Linux自旋锁
面对没有获取锁的现场,通常有两种处理方式。
- 互斥锁:堵塞自己,等待重新调度请求
- 自旋锁:循环等待该锁是否已经释放
本文主要讲述自旋锁
自旋锁其实是一种很乐观的锁,他认为只要再等一下下锁便能释放,避免了操作系统进程调度和线程切换。
自旋锁演进
- 传统TAS自旋锁:只有0、1两张状态,线程无序抢锁,不公平
- ticket based自旋锁:状态表示为两个counter——owner、next,线程有序持有锁,公平持锁
- queued自旋锁:只有一个线程自旋在spinlock,其他线程在自己的per cpu mcs lock自旋
ticket spinlock
ticket spinlock通过当前服务号来确定当前获取锁的对象,每一个对象在获取锁时都会获取到自己的服务号,当当前服务号与自己服务号一致时,就说明获取到锁
这有些像去外面吃饭等餐,先去服务员那里取号,然后空出位置来,服务员就会叫下一个号
typedef struct {union {u32 slock;struct __raw_tickets {
#ifdef __ARMEB__u16 next;u16 owner;
#elseu16 owner;u16 next;
#endif} tickets;};
} arch_spinlock_t;
以下以ARMv6 体系结构的 ticket-based 自旋锁为例
static inline void arch_spin_lock(arch_spinlock_t *lock)
{// 临时变量,用于存储中间结果unsigned long tmp;// 新的锁值u32 newval;// 当前锁的值arch_spinlock_t lockval;// 预取指令,提前加载 lock->slock 到缓存,以减少锁操作的内存访问延迟prefetchw(&lock->slock);// 使用 ARM 汇编代码实现的原子操作:// • ldrex %0, [%3]:加载并排他地读取 lock->slock 的值到 lockval。// • add %1, %0, %4:将 lockval 增加一个票数,存储到 newval。// • strex %2, %1, [%3]:尝试将 newval 写回 lock->slock,并将结果存储到 tmp。// • teq %2, #0:检查 tmp 是否为 0,表示写回操作是否成功。// • bne 1b:如果写回操作失败,跳回到 1 继续尝试。__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b": "=&r" (lockval), "=&r" (newval), "=&r" (tmp): "r" (&lock->slock), "I" (1 << TICKET_SHIFT): "cc");// 检查当前票数是否为锁的所有者票数,确保锁按照票数顺序被获取。如果当前票数不是所有者票数,处理器将进入低功耗等待状态,直到锁的所有者票数更新为当前票数while (lockval.tickets.next != lockval.tickets.owner) {wfe();lockval.tickets.owner = READ_ONCE(lock->tickets.owner);}// 内存屏障,确保在获取锁后所有的内存操作在锁的获取之后发生。这是因为 ARMv6 CPU 假设内存是弱顺序的(weakly ordered),需要内存屏障来保证操作顺序smp_mb();
}// 解锁
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{smp_mb();lock->tickets.owner++;dsb_sev();
}
在旧的自旋锁实现中,所有争用一个锁的处理器都会争来争去,看谁能先得到它。现在他们整齐地排队等候,按到达的顺序抢锁。多线程的运行时间甚至减少了,最大延迟也减少了(更重要的是,使其成为确定性的)。Nick说,新实现有轻微的成本,但在当代处理器上的成本非常小,相对于缓存未命中的成本基本上为零——这是处理争用锁时常见的事件。x86的维护者显然认为,消除自旋锁不合适的争夺所带来的好处超过了这个小成本;其他人似乎不太可能不同意。
以下是go实现版本
type ticketLock struct {// 记录当前服务号nowServing uint32// 记录下一个服务号nextTicket uint32
}// NewTicketLock instantiates a ticket-lock.
func NewTicketLock() *ticketLock {return &ticketLock{}
}// Lock locks the ticket-lock.
func (t *ticketLock) Lock() {// 递增下一个服务号,并获取当前服务号myTicket := atomic.AddUint32(&t.nextTicket, 1) - 1// 自旋等待直到轮到自己for myTicket != atomic.LoadUint32(&t.nowServing) {runtime.Gosched()}
}// Unlock unlocks the ticket-lock.
