从零到一,深入浅出大语言模型的奇妙世界
2022 年底,OpenAI 发布的 ChatGPT 模型在全球范围内引起了巨大轰动。本文详细的介绍了大语言模型的发展历程、构建过程和大语言模型如何使用等知识,帮助大家搞懂大语言模型。

一、大语言模型发展历程
大模型技术并不是一蹴而就的,大语言模型发展主要经历了统计语言模型、神经语言模型、预训练语言模型等多个发展阶段。在介绍具体的发展阶段之前,我们先来了解下什么是语言模型(Language Model, LM)。
日常生活中,人与人之间主要通过语言进行表达和交流,如果我们想要使用自然语言与计算机进行沟通,并且让计算机拥有像人类一样的阅读、理解、交流和写作的能力,应该如何实现呢?语言模型就是实现机器智能的主要技术途径之一。
具体来说,语言模型通过学习和分析人类语言使用的规律,能够在给定的上下文中,准确预测下一个词语序列出现的概率。这种概率计算过程能够帮助计算机理解人类语言,进而应用到文本生成、语音识别、机器翻译等多种任务场景中。
根据所采用技术方法的不同,语言模型主要分为以下四个发展阶段。
统计语言模型(Statistical Language Model, SLM)
基于统计学习方法研发的统计语言模型,兴起于 20 世纪 90 年代。统计语言模型使用马尔可夫假设来建立语言序列的预测模型,通常是根据词序列中若干个连续的上下文单词来预测下一个词的出现概率,从而实现对自然语言的理解和生成。代表模型:N-gram。
统计语言模型被广泛应用于信息检索和自然语言处理等领域,主要用来解决以信息检索,文本分类和语音识别为主的一些传统任务。但是,统计语言模型存在严重的数据稀疏问题(在构建统计语言模型时,由于训练数据中某些词或词组出现频率非常低或根本不出现,导致这些词或词组的概率估计不准确甚至为零的问题)。
神经语言模型(Neural Language Model, NLM)
神经语言模型使用神经网络学习自然语言的概率分布,以预测下一个词的出现概率。与传统的统计语言模型相比,神经语言模型通过学习词嵌入,能够更有效地捕捉词之间的语义和语法关系,并且通过循环神经网络(RNN)、长短时记忆网络(LSTM)和门控循环单元(GRU)等技术使得模型能够更好地捕捉长距离依赖和上下文信息,可以大范围扩展语言模型可应用的任务。代表模型:BNN-LM,word2vec。
然而,神经语言模型存在计算资源需求高、训练时间长、缺乏知识和可迁移性差等问题。
预训练语言模型(Pre-trained Language Model, PLM)
预训练语言模型是一种在大规模无标注文本数据上预先训练的深度学习模型,能够理解和生成自然语言文本。
早期的预训练语言模型(例如:word2vec)主要关注于学习词嵌入,以捕捉词汇间的语义关系。2017年,谷歌提出了基于自注意力机制的 Transformer 模型,基于 Transformer 架构,以 ELMo、BERT、GPT-1 为代表的预训练语言模型在训练架构与训练数据两个方面进行了改进与创新,并确立了预训练-微调这一任务求解范式。其中,预训练阶段通过大规模无标注文本来建立模型的基础能力,微调阶段则使用有标注数据对模型进行特定任务的适配,从而更好地解决下游的自然语言处理任务。
预训练语言模型加强了语义表征的上下文感知能力,并且可以通过下游任务进行微调,能够有效提升下游任务的性能以及任务迁移能力。但是,预训练语言模型仍然存在着资源消耗大、需要监督数据微调(伦理和偏见)等问题。
Transformer 模型
Transformer 模型是由多层的多头自注意力模块堆叠而成的神经网络模型,它是自然语言处理领域的一个里程碑式的创新。Transformer 模型的核心创新在于引入了自注意力机制,这一机制使得模型能够同时考虑输入序列中所有位置的上下文信息,捕捉长距离依赖关系,从而更好的理解和生成自然语言。
原始的 Transformer 模型由编码器和解码器两个部分构成,编码器的作用是将每个输入词元都编码成一个上下文语义相关的表示向量,解码器则基于来自编码器编码后的最后一层的输出表示以及已经由模型生成的词元序列,执行后续的序列生成任务。编码器和解码器也可以独立使用(例如,基于编码器架构的 BERT 模型和解码器架构的 GPT 模型),解码器架构还可以细分为因果解码器和前缀解码器两个变种架构。
Transformer 的模型设计对于硬件非常友好,可以通过 GPU 或者 TPU 进行加速训练,这为研发大语言模型提供了可并行优化的神经网络架构,当前主流的大语言模型都是基于 Transformer 模型进行设计的。
大语言模型(Large Language Model, LLM)
经过规模扩展的预训练语言模型在解决复杂任务时表现出了与小型预训练语言模型不同的行为(扩展法则),同时展现出了一些小型预训练语言模型不具备的能力特点(涌现能力),为了区别这一能力上的差异,学术界将这些大型预训练语言模型命名为大语言模型。因此,大语言模型可以理解为在海量无标注文本数据上进行预训练得到的大型预训练语言模型。
这里涉及到了两个概念,即扩展法则和涌现能力。
扩展法则:通过规模扩展(增加模型参数规模、数据规模、计算算力),通常会带来下游任务的模型性能提升,这种通过扩展带来的性能提升通常显著高于通过改进架构、算法等方面所带来的改进,这种现象称为扩展法则。
涌现能力: 大模型具有但小模型不具有的能力,通常被称为涌现能力。大语言模型典型的涌现能力有:上下文学习、指令遵循和逐步推理。上下文学习能力指大语言模型能够识别、理解和利用文本中前后文信息,进而能够使用少样本数据解决下游任务。指令遵循能力指大语言模型能够按照自然语言指令来执行对应的任务。逐步推理能力指大语言模型可以利用思维链提示策略加强推理性能,具体来说,大语言模型可以在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更为可靠的答案。

