图解Transformer学习笔记
教程是来自https://github.com/datawhalechina/learn-nlp-with-transformers/blob/main/docs/
图解Transformer
Attention为RNN带来了优点,那么有没有一种神经网络结构直接基于Attention构造,而不再依赖RNN、LSTM或者CNN的结构,这就是Transformer。
Transformer直接基于Self-Attention结构,取代了之前NLP任务中常用的RNN神经网络结构,Transformer一个巨大的优点是:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理序列,Transformer模型结构与seq2seq类似,分为编码器和解码器。
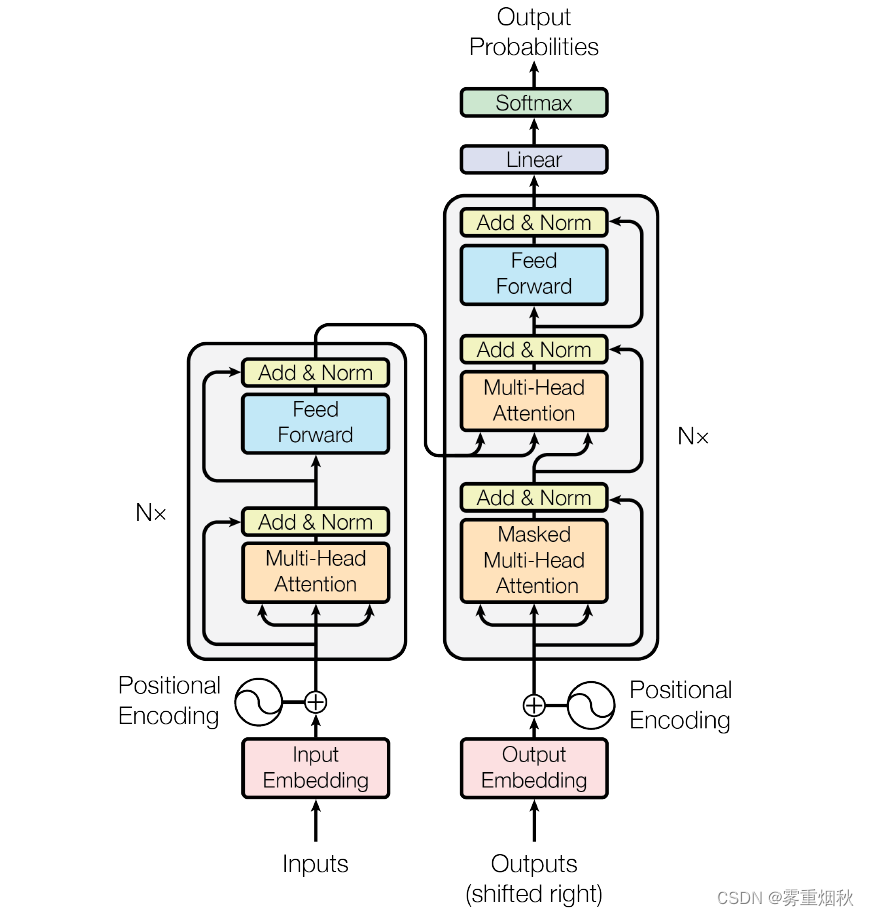
Transformer的宏观结构
Transformer最开始提出来解决机器翻译任务,因此可以先将Transformer这种特殊的seq2seq模型看做一个黑盒,输入是法语文本序列,输出是英语文本序列。

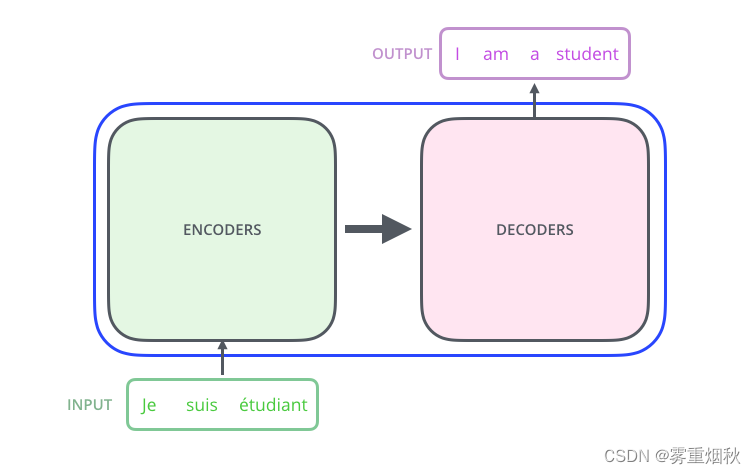
将上图的中间部分拆开成seq2seq标准结构,如图,左右分别是编码部分(Encoders)和解码部分(Decoders)。
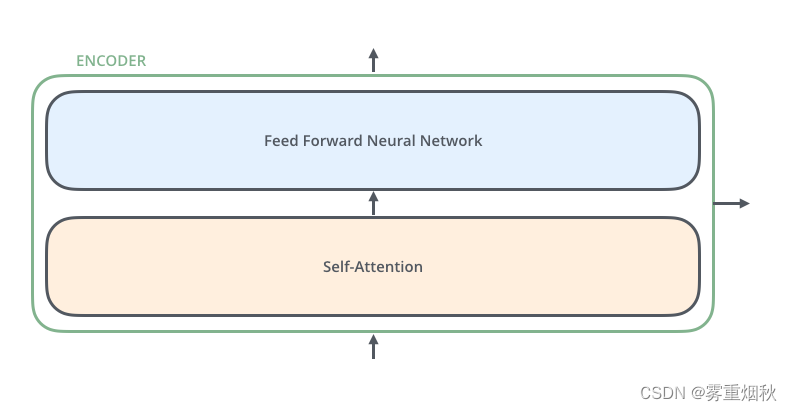
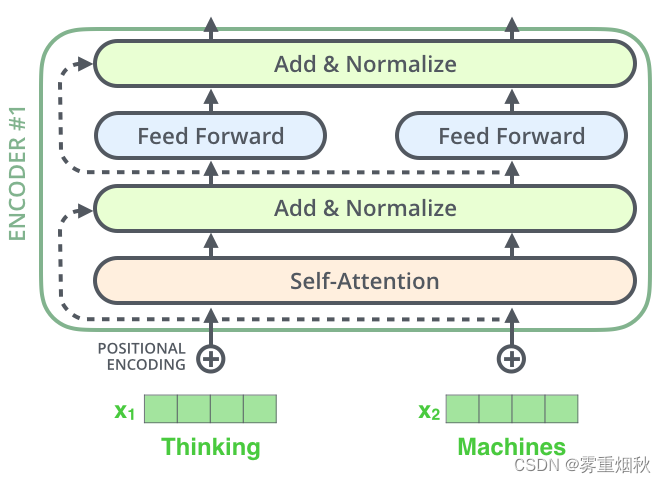
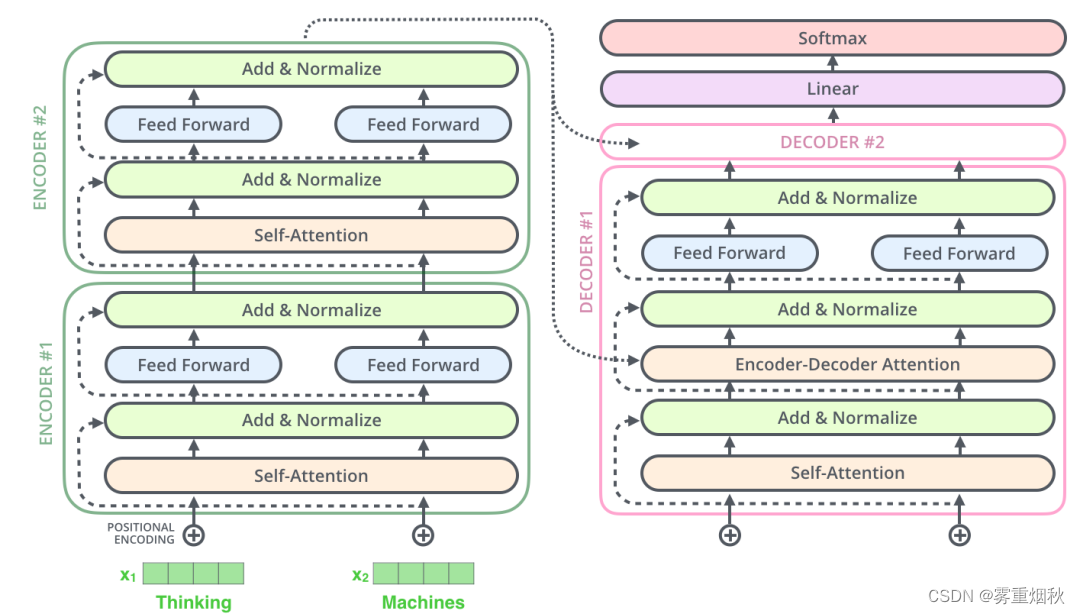
然后,再将上图中的编码器和解码器的细节绘出,得到下图,可以看到,编码部分(Encoders)是由多层编码器(Encoder)组成(Transformer论文中使用6层编码器,也可以自行根据实验效果修改层数),同理,解码部分由多层的解码器组成(论文里也是6层)。每层编码器网络结构是一样的,每层解码器网络结构也是一样的。不同层编码器和解码器网络结构不共享参数。