func (t *ticketLock) Unlock() {// 递增当前服务号atomic.AddUint32(&t.nowServing, 1)
}
mcs spinlock
mcs是简单的自旋锁,具有公平性,每个CPU在尝试获取锁时会在本地变量上自旋,从而避免了test-and-set自旋锁实现中的昂贵缓存争用。
mcsNode问题在于空间占用大,这对于操作系统并不是好消息
#ifndef __LINUX_MCS_SPINLOCK_H
#define __LINUX_MCS_SPINLOCK_H#include <asm/mcs_spinlock.h>struct mcs_spinlock {// 指向下一个等待的节点struct mcs_spinlock *next;// 表示锁是否被获取。1已获取0未获取int locked; /* 1 if lock acquired */// 用于嵌套计数int count; /* nesting count, see qspinlock.c */
};#ifndef arch_mcs_spin_lock_contended
// 使用smp_cond_load_acquire提供获取语义,确保后续操作在锁被获取后进行
#define arch_mcs_spin_lock_contended(l) \
do { \smp_cond_load_acquire(l, VAL); \
} while (0)
#endif#ifndef arch_mcs_spin_unlock_contended// 使用smp_store_release提供内存屏障,确保临界区的所有操作在解锁前完成
#define arch_mcs_spin_unlock_contended(l) \smp_store_release((l), 1)
#endifstatic inline
void mcs_spin_lock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{struct mcs_spinlock *prev;// 初始化节点,将locked设为0,next设为NULLnode->locked = 0;node->next = NULL;// 使用xchg函数交换锁变量和当前节点,获取前驱节点。// 通过使用 xchg(),我们确保了在 xchg() 之前对 @node 的所有初始化存储操作是正确排序的,并且这些操作在全局范围内被其他处理器或线程正确地看到。此外,这个 xchg() 指令还提供了与锁相关的 ACQUIRE 排序,以确保在获取锁时正确的内存可见性。prev = xchg(lock, node);// 如果前驱节点为空,说明锁已被获取,直接返回if (likely(prev == NULL)) {return;}// 否则,将前驱节点的next指针指向当前节点,并等待锁持有者传递锁WRITE_ONCE(prev->next, node);// 在节点的 locked 变量上自旋,直到前一个持有锁的线程将其设置为解锁状态arch_mcs_spin_lock_contended(&node->locked);
}/** Releases the lock. The caller should pass in the corresponding node that* was used to acquire the lock.*/
static inline
void mcs_spin_unlock(struct mcs_spinlock **lock, struct mcs_spinlock *node)
{// 获取当前节点的下一个节点指针struct mcs_spinlock *next = READ_ONCE(node->next);// 如果没有下一个节点,尝试将锁设为NULL(使用cmpxchg_release)if (likely(!next)) {// 如果成功,直接返回if (likely(cmpxchg_release(lock, node, NULL) == node))return;// 否则,等待下一个节点的next指针被设置while (!(next = READ_ONCE(node->next)))cpu_relax();}// 将锁传递给下一个等待节点arch_mcs_spin_unlock_contended(&next->locked);
}#endif /* __LINUX_MCS_SPINLOCK_H */
以下是尝试仿照得到的go实现
type mcsNode struct {next *mcsNodewaiting uint32
}type mcsLock struct {tail *mcsNode
}func newMCSLock() *mcsLock {return &mcsLock{}
}func (m *mcsLock) Lock(node *mcsNode) {// 初始化 node 节点,将其 next 设为 nil,并将 waiting 设为 1,表示该节点正在等待node.next = nilnode.waiting = 1// 使用 atomic.SwapPointer 将锁的 tail 指向当前节点,并返回先前的 tail(即前一个等待锁的节点)predecessor := (*mcsNode)(atomic.SwapPointer((*unsafe.Pointer)(unsafe.Pointer(&m.tail)), unsafe.Pointer(node)))// 如果先前没有其他等待节点(即 pred 为 nil),当前节点直接获得锁。if predecessor != nil {// 如果有前一个节点,将当前节点的 next 指向当前节点,并在 waiting 变量上自旋等待,直到前一个节点将 waiting 设为 0,表示锁已释放predecessor.next = nodefor atomic.LoadUint32(&node.waiting) == 1 {// 在等待期间,使用 runtime.Gosched() 函数让出当前线程,以便其他线程可以获得CPU时间片runtime.Gosched()}}
