Python日志配置策略
1 三种情况下都能实现日志打印:
- 被库 A 调用,使用库 A 的日志配置。
- 被库 B 调用,使用库 B 的日志配置。
- 独立运行,使用自己的日志配置。
需要实现一个灵活的日志配置策略,使得日志记录器可以根据调用者或运行环境自动调整。
实现方案
- 定义模块级别的日志记录器:在 Python 文件中定义一个模块级别的日志记录器。
- 检查已有的处理器:在模块级别日志记录器配置时检查是否已有处理器(即,是否已经由库 A 或库 B 配置了日志)。
- 独立运行时配置默认日志:如果没有已有的处理器,则添加默认的日志配置(如输出到控制台)。
示例代码
假设这个 Python 文件名为 my_module.py,以下是如何实现上述功能的完整代码:
# my_module.pyimport logging
import sys# 创建模块级别的日志记录器
logger = logging.getLogger(__name__)# 检查是否已有处理器
if not logger.hasHandlers():# 如果没有处理器,添加一个默认的控制台处理器logger.setLevel(logging.DEBUG)console_handler = logging.StreamHandler(sys.stdout)console_handler.setLevel(logging.DEBUG)formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')console_handler.setFormatter(formatter)logger.addHandler(console_handler)# 模块功能示例
def do_something():logger.debug("Debug message from my_module")logger.info("Info message from my_module")logger.warning("Warning message from my_module")logger.error("Error message from my_module")logger.critical("Critical message from my_module")# 检查是否作为脚本运行
if __name__ == '__main__':do_something()
详细说明
-
模块级别的日志记录器:
- 使用
logging.getLogger(__name__)获取一个模块级别的日志记录器,__name__保证了每个模块(文件)都有自己的日志记录器名称。 - 这使得日志记录器的名称会根据模块名称变化,如
my_module。
- 使用
-
检查已有处理器:
- 使用
logger.hasHandlers()检查是否已有处理器附加到日志记录器。 - 如果没有处理器(即此时没有任何库配置过该模块的日志),则添加默认的控制台处理器。这意味着在独立运行时,会使用这个默认处理器。
- 使用
-
独立运行时配置:
- 如果
my_module.py作为主脚本运行(即__name__ == '__main__'),将调用do_something(),触发日志输出。 - 当被其他库调用时,假设这些库已经配置了日志处理器,则不会添加新的处理器,使用调用者(库 A 或库 B)的日志配置。
- 如果
调用库 A 和库 B 的示例
假设有两个库,库 A 和库 B,各自配置了自己的日志记录器,然后调用 my_module:
# library_a.pyimport logging
import my_module# 配置库 A 的日志记录器
logger = logging.getLogger('library_a')
logger.setLevel(logging.DEBUG)
console_handler = logging.StreamHandler()
console_handler.setFormatter(logging.Formatter('%(asctime)s - library_a - %(levelname)s - %(message)s'))
logger.addHandler(console_handler)# 调用 my_module
my_module.do_something()
# library_b.pyimport logging
import my_module# 配置库 B 的日志记录器
logger = logging.getLogger('library_b')
logger.setLevel(logging.DEBUG)
console_handler = logging.StreamHandler()
console_handler.setFormatter(logging.Formatter('%(asctime)s - library_b - %(levelname)s - %(message)s'))
logger.addHandler(console_handler)# 调用 my_module
my_module.do_something()
验证功能
-
独立运行
my_module.py:- 直接运行
python my_module.py,日志将输出到控制台,使用my_module自己的配置。
- 直接运行
-
通过库 A 调用
my_module:- 运行
python library_a.py,日志将使用库 A 的配置。
- 运行
-
通过库 B 调用
my_module:- 运行
python library_b.py,日志将使用库 B 的配置。
- 运行
logging.getLogger('AITestCaseGenerator') 和 logging.getLogger('AITestCaseGenerator.ll') 获取的是具有层级关系的日志记录器,它们在日志管理和配置上有不同的作用。下面解释这两个日志记录器的区别:
2 日志记录器层级关系
在 Python 的 logging 模块中,日志记录器(logger)是分层级的。日志记录器的层级结构类似于文件系统的目录结构,这使得日志记录器可以继承父级日志记录器的配置和处理器。
获取日志记录器
-
logging.getLogger('AITestCaseGenerator'):- 获取名称为
'AITestCaseGenerator'的日志记录器。 - 它是该层级的主日志记录器。
- 获取名称为
-
logging.getLogger('AITestCaseGenerator.ll'):- 获取名称为
'AITestCaseGenerator.ll'的日志记录器。 - 这是
'AITestCaseGenerator'日志记录器的子级,继承其配置。
- 获取名称为
继承关系
子日志记录器会继承父日志记录器的处理器和级别,除非子日志记录器自己设置了处理器或日志级别。
示例
import logging# 获取父日志记录器
parent_logger = logging.getLogger('AITestCaseGenerator')
parent_logger.setLevel(logging.INFO)# 添加一个处理器到父日志记录器
parent_handler = logging.StreamHandler()
parent_handler.setFormatter(logging.Formatter('%(name)s - %(levelname)s - %(message)s'))
parent_logger.addHandler(parent_handler)# 获取子日志记录器
child_logger = logging.getLogger('AITestCaseGenerator.ll')# 记录日志
parent_logger.info("This is a message from the parent logger.")
child_logger.info("This is a message from the child logger.")
child_logger.debug("This is a debug message from the child logger.")
输出
AITestCaseGenerator - INFO - This is a message from the parent logger.
AITestCaseGenerator.ll - INFO - This is a message from the child logger.
- 解释:
parent_logger打印的消息显示其名称和日志级别。child_logger也显示其名称和日志级别,并继承了父日志记录器的处理器和日志级别,因此它的信息消息也被打印。child_logger的debug消息没有被打印,因为继承的日志级别为INFO。
如何配置和使用
-
父级日志记录器配置:
- 设置日志级别和处理器,将影响其所有子日志记录器,除非子日志记录器自己有设置。
-
子级日志记录器继承:
- 如果子级日志记录器没有自己设置处理器和级别,它将使用父级的处理器和级别。
- 可以为子级日志记录器添加额外的处理器或更改级别,覆盖继承的配置。
示例:为子级日志记录器添加自己的处理器
child_handler = logging.StreamHandler()
child_handler.setFormatter(logging.Formatter('%(name)s - %(levelname)s - %(message)s'))
child_logger.addHandler(child_handler)
child_logger.setLevel(logging.DEBUG)
现在,child_logger 将使用自己的处理器,并可以打印 DEBUG 级别的日志。
实际应用中的意义
-
模块化日志管理:
- 使用层级日志记录器,可以在大型项目中按模块或功能分区管理日志记录器。
- 每个模块可以有自己的日志记录器,同时继承项目级的日志配置。
-
灵活配置:
- 通过设置父级日志记录器的配置,确保统一的日志格式和级别管理。
- 通过设置子级日志记录器的配置,提供更精细的控制。
相关文章:

Python日志配置策略
1 三种情况下都能实现日志打印: 被库 A 调用,使用库 A 的日志配置。被库 B 调用,使用库 B 的日志配置。独立运行,使用自己的日志配置。 需要实现一个灵活的日志配置策略,使得日志记录器可以根据调用者或运行环境自动…...
想学编程,什么语言最好上手?
Python是许多初学者的首选,因为它的语法简洁易懂,而且有丰富的资源和社区支持。我这里有一套编程入门教程,不仅包含了详细的视频 讲解,项目实战。如果你渴望学习编程,不妨点个关注,给个评论222,…...

binlog和redolog有什么区别
在数据库管理系统中,binlog(binary log)和 redolog(redo log)是两种重要的日志机制,它们在数据持久性和故障恢复方面扮演着关键角色。虽然它们都用于记录数据库的变化,但它们的目的和使用方式有…...
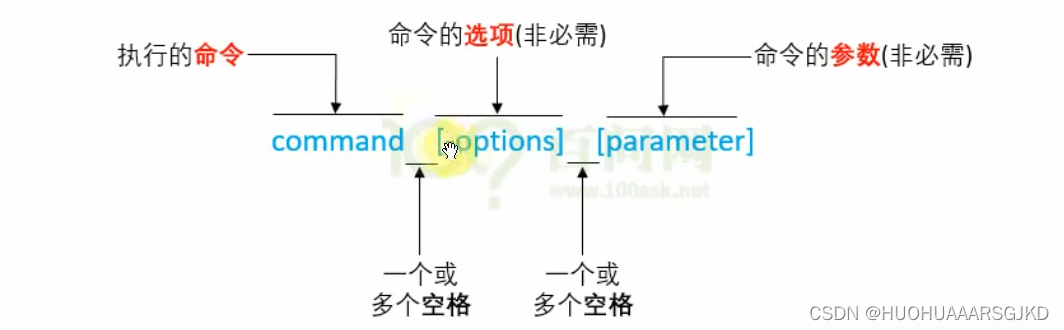
Linux笔记--ubuntu文件目录+命令行介绍
文件目录 命令行介绍 当我们在ubuntu中命令行处理位置输入ls后会显示出其所有目录,那么处理这些命令的程序就是shell,它负责接收用户的输入,并根据输入找到其他程序并运行 命令行格式 linux的命令一般由三部分组成:command命令、…...