下面看一下单层encoder,单层encoder主要由以下两部分组成:
- Self-Attention Layer
- Feed Forward Neural Network
编码器的输入文本序列 w 1 , w 2 , . . . , w n w_1,w_2,...,w_n w1,w2,...,wn最开始经过embedding转换,得到每个单词的向量表示 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,其中 x i ∈ R d x_i \in \mathbb{R}^{d} xi∈Rd是维度为 d d d的向量,然后所有向量经过一个Self-Attention神经网络层进行变换和信息交互得到 h 1 , h 2 , . . . , h n h_1,h_2,...,h_n h1,h2,...,hn,其中 h i ∈ R d h_i \in \mathbb{R}^{d} hi∈Rd是维度为 d d d的向量。self-attention层处理一个词向量的时候,不仅会使用这个词本身的信息,也会使用句子中其他词的信息。Self-Attention层的输出会经过前馈神经网络得到新的 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,依旧是 n n n个维度为 d d d的向量。这些向量将被送入下一层encoder,继续相同的操作。
与编码器对应,解码器在编码器的self-attention和FFNN中间插入了一个Encoder-Decoder Attention层,这个层帮助解码器聚焦于输入序列最相关的部分(类似于seq2seq模型中的Attention层)。
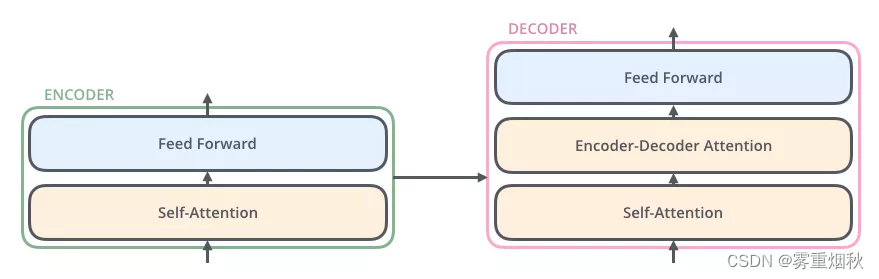
总结,Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由self-attention和FFNN组成,每个解码层由self-attention、FFNN和encoder-decoder attention组成。
Transformer结构细节
输入处理
词向量
和常见的NLP任务一样,首先会使用词嵌入算法(embedding algorithm),将输入文本序列的每一个词转换为一个词向量。实际应用中的向量一般是256或者512维,为了简化,下面都以4维向量来示意。
如下图,假设输入文本的序列包含了3个词,那么每个词可以通过词嵌入算法得到一个4维向量,于是整个输入被转化为一个向量序列。在实际应用中,我们通常会同时给模型输入多个句子,如果每个句子的长度不一样,我们会选择一个合适的长度,作为输入文本序列的最大长度:如果一个句子达不到这个长度,那么就填充一个特殊的”padding“词;如果句子超过这个长度,则做截断。最大序列长度是一个超参数,通常希望越大越好,但是更长的序列往往会占用更大的训练显存/内存,因此需要在模型训练时候视情况而定。

输入序列每个单词被转换成词向量表示还将加上位置向量来得到该词的最终向量表示。
位置向量
如下图,Transformer模型对每个输入的词向量都加上了一个位置向量。这些向量有助于确定每个单词的位置特征,或者句子中不同单词之间的距离特征。词向量加上位置向量背后的直觉是:将这些表示位置的向量添加到词向量中,得到的新向量,可以为模型提供更多有意义的信息,比如词的位置,词之间的距离等。
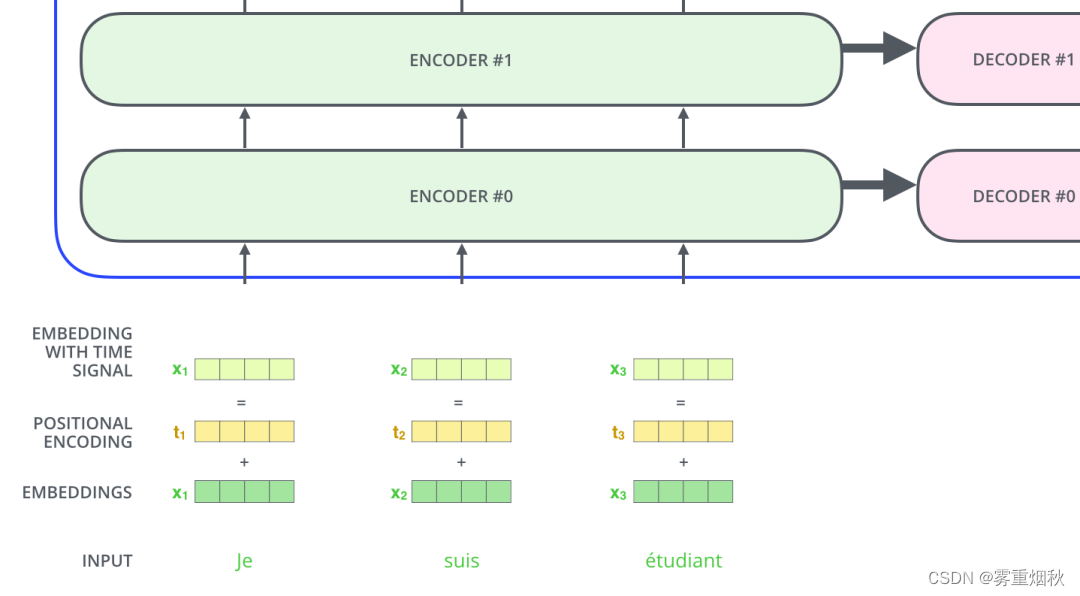
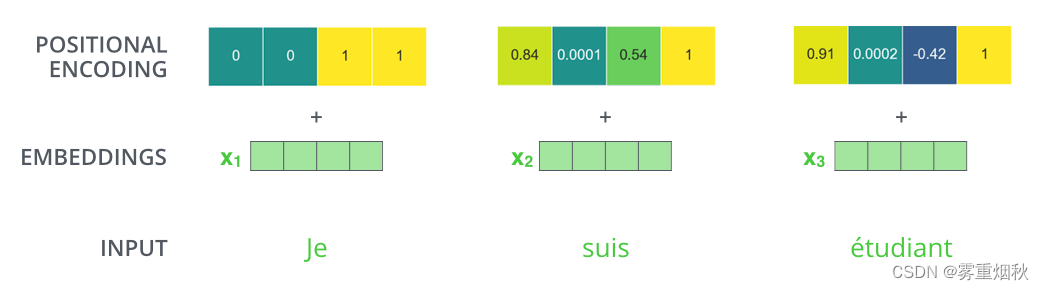
假设词向量和位置向量的维度是4,下图为一种可能的位置向量+词向量:
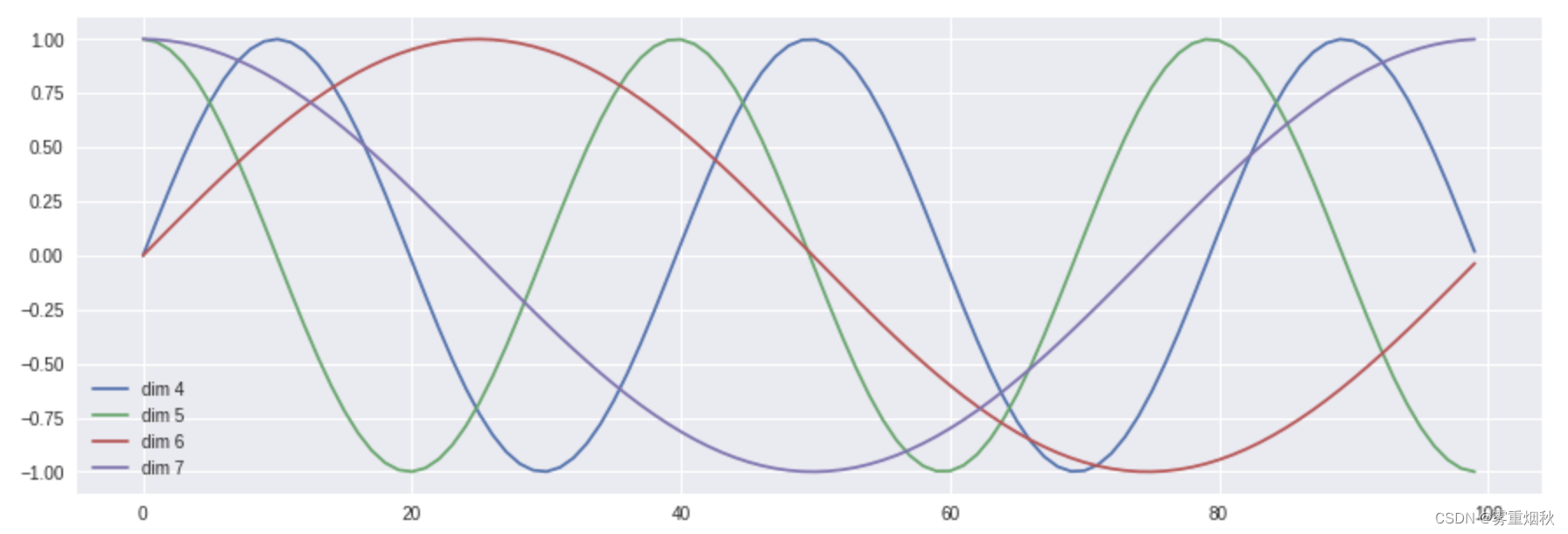
带有位置编码信息的向量到底遵循什么模式,原始论文中给出的设计表达式为: P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d model ) PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{\text{model}}}) \ PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{\text{model}}}) PE(pos,2i)=sin(pos/100002i/dmodel) PE(pos,2i+1)=cos(pos/100002i/dmodel)上式中的 p o s pos pos代表词的位置, d m o d e l d_{model} dmodel代表位置向量的维度, i ∈ [ 0 , d m o d e l ] i \in [0, d_{model}] i∈[0,dmodel]代表 d m o d e l d_{model} dmodel维位置向量的第 i i i维。根据上述公式,我们可以得到第 p o s pos pos位置的 d m o d e l d_{model} dmodel维位置向量。下图是一种位置向量在第4、5、6、7维度、不同位置的数值大小,横坐标表示位置下标(pos的值),纵坐标表示数值大小(如 P E ( p o s , 4 ) PE_{(pos, 4)} PE(pos,4))。
上述公式不是唯一生成位置编码向量的方法。但这种方法的优点是:可以扩展到未知的序列长度。例如,当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成一样长的位置编码向量。
编码器encoder
编码部分的输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第一层编码器,第一层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第一层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
下图展示了向量序列在单层encoder中的流动:融合位置信息的词向量进入self-attention层,self-attention输出每个位置的向量再输入FFNN得到每个位置的新向量。
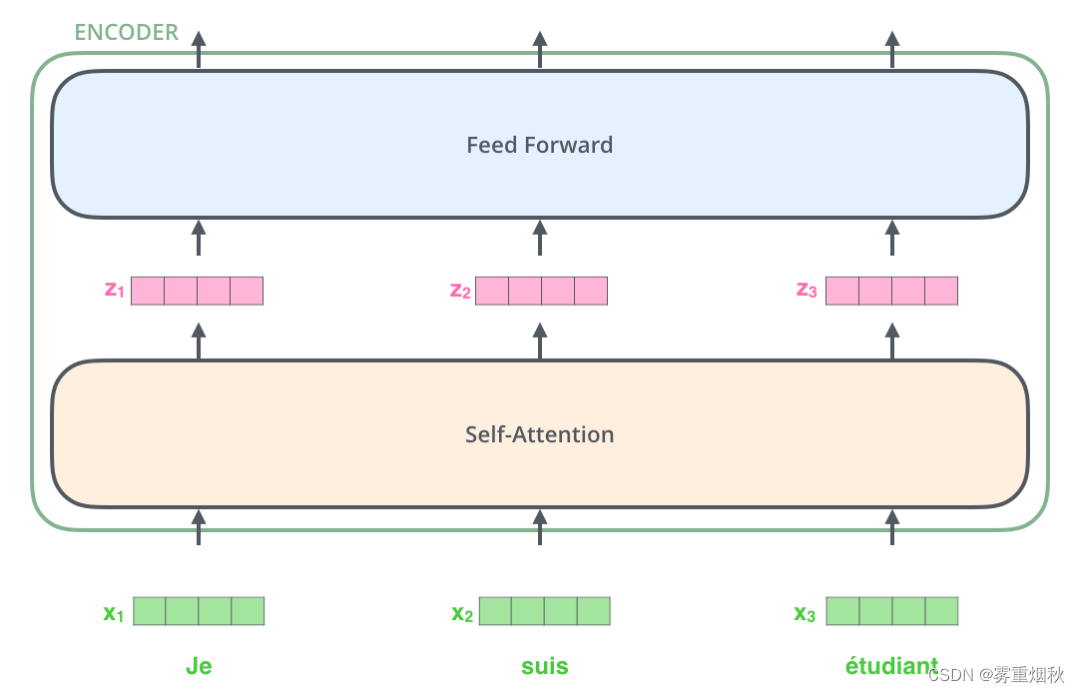
Self-Attention层
Self-Attention概览
假设我们想要翻译的句子是:
The animal didn't cross the street because it was too tired
这个句子中的it是一个指代词,那么it指的是什么,它是指animal还是street,这个问题对人来说很简单,但是对模型来说并不是很容易。但是如果模型引入了Self Attention机制之后,便能够让模型把it和animal关联起来了。同样的,当模型处理句子中其他词时,Self Attention机制也可以使得模型不仅仅关注当前位置的词,还会关注句子中其他位置的相关的词,进而可以更好地理解当前位置的词。
与RNN对比:RNN在处理序列中的一个词时,会考虑句子前面的词传过来的hidden state,而``hidden state就包含了前面的词的信息;而Self Attention机制指的是,当前词会直接关注到自己句子中前后相关的所有词语,如下图it的例子:

上图所示的it是一个真实的例子,是当Transformer在第5层编码器编码it时的状态,可视化之后显示it有一部分注意力集中在了The animal上,并且把这两个词的信息融合到了it中。
Self-Attention细节
先用一个简单的例子来理解一下什么是self-attention自注意力机制。假设一句话包含两个单词:Thinking Machines。自注意力的一种理解是:Thinking-Thinking,Thinking-Machines,Machines-Thinking,Machines-Machines,共 2 2 2^2 22种两两attention。那么具体如何计算?假设Thinking、Machines这两个单词经过词向量算法得到向量是 X 1 , X 2 X_1, X_2 X1,X2:
1. q 1 = X 1 W Q , q 2 = X 2 W Q ; k 1 = X 1 W K , k 2 = X 2 W K ; v 1 = X 1 W V , v 2 = X 2 W V , W Q , W K , W V ∈ R d x × d k q_1 = X_1 W^Q, q_2 = X_2 W^Q; k_1 = X_1 W^K, k_2 = X_2 W^K;v_1 = X_1 W^V, v_2 = X_2 W^V, W^Q, W^K, W^V \in \mathbb{R}^{d_x \times d_k} q1=X1WQ,q2=X2WQ;k1=X1WK,k2=X2WK;v1=X1WV,v2=X2WV,WQ,WK,WV∈Rdx×dk
2-3. s c o r e 11 = q 1 ⋅ q 1 d k , s c o r e 12 = q 1 ⋅ q 2 d k ; s c o r e 21 = q 2 ⋅ q 1 d k , s c o r e 22 = q 2 ⋅ q 2 d k ; score_{11} = \frac{q_1 \cdot q_1}{\sqrt{d_k}} , score_{12} = \frac{q_1 \cdot q_2}{\sqrt{d_k}} ; score_{21} = \frac{q_2 \cdot q_1}{\sqrt{d_k}}, score_{22} = \frac{q_2 \cdot q_2}{\sqrt{d_k}}; score11=dkq1⋅q1,score12=dkq1⋅q2;score21=dkq2⋅q1,score22=dkq2⋅q2;
4. s c o r e 11 = e s c o r e 11 e s c o r e 11 + e s c o r e 12 , s c o r e 12 = e s c o r e 12 e s c o r e 11 + e s c o r e 12 ; s c o r e 21 = e s c o r e 21 e s c o r e 21 + e s c o r e 22 , s c o r e 22 = e s c o r e 22 e s c o r e 21 + e s c o r e 22 score_{11} = \frac{e^{score_{11}}}{e^{score_{11}} + e^{score_{12}}},score_{12} = \frac{e^{score_{12}}}{e^{score_{11}} + e^{score_{12}}}; score_{21} = \frac{e^{score_{21}}}{e^{score_{21}} + e^{score_{22}}},score_{22} = \frac{e^{score_{22}}}{e^{score_{21}} + e^{score_{22}}} score11=escore11+escore12escore11,score12=escore11+escore12escore12;score21=escore21+escore22escore21,score22=escore21+escore22escore22
5-6. z 1 = v 1 × s c o r e 11 + v 2 × s c o r e 12 ; z 2 = v 1 × s c o r e 21 + v 2 × s c o r e 22 z_1 = v_1 \times score_{11} + v_2 \times score_{12}; z_2 = v_1 \times score_{21} + v_2 \times score_{22} z1=v1×score11+v2×score12;z2=v1×score21+v2×score22
下面,将上述self-attention计算的6个步骤进行可视化。
- 第一步:对输入编码器的词向量进行线性变换得到,Query向量 q 1 , q 2 q_1,q_2 q1,q2,Key向量 k 1 , k 2 k_1,k_2 k1,k2,Value向量 v 1 , v 2 v_1,v_2 v1,v2。这3个向量是词向量分别和3个参数矩阵相乘得到,而这个矩阵也是模型要学习的参数。
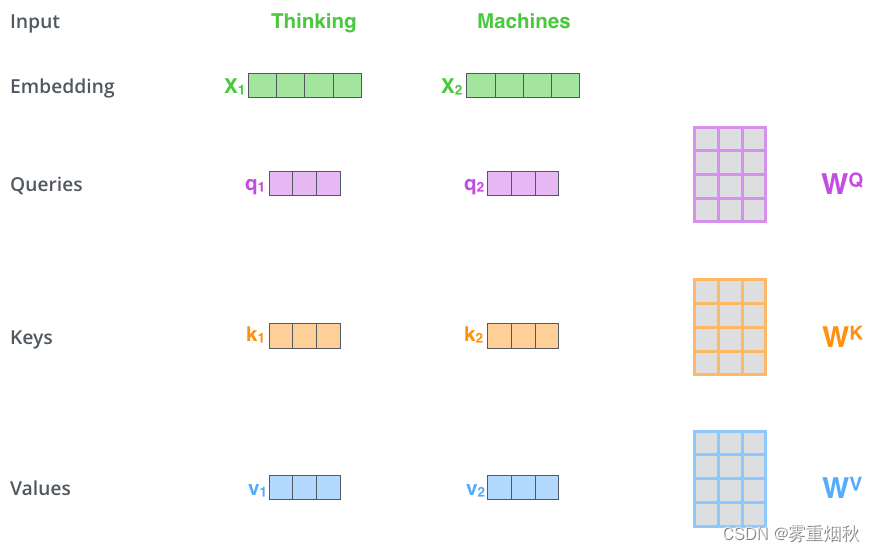
其实就是3个向量,给它们加上一个名称,可以让我们更好地理解Self-Attention的计算过程和逻辑。Attention计算的逻辑常常可以描述为:query和key计算attention得分,然后根据attention得分对value进行加权求和。 - 第2步:计算Attention Score(注意力分数)。假设我们现在计算第一个词Thinking的Attention Score,需要根据Thinking对应的词向量,对句子中的其他词向量都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的词向量的权重。
Attention score是根据Thinking对应的Query向量和其他位置的每个词的Key向量进行点积得到的。Thinking的第一个Attention Score就是 q 1 q_1 q1和 k 1 k_1 k1的内积,第二个分数就是 q 1 q_1 q1和 k 2 k_2 k2的点积。这个计算过程如下图所示,图中的具体得分数据是为了表达方便自定义的。
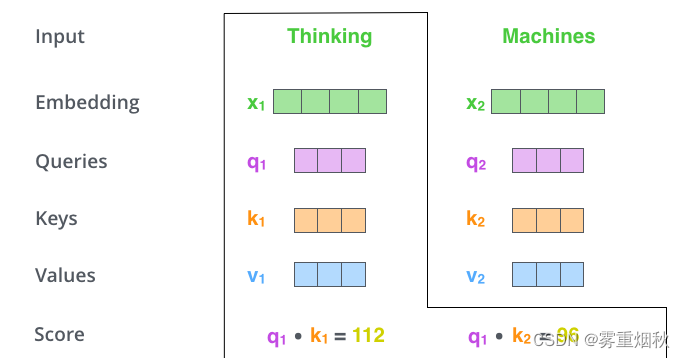
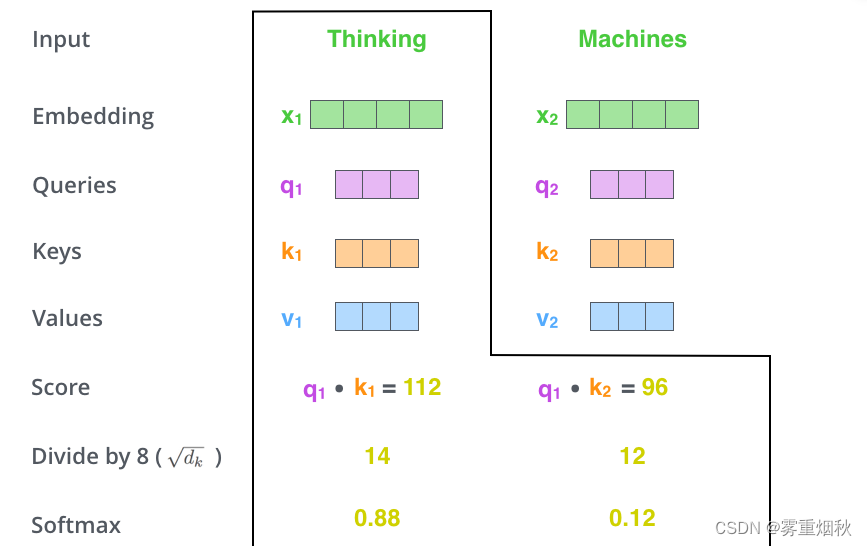
- 第3步:把每个分数除以 d k \sqrt{d_k} dk, d k d_{k} dk是Key向量的维度,也可以除以其他数,除以一个数是为了在反向传播时,求梯度时更加稳定。
- 第4步:接着把这些分数经过一个Softmax函数,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于1,如下图所示。这些分数决定了Thinking词向量,对其他所有位置的词向量分别有多少注意力(下图的Softmax的数值算错了,但是意思到了就行)。
- 第5步:得到每个词向量的分数后,将分数分别与对应的Value向量相乘,这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的。
- 第6步:把第5步得到的Value向量相加,就得到了Self Attention在当前位置(这里的例子是第1个位置)对应的输出。
最后,在下图展示了对第一个位置词向量计算Self Attention的全过程。最终得到的当前位置词向量会继续输入到前馈神经网络。注意:上面的6个步骤每次只能计算一个位置的输出向量,在实际的代码实现中,Self Attention的计算过程是使用矩阵快速计算的,一次就得到所有位置的输出向量。

