看到在查询员工信息列表时,既需要根据条件动态查询,还需要对查询的结果进行分页处理。 那要完成这个页面…...
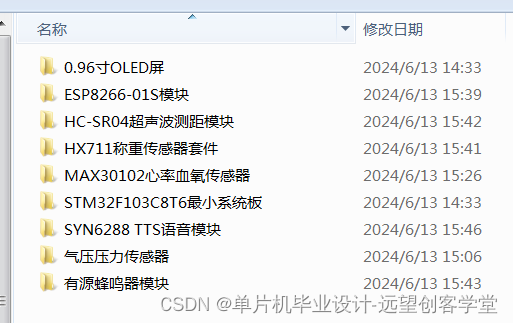
【单片机毕业设计选题24007】-基于STM32和阿里云的家庭健康数据监测系统
系统功能: 本课题设计是基于STM32单片机作为控制主体,通过HX711称重模块,HC-SR04超声波测距模块,红外测温,心率传感器等模块通过I2C或SPI接口与STM32进行通信,并读取传感器输出的身高,体重,心率…...
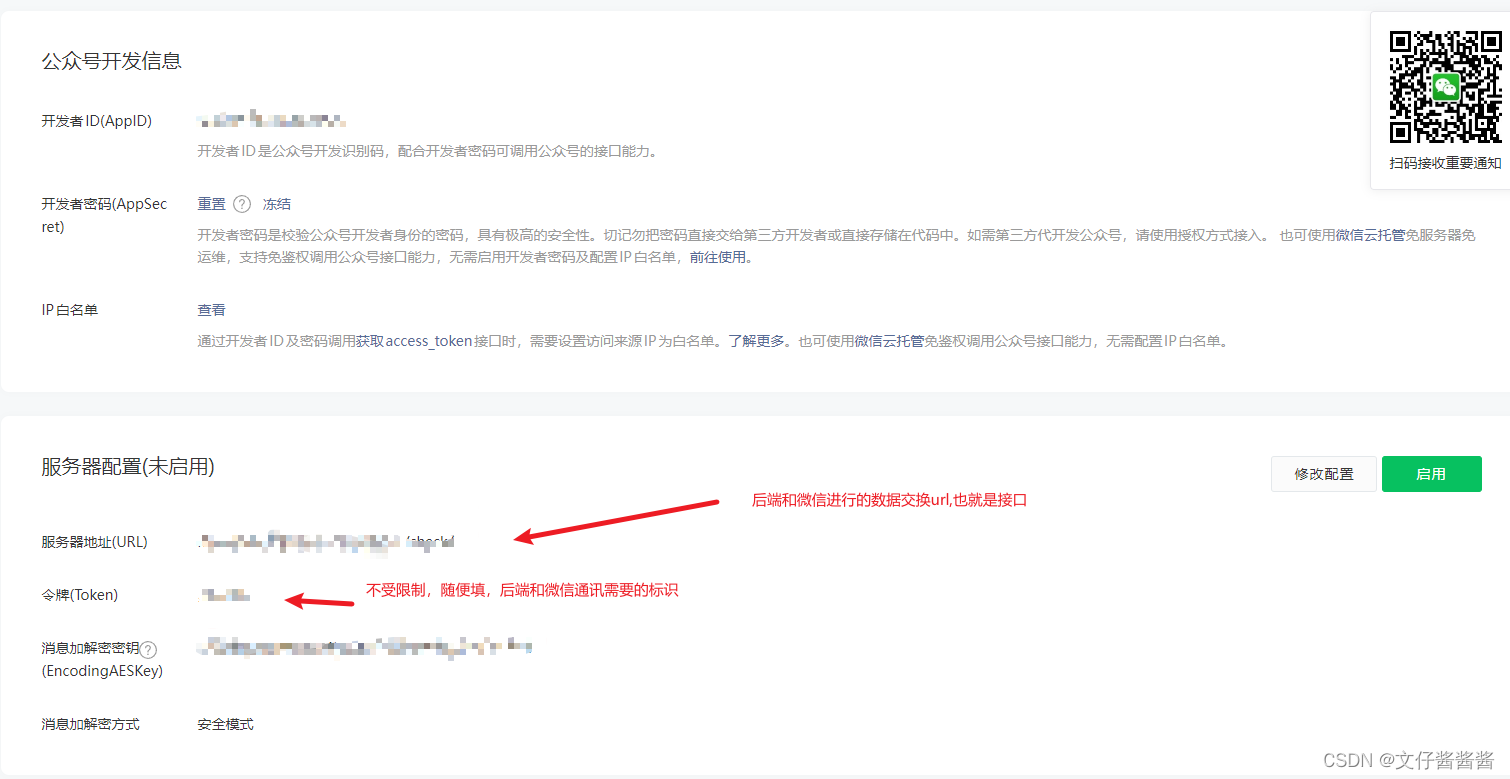
基于微信公众号开发h5的前端流程
1.首先公众号进行配置,必须要https域名 还有个txt文件,有弹框提示需要下载放在服务器上 前端处理code的代码封装 // 微信公众号授权 export function wxAuthorize(calback) {// 非静默授权,第一次有弹框 这里的回调页面就是放在服务器上微信…...

