PyTorch tutorials:快速学会使用PyTorch
准备深入学习transformer,并参考一些资料和论文实现一个大语言模型,顺便做一个教程,今天是番外篇,介绍下PyTorch,后面章节实现代码主要使用这个框架。
本系列禁止转载,主要是为了有不同见解的同学可以方便联系我,我的邮箱 fanzexuan135@163.com
快速学会PyTorch
PyTorch是一个流行的基于Python的深度学习库,在本书的其余部分将作为我们实现大型语言模型(LLMs)的主要工具。本章将指导你设置一个具有PyTorch和GPU支持的深度学习工作空间。
然后,你将学习PyTorch中张量(Tensor)的基本概念及其用法。我们还将深入研究PyTorch的自动微分引擎,这一特性使我们能够方便、高效地使用反向传播,这是神经网络训练的关键。
请注意,本章旨在为PyTorch深度学习新手提供入门指南。虽然本章从头开始解释PyTorch,但并不意味着对PyTorch库进行详尽的介绍。相反,本章重点介绍了我们将在本书中用于实现LLMs的PyTorch基础知识。如果你已经熟悉深度学习,可以跳过本附录,直接进入第1章处理文本数据。
A.1 PyTorch概述
PyTorch是由Facebook人工智能研究实验室(FAIR)开发的开源深度学习框架。它建立在Torch库之上,Torch是一个使用Lua编程语言的机器学习库。Torch主要用于研究和学术领域,而PyTorch则旨在为研究人员和实践者提供一个Python友好的接口。
PyTorch是为灵活性和速度而设计的。它提供了一个名为Tensor的主要数据结构,用于存储和操作多维数组。Tensor类似于NumPy的ndarray,但可以利用GPU来加速计算。PyTorch的一个关键特性是"动态计算图",这意味着计算图是在运行时定义的。这与TensorFlow等其他深度学习框架形成对比,后者使用静态计算图。动态计算图使得在模型开发过程中进行调试和实验更加容易。
PyTorch的另一个重要特性是自动微分。自动微分使计算函数的梯度变得容易,这对于训练神经网络至关重要。PyTorch使用一种称为"反向自动微分"的技术,它可以有效地计算梯度,并将其传播回模型的参数。这使得在PyTorch中实现复杂的神经网络架构变得直观。
PyTorch还提供了一个高级API,称为torch.nn,用于构建神经网络。torch.nn提供了一组预构建的层、损失函数和优化器,可用于快速原型化和训练模型。此外,PyTorch还包括torchvision和torchaudio等库,用于处理图像和音频数据。
总的来说,PyTorch旨在为研究人员和从业者提供一个灵活、直观的深度学习框架,同时不牺牲速度或性能。它在学术界和工业界都得到了广泛的应用,并且仍在不断发展以满足深度学习社区的需求。
A.2 设置工作空间
在开始使用PyTorch进行深度学习之前,我们需要设置一个适当的环境。这包括安装必要的软件包和配置我们的工作空间。
A.2.1 安装Python和PyTorch
第一步是安装Python。我们建议使用Python 3.7或更高版本。你可以从官方Python网站(https://www.python.org)下载并安装Python。
接下来,我们需要安装PyTorch。PyTorch的安装因操作系统和软件包管理器而异。对于大多数用户,我们建议使用pip,Python的标准软件包安装程序。
要使用pip安装PyTorch,请打开终端或命令提示符并运行以下命令:
pip install torch
这将安装PyTorch的最新稳定版本。如果你有GPU并希望利用它进行深度学习,你还需要安装CUDA和cuDNN。你可以在PyTorch的官方网站(https://pytorch.org)上找到关于如何为你的特定设置安装这些的说明。
A.2.2 设置Jupyter Notebook
Jupyter Notebook是一个交互式计算环境,非常适合深度学习实验和原型制作。它允许你在一个文档中组合代码、可视化和叙述性文本。
要安装Jupyter Notebook,请在终端或命令提示符下运行以下命令:
pip install notebook
安装完成后,你可以通过运行以下命令来启动Jupyter Notebook:
jupyter notebook
这将在你的默认Web浏览器中打开Jupyter Notebook。从这里,你可以创建一个新的notebook并开始编写Python代码。
A.2.3 使用GPU进行深度学习
深度学习通常涉及大量的计算,尤其是在训练大型模型时。虽然可以在CPU上进行这些计算,但使用GPU可以显著加快训练速度。
要在PyTorch中使用GPU,你首先需要确保你的系统上安装了CUDA和cuDNN。然后,你可以使用torch.cuda模块来移动你的数据和模型到GPU上。
例如,要检查你的系统是否有可用的GPU,你可以运行以下代码:
import torchif torch.cuda.is_available():print("GPU is available")
else:print("GPU is not available")
如果GPU可用,你可以使用.to()方法将你的数据和模型移动到GPU上:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MyModel().to(device)
data = MyData().to(device)
现在,你的模型和数据都在GPU上,任何涉及它们的计算都将在GPU上执行,从而显著加快速度。
A.3 Tensor基础
在PyTorch中,Tensor是主要的数据结构。Tensor是一种类似于NumPy的ndarray的多维数组,但Tensor可以在GPU上运行以加速计算。理解Tensor及其操作对于在PyTorch中有效地工作至关重要。
A.3.1 创建Tensor
