梯度提升决策树(GBDT)
GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,是一种迭代的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成思想进行了有效的结合。
原理
GBDT的核心思想是将多个弱学习器(通常是决策树)组合成一个强大的预测模型。具体而言,GBDT的定义如下:
- 初始化:首先GBDT使用一个常数(通常是目标变量的平均值,也可以是其他合适的初始值。初始预测值代表了模型对整体数据的初始估计。)作为初始预测值。这个初始预测值代表了我们对目标变量的初始猜测。
- 迭代训练:GBDT是一个迭代算法,通过多轮迭代来逐步改进模型。在每一轮迭代中,GBDT都会训练一棵新的决策树,目标是减少前一轮模型的残差(或误差)。残差是实际观测值与当前模型预测值之间的差异,新的树将学习如何纠正这些残差。
- 1)计算残差:在每轮迭代开始时,计算当前模型对训练数据的预测值与实际观测值之间的残差。这个残差代表了前一轮模型未能正确预测的部分。
- 2):训练新的决策树:使用计算得到的残差作为新的目标变量,训练一棵新的决策树。这棵树将尝试纠正前一轮模型的错误,以减少残差。
- 3):更新模型:将新训练的决策树与之前的模型进行组合。具体地,将新树的预测结果与之前模型的预测结果相加,得到更新后的模型。
- 集成:最终,GBDT将所有决策树的预测结果相加,得到最终的集成预测结果。这个过程使得模型能够捕捉数据中的复杂关系,从而提高了预测精度。
每次都以当前预测为基准,下一个弱分类器去拟合误差函数对预测值的残差(预测值与真实值之间的误差)。
GBDT的弱分类器使用的是树模型。
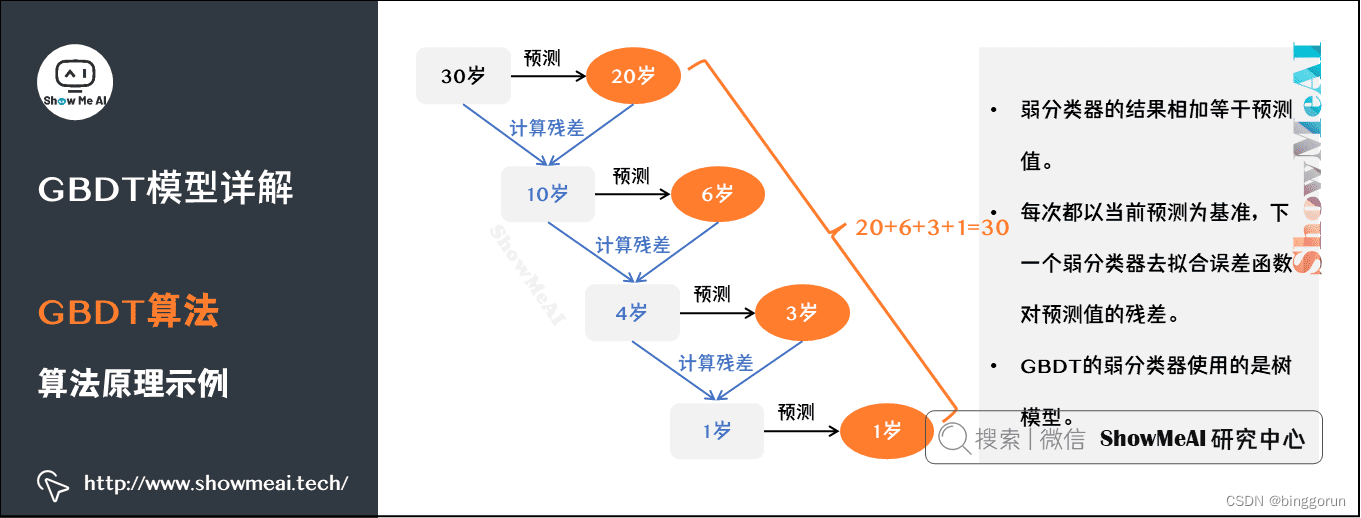
如图是一个非常简单的帮助理解的示例,我们用GBDT去预测年龄:
- 第一个弱分类器(第一棵树)预测一个年龄(如20岁),计算发现误差有10岁;
- 第二棵树预测拟合残差,预测值6,计算发现差距还有4岁;
- 第三棵树继续预测拟合残差,预测值3,发现差距只有1岁了;
- 第四课树用1岁拟合剩下的残差,完成。
最终,四棵树的结论加起来,得到30岁这个标注答案(实际工程实现里,GBDT是计算负梯度,用负梯度近似残差)。
GBDT的优势
1)高精度预测能力
GBDT以其强大的集成学习能力而闻名,能够处理复杂的非线性关系和高维数据。它通常能够在分类和回归任务中取得比单一决策树或线性模型更高的精度。
2)对各种类型数据的适应性
GBDT对不同类型的数据(数值型、类别型、文本等)具有很好的适应性,不需要对数据进行特别的预处理。这使得它在实际应用中更易于使用。
- 处理混合数据类型
在现实世界的数据挖掘任务中,常常会遇到混合数据类型的情况。例如,在房价预测问题中,特征既包括数值型(如房屋面积和卧室数量),还包括类别型(如房屋位置和建筑类型)和文本型(如房屋描述)数据。GBDT能够直接处理这些混合数据,无需将其转换成统一的格式。这简化了数据预处理的步骤,节省了建模时间。 - 不需要特征缩放
与某些机器学习算法(如支持向量机和神经网络)不同,GBDT不需要对特征进行缩放或归一化。这意味着特征的尺度差异不会影响模型的性能。在一些算法中,特征的尺度不一致可能导致模型无法正确学习,需要进行繁琐的特征缩放操作。而GBDT能够直接处理原始特征,减轻了数据预处理的负担。
3)在数据不平衡情况下的优势
- 加权损失函数
GBDT使用的损失函数允许对不同类别的样本赋予不同权重。这意味着模型可以更关注少数类别,从而提高对不平衡数据的处理能力。 - 逐步纠正错误
GBDT的迭代训练方式使其能够逐步纠正前一轮模型的错误。在处理不平衡数据时,模型通常会在多轮迭代中重点关注难以分类的少数类别样本。通过逐步纠正错误,模型逐渐提高了对少数类别的分类能力,从而改善了预测结果。
4)鲁棒性与泛化能力
GBDT在处理噪声数据和复杂问题时表现出色。其鲁棒性使得它能够有效应对数据中的异常值或噪声,不容易受到局部干扰而产生较大的预测误差。
5)特征重要性评估
GBDT可以提供有关特征重要性的信息,帮助用户理解模型的决策过程。通过分析每个特征对模型预测的贡献程度,用户可以识别出哪些特征对于问题的解决最为关键。这对于特征选择、模型解释和问题理解非常有帮助。
6)高效处理大规模数据
尽管GBDT通常是串行训练的,每棵树依赖于前一棵树的结果,但它可以高效处理大规模数据。这得益于GBDT的并行化实现和轻量级的决策树结构。此外,GBDT在处理大规模数据时可以通过特征抽样和数据抽样来加速训练过程,而不会牺牲太多预测性能。
关键参数与调优
参数解释
