大模型「训练」与「微调」概念详解【6000字长文】
本文你将学到什么
1、大模型预训练与微调的基本流程
2、预训练、训练、后期预训练、微调的区别
3、大模型训练与微调的一些概念,如:
Post-pretrain、SFT、RLHF、模型对齐、Lora、Q-Lora、大模型量化、微调指标、微调参数、大模型评测指标
预训练与微调概览
在大模型的预训练与微调过程中,我们通常面临如何告诉模型想要什么答案和不想要什么答案的问题(后者往往被大家忽略)。本节将详细阐述大模型预训练与微调的流程,包括预训练、微调的两个阶段(监督式微调SFT和对齐阶段)以及在实际操作中可能遇到的问题和解决方法。
总结来说,预训练是为了让模型学习通用知识,Post-pretraining 是为了让模型更好地适应特定领域,微调是为了优化模型在特定任务上的表现。SFT 是微调的一种,侧重于有监督的学习,而 RLHF 是一种结合了人类反馈的微调方法,旨在提高模型在复杂任务上的性能。
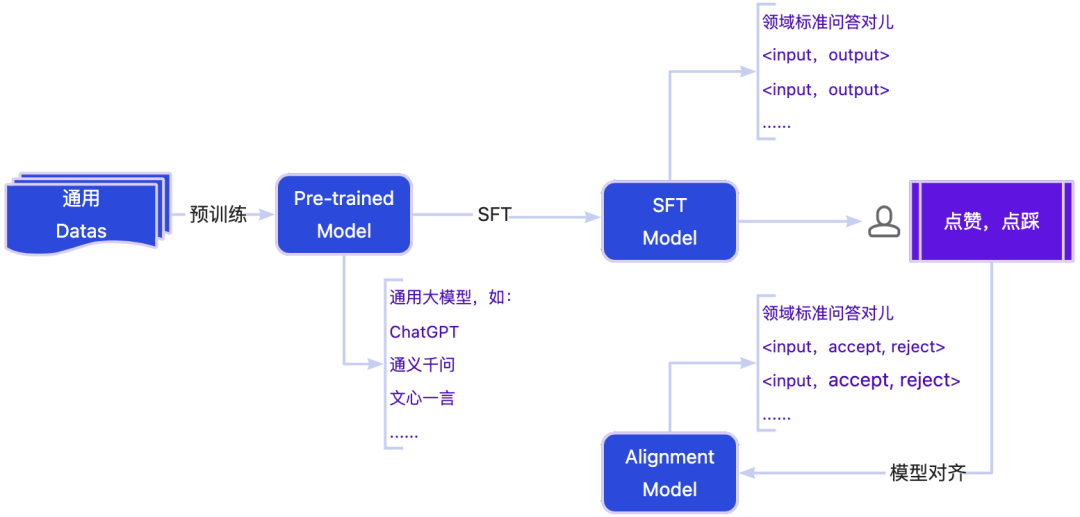
预训练(
目录
本文你将学到什么
预训练与微调概览
预训练(Pre-training)
训练
后期预训练
微调 (Fine-tuning)
SFT 监督微调
RLHF 人类反馈强化学习
模型对齐
问题解决策略及部署
RLHF与模型对齐区别
微调关键指标
Lora & Q-Lora
Lora(Low-Rank Adaptation)
Q-Lora(Quantized Lora)
大模型量化
大模型评测指标
往期推荐
Pre-training)
预训练是训练过程的一个特殊阶段,通常发生在模型进行特定任务训练之前。预训练的目的是让模型在一个广泛的数据集上学习到一些通用的特征或知识,即通用的大模型(我们称之为“预训练模型”(Pre-trained Model)),这个阶段的目标是构建一个具备广泛能力的模型,但可能无法满足特定场景的需求。这些特征或知识可以帮助模型在后续的特定任务上表现得更好。预训练的步骤包括:
- 选择一个大型的、通用的数据集:这个数据集不需要和模型最终的任务完全相关,但它应该足够大和多样化,能够让模型学习到广泛的特征和模式。
- 训练模型:在这个大型数据集上训练模型,使其学习到通用的知识或特征。
- 保存预训练模型:完成预训练后,保存模型的参数。这些参数可以作为后续特定任务训练的起点。
- 预训练模型通常使用自监督学习,这意味着模型试图从输入数据本身预测某些未知的或被遮蔽的部分,例如,预测句子中缺失的单词。
- 预训练的结果是一个通用的模型,它对语言有一个基本的理解,但还没有针对任何特定任务进行优化。
- 预训练的好处是显著减少了模型在特定任务上训练所需的数据量和时间,同时提高了模型在这些任务上的性能。这种方法在自然语言处理(NLP)、计算机视觉等领域尤其流行和有效。
训练
训练是指使用数据集对机器学习模型或深度学习网络进行学习的过程。在这个过程中,模型通过不断调整其内部参数(例如,神经网络中的权重和偏置)来最小化预测结果和实际结果之间的差异。这个过程通常涉及到以下几个步骤:
- 前向传播:模型根据当前参数对输入数据进行预测。
- 损失计算:计算模型预测结果和实际结果之间的差异(损失)。
- 反向传播:根据损失函数计算对模型参数的梯度(即损失对每个参数的导数)。
- 参数更新:使用梯度下降或其他优化算法调整模型参数,以减少损失。
