C++前期概念(重)
目录
命名空间
命名空间定义
1. 正常的命名空间定义
2. 命名空间可以嵌套
3.头文件中的合并
命名空间使用
命名空间的使用有三种方式:
1:加命名空间名称及作用域限定符(::)
2:用using将命名空间中某个成员引入
3:使用using namespace 命名空间名称 引入
C++输入&输出
说明:
std命名空间的使用惯例:
缺省参数
缺省参数分类
1:全缺省参数
2:半缺省参数
注意:半缺省参数必须从右到左依次来给出,不能间隔给,缺省参数不能在函数声明和定义中同时出现
编辑
3. 缺省值必须是常量或者全局变量
函数重载
1、参数类型不同
2、参数个数不同
3、参数类型顺序不同
main
引用
引用概念
重:类型& 引用变量名(对象名) = 引用实体;
注意:
引用特性
1. 引用在定义时必须初始化
2. 一个变量可以有多个引用
3. 引用一旦引用一个实体,再不能引用其他实体
常引用
使用场景(比C简单)
1. 做参数(交换值)
2. 引用做返回值(不用创建临时变量)
注意:引用是不可以改变指向的
地址的交换值(指针也可以开别名)
链表的双指针也可以更简单
总结:
引用的读写功能和优点
引用和指针的区别
内联函数(短小函数定义 换用内联函数)
宏的优缺点?
优点:
缺点:
auto在for循环中
空指针
命名空间
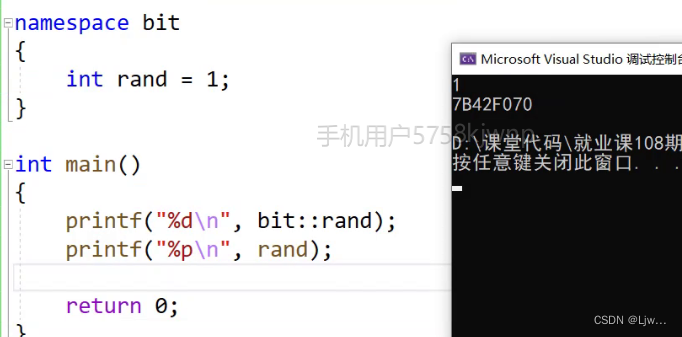
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存 在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
比如在C语言中
C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决
#include <stdio.h>
#include <stdlib.h>int rand = 10;// C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决int main()
{printf("%d\n", rand);return 0;
}// 编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”
命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{ }即可,{ }
中即为命名空间的成员。
1. 正常的命名空间定义
namespace N{// 命名空间中可以定义变量/函数/类型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}
2. 命名空间可以嵌套
namespace N1
{int a;int b;int Add(int left, int right){return left + right;}namespace N2{int c;int d;int Sub(int left, int right){return left - right;}}
}
3.头文件中的合并
同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。一个工程中的test.h和上面test.cpp中两个N1会被合并成一个.不同的头文件里定义的命名域,到.cpp里包含上这两个头文件,相当于合并了,都能访问到.

