强化RAG:微调Embedding还是LLM?

为什么我们需要微调?
微调有利于提高模型的效率和有效性。它可以减少训练时间和成本,因为它不需要从头开始。此外,微调可以通过利用预训练模型的功能和知识来提高性能和准确性。它还提供对原本无法访问的任务和领域的访问,因为它允许将预先训练的模型转移到新场景。换句话说,这一切都是为了获得更好的结果、减少奇怪的输出、更好地记住数据以及节省时间和金钱。
虽然微调也可用于使用外部数据“增强”模型,但微调可以通过多种方式补充RAG:
Embedding微调的好处
- 微调Embedding模型可以在数据训练分布上实现更有意义的Embedding表示,从而带来更好的检索性能。
LLM微调的好处
- 允许它学习给定数据集的风格
- 允许它学习训练数据中可能较少出现的 DSL(例如 SQL)
- 允许它纠正可能难以通过提示工程修复的幻觉/错误
- 允许它将更好的模型(例如 GPT-4)提炼成更简单/更便宜的模型(例如 GPT-3.5、Llama 2)
简而言之,微调有助于更好的相似性搜索,这是获取正确数据以及生成正确答复所必须的前提。
微调主要有两种类型。第一个是微调Embedding,目的是提高数据检索的准确性,第二个是微调LLM,将领域知识注入到现有的LLM中。第一个是 RAG 特定的,而第二个是通用的。
微调Embedding
大型语言模型 (LLM) 可以处理广泛的任务,包括情感分析、信息提取和问答。正确的架构、深思熟虑的训练过程以及整个互联网训练数据的可用性结合在一起,使它们能够胜任某些任务。
LLM经过训练,可以使用这些大量数据在许多领域进行泛化,产生一个总体上很优秀但缺乏特定领域知识的模型。这时,微调就变得很重要。
微调过程涉及更改语言模型以更好地适应数据领域。例如,想要处理大量有关患者的医院文书工作,因此可能希望将LLM专门研究这些类型的文本。
LlamaIndex 关于微调Embedding的包含三个主要步骤:
- 从数据生成综合问题-答案pari对数据集
- 微调模型
- 评估模型
微调Embedding
步骤总结:
- 切分训练集和验证集
- 使用LlamaIndex内置函数generate_qa_embedding_pairs生成训练数据集的问题/答案。此步骤将调用 LLM 模型(默认使用 OpenAI,可以替换为自己本地模型,例如ChatGLM、baichuan)来生成合成数据集
- 使用SentenceTransformersFinetuneEngine与HuggingFace模型“m3e”模型进行微调。m3e模型可以提前下载到本地,避免网络访问的错误问题。

- 使用hit rate 指标进行评估。
微调Adapter
这是微调Embedding的升级版本。基本的微调Embedding只需使用SentenceTransformersFinetuneEngine提供的开箱即用的功能即可。如果熟悉神经网络,那么layer、loss和 ReLU 等都不陌生。这个Adapter就是这样,让我们能够更好地控制微调过程。
步骤总结:
- 与微调Embedding的步骤 1 类似,切分训练集和验证集
- 类似于微调Embedding的步骤 2,构建合适的数据集
- 使用 EmbeddingAdapterFinetuneEngine ,而不是使用 SentenceTransformersFinetuneEngine 。可以使用预定义的TwoLayerNN将图层作为参数添加到EmbeddingAdapterFinetuneEngine中,如下所示