上图是Thinking(也就是第一个位置)经过self-attention之后的向量表示。
Self-Attention矩阵计算
将self-attention计算6个步骤中的向量放一起,比如 X = [ x 1 ; x 2 ] X=[x_1;x_2] X=[x1;x2],便可以进行矩阵计算。下面,依旧按步骤展示self-attention的矩阵计算方法。 X = [ x 1 ; x 2 ] Q = X W Q , K = X W K , V = X W V Z = s o f t m a x ( Q K T d k ) V X=[x_1;x_2] \\ Q=XW^Q,K=XW^K,V=XW^V \\ Z=softmax(\frac{QK^T}{\sqrt{d_k}})V X=[x1;x2]Q=XWQ,K=XWK,V=XWVZ=softmax(dkQKT)V
- 第一步:计算Query,Key,Value矩阵。首先,我们把所有词向量放到一个矩阵X中,然后分别和3个权重矩阵 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV相乘,得到Q,K,V矩阵。矩阵X中的每一行,表示句子中的每一个词的词向量。Q,K,V矩阵中的每一行表示Query向量,Key向量,Value向量,向量维度是 d k d_k dk。
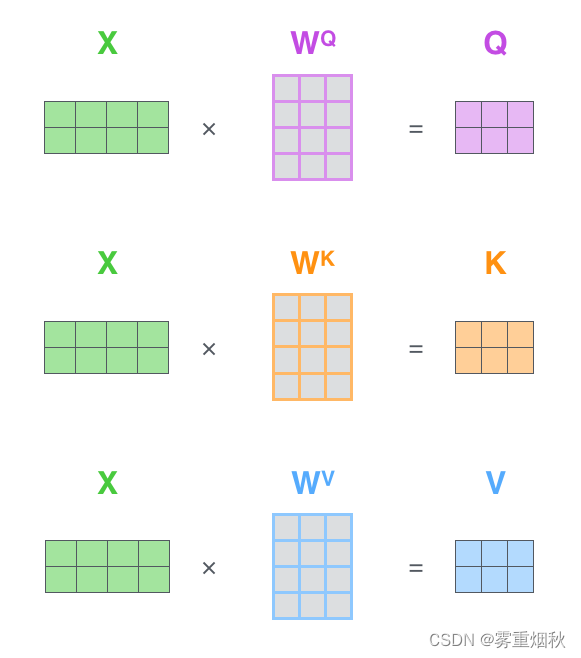
- 第2步:由于我们使用了矩阵来计算,我们可以把上面的第2步到第6步压缩为一步,直接得到Self Attention的输出。
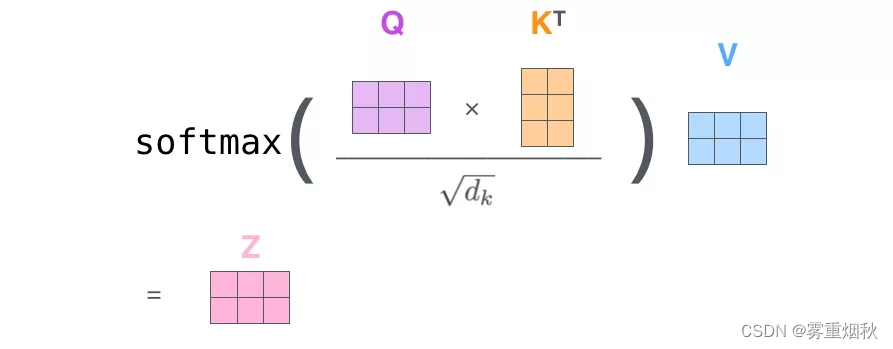
Q Q Q是 L L L行,每行是 d k d_k dk维的,也就是 L ∗ d k L*d_k L∗dk的矩阵, Q K T QK^T QKT的结果是 L ∗ L L*L L∗L的矩阵,其中的每个元素 Q K T i j = q i ⋅ k j {QK^T}_{ij}=q_i\cdot k_j QKTij=qi⋅kj,然后和 V V V相乘就是 L ∗ d k L*d_k L∗dk的矩阵,每一行就是self Attention的输出,以图为例,第 1 1 1行的结果是 s o f t m a x ( q 1 k 1 d k ) v 1 + s o f t m a x ( q 1 k 2 d k ) v 2 = z 1 softmax(\frac{q_1k_1}{\sqrt{d_k}})v_1+softmax(\frac{q_1k_2}{\sqrt{d_k}})v_2=z_1 softmax(dkq1k1)v1+softmax(dkq1k2)v2=z1。
多头注意力机制
Transformer的论文通过增加多头注意力机制(一组注意力称为一个attention head),进一步完善了Self-Attention。这种机制从如下两个方面增强了attention层的能力:
- 它扩展了模型关注不同位置的能力。在上面的例子中,第一个位置的输出 z 1 z_1 z1仅仅是单个向量,所以可能仅由第1个位置的信息主导了。而当我们翻译句子:
The animal didn’t cross the street because it was too tired时,我们不仅希望模型关注到it本身,还希望模型关注到The和Animal,甚至关注到tired。这时,多头注意力机制会有帮助。 - 多头注意力机制赋予attention层多个”子表示空间“。下面我们会看到,多头注意力机制会有多组 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV的权重矩阵(在Transformer的论文中,使用了8组注意力),因此可以将 X X X变换到更多种子空间进行表示。接下来我们也使用8组注意力头(attention heads)。每一组注意力的权重矩阵都是随机初始化的,但经过训练之后,每一组注意力权重 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV可以把输入的向量映射到一个对应的”子表示空间“。
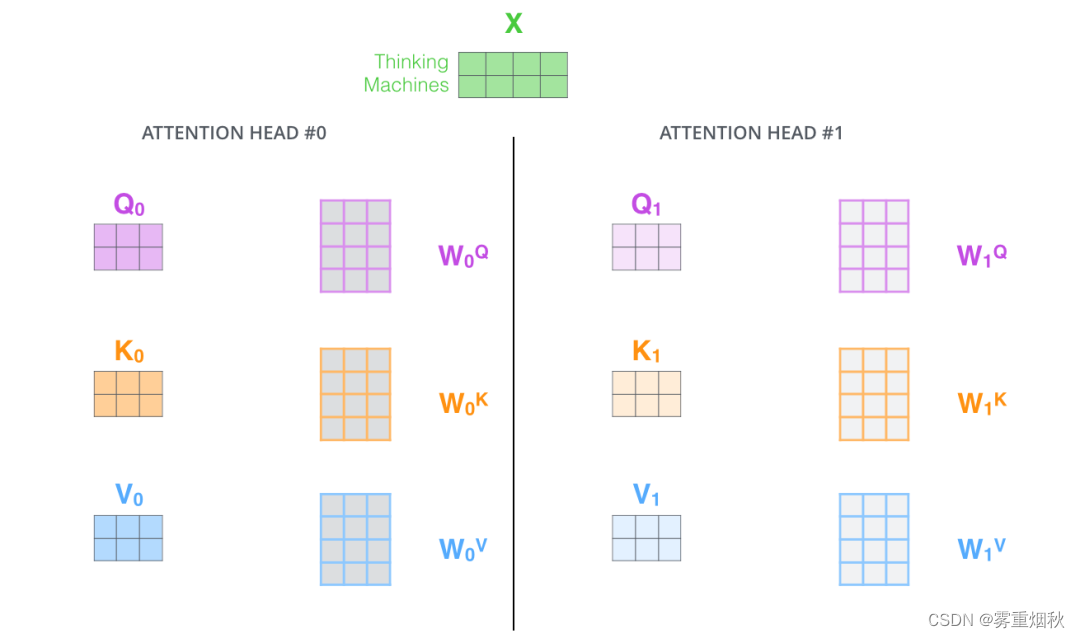
在多头注意力机制中,我们为每组注意力设定单独的 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV参数矩阵。将输入X和每组注意力的 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV相乘,得到8组Q,K,V矩阵。
接着,我们把每组Q,K,V计算得到每组的Z矩阵,就得到8个Z矩阵。

