数据结构(DS)C语言版:学习笔记(4):线性表
参考教材:数据结构C语言版(严蔚敏,吴伟民编著)
工具:XMind、幕布、公式编译器
正在备考,结合自身空闲时间,不定时更新,会在里面加入一些真题帮助理解数据结构
目录
2.1线性表的类型定义
2.2线性表的计算
2.3抽象数据类型线性表的定义
2.4线性表的基本操作
2.5线性表的顺序表示和实现
2.5.1顺序表中元素存储位置的计算
2.5.2顺序表的特点
2.5.3顺序表的顺序存储表示
2.5.4多项式的顺序存储结构类型定义
2.5.5类C语言有关操作的补充
2.5.6顺序表的实现方式
2.5.7顺序表基本操作的实现
(1)线性表L的初始化(参数用引用)
(2)销毁线性表L
(3)清空线性表L
(4) 求线性表L的长度
(5)判断线性表是否为空
(6)顺序表的取值(根据位置i获取相应位置数据元素的内容)
(7)线性表的查找
(8)顺序表的插入
(9)顺序表的删除
2.6顺序表的特点
2.1线性表的类型定义
线性表是最常用且最简单的一种数据结构,是一种典型的线性结构,一个线性表是n个数据元素的有限序列。
线性表:,
——
是数据元素,
是线性起点(起始结点),
是线性终点(终端结点)。
是
的直接前驱,
是
的直接后继。
n为元素总个数,即表长:线性表的长度。n = 0时为空表。
是第一个数据元素,
是最后一个数据元素,
是第i个数据元素,i为数据元素
在线性表中的位序。(位序是从1开始的,数组下标是从0开始的)
除了第一个元素外,每个元素有且仅有一个直接前趋;除了最后一个元素外,每个元素有且仅有一个直接后继。开始结点,没有直接前驱,仅有一个直接后继
;终端结点
,没有直接后继,仅有一个直接前驱
同一个线性表中的元素必定具有相同特征,数据元素之间的关系是线性关系。线性表中每个数据元素所占的空间是一样大的。
2.2线性表的计算
一元多项式的运算:实现两个多项式加、减、乘运算
把一元多项式中的每个系数拿出来,把他存成一个线性表,每一项的指数,用系数的下标来隐含的表示。此时系数的下标与指数相同P0常数项就是X的0次方,P₁就是X的一次方
线性表(每一项的指数i隐含在其系数
的序号中)
例一: ,用数组表示:
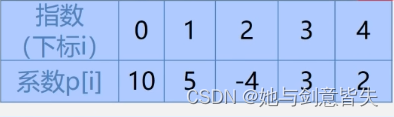
线性表
稀疏多项式:
例一:
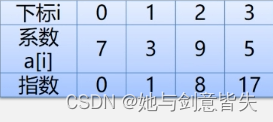

线性表
线性表A=((7,0),(3,1),(9,8),(5,17))线性表B=((8,1),(22,7),(-9,8))
求两个多项式的和:
(1)创建一个新的数组C
(2)分别从头遍历比较a和b的每一项:
指数相同:对应的系数相加,若其和不为零,则在C中增加一个新项;为零就不要了
指数不相同:将指数较小的项,复制到C中
(3)一个多项式已经遍历完毕时,将另一个剩余项依次复制到C中即可
所以,数组C:
思路:
1:首先比较线性表A(7,0)和线性表B(8,1),看它们的指数 ,一个是0一个是1,0<1,所以将线性表A的(7,0)放到数组C中(0,7)。此处线性表A(7,0)解决了,不要了。
2:因为线性表B(8,1)并没有被解决,所以接着和线性表A(3,1)比较,1=1,指数相同,系数相加3+8=11,然后放入到数组C中(1,11)。此处线性表A(3,1)和线性表B(8,1)都解决了,就不要了。
3:然后线性表A变成了(9,8)和线性表B(22,7)比较,8>7,指数不同,将线性表B(22,7)放入到数组C中(7,22)。此处数组B(22,7)解决了,不要了
4:接着看线性表A(9,8)和线性表B(-9,8),8=8,系数相加,9+(-9)=0,所以线性表A(9,8)和线性表B(-9,8)都不要了
5:此处线性表B已经没有了,线性表A还剩一项(5,17),所以直接将线性表A(5,17)复制到数组C中(17,5)
所以数组C为
顺序存储结构存在的问题:
1:存储空间不灵活 2:运算的空间复杂度高
法二:链式存储结构
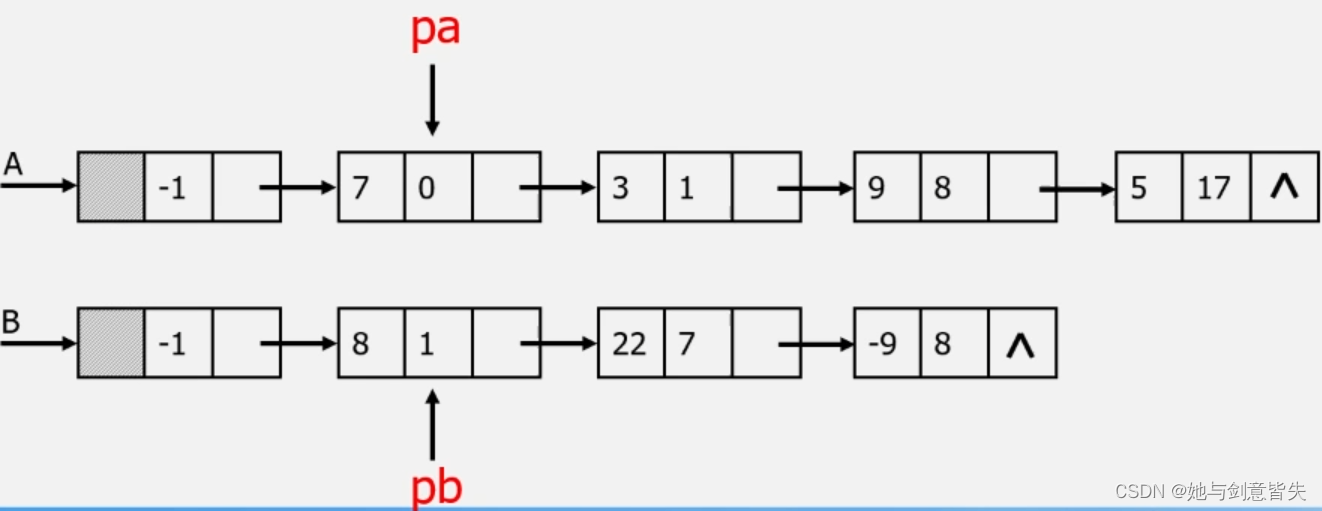 首先遍历这两个多项式,A多项式第一个系数为0,B多项式第一个系数为1,0<1,所以保留0次项
首先遍历这两个多项式,A多项式第一个系数为0,B多项式第一个系数为1,0<1,所以保留0次项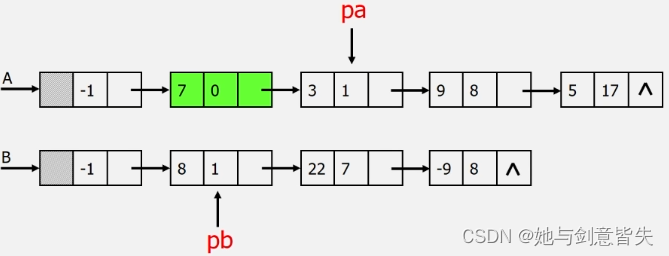
接着看A多项式第二个系数为1,B多项式第一个系数为1,1=1,然后系数相加,3+8=11
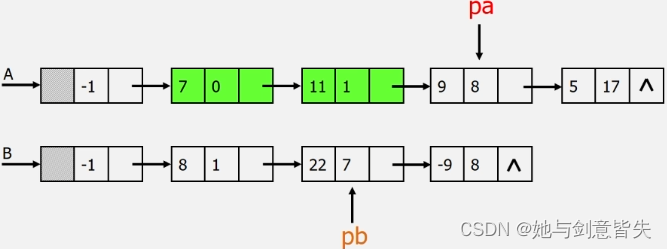
接着看A多项式第三个系数为8,B多项式第二个系数为7,7<8,所以保留这个7次项