注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
命名空间使用
比如:(里面printf,会出现//编译报错:error C2065: “a”: 未声明的标识符)
namespace N{// 命名空间中可以定义变量/函数/类型int a = 0;int b = 1;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}int main()
{// 编译报错:error C2065: “a”: 未声明的标识符printf("%d\n", a);return 0;
}
命名空间的使用有三种方式:
展开命名空间会进去搜索,展开命名空间域就等于暴露到全局
1:加命名空间名称及作用域限定符(::)
int main()
{printf("%d\n", N::a);return 0;
}2:用using将命名空间中某个成员引入
using N::b;int main()
{printf("%d\n", N::a);printf("%d\n", b);return 0;
}
3:使用using namespace 命名空间名称 引入
using namespce N;int main()
{printf("%d\n", N::a);printf("%d\n", b);Add(10, 20);return 0;
}C++输入&输出
std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
#include<iostream>// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中using namespace std;int main() {cout"Hello world!!!"endl;return 0; }说明:
1. 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件
以及按命名空间使用方法使用std。 2. cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含< iostream >头文件中。
3. 是流插入运算符,>>是流提取运算符。
4. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
C++的输入输出可以自动识别变量类型。
5. 实际上cout和cin分别是ostream和istream类型的对象,>>和也涉及运算符重载等知识, 这些知识我们我们后续才会学习,所以我们这里只是简单学习他们的使用。后面我们还有有 一个章节更深入的学习IO流用法及原理。 注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应 头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间, 规定C++头文件不带.h;旧编译器(vc 6.0)中还支持格式,后续编译器已不支持,因 此推荐使用+std的方式。
#include <iostream>using namespace std;int main()
{int a;double b;char c;// 可以自动识别变量的类型cin>>a;cin>>b>>c;cout<<a<<endl;cout<<b<<" "<<c<<endl;return 0;
std命名空间的使用惯例:
std是C++标准库的命名空间,如何展开std使用更合理呢?
1. 在日常练习中,建议直接using namespace std即可,这样就很方便。
2. using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模 大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 + using std::cout展开常用的库对象/类型等方式。
缺省参数
缺省参数就是给出的函数参数的默认值
在调用有缺省参数的函数时,如果没有指定实参则采用该默认值,否则使用指定的实参
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实 参则采用该形参的缺省值,否则使用指定的实参。
Func(); // 没有传参时,使用参数的默认值
Func(10); // 传参时,使用指定的实参
void Func(int a = 0)
{cout<<a<<endl;
}int main()
{Func(); // 没有传参时,使用参数的默认值Func(10); // 传参时,使用指定的实参return 0;
}缺省参数分类
1:全缺省参数
void Func(int a = 10, int b = 20, int c = 30){cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;}2:半缺省参数
void Func(int a, int b = 10, int c = 20){cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;}注意:半缺省参数必须从右到左依次来给出,不能间隔给,缺省参数不能在函数声明和定义中同时出现
3. 缺省值必须是常量或者全局变量
函数重载
参数不同包含类型不同,顺序不同,类型的顺序不同和个数不同
重载函数必须参数列表有所不同(包括参数类型和参数个数)
重载函数不依靠返回值来区分,所以返回值可以相同
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这 些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型 不同的问题。
1、参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}2、参数个数不同
void f()
{cout << "f()" << endl;
}void f(int a){cout << "f(int a)" << endl;
}3、参数类型顺序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
main
int main()
{Add(10, 20);Add(10.1, 20.2);f();f(10);f(10, 'a');f('a', 10);return 0;
}引用
引用概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用的变量共用同一块内存空间。
重:类型& 引用变量名(对象名) = 引用实体;
void TestRef()
{int a = 10;int& ra = a;//<====定义引用类型printf("%p\n", &a);printf("%p\n", &ra);
}
注意:
引用类型必须和引用实体是同种类型的
引用特性
1. 引用在定义时必须初始化
2. 一个变量可以有多个引用
3. 引用一旦引用一个实体,再不能引用其他实体
void TestRef()
{int a = 10;// int& ra; // 该条语句编译时会出错int& ra = a;int& rra = a;printf("%p %p %p\n", &a, &ra, &rra);
}常引用
void TestConstRef()
{const int a = 10;//int& ra = a; // 该语句编译时会出错,a为常量const int& ra = a;// int& b = 10; // 该语句编译时会出错,b为常量const int& b = 10;double d = 12.34;//int& rd = d; // 该语句编译时会出错,类型不同const int& rd = d;
}使用场景(比C简单)
1. 做参数(交换值)
void Swap(int& left, int& right)
{int temp = left;left = right;right = temp;
}
2. 引用做返回值(不用创建临时变量)
传值返回 ,返回的是他的拷贝,所以要调用一次拷贝构造
传引用返回,返回的是他的别名
减少了拷贝,提高了效率
静态的没问题去掉static就有问题了,n在静态栈,不在临时的count里
int& Count()
{static int n = 0;//静态的没问题去掉static就有问题了n++;// ...return n;返回的时n的别名(引用)
}
//add1对
int& add1()
{static int x = 3;return x;
}
//add2是不对的,
int& add2()
{int x = 3;return x;
}
注意:引用是不可以改变指向的