n_estimators:迭代次数,即最终模型中弱学习器的数量。
learning_rate(学习率):每次迭代时,新决策树对预测结果的贡献权重。
max_depth:决策树的最大深度,控制着树的复杂度。
min_samples_split:节点分裂所需的最小样本数。
subsample:用于训练每棵树的样本采样比例,小于1时可实现随机梯度提升。
loss:即我们GBDT算法中的损失函数。分类模型和回归模型的损失函数是不一样的。1)对于分类模型,有对数似然损失函数"deviance"和指数损失函数"exponential"两者输入选择。默认是对数似然损失函数"deviance"。2)对于回归模型,有均方差"ls", 绝对损失"lad", Huber损失"huber"和分位数损失“quantile”。默认是均方差"ls"。一般来说,如果数据的噪音点不多,用默认的均方差"ls"比较好。如果是噪音点较多,则推荐用抗噪音的损失函数"huber"。而如果我们需要对训练集进行分段预测的时候,则采用“quantile”。
subsample:用于训练每个弱学习器的样本比例。减小该参数可以降低方差,但也可能增加偏差。
调优策略
学习率与迭代次数的平衡:较低的学习率通常需要更多的迭代次数来达到较好的性能,但能减少过拟合的风险。
树的深度与样本采样:合理限制树的深度和采用子采样可以提高模型的泛化能力。
早停机制:在验证集上监控性能,一旦性能不再显著提升,则提前终止训练。
为了解决GBDT的效率问题,LightGBM和XGBoost等先进框架被提出,它们通过优化算法结构(如直方图近似)、并行计算等方式显著提高了训练速度。
python实现
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingRegressorGradientBoostingClassifier(*, loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None,max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated', validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)GradientBoostingRegressor(*, loss='ls', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated', validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
回归实现
# 导入必要的库
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error# 加载波士顿房价数据集
boston = load_boston()
X, y = boston.data, boston.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化GBDT回归器
gbdt_reg = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)# 训练模型
gbdt_reg.fit(X_train, y_train)# 预测
y_pred = gbdt_reg.predict(X_test)# 计算并打印均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")GBDT正则化
针对GBDT正则化,我们通过子采样比例方法和定义步长v方法来防止过拟合。
- 子采样比例:通过不放回抽样的子采样比例(subsample),取值为(0,1]。如果取值为1,则全部样本都使用。如果取值小于1,利用部分样本去做GBDT的决策树拟合。选择小于1的比例可以减少方差,防止过拟合,但是会增加样本拟合的偏差。因此取值不能太低,推荐在[0.5, 0.8]之间。
- 定义步长v:针对弱学习器的迭代,我们定义步长v,取值为(0,1]。对于同样的训练集学习效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
相关文章:
梯度提升决策树(GBDT)
GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,是一种迭代的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱的学习器(树&am…...

