【C++11】第一部分(一万六千多字)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
C++11简介
统一的列表初始化
{}初始化
std::initializer_list
声明
auto
decltype
右值引用和移动语义
左值引用和右值引用
左值引用与右值引用比较
右值引用使用场景和意义
右值引用引用左值及其一些更深入的使用场景分析
完美转发
新的类功能
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在努力学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所帮助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的道路上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
C++11简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了 C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞 进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。 从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于 C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中 约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言, C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更 强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个 重点去学习。C++11增加的语法特性篇幅非常多,我们这里没办法一 一讲解,所以本节课程主要讲解实际中比较实用的语法。
https://en.cppreference.com/w/cpp/11
小故事:
1998年是C++标准委员会成立的第一年,本来计划以后每5年视实际需要更新一次标准,C++国际 标准委员会在研究C++ 03的下一个版本的时候,一开始计划是2007年发布,所以最初这个标准叫 C++ 07。但是到06年的时候,官方觉得2007年肯定完不成C++ 07,而且官方觉得2008年可能也 完不成。最后干脆叫C++ 0x。x的意思是不知道到底能在07还是08还是09年完成。结果2010年的 时候也没完成,最后在2011年终于完成了C++标准。所以最终定名为C++11。
统一的列表初始化
{}初始化
在C++98中,标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point
{int _x;int _y;
};
int main()
{int array1[] = { 1, 2, 3, 4, 5 };int array2[5] = { 0 };Point p = { 1, 2 };return 0;
}C++11扩大了用大括号括起的列表(列表初始化)的使用范围,使其可用于所有的内置类型和用户自 定义的类型,使用列表初始化时,可添加等号(=),也可不添加。
创建对象时也可以使用列表初始化方式调用构造函数初始化
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "Date(int year, int month, int day)" << endl;}
private:int _year;int _month;int _day;
};// 一切皆可用{}初始化 (和初始化列表不一样,是两回事)
int main()
{int a = 0;// 不推荐int b = { 1 };int c{ 1 };int array1[]{ 1, 2, 3, 4, 5 };Point p{ 1,2 };// 多参数// C++98 构造Date d1(2024, 3, 23);// C++11 // 构造一个日期类的临时对象 + 拷贝构造 -> 优化,直接构造// 多参数的隐式类型转换Date d2 = {2024, 3, 23};// 多参数不能直接写圆括号(),语法要求写{}Date d3 { 2024, 3, 23 };// 单参数// 构造string s1("1111");// 先构造创建一个临时对象 + 再拷贝构造,将临时对象拷贝给s2 -> 优化,直接构造string s2 = "1111";// 单参数的构造函数支持隐式类型转换//Date d4 = (2024, 3, 23 ); // 不支持// 数组中的元素类型是自定义的类型,所以默认初始化的用自定义类型的默认值// 如果数组是10,只初始化了3个,其它的7个就用默认值初始化,但是没有合适的构造函数,所以,将数组的大小改为3个Date* darr1 = new Date[3]{d1,d2,d3};// 调用的是拷贝的构造函数// 多参数也支持隐式类型转换,构造 + 拷贝构造 -> 优化,直接构造Date* darr2 = new Date[3]{ { 2024, 3, 23 } ,{ 2024, 3, 23 } ,{ 2024, 3, 23 } };Date* darr3 = new Date(2023,3,34);// 调用的构造Date* darr4 = new Date{ 2023, 3, 34 };return 0;
}std::initializer_list
std::initializer_list的介绍文档:
http://www.cplusplus.com/reference/initializer_list/initializer_list/
std::initializer_list是什么类型:
int main()
{// the type of il is an initializer_list auto il = { 10, 20, 30 };cout << typeid(il).name() << endl;return 0;
}
std::initializer_list使用场景:
std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加 std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator= 的参数,这样就可以用大括号赋值。
http://www.cplusplus.com/reference/list/list/list/
http://www.cplusplus.com/reference/vector/vector/vector/
http://www.cplusplus.com/reference/map/map/map/
http://www.cplusplus.com/reference/vector/vector/operator=/
int main()
{vector<int> v = { 1,2,3,4 };list<int> lt = { 1,2 };// 这里{"sort", "排序"}会先初始化构造一个pair对象map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };// 使用大括号对容器赋值v = { 10, 20, 30 };return 0;
}namespace bit
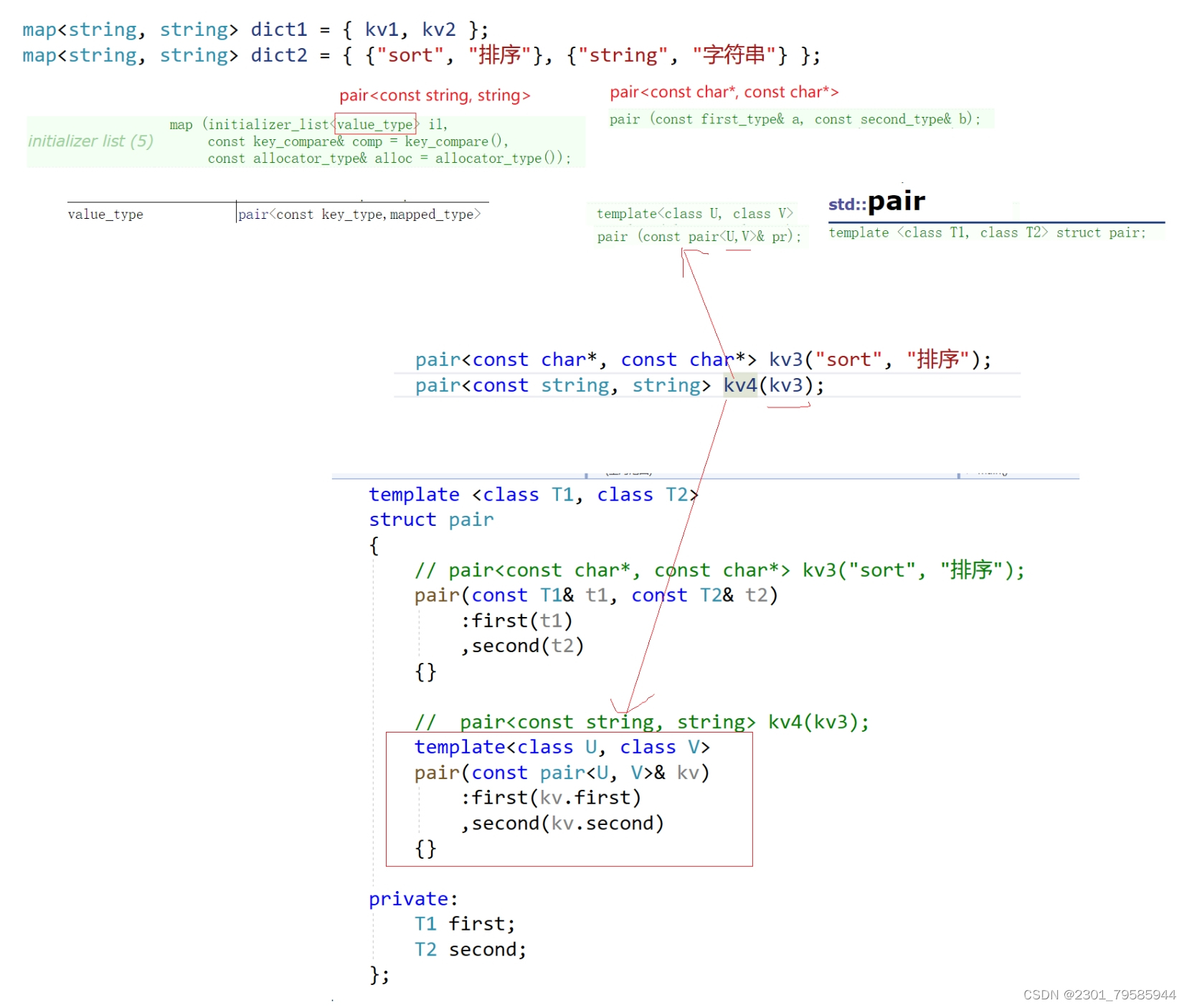
{template <class T1, class T2>struct pair{// pair<const char*, const char*> kv3("sort", "排序");pair(const T1& t1, const T2& t2):first(t1), second(t2){}// pair<const string, string> kv4(kv3);// kv3和kv4的类型不一样,为什么可以拷贝构造初始化呢?// 因为拷贝构造没有要求用同类型的模板参数来进行初始化,允许同一个模板不同的模板参数// 也能进行初始化template<class U, class V>pair(const pair<U, V>& kv): first(kv.first), second(kv.second){}private:T1 first;T2 second;};
}int main()