是赋值
 并且abc的值都被改了
并且abc的值都被改了
常引用
b的改变会影响a,是所以不行


引用的过程中,权限不能被放大。
const int a=0;int&b=a; const int c=0;int d=c;
类型相同不用创建临时变量、
类型不同,需要创建临时变量,同时临时变量具有常性
类型转换/强制类型转换就要创建临时变量 临时变量具有常性
临时变量具有常性

地址的交换值(指针也可以开别名)
用C需要二级指针,但用引用就可以不用二级
void swap(int*& a,int*& b)
{int*t=a;a=b;b=t;
}int main()
{int x=0;int y=1;int*px=&x;int*py=&y;swap(px,py);
}链表的双指针也可以更简单

总结:
1、基本任何场景都可以引用传参
2、谨慎用引用做返回值。出了函数作用域,对象不在了,就不能用引用返回,还在就可以用引用返回
引用的读写功能和优点
查找和修改

改进

引用和指针的区别
引用和指针的不同点:
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何 一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32
位平台下占4个字节)
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. 引用比指针使用起来相对更安全
10.引用一旦定义时初始化指定,就不能再修改,指针可以改变指向
11.引用表面好像是传值,其本质也是传地址,只是这个工作有编译器来做
12.指针需要开辟空间,引用不需要开辟空间
13.指针是间接操作对象,引用时对象的别名,对别名的操作就是对真实对象的直接操作
内联函数(短小函数定义 换用内联函数)
定义和声明要一起,inline函数不支持声明和定义分离开
1. inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会 用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运 行效率。
2. inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
宏的优缺点?
优点:
1.增强代码的复用性。
2.提高性能。
缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
2.导致代码可读性差,可维护性差,容易误用。
3.没有类型安全的检查 。
C++有哪些技术替代宏?
1. 常量定义 换用const enum
2. 短小函数定义 换用内联函数
auto在for循环中
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto
的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编 译期会将auto替换为变量实际的类型。
auto与指针和引用结合起来使用 用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须 加&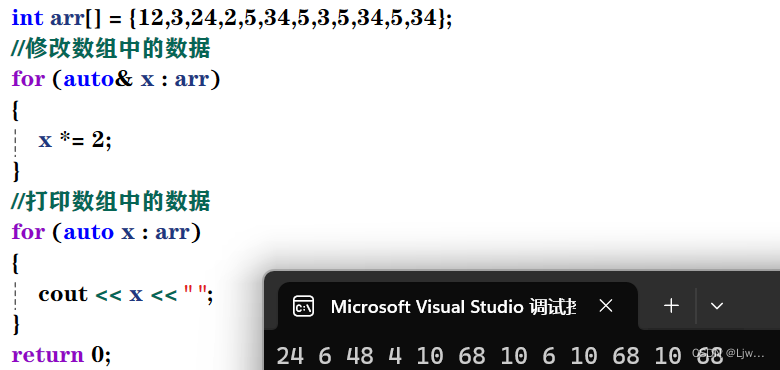
适用于数组
范围for
依次取数组中数据赋值给x
x只是个符号,符号随便起
空指针
C++中,NULL相当于0,要用nullptr了
相关文章:
C++前期概念(重)
目录 命名空间 命名空间定义 1. 正常的命名空间定义 2. 命名空间可以嵌套 3.头文件中的合并 命名空间使用 命名空间的使用有三种方式: 1:加命名空间名称及作用域限定符(::) 2:用using将命名空间中某个成员引入 3:使用using namespa…...