接着看A多项式第三个系数为8,B多项式第三个系数为8,8=8,然后系数相加,9-9=0,都不要
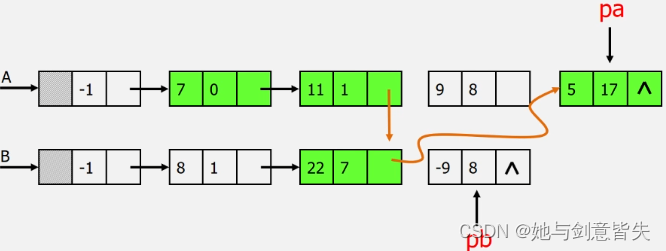
所以此方法并不需要额外空间
2.3抽象数据类型线性表的定义
ADT List{
数据对象:D = {|
∈ElemSet, i = 1,2,...,n,n≥0}
数据关系:R1 = {< ,
> |
,
∈D, i = 1,2,...,n}
基本操作:
InitList(&L)
操作结果:构造一个空的线性表L。
DestroyList(&L)
初始条件:线性表L已存在。
操作结果:将L重置为空表。
.........
}ADT List
2.4线性表的基本操作
InitList(&L) (Initialization List:初始化线性表)
操作结果:构造一个空的线性表L。(分配内存空间)
DestroyList(&L) (删除)
初始条件:线性表L已存在。
操作结果:销毁线性表L。(从内存中删除线性表,释放空间)
ClearList(&L) (重置)
初始条件:线性表L已存在。
操作结果:将L重置为空表。(内存还有,但是没有元素)
ListEmpty(L) (判断线性表是否为空表,空表n=0)
初始条件:线性表L已存在。
操作结果:若L为空表,则返回TRUE,否则返回FALSE。
ListLength(L) (求线性表的长度:线性表当中元素的个数)
初始条件:线性表L已存在。
操作结果:返回L中数据元素个数。
GetElem(L, i, &e) (获取线性表当中元素)
初始条件:线性表L已存在,1 ≤ i ≤ ListLength(L)。
操作结果:用e返回L中第i个数据元素的值。
LocateElem(L,e,compare()) (查找、定位)
初始条件:线性表L已存在,compare()是数据元素判定函数。
操作结果:返回L中第1个与e满足关系compare()的数据元素的位序。若这样的数据元素不存在,则返回值为0。
PriorElem(L,cur_e,&pre_e) (求一个元素的前趋)
初始条件:线性表L已存在。
操作结果:若cur_e是L的数据元素,且不是第一个,则用pre_e返回它的前驱,否则操作失败,pre_e无定义。
NextElem(L,cur_e,&next_e) (获取一个元素的后继)
初始条件:线性表L已存在。
操作结果:若cur_e是L的数据元素,且不是最后一个,则用next_e返回它的后继,否则操作失败,next_e无定义。
ListInsert(&L,i,e) (插入元素)
初始条件:线性表L已存在,1 ≤ i ≤ ListLength(L)+ 1。
操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1。
例:插入元素e之前(长度为n):
插入元素e之后(长度为n+1):
此处
是e的后继
ListDelete(&L,i,&e) (删除元素)
初始条件:线性表L已存在且非空,1 ≤ i ≤ ListLength(L)。
操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减1。
例:删除前(长度为n):
删除后(长度为n-1):
ListTraverse(L,visit()) (遍历线性表)
初始条件:线性表L已存在。
操作结果:依次对L的每个数据元素调用函数visit()。一旦visit()失败,则操作失败
PrintList(L):输出:按照前后顺序输出线性表L的所有元素值。
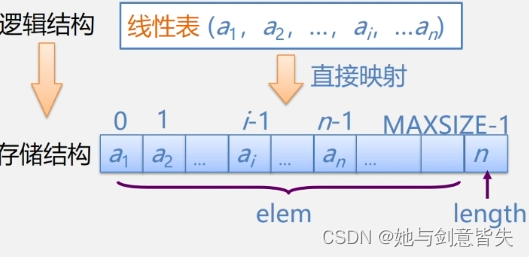
2.5线性表的顺序表示和实现
线性表的顺序表示:顺序存储结构或顺序映象。
线性表的顺序表示:指的是用同一组地址连续的存储单元依次存储线性表的数据元素。
顺序存储定义:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构。
线性表是一种逻辑结构
线性表中,第一个元素没有前驱,最后一个元素没有后继,除了第一个元素和最后一个元素,其他元素有且仅有一个前驱和一个后继。线性表中第一个数据元素a1的存储位置,称作线性表的起始位置或基地址(首地址)。
逻辑上相邻的元素,在物理位置上也是相邻的。
例如:线性表(1,2,3,4,5,6)的存储结构 是一个典型的线性表顺序存储结构。依次存储,地址连续——中间没有空出存储单元
是一个典型的线性表顺序存储结构。依次存储,地址连续——中间没有空出存储单元
 地址不连续——中间存在空的存储单元。不是一个线性表顺序存储结构。
地址不连续——中间存在空的存储单元。不是一个线性表顺序存储结构。
线性表顺序存储结构占用一片连续的存储空间。知道某个元素的存储位置就可以计算其他元素的存储位置。
2.5.1顺序表中元素存储位置的计算
例:,如果每个元素占用8个存储单元,
存储位置是2000单元,则
存储位置是?
已知每个元素占8个存储单元,所以
则是从2008开始存储的。
假设线性表的每个元素需占个存储单元,并以所占的第一个单元的存储地址作为数据元素的存储位置。则第
个数据元素的存储位置
和第
个数据元素的存储位置
之间满足关系 :
线性表的第 i 个数据元素的存储位置为:
与数学中的等差数列相似
,LOC是location的缩写。设线性表中第一个元素的存储位置是LOC(L),第二个元素的存储位置为:LOC(L)+数据元素的大小,第三个为LOC(L)+2 * 数据元素的大小
线性表顺序存储结构的图示: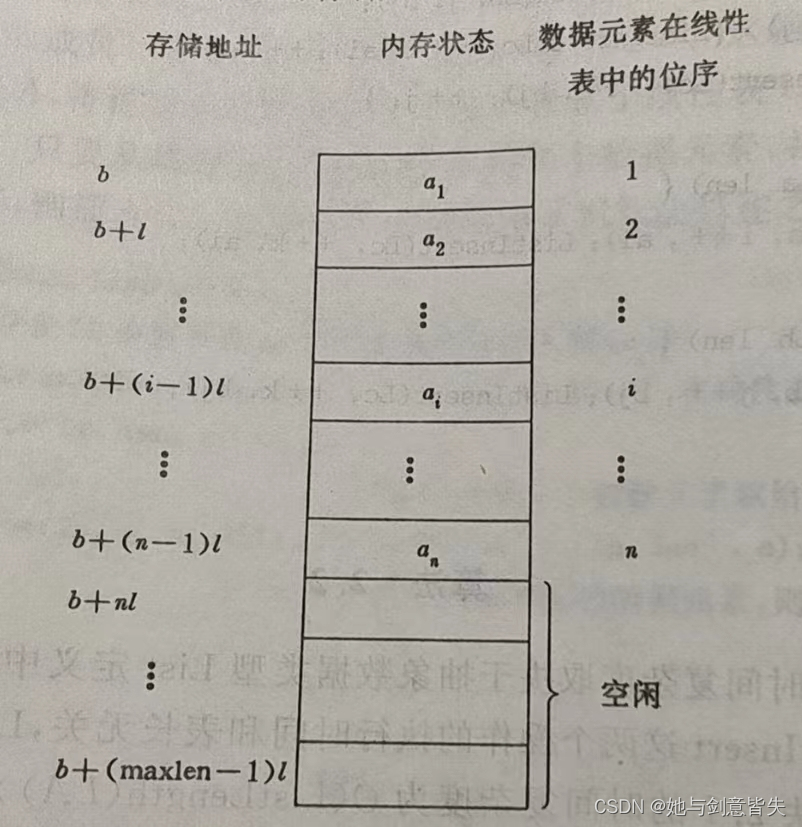
此图中的b也可以写成
2.5.2顺序表的特点
以元素在计算机内“物理位置相邻”来表示线性表中数据元素之间的逻辑关系。任意元素均可随机存取(优点)
2.5.3顺序表的顺序存储表示


