python实践笔记(三): 异常处理和文件操作
1. 写在前面
最近在重构之前的后端代码,借着这个机会又重新补充了关于python的一些知识, 学习到了一些高效编写代码的方法和心得,比如构建大项目来讲,要明确捕捉异常机制的重要性, 学会使用try...except..finally, 要通过日志模块logging监控整个系统的性能,学会把日志输出到文件并了解日志层级,日志模块的一些工作原理,能自定义日志,这样能非常方便的debug服务,学会使用装饰器对关键接口进行时间耗时统计,日志打印等装饰,减少代码的重复性, 学会使用类的类方法,静态方法对一些公用函数进行封装,来增强代码的可维护性, 学会使用文档对函数和参数做注解, 学会函数的可变参数统一代码的风格等等, 这样能使得代码从可读性,可维护性, 灵活性和执行效率上都有一定的提升,写出来的代码也更加优美一些。 所以把这几天的学习,分模块整理几篇笔记, 这次是从实践的再去补充python的内容,目的是要写出漂亮的python代码,增强代码的可读,可维护,灵活和高效,方便调试和监控。
这篇文章介绍两块内容,分别是异常处理机制以及文件操作, 异常处理操作在大型下项目里面非常有用,开发人员在编写程序时,难免会遇到错误,有的是编写人员疏忽造成的语法错误,有的是程序内部隐含逻辑问题造成的数据错误,还有的是程序运行时与系统的规则冲突造成的系统错误等等,通过异常处理,可以全局掌控自己的程序。 文件操作也是非常实用的一个技术,把文件随时存储到文件进行持久化,是一个非常好的习惯。
大纲如下:
- 异常处理机制
- 文件操作
Ok, let’s go!
2. 异常处理机制
2.1 What?
开发人员在编写程序时,难免会遇到错误,有的是编写人员疏忽造成的语法错误,有的是程序内部隐含逻辑问题造成的数据错误,还有的是程序运行时与系统的规则冲突造成的系统错误,等等。
- 语法错误: 写的代码不符合python语法规则, 解析器帮我们检查,如果发现及时报错, 这个解析器零容忍, 修复之后才能说运行的事情
- 运行错误:语法上没有问题能过,但运行的时候发生错误,比如1/0这种。
在 Python 中,把这种运行时产生错误的情况叫做异常(Exceptions)
常见的异常如下:
| 异常类型 | 解释 | demo |
|---|---|---|
| AssertionError | 当 assert 关键字后的条件为假时,程序运行会停止并抛出 AssertionError 异常 | def add(a: int, b: int) -> int: assert isinstance(a, int) and isinstance(b, int), f"{a} or {b} is invalid!, please check"<br.return a + b add(3.5, 3) # AssertionError: 3.5 or 3 is invalid!, please check |
| AttributeError | 当试图访问的对象属性不存在时抛出的异常 | a = {”name”: “zhongqiang”} print(a.len) # dict 没有属性len |
| IndexError | 索引超出序列范围会引发此异常 | a = [1, 2, 3] print(a[4]) # IndexError: list index out of range |
| KeyError | 字典中查找一个不存在的关键字时引发此异常 | a = {”name”: “zhongqiang”} print(a[’age’]) # KeyError |
| NameError | 尝试访问一个未声明的变量时,引发此异常 | print(hello) |
| TypeError | 不同类型数据之间的无效操作 | 1 + “hello” |
| ZeroDivisionError | 除法运算中除数为 0 引发此异常 | 1 / 0 |
开发者可以使用异常处理全面地控制自己的程序。异常处理不仅仅能够管理正常的流程运行,还能够在程序出错时对程序进行必的处理。大大提高了程序的健壮性和人机交互的友好性。
2.2 Why?
程序员的素养之一,就是写代码的时候尽可能考虑更多的边界, 想到更多的异常,并对可能会发生的异常做对应处理。从而保证自己代码的健壮性。
使用 Python 异常处理机制,可以让程序中的异常处理代码和正常业务代码分离,使得程序代码更加优雅,并可以提高程序的健壮性。
2.3 How?
Python 中,用try except语句块捕获并处理异常,其基本语法结构如下所示:
try:可能产生异常的代码块
except [ (Error1, Error2, ... ) [as e] ]:处理异常的代码块1
except [ (Error3, Error4, ... ) [as e] ]: # 一个Except可以处理多个异常处理异常的代码块2
except [Exception]: # 作为可选参数,可以代指程序可能发生的所有异常情况,其通常用在最后一个 except 块处理其它异常# 执行过程:# 1. 首先执行 try 中的代码块,如果执行过程中出现异常,系统会自动生成一个异常类型,并将该异常提交给 Python 解释器,此过程称为捕获异常# 2. 当 Python 解释器收到异常对象时,会寻找能处理该异常对象的 except 块,如果找到合适的 except 块,则把该异常对象交给该 except 块处理,这个过程被称为处理异常try:a = int(input("输入被除数:"))b = int(input("输入除数:"))c = a / bprint("您输入的两个数相除的结果是:", c )
except (ValueError, ArithmeticError):print("程序发生了数字格式异常、算术异常之一")
except :print("未知异常")
print("程序继续运行")# 获取特定异常的有关信息
# 每种异常类型都提供了如下几个属性和方法,通过调用它们,就可以获取当前处理异常类型的相关信息:# args:返回异常的错误编号和描述字符串;# str(e):返回异常信息,但不包括异常信息的类型;# repr(e):返回较全的异常信息,包括异常信息的类型。
try:1/0
except Exception as e:# 访问异常的错误编号和详细信息print(e.args) # ('division by zero',)print(str(e)) # division by zeroprint(repr(e)) # ZeroDivisionError('division by zero',)# 关于异常的更多信息,可以使用traceback 模块 该模块提供了一个标准接口来提取、格式化和打印 Python 程序的栈跟踪结果。
# 1. 直接打印异常
import traceback
try:raise SyntaxError, "traceback test"
except:traceback.print_exc()
# 2. 错误输出到日志
logger.info(traceback.format_exc())# try-except-else结构
# 使用 else 包裹的代码,只有当 try 块没有捕获到任何异常时,才会得到执行;反之,如果 try 块捕获到异常,即便调用对应的 except 处理完异常,else 块中的代码也不会得到执行。
try:result = 20 / int(input('请输入除数:'))print(result)
except ValueError:print('必须输入整数')
except ArithmeticError:print('算术错误,除数不能为 0')
else:print('没有出现异常')result = result * 2print("继续执行")print(result)# try-except-finally: 资源回收
# Python 异常处理机制还提供了一个 finally 语句,通常用来为 try 块中的程序做扫尾清理工作。
# 注意,和 else 语句不同,finally 只要求和 try 搭配使用,而至于该结构中是否包含 except 以及 else,对于 finally 不是必须的(else 必须和 try except 搭配使用)
# finally 语句的功能是:无论 try 块是否发生异常,最终都要进入 finally 语句,并执行其中的代码块。
# 当 try 块中的程序打开了一些物理资源(文件、数据库连接等)时,由于这些资源必须手动回收,而回收工作通常就放在 finally 块中。
# Python 垃圾回收机制,只能帮我们回收变量、类对象占用的内存,而无法自动完成类似关闭文件、数据库连接等这些的工作
try:#发生异常print(20/0)
[except xxx] # 可选
finally : # 肯定会执行print("执行 finally 块中的代码")# 所以最终的异常处理语法结构
try:#业务实现代码
except Exception1 as e:#异常处理块1...
except Exception2 as e:#异常处理块2...
#可以有多个 except
...
else:#正常处理块
finally :#资源回收块...# 使用注意# 在整个异常处理结构中,只有 try 块是必需的,也就是说:# except 块、else 块、finally 块都是可选的,当然也可以同时出现;# 可以有多个 except 块,但捕获父类异常的 except 块应该位于捕获子类异常的 except 块的后面;# 多个 except 块必须位于 try 块之后,finally 块必须位于所有的 except 块之后。# 要使用 else 块,其前面必须包含 try 和 except# else 语句块只有在没有异常发生的情况下才会执行
# finally 语句则不管异常是否发生都会执行。不仅如此,无论是正常退出、遇到异常退出,还是通过 break、continue、return 语句退出,finally 语句块都会执行
# 下面这个情况除外
try:os._exit(1) # 这个退出python解释器了
finally:print("执行finally语句")# 另外在通常情况下,不要在 finally 块中使用如 return 或 raise 等导致方法中止的语句(raise 语句将在后面介绍)
# 一旦在 finally 块中使用了 return 或 raise 语句,将会导致 try 块、except 块中的 return、raise 语句失效
def test():try:# 因为finally块中包含了return语句# 所以下面的return语句失去作用return Truefinally:return False
print(test())# 如果Python程序在执行try块、except块包含有return或raise语句,则Python解释器执行到该语句时,会先去查找finally块
# 如果没有finally块,程序才会立即执行return或 raise语句;反之,如果找到 finally 块,系统立即开始执行 finally 块
# 只有当 finally 块执行完成后,系统才会再次跳回来执行 try 块、except 块里的 return 或 raise 语句。
# 但是,如果在 finally 块里也使用了 return 或 raise 等导致方法中止的语句,finally 块己经中止了方法,系统将不会跳回去执行 try 块、except 块里的任何代码。
except匹配原理:

当 try 块捕获到异常对象后,Python 解释器会拿这个异常类型依次和各个 except 块指定的异常类进行比较,如果捕获到的这个异常类,和某个 except 块后的异常类一样,又或者是该异常类的子类,那么 Python 解释器就会调用这个 except 块来处理异常;反之,Python 解释器会继续比较,直到和最后一个 except 比较完,如果没有比对成功,则证明该异常无法处理。
注意, python的异常机制方便也能使代码健壮,但使用也得注意几点:
-
不要过度使用异常
- 把异常和普通错误混淆在一起,不再编写任何错误处理代码,而是以简单地引发异常来代苦所有的错误处理。
- 使用异常处理来代替流程控制
-
不要使用庞大的try块
-
不要忽略捕捉到的异常
既然己捕获到异常,那么 except 块理应做些有用的事情,及处理并修复异常。except 块整个为空,或者仅仅打印简单的异常信息都是不妥的!
except 块为空就是假装不知道甚至瞒天过海,这是最可怕的事情,程序出了错误,所有人都看不到任何异常,但整个应用可能已经彻底坏了。仅在 except 块里打印异常传播信息稍微好一点,但仅仅比空白多了几行异常信息。通常建议对异常采取适当措施,比如:
- 处理异常。对异常进行合适的修复,然后绕过异常发生的地方继续运行;或者用别的数据进行计算,以代替期望的方法返回值;或者提示用户重新操作……总之,程序应该尽量修复异常,使程序能恢复运行。
- 重新引发新异常。把在当前运行环境下能做的事情尽量做完,然后进行异常转译,把异常包装成当前层的异常,重新传给上层调用者。
- 在合适的层处理异常。如果当前层不清楚如何处理异常,就不要在当前层使用 except 语句来捕获该异常,让上层调用者来负责处理该异常。
2.4 raise用法
Python允许我们在程序中手动设置异常,使用 raise 语句即可。有些异常,是程序错误导致的运行异常,这种解释器会帮助我们抛出来,然后我们捕捉到进行处理,但还有些异常,是程序正常运行的结果,程序能正常运行,但是结果上可能不是我们想要的,这种情况我们也要考虑在内,然后用raise手动抛出, 再捕捉进行处理。
# 语法:raise [exceptionName [(reason)]], 常用方法# 1. raise:单独一个 raise。该语句引发当前上下文中捕获的异常(比如在 except 块中),或默认引发 RuntimeError 异常。# 2. raise 异常类名称:raise 后带一个异常类名称,表示引发执行类型的异常。# 2. raise 异常类名称(描述信息):在引发指定类型的异常的同时,附带异常的描述信息try:a = input("输入一个数:")#判断用户输入的是否为数字if(not a.isdigit()):# raise# raise ValueErrorraise ValueError("a 必须是数字")
except ValueError as e:print("引发异常:",repr(e))# assert断言也能起到调试的功效
try:s_age = input("请输入您的年龄:")age = int(s_age)assert 20 < age < 80 , "年龄不在 20-80 之间"print("您输入的年龄在20和80之间")
except AssertionError as e:print("输入年龄不正确",e)
2.5 自定义异常
实际开发中,有时候系统提供的异常类型不能满足开发的需求。这时就可以创建一个新的异常类来拥有自己的异常。
class InputError(Exception):'''当输出有误时,抛出此异常'''#自定义异常类型的初始化def __init__(self, value):self.value = value# 返回异常类对象的说明信息def __str__(self):return ("{} is invalid input".format(repr(self.value)))try:raise InputError(1) # 抛出 MyInputError 这个异常
except InputError as err:print('error: {}'.format(err))
需要注意的是,自定义一个异常类,通常应继承自 Exception 类(直接继承),当然也可以继承自那些本身就是从 Exception 继承而来的类(间接继承 Exception),命名上尽量以Error结尾,符合python的规范。