二、大语言模型构建过程
大语言模型的训练过程可以分为预训练和指令微调与人类对齐两个阶段。
预训练是指在一个大规模、无监督的文本数据集上预先训练模型的过程,是研发大语言模型的第一个训练阶段,通过在大规模数据上进行预训练,大语言模型可以掌握较为广泛的世界知识,获得通用的语言理解与生成能力,以及解决众多下游任务的潜力。
但是由于预训练任务形式有限,经过预训练后的大语言模型更擅长于文本补全,并不适合直接解决具体的任务,为了增强模型的任务解决能力,大语言模型在预训练之后需要进行适应性微调,通常涉及两个主要步骤,即指令微调(也称为有监督微调)和对齐微调。
经历上述两个过程后,大语言模型就能够具备较好的人机交互能力,通过问答形式解决人类所提出的问题。

预训练
预训练大语言模型,需要准备大规模文本数据,并且进行严格的数据清洗,去除掉可能包含有毒有害的内容,最后将清洗后的数据进行词元化流,并且切分成批次,用于大语言模型的预训练。
准备数据
大语言模型的能力基础主要来源于预训练数据,收集高质量、多领域、多源化的训练数据可以帮助大语言模型更加全面地学习真实世界的语言与知识,从而提高其通用性和准确性。
数据来源
网页:网页中包含了丰富多样的文本内容,可以为大语言模型提供丰富的世界知识,是目前大语言模型训练语料中最主要的数据来源。使用大规模网页文本数据进行预训练,有助于大语言模型获取多样化的语言知识,并增强其自然语言理解和生成的能力。常用的网页数据集有:C4、RefinedWeb、CC-Stories。
书籍:书籍中的文本内容较为正式与详实,使用书籍数据进行预训练,能够帮助模型积累丰富的语言知识,理解语言的内在逻辑与表达习惯,提高模型捕捉文本长程依赖关系的能力。常用的书籍数据集有:BookCorpus、Project Gutenberg、arXiv Dataset、S2ORC。
代码:代码数据可以增强模型结构化语义理解与逻辑推理能力,以及生成编程语言的能力。同时,代码中的函数调用关系还有助于增强模型的工具使用与学习能力。常用代码数据集有:BigQuery、The Stack、StarCoder。
多语文本:多语言文本数据可以增强模型的多语理解与生成能力,支持跨语言理解与对话任务。多语言数据还能有效增加数据的多样性,有助于提升模型的综合性能。
数据预处理
收集了丰富的文本数据之后,为了确保数据的质量和效用,还需要对数据进行预处理,从而消除低质量、冗余、无关和有害的数据。