{Date d1 = { 2024, 3, 23 };auto il1 = { 1, 2, 3, 4, 5, 6, 7, 8, 9};// 这两个il1和il2是一回事initializer_list<int> il2 = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };cout << sizeof(il1) << endl;cout << sizeof(il2) << endl;// 画板:将{}中的值赋值给il对象,那么会把il对象的类型识别成一个initializer_list int// 可以将initializer_list看作一个容器,只不过这个容器不实际存储数据// 本质是:调用的是initializer_list的构造函数,initializer_list是C++11中增加的一个类型vector<int> v1 = { 1,2,3,4,5,6,7,8,9};for (auto e : v1){cout << e << " ";}cout << endl;v1 = { 10, 20,30 };pair<string, string> kv1("sort", "排序");pair<string, string> kv2("string", "字符串");map<string, string> dict1 = { kv1, kv2 };map<string, string> dict2 = { {"sort", "排序"}, {"string", "字符串"} };for (auto& kv : dict2){cout << kv.first << ":" << kv.second << endl;}// kv3和kv4都用的是pair类型的模板,但是模板参数不同,所以kv3和kv4的是不同的类型// 按理来说kv3是不能调用拷贝构造给kv4对象的,但是实际上是可以的// 因为kv4调用的是类模板的拷贝构造函数,所以它们的模板参数类型可以不一样pair<const char*, const char*> kv3("sort", "排序");pair<const string, string> kv4(kv3);return 0;
}
声明
c++11提供了多种简化声明的方式,尤其是在使用模板时。
auto
在C++98中auto是一个存储类型的说明符,表明变量是局部自动存储类型,但是局部域中定义局 部的变量默认就是自动存储类型,所以auto就没什么价值了。C++11中废弃auto原来的用法,将 其用于实现自动类型推断。这样要求必须进行显示初始化,让编译器将定义对象的类型设置为初 始化值的类型。
auto func3()
{auto z = 4;//...return z;
}auto func2()
{auto y = func3();return y;
}auto func1()
{auto ret = func2();//...return ret;
}// 切记:不要auto做返回值
int main()
{map<string, string> dict2 = { {"sort", "排序"}, {"string", "字符串"} };auto it2 = dict2.begin();cout << typeid(it2).name() << endl;auto x = func1();return 0;
}decltype
关键字decltype将变量的类型声明为表达式指定的类型。
int main()
{const int x = 1;double y = 2.2;// typeid(x).name:是帮助我们打印类型,但是我们不能用typeid(x).name再来帮我们定义一个变量cout << typeid(x).name() << endl;cout << typeid(string).name() << endl;// decltype可以推导出x的类型,并用可以用该类型定义一个变量z// 注意:上面x的类型是const int,decltype(x)和typeid(z).name所推到和打印出来的类型都是int,要去掉const// const是修饰x的类型不被改变,实际上x的类型还是intdecltype(x) z = 1;cout << typeid(z).name() << endl;// 顶层const:修饰的是变量本身// 底层const:修饰的是指针指向的内容// 所以p1和p2的类型是const int*const int* p1 = &x;cout << typeid(p1).name() << endl;// 结果:int const*decltype(p1) p2 = nullptr;cout << typeid(p2).name() << endl;// 结果:int const*auto ret = func1();// 假设要用vector存func1类型的数据vector<decltype(ret)> v;return 0;
} decltype:推导我们的类型
Python:运行慢的原因是因为它不编译,Python是边编译边运行
C++:是先编译,再运行
右值引用和移动语义
左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们 之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋 值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左 值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
int main()
{// 以下的p、b、c、*p, func2()返回值 都是左值int* p = new int(0);int b = 1;const int c = 2;const int* ptr1 = &c;int* ptr2 = &func2();printf("%p %p\n", ptr1, ptr2);// 左值引用就是给左值取别名(一个&)int*& rp = p;int& rb = b;const int& rc = c;int& pvalue = *p;return 0;
}// 不能说在左边的就是左值,在右边的就是右值
// 左值一般情况下可以修改,不能认为左值是一个变量或者对象,左值是一个表达式
int func()
{return 10;// 返回的右值
}int main()
{int i = 10;10 = i;// 右值不能在左边func() = 1;int j = 1;i + j = 10;// 表达式相加:拷贝的临时变量都是右值return 0;
}int func1()
{static int x = 0;return x;// 返回的是右值(返回的是x的拷贝,拷贝的临时变量)
}int& func2()
{static int x = 0;return x;// 返回的是左值(x的别名)
}什么是右值?什么是右值引用?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引 用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能 取地址。右值引用就是对右值的引用,给右值取别名。
int func1()
{static int x = 0;return x;// 返回的是右值(返回的是x的拷贝,拷贝的临时变量)
}int main()
{ double x = 1.1, y = 2.2;double& r1 = x;// 以下几个都是常见的右值10;x + y;func1();// 以下几个都是对右值的右值引用(两个&&)int&& rr1 = 10;double&& rr2 = x + y;double&& rr3 = fmin(x, y);// 这里编译会报错:error C2106: “=”: 左操作数必须为左值/*10 = 1;x + y = 1;fmin(x, y) = 1;*/return 0;
}需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可 以取到该位置的地址,也就是说例如:不能取字面量10的地址,但是rr1引用后,可以对rr1取地 址,也可以修改rr1。如果不想rr1被修改,可以用const int&& rr1 去引用,是不是感觉很神奇, 这个了解一下实际中右值引用的使用场景并不在于此,这个特性也不重要。
int main()
{double x = 1.1, y = 2.2;int&& rr1 = 10;const double&& rr2 = x + y;rr1 = 20;rr2 = 5.5; // 报错return 0;
}左值引用与右值引用比较
左值引用总结:
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值。
int main()
{// 左值引用只能引用左值,不能引用右值。int a = 10;int& ra1 = a;// ra为a的别名//int& ra2 = 10; // 编译失败,因为10是右值// const左值引用既可引用左值,也可引用右值。const int& ra3 = 10;const int& ra4 = a;return 0;
}右值引用总结:
- 右值引用只能右值,不能引用左值。
- 但是右值引用可以move以后的左值。
int main()
{// 右值引用只能右值,不能引用左值。int&& r1 = 10;// error C2440: “初始化”: 无法从“int”转换为“int &&”// message : 无法将左值绑定到右值引用int a = 10;int&& r2 = a;// 右值引用可以引用move以后的左值int&& r3 = std::move(a);return 0;
}总结一下:
- 语法上,引用都是别名,不开空间,左值引用是给左值取别名,右值引用是给右值取别名。
- 底层,引用是用指针实现的。左值引用是存当前左值的地址;右值引用,是把当前右值拷贝到栈上的一个临时空间,存储这个临时空间的地址。
右值引用使用场景和意义
前面我们可以看到左值引用既可以引用左值和又可以引用右值,那为什么C++11还要提出右值引 用呢?是不是化蛇添足呢?下面我们来看看左值引用的短板,右值引用是如何补齐这个短板的!