线性表的长度是可以变的(删除)
一位数组的定义方式:
类型说明符 数组名[常量表达式]
说明:常量表达式中可包含常量和符号常量,不能包含变量。即C语言中不允许对数组的大小作动态定义
顺序表的定义(模版):
#define LIST_INIT_SIZE 10 //线性表存储空间的初试分配量,定义一个整型常量,值为100
typedef struct{ElemType elem[LIST_INIT_SIZE]; //用静态的“数组”存放数据元素int length; //顺序表的当前长度
}SqList; //顺序表的类型定义(静态分配方式)2.5.4多项式的顺序存储结构类型定义
线性表
#define MAXSIZE 1000 //多项式可能达到的最大长度typedef struct{ //多项式非零项的定义float p; //系数int e; //指数
}Polynomial; //Polynomial:多项式typedef struct{Polynomialp *elem; //存储空间的基地址int length; //多项式中当前项的个数
}SqList; //多项式的顺序存储结构类型为SqList
例:图书表的顺序存储结构类型定义
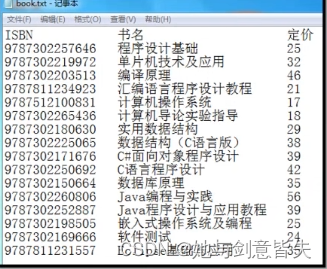
#define MAXSIZE 1000 //图书表可能达到的最大长度typedef struct{ //图书信息定义char no[20]; //图书ISBNchar name[50]; //图书名字float p; //图书价格
}Book; typedef struct{Book *elem; //存储空间的基地址int length; //图书表当前图书个数
}SqList; //图书表的顺序存储结构类型为SqList
2.5.5类C语言有关操作的补充
(一)补充:元素类型说明
顺序表类型定义:
typedef struct{ElemType data[]; int length;
}SqList; //顺序表类型ElemType可以是任意类型,也可以是自定义的结构体类型,即结构体数组 。
ElemType的含义:“数据元素的类型”,是一个抽象的概念,是表示我们所要使用的数据元素应有的类型。ElemType的默认是int型。可以用typedef重定义你想要的类型。
在C语言中,ElemType表示数据元素类型的通用数据类型,可以根据具体需要定义
例:typedef char ElemType;// 定义ElemType为char类型
typedef int ElemType;//定义ElemType为int类型
在数组中,可以用ElemType类型定义每个元素的数据类型:
typedef int ElemType; ElemType arr[10];在链表中,我们通常会定义一个节点结构,包含一个数据域和一个指向下一节点的指针。
typedef struct node{ElemType data;struct node*next; }Node;定义了一个Node的结构,其中的数据域data的类型为ElemType,表示节点存储的数据类型。
如果是一个复杂的部分:若一个元素包含两个部分,可以定义一个结构类型,它包括一个实型的系数,一个整型的指数。例:
typedef struct{ //多项式非零项的定义float p; //系数int e; //指数 }Polynomial; //Polynomial:多项式typedef struct{Polynomialp *elem; //存储空间的基地址int length; //多项式中当前项的个数 }SqList; //多项式的顺序存储结构类型为SqList*elem:代表数组elem中第一个元素的地址
SqList:Sq: sequence——顺序,序列
(二)补充:C++的动态存储分配
new 类型名T(初值列表)功能:申请用于存放T类型对象的内存空间,并依初值列表赋以初值结果值:成功:T类型的指针,指向新分配的内存失败:0(NULL)例:int *p1 = new int; 或int *p1 = new int(10);
delete 指针P
功能:释放指针P所指向的内存。P必须是new操作的返回值(三)补充:C++中的参数传递
函数调用时传送给形参表的实参必须与形参三个一致:类型、个数、顺序
参数传递的两种方式:
①:传值方式(参数为整型、实型、字符型等)
②:传地址:参数为指针变量 参数为引用类型 参数为数组名
地址也是值,只不过给了指针变量,指针变量可以指向地址值对应的存储空间。
第一种:传入&a,传入a的地址
第二种:传入a本身
第三张:数组名就是一个地址,直接传入数组名a
传值方式 :
把实参的值传送给函数局部工作区相应的副本中,函数使用这个副本执行必要的功能。函数修改的是副本的值,实参的值不变。