训练的目标是使模型能够准确地从输入数据中学习到输出结果,从而在未见过的数据上也能做出准确的预测或决策。
后期预训练
Post-pretraining(后期预训练)是一种在模型的初始预训练和最终微调之间进行的训练方法。这种方法通常用于进一步适应模型以处理特定类型的数据或任务。以下是详细介绍,参考了之前对SFT和RLHF的描述方式:
1、后期预训练(Post-pretraining)
- Post-pretraining是在通用预训练模型的基础上,对模型进行额外训练的过程,通常是为了使模型更好地适应特定的领域或任务。
- 这个过程使用的数据集通常比预训练阶段的数据集更专注于某个领域或任务,但比微调阶段使用的数据集更大、更广泛。
- 训练方法可以是监督学习,也可以是自监督学习,具体取决于可用数据的类型和训练目标。
- Post-pretraining的目标是在不过度专化到某个特定任务的同时,提高模型对特定领域的理解和表现。
2、训练过程
- 在Post-pretraining阶段,模型通常会在一个包含大量领域特定数据的数据集上进行训练。
- 这个阶段的训练可以包括多种任务,如语言建模、文本分类、实体识别等,这些任务都是为了提升模型在特定领域的表现。
- 训练过程中,模型的参数会根据领域特定数据集进行调整,以便更好地捕捉和理解领域内的语言模式和知识。
3、优势与目标
- Post-pretraining允许模型在保持通用性的同时,增强对特定领域的理解,这有助于模型在后续的微调阶段更快速地适应特定任务。
- 与 SFT 相比,Post-pretraining在微调之前提供了一个中间步骤,有助于模型更平滑地过渡到特定任务上。
- 与 RLHF 相比,Post-pretraining不依赖于复杂的奖励机制或人类反馈,而是通过大量的领域特定数据来提升模型性能。
- 总结来说,Post-pretraining是一个介于预训练和微调之间的训练阶段,它使用大量的领域特定数据来进一步调整模型,使其更好地理解特定领域的语言和任务。这个阶段不需要复杂的奖励机制,而是通过传统的监督或自监督学习方法来实现模型性能的提升。
微调 (Fine-tuning)
- 在这个阶段,预训练模型(可能经过了Post-pretraining)被进一步训练,以优化它在一个特定任务上的表现。
- 微调通常在一个相对较小的、特定任务的数据集上进行,这个数据集包含了明确的标签,模型通过监督学习来进行优化。
- 微调的目的是调整模型的参数,使其能够在特定任务上做出准确的预测。
SFT 监督微调
SFT (Supervised Fine-Tuning) 是微调的一种形式,强调在有监督的环境下进行。
在SFT阶段,我们使用特定领域的数据或私有化数据对预训练模型进行改良。这一阶段需要指令微调数据,数据集通常由输入(用户问题)和输出(标准答案)两个字段构成。标准答案通常由专家标注获得。
1、SFT是一种简单的微调方法,它使用带有正确答案的数据集来继续训练一个预训练的模型。
2、这种方法依赖于大量的标注数据,即每个输入都有一个预先定义的正确输出。
3、微调的目的是使模型更好地适应特定的任务或领域【垂直领域】,比如特定类型的语言理解或生成任务。
4、SFT通常不涉及复杂的策略或奖励函数,只是简单地最小化预测输出和真实输出之间的差异。
RLHF 人类反馈强化学习