3. 文件操作
3.1 绝对路径和相对路径
在文件操作里面,首先得写对文件存在的路径,否则会报错找不到文件,所以这里先介绍几个常用的函数, 查看当前工作目录,以及修改工作目录,以及获取文件的绝对路径和相对路径来解决这个问题。
os.getcwd(): 获得当前工作路径的字符串os.chdir("xxx"): 改变当前工作目录# 获取到工作目录之后, 再查看文件的绝对和相对路径
# 绝对路径: 从根目录开始到当前文件
# 相对路径: 从当前工作目录开始到当前文件
os.path.abspath(path) 将返回 path 参数的绝对路径的字符串,这是将相对路径转换为绝对路径的简便方法。
os.path.isabs(path),如果参数是一个绝对路径,就返回 True,如果参数是一个相对路径,就返回 False。
os.path.relpath(path, start) 将返回从 start 路径到 path 的相对路径的字符串。如果没有提供 start,就使用当前工作目录作为开始路径。
os.path.dirname(path) 将返回一个字符串,它包含 path 参数中最后一个斜杠之前的所有内容;
os.path.basename(path) 将返回一个字符串,它包含 path 参数中最后一个斜杠之后的所有内容# 如果同时需要一个路径的目录名称和基本名称,就可以调用 os.path.split() 获得这两个字符串的元组, 这个内部就是按照最后一个/分开的, 自动获取dirname以及basename# 如果提供的路径不存在,许多 Python 函数就会崩溃并报错,但好在 os.path 模块提供了以下函数用于检测给定的路径是否存在,以及它是文件还是文件夹# 1. 如果 path 参数所指的文件或文件夹存在,调用 os.path.exists(path) 将返回 True,否则返回 False。# 2. 如果 path 参数存在,并且是一个文件,调用 os.path.isfile(path) 将返回 True,否则返回 False。# 3. 如果 path 参数存在,并且是一个文件夹,调用 os.path.isdir(path) 将返回 True,否则返回 False。
3.2 文件操作的基本步骤
这里说的文件操作主要是应用级别的操作, 也就是向文件里面写内容。 主要分为三步:
-
打开文件:使用
open()函数,该函数会返回一个文件对象;file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]]) print(file) # 文件对象# file_name: 文件名, 路径要写对 # mode: 可选参数,用于指定文件的打开模式。 读或写, 常用的如下:# 读: r(只读, 文件必须存在)、rb(二进制哥格式读,一般用于图片,视频, 文件必须存在)# 写: w,wb(写内容,文件不在则创建,会清空原来内容), a ab(追加模式打开文件,不会清除已有内容,文件不存在则创建) # buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区,建议使用缓冲区# 0(或者 False),则表示在打开指定文件时不使用缓冲区;大于1的整数,该整数用于指定缓冲区的大小(单位是字节);负数,则代表使用默认的缓冲区大小。一般默认即可# 计算机内存的 I/O 速度仍远远高于计算机外设(例如键盘、鼠标、硬盘等)的 I/O 速度,如果不使用缓冲区,则程序在执行 I/O 操作时,内存和外设就必须进行同步读写操作# 也就是说,内存必须等待外设输入(输出)一个字节之后,才能再次输出(输入)一个字节。这意味着,内存中的程序大部分时间都处于等待状态。# 如果使用缓冲区,则程序在执行输出操作时,会先将所有数据都输出到缓冲区中,然后继续执行其它操作,缓冲区中的数据会有外设自行读取处理;# 同样,当程序执行输入操作时,会先等外设将数据读入缓冲区中,无需同外设做同步读写操作。 # encoding:手动设定打开文件时所使用的编码格式# 常用属性 # 输出文件是否已经关闭 print(file.closed) # 输出访问模式 print(file.mode) #输出编码格式 print(file.encoding) # 输出文件名 print(file.name)# 文件读取, 二进制和普通模式有啥区别? 对换行符的处理有区别 # 在 Windows 系统中,文件中用 "\r\n" 作为行末标识符(即换行符),当以文本格式读取文件时,会将 "\r\n" 转换成 "\n"; # 反之,以文本格式将数据写入文件时,会将 "\n" 转换成 "\r\n"。 # 这种隐式转换换行符的行为,对用文本格式打开文本文件是没有问题的,但如果用文本格式打开二进制文件,就有可能改变文本中的数据(将 \r\n 隐式转换为 \n)。 # 在 Unix/Linux 系统中,默认的文件换行符就是 \n,因此在 Unix/Linux 系统中文本格式和二进制格式并无本质的区别# 所以windows里面,建议统一用二进制读取, linux里面,无区别,都可以# open() 函数打开文件并读取文件中的内容时,总是会从文件的第一个字符(字节)开始读起。 # 那么,有没有办法可以自定指定读取的起始位置呢?答案是肯定,这就需要移动文件指针的位置。 # 指针移动之后,用tell()函数,可以获取到指针当前的位置 # 用seek()函数,可以自定义读取位置 f = open("a.txt",'r') print(f.tell()) # 0 print(f.read(3)) print(f.tell()) # 3 f.seek(4) print(f.tell()) # 4 -
对已打开文件做读/写操作:读取文件内容可使用
read()、readline()以及readlines()函数;向文件中写入内容,可以使用write()函数。# 数据读取# read() 函数:逐个字节或者字符读取文件中的内容;# readline() 函数:逐行读取文件中的内容;# readlines() 函数:一次性读取文件中多行内# read(): 如果是普通文本模式打开的,会逐字符读取, 如果是二进制,则逐字节读取 # read时, 有时还会报错UnicodeDecodeError,原因在于,目标文件使用的编码格式和 open() 函数打开该文件时使用的编码格式不匹配。需要在open函数的encoding中,指定正确的编码格式 # readline(): 按行读取内容,遇到\n结束 # readlines(): 读取多行内容,放到一个列表里面f = open("my_file.txt",encoding = "utf-8") print(f.read(6))f = open("my_file.txt") byt = f.readline() # 读取一行, 还可以加最大读取限制f.readline(6) print(byt)f = open("my_file.txt",'rb') byt = f.readlines() print(byt) # [b"xxx", b"xxx"]# 写入数据# write()函数: 写入内容# writelines(): 逐行写入, 可以实现将字符串列表写入文件中, 需要注意的是,使用 writelines() 函数向文件中写入多行数据时,不会自动给各行添加换行符f = open("a.txt", 'w') # f = open("a.txt", 'a) # 追加写入 f.write("写入一行新数据") # 执行操作 f.flush() # 或者 f.close()# 在写入文件完成后,一定要调用 close() 函数将打开的文件关闭,否则写入的内容不会保存到文件中。 # 这是因为,当我们在写入文件内容时,操作系统不会立刻把数据写入磁盘,而是先缓存起来(放入缓冲区中),只有调用 close() 函数时,操作系统才会保证把没有写入的数据全部写入磁盘文件中。 # 如果不想立即关闭文件,用f.flush()也行# 所以,如果写入文本内容时, 缓冲区如果设置成0, 就会报错 f = open("a.txt", 'w',buffering = 0) # ValueError: can't have unbuffered text I/O -
关闭文件:完成对文件的读/写操作之后,最后需要关闭文件,可以使用
close()函数。注意,使用
open()函数打开的文件对象,必须手动进行关闭,Python 垃圾回收机制无法自动回收打开文件所占用的资源# 文件在打开并操作完成之后,就应该及时关闭,否则程序的运行可能出现问题 file.close()# 如果不关闭,后面想删除文件,会报错 # 如果不关闭, 写数据的时候,会写不进去,在向以文本格式(而不是二进制格式)打开的文件中写入数据时,Python 出于效率的考虑,会先将数据临时存储到缓冲区中, # 只有使用 close() 函数关闭文件时或者clush()刷新缓冲区时,才会将缓冲区中的数据真正写入文件中
3.3 python的with…as机制
任何一门编程语言中,文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。
但资源都是有限的,完成资源使用后,必须释放出来,不然就容易造成资源泄露,轻者使系统处理缓慢,严重时会使系统崩溃。
但有时候即便使用 close() 做好了关闭文件的操作,如果在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。
为了更好地避免此类问题,不同的编程语言都引入了不同的机制。python中对应的解决方式是使用 with…as…. 语句操作上下文管理器(context manager),它能够帮助我们自动分配并且释放资资源。
# 使用 with as 操作已经打开的文件对象(本身就是上下文管理器),无论期间是否抛出异常,都能保证 with as 语句执行完毕后自动关闭已经打开的文件。
with 表达式 [as target]:代码块with open('a.txt', 'a') as f:f.write("\nxxx")# 这个不用调用f.close就会自动写入到文件
这个用起来比较简单, 下面看下内部的原理。 首先啥叫上下文管理器呢?
简单的理解,同时包含
__enter__()和__exit__()方法的对象就是上下文管理器。也就是说,上下文管理器必须实现如下两个方法:
__enter__(self):进入上下文管理器自动调用的方法,该方法会在with...as代码块执行之前执行。如果 with 语句有 as子句,那么该方法的返回值会被赋值给 as 子句后的变量;该方法可以返回多个值,因此在 as 子句后面也可以指定多个变量(多个变量必须由“()”括起来组成元组)。__exit__(self, exc_type, exc_value, exc_traceback):退出上下文管理器自动调用的方法。该方法会在with…as代码块执行之后执行。如果with…as代码块成功执行结束,程序自动调用该方法,调用该方法的三个参数都为 None:如果with…as代码块因为异常而中止,程序也自动调用该方法,使用sys.exc_info得到的异常信息将作为调用该方法的参数。
当 with as 操作上下文管理器时,就会在执行语句体之前,先执行上下文管理器的 __enter__() 方法,然后再执行语句体,最后执行__exit__()方法
# 构建上下文管理器,有两种方法# 1. 基于类的上下文管理器
class FkResource:def __init__(self, tag):self.tag = tagprint('构造器,初始化资源: %s' % tag)# 定义__enter__方法,with体之前的执行的方法def __enter__(self):print('[__enter__ %s]: ' % self.tag)# 该返回值将作为as子句中变量的值return 'fkit' # 可以返回任意类型的值# 定义__exit__方法,with体之后的执行的方法def __exit__(self, exc_type, exc_value, exc_traceback):print('[__exit__ %s]: ' % self.tag)# exc_traceback为None,代表没有异常if exc_traceback is None:print('没有异常时关闭资源')else:print('遇到异常时关闭资源')return False # 可以省略,默认返回None也被看做是Falsewith FkResource('孙悟空') as dr:print(dr)print('[with代码块] 没有异常')
print('------------------------------')
with FkResource('白骨精'):print('[with代码块] 异常之前的代码')raise Exceptionprint('[with代码块] ~~~~~~~~异常之后的代码')构造器,初始化资源: 孙悟空
[__enter__ 孙悟空]:
fkit
[with代码块] 没有异常
[__exit__ 孙悟空]:
没有异常时关闭资源
------------------------------
构造器,初始化资源: 白骨精
[__enter__ 白骨精]:
[with代码块] 异常之前的代码
[__exit__ 白骨精]:
遇到异常时关闭资源
Traceback (most recent call last):File "script.py", line 25, in raise Exception
Exception# 从上面的输出结果来看,使用 with as 语句管理资源,无论代码块是否有异常,程序总可以自动执行 __exit__() 方法
# 注意,当出现异常时,如果 __exit__ 返回 False(默认不写返回值时,即为 False),则会重新抛出异常,让 with as 之外的语句逻辑来处理异常;
# 反之,如果返回 True,则忽略异常,不再对异常进行处理# 2. 基于生成器的上下文管理器
from contextlib import contextmanager
@contextmanager
def file_manager(name, mode):try:f = open(name, mode)yield ffinally:f.close()with file_manager('a.txt', 'w') as f:f.write('hello world')# 函数 file_manager() 就是一个生成器,当我们执行 with as 语句时,便会打开文件,并返回文件对象 f;当 with 语句执行完后,finally 中的关闭文件操作便会执行
# 基于类的上下文管理器和基于生成器的上下文管理器,这两者在功能上是一致的。
# 基于类的上下文管理器更加灵活,适用于大型的系统开发,而基于生成器的上下文管理器更加方便、简洁,适用于中小型程序。
# 但是,无论使用哪一种,不用忘记在方法“__exit__()”或者是 finally 块中释放资源,这一点尤其重要。
3.4 文件处理方面的常用模块汇总
3.4.1 pickle模块
pickle模块能够实现任意对象与文本之间的相互转化,也可以实现任意对象与二进制之间的相互转化。也就是说,pickle 可以实现 Python 对象的存储及恢复。
# 1. 基于内存的 Python 对象与二进制互转# dumps():将 Python 中的对象序列化成二进制对象,并返回;# loads():读取给定的二进制对象数据,并将其转换为 Python 对象;
port pickle
tup1 = ('I love Python', {1,2,3}, None)
#使用 dumps() 函数将 tup1 转成 p1
p1 = pickle.dumps(tup1)
print(p1)
#使用 loads() 函数将 p1 转成 Python 对象
t2 = pickle.loads(p1)
print(t2)# 2. 基于文件的 Python 对象与二进制互转# dump():将 Python 中的对象序列化成二进制对象,并写入文件;# load():读取指定的序列化数据文件,并返回对象
import pickle
tup1 = ('I love Python', {1,2,3}, None)
#使用 dumps() 函数将 tup1 转成 p1
with open ("a.txt", 'wb') as f: #打开文件pickle.dump(tup1, f) #用 dump 函数将 Python 对象转成二进制对象文件
with open ("a.txt", 'rb') as f: #打开文件t3 = pickle.load(f) #将二进制文件对象转换成 Python 对象print(t3)# 这个简单看看, 用的不是很多了, 原因是不能在多语言之间共享,另外 pickle 不支持并发地访问持久性对象,在复杂的系统环境下,尤其是读取海量数据时,使用 pickle 会使整个系统的I/O读取性能成为瓶颈。
3.4.2 fileinput模块
fileinput模块:里面有个input函数能同时打开指定的多个文件,还可以逐个读取这些文件中的内容
import fileinput
#使用for循环遍历 fileinput 对象
for line in fileinput.input(files=('my_file.txt', 'file.txt')):# 输出读取到的内容print(line)
# 关闭文件流
fileinput.close()# 这里面一个简单的应用就是先用glob扫到某个目录下面所有txt文件,然后组成一个tuple, 再用这个函数去读取
3.4.3 os.path模块
os.path模块: 这个有一些路径判断好用的函数整理一下
# os.path.abspath(path) 返回 path 的绝对路径。
# os.path.basename(path) 获取 path 路径的基本名称,即 path 末尾到最后一个斜杠的位置之间的字符串。
# os.path.commonprefix(list) 返回 list(多个路径)中,所有 path 共有的最长的路径。
# os.path.dirname(path) 返回 path 路径中的目录部分。
# os.path.exists(path) 判断 path 对应的文件是否存在,如果存在,返回 True;反之,返回 False。和 lexists() 的区别在于,exists()会自动判断失效的文件链接(类似 Windows 系统中文件的快捷方式),而 lexists() 却不会。
# os.path.getatime(path) 返回 path 所指文件的最近访问时间(浮点型秒数)。
# os.path.getmtime(path) 返回文件的最近修改时间(单位为秒)。
# os.path.getctime(path) 返回文件的创建时间(单位为秒,自 1970 年 1 月 1 日起(又称 Unix 时间))。
# os.path.getsize(path) 返回文件大小,如果文件不存在就返回错误。# os.path.isabs(path) 判断是否为绝对路径。
# os.path.isfile(path) 判断路径是否为文件。
# os.path.isdir(path) 判断路径是否为目录。# os.path.join(path1[, path2[, ...]]) 把目录和文件名合成一个路径。
# os.path.realpath(path) 返回 path 的真实路径。
# os.path.relpath(path[, start]) 从 start 开始计算相对路径。
# os.path.samefile(path1, path2) 判断目录或文件是否相同。
# os.path.split(path) 把路径分割成 dirname 和 basename,返回一个元组。# os.path.walk(path, visit, arg) 遍历path,进入每个目录都调用 visit 函数,visit 函数必须有 3 个参数(arg, dirname, names),dirname 表示当前目录的目录名,names 代表当前目录下的所有文件名,args 则为 walk 的第三个参数。
3.4.4 tempfile模块
tempfile模块: 专门用于创建临时文件和临时目录, 这个实际中还是比较常用的,临时存储一下很方便
# 常用方法
# tempfile.TemporaryFile(mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None) 创建临时文件。该函数返回一个类文件对象,也就是支持文件 I/O。
# tempfile.NamedTemporaryFile(mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None, delete=True) 创建临时文件。该函数的功能与上一个函数的功能大致相同,只是它生成的临时文件在文件系统中有文件名。
# tempfile.TemporaryDirectory(suffix=None, prefix=None, dir=None) 生成临时目录。
# tempfile.gettempdir() 获取系统的临时目录。# temporarydictory的使用:
# 我一般喜欢存储文件到云的时候,用这个在本地做一层缓存
def _save_csv(self, df):with tempfile.TemporaryDirectory() as tmpdirname:temp_file = os.path.join(tmpdirname, 'tag_statistic.csv')df.to_csv(temp_file, encoding='utf-8-sig')tag_file = os.path.join(self._mount_path, self._workdir, self._input_path, "tag_statistic.csv")with open(temp_file, 'rb') as f:data_bytes = f.read()with open(tag_file, "wb") as f:f.write(data_bytes)# 上传到云upload_ks3(temp_file, remote_file)# 从远程下载压缩包解压,我喜欢用临时目录存储,处理
with TemporaryDirectory() as temp_dir:urllib.request.urlretrieve(artifact_url, f"{temp_dir}/artifact_tar.tar.gz")with tarfile.open(f"{temp_dir}/artifact_tar.tar.gz") as f:base_dir = f"{temp_dir}/artifact"os.mkdir(base_dir)f.extractall(base_dir)# 处理里面的文件# 临时文件 上传到云用
with tempfile.NamedTemporaryFile(mode='w') as temp_file:json.dump(json_list, temp_file)temp_file.seek(0)ks3_util = KS3Util(env=KS3EnvEnum.online.value, bucket=KS3BucketEnum.ad_warehouse_online.value)ks3_util.upload_file(temp_file.name, ks3_file)
3.5 常见文件格式的写入和读取
这里整理python读写不同格式常用的代码模板。
# json文件:这个非常好用, 也是我现在最常用的方式
# 原因是json文件内容灵活,什么字典,列表等都可以存进去,读起来也方便,另外跨语言也没问题, 传输也方便
**#** 读取JSON文件
****with open('example.json', 'r') as file:data = json.load(file) # load方法用于从一个文件句柄中读取JSON数据。# 如果这里用json.loads,要这样写# data = json.loads(file.read()) # 用于将一个JSON格式的字符串转换为Python的数据结构, loads loading string的缩写print(data)with open('xxx.json', 'w') as f:f.write(json.dumps(data))# or json.dump(data, f)# txt文件
with open('example.txt', 'r') as file:content = file.read()print(content)
# 写入文本文件
with open('example.txt', 'w') as file:file.write("Hello, World!")
4. 小总
这篇文章算是作为python过程中的一些辅助了,在实际的项目中, 这两块内容还是很重要的,异常处理可以帮助我们更好的掌控代码, 写出鲁棒性的代码, 而文件操作可以帮助我们对数据更好的读取处理, 都是一些非常实用的内容。
参考
- C语言中文网教程
相关文章:
python实践笔记(三): 异常处理和文件操作
1. 写在前面 最近在重构之前的后端代码,借着这个机会又重新补充了关于python的一些知识, 学习到了一些高效编写代码的方法和心得,比如构建大项目来讲,要明确捕捉异常机制的重要性, 学会使用try...except..finally&…...