cin>> 对应scanf():输入a和b的值 cout<< 对应printf():输出a和b的值 endl:换行
例如:a=3,b=5,将a的值传给m,b的值传给n => m=3,n=5,
对m和n进行交换,m=5,n=3 改变了m和n 的值
传地址方式——指针变量作形参
形参变化影响实参:

*m:解引用
分析:定义了两个指针:p1和p2,p1指向a,p2指向b,然后将两个指针p1和p2作为参数,实参传递。假如a=3,b=5,p1存的a的地址,p2存的b的地址,具体多少不知道,所以画一个箭头表示指向它
这就是指针的由来,存放地址的变量叫指针。然后开始调用函数,将p1和p2作为参数传递,把p1的值传给了m,p2的值传给n。因为p1的值是a 的地址,所以m也存放a的地址,也指向a。p2里面存放的是b的地址,所以n里面也存放b的地址,也指向b。定义了一个实型变量,交换的是他们的内容,此处的*m是运算是取指针变量的内容,m指针变量的内容就是a的这个变量,交换的是m指针所指的变量和n指针所指的这个变量。交换了a变量和b变量的值,所以a变成了5,b变成了3。交换完成,函数执行完毕,形参被释放,m和n就没有了,执行完返回调用的地方,输出a和b的值,此处a和b的值发生了变化!
形参变化不影响实参:

分析:a和m指向一个地方,b和n指向一个地方,交换mn和ab无关。这里是将声明的局部变量指针m、n的地址进行了交换,而并没有将真正的指针p1、p2进行交换。m、n释放掉后就没得了,所以实质上a和b的值压根没有任何变化。
传地址方式——数组名作参数
传递的是数组的首地址,对形参数组所做的任何改变都将反映到实参数组中。

传地址方式——引用类型作参数
引用:用来给一个对象提供一个替代的名字。

j是一个引用类型,代表i的一个替代名。i值改变时,j值也跟着改变,所以会输出i=7,j=7。
对引用的理解:i是你的本名,j是你的小名,所以对i(本名)的操作和对j(小名)的操作相同。
在C是取地址符,在C++是引用替代名字,在数据结构是返回参数。

右边代码的意思是这个函数传入了什么,左边这个代码的意思是这个函数内部发生了什么。有个比较形象的比喻:a就是一个人的名字,而m就是他的小名 。
分析:在实参里面输入了ab,定义了两个引用型的,m是对a的引用,n是对b的引用。m和a用的是同一块空间;n和b用的是同一块空间。所以对m的任何操作实际上都是对a的操作。此处交换了m和n的值,实际上也就是交换了a和b的值。对mn的操作就相当于:对形参的操作相当于对实参的操作。
引用类型作形参的三点说明:
(1)传递引用给函数与传递指针的效果是一样的,形参变化实参也发生变化
(2)引用类型作形参,在内存中并没有产生实参的副本,它直接对实参操作。而一般变量作参数,形参与实参就占用不同的存储单元,所以形参变量的值是实参变量的副本。因此,当参数传递的数据量较大时,用引用比用一般变量传递参数的时间和空间效率都好。
(3)指针参数虽然也能达到与使用引用的效果,但在被调函数中需要重复使用“*指针变量名”的形式进行运算,这很容易产生错误且程序的阅读性差;另一方面,在主调函数的调用点处,必须用变量的地址作为实参。
这个 * 代表 解引用操作!也就是地址中存储的值。
单独的星号加指针变量名本质是内容值,而类型名加星号加指针变量名本质是地址。
引用不是指针常量,指针常量本身还要占用空间,引用没有。
2.5.6顺序表的实现方式
逻辑位序和物理位序相差1
(一)静态分配:
#define MaxSize 10 //定义最大长度
typedef struct{ElemType data[MaxSize]; //用静态的“数组”存放数据元素int length; //顺序表的当前长度
}SqList; //顺序表的类型定义(静态分配方式)存储空间是静态的,顺序表的表长一旦确定无法修改,所以数组满了直接放弃。
(二)动态分配:
#define MaxSize 10 //顺序表的初始长度
typedef struct{ElemType *data; //指示动态分配数组的指针int MaxSize //顺序表的最大容量int length; //顺序表的当前长度
}SeqList; //顺序表的类型定义(动态分配方式)data[MaxSize]和*data都是定义一个数组,data[MaxSize]是静态分配,*data是动态分配
data[MaxSize这里的data有三种意思:首地址,地址常量,&data【0】
当我们访问第一个元素时可以使用:a[0],也可以使用*a或者*(a+0)
数组名是指针变量,指针是地址,指针变量是存放指针的空间,数组名存放的是数组地址。
此处data的内存大小为:
SqList L; L.data=(ElemType*)malloc(sizeof(ElemType)*MaxSize);第一个是*指针,指的是首地址。第二个*不是指针,是相乘,意思是分配MaxSize个ElemType类型的空间
由于malloc返回的是void*,所以需要强制转换才行。(ElemType*):强制类型转换,表示强制转换为一个指向ElemType形的指针
(一)malloc(m)函数:开辟m字节长度的地址空间,并返回这段空间的首地址。
malloc函数会申请一整片连续的存储空间。,malloc函数返回一个指针,需要强制转换为你定义的数组元素类型指针。malloc函数的参数,指明要分配多大的连续内存空间。
(二)sizeof(x)运算:计算变量x的长度。
(三)free(p)函数:释放指针p所指变量的存储空间,即彻底删除一个变量。
free释放的是空间而不是释放指针,因此释放空间后还需要将指针置为NULL
动态开辟的空间记得free
需要加载头文件:<stdlib.h>
C 的初始动态分配语句为:
L.data=(ElemType*)malloc(sizeof(ElemType)*Initsize);C++的初始动态分配语句为:
L.data=new ElemType[InitSize];注:动态分配并不是链式存储,它同样属于顺序存储结构,物理结构没有变化,依然是随机存取方式,只是分配的空间大小可以在运行时动态决定。
顺序表示意图:

SqList L; //定义变量L,L是SqList这种类型的,L是个顺序表
例如:int a; //定义变量a,a是int型
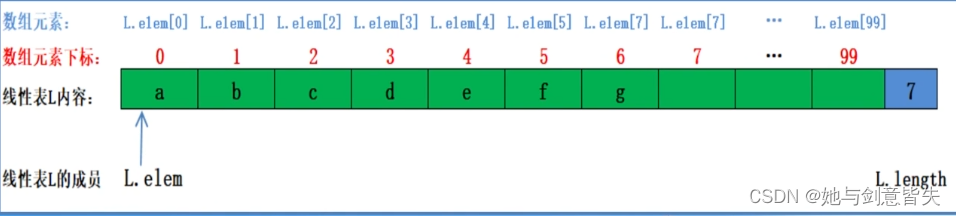
定义变量L,改变成员变量:L.length
L是指针时(*L)改变成员变量用L->length
这里如果换成了*L,要用malloc分配一下这个结构体的空间
注意L->elem=(*L).elem
2.5.7顺序表基本操作的实现
线性表的基本操作:

补充:操作算法中用到的预定义常量和类型
//函数结果状态代码
#define TURE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
//Status是函数的类型,其值是函数结果状态的代码
typedef int Status;
typedef char ElemType;(1)线性表L的初始化(参数用引用)
Status InitList_Sq(SqList &L){ //构造一个空的顺序表LL.elem=new ElemType[MAXSIZE]; //为顺序表分配空间if(!L.elem) exit(OVERFLOW);//存储分配失败L.length=0; //空表长度为0return Ok;
}new表示动态分配空间,即空间可伸缩
这个函数是初始化线性表,1.给数组分配空间,并检测分配是否成功 2.为长度赋值为0
if(!L.elem):这是一个条件语句,检查线性表L中的elem’成员是否为NULL或者未分配。’!是逻辑非运算符,所以’!L.elem”的意思是如果L.elem'为NULL或者未分配,条件成立。
c的写法是(elem type*)malloc(sizeof(elemtype)*maxsize;
(2)销毁线性表L
void DestroyList(SqList &L){if(L.elem) delete L.elem;//释放存储空间
}销毁:从内存中将L占用的空间释放
前提条件:有空间才才释放,没有空间不需要释放
if(L.elem) delete L.elem:如果这个线性表存在,然后将他删除掉,线性表L将不再存在。
(3)清空线性表L
vold ClearList(SqList &L){L.length=0; //将线性表的长度置为0
}这个就属于逻辑上的清空,让之前的数据找不到了就叫做清空。
逻辑清空,假装已经清空了,只要把长度变成0,那么后面的访问超出范围就会主动拒绝掉。
(4) 求线性表L的长度
int GetLength(SqList L){return (L.length);
}这里可以加&,这样当列表很大时可以节约开辟副本的时间和空间。
(5)判断线性表是否为空
int IsEmpty(SqList L){
if (L.length==0) return 1;
else return 0;
}if (L.length==0):判断线性表是否为空,如果是空的则返回1,不是空的返回0
(6)顺序表的取值(根据位置i获取相应位置数据元素的内容)
int GetElem(SqList L,int i,ElemType &e){if (i<1||i>L.length) return ERROR;//判断i值是否合理,若不合理,返回ERRORe=L.elem[i-1];//第i-1的单元存储着第i个数据return Ok;
}不引用是因为,不需要修改,牢记一点:是否需要对这个数据进行修改?不需要修改那么不需要引用。
只要记住,引用&的目的是修改这个数据,不修改就不引用,这个要点可以解答你所有有关“为什么&,为什么不&”的问题
i是需要获取第i个元素,e代表要取出的元素,这里用&引用直接会修改传入的变量e
这里i是位序,逻辑位序,物理位序的话是数组的下标,差了1,所以逻辑上的i,实际上是数组里的i-1
判断里是逻辑序号1,2,...,length, e的赋值语句里是物理序号0,1,,...,length-1,也可以把判断换成i<0||i>L.length-1
因为每个语句只执行一次,此处的时间复杂度为常量阶:O(1)
线性表的常用的两种储存结构:顺序存储结构(顺序表)和链式存储结构(链表)
(7)线性表的查找
1:在线性表L中查找与指定值e相同的数据元素的位置
2:从表的一端开始,逐个进行记录的关键字和给定值的比较。如果找到,返回该元素的位置序号,未找到,返回0。
int LocateELem(SqList L, ElemType e){
//在线性表L中查找值为e的数据元素,返回其序号(是第几个元素)for (i=0;i< L.length;i++)if(L.elem[i]==e) return i+1; //查找成功,返回序号return 0; //查找失败,返回0
}这里面elem如果是自定义类型,是不可以做相等判断的,需要重载==
l.length就是元素的个数,因为下标从0开始,所以i=0,从0开始查找
i是对比数组里下标为i的数,数组的实际使用个数=l.length,但是下标是length-1.
此算法的执行次数最多的语句是: if(L.elem[i]==e) return i+1; 时间复杂度:O(n)
int LocateELem(SqList L, ElemType e){
//在线性表L中查找值为e的数据元素,返回其序号(是第几个元素)while (i< L.length&&L.elem[i]!=e) i++;if(i<L.length) return i+1; //查找成功,返回序号return 0; //查找失败,返回0
}顺序表的查找分析:
因为查找算法的基本操作为:将记录的关键字同给定值进行比较
基本操作:L.elem[i] == e

比较次数,e=a,1次;e=b,2次;e=c,3次;......,e=g,7次
平均查找次数:(1+2+3+4+5+6+7)/7 =4次 (首相加末项)/2=(1+7)/2
最好情况:查找的元素就在表头,仅需比较一次,时间复杂度为O(1)。
最坏情况:查找的元素在表尾(或不存在)时,需要比较n次,时间复杂度为O(n)
平均查找长度ASL(Average Search Length)
为确定记录在表中的位置,需要与给定值进行比较的关键字的个数的期望值叫做查找算法的平均查找长度。
对含有n个记录的表,查找成功时:
Pi:第i个记录被查找的概率 Ci:找到第i个记录需比较的的次数
顺序查找的平均查找长度:
假设每个记录的查找概率相等:则