RLHF是一种利用人类反馈来训练强化学习模型的方法。在RLHF中,模型通过与人类交互获得反馈,这些反馈作为奖励信号来指导模型的行为。RLHF通常用于训练能够生成更自然、更符合人类偏好的文本或其他输出的模型。这种方法特别适用于需要模型理解和适应人类偏好的场景。
1、RLHF (Reinforcement Learning from Human Feedback) 是一种更复杂的训练方法,它结合了监督学习和强化学习。
2、在RLHF中,模型首先通过监督学习进行预训练,然后通过人类提供的反馈来进行强化学习。
3、人类反馈可以是对模型输出的评分,或者是在模型输出之间做出选择的偏好。
4、强化学习部分涉及到定义一个奖励函数,该函数根据人类反馈来调整模型的行为,以优化长期的奖励。
5、RLHF的目标是训练出一个在没有明确标签的复杂任务中表现良好的模型,这些任务可能需要更细致的判断和调整。
模型对齐
对齐阶段目的是进一步优化模型,使其更符合实际应用需求。在这个阶段,我们收集用户反馈数据(如点赞或点踩),并基于这些数据进行模型的进一步训练。
对齐阶段的数据格式与SFT阶段不同:
通常包含对同一问题的接受(accept)和拒绝(reject)两种答案。
问题解决策略及部署
在SFT阶段,模型被训练以识别“想要的答案”,但未明确告知“不想要的答案”。为解决这一问题,我们通过收集用户反馈和日志数据,在对齐阶段告诉模型哪些答案是不可接受的。
经过SFT和对齐阶段的训练,我们可以得到一个优化后的模型,这个模型可以部署上线。在对齐过程中,我们可以使用一些常见的方法,如PPO(Proximal Policy Optimization)和DPO(Distributional Proximal Optimization)。DPO由于训练过程相对简单,已成为对齐阶段的主流算法。
总的来说,SFT更侧重于直接从标注数据中学习,而RLHF则试图通过人类的反馈来引导模型学习更复杂和更细粒度的行为。RLHF通常被认为是一种更接近人类学习方式的方法,因为它不仅仅依赖于标签数据,还依赖于人类对模型输出的评价和偏好。
RLHF与模型对齐区别
总的来说,模型对齐阶段可以视为一个更广泛的概念,而RLHF是一种特定的实现方式,特别是在强化学习领域。两者在实践中可能会有交集,但它们侧重点和应用方式有所不同。
1、联系:两者都涉及到根据反馈来调整模型的行为,以提高模型的性能和适应性。
2、区别:
- 技术实现:对齐阶段可能不仅限于强化学习,还可以包括监督学习或其他类型的学习;而RLHF明确使用了强化学习框架。
- 反馈来源:对齐阶段的反馈可以来自用户的实际使用情况,而RLHF的反馈通常来自与模型交互的人类评估者。
- 目标:对齐阶段的目标是使模型的输出与用户期望对齐,而RLHF的目标是通过人类反馈来优化模型的决策过程。
微调关键指标
在大模型微调过程中,评估模型是否需要继续训练通常涉及以下几个步骤:
1、验证集评估
- 使用一个独立的验证集(不参与训练过程的数据集)来评估模型的性能。
- 验证集应具有代表性,能够反映模型在实际应用中的表现。
2、性能指标
根据任务类型选择合适的性能指标。例如,对于分类任务,可能使用准确率、精确率、召回率或F1分数;对于回归任务,则可能使用均方误差(MSE)、均方根误差(RMSE)或平均绝对误差(MAE)。
3、损失函数
- 观察模型在验证集上的损失函数值。随着训练的进行,损失应该逐渐减小,如果损失不再显著下降,可能意味着模型已经收敛。