质量过滤
质量过滤的目的是为了去除原始数据集中的错误、不完整或无关的信息,提高数据的整体质量。目前,主要有两种数据清洗方法:基于启发式规则的方法和基于分类器的方法。
基于启发式规则的方法:通过精心设计的规则来针对地识别和剔除低质量的文本数据,不同类型的文本数据往往需要设计不同的清洗规则。常见的过滤策略有语种过滤、统计过滤和关键词过滤。
-
基于语种的过滤:过滤掉其他语言的文本数据,用于训练特定语言的大语言模型。
-
基于简单统计指标的过滤:通过分析语料中标点符号分布、符号与单词比率、句子长度等特征,构建相应的规则或阙值,来衡量文本质量,从而过滤低质量的数据。
-
基于关键词的过滤:基于要过滤的文本构建关键词集合,然后结合关键词集合,对语料中的重复文本或者一些具有攻击性、冒犯性的文本信息进行扫描过滤。
基于分类器的方法:训练用于识别数据质量的文本分类器,然后利用这个训练好的文本分类器,进行预训练语料的清洗。
总的来说,两种方法各有优劣,基于启发式规则的方法,过滤效率高,计算资源消耗较低。基于分类器的方法,过滤精确度高,需要消耗更多的计算资源。为了平衡过滤的效率与准确性,可以针对具体的数据集合灵活组合过滤策略。例如,可以先使用启发式规则对数据集进行初步筛选,排除不符合要求的数据,然后再采用分类器方法进一步精细过滤,确保最终筛选出的语料具有较好的文本质量。
敏感内容过滤
敏感内容过滤的目的是为了去除数据集中包含的非法、有毒或隐私内容的信息。
如果预训练数据中包含有毒内容,模型则可能会产生侮辱性、攻击性或其他有害的输出。过滤有毒内容,可以使用基于分类器的过滤方法,精确过滤含有有毒内容的文本。
如果训练数据中包含隐私内容,模型在输出中可能会泄露个人信息(邮箱地址、IP地址、电话号码等)。过滤隐私内容,可以使用关键字识别的启发式规则过滤方法,检测和删除数据集中的隐私内容。
数据去重
由于大语言模型具有强大的参数量和学习记忆能力,很容易习得训练数据中的重复模式,从而引发模型训练过程不稳定甚至崩溃的问题,同时也使得模型可能在生成结果时频繁输出重复数据,影响模型的性能。
一般来说,可以在句子级别、文档级别和数据集级别等多种粒度上对数据集进行去重。句子级别上,可以删除包含重复单词和短语的低质量句子。文档级别上,可以通过相关算法计算出文档的重叠比率,进而检测和删除包含相似内容的重复文档。数据集级别上,通常采用多阶段、多粒度的方式来实现高效的去重,首先针对数据集在文档级别进行去重,然后,可以进一步在句子级别实现更为精细的去重。
词元化(分词)
词元化是数据预处理中的一个关键步骤,目的是将文本数据切分成小的、有意义的、模型可识别的单元(词元),作为大语言模型的输入数据。主要有三种词元化方法:BPE 分词、WordPiece 分词和 Unigram 分词。对于大语言模型而言,选择合适的词元化方法能够显著影响模型的训练效率和最终性能。同时,针对大语言模型的某些特定能力,可以专门设计和训练定制化的分词器。
数据调度
完成数据预处理之后,需要设计合适的调度策略来安排这些多来源的数据,进而用于训练大语言模型。数据调度主要关注两个方面:各个数据源的混合比例(数据混合)和各数据源用于训练的顺序(数据课程)。
数据混合:不同数据源与大语言模型学习具备的能力具有紧密的联系,在预训练期间,将根据设置的数据混合比例从不同数据源中采样数据,数据源的权重越大,从中选择的数据就越多。
数据课程:按照特定的顺序安排预训练数据进行模型的训练。例如,从简单/通用的数据开始,逐渐引入更具挑战性/专业化的数据。
准备预训练
模型的预训练过程涉及到大量需要深入探索的经验性技术,需要考虑各种实施细节,那么该如何进行大语言模型的预训练呢?
预训练任务
在进行模型的大规模预训练时,需要设计合适的自监督预训练任务,使得模型能够从海量无标注数据中学习到广泛的语义知识与世界知识。目前,常用的预训练任务主要分为三类:语言建模、去噪自编码和混合去噪器。
语言建模任务是目前大部分大语言模型广泛采用的预训练任务,经常被应用于训练基于解码器的大语言模型。该任务的目标是估计给定文本序列中下一个词或词元的概率。
去噪自编码是另一种常见的语言模型预训练任务,该任务的核心在于在输入数据中引入“噪声”,然后让模型学习恢复原始数据。与语言建模相比,去噪自编码任务的实现更为复杂,目前完全使用去噪自编码进行预训练的大语言模型还较为有限。