假如
,则
(8)顺序表的插入
线性表的插入运算是指在表的第 i (1≤i<n(L.length)+1)个位置上,插入一个新结点(元素) e,使长度为n(L.length)的线性表(a1,… ai -1,ai,… an)变成长度为n+1(L.length+1) 的线性表(a1, .. ai -1,e, ai,an)。
算法思想:①判断插入位置i 是否合法。
②判断顺序表的存储空间是否已满,若已满返回ERROR。 ③将第n至第ì 位的元素依次向后移动一个位置,空出第i个位置 ④将要插入的新元素e放入第i个位置。 ⑤表长加1,插入成功返回OK。
Status ListInsert_Sq(SqList &L,int i ,ElemType e){if(i < 1 || i > L.Length+1)return ERROR; //i值不合法if(L.length == MAXSIZE) return ERROR; //当前存储空间已满for(j = L.length-1; j >= i-1; j--)L.elem[j+1]=L.elem[j]; //插入位置及之后的元素后移L.elem[i-1]=e; //将新元素e放入第i个位置L.length++; //表长增1return OK;
}
if(i < 1 || i > L.Length+1)return ERROR:判断i的范围是否有效,i只能在1~L.length+1的范围,如果i不在规定范围:i<1或i > L.Length+1,则返回error。注意:这里的i是位序 不是组数下标!
if(L.length == MAXSIZE) return ERROR:判断当前的存储空间是否已满,L.length == MAXSIZE:当前存储空间已满,不能插入,则返回error
for(j = L.length-1; j >= i-1; j--)
L.elem[j+1]=L.elem[j]; :j是数组下标,将第i个元素及之后的元素后移,将下标为j的元素放入到j+1p要小于等于n+1就是只能紧贴着原数组的最后一个元素去插入,因为线性表规定所有元素必须紧挨在一起,不能出现空一个的情况
算法时间主要耗费在移动元素的操作上:
若插入在尾结点之后,则根本无需移动(特别快); 时间复杂度:O(1)
若插入在首结点之前,则表中元素全部后移(特别慢); 时间复杂度:O(n)
若要考虑在各种位置插入(共n+1种可能)的平均移动次数,该如何计算?

i+x=n+1,x=n+1-i i是第几个位置,x是移动次数
i~n总共移动x次,也就是总共x个元素,移动后i~n下标变成i+1~n+1,所以前面i个元素与后面x个元素的和为n+1。
i是位序(插到第几位),n是下标,x是移动次数,例:数组有5个元素,把新元素添插在最后就是第6;代入公式:6+0=5+1。
再来一个理解方法:n+1是插入新元素数组的最后一个位置,i是插入元素的位置,移动次数就是[最后-当前]=[n+1-i]
设pi代表在第i个位置上插入一个结点的概率,那么pi=1/(n+1),所以在长度为n个结点的顺序表中插入结点时所需要移动的平均次数可以这样表示·:

顺序表插入算法的平均时间复杂度:O(n)

插入不同位置的算法演示:
插入位置在最后:![]()
插入位置在中间:![]()
实际操作的时候, 先判断数组是否满, 满就返回错误。然后如果是在中间插入, 当然需要挪元素, 需要挪最后一个元素,最后一个元素的位序是 length-1 , 然后挪到length的位置
插入位置在最前面: ![]()
可以遍历整一个逆序的数组,然后在最后面插入一个元素,然后再遍历逆序一下,回到原来的数组
(9)顺序表的删除
线性表的删除运算是指将表的第 i (1 ≤ i ≤ n(L.length) )个结点删除
使长度为n 的线性表
变成长度为n-1的线性表
算法思想:
①判断删除位置i 是否合法(合法值为1≤i≤n)。不合法则返回ERROR ②将欲删除的元素保留在e中。
③将第i+1至第n 位的元素依次向前移动一个位置。
④表长减1,删除成功返回OK。
Status ListDelete_Sq(SqList &L,int i){if((i < 1)||(i > L.length)) return ERROR; //i值不合法for (j = i;j <= L.length-1; j+ +) L.elem[j-1 ]= L.elem[j]; //被删除元素之后的元素前移 L.length- -; //表长减1return OK;
}Status ListDelete_Sq(SqList &L,int i):在线性表L上面删除第i个位置上的元素,删除的结果仍由线性表L保存
if((i < 1)||(i > L.length)) return ERROR:判断删除位置是否合法,如果是小于1或大于L.length,则不合法,返回ERROR,位置合法,进行下一步。L.length就是元素的个数。
for (j = i;j <= L.length-1; j+ +) :从删除的元素i的后继开始,一直到最后一个元素L.length。 L.length个元素在L.length-1的位置存储。
L.elem[j-1 ]= L.elem[j]:将后面一个元素,赋值到前一个位置
i理解为位置,j是下标,i位置是(1~n),j对应下标是(0~n-1),所以删第i个位置就是删下标i-1。这里是j等于i,是指位置序号,不是数组下标
这里包括前面的代码都是删除指定位置的元素而不是指定索引的元素。
算法时间主要耗费在移动元素的操作上:
若删除尾结点,则根本无需移动(特别快); 时间复杂度:O(1)
若删除首结点,则表中n-1个元素全部前移(特别慢); 时间复杂度:O(n) 若要考虑在各种位置删除(共n种可能)的平均移动次数,该如何计算?

i=1,2,3,...,n x(次数)=n-1,n-2,...,0 i和x的关系:n-i
将移动次数相加:((n-1) + (n-2)+...+(0)) / n
顺序表删除算法的平均时间复杂度为O(n)
2.6顺序表的特点
(1)利用数据元素的存储位置表示线性表中相邻数据元素之间的前后关系,即线性表的逻辑结构与存储结构一致。
(2)在访问线性表时,可以快速地计算出任何一个数据元素的存储地址。因此可以粗略地认为,访问每个元素所花时间相等。
这种存取元素的方法被称为随机存取法。
时间复杂度:查找、插入、删除算法的平均时间复杂度为O(n)
空间复杂度:顺序表操作算法的空间复杂度S(n) = O(1) (没有占用辅助空间)
顺序表的优缺点:
- 优点:
- 存储密度大(结点本身所占存储量 / 结点结构所占存储量)
- 可以随机存取表中任一元素
结点本身所占存储量 / 结点结构所占存储量 = 1 是密度最大的情况
这里的存储密度应该是指:而顺序表是不用存放别的东西,比如说地址、前驱、后继之类的,它的整个存储空间(指存放这个数据)就只用存放数据,所以因为只用存放数据,不用存放别的,所以存储密度大,达到了1。但是在整个顺序表中为了存放所有的元素令他不会溢出,我们设定的这个数组往往很大,所以整个空间是需要多的。这是存储空间的浪费
- 缺点:
- 在插入、删除某一元素时,需要移动大量元素
- 浪费存储空间
- 属于静态存储形式,数据元素的个数不能自由扩充
通过链表可以克服顺序表的缺点 。
相关文章:
数据结构(DS)C语言版:学习笔记(4):线性表
参考教材:数据结构C语言版(严蔚敏,吴伟民编著) 工具:XMind、幕布、公式编译器 正在备考,结合自身空闲时间,不定时更新,会在里面加入一些真题帮助理解数据结构 目录 2.1线性…...