namespace bit
{class string{public:typedef char* iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str)" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 没有右值引用的重载的话,左值和右值都走它// 拷贝构造 -- 左值string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}// 移动构造 -- 右值(将亡值)string(string&& s){cout << "string(string&& s) -- 移动拷贝" << endl;swap(s);}// 拷贝赋值// s2 = tmpstring& operator=(const string& s){cout << "string& operator=(const string& s) -- 深拷贝" << endl;string tmp(s);// 调用拷贝构造swap(tmp);return *this;}// 移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) -- 移动拷贝" << endl;swap(s);return *this;}~string(){delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}//string operator+=(char ch)string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0; // 不包含最后做标识的\0};bit::string to_string(int value){bool flag = true;if (value < 0){flag = false;value = 0 - value;}bit::string str;while (value > 0){int x = value % 10;value /= 10;str += ('0' + x);}if (flag == false){str += '-';}std::reverse(str.begin(), str.end());return move(str);}
}左值引用的使用场景:
做参数和做返回值都可以提高效率。
左值引用解决了什么问题
- 传参的拷贝全解决了
- 传返回值的问题解决了一部分(对象在,用引用返回)
void func1(bit::string s)
{}void func2(const bit::string& s)
{}
int main()
{bit::string s1("hello world");// func1和func2的调用我们可以看到左值引用做参数减少了拷贝,提高效率的使用场景和价值func1(s1);func2(s1);// string operator+=(char ch) 传值返回存在深拷贝// string& operator+=(char ch) 传左值引用没有拷贝提高了效率s1 += '!';return 0;
}局部对象(出了作用域就销毁的对象)返回的拷贝问题,没有解决,要用右值引用解决。
左值引用的短板:
但是当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回, 只能传值返回。例如:bit::string to_string(int value)函数中可以看到,这里只能使用传值返回, 传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。

右值引用和移动语义解决上述问题:
在bit::string中增加移动构造,移动构造本质是将参数右值的资源窃取过来,占位已有,那么就不 用做深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己。
// 移动构造
string(string&& s):_str(nullptr), _size(0), _capacity(0)
{cout << "string(string&& s) -- 移动语义" << endl;swap(s);
}int main()
{bit::string ret2 = bit::to_string(-1234);return 0;
}再运行上面bit::to_string的两个调用,我们会发现,这里没有调用深拷贝的拷贝构造,而是调用了移动构造,移动构造中没有新开空间,拷贝数据,所以效率提高了。

不仅仅有移动构造,还有移动赋值:
在bit::string类中增加移动赋值函数,再去调用bit::to_string(1234),不过这次是将 bit::to_string(1234)返回的右值对象赋值给ret1对象,这时调用的是移动构造。
// 移动赋值
string& operator=(string&& s)
{cout << "string& operator=(string&& s) -- 移动语义" << endl;swap(s);return *this;
}
int main()
{bit::string ret1;ret1 = bit::to_string(1234);return 0;
}
// 运行结果:
// string(string&& s) -- 移动语义
