【Python】在 Pandas 中使用 AdaBoost 进行分类
我们都找到天使了
说好了 心事不能偷藏着
什么都 一起做 幸福得 没话说
把坏脾气变成了好沟通
我们都找到天使了 约好了
负责对方的快乐
阳光下 的山坡 你素描 的以后
怎么抄袭我脑袋 想的
🎵 薛凯琪《找到天使了》
在数据科学和机器学习的工作流程中,Pandas 是一个非常强大的数据操作和分析工具库。结合 Pandas 和 AdaBoost 分类算法,可以高效地进行数据预处理和分类任务。本文将介绍如何在 Pandas 中使用 AdaBoost 进行分类。
什么是 AdaBoost?
AdaBoost(Adaptive Boosting)是一种集成学习算法,通过结合多个弱分类器来提升分类性能。每个弱分类器都专注于之前分类错误的样本,最终形成一个强分类器。AdaBoost 适用于各种分类任务,具有很高的准确性和适应性。
使用 AdaBoost 的步骤
数据准备:使用 Pandas 加载和预处理数据。
模型训练:使用 Scikit-Learn 实现 AdaBoost 算法进行模型训练。
模型评估:评估模型的性能。
安装必要的库
在开始之前,请确保你已经安装了 Pandas 和 Scikit-Learn。你可以使用以下命令进行安装:
pip install pandas scikit-learn
步骤一:数据准备
我们将使用一个示例数据集,并通过 Pandas 进行加载和预处理。假设我们使用的是著名的 Iris 数据集。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris# 加载 Iris 数据集
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target# 显示前几行数据
print(df.head())
步骤二:模型训练
在这一步中,我们将使用 Scikit-Learn 提供的 AdaBoostClassifier 进行模型训练。
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 分割数据集为训练集和测试集
X = df.drop(columns=['target'])
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 初始化弱分类器(决策树)
weak_classifier = DecisionTreeClassifier(max_depth=1)# 初始化 AdaBoost 分类器
adaboost = AdaBoostClassifier(base_estimator=weak_classifier, n_estimators=50, learning_rate=1.0, random_state=42)# 训练模型
adaboost.fit(X_train, y_train)# 预测
y_pred = adaboost.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
步骤三:模型评估
我们已经在上面的代码中计算了模型的准确性。除此之外,我们还可以绘制混淆矩阵和分类报告,以更详细地评估模型性能。
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
import matplotlib.pyplot as plt# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()# 分类报告
report = classification_report(y_test, y_pred, target_names=iris.target_names)
print(report)
结论
通过上述步骤,我们展示了如何使用 Pandas 和 Scikit-Learn 实现 AdaBoost 分类。具体步骤包括数据准备、模型训练和模型评估。AdaBoost 是一种强大的集成学习算法,通过结合多个弱分类器来提高分类性能。结合 Pandas 的数据处理能力和 Scikit-Learn 的机器学习工具,可以高效地完成分类任务。
相关文章:

【Python】在 Pandas 中使用 AdaBoost 进行分类
我们都找到天使了 说好了 心事不能偷藏着 什么都 一起做 幸福得 没话说 把坏脾气变成了好沟通 我们都找到天使了 约好了 负责对方的快乐 阳光下 的山坡 你素描 的以后 怎么抄袭我脑袋 想的 🎵 薛凯琪《找到天使了》 在数据科学和机器学习的工作…...
)
持续总结中!2024年面试必问 20 道并发编程面试题(九)
上一篇地址:持续总结中!2024年面试必问 20 道并发编程面试题(八)-CSDN博客 十七、请解释什么是Callable和FutureTask。 Callable和FutureTask是Java并发API中的重要组成部分,它们用于处理可能产生结果的异步任务。 …...
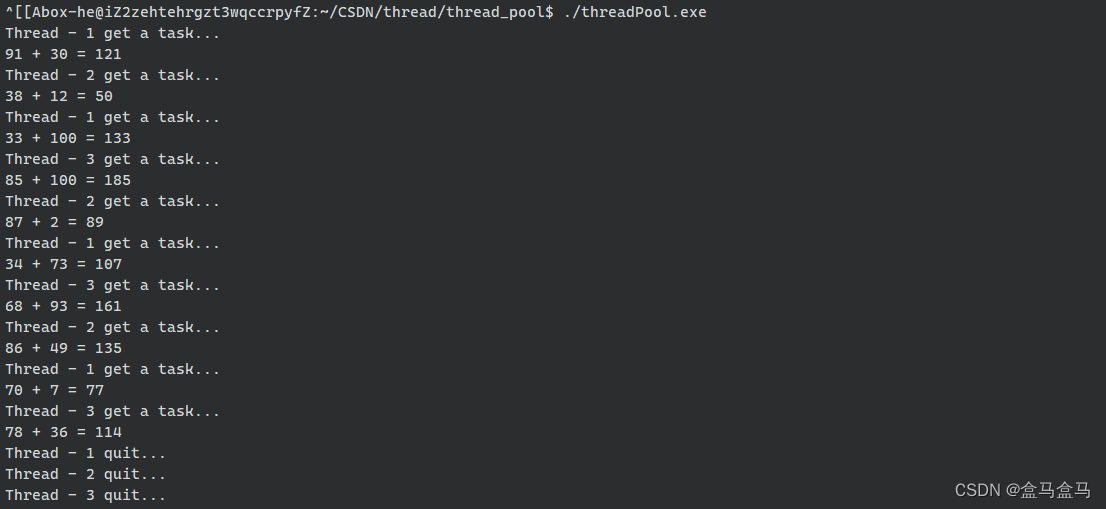
Linux:线程池
Linux:线程池 线程池概念封装线程基本结构构造函数相关接口线程类总代码 封装线程池基本结构构造与析构初始化启动与回收主线程放任务其他线程读取任务终止线程池测试线程池总代码 线程池概念 线程池是一种线程使用模式。线程过多会带来调度开销,进而影…...

集成学习方法:Bagging与Boosting的应用与优势
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...

JEnv-for-Windows 2 java版本工具的安装使用踩坑
0.环境 windows11pro 1.工具下载 GitHub - Mu-L/JEnv-for-Windows: Change your current Java version with one line or JEnv-for-Windows:Change your current Java version with one line - GitCode 2.执行jenv 初始化 2.1 问题:PowerShell 未对文件\XXX.…...
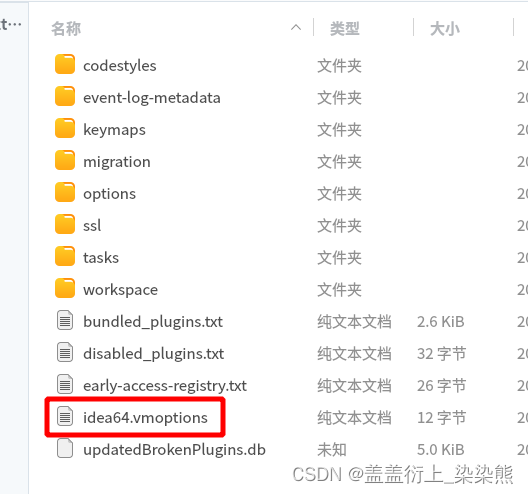
linux中: IDEA 由于JVM 设置内存过小,导致打开项目闪退问题
1. 找到idea安装目录 由于无法打开idea,只能找到idea安装目录 在linux(debian/ubuntu)中idea的插件默认安装位置和配置文件在哪里? 默认路径: /home/当前用户名/.config/JetBrains/IntelliJIdea2020.具体版本号/options2. 找到jvm配置文件 IDEA安装…...

d3.js获取流程图不同的节点
在D3.js中,获取流程图中不同的节点通常是通过选择SVG元素并使用数据绑定来实现的。流程图的节点可以通过BPMN、JSON或其他数据格式定义,然后在D3.js中根据这些数据动态生成和选择节点。 以下是一个基本的示例,展示如何使用D3.js选择和操作流…...