数据结构之B树的原理与业务场景
B树是一种自平衡的树形数据结构,它能够保持数据有序,并且可以高效地进行查找、顺序访问、插入和删除操作。B树的设计是为了优化磁盘I/O操作,因为它可以减少磁盘访问次数,这在数据库和文件系统中非常有用。 1. B树的原理 节点的出…...

【Android面试八股文】你能说一说线程池管理线程的原理吗?
面试官(Interviewer): 欢迎参加面试,今天我们会讨论一些关于 Java 线程池管理的问题。你能给我解释一下 ThreadPoolExecutor 是如何管理线程的吗? 候选人(Candidate): 当然可以,ThreadPoolExecutor 是 Java 中用于创建和管理线程池的核心类。它通过一组核心参数来控制线…...

springer 在线投稿编译踩坑
springer投稿,在线编译踩坑总结 注意: 有的期刊需要双栏,而预定义的模板中可能为单栏,需要增加iicol选项。 例如: \documentclass[sn-mathphys-num]{sn-jnl}% —>\documentclass[sn-mathphys-num, iicol]{sn-jnl}…...

固态硬盘的指标
固态硬盘的指标主要包括以下几个方面: 接口类型:这是固态硬盘与外部设备连接的方式,常见的接口类型有SATA、PCIe和NVMe等。不同的接口类型决定了固态硬盘的传输速度和性能。例如,PCIe接口的固态硬盘通常比SATA接口的固态硬盘具有…...

mysql 分组后每个取最新的一条记录
在MySQL中,若要从一个分组中获取每组的最新一条记录(通常基于时间戳或其他递增的列),可以使用子查询或者窗口函数(如果MySQL版本支持)。 以下是两种不同的实现方法: 方法1: 使用子查询和LIMIT…...

Java语法和基本结构介绍
Java语法和基本结构是Java编程的基础,它决定了Java代码的书写方式和程序的结构。以下是Java语法和基本结构的一些关键点: 1.标识符和关键字:Java中的标识符是用来标识变量、函数、类或其他用户自定义元素的名称。关键字是预留的标识符&#x…...

TDengine 3.3.0.0 引入图形化管理工具、复合主键等 13 项关键更新
在涛思数据研发团队的努力下,TDengine 3.3.0.0 版本终于和大家见面了。这一版本中,我们引入了多项革新功能和性能优化,力求在为用户提供极致体验的同时,不断推动技术的前沿。 此次更新不仅针对开源社区版本,进行了一系…...

C++基础之红黑树
二叉搜索树 二叉搜索树(Binary Search Tree,BST)是一种二叉树,具有以下性质: 左子树节点值小于根节点值:对于树中的每个节点 x,其左子树中所有节点的值都小于 x 的值。右子树节点值大于根节点值…...

ClickHouse数据库对比、适用场景与入门指南
本文全面对比了ClickHouse与其他数据库(如StarRocks、HBase、MySQL、Hive、Elasticsearch等)的性能、功能、适用场景,并提供了ClickHouse的教学入门指南,旨在帮助读者选择合适的数据库产品并快速掌握ClickHouse的使用。 文章目录 …...

举例说明 如何通过SparkUI和日志定位任务莫名失败?
有一个Task OOM: 通过概览信息,发现Stage 10的Task 36失败了4次导致Job失败。概览信息中显示最后一次失败的退出代码(exit code)是143,意味着发生了内存溢出(OOM,即Out of Memory)。…...