有几种方法可以创建Tensor。最简单的方法之一是直接从Python列表或NumPy数组转换:
import torch
import numpy as np# 从Python列表创建
python_list = [[1, 2], [3, 4]]
tensor_from_list = torch.tensor(python_list)
print(tensor_from_list)# 从NumPy数组创建
np_array = np.array([[1, 2], [3, 4]])
tensor_from_np = torch.from_numpy(np_array)
print(tensor_from_np)
这将输出:
tensor([[1, 2],[3, 4]])
tensor([[1, 2],[3, 4]])
PyTorch还提供了几个函数来创建特殊的Tensor:
# 创建一个填充了0的Tensor
zeros_tensor = torch.zeros(2, 2)
print(zeros_tensor)# 创建一个填充了1的Tensor
ones_tensor = torch.ones(2, 2)
print(ones_tensor)# 创建一个填充了随机值的Tensor
random_tensor = torch.rand(2, 2)
print(random_tensor)
输出可能类似于:
tensor([[0., 0.],[0., 0.]])
tensor([[1., 1.],[1., 1.]])
tensor([[0.8823, 0.9150],[0.3829, 0.9593]])
A.3.2 Tensor操作
PyTorch提供了大量的操作来操作Tensor。这些操作可以分为几类:算术运算、线性代数、索引和切片等。
算术运算是最基本的Tensor操作。PyTorch支持所有标准的算术运算,如加法、减法、乘法和除法:
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5, 6], [7, 8]])# 加法
print(x + y)
print(torch.add(x, y))# 减法
print(x - y)
print(torch.sub(x, y))# 乘法
print(x * y)
print(torch.mul(x, y))# 除法
print(x / y)
print(torch.div(x, y))
这将输出:
tensor([[ 6, 8],[10, 12]])
tensor([[ 6, 8],[10, 12]])
tensor([[-4, -4],[-4, -4]])
tensor([[-4, -4],[-4, -4]])
tensor([[ 5, 12],[21, 32]])
tensor([[ 5, 12],[21, 32]])
tensor([[0.2000, 0.3333],[0.4286, 0.5000]])
tensor([[0.2000, 0.3333],[0.4286, 0.5000]])
对于线性代数操作,PyTorch提供了函数如torch.matmul用于矩阵乘法,torch.inverse用于矩阵求逆等:
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5, 6], [7, 8]])# 矩阵乘法
print(torch.matmul(x, y))# 矩阵转置
print(x.t())# 矩阵求逆
print(torch.inverse(x))
输出为:
tensor([[19, 22],[43, 50]])
tensor([[1, 3],[2, 4]])
tensor([[-2.0000, 1.0000],[ 1.5000, -0.5000]])
索引和切片操作允许你访问Tensor的特定元素或子区域:
x = torch.tensor([[1, 2], [3, 4]])# 访问单个元素
print(x[0, 0])# 访问一行
print(x[0, :])# 访问一列
print(x[:, 0])
输出为:
tensor(1)
tensor([1, 2])
tensor([1, 3])
这只是PyTorch提供的Tensor操作的一小部分。PyTorch支持广泛的操作,包括统计操作(如均值和标准差)、比较操作(如等于和大于)、梯度操作(在下一节中讨论)等。熟悉这些操作对于在PyTorch中有效地工作至关重要。
A.4 自动微分
PyTorch的一个关键特性是自动微分。在深度学习中,我们经常需要计算函数相对于其输入的导数或梯度。例如,在训练神经网络时,我们需要计算损失函数相对于网络权重的梯度,以便我们可以更新权重以最小化损失。手动计算这些梯度可能很困难且容易出错,尤其是对于复杂的函数。
PyTorch的自动微分系统,称为Autograd,为我们处理这个问题。使用Autograd,我们可以定义任意复杂的函数,PyTorch将为我们计算梯度。
A.4.1 Tensor和梯度
在PyTorch中,autograd是围绕Tensor类的torch.Tensor扩展构建的。任何通过操作创建的Tensor都将有一个.grad_fn属性,这个属性引用了创建该Tensor的函数。这有效地创建了一个计算图,编码了创建Tensor的整个函数链。
另外,如果你将.requires_grad属性设置为True,那么通过该Tensor的所有操作也将被跟踪。这允许你稍后计算相对于这个Tensor的梯度。
让我们看一个简单的例子:
import torch# 创建一个Tensor并设置 requires_grad=True
x = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)# 进行一些操作
y = x + 2
z = y * y * 3