}func (m *mcsLock) Unlock(node *mcsNode) {// 如果当前节点的 next 为 nil,表示没有其他节点在等待锁,直接将 tail 设为 nil,释放锁if node.next == nil {if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&m.tail)), unsafe.Pointer(node), nil) {return}// 如果 CAS 操作失败,表示有其他节点在等待锁,等待其它节点将 waiting 设为 0for node.next == nil {runtime.Gosched()}}// 如果当前节点的 next 不为 nil,将 next 节点的 waiting 设为 0,表示锁已释放atomic.StoreUint32(&node.next.waiting, 0)
}qspinlock
qspinlock基于MCS锁(队列锁),并结合锁状态,旨在提高多处理器系统中的性能,特别是在NUMA(非统一内存访问)系统中
MCS锁在NUMA系统中表现得接近最佳,因为每个CPU只关注自己的队列条目,极大减少了处理器之间的缓存行传递
其主要原理如下:
- 基于MCS锁的队列机制
- 每个等待获取锁的CPU在一个每CPU结构数组中有一个专用的mcs_spinlock结构。
- 当锁被占用时,CPU会将自己添加到一个队列中,并在自己的mcs_spinlock结构上自旋,减少对共享锁变量的访问,从而减少缓存行的争用。
- 32位锁字段设计
- 锁字段被分为多个部分,包括一个整数计数器(类似于锁定字段)、一个两位索引字段(指示队列尾部的条目)、一个单个位的“pending”字段和一个整数字段(保存队列尾部的CPU编号)
- 优化策略
- 当CPU是下一个获取锁的候选者时,它会直接在锁本身上自旋,而不是在其每CPU结构上自旋,减少缓存行的访问
- 如果锁被占用但没有其他CPU在等待,CPU会设置“pending”位,不使用其mcs_spinlock结构,直到有第二个CPU加入队列
- 为了防止锁在某个节点上过长时间停留,如果主队列在一定时间内(默认10毫秒)没有清空,整个次要队列将被提升到主队列的头部,强制锁转移到另一个节点。
typedef struct qspinlock {union {atomic_t val;/** By using the whole 2nd least significant byte for the* pending bit, we can allow better optimization of the lock* acquisition for the pending bit holder.*/
#ifdef __LITTLE_ENDIANstruct {// 持锁状态u8 locked;// 是否有pending线程。// 1表示有thread正自旋在spinlock上,0表示没有pending threadu8 pending;};struct {// 锁位和等待位u16 locked_pending;// 指向mcs node队列的尾部节点// 这个队列中的thread有两种状态:头部的节点对应的thread自旋在pending+locked域,其他节点自旋在其自己的mcs lock上。u16 tail;};
#elsestruct {u16 tail;u16 locked_pending;};struct {u8 reserved[2];u8 pending;u8 locked;};
#endif};
} arch_spinlock_t;
qspinlock由locked、pending和tail的三元组表示。常见状态组合有
- 0、0、0: 代表初始状态
- 0、0、1: 代表仅有一个thread持有锁,无等待及MCS队列
- 0、1、1: 代表锁被持有且存在等待者
- n、1、1: 代表锁被持有、存在等待者且存在一个MCS队列
- *、1、1: 代表锁被持有、存在等待者且存在多个MCS队列
状态迁移图如下

流程
线程以T表示
-
初始锁状态为(0, 0, 0),T1直接获取锁成功
(0, 0, 0) -> (0, 0, 1)
-
T2获取锁,设置等待位,并等待锁释放
(0, 0, 1) -> (0, 1, 1)
在获取锁之后,将会重置等待位,并设置锁
(0, 1, 1) -> (0, 0, 1)
-
T3获取锁,由于锁被持有且存在等待,直接进入队列等待锁
-
由于队列仅有T3一个等待者,所以一直自旋等待锁非锁持有且等待位的情况出现,也就是锁被释放,且没有等待者
以下是代码详细解释
获取锁时先快速判断是否无任何竞争状态,然后直接加锁
/*** queued_spin_lock - acquire a queued spinlock* @lock: Pointer to queued spinlock structure*/
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{u32 val = 0;// 首先尝试直接获取锁,如果锁可用(lock->val 为 0),则获取锁并返回// 此处对应(0, 0, 0)->(0, 0, 1)if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL)))return;// 如果锁不可用,则进入慢路径,加入等待队列queued_spin_lock_slowpath(lock, val);
}
接着走入慢路径