Java字符串加密HMAC-SHA1密钥,转换成Base64编码
新建一个maven测试项目,直接把代码复制过去就行,把data和secretKey的值替换成想加密的值。 package test;import javax.crypto.Mac; import javax.crypto.spec.SecretKeySpec; import java.security.InvalidKeyException; import java.security.NoSuchA…...
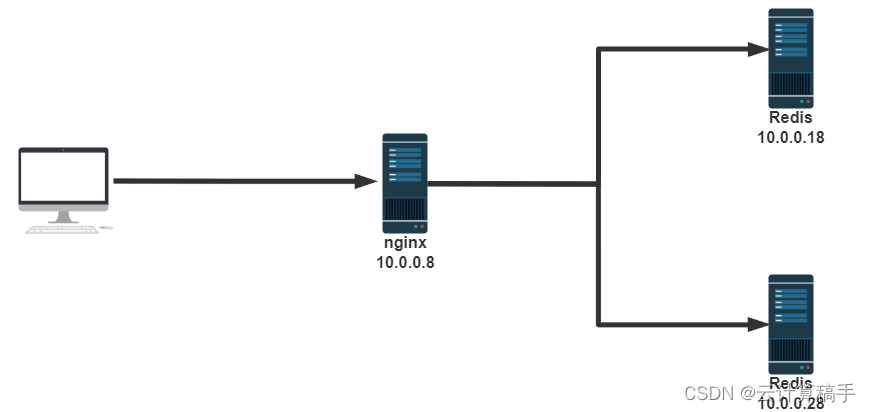
【网络架构】Nginx
目录 一、I/O模型 1.1 Linux 的 I/O 1.2 零拷贝技术 1.3 网络IO模型 1.3.1 阻塞型 I/O 模型(blocking IO)编辑 1.3.2非阻塞型 I/O 模型 (nonblocking IO)编辑 1.3.3 多路复用 I/O 型 ( I/O multiplexing )编辑 1.3.4 信号驱动式 I/O 模型 …...

C# OpenCvSharp 逻辑运算-bitwise_and、bitwise_or、bitwise_not、bitwise_xor
bitwise_and 函数 🤝 作用或原理: 将两幅图像进行与运算,通过逻辑与运算可以单独提取图像中的某些感兴趣区域。如果有掩码参数,则只计算掩码覆盖的图像区域。 示例: 在实际应用中,可以用 bitwise_and 来提取图像中的某些部分。例如,我们可以从图像中提取出一个特定的颜…...
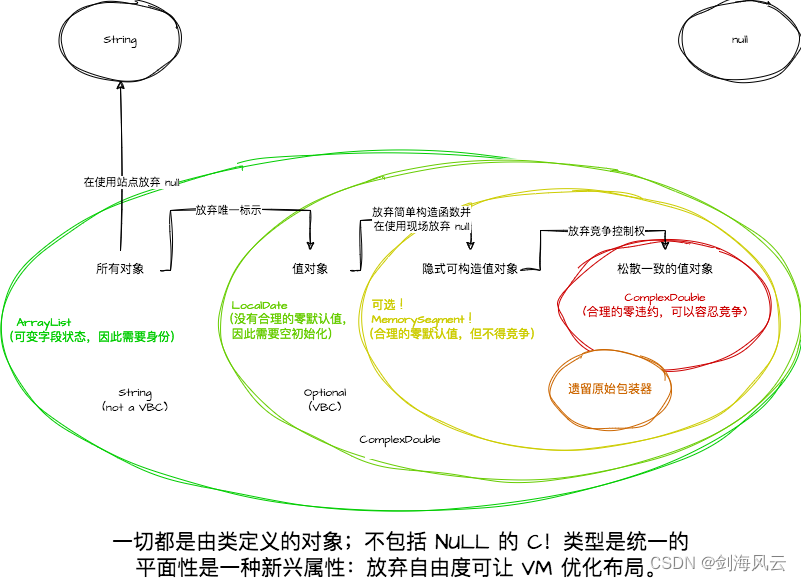
JVM常用概念之扁平化堆容器
扁平化堆容器是OpenJDK Valhalla 项目提出的,其主要目标为将值对象扁平化到其堆容器中,同时支持这些容器的所有指定行为,从而达到不影响原有功能的情况下,显著减少内存空间的占用(理想条件下可以减少24倍)。…...
)
python面试题5:浅拷贝和深拷贝之间有什么区别?(难度--中等)
文章目录 题目回答1.浅拷贝2.深拷贝 题目 浅拷贝和深拷贝之间有什么区别? 回答 1.浅拷贝 浅拷贝对于不可变数据,如字符串,整数,数组,往往是直接复制其的值。对于可变对象如列表,则是指向同一个地址。这…...