- 若损失值震荡,可尝试降低学习率,以便让模型更稳定地收敛。
- 若损失值下降较慢,但并没有出现明显的震荡,可尝试增大学习率,以便让模型更快地收敛。
4、学习率调整
如果模型在验证集上的性能停止提升,可以考虑调整学习率。使用学习率衰减策略,如学习率预热、周期性调整或使用自适应学习率优化器。
5、过拟合与欠拟合
- 检查模型是否存在过拟合(训练误差小,验证误差大)或欠拟合(训练和验证误差都大)的情况。
- 如果出现过拟合,可以尝试使用正则化技术、数据增强或简化模型。
- 如果出现欠拟合,可能需要增加模型复杂度、提供更多数据或调整模型参数。
6、早停法(Early Stopping)
- 一种常用的技术,用于在验证集上的性能不再提升时停止训练,以避免过拟合。
- 设置一个阈值,如果在一定数量的epoch后性能没有改善,则停止训练。
7、可视化工具
使用TensorBoard等可视化工具来监控训练和验证过程中的各种指标,这有助于直观地理解模型的行为。
8、交叉验证
如果数据集较小,可以考虑使用交叉验证来更全面地评估模型性能。
9、实验记录
记录不同epoch下的性能指标,以便进行比较和分析。
10、模型更新
如果在3-5个epoch后,模型在验证集上的表现没有达到预期,可以考虑更新模型架构、调整超参数或改进数据预处理。
通过这些评估方法,你可以决定模型是否需要继续训练,或者是否需要采取其他措施来改善模型性能。
Lora & Q-Lora
常见微调方法有:
- 全参数微调:在训练过程中更新所有参数
- LoRA:只更新adapter层的参数而无需更新原有语言模型的参数。
- Q-LoRA:只更新adapter层的参数而无需更新原有语言模型的参数。
在深度学习领域,微调(Fine-tuning)是一种常见的技术,它涉及将一个在大型数据集上预训练好的模型应用到一个特定任务上,通过在该任务上继续训练模型来调整模型的权重。这样做可以利用预训练模型的知识,加快学习速度,并提高特定任务的性能。
LoRA(Low-Rank Adaptation)和 Q-LoRA 是微调大型模型时使用的技术,它们旨在减少微调过程中所需的计算资源和时间。
Lora(Low-Rank Adaptation)
LoRA 是一种微调技术,它通过在模型的权重矩阵中引入低秩结构来进行微调。具体来说,它将原始的权重矩阵分解为两个较小的矩阵的乘积,这两个较小的矩阵在微调过程中被更新,而原始的权重矩阵保持不变。这样,只需要对模型的一小部分参数进行更新,从而减少了计算量和存储需求。
低秩适应是一种有效的模型压缩和加速技术,特别适用于大型模型,因为它可以显著减少模型的参数数量,同时保持性能。
Q-Lora(Quantized Lora)
Q-LoRA 是 LoRA 的一种变体,它结合了量化和低秩适应的概念。在 Q-LoRA 中,除了使用低秩矩阵来减少参数数量外,还会对这些矩阵进行量化,即将它们从浮点数转换为整数形式,如Int8或Int16。
量化可以进一步减少模型的大小,加快模型的推理速度,并且可以在某些硬件上实现更高效的计算。Q-LoRA通过结合量化和低秩适应,旨在实现更高效的模型微调,特别是在资源受限的环境中。
这些技术对于在保持模型性能的同时减少模型的计算和存储需求非常有用,特别是在部署大型模型到边缘设备或移动设备时。通过 LoRA 或 Q-LoRA,可以以较低的成本对大型模型进行微调,使其适应特定的应用场景。