- 与基本微调Embedding的步骤4类似
Router微调
我自己并不经常使用这种微调,这种类型的微调对于router查询很有用。但路由器查询是非常特定于数据域的,添加这种Embedding只会增加 RAG 的复杂性。
路由器的快速总结:不能扔一堆文档进行Embedding,然后在其上构建检索。这种方法不会给你带来任何好的结果,甚至是一个不可接受的结果。因此 LlamaIndex 引入了一个奇妙的概念,称为 Router。路由器是 LLM 实现自动化决策的重要一步,这本质上将 LLM 视为分类器
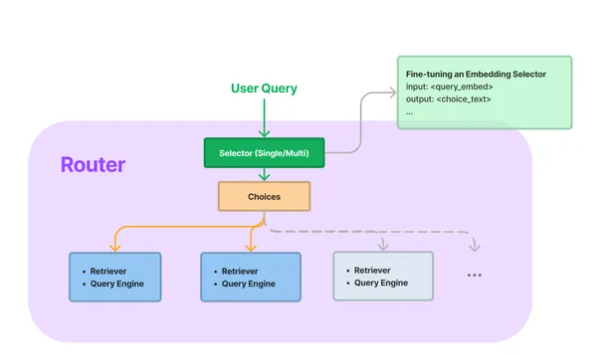
但是,基础路由器有时很差劲,查询和索引之间的匹配率非常低。为了解决这个问题,LlamaIndex 现在可以微调路由器。这将有助于减少每个查询运行的循环数量,因此期望结果更快。但结果有时还是很可怕。
基本上,对于每个文档,在其上构建多个索引,例如 VectorIndex、SummaryIndex、KeywordIndex 等,然后给出每个索引的元数据或描述,然后在此基础上构建代理,并使用元数据描述来告诉 LLM这个代理是做什么的。如果有 100 万份文档,那么就有 100 万个代理。每次进行查询时,LLM 都需要通过 100 万个代理来找出最适合用来回答问题的代理。因此,它是非常慢的。为了解决这个问题,LlamaIndex 将当前版本升级到另一个版本,该版本基本上是在文档(工具)检索期间重新排名代理可以用来规划的查询规划工具。
仅当设计的 RAG 系统以路由器为中心时,否则,ReAct 代理或多代理是更好的方法。
Cross-Encoder微调
简而言之,Bi-Encoder 就是使用双编码器,将句子 A 和句子 B 转换为句子Embedding A1 和句子Embedding B1。然后可以使用余弦相似度来比较这些句子Embedding。
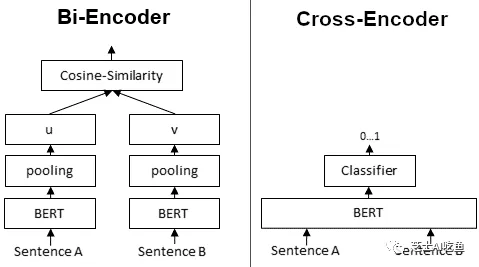
相反,对于交叉编码器,我们将两个句子同时传递到 Transformer 网络。它产生一个介于 0 和 1 之间的输出值,表示输入句子对的相似度
交叉编码器不会产生句子Embedding。此外,我们无法将单个句子传递给交叉编码器。
交叉编码器比双编码器具有更好的性能。然而,对于许多应用来说,它们并不实用,因为它们不产生Embedding,我们可以使用余弦相似度进行索引或有效比较。
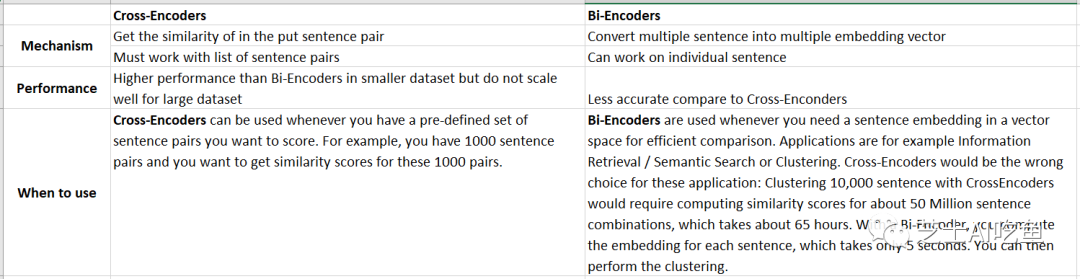
交叉编码器比双编码器具有更高的性能,但是,它们对于大型数据集的扩展性不佳。在这里,结合交叉编码器和双向编码器是有意义的,例如在信息检索/语义搜索场景中:首先,使用高效的双向编码器来检索查询的前 100 个最相似的句子。然后,使用交叉编码器通过计算每个(查询、命中)组合的分数来重新排名这 100 个命中。
微调LLM
因此,已经完成了Embedding的微调,如上所述,微调Embedding有助于提高数据检索的准确性。如果是这样,我们是否需要对LLM进行微调?
因为并非每次都需要 RAG。开发功能齐全的 RAG 每一步都很复杂。拥有一个好的RAG应用程序需要一个由优秀的软件工程师组成的团队来开发前端和可扩展的后端,优秀的数据工程师来处理用于开发RAG的数据管道和多个数据库,一些优秀的机器学习工程师+数据科学家开发模型并对文本块、Embedding性能、良好的数据检索方法进行实验,然后合成数据、路由器、代理等。更不用说将需要良好的 MLOps 来监控 RAG 的性能。
如果可以通过在新数据上逐步微调 LLM 来简化所有这些方法,会怎么样?使其成为 ChatGPT,但根据自己的数据进行微调。会更容易吗?
大多数LLM/RAG以PoC为主。它可以处理小数据集并在非常特定的情况下处理得很好,但很难扩展或处理现实生活中的用例。
但我们假设有资金定期调整LLM课程。我们该怎么做呢?
LlamaIndex 有多种选项可以帮助微调的LLM。主要目的是改进较小模型以超越较大参数规模模型。假设 GPT-4 对你的应用程序来说非常好,但它会让公司破产,因为它很昂贵。GPT-3.5 更便宜,性能也可以接受,但希望 GPT-4 的性能让的客户满意。那么你可能会想到微调LLM。
为什么要微调LLM
如前所述,微调不仅可以提高基本模型的性能,而且较小(微调)的模型通常可以在训练它的任务集上胜过较大(更昂贵)的模型。OpenAI 通过其第一代“InstructGPT”模型证明了这一点,其中 1.3B 参数 InstructGPT 模型补全优于 175B 参数 GPT-3 基本模型,尽管其尺寸要小 100 倍。
其中一大问题是LLM的背景知识是有限的。因此,该模型可能在需要大量知识库或特定领域信息的任务上表现不佳。微调模型可以通过在微调过程中“学习”这些信息,或者换句话说,使用最新数据更新模型来避免此问题。GPT-4 仅拥有 2023年3月之前的知识。微调 LLM 将使用的私人数据更新模型并减少幻觉,也不需要 RAG,因为微调 LLM 已经更新了的数据。
改进 RAG 很困难,有多个步骤,根据我的经验,可以显着改进 RAG 的最重要步骤是文本块和Embedding。因此,微调Embedding模型是必要的(但是不是必须的)步骤。此外,微调LLM将更新现有LLM的行为,从而减少响应中的幻觉并提供更好的综合答案。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
相关文章:
强化RAG:微调Embedding还是LLM?
为什么我们需要微调? 微调有利于提高模型的效率和有效性。它可以减少训练时间和成本,因为它不需要从头开始。此外,微调可以通过利用预训练模型的功能和知识来提高性能和准确性。它还提供对原本无法访问的任务和领域的访问,因为它…...