由于前馈神经网络层接收的是1个矩阵(其中每行的向量表示一个词),而不是8个矩阵,所以我们直接把8个子矩阵拼接起来得到一个大的矩阵,然后和另一个权重矩阵 W O W^O WO相乘做一次变换,映射到前馈神经网络层所需要的维度。
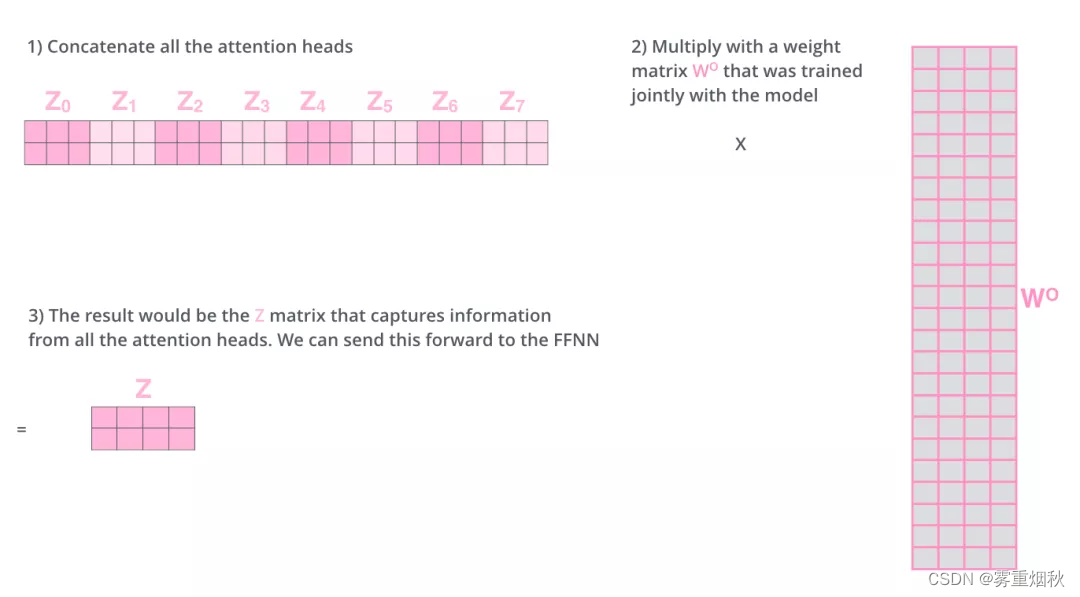
总结一下就是:
- 把8个矩阵 [ Z 0 , Z 1 , . . . , Z 7 ] [Z_0,Z_1,...,Z_7] [Z0,Z1,...,Z7]拼接起来
- 把拼接后的矩阵和 W O W^O WO权重矩阵相乘
- 得到最终的矩阵 Z Z Z,这个矩阵包含了所有attention heads(注意力头)的信息。这个矩阵会输入到FFNN层。
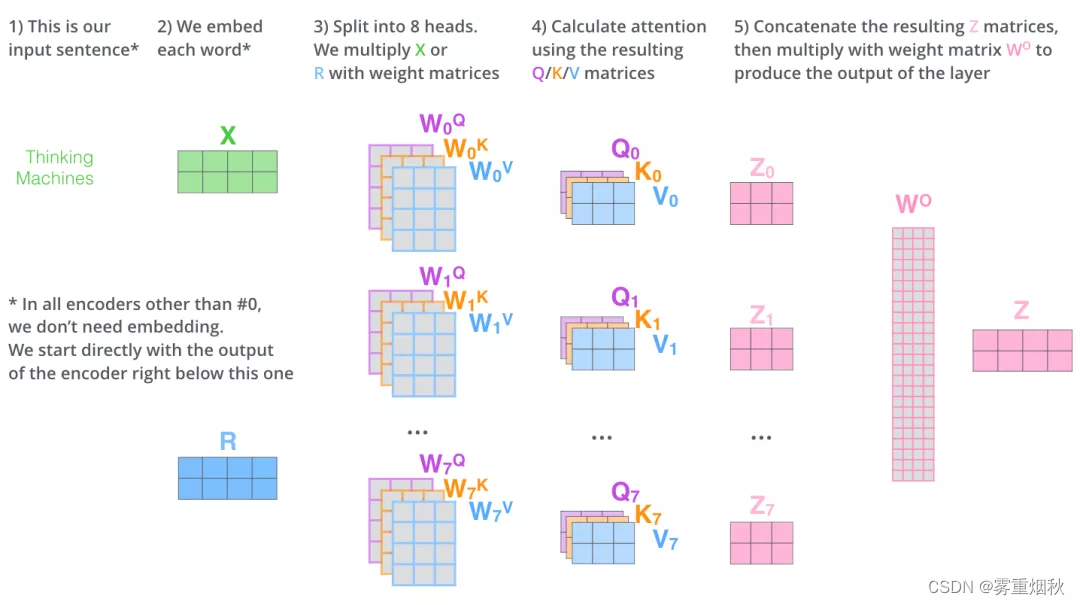
下图是多头注意力所有内容的集合。
学会了多头注意力机制,再回头看之前提到的it的例子,不同的attention heads(注意力头)对应的it attention了哪些内容。下图中的绿色和橙色线条分别表示2组不同的attention heads:
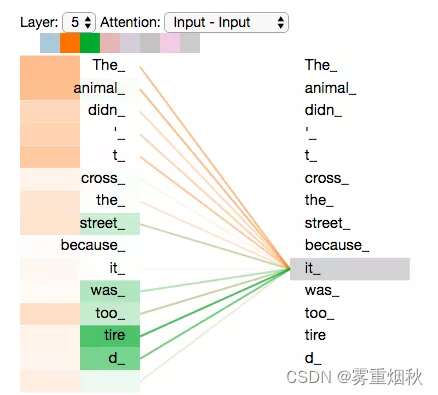
当我们编码it时,其中一个attention head(橙色注意力头)最关注的是the animal,另外一个绿色attention head关注的是tired。因此在某种意义上,it在模型中的表示,融合了animal和tire的部分表达。
Attention代码实例
下面的代码实现,张量的第一维时batch size,第2维是句子长度。代码中进行了详细的注释和说明。
import torch
from torch import nnclass MultiheadAttention(nn.Module):# n_heads: 多头注意力的数量# hid_dim: 每个词输出的向量维度def __init__(self, hid_dim, n_heads, dropout):super(MultiheadAttention, self).__init__()self.hid_dim = hid_dimself.n_heads = n_heads# 强制 hid_dim 必须整除 n_headsassert hid_dim % n_heads == 0# 定义 W_q 矩阵self.w_q = nn.Linear(hid_dim, hid_dim)# 定义 W_k 矩阵self.w_k = nn.Linear(hid_dim, hid_dim)# 定义 W_v 矩阵self.w_v = nn.Linear(hid_dim, hid_dim)self.fc = nn.Linear(hid_dim, hid_dim)self.do = nn.Dropout(dropout)# 缩放self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads]))def forward(self, query, key, value, mask=None):# 注意Q, K, V的在句子长度这一个维度可以一样,可以不一样。# K: [64,10,300], 假设batch_size为64,有10个词,每个词的Query向量是300# V: [64,10,300], 假设batch_size为64,有10个词,每个词的Query向量是300# Q: [64,12,300], 假设batch_size为64,有12个词,每个词的Query向量是300bsz = query.shape[0]Q = self.w_q(query)K = self.w_k(key)V = self.w_v(value)# 这里把 K Q V 矩阵拆分为多组注意力# 最后一维就是用 self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度,# 每个 head 的向量长度是:50# 64 表示 batch size,6 表示有 6 组注意力,10 表示有 10 词,50 表示每组注意力的词的向量长度# K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 [64,6,10,50]# V: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 [64,6,10,50]# Q: [64,12,300] 拆分多组注意力 -> [64,12,6,50] 转置得到 [64,6,12,50]# 转置是为了把注意力的数量 6 放到前面, 把 10 和 50 放到后面,方便下面计算Q = Q.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)K = K.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)V = V.view(bsz, -1, self.n_heads, self.hid_dim // self.n_heads).permute(0, 2, 1, 3)# 第 1 步: Q 乘以 K的转置,除以scale# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]# attention: [64,6,12,10]attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale# 如果 mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10,# 这里用“0”来指示哪些位置的词向量不能被attention到,比如padding位置,当然也可以用“1”或者其他数字来指示,主要设计下面2行代码的改动。if mask is not None:attention = attention.masked_fill(mask == 0, -1e10)# 第 2 步: 计算上一步结果的 softmax,再经过 dropout,得到 attention# 注意,这里是对最后一维做 softmax,也就是在输入序列的维度做 softmax# attention: [64,6,12,10]attention = self.do(torch.softmax(attention, dim=-1))# 第 3 步: attention结果与V相乘,得到多头注意力的结果# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]# x: [64,6,12,50]x = torch.matmul(attention, V)# 因为 query 有 12 个词,所以把 12 放到前面,把 50 和 6 放到后面,方便下面拼接多组的结果# x: [64,6,12,50] 转置-> [64,12,6,50]x = x.permute(0, 2, 1, 3).contiguous() # contiguous确保张量在内存中是连续的# 这里的矩阵转换就是:把多组注意力的结果拼接起来# 最终结果就是 [64,12,300]# x: [64,12,6,50]->[64,12,300]x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))x = self.fc(x)return x# batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(64, 12, 300)
# batch_size 为 64,有 12 个词,每个词的 Key 向量是 300 维
key = torch.rand(64, 10, 300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value = torch.rand(64, 10, 300)
attention = MultiheadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
# output: torch.Size([64, 12, 300])
print(output.shape)
残差连接
到目前为止,我们计算得到了self-attention的输出向量。而单层encoder里后续还有两个重要的操作:残差链接、标准化。
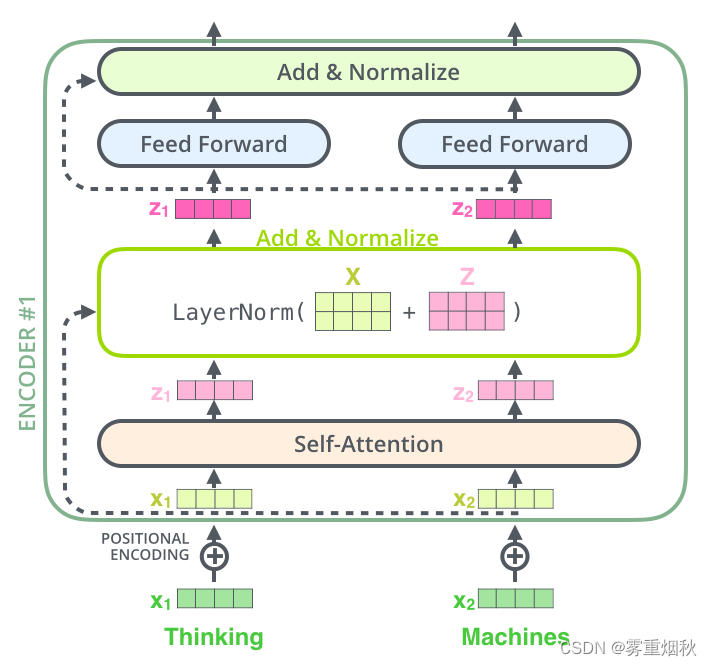
编码器的每个子层(Self Attention 层和 FFNN)都有一个残差链接和层标准化(Layer normalization),如下图所示。
将Self-Attention层的层标准化和涉及的向量计算细节都进行可视化,如下图所示。
编码器和解码器的子层里面都有层标准化。假设一个Transformer是由2层编码器和2层解码器组成的,将全部内容细节展示起来如下图所示。
解码器
现在我们已经介绍了编码器中的大部分概念,我们也知道了编码器的原理。现在让我们看下,编码器和解码器是如何协同工作的。
编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量,这组序列向量会作为解码器的 K , V K,V K,V输入,其中 K = V = 解码器输出的序列向量表示 K=V=解码器输出的序列向量表示 K=V=解码器输出的序列向量表示。这些注意力向量将会输入到每个解码器的Encoder-Decoder Attention层,这有助于解码器把注意力集中到输入序列的合适位置,如下图所示。