out = z.mean()# 计算梯度
out.backward()# 打印梯度
print(x.grad)
这将输出:
tensor([[4.5000, 6.0000],[7.5000, 9.0000]])
让我们逐步分析这个例子:
- 我们创建了一个 Tensor x,并设置 requires_grad 为 True。
- 我们对 x 进行一些数学操作得到了一个新的 Tensor out。
- 我们在 out 上调用 .backward()。这计算了 out 相对于 x 的梯度。
- 梯度存储在x.grad中。
在这个例子中,out是一个标量。out.backward()计算out相对于x的梯度,在数学上可以表示为∂out/∂x。如果out是一个更高维的Tensor,out.backward()将计算出相对于x的雅可比矩阵。
A.4.2 自动微分的使用案例
让我们看一个稍微复杂一点的例子,说明如何使用PyTorch的自动微分来训练一个简单的模型。我们将创建一个简单的线性模型,并使用梯度下降法来学习模型的参数。
首先,我们需要创建一些数据:
import torch# 创建输入和输出数据
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
接下来,我们定义我们的模型。对于线性模型,我们需要学习两个参数:权重w和偏差b。我们的模型将是y = w * x + b的形式。
# 初始化模型参数w = torch.tensor([1.0], requires_grad=True)
b = torch.tensor([0.0], requires_grad=True)
现在我们有了数据和模型,我们可以定义我们的预测函数:
# 前向传递函数
def forward(x):return w * x + b
我们还需要一个损失函数来衡量我们的模型有多好。对于这个简单的例子,我们将使用平均平方误差(MSE):
# 损失函数
def loss(y_pred, y_true):return ((y_pred - y_true)**2).mean()
现在我们准备训练我们的模型。我们将通过多个epochs(数据的完整传递)来训练,在每个epoch中,我们将:
- 进行预测
- 计算损失
- 计算相对于模型参数的梯度
- 使用梯度更新模型参数
# 训练模型
learning_rate = 0.01
n_epochs = 100for epoch in range(n_epochs):# 前向传递y_pred = forward(x_data)# 计算和打印损失l = loss(y_pred, y_data)if epoch % 10 == 0:print(f'epoch {epoch+1}: w = {w.item():.3f}, loss = {l:.8f}')# 反向传播来计算 w 和 b 相对于损失的梯度l.backward()# 手动更新权重with torch.no_grad():w -= learning_rate * w.gradb -= learning_rate * b.grad# 手动将梯度归零w.grad.zero_()b.grad.zero_()
这将输出:
epoch 1: w = 1.300, loss = 1.00000000
epoch 11: w = 1.665, loss = 0.02962963
epoch 21: w = 1.934, loss = 0.00087511
epoch 31: w = 1.987, loss = 0.00002586
epoch 41: w = 1.997, loss = 0.00000076
epoch 51: w = 1.999, loss = 0.00000002
epoch 61: w = 2.000, loss = 0.00000000
epoch 71: w = 2.000, loss = 0.00000000
epoch 81: w = 2.000, loss = 0.00000000
epoch 91: w = 2.000, loss = 0.00000000
如你所见,随着训练的进行,我们的模型学会了正确的权重(w=2),损失也减少到了接近零。这就是PyTorch的自动微分如何使复杂模型的训练变得容易。
A.5 神经网络模块: torch.nn
虽然使用Tensor和autograd可以从头开始构建神经网络,但这可能很繁琐。PyTorch的 torch.nn 模块提供了一组预构建的层和工具,使构建神经网络更加容易。
A.5.1 定义网络
torch.nn模块的核心数据结构是 nn.Module。你的网络应该继承这个类,而你的层将成为这个类的属性。让我们定义一个简单的前馈网络:
import torch
import torch.nn as nnclass SimpleNet(nn.Module):def __init__(self):super().__init__()self.linear1 = nn.Linear(10, 20)self.relu = nn.ReLU()self.linear2 = nn.Linear(20, 2)def forward(self, x):x = self.linear1(x)x = self.relu(x)x = self.linear2(x)return x
在这个例子中,我们定义了一个具有两个线性层(nn.Linear)的网络,中间有一个ReLU激活函数。forward方法定义了网络的前向传递。
A.5.2 损失函数和优化器
torch.nn 还提供了常用的损失函数,如nn.MSELoss用于均方误差,nn.CrossEntropyLoss用于交叉熵损失等。
为了训练我们的网络,我们需要一个优化器。PyTorch在torch.optim模块中提供了各种优化器,最常用的是 Adam 和 SGD。