提取 Excel单元格文本下的超链接
在Excel中,可以使用内置的函数来提取单元格中的超链接地址。如果你有一个包含超链接的单元格,例如B1,你可以使用以下步骤来提取这个超链接: 在一个新的单元格(例如C1)中,输入以下公式ÿ…...

一键安全体检!亚信安全携手鼎捷软件推出企业安全体检活动 正式上线
亚信安全联合鼎捷软件股份有限公司(以下简称“鼎捷软件”)正式推出“一键安全体检”服务。亚信安全网络安全专家将携手鼎捷软件数据安全专家,围绕企业的数智安全状况,进行问题探索与治愈、新问题预测与预警,在全面筛查…...
)
numpy - array(1)
一维数据:向量 二位数据:矩阵 维度超过三维的数据:张量 这些数据在numpy中统称array (1)使用穷举法创建多为数据,接受列表或者元组类型的数据 a numpy.array([1, 2, 3]) b numpy.array([[1, 2, 3], (4, 5, 6), [7, 8, 9]]) (2)创建所有元…...
师彼长技以助己(6)递归思维
师彼长技以助己(6)递归思维 递归思维-小游戏 思维小游戏 思维 小游戏:1 玩一个从1或2开始往上加的游戏,谁加到20就赢 如何保证一定赢呢?我们倒推,要先到20的话,谁先到17就赢,如此…...