解码(Decoding)阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译),解码器当前时间步的输出又重新作为输入 Q Q Q和编码器的输出 K , V K,V K,V共同作为下一个时间步解码器的输入。然后重复这个过程,直到输出一个结束符(这种是自回归式解码,所以看起来有顺序,不能并行)。如下图所示:

解码器中的Self Attention层和编码器中的Self Attention层的区别:
- 在解码器里,Self Attention层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在Self Attention分数经过Softmax层之前,屏蔽当前位置之后的那些位置(将 attention score设置为-inf)。
- 解码器Attention层是使用前一层的输出来构造Query矩阵,而Key矩阵和Value矩阵来自于编码器最终的输出。
线性层和softmax
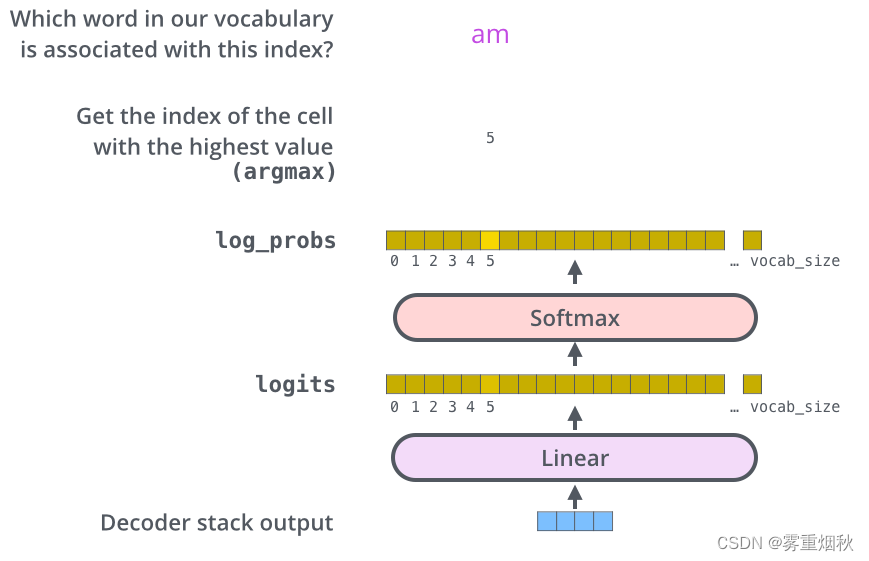
Decoder最终的输出是一个向量,其中每个元素是浮点数。我们通过线性层和softmax将这个向量转换为单词。
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为logits向量:假设我们的模型有10000个英语单词(模型的输出词汇表),此logits向量便会有10000个数字,每个数表示一个单词的分数。
然后,Softmax层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于1).然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
损失函数
Transformer训练的时候,需要将解码器的输出和label一同送入损失函数,以获得loss,最终模型根据loss进行方向传播,在下面用一个例子来说明训练过程的loss计算:把”merci“翻译为”thanks“。
我们希望模型解码器最终输出的概率分布,会指向单词”thanks“。但是,一开始模型还没训练好,它输出的概率分布可能和我们希望的概率分布相差甚远。如下图,正确的概率分布应该是”thanks“单词的概率最大。但是,由于模型的参数都是随机初始化的,所以一开始模型预测所有词的概率几乎都是随机的。
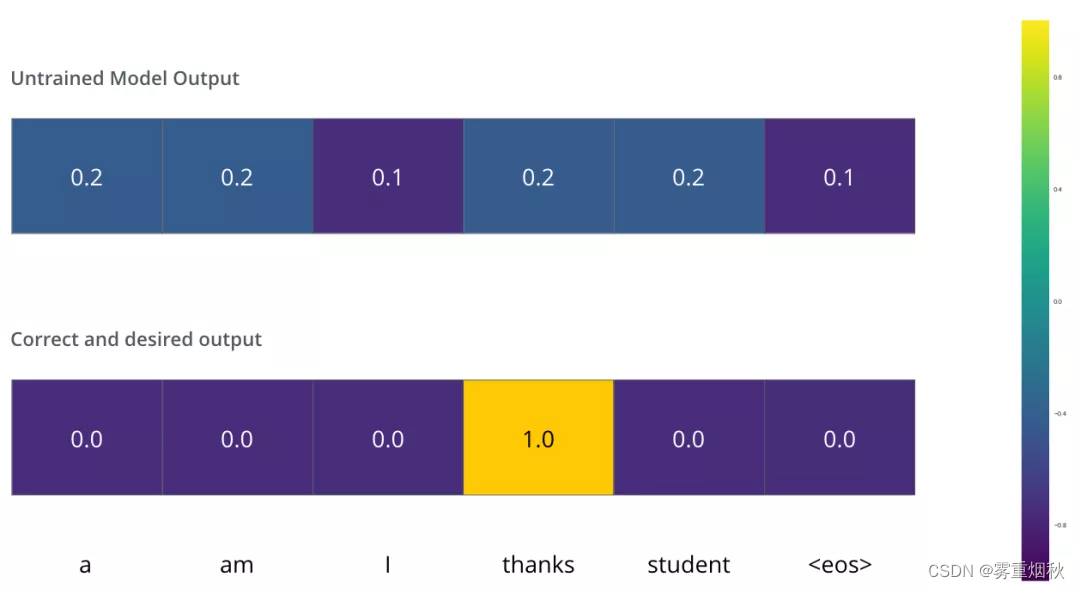
只要Transformer解码器预测了一组概率,我们就可以把这组概率和正确的输出概率做对比,然后使用反向传播来调整模型的权重,使得输出的概率分布更加接近整数输出。
那我们要怎样比较两个概率分布:我们可以简单的用两组概率向量的空间距离作为loss(向量相减,然后求平方和,再开方),当然也可以用交叉熵(cross-entropy)和KL散度(Kullback-Leibler divergence)。
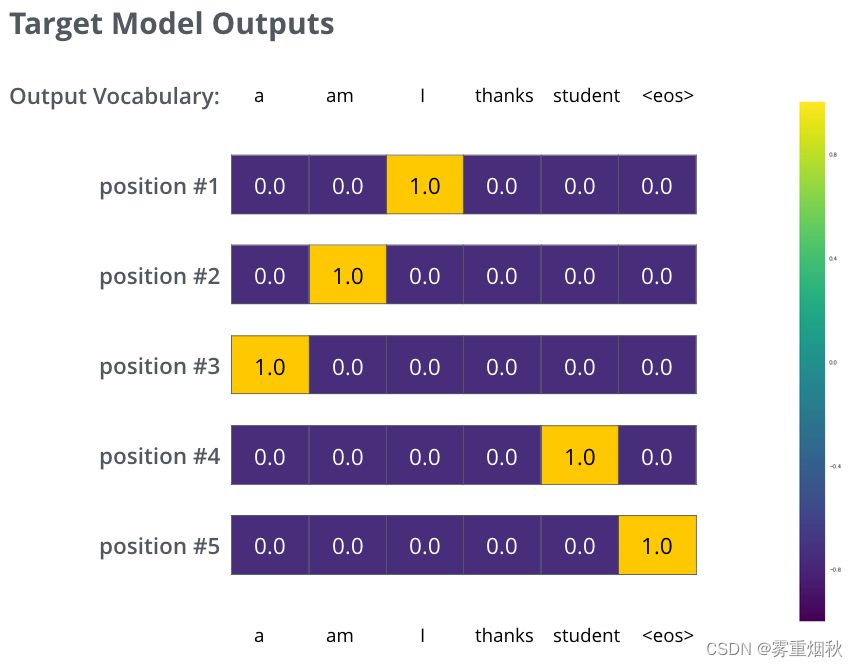
由于上面仅有一个单词的例子太简单了,我们可以再看一个复杂一点的例子。句子输入是:”je suis étudiant“,输出是:”i am a student“。这意味着,我们的transformer模型解码器要多次输出概率分布向量:
- 每次输出的概率分布都是一个向量,长度是
vocab_size(前面约定最大的vocab size,也就是向量长度是6,但实际中的vocab size更可能是30000或者50000) - 第1次输出的概率分布中,最高概率对应的单词是”i“
- 第2次输出的概率分布中,最高概率对应的单词是”am“
- 以此类推,直到第5个概率分布中,最高概率对应的单词是”“,表示没有下一个单词了。
于是我们的目标概率分布如下图:
我们用例子中的句子训练模型,希望产生图中所示的概率分布,我们的模型在一个足够大的数据集上,经过足够长时间的训练后,希望输出的概率分布如下图所示:
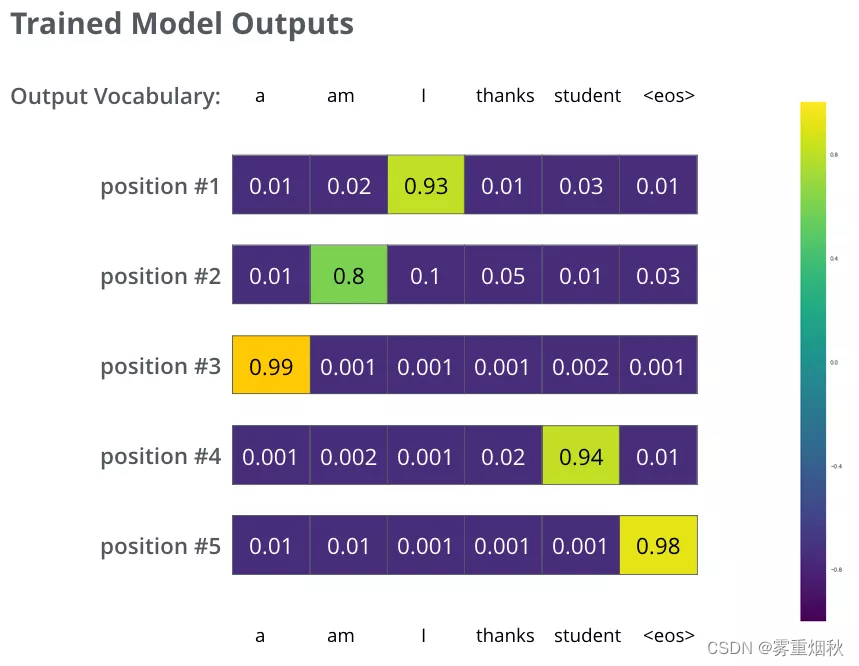
我们希望模型经过训练之后可以输出的概率分布也就对应了正确的翻译。当然,如果你要翻译的句子是训练集中的一部分,那输出的结果并不能说明什么。我们希望模型在没见过的句子上也能够准确翻译。
额外提一下greedy decoding和beam search的概念:
- Greedy decoding:由于模型每个时间步只产生一个输出,我们这样看待:模型是从概率分布中选择概率最大的词,并且丢弃其他词。这种方法叫做贪婪解码(greedy decoding)。
- Beam search:每个时间步保留k个最高概率的输出词,然后在下一个时间步,根据上一个时间步保留的k个词来确定当前应该保留哪k个词。假设k=2,第一个位置概率最高的两个输出词是”I“和”a“,这两个词都保留,然后根据第一个词计算第2个位置的词的概率分布,再取出第2个位置上2个概率最高的词。对于第3个位置和第4个位置,我们也重复这个过程。这种方法称为集束搜索(beam search)。
相关文章:
图解Transformer学习笔记
教程是来自https://github.com/datawhalechina/learn-nlp-with-transformers/blob/main/docs/ 图解Transformer Attention为RNN带来了优点,那么有没有一种神经网络结构直接基于Attention构造,而不再依赖RNN、LSTM或者CNN的结构,这就是Trans…...