// string& operator=(string&& s) -- 移动语义这里运行后,我们看到调用了一次移动构造和一次移动赋值。因为如果是用一个已经存在的对象 接收,编译器就没办法优化了。bit::to_string函数中会先用str生成构造生成一个临时对象,但是我们可以看到,编译器很聪明的在这里把str识别成了右值,调用了移动构造。然后在把这个临时对象做为bit::to_string函数调用的返回值赋值给ret1,这里调用的移动赋值。
STL中的容器都是增加了移动构造和移动赋值:
http://www.cplusplus.com/reference/string/string/string/
http://www.cplusplus.com/reference/vector/vector/vector/
// 左值引用& + const:左值或右值传参过来都可以被取别名
void func(const int& i)
{cout << "void func(const int& i)" << endl;
}// 右值引用&&
void func(int&& i)
{cout << "void func(int&& i)" << endl;
}int main()
{int a = 0;func(a);// 调用左值引用func(10);// 调用右值引用return 0;
}右值引用的场景:
- 场景一:传值返回
- 场景二:容器的插入
知识点:
- 左值和右值都是一个表达式,平常见到的常量和变量都只是表达式的一种常见形态
- 左值可能会修改,也可能不会修改,比如:const int c = 10;c就不能修改
- 右值:传值返回的函数,如:后置++( T operator++(int) )
- 特殊:1、const左值引用可以给右值取别名;2、右值引用可以给move(左值)取别名
- 返回值生成的临时对象,如果临时对象比较小,是存在寄存器中(4个、8个字节)的,vector中有三个指针,在32位平台下,是12个字节,在64位平台下,是24个字节,寄存器是存不下的,那么此时临时对象存放在两个函数栈帧之间
- const 左值引用可以给右值取别名,那么为什么还要右值引用呢?引用的本质就是取别名,是为了减少拷贝。右值引用的出现是因为左值引用在某些场景下对于某些问题无法解决,无法减少拷贝,所以才会有右值引用。
- 移动构造也是一个构造,也会走初始化列表。
- 移动语义的本质:移动构造和移动赋值
左值引用的场景:
- 解决传值传参拷贝的问题;传右值还是传左值,都可以,(void func(const T& val))一个函数的参数我们建议用左值引用,建议加const,加了const之后,既可以传左值,也可以传右值,都没有拷贝
- 解决部分返回对象拷贝的问题。(出了函数作用域,返回对象还在,可以左值引用返回,减少了拷贝)
- 没有解决的问题:返回对象是一个局部对象,出了函数作用域生命周期就到了,只能传值返回,就存在拷贝,如果有些对象消耗巨大。
右值引用引用左值及其一些更深入的使用场景分析
按照语法,右值引用只能引用右值,但右值引用一定不能引用左值吗?因为:有些场景下,可能 真的需要用右值去引用左值实现移动语义。当需要用右值引用引用一个左值时,可以通过move 函数将左值转化为右值。C++11中,std::move()函数位于头文件中,该函数名字具有迷惑性, 它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
template<class _Ty>
inline typename remove_reference<_Ty>::type&& move(_Ty&& _Arg) _NOEXCEPT
{// forward _Arg as movablereturn ((typename remove_reference<_Ty>::type&&)_Arg);
}int main()
{bit::string s1("hello world");// 这里s1是左值,调用的是拷贝构造bit::string s2(s1);// 这里我们把s1 move处理以后, 会被当成右值,调用移动构造// 但是这里要注意,一般是不要这样用的,因为我们会发现s1的// 资源被转移给了s3,s1被置空了。bit::string s3(std::move(s1));return 0;
}http://www.cplusplus.com/reference/list/list/push_back/
http://www.cplusplus.com/reference/vector/vector/push_back/
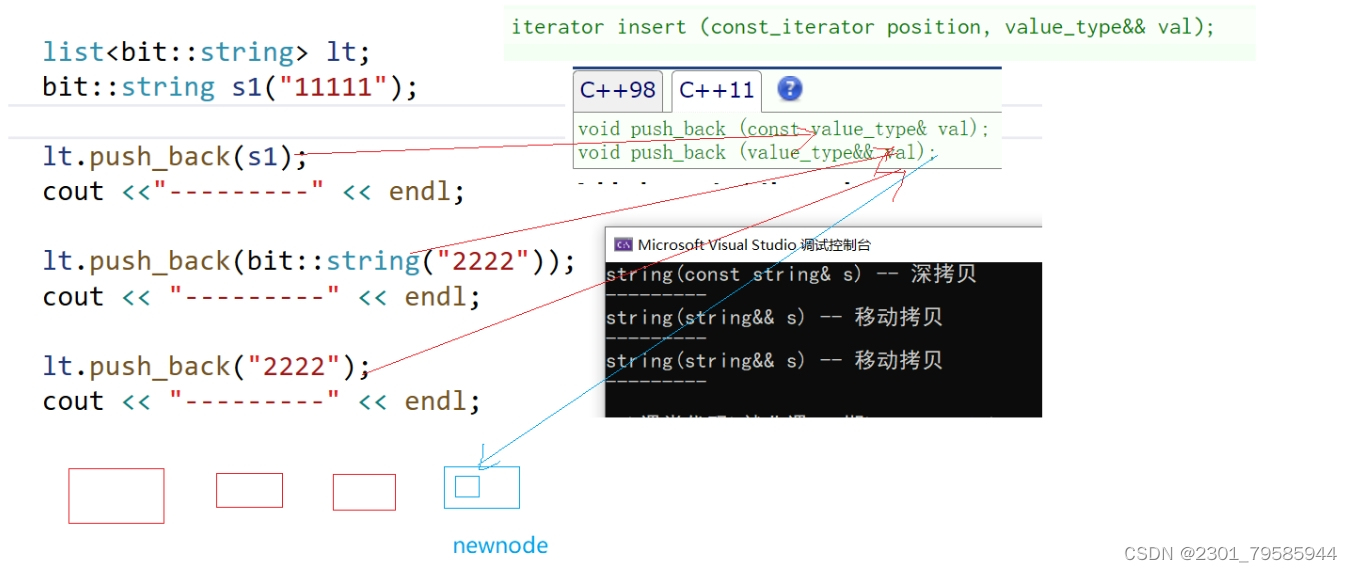
void push_back(value_type&& val);int main()
{list<bit::string> lt;bit::string s1("1111");// 这里调用的是拷贝构造lt.push_back(s1);// 下面调用都是移动构造lt.push_back("2222");lt.push_back(std::move(s1));return 0;
}
// 运行结果:
// string(const string& s) -- 深拷贝
// string(string&& s) -- 移动语义
// string(string&& s) -- 移动语义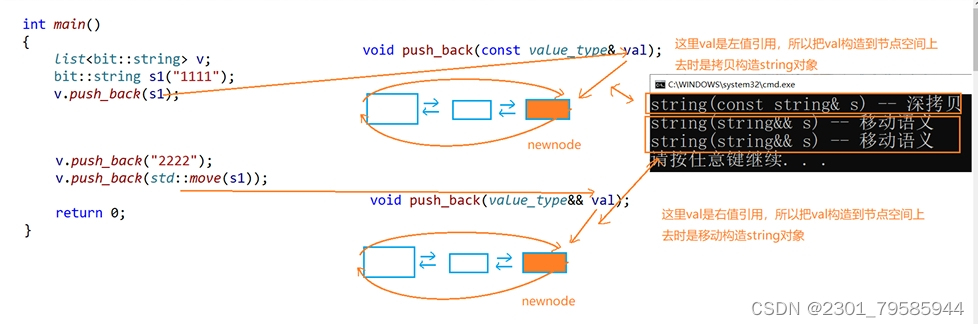
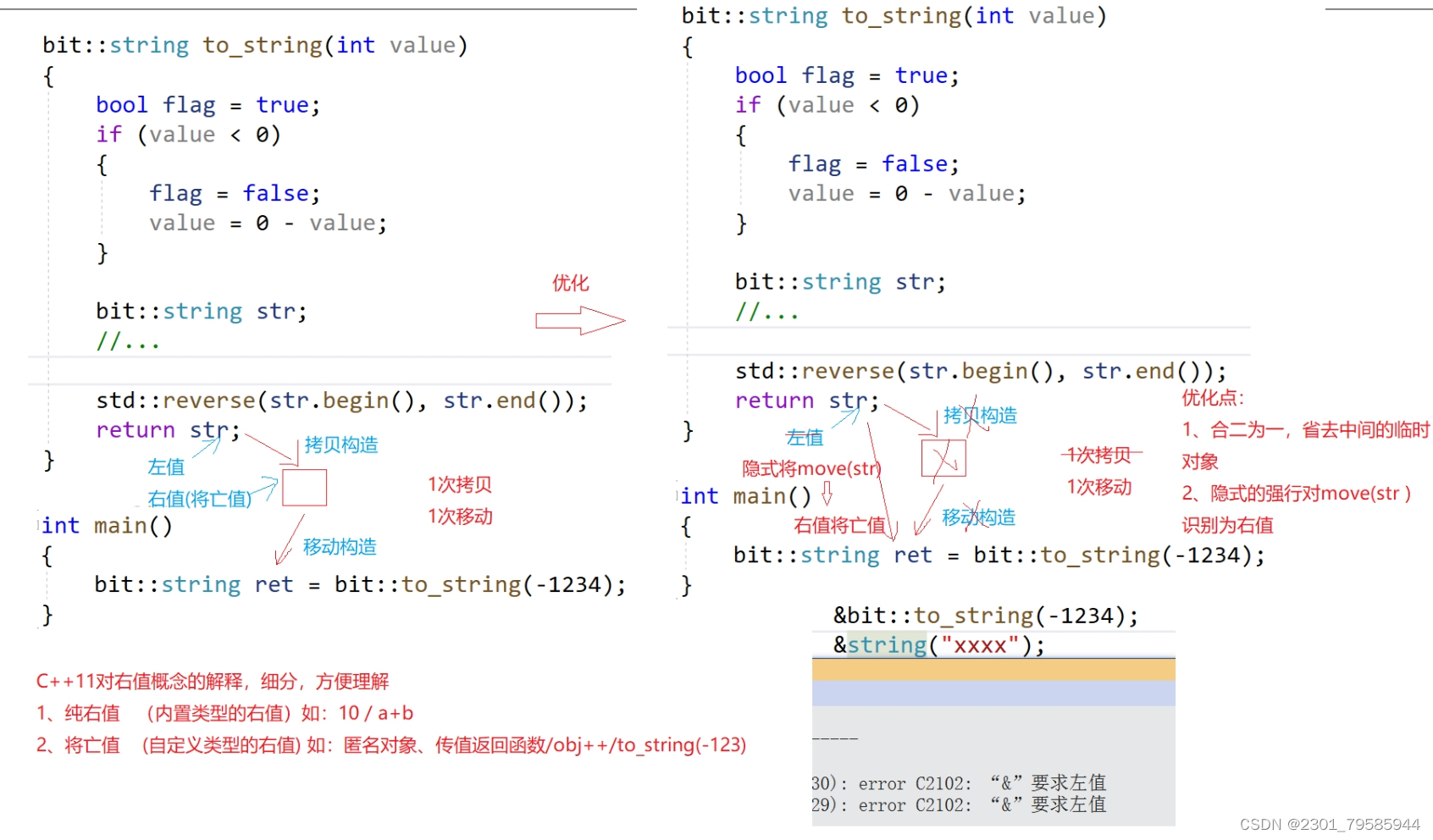
C++11对右值概念的细分:
- 纯右值(内置类型的右值)如:10、a + b....
- 将亡值(自定义类型的右值)如:匿名对象、传值返回函数......