Excel VLOOKUP 使用记录
Excel VLOOKUP 使用记录 VLOOKUP简单使用 VLOOKUP(lookup_value,table_array,col_index_num,[range-lookup]) 下面是excel对VLOOKUP 的解释 lookup_value(查找值):要匹配查找的值 table_array(数据表)࿱…...
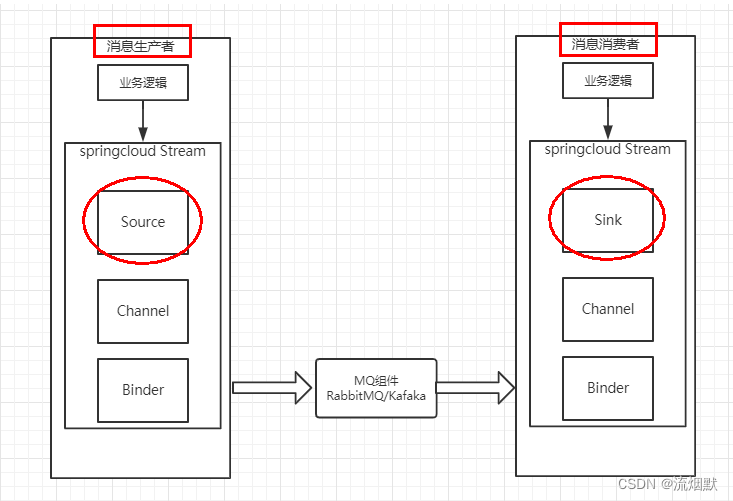
Spring Cloud Stream 消息驱动基础入门与实践总结
Spring Cloud Stream是用于构建与共享消息传递系统连接的高度可伸缩的事件驱动微服务框架,该框架提供了一个灵活的编程模型,它建立在已经建立和熟悉的Spring熟语和最佳实践上,包括支持持久化的发布/订阅、消费组以及消息分区这三个核心概念。…...