【Java并发编程之美 | 第一篇】并发编程线程基础
文章目录 1.并发编程线程基础1.1什么是线程和进程?1.2线程创建与运行1.2.1继承Thread类1.2.2实现Runnable接口1.2.3实现Callable接口(与线程池搭配使用)1.2.4小结 1.3线程常用方法1.3.1线程等待与通知1.3.2线程睡眠1.3.3让出CPU执行权1.3.4线…...
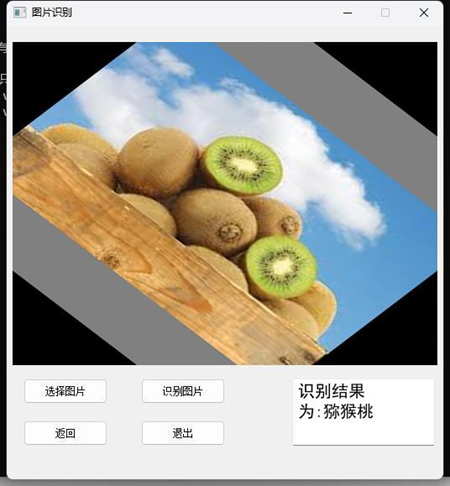
基于python-CNN卷积网络训练识别牛油果和猕猴桃-含数据集+pyqt界面
代码下载地址: https://download.csdn.net/download/qq_34904125/89383066 本代码是基于python pytorch环境安装的。 下载本代码后,有个requirement.txt文本,里面介绍了如何安装环境,环境需要自行配置。 或可直接参考下面博文…...
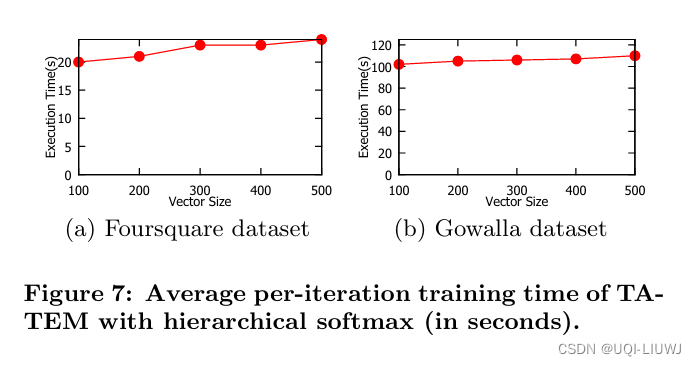
论文笔记:ATime-Aware Trajectory Embedding Model for Next-Location Recommendation
Knowledge and Information Systems, 2018 1 intro 1.1 背景 随着基于位置的社交网络(LBSNs),如Foursquare和Facebook Places的日益流行,大量用户签到数据变得可用 这些大量签到数据的可用性带来了许多有用的应用,以…...

深度学习之---迁移学习
目录 一、什么是迁移学习 二、为什么需要迁移学习? 1. 大数据与少标注的矛盾: 2. 大数据与弱计算的矛盾: 3. 普适化模型与个性化需求的矛盾: 4. 特定应用(如冷启动)的需求。 三、迁移学习的基本问题有…...

百度网盘限速解决办法
文章目录 开启P2P下载30秒会员下载体验一次性高速下载服务导入“百度网盘青春版”后下载注册新号参与活动 获取下载直链后使用磁力链接下载不是办法的办法无效、已失效方法免限速客户端、老版本客户端、永久会员下载体验试用客户端,或类似脚本、工具获取下载直链后多…...
银河麒麟系统项目部署
使用服务器信息 软件:VMware Workstation Pro 虚拟机:ubtun 内存:20G 虚拟机连接工具: MobaXterm Redis连接工具: RedisDesktopManager 镜像:F:\Kylin-Server-10-8.2-Release-Build09-20211104-X86_64…...

Stable Diffusion【应用篇】【艺术写真】:粘土风之后陶瓷风登场,来看看如何整合AI艺术写真吧
在国外的APP Remini引爆了粘土滤镜后,接着Remini又推出了瓷娃娃滤镜。相当粘土滤镜,个人更喜欢瓷娃娃滤镜,因为陶瓷工艺更符合东方艺术审美。 下面我们就来看看陶瓷特效在AI写真方面的应用。话不多说,我们直接开整。 关于粘土整…...

手机IP地址距离多远会变:解析移动设备的网络定位奥秘
在移动互联网时代,手机IP地址扮演着至关重要的角色,它不仅是我们访问网络的基础,还常常与网络定位、地理位置服务等相关联。那么,手机IP地址在距离多远时会发生变化呢?手机IP地址距离多远会变?下面跟着虎观…...