让我们看一个完整的训练循环的例子:
import torch
import torch.nn as nn
import torch.optim as optim# 定义网络
model = SimpleNet()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练数据 (这里我们使用随机数据作为例子)
inputs = torch.randn(100, 10)
labels = torch.randint(2, (100,))# 训练循环
for epoch in range(100):# 前向传递outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if (epoch+1) % 10 == 0:print(f'Epoch [{epoch+1}/100], Loss: {loss.item():.4f}')
这个例子展示了使用 torch.nn 定义和训练一个神经网络有多么简单。nn.Module 提供了一个组织网络的方便方法,而 torch.optim 使优化过程变得简单。
A.6 在GPU上训练模型
如前所述,GPU可以显著加快深度学习模型的训练速度。PyTorch使在GPU上训练模型变得简单。
要在GPU上训练,你首先需要将你的模型和数据移动到GPU上。你可以使用 .to(device) 方法来实现,其中 device 可以是 “cpu” 或 “cuda”(如果有GPU可用)。
让我们修改前面的例子以使用GPU(如果可用):
import torch
import torch.nn as nn
import torch.optim as optim# 定义网络
model = SimpleNet()# 移动模型到GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练数据 (这里我们使用随机数据作为例子)
inputs = torch.randn(100, 10).to(device)
labels = torch.randint(2, (100,)).to(device)# 训练循环
for epoch in range(100):# 前向传递 outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward() optimizer.step()if (epoch+1) % 10 == 0:print(f'Epoch [{epoch+1}/100], Loss: {loss.item():.4f}')
注意,我们移动了模型、输入和标签到GPU。现在,所有的计算都将在GPU上进行,从而显著加快训练速度。
重要的是要注意,当你在GPU上训练时,你的整个模型必须在GPU上。你不能让一部分模型在CPU上,而另一部分在GPU上。此外,你的数据批次必须足够大以利用GPU的并行性,但又不能太大以至于超过GPU的内存容量。
总结
在本章中,我们介绍了PyTorch,一个功能强大且灵活的深度学习框架。我们学习了如何设置PyTorch环境,探索了Tensor和autograd系统的基础知识,并看到了如何使用torch.nn模块构建和训练神经网络。
PyTorch的设计使得它直观且易于使用,同时仍然提供了研究和生产所需的所有功能。它的动态计算图使调试和实验更加容易,而它的自动微分系统使得训练复杂模型变得简单。
在接下来的章节中,我们将利用这里学到的PyTorch知识来构建各种类型的大型语言模型。我们将探索如何处理文本数据,如何实现transformer架构,以及如何在特定任务上微调预训练的语言模型。
通过对PyTorch的深入理解,你将拥有在这个快速发展的领域中进行实验和创新所需的工具和知识。无论你是一个刚刚开始深度学习之旅的初学者,还是一个寻求扩展知识的有经验的从业者,PyTorch都提供了一个强大而友好的环境来探索大型语言模型的世界。
参考文献
-
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., … & Chintala, S. (2019). PyTorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32.
-
PyTorch documentation. (2023). Retrieved from https://pytorch.org/docs/stable/index.html
-
Chintala, S. (2017). PyTorch tutorials. Retrieved from https://pytorch.org/tutorials/
-
Li, M., Andersen, D. G., Park, J. W., Smola, A. J., Ahmed, A., Josifovski, V., … & Su, B. Y. (2014). Scaling distributed machine learning with the parameter server. In 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14) (pp. 583-598).
-
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., … & Zheng, X. (2016). Tensorflow: A system for large-scale machine learning. In 12th USENIX symposium on operating systems design and implementation (OSDI 16) (pp. 265-283).
相关文章:

PyTorch tutorials:快速学会使用PyTorch
准备深入学习transformer,并参考一些资料和论文实现一个大语言模型,顺便做一个教程,今天是番外篇,介绍下PyTorch,后面章节实现代码主要使用这个框架。 本系列禁止转载,主要是为了有不同见解的同学可以方便联…...

【CT】LeetCode手撕—手撕快排
目录 题目1-思路-快排1-1 快排的核心思想快速排序算法步骤优美的调整区间 1-2 ⭐快排的实现 2- 实现⭐912. 排序数组——题解思路 3- ACM 实现 题目 原题连接:912. 排序数组 1-思路-快排 1-1 快排的核心思想 选择一个基准 基准左侧的元素都小于该元素基准右侧的元…...

使用ARK工具ATool清除典型蠕虫MyDoom
1 概述 在长期的日常安全事件监测过程中,安天CERT经常捕获到大量的MyDoom蠕虫样本和传播该蠕虫的钓鱼邮件。受害主机感染MyDoom后会被放置后门,以便攻击者下发后续恶意软件,进行攻击或窃密等操作。MyDoom蠕虫最早发现于2004年&…...
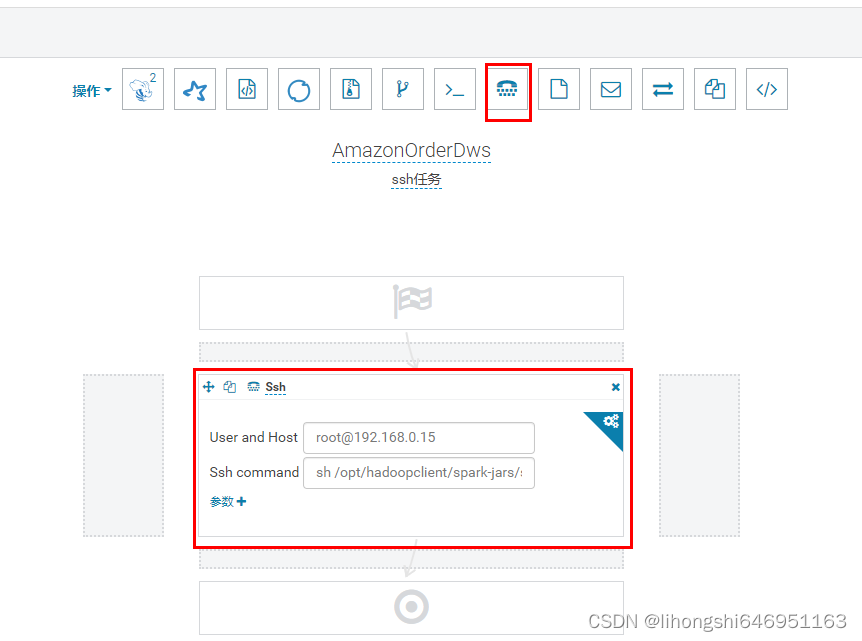
在hue中使用ooize调度ssh任务无法执行成功,无法查看错误
ssh执行失败,但是hue没有给出明确的错误原因: 经过经验分析,原来是服务器上的sh文件用的是doc/window格式,需要使用notepad将格式改为unix之后就可以正常执行。 特此记录,避免遗忘知识点...
一套轻量、安全的问卷系统基座,提供面向个人和企业的一站式产品级解决方案
大家好,今天给大家分享的是一款轻量、安全的问卷系统基座。 XIAOJUSURVEY是一套轻量、安全的问卷系统基座,提供面向个人和企业的一站式产品级解决方案,快速满足各类线上调研场景。 内部系统已沉淀 40种题型,累积精选模板 100&a…...