MFC socket编程-服务端和客户端流程
MFC 提供了一套丰富的类库来简化 Windows 应用程序的网络编程。以下是使用 MFC 进行 socket 编程时服务端和客户端的基本流程: 服务端流程: 初始化 Winsock: 调用 AfxSocketInit 初始化 Winsock 库。 创建 CSocket 或 CAsyncSocket 对象&am…...

22.1 正则表达式-定义正则表达式、正则语法
1.定义正则表达式 正则表达式意在描述隐藏在数据中的某种模式或规则。 例如:下面的几个字符串看似各不相同: slimshady999roger1813Wagner但看似不同的数据却隐藏着相同的特征: 仅由英语字母和数字组成英语字母有小写也有大写总字符数介于 …...
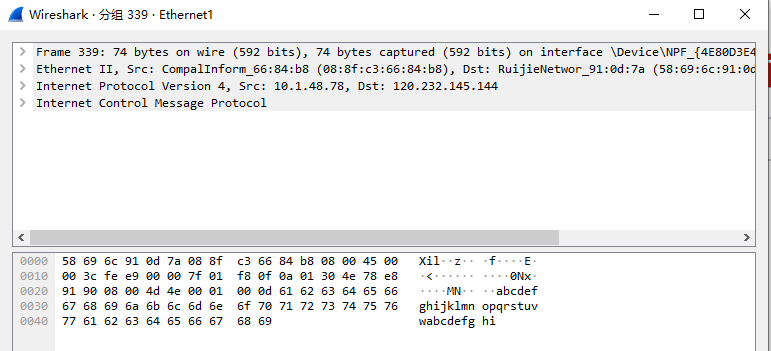
网络数据包抓取与分析工具wireshark的安及使用
WireShark安装和使用 WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。 1 任务目标 1.1 知识目标 了解WireShark的过滤器使用,通过过滤器可以筛选出想要分析的内容 掌握Wir…...
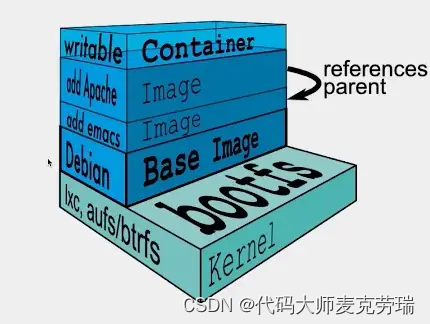
Docker镜像技术剖析
目录 1、概述1.1 什么是镜像?1.2 联合文件系统UnionFS1.3 bootfs和rootfs1.4 镜像结构1.5 镜像的主要技术特点1.5.1 镜像分层技术1.5.2 写时复制(copy-on-write)策略1.5.3 内容寻址存储(content-addressable storage)机制1.5.4 联合挂载(union mount)技术 2.机制原理…...
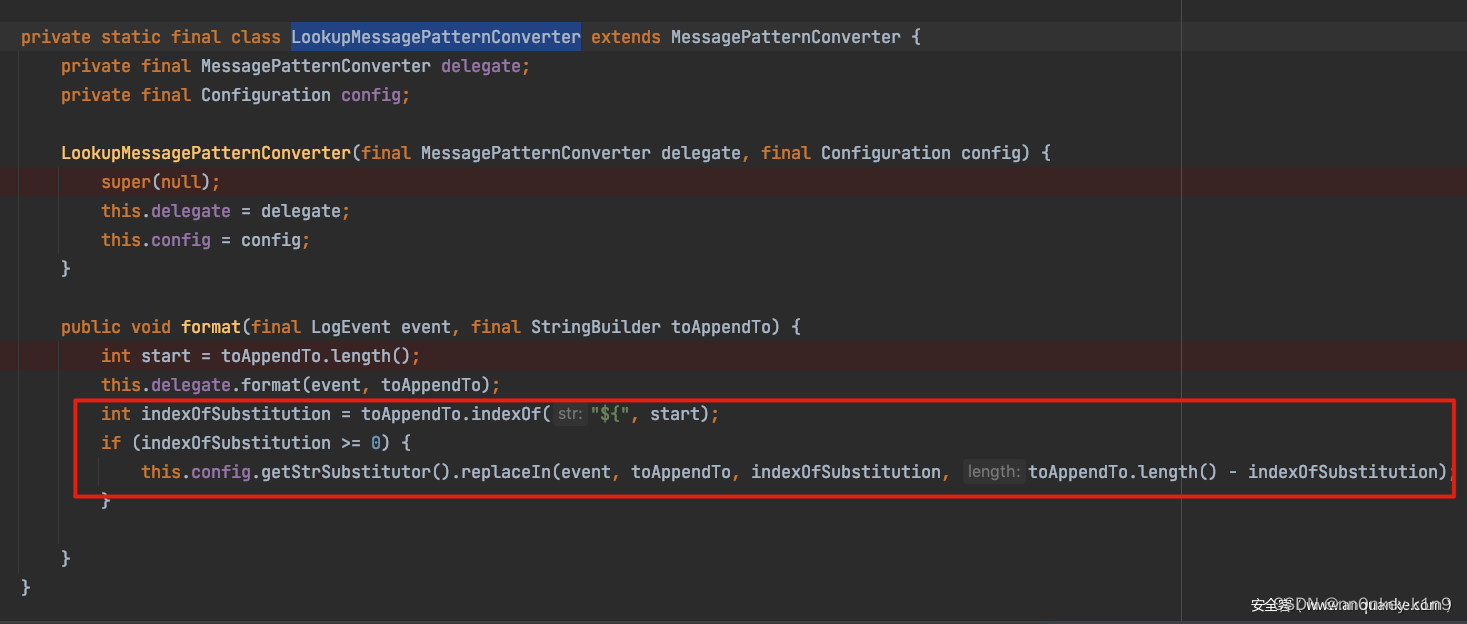
log4j漏洞学习
log4j漏洞学习 总结基础知识属性占位符之Interpolator(插值器)模式布局日志级别 Jndi RCE CVE-2021-44228环境搭建漏洞复现代码分析日志记录/触发点消息格式化 Lookup 处理JNDI 查询触发条件敏感数据带外漏洞修复MessagePatternConverter类JndiManager#l…...