你好rust
第一次安装rust,记录一下笔记。 几年前就听说过rust,自己一直是个c爱好者,所以比较抵触rust,早年还有什么rust向上突破群。一直比较抵触,直到这几年rust已经渐渐深入到linux内核、云原生可观测以及zend社区当中&#x…...
STM32 printf 重定向到CAN
最近在调试一款电机驱动板 使用的是CAN总线而且板子上只有一个CAN 想移植Easylogger到上面试试easylogger的效果,先实现pritnf的重定向功能来打印输出 只需要添加以下代码即可实现 代码 #include <stdarg.h> uint8_t FDCAN_UserTxBuffer[512]; void FDCAN_p…...
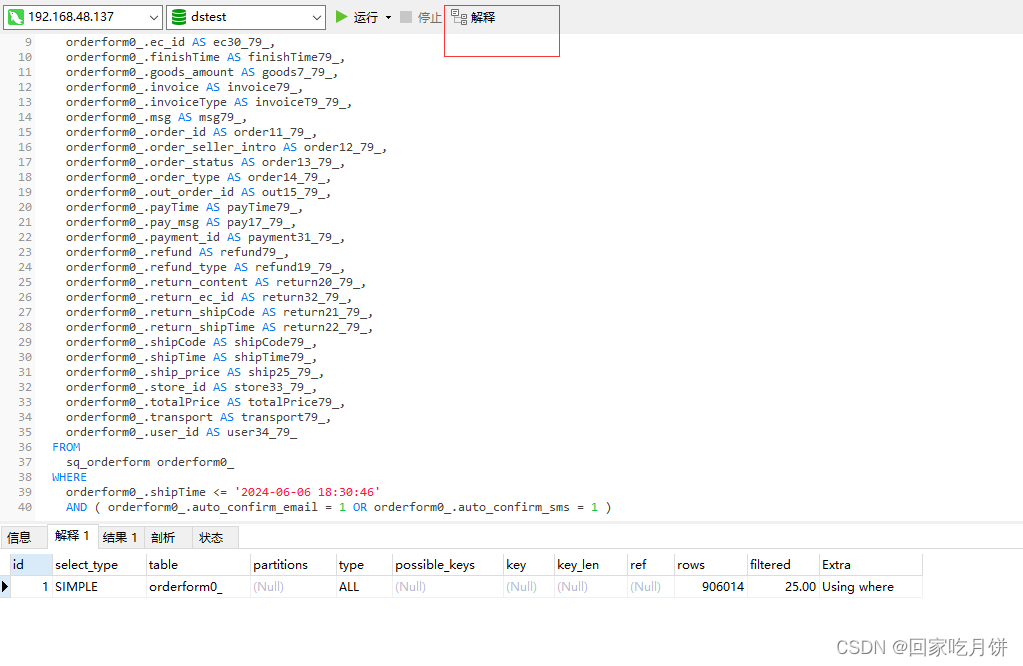
jmeter性能优化之mysql监控sql慢查询语句分析
接上次博客:基础配置 多用户登录并退出jmx文件:百度网盘 提取码:0000 一、练习jmeter脚本检测mysql慢查询 随意找一个脚本(多用户登录并退出),并发数设置300、500后分别查看mysql监控平台 启动后查看,主要查看mysql…...