python操作数据库,django操作数据库
安装驱动 pip install mysqlclient工程同名app下的settings.py DATABASES {default: {ENGINE: django.db.backends.mysql,NAME: test,USER: root,PASSWORD: hirain123,HOST: localhost,PORT: 3306,OPTION; {init_command: SET sql_model"STRICT_TRANS_TABLES",}} …...

React框架资源
React框架资源可以从多个方面获取,包括官方文档、教程、书籍、社区等。以下是一些React框架资源的清晰分点和归纳: 官方文档 新官方文档:React在2023年3月发布了全新的官方文档,位于https://react.dev/。新文档包含教程、指南…...

【数据结构】初识数据结构之复杂度与链表
【数据结构】初识数据结构之复杂度与链表 🔥个人主页:大白的编程日记 🔥专栏:C语言学习之路 文章目录 【数据结构】初识数据结构之复杂度与链表前言一.数据结构和算法1.1数据结构1.2算法1.3数据结构和算法的重要性 二.时间与空间…...

word怎么单页横向设置(页码不连续版)
打开word,将光标放在第一页的最后位置。 然后点击布局下的分隔符,选择下一页。 将光标放在第二页的开头,点击布局下的纸张方向,选择横向即可。 效果展示。 PS:如果那一页夹在两页中间,那么在…...

搭建 Tomcat 集群【Nginx 负载均衡】
当我们想要提高后端服务器的并发性能,可以通过分配更多的资源给 Tomcat 服务器,但是这只能提高一部分的性能。因为每台 Tomcat 的服务器是有最大连接数为 200.所以即可拥有无穷无尽的内存,也会因为单台 Tomcat 的原因而无法发挥这些资源的最大…...
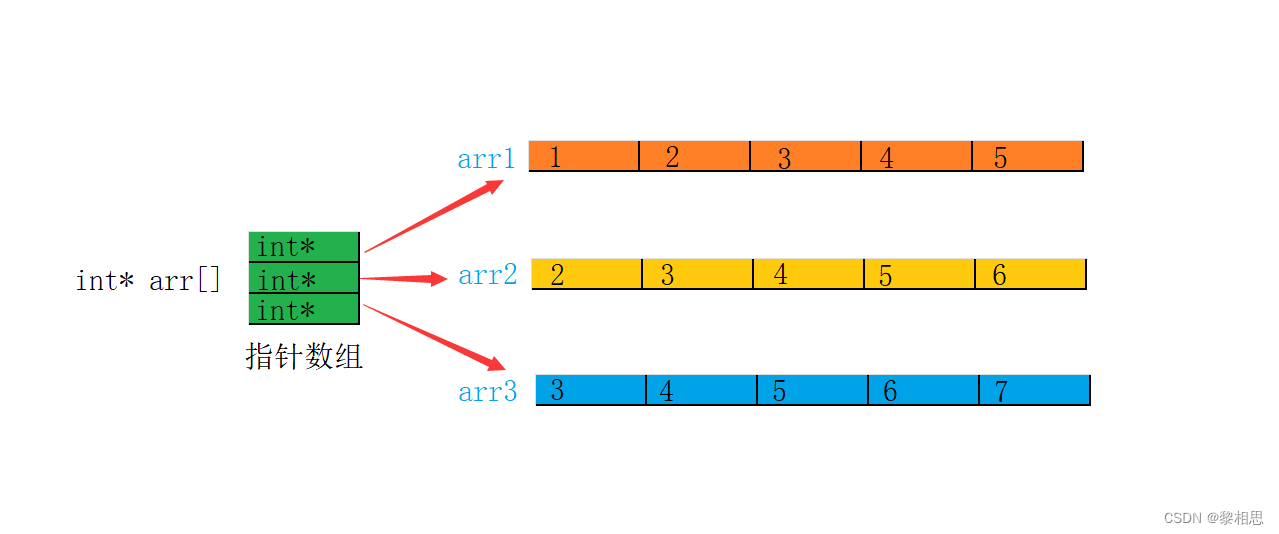
深入理解指针(二)
目录 1. 数组名的理解 2. 使用指针访问数组 3. ⼀维数组传参的本质 4. 冒泡排序 5. 二级指针 6. 指针数组 7. 指针数组模拟二维数组 1. 数组名的理解 有下面一段代码: #include <stdio.h> int main() {int arr[10] { 1,2,3,4,5,6,7,8,9,10 };int* p &arr[…...