混合去噪器任务是结合了上述两种方法的变体,它将语言建模和去噪自编码的目标均视为不同类型的去噪任务,进而对预训练任务进行统一建模,来增强模型的理解和生成能力。
训练优化设置
选择合适的训练优化设置,可以稳定模型的训练过程,提高模型预训练的稳定性和吞吐量。常用的模型训练优化设置有动态调整训练批次大小策略、学习率调整策略、优化器选择和稳定优化技术(梯度裁剪、训练恢复等)等。
高效训练技术
随着模型参数规模与数据规模的不断扩展,高效的模型训练技术,对于提高大语言模型的训练效率、降低资源消耗以及提高模型质量至关重要。常见的高效训练技术有 3D 并行训练、激活重计算和混合精度训练。
综合运用这些策略,不仅可以提高模型训练的稳定性和效率,缩短训练周期,还能在资源有限的情况下训练出更大、更复杂的模型,进而提升最终模型的性能。
指令微调
指令微调是指使用自然语言形式的数据对预训练后的大语言模型进行参数微调,它是增强和激活大语言模型特定能力的重要方法之一。通过使用任务输入与输出的配对数据进行模型训练,可以使语言模型掌握通过问答形式进行任务求解的能力和较强的指令遵循能力,并且能够无需下游任务的训练样本或者示例就可以解决训练中未见过的任务。
构建指令数据
构建格式化指令数据是强化大语言模型特定功能的关键步骤,一个经过格式化的指令数据通常包括任务描述(也称为指令)、任务输入-任务输出以及可选的示例。目前,主要有三种构建格式化指令数据的方法:基于现有的自然语言处理任务数据集构建、基于日常对话数据构建和基于合成数据构建。
基于现有的自然语言处理任务数据集构建:在开源的自然语言处理任务数据集合上,为数据添加人工编写的任务描述信息,扩充原始的任务数据集,从而得到可以用于指令微调的自然语言处理任务数据集。经过自然语言处理指令数据微调后,大语言模型可以学习到指令遵循的能力,进而能够解决其他未见过的自然语言处理任务。常用的自然语言处理任务数据集:P3、FLAN。
基于日常对话数据构建:将用户在日常对话中的实际需求作为任务描述(例如用户提交给 OpenAI API 的查询)和由人类标注员回答或者语言模型所生成的输出进行配对,构建指令数据。大语言模型能够从这些源自于真实应用场景、采用自然语言形式进行表达的任务描述中学习到指令遵循的能力,常用的日常对话数据集:ShareGPT、OpenAssistant、Dolly。
基于合成数据构建:借助已有的高质量指令数据作为上下文学习示例输入到大语言模型,然后运用自然语言处理技术生成新的、多样化的任务描述及对应的输入-输出数据。常用的合成数据集:Self-Instruct-52K、Alpaca-52K。
优化设置和数据组织策略
指令微调中的优化器设置、稳定优化技术(梯度裁剪)和训练技术(3D 并行训练)都与预训练阶段保持一致,可以完全沿用。除了这些优化参数的设置,指令微调过程中还需要考虑一定的数据组织形式, 从而使得模型获得更好的微调效果,一般有三种常用的数据组织策略:平衡数据分布、多阶段指令数据微调和结合预训练数据与指令微调数据。
高效模型微调
由于大语言模型参数量巨大, 进行全参数微调,需要消耗较多的算力资源,在资源有限或追求效率的情况下,可以进行参数高效微调(也称为轻量化微调)。参数高效微调可以减少需要训练的模型参数量,同时保证微调后的模型性能能够与全量微调的表现相媲美。
低稚适配(LoRA)微调方法:在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练的参数,与全参数微调相比,LoRA 微调在保证模型效果的同时,能够显著降低模型训练的成本。
人类对齐
经过大规模的预训练和有监督指令微调,大语言模型已经具备了解决各种任务的通用能力和指令遵循能力,但是还需要将大语言模型与人类的期望、需求以及价值观对齐,防止模型生成有偏见的、虚假的以及事实错误的文本内容。
现有的对齐目标一般聚焦于三个方面:有用性(大语言模型应能够提供有用的信息,正确理解上下文,准确完成任务)、诚实性(模型的输出应具备真实性和客观性,不应夸大或歪曲事实,避免产生误导性陈述)和无害性(大语言模型应避免生成可能引发潜在负面影响或危害的内容)。
基于人类反馈的强化学习算法(RLHF)
由于对齐标准难以通过形式化的优化目标进行建模,因此研究人员提出了基于人类反馈的强化学习,对大语言模型的行为进行指导。RLHF 使用收集到的人类反馈数据来指导大语言模型进行微调,从而使大语言模型在多个标准上实现与人类对齐,当前,RLHF 是实现人类对齐的主要技术途径之一。