海南聚广众达电子商务咨询有限公司引领行业变革
在数字化浪潮席卷全球的今天,电商行业正以前所未有的速度发展。海南聚广众达电子商务咨询有限公司,凭借其在抖音电商领域的深厚积累和不断创新,正逐步成为行业的佼佼者。这家以专注、专业、专注为核心理念的公司,不仅为客户提供全…...
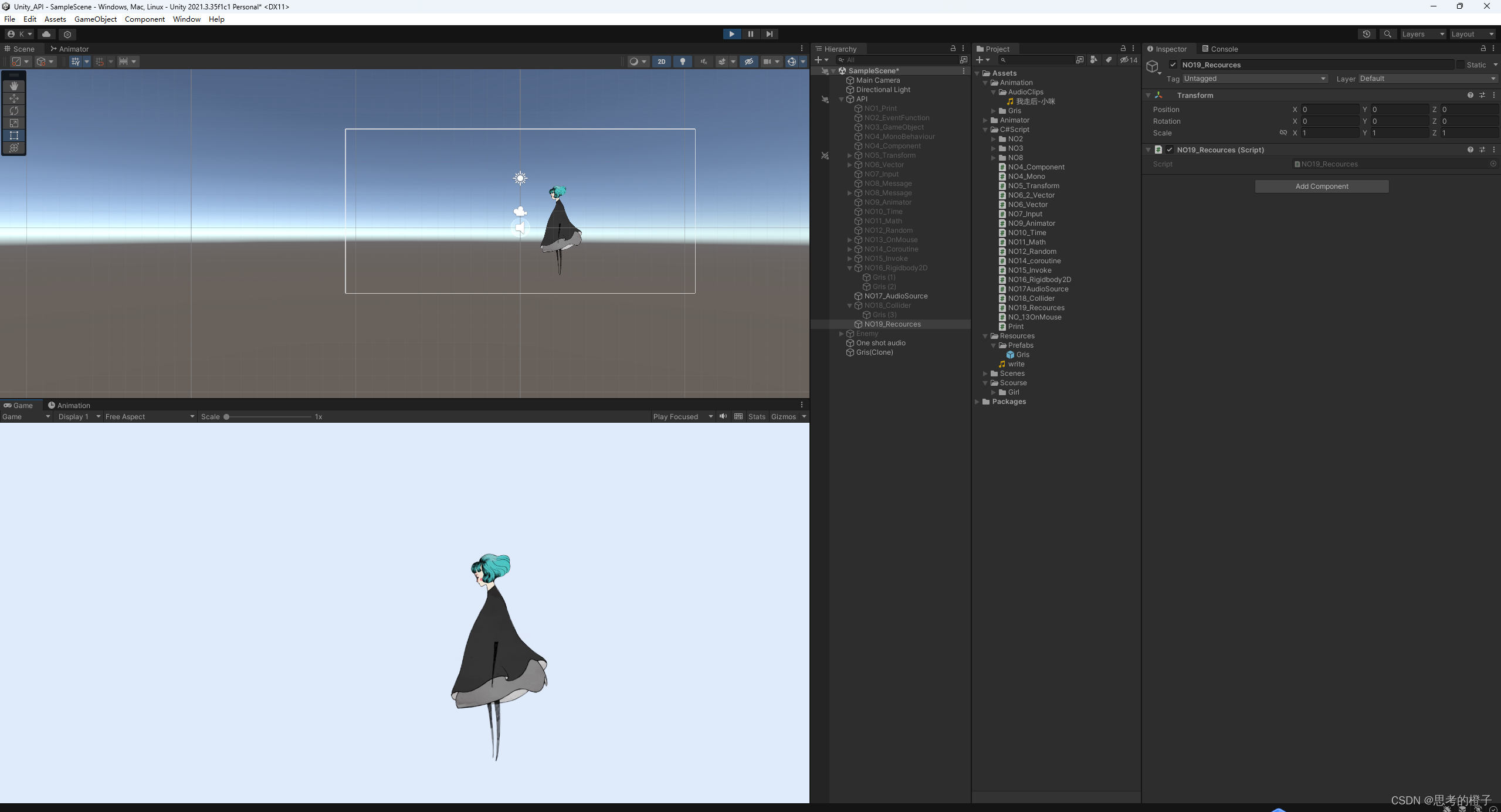
Unity API学习之资源的动态加载
资源的动态加载 在实际游戏开发的更新换代中,随着开发的软件不断更新,我们在脚本中需要拖拽赋值的变量会变空,而要想重新拖拽又太花费时间,因此我们就需要用到Resources.Load<文件类型>("文件名")函数来在一开始…...