强行将move(str),如果传值返回的地方都move一下,会将该属性从左值改成右值,但是为了解决存量的问题,也就是要兼容以前的代码,虽然str是左值,但是编译器知道它有将亡值属性,所以隐式将move(str),move之后,str的属性就变成了将亡值(右值),str本身还是左值。
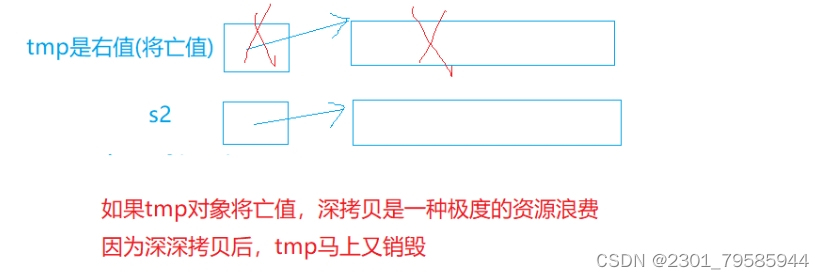
string s2(tmp):
- 如果tmp对象将亡值,深拷贝是一种极度的资源浪费,因为深拷贝后,tmp马上又销毁;
- C++提供右值引用,本质是为了参数匹配时,区分左值和右值。

总结一下:浅拷贝的类不需要移动构造;深拷贝的类才需要移动构造
移动构造是将一个将亡值对象中的资源移动到另一个对象中,将资源的使用寿命延长了。
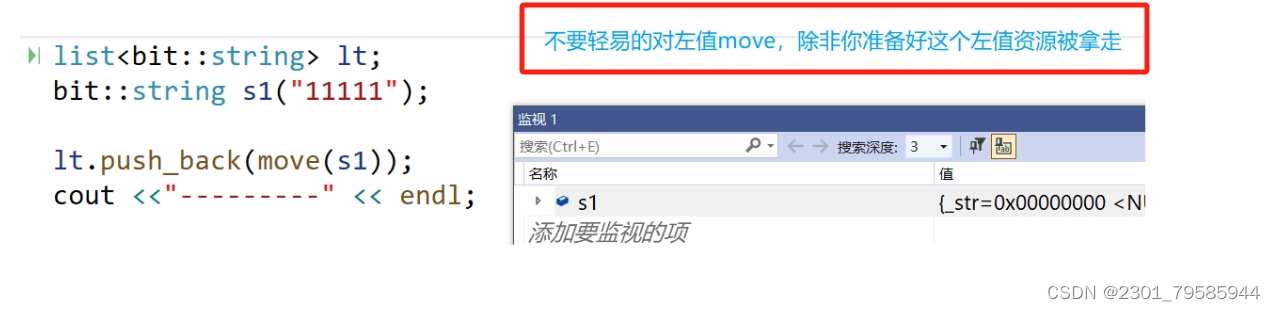
int main()
{bit::list<bit::string> lt;bit::string s1("11111");//lt.push_back(move(s1));// move(s1):s1本身还是左值,不过move(s1)之后,这个表达式的返回值的属性是右值lt.push_back(s1);cout << "---------" << endl;lt.push_back(bit::string("2222"));// 匿名对象的作用域就那一行,相当于临时对象(将亡值)cout << "---------" << endl;lt.push_back("2222");// 隐式类型转换,中间生成临时对象(就是右值)cout << "---------" << endl;//bit::string s2 = "33333"; // 构造 + 拷贝构造 -》合二为一直接构造//const bit::string& s3 = "33333";// 没有拷贝构造,临时对象是右值,const 左值引用右值//bit::string&& s4 = "33333";// 右值引用临时对象return 0;
}
右值被右值引用了之后,右值引用本身的属性是左值,右值引用的底层是指针
int main()
{// 右值被右值引用以后,右值引用r的属性是左值// 右值不可以被改变,但是右值引用可以被改变;// 右值引用的前面也能加const,使得r这个右值引用不能被改变// 为什么要这样设计?int&& r = 10;r++;cout << &r << endl;// 也可以取地址 return 0;
}
完美转发
模板中的&& 万能引用
std::forward 完美转发在传参的过程中保留对象原生类型属性
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }// 极度追求效率
// 引用折叠
// & && -> & 传值传参的属性是左值(&),遇到&&,就将&&折叠成&
// && && -> && 传值传参的属性是右值(&&),遇到&&,就将&&折叠成&&
//
// move 左值属性->右值属性
// forward 保持属性->本身是左值,就不变;
// 本身是右值,右值引用后,属性是左值,转成右值,相当于move一下
//
// 不能单纯把下面的模板理解成右值引用的模板
// 万能引用-> 传左值,他就是左值引用
// 万能引用-> 传右值,他就是右值引用
template<typename T>
void PerfectForward(T&& t)
{// 按照我们之前学的,见到右值引用,我们认为只能传右值,但是此地是一个例外// 他是一个类模板,带有推演的属性// 模板参数T&&当成一个整体。传左值,就推演成T&;传右值,就推演成T&&Fun(std::forward<T>(t));// 完美转发//cout << "void PerfectForward(T&& t)" << endl;
}int main()
{PerfectForward(10); // 右值int a;PerfectForward(a); // 左值PerfectForward(std::move(a)); // 右值const int b = 8;PerfectForward(b); // const 左值PerfectForward(std::move(b)); // const 右值return 0;
}完美转发实际中的使用场景:
iterator insert(iterator pos, T&& x)
{Node* cur = pos._node;Node* prev = cur->_prev;//Node* newnode = new Node(move(x));Node* newnode = new Node(std::forward<T>(x));//forward 保持属性->本身是左值,就不变;// 本身是右值,右值引用后,属性是左值,转成右值,相当于move一下prev->_next = newnode;newnode->_prev = prev;newnode->_next = cur;cur->_prev = newnode;//return iterator(newnode);return newnode;
}// 右值引用
void push_back(T&& x)
{insert(end(), std::forward<T>(x));// x是右值引用,x的属性是左值,所以,还是得move(x),将x转变为右值
}// emplace版本的参数包并不能随便传,至少要有匹配它对应的构造函数
template<class ...Args>
ListNode(Args&&... args): _next(nullptr), _prev(nullptr), _data(forward<Args>(args)...)
{}新的类功能
默认成员函数
原来C++类中,有6个默认成员函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值重载
- 取地址重载
- const 取地址重载
最后重要的是前4个,后两个用处不大。默认成员函数就是我们不写编译器会生成一个默认的。
C++11 新增了两个:移动构造函数和移动赋值运算符重载。
针对移动构造函数和移动赋值运算符重载有一些需要注意的点如下:
- 如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任 意一个。那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类 型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造, 如果实现了就调用移动构造,没有实现就调用拷贝构造。
- 如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中 的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内 置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋 值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造 完全类似)
- 如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}// 写了拷贝构造或移动构造,编译器默认生成的拷贝构造就不会生成了// 写了移动构造之后,如果不写拷贝构造,那么系统默认生成的就是浅拷贝了,为了避免浅拷贝,// 强制生成的移动构造会干扰默认生成的拷贝构造,就必须得写拷贝构造Person(const Person& p) = default;Person(Person&& p) = default;Person& operator=(Person&& p) = default;~Person(){}private:bit::string _name = "张三";int _age;
};int main()
{Person s1;// 拷贝构造Person s2 = s1;// 移动构造Person s3 = move(s1);// 如果没有移动构造,则调用拷贝构造Person s4;s4 = std::move(s2);return 0;
}
- 拷贝构造不写,会默认生成拷贝构造;构造函数写了,编译器就不会生成默认的构造函数;
- 那么拷贝构造也是构造,拷贝构造写了,构造函数就不能默认生成了。
类成员变量初始化
C++11允许在类定义时给成员变量初始缺省值,默认生成构造函数会使用这些缺省值初始化,这 个我们在类和对象默认就讲了,这里就不再细讲了。
强制生成默认函数的关键字default:
C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原 因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以 使用default关键字显示指定移动构造生成。
class Person
{
public:Person(const char* name = "", int age = 0):_name(name), _age(age){}// 拷贝构造Person(const Person& p):_name(p._name), _age(p._age){}// 强制生成默认的移动构造Person(Person&& p) = default;
private:bit::string _name;int _age;
};
int main()
{Person s1;Person s2 = s1;Person s3 = std::move(s1);return 0;
}禁止生成默认函数的关键字delete:
如果能想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且只声明补丁 已,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即 可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
方法一:自己不写,编译器会默认生成,我们可以干扰编译器的实现(C++98)
class A
{
public:A() = default;
private:// 方法一:C++98中干扰编译器的实现// 只声明不实现// 放到私有A(const A& aa);int a = 0;
};// 不希望A类对象被拷贝
A::A(const A& aa)
{//...