Linux 命令大全
Linux 命令大全 Linux是一个强大的操作系统,它通过命令行界面提供了丰富的功能和灵活性。了解和掌握各种Linux命令对于系统管理员和开发者来说至关重要。本文将为您提供一个全面的Linux命令大全,帮助您更好地理解和使用Linux系统。 基础命令 ls - 列出目录内容。cd - 更改当…...
[华为北向网管NCE开发教程(6)消息订阅
1.作用 之前介绍的都是我们向网管NCE发起请求获取数据,消息订阅则反过来,是网管NCE系统给我们推送信息。其原理和MQ,JMS这些差不多,这里不过多累述。 2.场景 所支持订阅的场景有如下,以告警通知为例,当我…...

2024.6.15 英语六级 经验与复盘
文章目录 英语六级 经验与复盘2024年上半年六级考试(2024 6.8 - 6.15)前情提要:经验:作文:(30min)听力:(25min)SectionC(精细阅读) (30min)SectionB(段落匹配) (15min)SectionA(选词填空) (5min / 舍弃)翻译(20min&…...

计算机专业的未来展望
身份角度一:一名曾经的计算机专业学生 作为一名曾经的计算机专业学生,我认为计算机相关专业仍然是一个值得考虑的选择。随着科技的飞速发展,计算机行业的需求只会越来越高,因此,无论是在就业前景还是个人发展方面&a…...

Shell变量的高级用法
在Shell编程中,变量的使用是至关重要的。初学者可能只使用最基本的变量赋值和调用,但Shell变量实际上有很多高级用法,可以极大地提升脚本的灵活性和效率。本文将介绍几种Shell变量的高级用法,帮助您更好地利用Shell脚本。 1. 参数…...

【Python/Pytorch - 网络模型】-- SVD算法
文章目录 文章目录 00 写在前面01 基于Pytorch版本的SVD算代码02 理论知识 00 写在前面 (1)矩阵的奇异值分解在最优化问题、特征值问题、最小二乘方问题、广义逆矩阵问题及统计学等方面都有重要应用; (2)应用&#…...
全光万兆时代来临:信而泰如何推动F5G-A(50PONFTTR)技术发展
技术背景 F5G-A(Fifth Generation Fixed Network-Advanced,第五代固定网络接入)是固定网络技术的一次重大升级,代表了光纤网络技术的最新发展。F5G-A旨在提供更高的带宽、更低的延迟、更可靠的连接以及更广泛的应用场景。 F5G-A六…...

港科夜闻 | 香港科大与香港科大(广州)合推红鸟跨校园学习计划,共享教学资源,促进港穗学生交流学习...
关注并星标 每周阅读港科夜闻 建立新视野 开启新思维 1、香港科大与香港科大(广州)合推“红鸟跨校园学习计划”,共享教学资源,促进港穗学生交流学习。香港科大与香港科大(广州)6月14日共同宣布推出“红鸟跨校园学习计划”,以进一步加强两校学…...
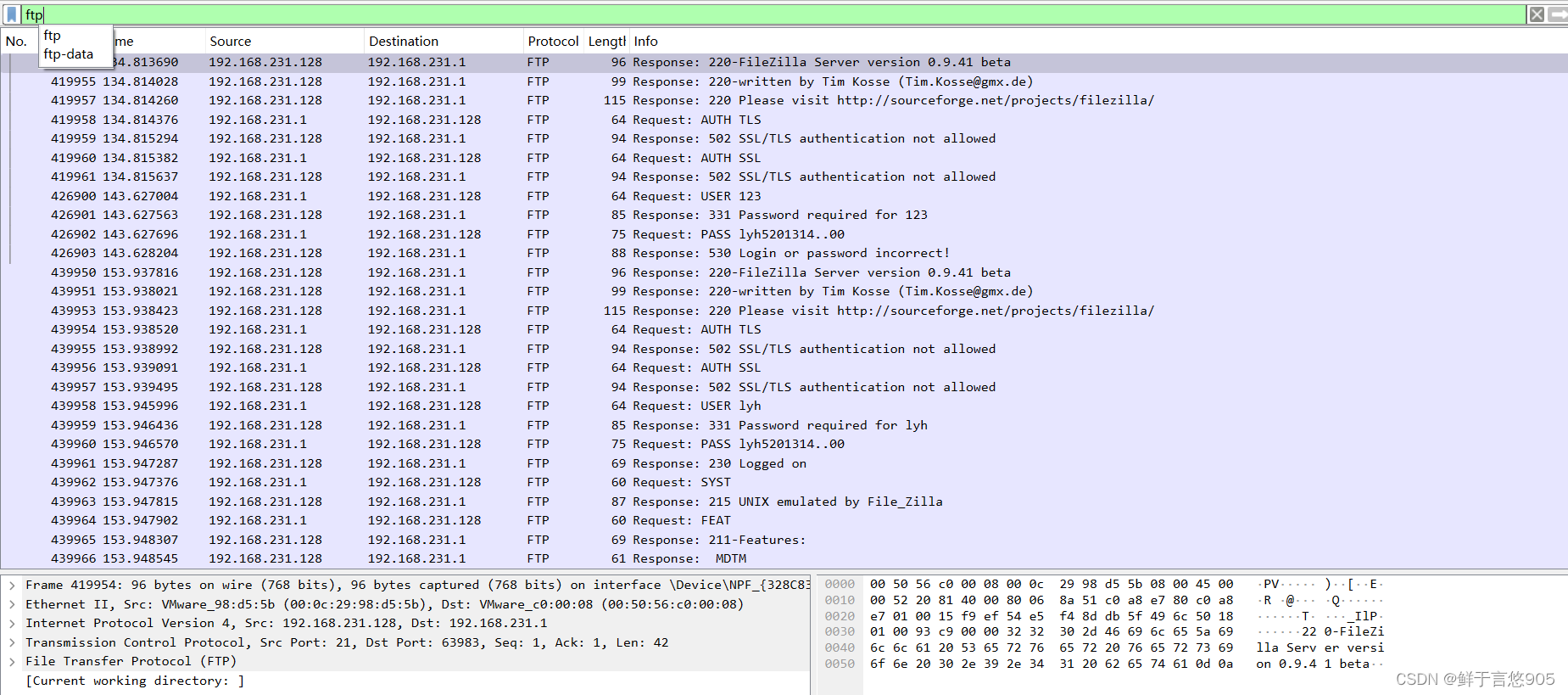
基于Wireshark实现对FTP的抓包分析
基于Wireshark实现对FTP的抓包分析 前言一、虚拟机Win10环境配置二、FileZilla客户端的安装配置下载FileZilla客户端安装FileZilla 三、FileZilla Server安装下载FileZilla Server安装 四、实现对FTP的抓包前置工作实现抓包完成抓包 前言 推荐一个网站给想要了解或者学习人工智…...