Kali Linux 2024.2
Kali Linux 2024.2 版本(t64、GNOME 46 和社区包) 比平常晚了一点,但 Kali 2024.2 来了!延迟是由于实现这一目标的幕后变化所致,这也是人们关注的焦点。社区提供了大量帮助,这次他们不仅添加了新的软件包&…...
【Spine学习08】之短飘,人物头发动效制作思路
上一节说完了跑步的, 这节说头发发型。 基础过程总结: 1.创建骨骼(头发需要在上方加一个总骨骼) 2.创建网格(并绑定黄线) 3.绑定权重(发根位置的顶点赋予更多总骨骼的权重) 4.切换到…...

chatgpt的命令词
人不走空 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌赋:斯是陋室,惟吾德馨 目录 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌…...

用python把docx批量转为pdf
为保证转换质量,本文的方法是通过脚本和com技术调用office自带的程序进行转换的,因此需要电脑已经装有office。如果希望不装office也能用,则需要研究OpenXML技术,后面实在闲的慌(退休)再搞。 安装所需库 …...

项目采购管理
目录 1.概述 2.三个子过程 2.1.规划采购管理 2.2.实施采购 2.3.控制采购 2.4.归属过程组 3.应用场景 3.1.十个应用场景 3.2.软件开发项目 3.2.1. 需求识别和分析 3.2.2. 制定采购计划 3.2.3. 发布采购请求 3.2.4. 供应商评估与选择 3.2.5. 合同签订 3.2.6. 采购…...

Elasticsearch 认证模拟题 - 18
一、题目 为一个索引,按要求设置以下 dynamic Mapping 一切 text 类型的字段,类型全部映射成 keyword一切以 int_ 开头命名的字段,类型都设置成 integer 1.1 考点 字段的动态映射 1.2 答案 # 创建索引和索引模板 PUT my_index {"m…...

Python基础-速记笔记
Python的基础数据类型都有哪些? 1、字符串(string)2、布尔类型(bool)3、整数(int) 4、浮点数(float)5、列表(list)6、集合(set)7、元组(tuple)8、字典(dict) 其中不可变类型有: 字符串(string)、布尔类型(bool)、整数(int) 、浮点数(float)、元组(tup…...