Jetson Linux 上安装ZMQ
1. 安装ZMQ 框架 apt-get install libzmq3-dev 2. 或者自己build ZMQ https://github.com/zeromq/libzmq.git 参考官网教程 3. 安装CPPZMQ CPPZMQ 是ZMQ 的友好的C封装,只需要一个zmq.hpp 头文件即可 git clone https://github.com/zeromq/cppzmq.git cd cppz…...
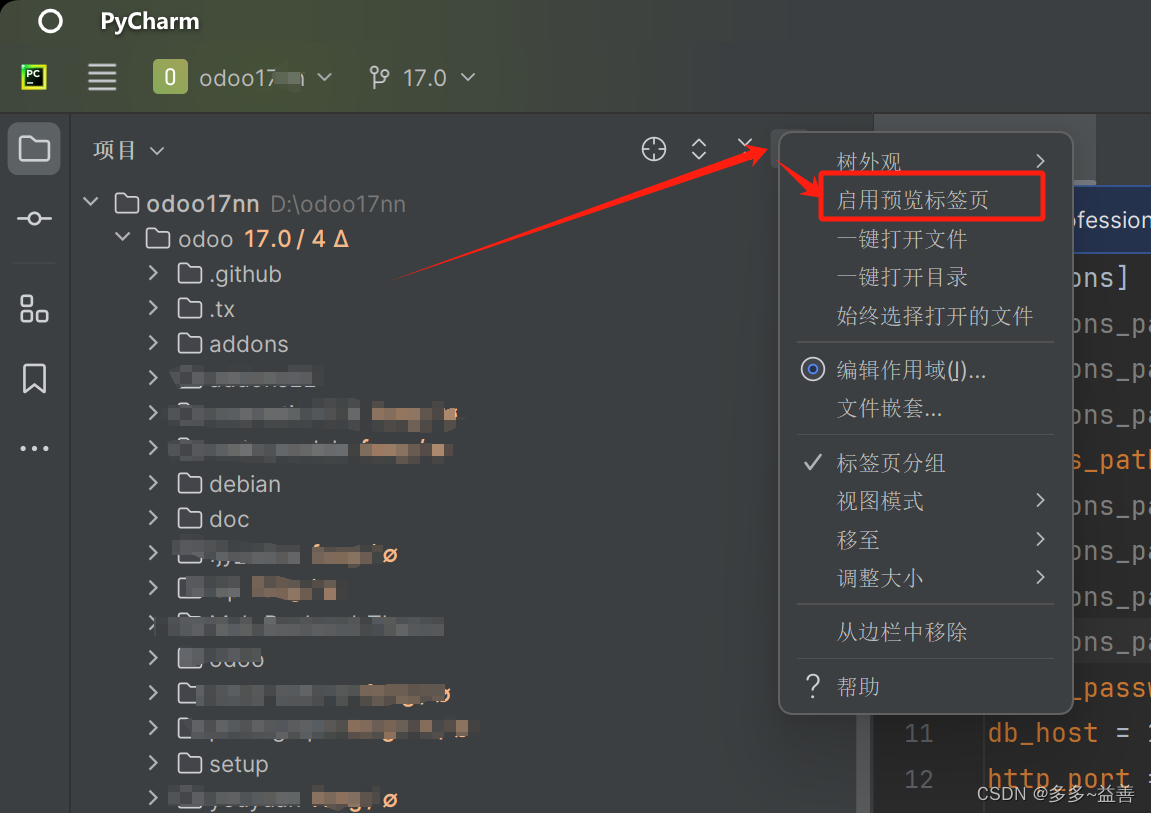
【Pycharm】设置双击打开文件
概要 习惯真可怕。很多小伙伴用习惯了VsCode开发,或者其他一些开发工具,然后某些开发工具是单击目录文件就能打开预览的,而换到pycharm后,发现目录是双击才能打开预览,那么这个用起来就特别不习惯。 解决办法 只需一…...