【Qt 学习笔记】Qt窗口 | 标准对话框 | 文件对话框QFileDialog
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Qt窗口 | 标准对话框 | 文件对话框QFileDialog 文章编号:Q…...

换卡槽=停机?新手机号使用指南!
刚办理的手机号莫名其妙的就被停用了?这到底是怎么回事?这篇文章快来学习一下吧。 先说一下,你的手机为什么被停机? 现在运营商对于手机卡的使用有着非常严格的要求,尤其是刚办理的新号码,更是“严上加…...

主题切换之根元素CSS自定义类
要实现CSS样式的主题切换,可以通过在HTML中添加一个按钮来触发JavaScript事件,进而通过JavaScript动态修改HTML元素的class或直接切换CSS文件,以达到改变页面整体风格的目的。以下是实现这一功能的步骤、原理及代码示例。 原理: …...

如何在 ASP.NET Core Web Api 项目中应用 NLog 写日志?
前言 昨天分享了在 .NET Core Console 项目中应用 NLog 写日志的详细例子,有几位小伙伴私信说 ASP.NET Core Web Api 项目中无法使用,其实在 ASP.NET Core Web Api 项目中应用 NLog 写日志,跟 .NET Core Console 项目是有些不一样的…...

selenium execute_script常用方法汇总
driver.execute_script() 是 Selenium WebDriver 中非常强大且灵活的功能,可以用来执行任意的 JavaScript 代码在浏览器上下文中。以下是一些常用的 execute_script() 方法的例子和用法: 修改元素的属性和值 python# 修改输入框的值 driver.execute_sc…...

如何选择最佳的APP封装平台-小猪APP分发为您解忧
在开发移动应用程序的过程中,选择一个可靠的APP封装平台显得尤为重要。无论你是初创企业还是大型企业,找到一个合适的平台可以大大简化你的开发流程。如何选择最佳的APP封装平台呢?今天我们就来聊聊这个话题,并重点介绍一下小猪AP…...

Linux基础 (十八):Libevent 库的安装与使用
目录 一、Libevent 概述 1.0 Libevent的安装 1.0.1 使用源码方式 1.0.2 终端命令行安装 1.1 主要特性 1.2 主要组件 1.3 Libevent 使用模型 1.4 原理 1.5 使用的基本步骤 1.5.1 初始化事件基础设施 1.5.2. 创建和绑定服务器套接字 1.5.3. 设置监听事件 1.5.4. 定义…...

冒泡排序的详细介绍 , 以及c , python , Java的实现方法
冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...

Elastic 获得 AWS 教育 ISV 合作伙伴资质,进一步增强教育解决方案产品组合
作者:来自 Elastic Udayasimha Theepireddy (Uday), Brian Bergholm, Marianna Jonsdottir 通过搜索 AI 和云创新推动教育领域的数字化转型。 我们非常高兴地宣布,Elastic 已获得 AWS 教育 ISV 合作伙伴资质。这一重要认证表明,Elastic 作为 …...