}int main()
{A aa1;A aa2 = aa1;return 0;
}方法二:C++11
class A
{
public:A() = default;A(const A& aa) = delete;private:int a = 0;
};int main()
{A aa1;A aa2 = aa1;return 0;
}总结
好了,本篇博客到这里就结束了,如果有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。
相关文章:
【C++11】第一部分(一万六千多字)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 C11简介 统一的列表初始化 {}初始化 std::initializer_list 声明 auto decltype 右值引用和移动语义 左值引用和右值引用 左值引…...
FPGA专项课程即将开课,颁发AMD官方证书
社区成立以来,一直致力于为广大工程师提供优质的技术培训和资源,得到了众多用户的喜爱与支持。为了满足用户需求,我们特别推出了“基于Vitis HLS的高层次综合及图像处理开发”课程。 本次课程旨在帮助企业工程师掌握前沿的FPGA技术ÿ…...

C++ shared_ptr
shared_ptr共享它指向的对象,多个shared_ptr可以指向(关联)相同的对象,在内部采用计数机制来实现。 当新的shared_ptr与对象关联时,引用计数增加1。 当shared_ptr超出作用域时,引用计数减1。当引用计数变为…...

2024.6.15
2024.6.15 【夜幽幽,月优优,曲悠悠,吾忧忧。】 Saturday 五月初十 <theme oi-“DP”> 看几道DP基础题, 巩固一下DP思路和基础 Coin Combinations I //2024.6.15 //by white_ice //Coin Combinations I CSES - 1635 #i…...
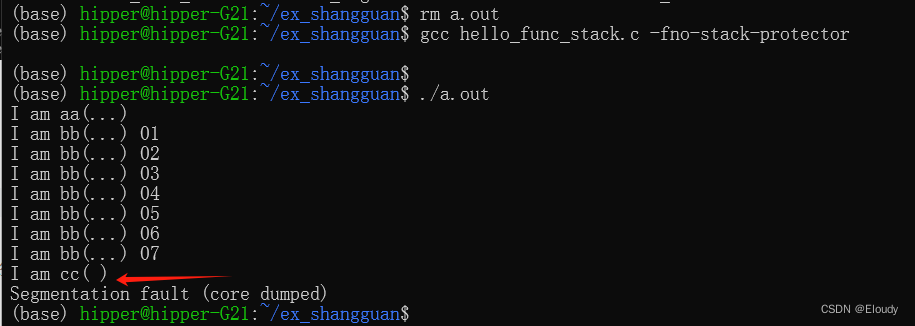
堆栈溢出的攻击 -fno-stack-protector stack smash 检测
在程序返回的一条语句堆栈项目处,用新函数的起始地址覆盖,将会跳转到执行新函数。 现在系统对这个行为做了判断,已经无法实施这类攻击或技巧。 1,测试代码 #include <stdio.h> void cc() {printf("I am cc( )\n"…...

掌握特劳特定位理论核心,明晰企业战略定位之重
在当今瞬息万变的市场环境中,企业战略定位的重要性日益凸显。它不仅是企业在激烈竞争中保持优势的关键,更是企业实现长期可持续发展的基石。 哈佛大学战略学教授迈克尔波特(Michael Porter)指出战略就是形成一套独具的运营活动&a…...

RAGFlow 学习笔记
RAGFlow 学习笔记 0. 引言1. RAGFlow 支持的文档格式2. 嵌入模型选择后不再允许改变3. 干预文件解析4. RAGFlow 与其他 RAG 产品有何不同? 5. RAGFlow 支持哪些语言? 6. 哪些嵌入模型可以本地部署? 7. 为什么RAGFlow解析文档的时间比…...

使用Docker-Java监听Docker容器的信息
使用Docker-Java监听Docker容器的信息 Docker作为一种轻量级的容器化平台,极大地方便了应用的部署与管理。然而,在实际使用过程中,我们常常需要对运行中的容器进行监控,以确保其健康状态,并能及时响应各种异常情况。本…...
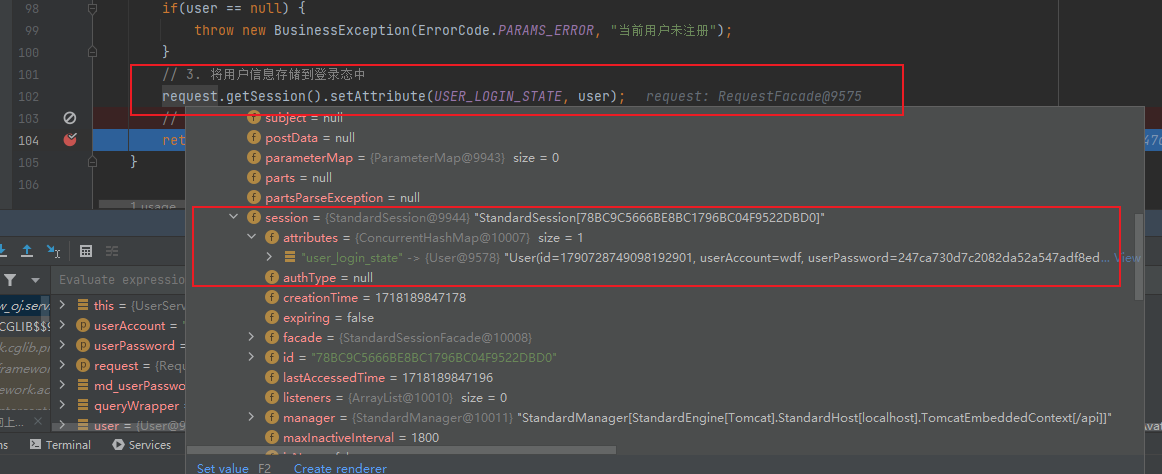
Spring Boot + Mybatis Plus实现登录注册
Spring Boot 实现登录注册 1. 注册 业务逻辑 客户端输入注册时需要的用户参数,比如:账户名、密码、确认密码、其他服务端接收到客户端的请求参数进行校验,然后判断是否有误,有误的地方就将错误信息抛出将密码进行加密之后存储到…...

IDEA创建web项目
IDEA创建web项目 第一步:创建一个空项目 第二步:在刚刚创建的项目下创建一个子模块 第三步:在子模块中引入web 创建结果如下: 这里我们需要把这个目录移到main目录下,并改名为webapp,结果如下 将pom文件…...