RLHF 算法系统主要包括三个关键组成部分:需要与人类价值观对齐的模型、 基于人类反馈数据学习的奖励模型以及用于训练大语言模型的强化学习算法。RLHF 首先需要收集人类对于不同模型输出的偏好,然后使用收集到的人类反馈数据训练奖励模型, 最后基于奖励模型使用强化学习算法微调大语言模型。
三、大语言模型使用
低资源部署策略
由于大模型的参数量巨大,在解码(大语言模型针对输入内容逐个单词生成输出内容,这个过程称为解码)阶段需要占用大量的显存资源,因此在实际应用中的部署代价非常高。为了能够在资源有限的环境中使用大语言模型,通过使用模型压缩方法,能够显著减少大语言模型的显存资源占用和解码延迟。下面介绍三种常见的模型压缩方法:模型量化、模型蒸馏和模型剪枝。
模型量化:量化通常是指从浮点数到整数的映射过程。模型量化方法主要分为两大类,即量化感知训练和训练后量化,训练后量化方法会消耗更少的算力,在实践中应用更为广泛。目前比较常用的是 8 比特整数量化,即 INT8 量化,大多数情况下,INT8 权重量化可以在不显著影响模型性能的情况下,有效地减小显存占用。
模型蒸馏:将大型、复杂的模型(称为教师模型)迁移到小型、简单的模型(称为学生模型)上,从而实现复杂模型的压缩,同时尽量保持教师模型的性能。一般来说,通常会使用教师模型的输出传递模型知识,来训练学生模型。
模型剪枝:在尽可能不损失模型性能的情况下,减少模型的参数数量,从而降低模型的显存需求以及算力开销。
提示学习
如何有效地使用大语言模型解决实际任务,目前常用的方法是设计合适的提示(Prompt),通过自然语言接口与大语言模型进行交互。
基础提示
针对特定任务设计合适的任务提示,这一过程被称为“提示工程”,设计合适的任务提示需要考虑四个关键要素,即任务描述、 输入数据、上下文信息和提示策略。
任务描述指示了大语言模型应当遵循的具体指令,一个明确的任务描述应该简洁明了,直接告诉模型做什么。
输入数据指用户可以直接使用自然语言描述输入数据的内容,以便模型可以直接处理。
上下文信息指针对某些特定任务,能够以上下文信息的形式引入外部信息作为大语言模型的输入,使模型能够做出更加精准和符合情境的响应。
提示策略指如何组织上述元素来构建最终的提示,以最优方式激发模型的潜能。
上下文学习
上下文学习(ICL)使用任务描述与示例所组成的自然语言文本作为提示,能够引导大语言模型更好地解决未见过的任务。目前,上下文学习已经成为使用大语言模型解决下游任务的一种主流途径。
思维链提示
思维链提示(CoT)是一种高级提示策略,与上下文学习方法仅使用 ⟨ 输入,输出 ⟩ 二元组来构造提示不同,思维链提示使用 ⟨ 输入,思维链,输出 ⟩ 三元组来构造提示,进一步融合了中间的推理步骤加入到提示中,指导模型解决复杂的推理任务。
智能体
智能体(Agent)是一个具备环境感知、决策制定及动作执行能力的自主算法系统,包含三个基本组件:记忆组件、规划组件和执行组件,通过这些组件共同协作,智能体能够有效地感知环境、制定决策并执行规划的动作,进而完成相应任务。
记忆组件用于存储智能体与环境的历史交互记录,这些信息可以是文本、图像、声音等多种形式,记忆功能使得智能体能够基于过往经验优化未来的决策,实现所谓的“学习”效果。
规划组件负责基于当前目标和记忆中的信息,同时生成多个候选方案,并从中选择一个最佳方案用于执行。这种方法有助于提高问题解决的效率和效果,提高智能体对复杂环境的适应性和操作的可靠性。
执行组件负责执行由规划组件制定的任务解决方案。通过设置执行组件,智能体可以与外界环境进行交互,并获得实际的执行效果反馈。
虽然大语言模型智能体在自主解决复杂任务方面展现出了巨大的潜力,但是它们在实际应用中仍然面临着诸如计算资源耗费大、复杂工具使用难、真实世界使用差异等许多技术挑战。
末尾
如果本文对你有帮助的话,欢迎 点赞 + 收藏 ,非常感谢!
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
相关文章:
从零到一,深入浅出大语言模型的奇妙世界
2022 年底,OpenAI 发布的 ChatGPT 模型在全球范围内引起了巨大轰动。本文详细的介绍了大语言模型的发展历程、构建过程和大语言模型如何使用等知识,帮助大家搞懂大语言模型。 一、大语言模型发展历程 大模型技术并不是一蹴而就的,大语言模型…...