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{struct mcs_spinlock *prev, *next, *node;u32 old, tail;int idx;// 检查系统配置和虚拟化情况// ... /** 0,1,0 -> 0,0,1*/// 如果仅有等待者,说明锁被释放,但等待着还未获取锁,则有限等待锁被获取if (val == _Q_PENDING_VAL) {int cnt = _Q_PENDING_LOOPS;val = atomic_cond_read_relaxed(&lock->val,(VAL != _Q_PENDING_VAL) || !cnt--);}// 若除锁状态位以外的其他位被设置,说明有队列等待,或者存在等待位,则直接队列等待if (val & ~_Q_LOCKED_MASK)goto queue;/** trylock || pending** 0,0,* -> 0,1,* -> 0,0,1 pending, trylock*/// 设置等待位val = queued_fetch_set_pending_acquire(lock);// 再次检测竞争状态if (unlikely(val & ~_Q_LOCKED_MASK)) {/* Undo PENDING if we set it. */if (!(val & _Q_PENDING_MASK))clear_pending(lock);goto queue;}/** 0,1,1 -> 0,1,0*/// 处于仅持有状态,说明可以直接去等待持有锁了if (val & _Q_LOCKED_MASK)atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_MASK));/** 0,1,0 -> 0,0,1*/// 获取锁。清除pending位,设置lockedclear_pending_set_locked(lock);lockevent_inc(lock_pending);return;queue:lockevent_inc(lock_slowpath);
pv_queue:// 初始化MCS节点// 获取当前CPU上的MCS节点node = this_cpu_ptr(&qnodes[0].mcs);// 增加MCS节点计数器idx = node->count++;// 编码尾指针,包含当前 CPU 的 ID 和 MCS 节点索引tail = encode_tail(smp_processor_id(), idx);// 检查MCS节点数量。如果当前 CPU 的 MCS 节点数量超过最大值 MAX_NODES,则进入自旋锁的等待循环if (unlikely(idx >= MAX_NODES)) {lockevent_inc(lock_no_node);while (!queued_spin_trylock(lock))cpu_relax();goto release;}// 获取MCS节点node = grab_mcs_node(node, idx);/** Keep counts of non-zero index values:*/lockevent_cond_inc(lock_use_node2 + idx - 1, idx);barrier();// 初始化node->locked = 0;node->next = NULL;pv_init_node(node);// 再次尝试直接获取锁if (queued_spin_trylock(lock))goto release;smp_wmb();/*** p,*,* -> n,*,**/// 设置节点到锁尾位中old = xchg_tail(lock, tail);next = NULL;// 如果MCS节点不为空,则获取上一个节点,将当前节点加入等待队列,直到当前节点解锁if (old & _Q_TAIL_MASK) {prev = decode_tail(old);/* Link @node into the waitqueue. */WRITE_ONCE(prev->next, node);pv_wait_node(node, prev);arch_mcs_spin_lock_contended(&node->locked);// 在等待 MCS 锁的时候,尝试提前加载下一个指针并预取它的缓存行,以减少即将进行的 MCS 解锁操作的延迟next = READ_ONCE(node->next);if (next)prefetchw(next);}// 与Paravirtualization有关,暂忽略// ... // 等待锁释放且无等待位val = atomic_cond_read_acquire(&lock->val, !(VAL & _Q_LOCKED_PENDING_MASK));locked:// 如果等待者就是当前节点,那么直接重置锁为仅持有锁// (n, 0, 1) -> (0, 0, 1)if ((val & _Q_TAIL_MASK) == tail) {if (atomic_try_cmpxchg_relaxed(&lock->val, &val, _Q_LOCKED_VAL))goto release; /* No contention */}// 若MCS队列中还有其他节点,则设置锁位// (n, 0, 0) -> (n, 0, 1)set_locked(lock);// 解除下一个节点的自旋if (!next)next = smp_cond_load_relaxed(&node->next, (VAL));arch_mcs_spin_unlock_contended(&next->locked);pv_kick_node(lock, next);release:// 释放当前cpu的MCS节点// 也就是MCS节点数量递减__this_cpu_dec(qnodes[0].mcs.count);
}
EXPORT_SYMBOL(queued_spin_lock_slowpath);/** We must be able to distinguish between no-tail and the tail at 0:0,* therefore increment the cpu number by one.*/static inline __pure u32 encode_tail(int cpu, int idx)
{u32 tail;tail = (cpu + 1) << _Q_TAIL_CPU_OFFSET;tail |= idx << _Q_TAIL_IDX_OFFSET; /* assume < 4 */return tail;
}static inline __pure struct mcs_spinlock *decode_tail(u32 tail)
{int cpu = (tail >> _Q_TAIL_CPU_OFFSET) - 1;int idx = (tail & _Q_TAIL_IDX_MASK) >> _Q_TAIL_IDX_OFFSET;return per_cpu_ptr(&qnodes[idx].mcs, cpu);