Vue前端通过Axios的post方式传输数据,后端为什么一直接收的值是null?
沃靠!这个细节太细了,搞了我两个多小时才找到这个bug。 一、 首先官方文档给我的post请求的例子是这样的: axios.post(/user, {firstName: Fred,lastName: Flintstone}).then(function (response) {console.log(response);}).catch(function (error) {console.log(error);})…...
外链建设如何进行?
理解dofollow和nofollow链接,所谓dofollow链接,就是可以传递权重到你的网站的链接,这种链接对你的网站排名非常有帮助,这种链接可以推动你的网站在搜索结果中的位置向上爬,但一个网站全是这种有用的链接,反…...

深入理解Java正则表达式及其应用
正则表达式是一种强大的文本匹配和处理工具,可以在字符串中查找、替换、提取符合特定模式的内容。Java作为一种广泛应用的编程语言,提供了丰富的正则表达式支持。本文将深入探讨Java正则表达式的基本概念、语法以及常见应用场景,帮助读者全面…...
Gstreamer学习3----灌数据给管线之appsrc
参考资料 Basic tutorial 8: Short-cutting the pipeline gstreamer向appsrc发送帧画面的代码_gst appsrc可变帧率-CSDN博客 在官网教程Basic tutorial 8: Short-cutting the pipeline 里面,讲了一个例子,push音频数据给管线,视频的例子更…...

【深度学习量化交易1】一个金融小白尝试量化交易的设想、畅享和遐想
关注我的朋友们可能知道,我经常在信号处理的领域出没,时不时会发一些信号处理、深度学习科普向的文章。 不过算法研究久了,总想做一些更有趣的事情。 比如用深度学习算法赚大钱。。毕竟有什么事情能比暴富更有意思呢。 一、神经网络与彩票…...
【0基础学爬虫】爬虫基础之自动化工具 DrissionPage 的使用
概述 前三期文章中已经介绍到了 Selenium 与 Playwright 、Pyppeteer 的使用方法,它们的功能都非常强大。而本期要讲的 DrissionPage 更为独特,强大,而且使用更为方便,目前检测少,强烈推荐!!&a…...
c++_0基础_讲解7 练习
这一讲我为大家准备了几道题目,大家试着独自做一下(可能来自不同网站) 整数大小比较 - 洛谷 题目描述 输入两个整数,比较它们的大小。若 x>yx>y ,输出 > ;若 xyxy ,输出 ÿ…...

docker一些常用命令以及镜像构建完后部署到K8s上
docker一些常用命令以及镜像构建完后部署到K8s上 1.创建文件夹2.删除文件3.复制现有文件内容到新建文件4.打开某个文件5.查看文件列表6.解压文件(tar格式)7.解压镜像8.查看镜像9.删除镜像10.查看容器11.删除容器12.停止运行容器13.构建镜像14.启动容器15…...