LoRA 与 Q-LoRA 只更新 adapter层 的参数,不会更新原有语言模型的参数。所以微调结束后还需要做模型合并后才能使用微调后的模型。
关于层-Layer的概念请阅读下文👇
大模型量化
大模型量化版(Quantized Version of Large Models)通常指的是对大型机器学习模型进行量化处理后的版本。量化是一种模型优化技术,用于减少模型的计算和存储需求,从而提高模型在硬件上的运行效率,尤其是在资源受限的环境中。
以下是量化处理的一些关键点:
- 减少精度:量化涉及将模型中的浮点数权重和激活值转换为低精度的表示,例如从32位浮点数(FP32)转换为低精度格式(如 Int4、Int8、BF16 等)。
- 减少大小:通过降低数值的精度,模型的文件大小可以显著减少,这有助于更快地下载和部署模型。
- 提高速度:量化后的模型可以在特定的硬件上更快地运行,因为整数运算通常比浮点运算更快,也更节能。
- 硬件兼容性:某些硬件加速器对整数运算进行了优化,量化后的模型可以更好地利用这些硬件特性。
- 保持性能:尽管量化会降低数值精度,但目标是在不显著影响模型性能的情况下进行优化。
- 适用场景:量化特别适用于需要在边缘设备上运行的模型,如智能手机、嵌入式系统和物联网设备,因为这些设备通常计算资源有限。
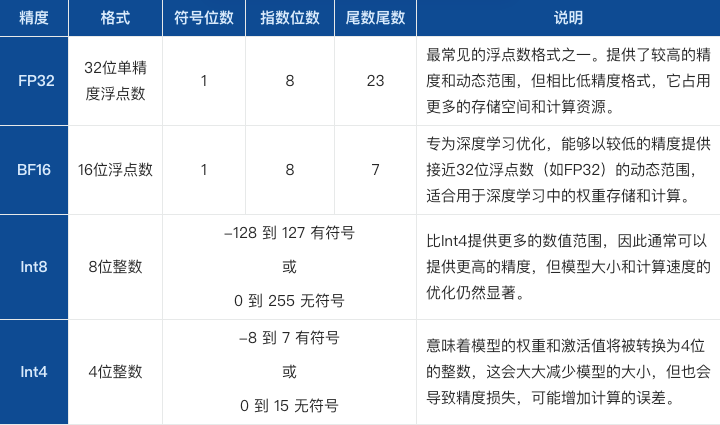
量化是模型部署前的一个重要步骤,它有助于平衡模型的性能和效率,在一些应用中,可以接受一定程度的精度损失以换取显著的效率提升,使得大型模型能够在各种设备上有效运行。然而,量化过程需要谨慎执行,以确保模型的准确度和性能不会受到太大影响。量化的过程需要在模型的精度和效率之间做出权衡。
大模型评测指标
1、语言、知识、创作、数学、推理
2、长文本理解
3、Function Call支持效果
4、MMLU、GPQA、HumanEval、CEval (val)、GSM8K
- MMLU (Massive Multitask Language Understanding): MMLU是一个大规模的多任务语言理解基准测试,它包含57个任务,旨在评估语言模型在多种语言理解和生成任务上的能力。
- GPQA (Graded Prompting Quality Assessment): GPQA是一个评估语言模型在不同难度级别上生成质量的测试。它通过分级的提示(graded prompts)来测试模型生成的文本质量。
- HumanEval: HumanEval是一个用于评估语言模型生成文本质量的测试,它通常包含一些人类编写的提示,用于测试模型生成的文本是否接近人类水平。
- CEval (val): 这个指标可能是指一个特定的评估集(validation set)或评估过程,用于在训练过程中评估模型的性能。"CEval"可能是指某个特定数据集或评估框架的名称,而"val"通常代表验证集(validation set),用于模型的调优和性能评估。
- GSM8K: 这个指标可能是指一个包含8000个句子的数据集,用于测试语言模型在特定任务上的表现。GSM8K可能是某个特定数据集的缩写或名称,但具体含义可能需要更多的上下文信息来确定。
读到这里的你,已经很累了吧,本文先到这,接下来会更新微调实操,带大家一步一步从买 GPU 云服务开始进行微调实操。