3秒生成!这个AI模型画风也太治愈了,新手也能轻松驾驭
还在为不会画画而苦恼吗?别担心,今天给大家介绍一个超好用的AI模型——Soft and Squishy Linework,即使是小白也能轻松生成可爱的动漫图像! Soft and Squishy Linework:专门生成柔和的、低保真(lofi&#…...

数字人全拆解:如何构建一个基于大模型的实时对话3D数字人?
简单地说,数字人就是在数字世界的“人”。当前语境下我们谈到的数字人通常指的是借助AI技术驱动的虚拟世界人物,具备与真实人类相似甚至接近的外形、感知、交互与行为能力。 AI技术在智能数字人的应用中举足轻重,特别是随着大模型能力的涌现…...
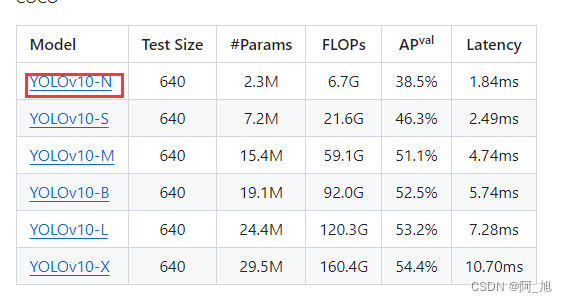
实战 | 基于YOLOv10的车辆追踪与测速实战【附源码+步骤详解】
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

2024北京智源大会
北京智源大会是年度国际性人工智能高端学术交流的盛会,定位于内行的AI盛会。智源大会紧密围绕当前人工智能学术领域迫切需要解决的问题,以及产业落地过程中存在的诸多挑战,开展深入探讨。智源研究院是2018年11月份成立的一家人工智能领域的新…...

youlai-boot项目的学习—本地数据库安装与配置
数据库脚本 在项目代码的路径下,有两个版本的mysql数据库脚本,使用对应的脚本就安装对应的数据库版本,本文件选择了5 数据库安装 这里在iterm2下使用homebrew安装mysql5 brew install mysql5.7注:记得配置端终下的科学上网&a…...
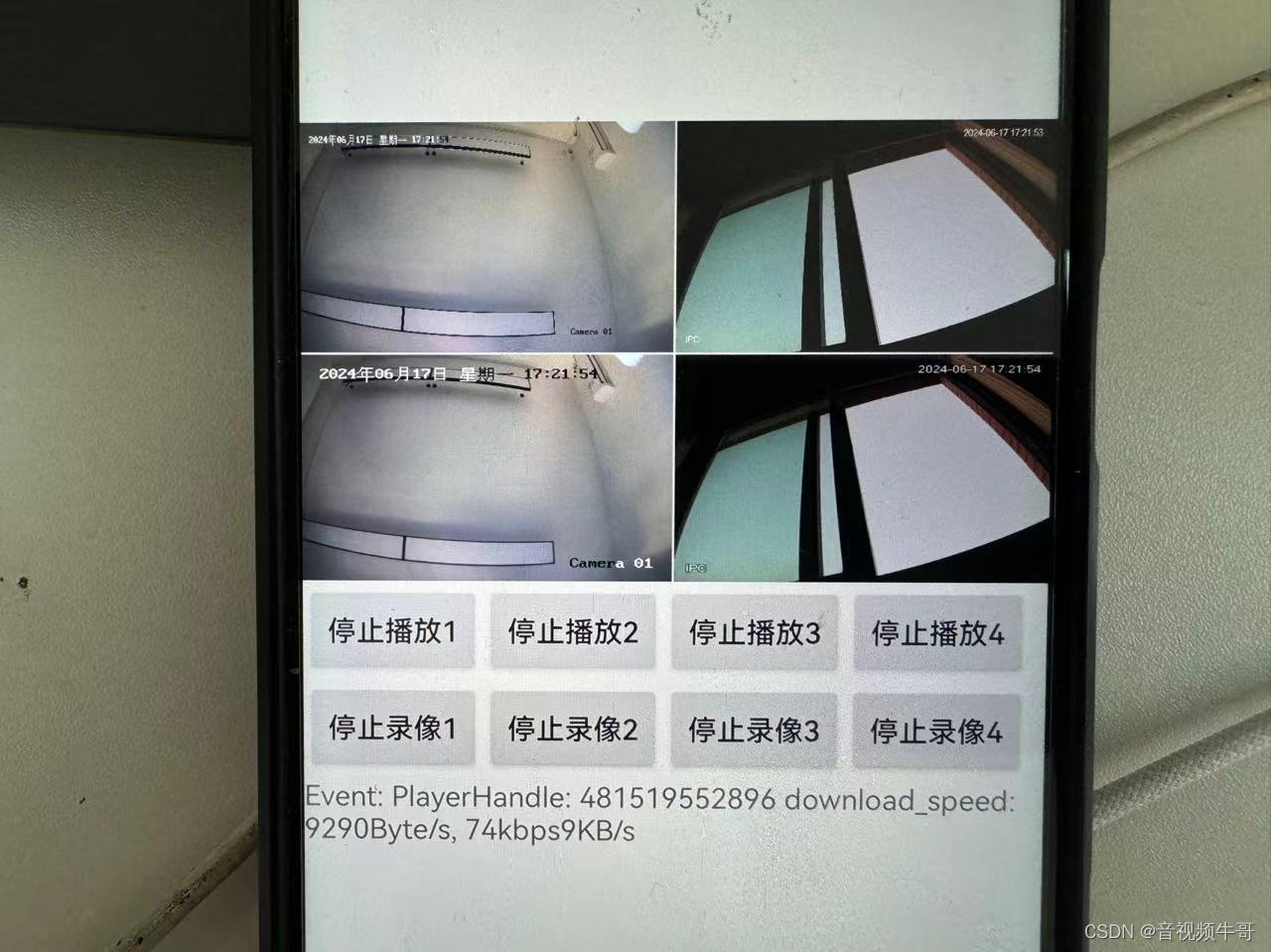
Android平台如何实现多路低延迟RTSP|RTMP播放?
技术背景 实际上,我们在2015年做Android平台RTSP、RTMP播放模块的时候,第一版就支持了多实例播放,因为SDK设计比较灵活,做个简单的player实例封装即可实现多实例播放(Android Unity的就有多路demo)&#x…...