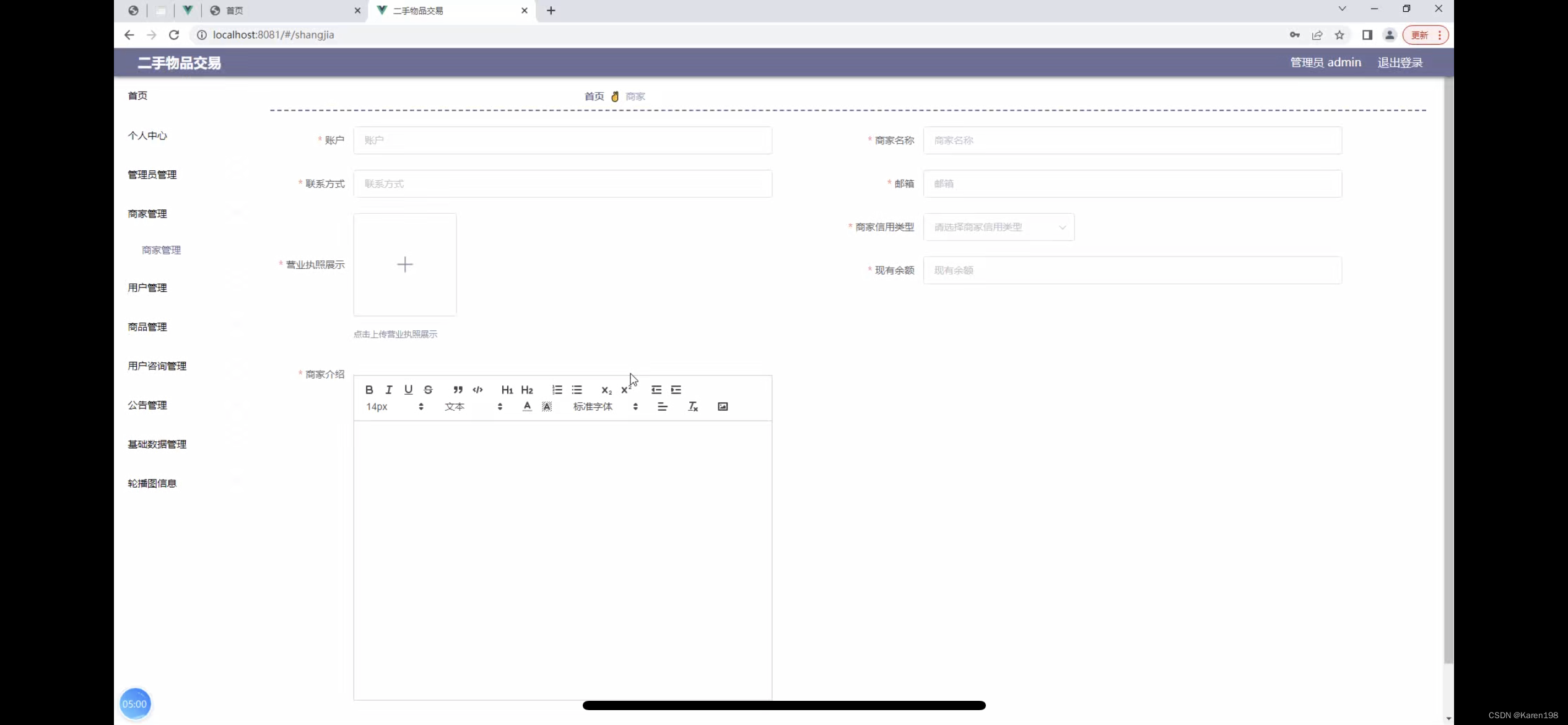
二手物品交易系统的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,商家管理,用户管理,商品管理,用户咨询管理 商家账户功能包括:系统首页,个人中心,商品管理,用…...

探索大数据在信用评估中的独特价值
随着我国的信用体系越来越完善,信用将影响越来越多的人。现在新兴的大数据信用和传统信用,形成了互补的优势,大数据信用变得越来越重要,那大数据信用风险检测的重要性主要体现在什么地方呢?本文将详细为大家介绍一下,…...

MFC基础学习应用
MFC基础学习应用 1.基于对话框的使用 左上角为菜单键(其下的关于MFC主要功能由IDD_ABOUTBOX决定) 附图 右下角为按钮(基本功能由IDD_DIALOG决定,添加按钮使用由左上角的工具箱完成) 附图 2.自行添加功能与按钮//功能代码 void CMFCApplication4Dlg:…...
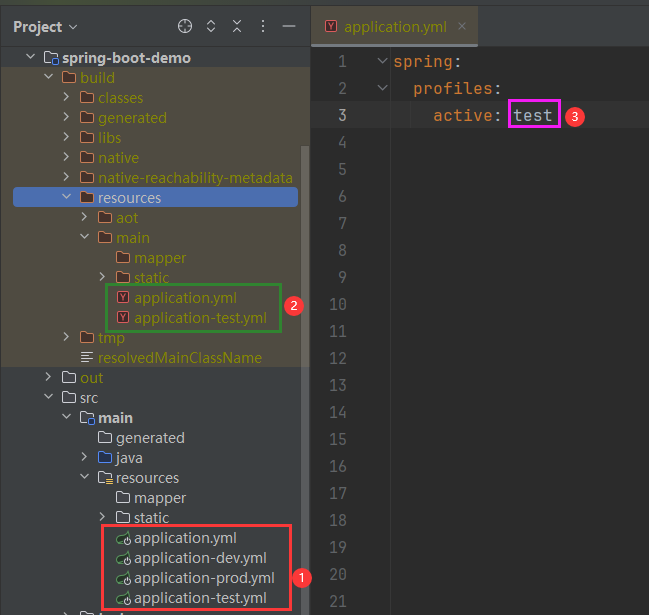
Gradle实现类似Maven的profiles功能
版本说明 GraalVM JDK 21.0.3Gradle 8.7Spring Boot 3.2.5 目录结构 指定环境打包 application.yml/yaml/properties 执行 bootJar 打包命令前要先执行 clean【其它和 processResources 相关的命令也要先执行 clean】,否则 active 值不会变! spring…...
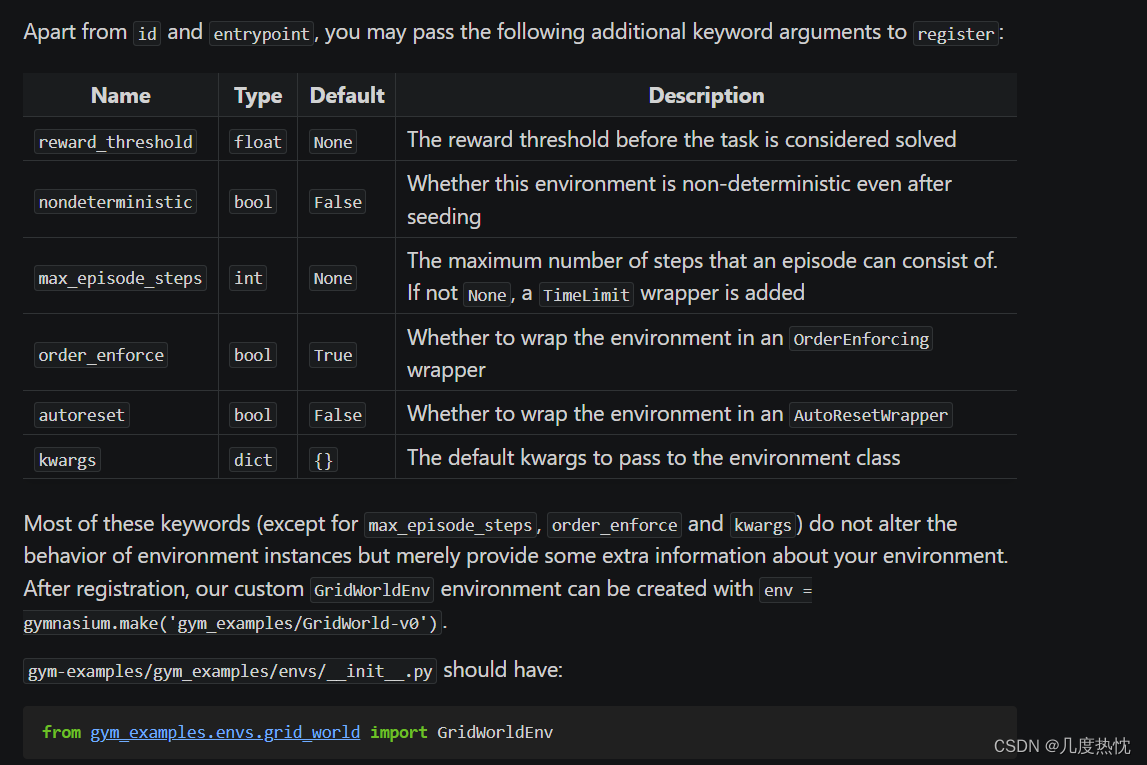
【强化学习】gymnasium自定义环境并封装学习笔记
【强化学习】gymnasium自定义环境并封装学习笔记 gym与gymnasium简介gymgymnasium gymnasium的基本使用方法使用gymnasium封装自定义环境官方示例及代码编写环境文件__init__()方法reset()方法step()方法render()方法close()方法 注册环境创建包 Package(最后一步&a…...