Web前端后端架构:构建高效、稳定与可扩展的互联网应用
Web前端后端架构:构建高效、稳定与可扩展的互联网应用 在构建互联网应用的过程中,Web前端与后端架构的设计与实施至关重要。一个优秀的架构能够确保应用的稳定性、高效性和可扩展性,为用户提供流畅、安全的体验。本文将从四个方面、五个方面…...

数据仓库核心:事实表深度解析与设计指南
文章目录 1. 引言1.1基本概念1.2 事实表定义 2. 设计原则2.1 原则一:全面覆盖业务相关事实2.2 原则二:精选与业务过程紧密相关的事实2.3 原则三:拆分不可加事实为可加度量2.4 原则四:明确声明事实表的粒度2.5 原则五:避…...

Reactor和epoll
Reactor模式和epoll都是与事件驱动的网络编程相关的术语,但它们属于不同的概念层面: Reactor模式 Reactor模式是一种事件驱动的编程模型,用于处理并发的I/O事件。这种模式使用一个或多个输入源(如套接字),…...
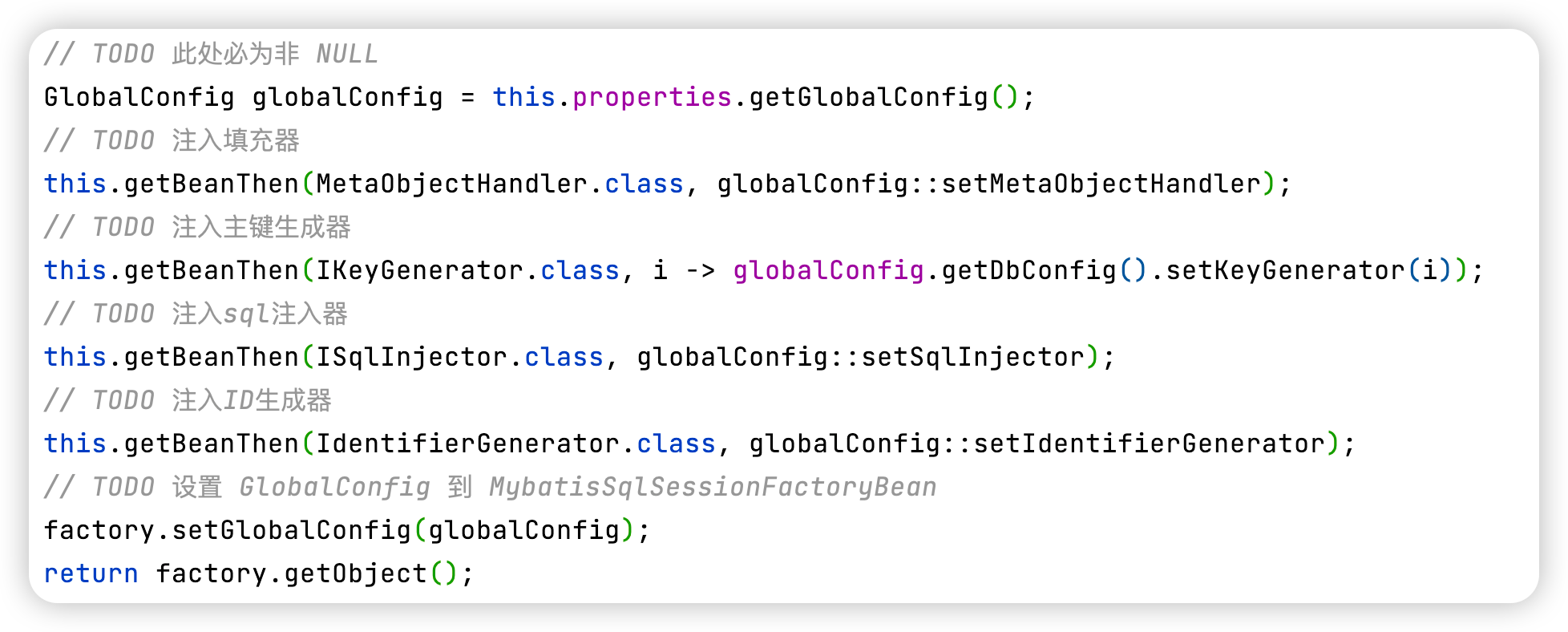
Mybatis-Plus多种批量插入方案对比
背景 六月某日上线了一个日报表任务,因是第一次上线,故需要为历史所有日期都初始化一次报表数据 在执行过程中发现新增特别的慢:插入十万条左右的数据,SQL执行耗费高达三分多钟 因很早就听闻过mybatis-plus的[伪]批量新增的问题&…...