另外,感兴趣的小伙伴也欢迎加入我的 「AI全栈·人工智能研究院」,是AI2.0 最早一批的社群,从 2023 年 4 月份开始运营至今,保证让你学到AI全栈干货!👇
往期推荐
大模型训练及推理【硬件选型指南】及 GPU 通识
【RAG+通用大模型】 or 【RAG+微调大模型】?企业知识库落地方案如何抉择?
LangChain 劲敌强势崛起,Sping AI 震撼发布,AIGC开发终极武器登场!Java 程序员看过来!
用 LM Studio 1 分钟搭建可在本地运行大型语言模型平台,替代 ChatGPT
相关文章:
大模型「训练」与「微调」概念详解【6000字长文】
本文你将学到什么 1、大模型预训练与微调的基本流程 2、预训练、训练、后期预训练、微调的区别 3、大模型训练与微调的一些概念,如: Post-pretrain、SFT、RLHF、模型对齐、Lora、Q-Lora、大模型量化、微调指标、微调参数、大模型评测指标 预训练与微…...

JVM 垃圾回收器
一、垃圾回收器类型 如果说垃圾收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体 实现。下图展示了7种作用于不同分代的收集器,其中用于回收新生代的收集器 包括Serial、PraNew、Parallel Scavenge,回收老年代的收集器包括Seri…...

Spring IOC 容器的构建流程?
Spring loc (Inversion of Control) 是一种设计模式,其中对象的创建和依赖关系由框架管理,而不是由应用程序直接管理。Spring loc容器是Spring框架的核心,它使用loC模式来管理应用程序中的对象 Spring loC容器的构建过程如下: 1.配置元数据…...
官方文档 搬运 MAXMIND IP定位 mysql导入 简单使用
官方文档地址: 官方文档 文件下载 1. 导入mysql可能报错 Error Code: 1290. The MySQL server is running with the --secure-file-priv option so it cannot execute this statement 查看配置 SHOW GLOBAL VARIABLES LIKE %secure%;secure_file_priv 原来…...

PHP入门教程1:PHP的基础概念和基本语法
本文将从基础开始,介绍PHP的基础概念和基本语法。 PHP简介环境搭建基本语法变量和常量数据类型操作符常见错误和调试方法 1. PHP简介 PHP,全称是 “PHP: Hypertext Preprocessor”,是一种开源的通用脚本语言,尤其适用于Web开发…...

头歌资源库(5)求阶乘问题
一、 问题描述 请输入一个50至100之间的整数n,求解n! 二、算法思想 输入一个50至100之间的整数n。声明一个变量result,并将其初始化为1,用于保存n的阶乘。使用一个循环,从1到n,循环变量为i。在循环中,将…...

09:整型与布尔型的转换
OpenJudge - 09:整型与布尔型的转换 描述 将一个整型变量的值赋给一个布尔型变量,再将这个布尔型变量的值赋给一个整型变量,得到的值是多少? 输入 一个整型范围内的整数,即初始时整型变量的值。 输出 一个整数,经过上述…...