架构设计 - WEB项目的基础序列化配置
摘要:web项目中做好基础架构(redis,json)的序列化配置有重要意义 支持复杂数据结构:Redis 支持多种不同的数据结构,如字符串、哈希表、列表、集合和有序集合。在将这些数据结构存储到 Redis 中时,需要将其序列化为字节…...
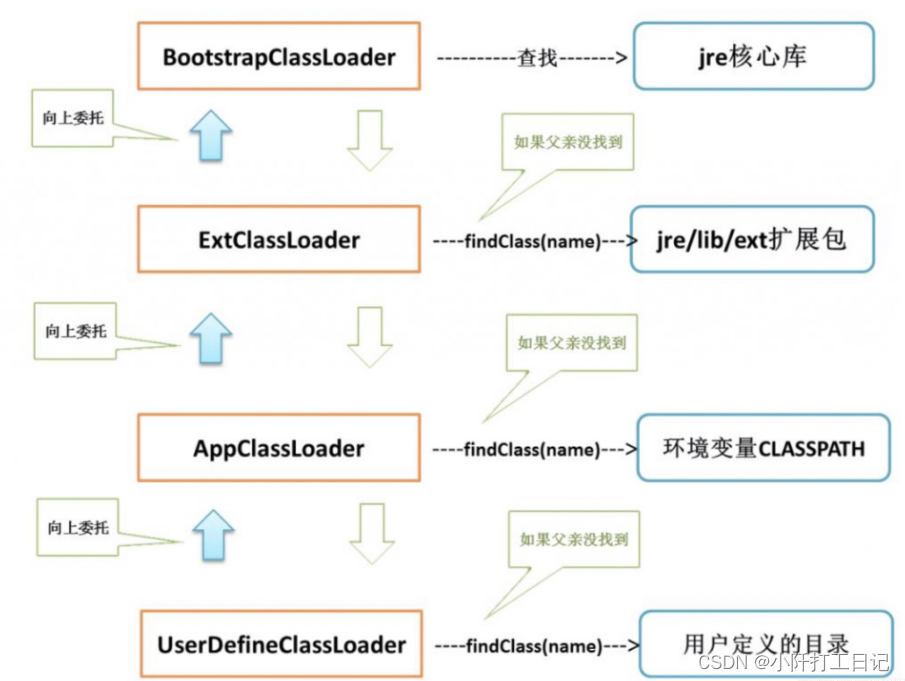
java(JVM)
JVM Java的JVM(Java虚拟机)是运行Java程序的关键部件。它不直接理解或执行Java源代码,而是与Java编译器生成的字节码(Bytecode)进行交互。下面是对Java JVM更详尽的解释: 1.字节码: 当你使用J…...