71、最长上升子序列II
最长上升子序列II 题目描述 给定一个长度为N的数列,求数值严格单调递增的子序列的长度最长是多少。 输入格式 第一行包含整数N。 第二行包含N个整数,表示完整序列。 输出格式 输出一个整数,表示最大长度。 数据范围 1 ≤ N ≤ 100000…...
解决必剪电脑版导出视频缺斤少两的办法
背景 前几天将电脑重置了,今天想要剪辑一下视频,于是下载了必剪,将视频、音频都调整好,导出,结果15分钟的视频只能导出很短的时长,调整参数最多也只能导出10分钟,My God! 解决 首…...
)
新人学习笔记之(常量)
一、什么是常量 1.常量:在程序的执行过程中,其值不能发生改变的数据 二、常量的分类 常量类型说明举例整型常量整数、负数、0123 456实型常量所有带小数点的数字1.93 18.2字符常量单引号引起来的字母、数字、英文符号S B字符串常量双引号引起来的&…...

Lua解释器裁剪
本文目录 1、引言2、文件功能3、选择需要初始化的库4、结论 文章对应视频教程: 已更新。见下方 点击图片或链接访问我的B站主页~~~ Lua解释器裁剪,很简单~ 1、引言 在嵌入式中使用lua解释器,很多时候会面临资源紧张的情况。 同时,…...

web前端设计nav:深入探索导航栏设计的艺术与技术
web前端设计nav:深入探索导航栏设计的艺术与技术 在web前端设计中,导航栏(nav)扮演着至关重要的角色,它不仅是用户浏览网站的指引,更是网站整体设计的点睛之笔。本文将从四个方面、五个方面、六个方面和七…...

分析解读NCCL_SHM_Disable与NCCL_P2P_Disable
在NVIDIA的NCCL(NVIDIA Collective Communications Library)库中,NCCL_SHM_Disable 和 NCCL_P2P_Disable 是两个重要的环境变量,它们控制着NCCL在多GPU通信中的行为和使用的通信机制。下面是对这两个环境变量的详细解读࿱…...

使用 Python 进行测试(6)Fake it...
总结 如果我有: # my_life_work.py def transform(param):return param * 2def check(param):return "bad" not in paramdef calculate(param):return len(param)def main(param, option):if option:param transform(param)if not check(param):raise ValueError(…...

Flink Watermark详解
Flink Watermark详解 一、概述 Flink Watermark是Apache Flink框架中为了处理乱序和延迟事件时间数据而引入的一种机制。在流处理中,由于数据可能不是按照事件产生的时间顺序到达的,Watermark被用来告知系统在该时间戳之前的数据已经全部到达ÿ…...

LeetCode538.把二叉搜索树转换为累加树
class Solution { public:int sum 0; TreeNode* convertBST(TreeNode* root) { if (root){convertBST(root->right);sum root->val;root->val sum;convertBST(root->left);}return root;}};...