Vue54-浏览器的本地存储webStorage
一、本地存储localStorage的作用 二、本地存储的代码实现 2-1、存储数据 注意: localStorage是window上的函数,所以,可以把window.localStorage直接写成localStorage(直接调用!) 默认调了p.toString()方…...

Linux下Shell脚本基础知识
主要参考视频: 这可能是B站讲的最好的Linux Shell脚本教程,3h打通Linux-shell全套教程,从入门到精通完整版_哔哩哔哩_bilibili 主要参考文档: Shell 教程 | 菜鸟教程 (runoob.com) Bash Shell教程 (yiibai.com) 先用视频入门&…...
爬虫初学篇——看完这些还怕自己入门不了?
初次学习爬虫,知识笔记小分享 学scrapy框架可看:孤寒者博主的【Python爬虫必备—>Scrapy框架快速入门篇——上】 目录🌟 一、🍉基础知识二、🍉http协议:三、🍉解析网页(1) xpath的用…...

[数据集][目标检测]减速区域检测数据集VOC+YOLO格式1654张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1654 标注数量(xml文件个数):1654 标注数量(txt文件个数):1654 标注…...
OpenGL3.3_C++_Windows(8)
材质&&漫反射,光照贴图 使用struct为材质建立结构体,以便方便管理漫反射贴图是物体的颜色值(纹理)(通过 UV 坐标映射到渲染物体的表面),材质是物体的属性(物体对光的交互&a…...
GPU的工作原理
location: Beijing 1. why is GPU CPU的存储单元和计算单元的互通过慢直接促进了GPU的发展 先介绍一个概念:FLOPS(Floating Point Operations Per Second,浮点运算每秒)是一个衡量其执行浮点运算的能力,可以作为计算…...
Linux常⽤服务器构建-samba
目录 1. 介绍 2. 安装 3. 配置 3.1 创建存放共享⽂件的路径 3.2 创建samba账户 4 重启samba 5. 访问共享⽂件 5.1 mac下访问⽅式 5.2 windows下访问⽅式 1. 介绍 Samba 是在 Linux 和 UNIX 系统上实现 SMB 协议的⼀个免费软件,能够完成在 windows 、 mac 操作系统…...

【Java】已解决java.lang.UnsupportedOperationException异常
文章目录 问题背景可能出错的原因错误代码示例正确代码示例注意事项 已解决java.lang.UnsupportedOperationException异常 在Java编程中,java.lang.UnsupportedOperationException是一个运行时异常,通常表示尝试执行一个不支持的操作。这种异常经常发生…...
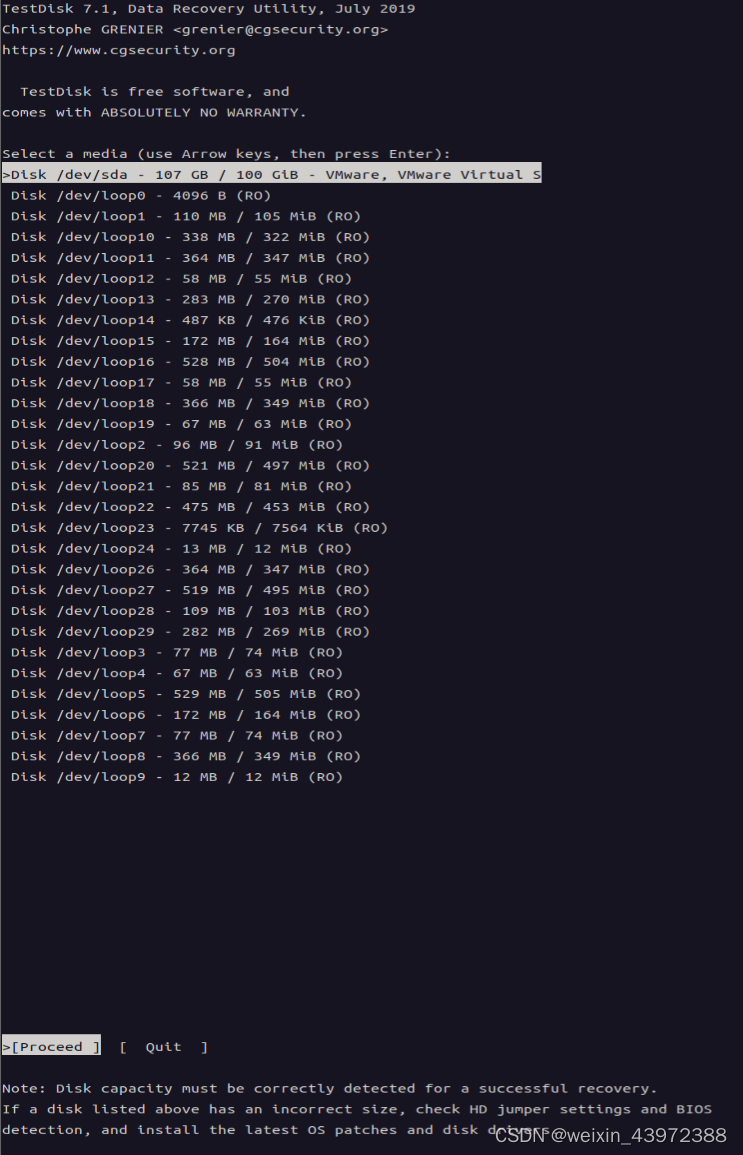
在ubuntu中恢复误删除的文件
1、安装 TestDisk 在 Ubuntu 上,可以使用以下命令安装 TestDisk: sudo apt-get install testdisk2、查询你删除的文件所在那个分区 #查询分区 df -h #我这里是/dev/sda2 #也可以使用下面命令查看具体哪个分区 lsblk3、查询该分区是什么系统类型 sudo …...
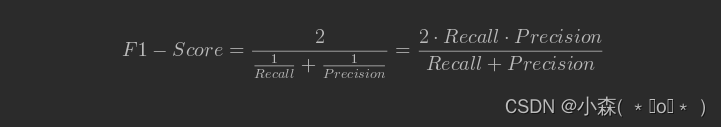
Sklearn中逻辑回归建模
分类模型的评估 回归模型的评估方法,主要有均方误差MSE,R方得分等指标,在分类模型中,我们主要应用的是准确率这个评估指标,除此之外,常用的二分类模型的模型评估指标还有召回率(Recallÿ…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...