深入探索Java开发世界:Java基础~类型分析大揭秘
文章目录 一、基本数据类型二、封装类型三、类型转换四、集合类型五、并发类型 Java基础知识,类型知识点梳理~ 一、基本数据类型 Java的基本数据类型是语言的基础,它们直接存储在栈内存中,具有固定的大小和不变的行为。 八种基本数据类型的具…...

短URL服务设计
引言 在营销系统里,为了增加系统的活跃用户数,经常会有各种各样的营销活动。这类活动几乎都是为了充分利用存量用户的价值,促使他们分享产品或App以达到触达到更多用户的目的。又或者是出于营销目的,群发优惠券触达短信这种场景。…...

Kafka集成flume
1.flume作为生产者集成Kafka kafka作为flume的sink,扮演消费者角色 1.1 flume配置文件 vim $kafka/jobs/flume-kafka.conf # agent a1.sources r1 a1.sinks k1 a1.channels c1 c2# Describe/configure the source a1.sources.r1.type TAILDIR #记录最后监控文件…...
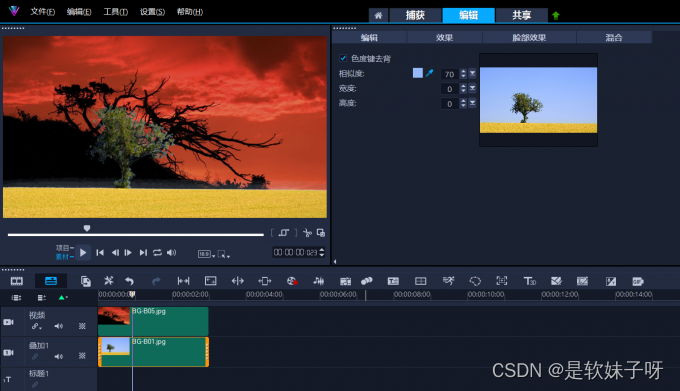
如何让视频有高级感 高级感视频制作方法 高级感视频怎么剪 会声会影视频剪辑制作教程 会声会影中文免费下载
高质量视频通常具有清晰的画面、优质的音频和令人印象深刻的视觉效果。这篇文章来了解如何让视频有高级感,高级感视频制作方法。 一、如何让视频有高级感 要让视频有高级感,要注意以下几个要点: 1、剧本和故事性:一个好的剧本和…...

详解|访问学者申请被拒原因有哪些?
访问学者项目为全球科研人员提供了一个难得的机会,让他们能够跨越国界,深入不同的学术环境,进行学术交流和合作。然而,并非所有申请者都能如愿以偿地获得这一机会。本文将对访问学者申请中常见的被拒原因进行详细解析,…...

[鹤城杯 2021]BabyRSA
题目: from Crypto.Util.number import getPrime, bytes_to_long from secret import flagp getPrime(1024) q getPrime(1024) n p * q e 65537 hint1 p >> 724 hint2 q % (2 ** 265) ct pow(bytes_to_long(flag), e, n) print(hint1) print(hint2) p…...
)
西安市工业倍增引导基金子基金申报条件流程和材料程序指南(2024年)
一、基本情况 产业投资基金是以产业发展为首要目标,围绕经济社会发展规划和产业发展政策,发挥“有效市场”作用,支持重点领域、重点产业、重点区域(如:全市六大支柱产业、五大新兴产业领域成熟期重点规模以上企业以及“…...