数据库面试
1. 简单介绍一下Spring中的事务管理。 答:事务就是对一系列的数据库操作(比如将insert,delete,update,select多条sql语句)作为一个整体执行,进行统一的提交或回滚操作,如果这组sql语…...

探索Web Components
title: 探索Web Components date: 2024/6/16 updated: 2024/6/16 author: cmdragon excerpt: 这篇文章介绍了Web Components技术,它允许开发者创建可复用、封装良好的自定义HTML元素,并直接在浏览器中运行,无需依赖外部库。通过组合HTML模…...

摄影师在人工智能竞赛中与机器较量并获胜
摄影师在人工智能竞赛中与机器较量并获胜 自从生成式人工智能出现以来,由来已久的人机大战显然呈现出一边倒的态势。但是有一位摄影师,一心想证明用人眼拍摄的照片是有道理的,他向算法驱动的竞争对手发起了挑战,并取得了胜利。 迈…...

CMU最新论文:机器人智慧流畅的躲避障碍物论文详细讲解
CMU华人博士生Tairan He最新论文:Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion 代码开源:Code: https://github.com/LeCAR-Lab/ABS B站实际效果展示视频地址:bilibili效果地址 我会详细解读论文的内容,让我们开始吧…...

Spring中自定义注解进行类方法增强
说明 说到对类方法增强,第一时间想到自定义注解,通过aop切面进行实现。这是一种常用做法,但是在某些场景下,如开发公共组件,定义aop切面可能不是最优方案。以后通过原生aop方式,自定义注解,对类…...

TS:元组
问: 解释下什么是元组 回答: 元组(Tuple)是一种数据结构,类似于数组,但与数组不同的是,元组中的元素类型可以各不相同,且元组的长度是固定的。元组在许多编程语言中都有实现,包括 TypeScript…...

微服务 | Springboot整合Dubbo+Nacos实现RPC调用
官网:Apache Dubbo 随着互联网技术的飞速发展,越来越多的企业和开发者开始关注微服务架构。微服务架构可以将一个大型的应用拆分成多个独立、可扩展、可维护的小型服务,每个服务负责实现应用的一部分功能。这种架构方式可以提高开发效率&…...

读书的意义
...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...