在typora中利用正则表达式,批量处理图片
一,png格式 在 Typora 中批量将 HTML 图片标签转换为简化的 Markdown 图片链接,且忽略 alt 和 style 属性,可以按照以下步骤操作: 打开 Typora 并加载你的文档。按下 Ctrl H(在 Windows/Linux 上)或 Cmd…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...
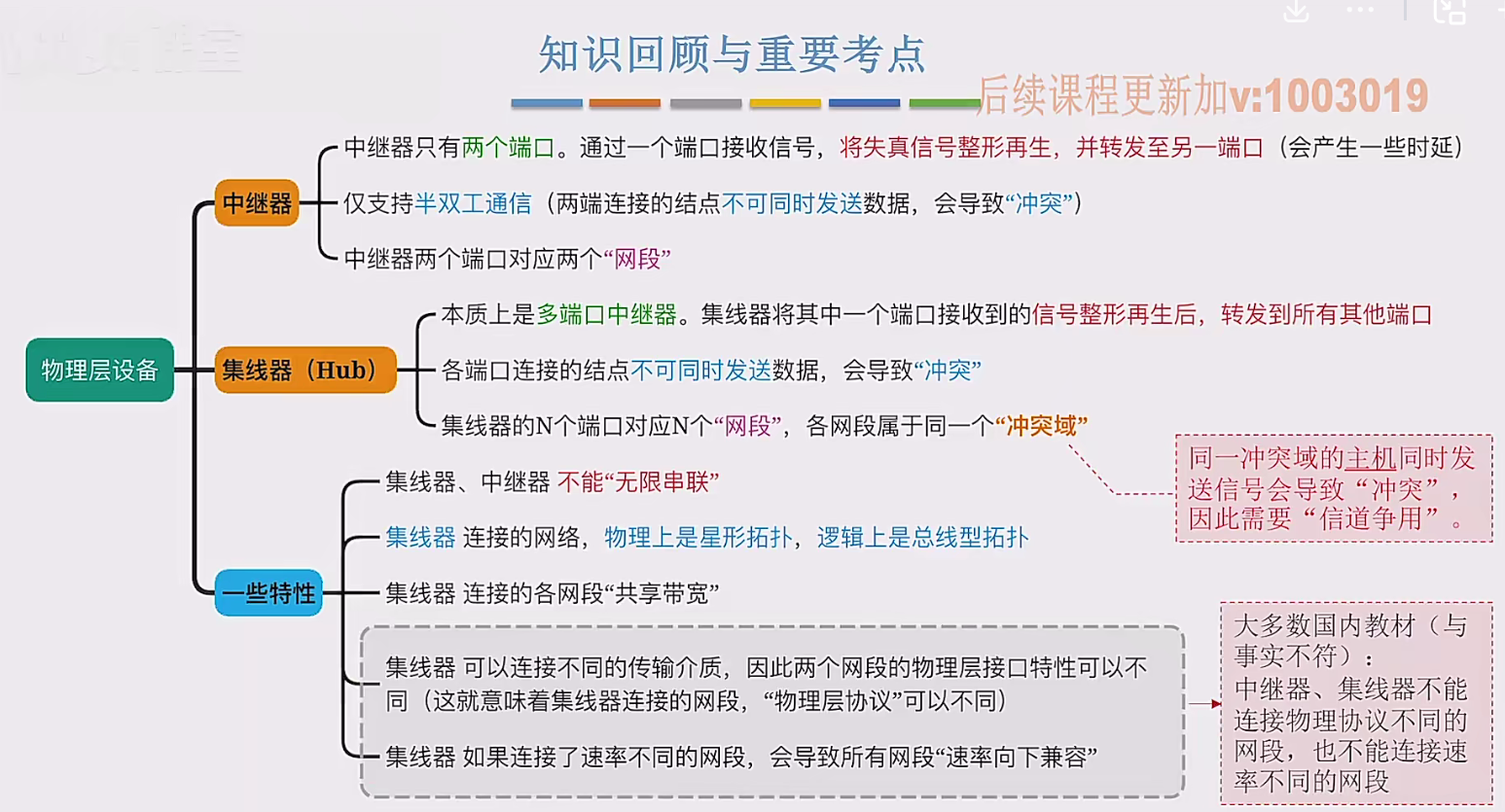
2.3 物理层设备
在这个视频中,我们要学习工作在物理层的两种网络设备,分别是中继器和集线器。首先来看中继器。在计算机网络中两个节点之间,需要通过物理传输媒体或者说物理传输介质进行连接。像同轴电缆、双绞线就是典型的传输介质,假设A节点要给…...

起重机起升机构的安全装置有哪些?
起重机起升机构的安全装置是保障吊装作业安全的关键部件,主要用于防止超载、失控、断绳等危险情况。以下是常见的安全装置及其功能和原理: 一、超载保护装置(核心安全装置) 1. 起重量限制器 功能:实时监测起升载荷&a…...

Git 命令全流程总结
以下是从初始化到版本控制、查看记录、撤回操作的 Git 命令全流程总结,按操作场景分类整理: 一、初始化与基础操作 操作命令初始化仓库git init添加所有文件到暂存区git add .提交到本地仓库git commit -m "提交描述"首次提交需配置身份git c…...

P10909 [蓝桥杯 2024 国 B] 立定跳远
# P10909 [蓝桥杯 2024 国 B] 立定跳远 ## 题目描述 在运动会上,小明从数轴的原点开始向正方向立定跳远。项目设置了 $n$ 个检查点 $a_1, a_2, \cdots , a_n$ 且 $a_i \ge a_{i−1} > 0$。小明必须先后跳跃到每个检查点上且只能跳跃到检查点上。同时࿰…...

更新 Docker 容器中的某一个文件
🔄 如何更新 Docker 容器中的某一个文件 以下是几种在 Docker 中更新单个文件的常用方法,适用于不同场景。 ✅ 方法一:使用 docker cp 拷贝文件到容器中(最简单) 🧰 命令格式: docker cp <…...