}/*** set_locked - Set the lock bit and own the lock* @lock: Pointer to queued spinlock structure** *,*,0 -> *,0,1*/
static __always_inline void set_locked(struct qspinlock *lock)
{WRITE_ONCE(lock->locked, _Q_LOCKED_VAL);
}/** xchg_tail - Put in the new queue tail code word & retrieve previous one* @lock : Pointer to queued spinlock structure* @tail : The new queue tail code word* Return: The previous queue tail code word** xchg(lock, tail), which heads an address dependency** p,*,* -> n,*,* ; prev = xchg(lock, node)*/
static __always_inline u32 xchg_tail(struct qspinlock *lock, u32 tail)
{/** We can use relaxed semantics since the caller ensures that the* MCS node is properly initialized before updating the tail.*/return (u32)xchg_relaxed(&lock->tail,tail >> _Q_TAIL_OFFSET) << _Q_TAIL_OFFSET;
}
解锁就很简单了,直接设置锁位为0就可以了
static inline void queued_spin_unlock(struct qspinlock *lock)
{// Release the lockatomic_set(&lock->val, 0);
}以下是仿照qspinlock思想所做出的go版本实现
import ("runtime""sync/atomic"
)const (// LOCKED 表示锁被持有LOCKED uint32 = 1 << iota// PENDING 表示锁被持有,但有等待者PENDING// TAIL 表示等待者MCS节点尾部TAIL// LOCKED_PENDING_MASK 表示锁的状态LOCKED_PENDING_MASK = LOCKED | PENDING// PENDING_CLEAR_MASK 表示清除等待标记PENDING_CLEAR_MASK uint32 = ^PENDING// LOCKED_CLEAR_MASK 表示清除锁标记LOCKED_CLEAR_MASK uint32 = ^LOCKED// TAIL_OFFSET 表示尾部索引偏移TAIL_OFFSET = 2// TAIL_MASK 表示尾部索引掩码,用于检查尾部索引是否存在TAIL_MASK uint32 = 0xFFFFFFFC// MCS_UNLOCKED MCS解锁状态MCS_UNLOCKED uint32 = 1// COUNT_ADD_MASK 计数掩码COUNT_ADD_MASK uint64 = 1<<32 | 1// COUNT_INDEX_MASK 计数索引掩码COUNT_INDEX_MASK uint64 = 0xFFFFFFFF// COUNT_SUB_MASK 计数减法掩码COUNT_SUB_MASK uint64 = 0xFFFFFFFF00000000
)type qspinlock struct {val uint32count uint64
}type qmcsNode struct {locked uint32next *qmcsNodereleased bool
}const (maxMcsNodeCount = 16maxTrySetCount = 1000
)var (qnodes = make([]*qmcsNode, maxMcsNodeCount)
)func init() {for i := 0; i < maxMcsNodeCount; i++ {qnodes[i] = &qmcsNode{}}
}// atomicCondReadAcquire 自旋直到 addr 的值满足 condition
func atomicCondReadAcquire(addr *uint32, condition func(uint32) bool) uint32 {var val uint32for {val = atomic.LoadUint32(addr)if condition(val) {break}runtime.Gosched() // Yield the processor}return val
}// clearPendingSetLocked 清除等待标记,设置锁标记
func clearPendingSetLocked(lock *qspinlock) {for {// 读取当前值old := atomic.LoadUint32(&lock.val)// 如果锁已经被持有,这是不应该出现的情况if old&LOCKED != 0 {panic("clearPendingSetLocked: Lock By Others")}// 计算新值,清除等待标记,设置锁标记val := old & PENDING_CLEAR_MASKval |= LOCKED// 尝试更新变量值if atomic.CompareAndSwapUint32(&lock.val, old, val) {break}// 如果更新失败,继续尝试}
}// trySetPending 尝试设置等待标记