【网络安全】【深度学习】【入侵检测】SDN模拟网络入侵攻击并检测,实时检测,深度学习【二】
文章目录 1. 习惯终端2. 启动攻击3. 接受攻击4. 宿主机查看h2机器 1. 习惯终端 上次把ubuntu 22自带的终端玩没了,治好用xterm: 以通过 AltF2 然后输入 xterm 尝试打开xterm 。 然后输入这个切换默认的终端: sudo update-alternatives --co…...
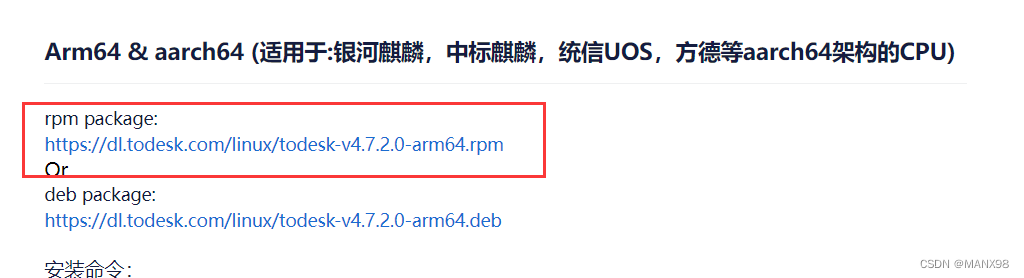
飞腾银河麒麟V10安装Todesk
下载安装包 下载地址 https://www.todesk.com/linux.html 安装 yum makecache yum install libappindicator-gtk3-devel.aarch64 rpm -ivh 下载的安装包文件后台启动 service todeskd start修改配置 编辑 /opt/todesk/config/config.ini 移除自动更新临时密码 passupda…...

JWT令牌、过滤器Filter、拦截器Interceptor
目录 JWT令牌 简介 JWT生成 解析JWT 登陆后下发令牌 过滤器(Filter) Filter快速入门 Filter拦截路径 过滤器链 登录校验Filter-流程 拦截器(Interceptor) Interceptor 快速入门 拦截路径 登录校验流程 JWT令牌 简介 全称:JSON Web Token(https://iwt.io/) …...

iText7画发票PDF——小tips
itext7教程: 1、https://blog.csdn.net/allway2/article/details/124295097 2、https://max.book118.com/html/2017/0720/123235195.shtm 3、https://www.cnblogs.com/fonks/p/15090635.html 4、https://www.cnblogs.com/sky-chen/p/13026203.html 5、官方ÿ…...

跟着刘二大人学pytorch(第---10---节课之卷积神经网络)
文章目录 0 前言0.1 课程链接:0.2 课件下载地址: 回忆卷积卷积过程(以输入为单通道、1个卷积核为例)卷积过程(以输入为3通道、1个卷积核为例)卷积过程(以输入为N通道、1个卷积核为例)…...
transformer实战
1.pipeline() 首先下载transformer,之后 from transformers import pipeline# 加载一个用于文本分类的pipeline # Use a pipeline as a high-level helperpipe pipeline("zero-shot-classification", model"https://hf-mirror.com/morit/chinese_…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

旋量理论:刚体运动的几何描述与机器人应用
旋量理论为描述刚体在三维空间中的运动提供了强大而优雅的数学框架。与传统的欧拉角或方向余弦矩阵相比,旋量理论通过螺旋运动的概念统一了旋转和平移,在机器人学、计算机图形学和多体动力学领域具有显著优势。这种描述不仅几何直观,而且计算…...