C++算法——回溯
回溯算法 实现思想 先看一个实例: //暴力枚举的算法 int n 5; for (int a 1; i < n; i) {for (int b 1; b < n; b){for (int c 1; c < n; c){for (int d 1; d < n; d){for (int e 1; e < n; e){//判断 abcde 是否互补相同if (a ! b &&a…...

java的深拷贝和浅拷贝
总结: 深拷贝:无论是基本类型还是引用类型都会创建新的实例。 浅拷贝:对于基本类型就是复制其值,对于引用类型则是复制了指向这些数据类型的内存地址。 浅拷贝(Shallow Copy) 浅拷贝是指在创建新对象时&am…...

AI产品经理,应掌握哪些技术?
美国的麻省理工学院(Massachusetts Institute of Technology)专门负责科技成果转化商用的部门研究表明: 每一块钱的科研投入,需要100块钱与之配套的投资(人、财、物),才能把思想转化为产品&…...

同三维T80004EHL-W-4K30 4K HDMI编码器,支持WEBRTC协议
输入:1路HDMI1路3.5音频,1路HDMI环出1路3.5音频解嵌输出 4K30超高清,支持U盘/移动硬盘/TF卡录制,支持WEBRTC协议,超低延时,支持3个点外网访问 1个主流1个副流输出,可定制选配POE供电模块,WEBR…...

Hi3861 OpenHarmony嵌入式应用入门--点灯
本篇实现对gpio的控制,通过控制输出进行gpio的点灯操作。 硬件 我们来操作IO2,控制绿色的灯。 软件 GPIO API API名称 说明 hi_u32 hi_gpio_deinit(hi_void); GPIO模块初始化 hi_u32 hi_io_set_pull(hi_io_name id, hi_io_pull val); 设置某个IO…...
SaaS案例分享:成功构建销售渠道的实战经验
面对SaaS产品推广的难题,你是否曾感到迷茫,不知如何选择有效的销售渠道?Shopify独立站联盟营销或许能为你提供新的思路。Shopify作为领先的电商解决方案提供商,其独立站功能为众多商家提供了强大的在线销售平台。而联盟营销&#…...
密钥管理简介
首先我们要知道什么是密钥管理? 密钥管理是一种涉及生成、存储、使用和更新密钥的过程。 密钥的种类 我们知道,对称密码主要包括分组密码和序列密码。但有时也可以将杂凑函数和消息认证码划分为这一类,将它们的密钥称为对称密钥;…...

2024中国应急(消防)品牌巡展成都站成功召开!
汇聚品牌力量,共同相聚成都。6月14日,由中国安全产业协会指导,中国安全产业协会应急创新分会、应急救援产业网联合主办,四川省消防协会协办的“一切为了安全”2024年中国应急(消防)品牌巡展-成都站成功举办。该巡展旨在展示中国应…...

ansible-Role角色批量按照node_export节点,并追加信息到Prometheus文件中
文章目录 剧本功能 inventory.yaml文件定义deploy.yaml角色定义node_exporter_lock角色定义任务角色main.yamlnode_exporter_tasks.yml角色触发任务notifyextra_tasks.yml角色prometheus_node_config.j2模板文件 执行命令查看变量 剧本功能 功能1: 批量执行node_ex…...

求最小公倍数 、小球走过路程计算 题目
题目 JAVA11 求最小公倍数分析:代码:大佬代码: JAVA12 小球走过路程计算分析:代码: JAVA11 求最小公倍数 描述 编写一个方法,该方法的返回值是两个不大于100的正整数的最小公倍数。 输入描述:…...