关于编程思想
面向过程思想 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候再一个一个的依次调用就可以了 JS就是典型的面向过程的编程语言 优点: 性能比面向对象编程高,适合跟硬件联系很紧密的东西…...
521. 最长特殊序列 Ⅰ(Rust单百解法-脑筋急转弯)
题目 给你两个字符串 a 和 b,请返回 这两个字符串中 最长的特殊序列 的长度。如果不存在,则返回 -1 。 「最长特殊序列」 定义如下:该序列为 某字符串独有的最长 子序列 (即不能是其他字符串的子序列) 。 字符串 s …...
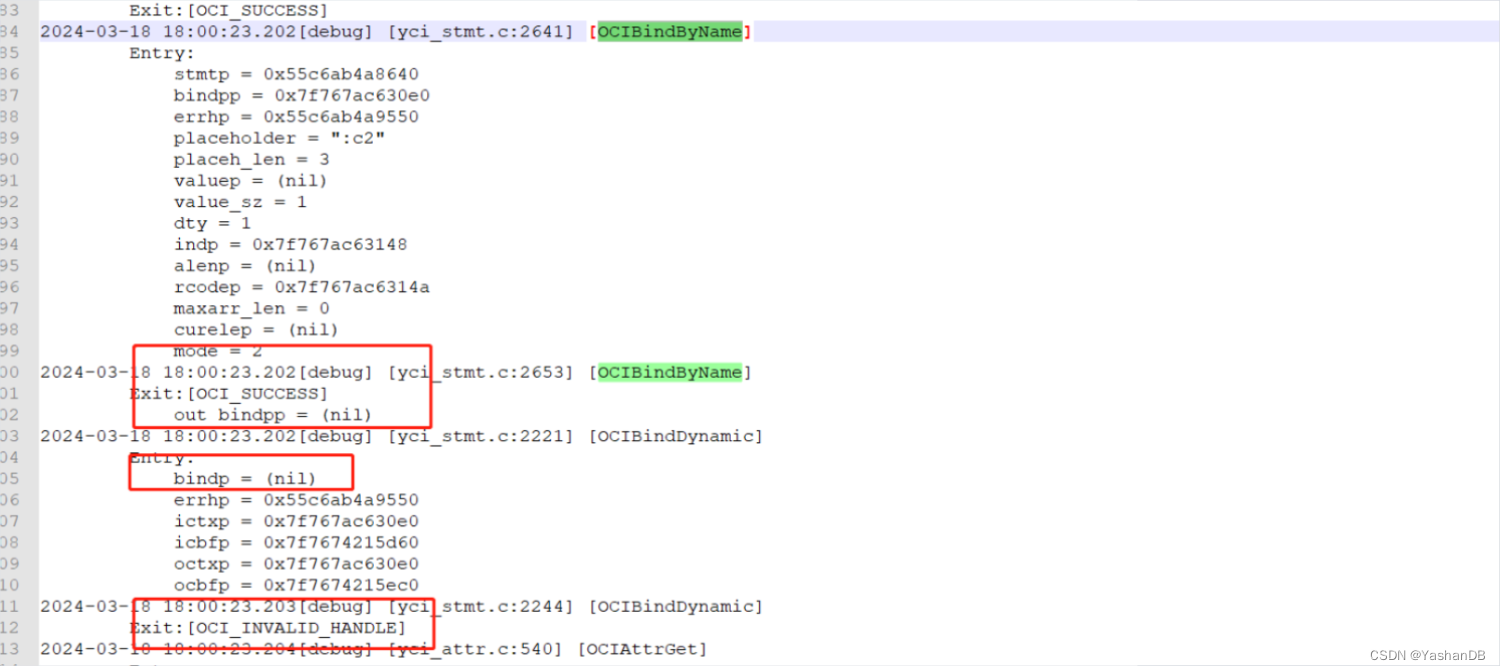
【YashanDB知识库】PHP使用OCI接口使用数据库绑定参数功能异常
【问题分类】驱动使用 【关键字】OCI、驱动使用、PHP 【问题描述】 PHP使用OCI8连接yashan数据库,使用绑定参数获取数据时,出现报错 如果使用PDO_OCI接口连接数据库,未弹出异常,但是无法正确获取数据 【问题原因分析】 开启O…...

深入分析 Android BroadcastReceiver (三)
文章目录 深入分析 Android BroadcastReceiver (三)1. 广播消息的优缺点及使用场景1.1 优点1.2 缺点 2. 广播的使用场景及代码示例2.1. 系统广播示例:监听网络状态变化 2.2. 自定义广播示例:发送自定义广播 2.3. 有序广播示例:有序广播 2.4. …...

在java中使用Reactor 项目中的一个类Mono,用于表示异步单值操作
Mono 是 Reactor 项目中的一个类,用于表示异步单值操作。Reactor 是一个响应式编程库,广泛应用于 Java 中的异步编程和非阻塞 I/O 操作。Mono 可以类比为一个可能(或将来)包含零个或一个值的异步计算结果。与 Flux(另一…...
LabVIEW故障预测
在LabVIEW故障预测中,振动信号特征提取的关键技术主要包括以下几个方面: 时域特征提取:时域特征是直接从振动信号的时间序列中提取的特征。常见的时域特征包括振动信号的均值、方差、峰值、峰-峰值、均方根、脉冲指数等。这些特征能够反映振动…...