ChatGPT中文镜像网站分享
ChatGPT 是什么? ChatGPT 是 OpenAI 开发的一款基于生成预训练变换器(GPT)架构的大型语言模型。主要通过机器学习生成文本,能够执行包括问答、文章撰写、翻译等多种文本生成任务。截至 2023 年初,ChatGPT 的月活跃用户…...

碳化硅陶瓷膜良好的性能
碳化硅陶瓷膜是一种高性能的陶瓷材料,以其独特的物理和化学特性,在众多领域展现出了广泛的应用前景。以下是对碳化硅陶瓷膜的详细介绍: 一、基本特性 高强度与高温稳定性:碳化硅陶瓷膜是一种非晶态陶瓷材料,具有极高的…...
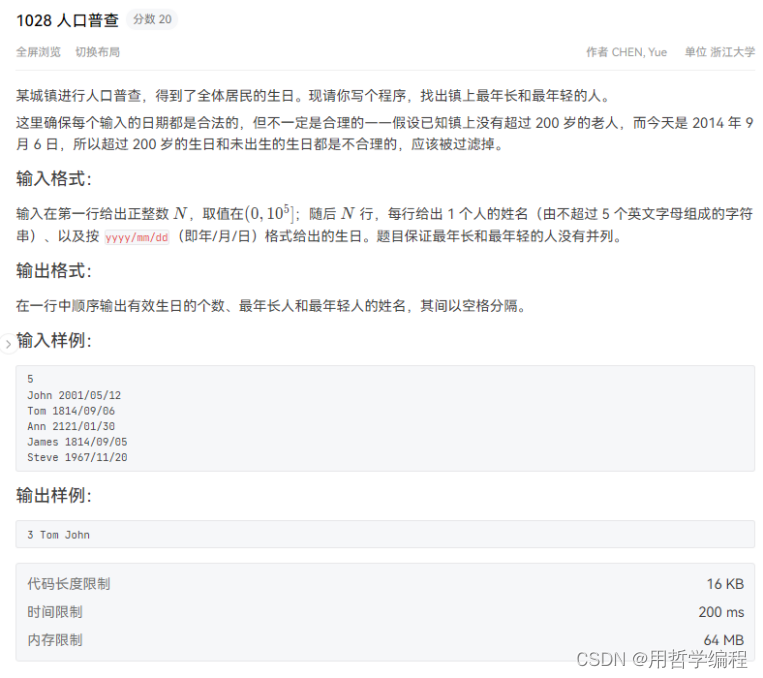
每日一题——Python实现PAT乙级1028 人口普查 Keyboard(举一反三+思想解读+逐步优化)六千字好文
一个认为一切根源都是“自己不够强”的INTJ 个人主页:用哲学编程-CSDN博客专栏:每日一题——举一反三Python编程学习Python内置函数 Python-3.12.0文档解读 目录 题目链接编辑我的写法 专业点评 时间复杂度分析 空间复杂度分析 总结 我要更强…...
小程序 UI 风格,构建美妙视觉
小程序 UI 风格,构建美妙视觉...

使用Python在VMware虚拟机中模拟Ubuntu服务器搭建网站
在此之前可以先使用VS Code连接到虚拟机:Visual Studio Code连接VMware虚拟机-CSDN博客 安装Web服务器Apache sudo apt-get install apache2 在个别情况下需要对Apache服务器的配置文件进行调整: 打开etc路径下的apache2文件夹,根据端口…...

腾讯测试开发<ieg 实验室>
3.26 40min 自我介绍实习经历有无遇到什么难点,你是如何克服的在这个项目中你大概做了多少个测试用例,这么多测试用例你平时用什么工具进行管理的,每一次跑全部还是每次只跑一部分现在假设给你一个新的项目,需要你这边去做测试&a…...

windows命令帮助大全
有关某个命令的详细信息,请键入 HELP 命令名 ASSOC 显示或修改文件扩展名关联。 ATTRIB 显示或更改文件属性。 BREAK 设置或清除扩展式 CTRLC 检查。 BCDEDIT 设置启动数据库中的属性以控制启动加载。 CACLS 显示或修改文件的访问控制列表(ACL)。 CALL 从另一个批处…...
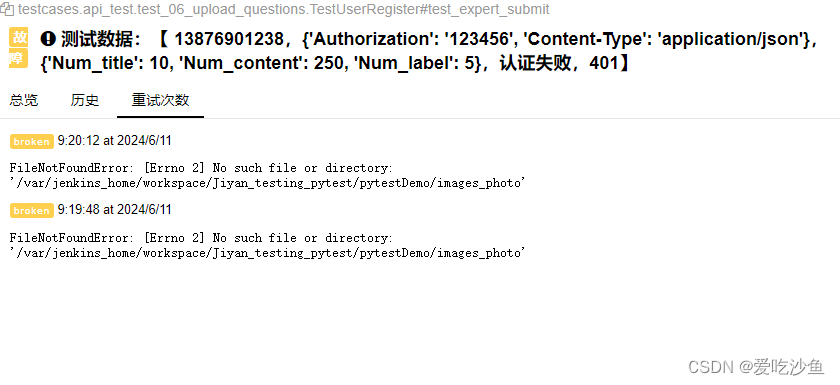
pytest中失败用例重跑
pip install pytest-rerunfailures 下载rerunfailures插件包 配置文件中加入命令 --reruns 次数 也可在命令行中pytest --rerun-failures2 可以在allure报告中看到重试效果...
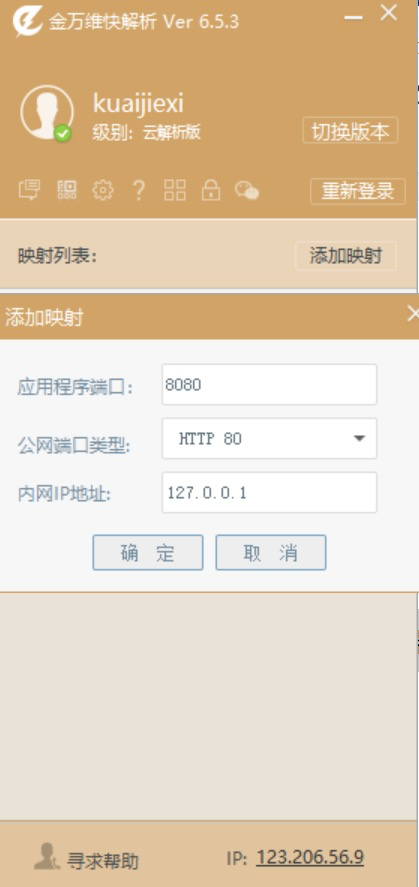
http穿透怎么做?
众所周知http协议的默认端口是80,由于国家工信部要求,域名必须备案才给开放80端口,而备案需要固定公网IP,这就使得开放http80端口的费用成本和时间成本变的很高。那么能不能利用内网穿透技术做http穿透呢?下面我就给大…...

前端技术回顾系列 11|TS 中一些实用概念
在微信中阅读,关注公众号:CodeFit。 创作不易,如果你觉得这篇文章对您有帮助,请不要忘了 点赞、分享 和 关注 我的公众号:CodeFit,为我的持续创作提供动力。 上文回顾:泛型在类和接口中的应用 上一篇文章我们回顾了 泛型 在 类 和 接口 中的应用。 通过使用泛型,我们…...

leetcode LRU 缓存
leetcode: LRU 缓存 LRU 全称为 Least Recently Used,最近最少使用,常常用于缓存机制,比如 cpu 的 cache 缓存,使用了 LRU 算法。LRU 用于缓存机制时,关键的是当缓存满的时候有新数据需要加载到缓存的,这个…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...
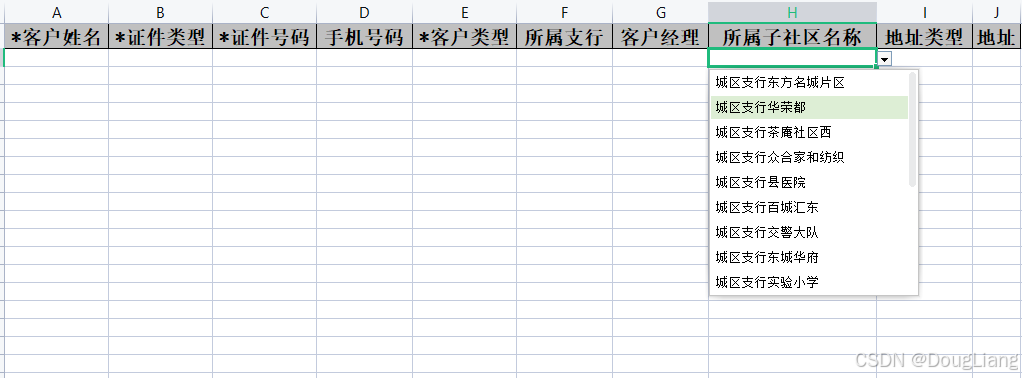
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...
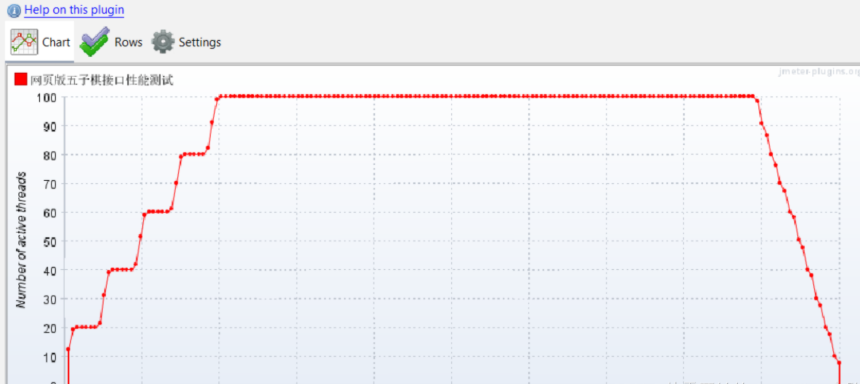
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...