青少年编程与数学 01-001开始使用计算机 02课题、计算机操作系统3_3
青少年编程与数学 01-001开始使用计算机 02课题、计算机操作系统3_3 四、Linux操作系统安装(一) 准备工作(二)设置BIOS/UEFI(三) 安装Linux(四)磁盘分区(五)安…...
填表统计预约打卡表单系统(FastAdmin+ThinkPHP+UniApp)
填表统计预约打卡表单系统:一键搞定你的预约与打卡需求 填表统计预约打卡表单系统是一款基于FastAdminThinkPHPUniApp开发的一款集信息填表、预约报名,签到打卡、活动通知、报名投票、班级统计等功能的自定义表单统计小程序。 📝 一、引言…...
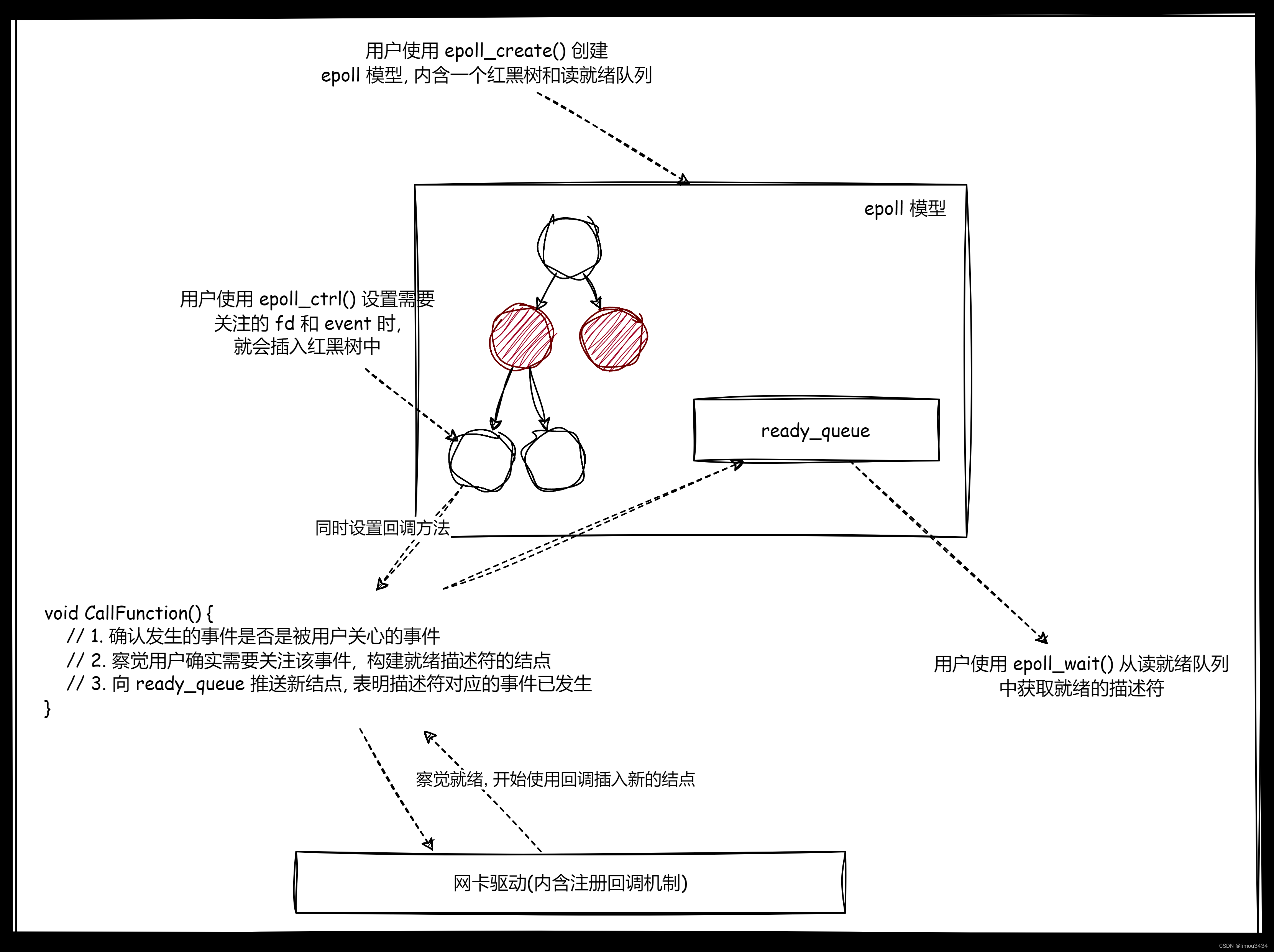
IO模型和多路转接
叠甲:以下文章主要是依靠我的实际编码学习中总结出来的经验之谈,求逻辑自洽,不能百分百保证正确,有错误、未定义、不合适的内容请尽情指出! 文章目录 1.IO 概要1.1.IO 低效原因1.2.IO 常见模型1.2.1.阻塞 IO1.2.2.非阻…...

如何完美解决升级 IntelliJ IDEA 最新版之后遇到 Git 记住密码功能失效的问题
🛠️ 如何完美解决升级 IntelliJ IDEA 最新版之后遇到 Git 记住密码功能失效的问题 摘要 在这篇文章中,我们将详细探讨如何解决在升级到 IntelliJ IDEA 最新版(2024.1.3 Ultimate Edition)后遇到的 Git 记住密码功能失效的问题。…...

SpringCloud微服务架构(eureka、nacos、ribbon、feign、gateway等组件的详细介绍和使用)
一、微服务演变 1、单体架构(Monolithic Architecture) 是一种传统的软件架构模式,应用程序的所有功能和组件都集中在一个单一的应用中。 在单体架构中,应用程序通常由一个大型的、单一的代码库组成,其中包含了所有…...

flinksql BUG : flink hologres-cdc source FINISHED
org.apache.flink.runtime.JobException: The failure is not recoverable or the failure does not allow to restart.at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler...
现代密码学-国密算法
商用密码算法种类 商用密码算法 密码学概念、协议与算法之间的依赖关系 数字签名、证书-公钥密码、散列类算法 消息验证码-对称密码 ,散列类 安全目标与算法之间的关系 机密性--对称密码、公钥密码 完整性--散列类算法 可用性--散列类、公钥密码 真实性--公…...
Postman简介
目录 1.概述 2.诞生背景 3.历史版本 4.安装和卸载 5.菜单和菜单项 6.使用 7.应用场景 8.示例 8.1.简单的GET请求 8.2.POST请求提交数据 8.3.查询参数 9.未来展望 10.总结 1.概述 Postman是一款用于API开发、测试和文档管理的综合性工具。允许开发者和测试人员创建…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...