掌握JavaScript中的`async`和`await`:循环中的使用指南
引言 在JavaScript的异步编程中,async和await提供了一种更接近同步代码的写法,使得异步逻辑更加清晰易懂。然而,当它们与循环结合时,一些常见的陷阱和误区可能会出现。本文将通过代码示例,指导你如何在循环中正确使用…...

从Nucleo板到我的DIY板:手把手教你移植STM32F103的BSP驱动代码
从Nucleo板到我的DIY板:手把手教你移植STM32F103的BSP驱动代码 当你在Nucleo开发板上完成了一个完美的项目,正准备将其移植到自己的定制电路板时,硬件差异往往会成为第一个拦路虎。LED引脚变了、按键位置不同、串口通道更换——这些看似微小的…...

多显示器DPI精准调节:效率倍增的显示一致性解决方案
多显示器DPI精准调节:效率倍增的显示一致性解决方案 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 在当今多屏办公环境中,你是否曾经历过这样的尴尬:主显示器文字清晰锐利,副显示器却模糊…...
)
Burp Suite实战:文件上传漏洞双写绕过技巧详解(附完整Payload)
Burp Suite实战:文件上传漏洞双写绕过技巧详解(附完整Payload) 在Web安全测试中,文件上传功能往往是攻击者最青睐的攻击入口之一。许多开发者会通过黑名单过滤、后缀名检查等方式来防御恶意文件上传,但这些防护措施往往…...

ART-Adversarial Robustness Toolbox实战:从手写数字到交通信号的对抗攻防演练
1. 对抗攻击与防御的实战起点 第一次听说"对抗样本"这个概念时,我正在调试一个手写数字识别模型。明明人眼都能轻松辨认的数字"7",模型却固执地认为它是"1"。这种看似魔法的现象,背后其实是精心设计的微小扰动…...
)
Nacos端口配置全攻略:从1.x到3.0版本差异详解(附防火墙规则)
Nacos端口配置全攻略:从1.x到3.0版本差异详解(附防火墙规则) 在微服务架构的浪潮中,Nacos作为阿里巴巴开源的动态服务发现、配置管理和服务管理平台,已经成为众多企业技术栈中的核心组件。随着版本的迭代,N…...

BloodHound实战指南:内网域渗透的可视化利器
1. BloodHound:内网域渗透的"上帝视角" 第一次接触BloodHound时,我正被困在一个庞大的企业内网里。传统的手工枚举让我精疲力尽,直到看到这个工具将整个域环境变成了一张立体关系网——用户、计算机、权限关系像星座图一样清晰呈现…...

基于SpringBoot毕业设计管理系统的效率优化实战:从单体架构到高响应体验
最近在参与一个毕业设计管理系统的重构项目,系统主要服务于师生进行选题、开题、中期检查、答辩等全流程管理。随着用户量增长,原有的系统在高并发场景下暴露出了不少性能问题,比如选题时页面卡顿、审核流程通知延迟、报表查询缓慢等。我们团…...

影刀RPA操作飞书表格时,那个烦人的‘记录ID数组’问题,我是这样绕过去的
影刀RPA操作飞书多维表格时如何巧妙规避记录ID数组陷阱 第一次用影刀RPA批量更新飞书多维表格时,我盯着调试面板里那串诡异的[["recxxxxx"]]格式记录ID发呆了半小时——这跟官方文档里承诺的"直接字符串ID"完全不符。更糟的是,当我尝…...

RMBG-2.0开发者实操手册:@st.cache_resource缓存机制与推理延迟优化策略
RMBG-2.0开发者实操手册:st.cache_resource缓存机制与推理延迟优化策略 1. 引言:从“能用”到“好用”的性能跃迁 如果你已经体验过RMBG-2.0抠图工具,可能会发现一个现象:第一次点击“开始抠图”时,需要等待几秒钟&a…...

实战解析——Spring Cache与Redis在苍穹外卖中的高效缓存策略
1. 为什么需要缓存策略 在开发苍穹外卖这类高并发餐饮系统时,数据库查询压力是个绕不开的难题。想象一下中午用餐高峰期,成千上万的用户同时浏览菜单,如果每次请求都直接查询数据库,MySQL服务器很快就会不堪重负。我去年做过压力测…...