【Android面试八股文】你能说一说为什么IO是耗时操作?
IO(输入/输出)操作之所以是耗时操作,主要是由于以下几个原因: 1. 物理设备的限制 机械动作:传统的硬盘驱动器(HDD)包含旋转的磁盘和移动的磁头,以读取或写入数据。这些机械动作需要时间完成。虽然固态硬盘(SSD)没有机械部件,但它们仍然受到电子信号传输速度的限制。…...

怎样增强 CLike 游戏的社交功能,促进玩家之间的互动和交流?
要增强CLike游戏的社交功能,以促进玩家之间的互动和交流,可以考虑以下几个方面: 添加聊天功能:在游戏中加入实时聊天功能,让玩家可以在游戏内互相交流。可以通过文本聊天或者语音聊天来实现。 社交平台集成࿱…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...
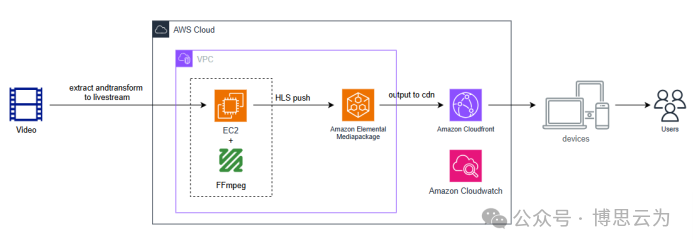
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...

OpenGL-什么是软OpenGL/软渲染/软光栅?
软OpenGL(Software OpenGL)或者软渲染指完全通过CPU模拟实现的OpenGL渲染方式(包括几何处理、光栅化、着色等),不依赖GPU硬件加速。这种模式通常性能较低,但兼容性极强,常用于不支持硬件加速…...

Pandas 可视化集成:数据科学家的高效绘图指南
为什么选择 Pandas 进行数据可视化? 在数据科学和分析领域,可视化是理解数据、发现模式和传达见解的关键步骤。Python 生态系统提供了多种可视化工具,如 Matplotlib、Seaborn、Plotly 等,但 Pandas 内置的可视化功能因其与数据结…...

安宝特方案丨从依赖经验到数据驱动:AR套件重构特种装备装配与质检全流程
在高压电气装备、军工装备、石油测井仪器装备、计算存储服务器和机柜、核磁医疗装备、大型发动机组等特种装备生产型企业,其产品具有“小批量、多品种、人工装配、价值高”的特点。 生产管理中存在传统SOP文件内容缺失、SOP更新不及、装配严重依赖个人经验、产品装…...
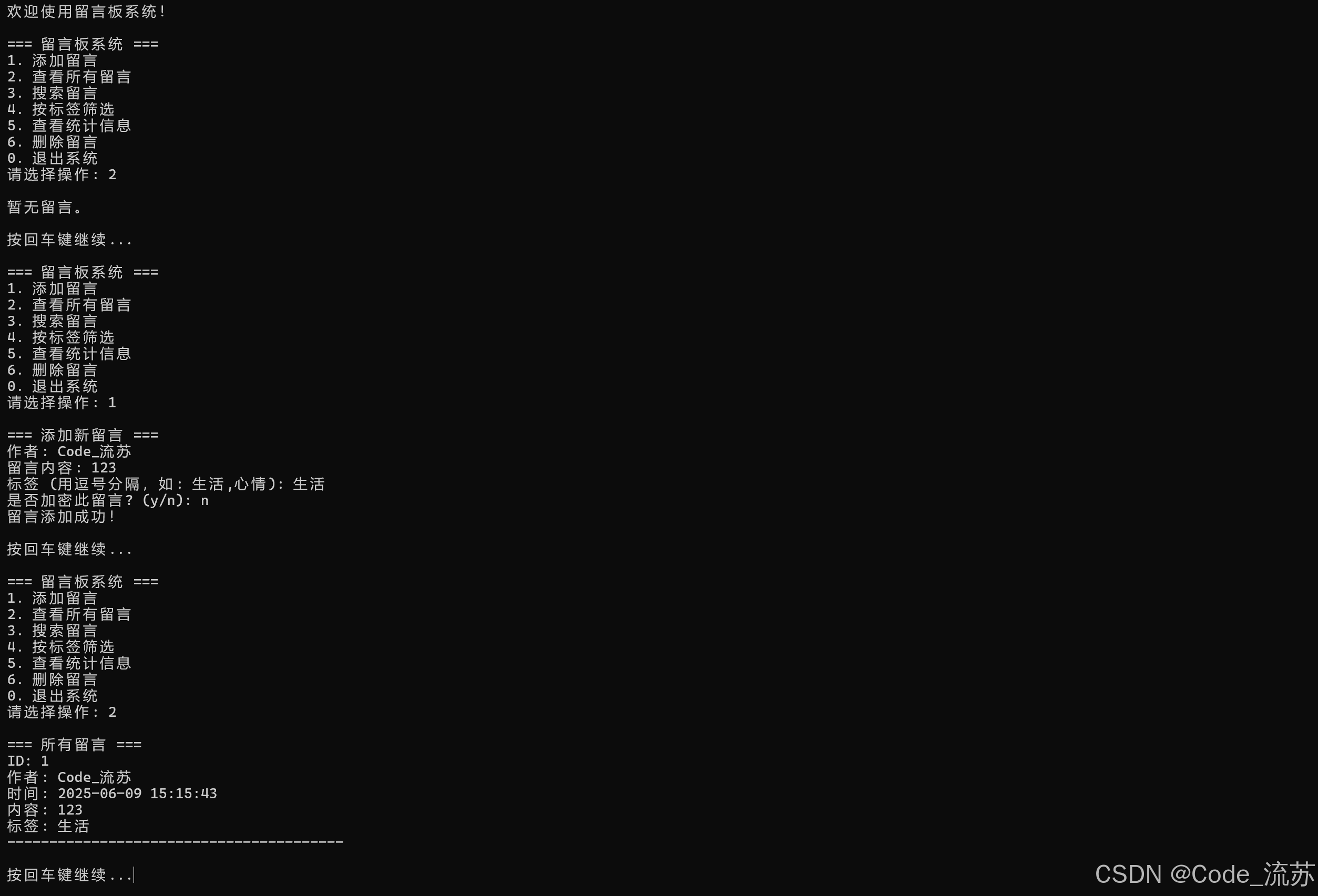
C++课设:实现本地留言板系统(支持留言、搜索、标签、加密等)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、项目功能概览与亮点分析1. 核心功能…...