ESP8266发送WOL幻数据包实现电脑远程唤醒
计算机远程唤醒(Wake-on-LAN, WOL) 计算机远程唤醒(Wake-on-LAN,简称 WOL)是一种局域网唤醒技术,可以将局域网内处于关机或休眠状态的计算机唤醒至引导(Boot Loader)或运行状态。无…...
用一个ESP32S3-Zero把有线键盘变为无线
三脚猫最近一直琢磨,那些喜欢买剪线键盘,以及自制键盘瞎折腾的人都是怎么搞的。经过不懈努力,终于想明白除了直接的硬件一个个pin针的高低电压判断后转给蓝牙,拿到现成的古董剪线键盘还有一个方式其实是在usb host转发给蓝牙类似这…...

Redis 7.x 系列【3】多种连接方式
有道无术,术尚可求,有术无道,止于术。 本系列Redis 版本 7.2.5 源码地址:https://gitee.com/pearl-organization/study-redis-demo 文章目录 1. 概述2. Redis Cli3. 可视化管理工具3.1 Redis Insight3.2 RedisDesktopManager 4. …...

数据结构(DS)C语言版:学习笔记(4):线性表
参考教材:数据结构C语言版(严蔚敏,吴伟民编著) 工具:XMind、幕布、公式编译器 正在备考,结合自身空闲时间,不定时更新,会在里面加入一些真题帮助理解数据结构 目录 2.1线性…...

Linux 命令大全
Linux 命令大全 Linux是一个强大的操作系统,它通过命令行界面提供了丰富的功能和灵活性。了解和掌握各种Linux命令对于系统管理员和开发者来说至关重要。本文将为您提供一个全面的Linux命令大全,帮助您更好地理解和使用Linux系统。 基础命令 ls - 列出目录内容。cd - 更改当…...
[华为北向网管NCE开发教程(6)消息订阅
1.作用 之前介绍的都是我们向网管NCE发起请求获取数据,消息订阅则反过来,是网管NCE系统给我们推送信息。其原理和MQ,JMS这些差不多,这里不过多累述。 2.场景 所支持订阅的场景有如下,以告警通知为例,当我…...

2024.6.15 英语六级 经验与复盘
文章目录 英语六级 经验与复盘2024年上半年六级考试(2024 6.8 - 6.15)前情提要:经验:作文:(30min)听力:(25min)SectionC(精细阅读) (30min)SectionB(段落匹配) (15min)SectionA(选词填空) (5min / 舍弃)翻译(20min&…...

计算机专业的未来展望
身份角度一:一名曾经的计算机专业学生 作为一名曾经的计算机专业学生,我认为计算机相关专业仍然是一个值得考虑的选择。随着科技的飞速发展,计算机行业的需求只会越来越高,因此,无论是在就业前景还是个人发展方面&a…...

Shell变量的高级用法
在Shell编程中,变量的使用是至关重要的。初学者可能只使用最基本的变量赋值和调用,但Shell变量实际上有很多高级用法,可以极大地提升脚本的灵活性和效率。本文将介绍几种Shell变量的高级用法,帮助您更好地利用Shell脚本。 1. 参数…...

【Python/Pytorch - 网络模型】-- SVD算法
文章目录 文章目录 00 写在前面01 基于Pytorch版本的SVD算代码02 理论知识 00 写在前面 (1)矩阵的奇异值分解在最优化问题、特征值问题、最小二乘方问题、广义逆矩阵问题及统计学等方面都有重要应用; (2)应用&#…...
全光万兆时代来临:信而泰如何推动F5G-A(50PONFTTR)技术发展
技术背景 F5G-A(Fifth Generation Fixed Network-Advanced,第五代固定网络接入)是固定网络技术的一次重大升级,代表了光纤网络技术的最新发展。F5G-A旨在提供更高的带宽、更低的延迟、更可靠的连接以及更广泛的应用场景。 F5G-A六…...