51单片机STC89C52RC——2.1 独立按键控制LED亮灭
目录 目的 一,STC单片机模块 二,独立按键 2.1 独立按键位置 2.2 独立按键电路图 三,创建Keil项目 四,代码 五,代码编译、下载到51单片机 六,效果 目的 当独立K1按键按下时LED D1 点亮&#x…...

系统架构师考点--计算机硬件
大家好。今天我总结一下计算机硬件的一些考点。 一、中央处理单元(CPU) 我们知道,计算机的基本硬件系统由运算器、控制器、存储器、输入设备和输出设备5大部件组成。其中运算器、控制器等部件被集成在一起统称为中央处理单元(Central Proce…...
vite-plugin-mock前端自行模拟接口返回数据的插件
vite-plugin-mock前端自行模拟接口返回数据的插件 安装导入、配置(vite.config.js)使用目录结构/mock/user.js具体在页面请求中的使用 注意事项 中文文档:[https://gitcode.com/vbenjs/vite-plugin-mock/blob/main/README.zh_CN.md) 参考其他…...

网络安全知识全景地图V1.0 - 20240616更新
网络安全领域的知识全景涵盖了从基础概念到高级技术的广泛内容。博主基于自身十年多的工作经验结合CISSP认证官方教材按照不同的主题和层次梳理出如下高层次的概览地图,可以帮助个人和组织理解网络安全领域的主题。 1.1. 基础理论 1.1.1. 网络安全概述 网络安全的…...
力扣19. 删除链表的倒数第N个节点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n 1 输出:[] 示例…...
电脑找不到vcruntime140_1.dll的原因分析及5种解决方法分享
电脑已经成为我们生活和工作中不可或缺的工具。然而,在使用电脑的过程中,我们常常会遇到一些常见的问题,其中之一就是电脑显示vcruntime140_1.dll丢失。那么,这个问题是怎么回事呢?又有哪些解决方法呢?如何…...

洗地机哪个牌子质量好,性价比高?一文盘点市场热门选择
近年来,洗地机因为其能快速的解决我们耗时、费力又繁琐的地板清洁工作,备受人们的喜爱。但面对多款设备不同功能和特点相近的洗地机,你可能会疑惑:“洗地机哪个牌子质量好?”,如果你正在寻找一款高效、便捷…...
—— JSON 函数)
MySQL 之 JSON 支持(三)—— JSON 函数
目录 一、JSON 函数参考 二、创建 JSON 值的函数 1. JSON_ARRAY([val[, val] ...]) 2. JSON_OBJECT([key, val[, key, val] ...]) 3. JSON_QUOTE(string) 三、搜索 JSON 值的函数 1. JSON_CONTAINS(target, candidate[, path]) 2. JSON_CONTAINS_PATH(json_doc, one_or…...