微型丝杆的耐用性和延长使用寿命的关键因素!
无论是机械设备,还是精密传动元件,高精度微型丝杆是各种机械设备中不可或缺的重要组件。它的精度和耐用性直接影响着工作效率和产品品质,在工业技术不断进步的情况下,对微型丝杆的性能要求也越来越高,如何提升微型丝杆…...
音频文件下载后,如何轻松转换格式?
在我们日常的数字生活中,下载各种音频文件是司空见惯的事情。然而,有时候我们可能需要将这些音频文件转换为不同的格式,以适应不同的设备或编辑需求。无论您是希望将下载的音频文件转换为通用的MP3格式,还是需要将其转换为高保真的…...

嵌入式系统开发:硬件思维与架构实践
1. 嵌入式领域的技术特性解析嵌入式系统开发与传统软件工程存在本质差异。在资源受限的硬件环境中,开发者往往需要直接操作寄存器、管理内存分配、处理中断服务例程。这种"贴近金属"的开发方式,决定了嵌入式工程师必须具备硬件思维。以STM32系…...

数据团队该醒醒了:AI智能体不是你的下一个仪表盘闹
7.1 初识三维模型 7.1.1 三维模型的数据载体 随着计算机图形技术的发展,我们或多或少都会见过或者听说过三维模型。笔者始终记得小时候第一次在电视上看到三维动画《变形金刚:超能勇士》的震撼感受;而现在我们已经可以在手机上玩三维游戏《王…...

三维点云障碍物检测与聚类算法对比实现
三维点云障碍物检测与聚类算法对比实现 项目概述 本项目实现了一个完整的三维点云障碍物检测系统,集成了K-means和DBSCAN两种经典聚类算法,并对它们的性能进行了对比分析。系统包含点云数据生成、预处理、聚类检测、结果可视化和性能评估等模块。代码设计遵循模块化原则,注…...

大模型之Linux服务器部署大模型头
一、各自优势和对比 这是检索出来的数据,据说是根据第三方评测与企业数据,三款产品在代码生成质量上各有侧重: 产品 语言优势 场景亮点 核心差异 百度 Comate C核心代码质量第一;Python首生成率达92.3% SQL生成准确率提升35%&…...

fast-memoize.js高级用法:自定义策略与性能调优技巧
fast-memoize.js高级用法:自定义策略与性能调优技巧 【免费下载链接】fast-memoize.js :rabbit2: Fastest possible memoization library 项目地址: https://gitcode.com/gh_mirrors/fa/fast-memoize.js fast-memoize.js是目前JavaScript中最快的记忆化&…...

如何通过Bilibili-Evolved实现B站动画60fps流畅播放优化指南
如何通过Bilibili-Evolved实现B站动画60fps流畅播放优化指南 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved 想要在哔哩哔哩享受影院级别的动画播放体验吗?Bilibili-Evolved作为一…...
理解效果)
Phi-4-reasoning-vision-15B作品集:15类真实办公截图(邮件/PPT/数据库/IDE等)理解效果
Phi-4-reasoning-vision-15B作品集:15类真实办公截图理解效果展示 1. 模型能力概览 Phi-4-reasoning-vision-15B是微软最新发布的视觉多模态推理模型,专门针对办公场景的视觉理解需求进行了优化。这个模型不仅能看懂图片内容,还能像专业人士…...

WinClaw实战教程 01|安全版OpenClaw从零部署:5分钟上手+全功能实测+避坑大全
摘要:2026年AI Agent已然从极客小众工具进化为全民级效率神器,OpenClaw(小龙虾)凭借AI直控电脑的核心能力引爆开源社区,但恶意Skill泛滥、AI误删数据、配置门槛极高、资产暴露等安全与易用性问题频发——某互联网公司员工因使用OpenClaw第三方Skill导致核心项目文档泄露,…...

Linux网络编程核心API速查手册喊
智能体时代的代码范式转移与 C# 的战略转型 传统的 C# 开发模式,即所谓的“工程导向型”开发,要求开发者创建一个复杂的项目结构,包括项目文件(.csproj)、解决方案文件(.sln)、属性设置以及依赖…...

深度解析TFTP与FTP:核心区别、工作原理与应用场景
深度解析TFTP与FTP:核心区别、工作原理与应用场景摘要一、基础定义1.1 FTP 协议1.2 TFTP 协议二、TFTP 和 FTP 核心区别(表格对比)三、工作原理简要说明FTP 原理TFTP 原理四、TFTP 应用场景(最典型)1. **网络设备配置备…...