港科夜闻 | 香港科大与香港科大(广州)合推红鸟跨校园学习计划,共享教学资源,促进港穗学生交流学习...
关注并星标 每周阅读港科夜闻 建立新视野 开启新思维 1、香港科大与香港科大(广州)合推“红鸟跨校园学习计划”,共享教学资源,促进港穗学生交流学习。香港科大与香港科大(广州)6月14日共同宣布推出“红鸟跨校园学习计划”,以进一步加强两校学…...
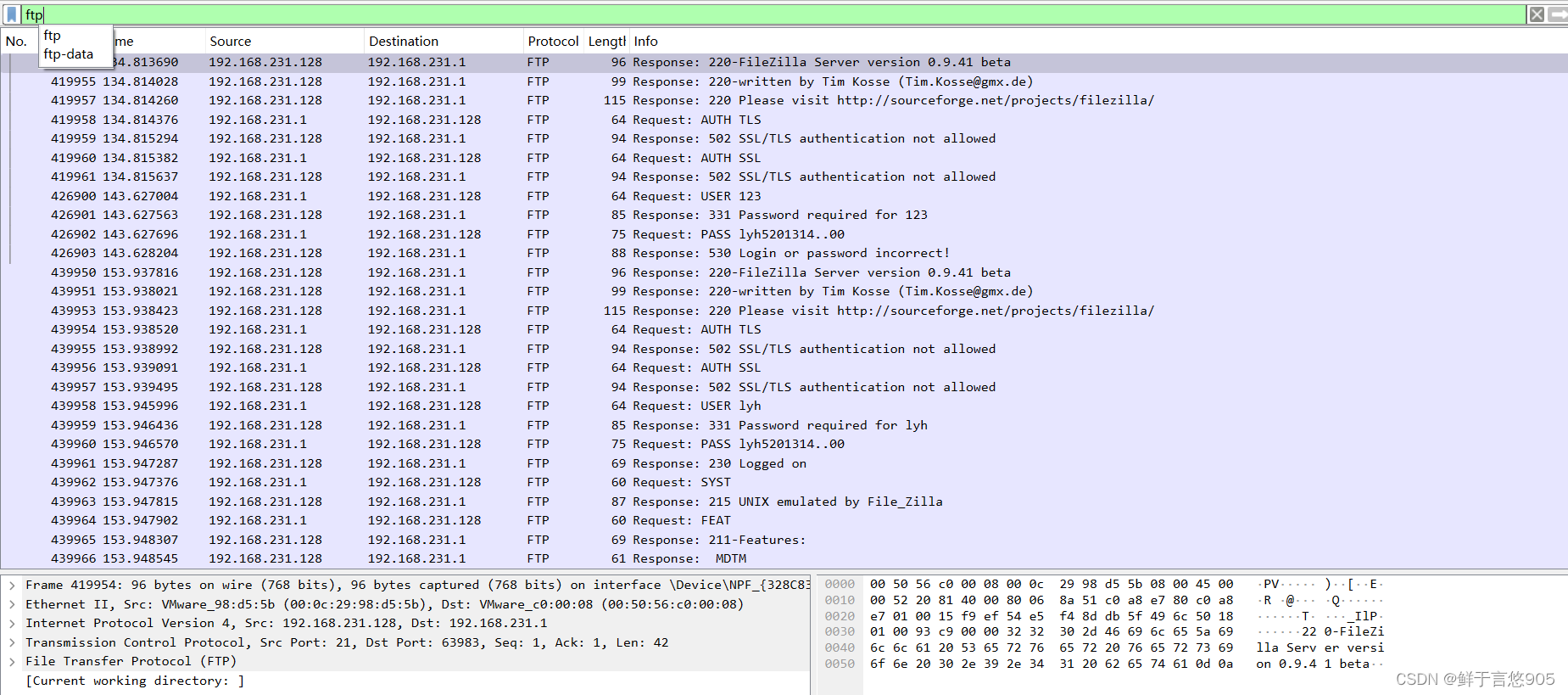
基于Wireshark实现对FTP的抓包分析
基于Wireshark实现对FTP的抓包分析 前言一、虚拟机Win10环境配置二、FileZilla客户端的安装配置下载FileZilla客户端安装FileZilla 三、FileZilla Server安装下载FileZilla Server安装 四、实现对FTP的抓包前置工作实现抓包完成抓包 前言 推荐一个网站给想要了解或者学习人工智…...

Vue54-浏览器的本地存储webStorage
一、本地存储localStorage的作用 二、本地存储的代码实现 2-1、存储数据 注意: localStorage是window上的函数,所以,可以把window.localStorage直接写成localStorage(直接调用!) 默认调了p.toString()方…...

Linux下Shell脚本基础知识
主要参考视频: 这可能是B站讲的最好的Linux Shell脚本教程,3h打通Linux-shell全套教程,从入门到精通完整版_哔哩哔哩_bilibili 主要参考文档: Shell 教程 | 菜鸟教程 (runoob.com) Bash Shell教程 (yiibai.com) 先用视频入门&…...
爬虫初学篇——看完这些还怕自己入门不了?
初次学习爬虫,知识笔记小分享 学scrapy框架可看:孤寒者博主的【Python爬虫必备—>Scrapy框架快速入门篇——上】 目录🌟 一、🍉基础知识二、🍉http协议:三、🍉解析网页(1) xpath的用…...

[数据集][目标检测]减速区域检测数据集VOC+YOLO格式1654张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1654 标注数量(xml文件个数):1654 标注数量(txt文件个数):1654 标注…...
OpenGL3.3_C++_Windows(8)
材质&&漫反射,光照贴图 使用struct为材质建立结构体,以便方便管理漫反射贴图是物体的颜色值(纹理)(通过 UV 坐标映射到渲染物体的表面),材质是物体的属性(物体对光的交互&a…...
GPU的工作原理
location: Beijing 1. why is GPU CPU的存储单元和计算单元的互通过慢直接促进了GPU的发展 先介绍一个概念:FLOPS(Floating Point Operations Per Second,浮点运算每秒)是一个衡量其执行浮点运算的能力,可以作为计算…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...