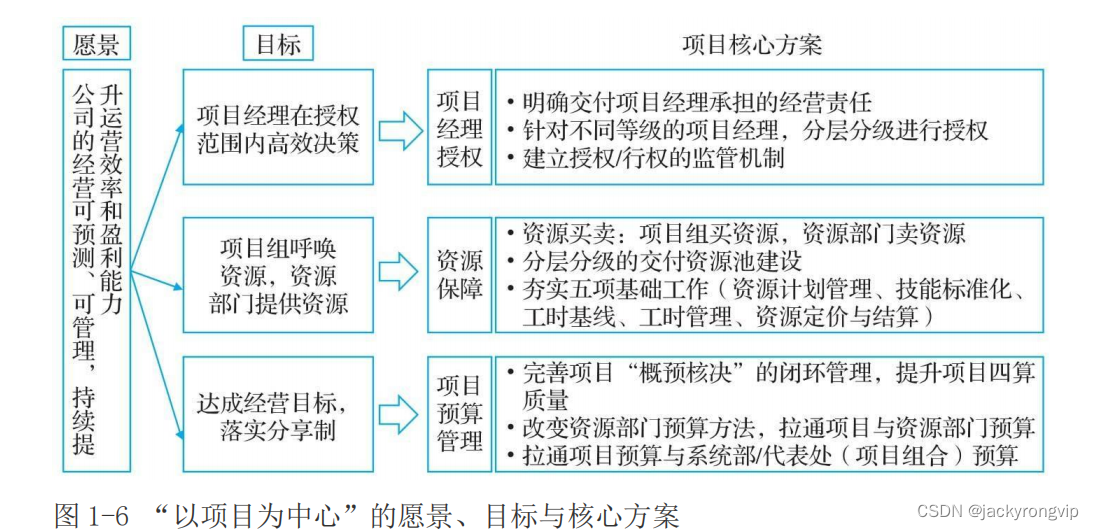
《华为项目管理之道》第1章笔记
《华为项目管理之道》,是新出的华为官方的项目管理书,整个书不错。第1章的精华: 1.2.2 以项目为中心的机制 伴随着项目型组织的建立,华为逐步形成了完备的项目管理流程和制度,从而将业务运 作构建在项目经营管理之…...

C# —— 算数运算符
算术运算符: 用于数值类型进行变量计算的运算符 他的返回结果是数值 赋值运算符 : 先看右侧 再看 左侧 将右侧的数据赋值给左侧的变量 int num 5; string name "老王"; float myHeight 187.5f; 加 先计算 再赋值 // 进行数据的加法…...
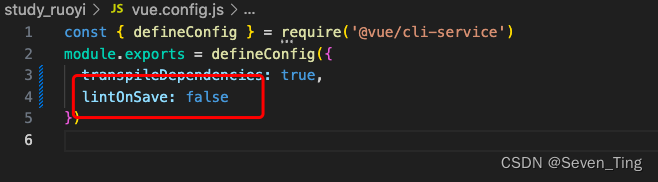
去掉eslint
1、在vue.config.js文件里加上下面的代码,然后重启就可以了! 2、vue.config.js文件代码: const { defineConfig } require(vue/cli-service) module.exports defineConfig({transpileDependencies: true,lintOnSave: false })...

【代码随想录算法训练Day38】LeetCode 509.斐波纳契数、LeetCode 76.爬楼梯、LeetCode 746. 使用最小花费爬楼梯
Day38 动态规划 又开始了新的章节,有了点难度的感觉。。 动态规划五部曲: 确定dp数组(dp table)以及下标的含义 确定递推公式 dp数组如何初始化 确定遍历顺序 举例推导dp数组 这些以后慢慢参透 LeetCode 509.斐波纳契数 最简单…...

Rust 的编译时间过长
Rust 代码的编译时间可能会比某些其他编程语言长,原因有以下几点: Rust 使用了静态类型,这意味着编译器需要更多的时间来验证类型安全性。与动态类型的语言相比,这可能会导致编译时间变长。Rust 的编译器在进行许多优化时需要大量…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

学习一下用鸿蒙DevEco Studio HarmonyOS5实现百度地图
在鸿蒙(HarmonyOS5)中集成百度地图,可以通过以下步骤和技术方案实现。结合鸿蒙的分布式能力和百度地图的API,可以构建跨设备的定位、导航和地图展示功能。 1. 鸿蒙环境准备 开发工具:下载安装 De…...

LCTF液晶可调谐滤波器在多光谱相机捕捉无人机目标检测中的作用
中达瑞和自2005年成立以来,一直在光谱成像领域深度钻研和发展,始终致力于研发高性能、高可靠性的光谱成像相机,为科研院校提供更优的产品和服务。在《低空背景下无人机目标的光谱特征研究及目标检测应用》这篇论文中提到中达瑞和 LCTF 作为多…...