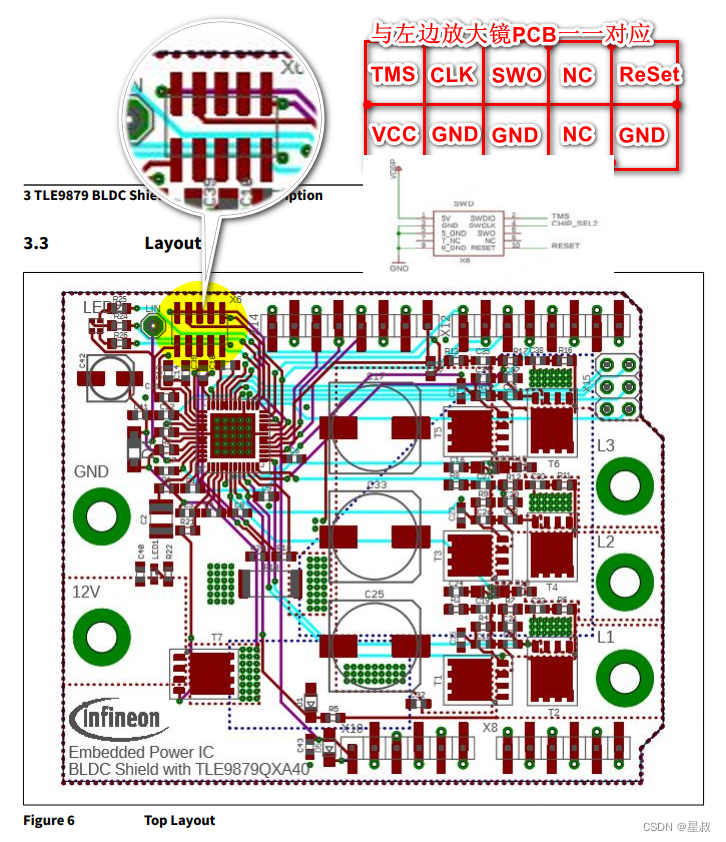
TLE9879的基于Arduino调试板SWD刷写接口
官方的Arduino评估板,如下图所示: 如果你有官方的调试器,应该不用关注本文章,如下图连接就是: 如果,您和博主一样需要自己飞线的话,如下图所示:PCB的名称在右边整理,SWD的…...

基于 Delphi 的前后端分离:之五,使用 HTMX 让页面元素组件化之面向对象的Delphi代码封装
前情提要 本博客上一篇文章,描述了使用 Delphi 作为后端的 Web Server,前端使用 HTMX 框架,把一个开源的前端图表 JS 库,进行了组件化。 上一篇文章仅仅是描述了简单的前端代码组件化的可能性,依然是基于前端库的 JS…...
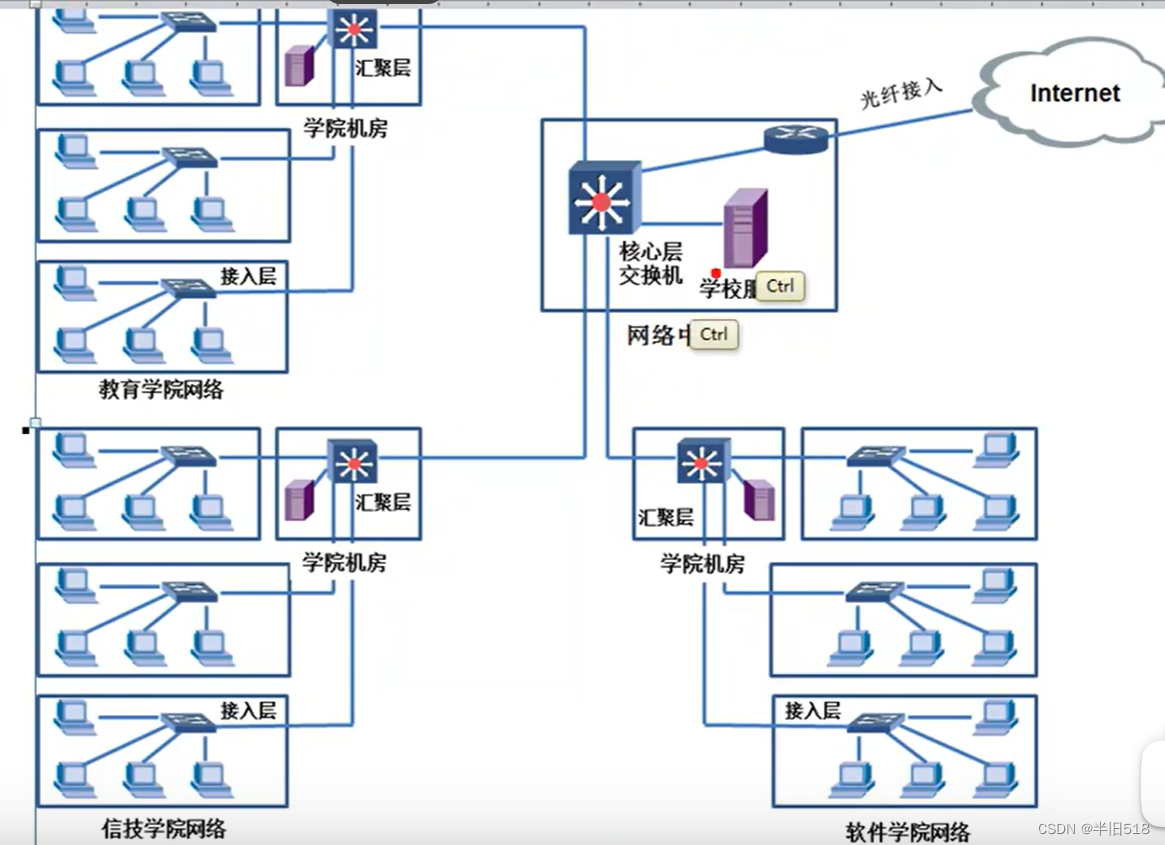
讲透计算机网络知识(实战篇)01——计算机网络和协议
一、计算机网络和协议 1、网络和互联网络 1.1 网络、互联网、Internet 用交换机、集线器连接在一起的计算机构成一个网络。 用路由器连接多个网络,形成互联网。 全球最大的互联网:Internet。 1.2 网络举例 家庭互联网 图中的无线拨号路由器既是路由…...

8个宝藏APP,个个都牛逼哈拉!
AI视频生成:小说文案智能分镜智能识别角色和场景批量Ai绘图自动配音添加音乐一键合成视频https://aitools.jurilu.com/ 目前win7已经逐渐淡出人们的视野,大部分人都开始使用win10,在日常工作和使用中,创客们下载神奇的软件能大幅提…...

使用docker构建java应用
1、docker简介 Docker是一个开源的容器化平台,可以帮助开发人员将应用程序及其依赖项打包成一个可移植的容器。容器化是一种轻量级的虚拟化技术,可以使应用程序在不同的操作系统和环境中具有一致的运行方式。 使用Docker带来的好处包括: 简…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...