深度解析:etcd 在 Milvus 向量数据库中的关键作用
目录 🚀 深度解析:etcd 在 Milvus 向量数据库中的关键作用 💡 什么是 etcd? 🧠 Milvus 架构简介 📦 etcd 在 Milvus 中的核心作用 🔧 实际工作流程示意 ⚠️ 如果 etcd 出现问题会怎样&am…...
)
iOS 项目怎么构建稳定性保障机制?一次系统性防错经验分享(含 KeyMob 工具应用)
崩溃、内存飙升、后台任务未释放、页面卡顿、日志丢失——稳定性问题,不一定会立刻崩,但一旦积累,就是“上线后救不回来的代价”。 稳定性保障不是某个工具的功能,而是一套贯穿开发、测试、上线全流程的“观测分析防范”机制。 …...
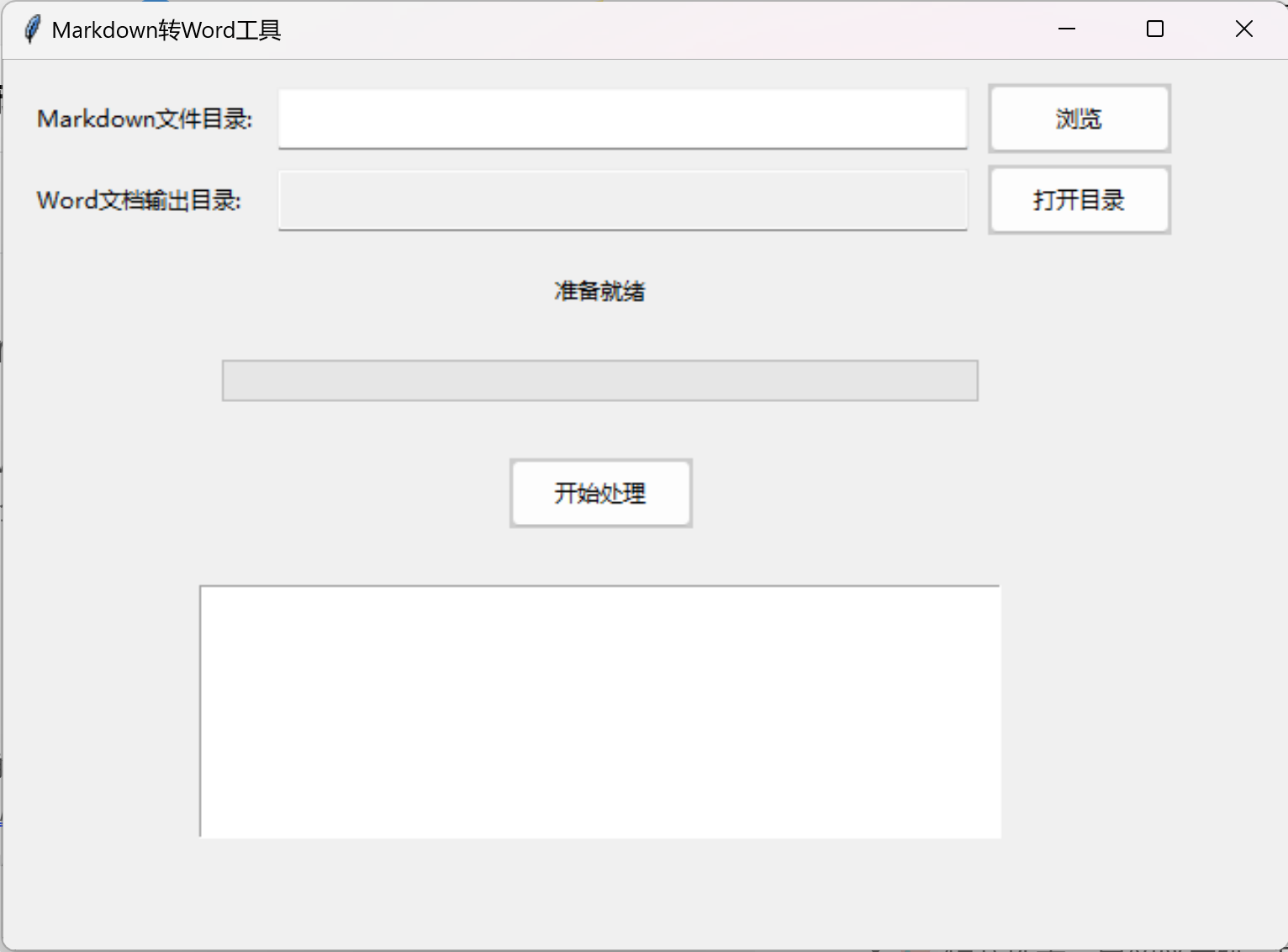
免费批量Markdown转Word工具
免费批量Markdown转Word工具 一款简单易用的批量Markdown文档转换工具,支持将多个Markdown文件一键转换为Word文档。完全免费,无需安装,解压即用! 官方网站 访问官方展示页面了解更多信息:http://mutou888.com/pro…...