func trySetPending(lock *qspinlock) bool {var old uint32loopCount := maxTrySetCountfor loopCount > 0 {// 若已经被设置等待标记,则说明等待位已经被其他线程设置,直接返回old = atomic.LoadUint32(&lock.val)if old&PENDING != 0 {return false}// 尝试设置等待标记if atomic.CompareAndSwapUint32(&lock.val, old, old|PENDING) {return true}loopCount--}return false
}// setLocked 设置锁标记
func setLocked(lock *qspinlock) {for {// 读取当前值old := atomic.LoadUint32(&lock.val)// 设置锁标记val := old | LOCKED// 如果锁已经被持有,则退出if val == old {panic("setLocked: Lock By Others")}// 尝试更新变量值if atomic.CompareAndSwapUint32(&lock.val, old, val) {break}// 如果更新失败,继续尝试}
}// xchgTail 将尾部索引设置到锁变量中
func xchgTail(lock *qspinlock, tail uint32) uint32 {var old uint32for {// 读取当前值old = atomic.LoadUint32(&lock.val)// 计算新值,将尾部索引设置到变量中val := (old & LOCKED_PENDING_MASK) | tail// 尝试更新变量值if atomic.CompareAndSwapUint32(&lock.val, old, val) {break}// 如果更新失败,继续尝试}return old
}// queuedSpinTryLock 快速尝试获取锁
func queuedSpinTryLock(lock *qspinlock) bool {return atomic.CompareAndSwapUint32(&lock.val, 0, LOCKED)
}// decodeTail 解析尾部索引
func decodeTail(tail uint32) *qmcsNode {idx := tail >> TAIL_OFFSETreturn qnodes[idx-1]
}// encodeTail 编码尾部索引。索引从1开始
func encodeTail(idx uint32) uint32 {return (idx + 1) << TAIL_OFFSET
}// 锁计数以及索引递增
// Attention! 索引递增上限度为1<<32-1
func increaseLockCount(count *uint64) (uint32, uint32) {x := atomic.AddUint64(count, COUNT_ADD_MASK)return uint32((x-1)&COUNT_INDEX_MASK) & (maxMcsNodeCount - 1), uint32(x >> 32)
}// 锁计数递减
func decreaseLockCount(count *uint64) {atomic.AddUint64(count, COUNT_SUB_MASK)
}func (l *qspinlock) Lock() {val := atomic.LoadUint32(&l.val)if val == 0 && queuedSpinTryLock(l) {return}queuedSpinLockSlowPath(l, val)
}func queuedSpinLockSlowPath(lock *qspinlock, val uint32) {var old, tail uint32var node, next *qmcsNodevar success bool// b1 若仅有等待位,则等待非仅有等待位// b2 若仅有加锁位,则进入a逻辑if val == PENDING {val = atomicCondReadAcquire(&lock.val, func(v uint32) bool {return v != PENDING})}if val != LOCKED {goto queue}// a1 若原来仅有加锁位,则尝试设置等待位// a2 等待位设置成功后,等待获取锁,并设置锁位// a3 若等待位设置失败,则队列等待锁success = trySetPending(lock)if success {atomicCondReadAcquire(&lock.val, func(v uint32) bool {return v&LOCKED == 0})clearPendingSetLocked(lock)return}// 队列等待锁// c1. 申请一个MCS节点// c2. 将MCS节点尾部索引设置到锁中// c3. 若设置成功前的MCS节点已经存在,则获取上一个节点,添加到队列中,并等待上一个节点的解锁(主动解锁,或者不存在)// c4. 等待无加锁等待位// c5. 若当前尾节点就是当前节点,则尝试重置为仅有锁位// c6. 若当前尾节点不是当前节点,则获取下一个节点并解锁// c7. 设置锁位
queue:idx, count := increaseLockCount(&lock.count)if count > maxMcsNodeCount {for !queuedSpinTryLock(lock) {runtime.Gosched()}goto release}node = qnodes[idx]node.locked = 0node.next = nilnode.released = falsetail = encodeTail(idx)old = xchgTail(lock, tail)if old&TAIL_MASK != 0 {prev := decodeTail(old)if !prev.released {prev.next = nodeatomicCondReadAcquire(&node.locked, func(v uint32) bool {return v == MCS_UNLOCKED || prev.released})}}val = atomicCondReadAcquire(&lock.val, func(v uint32) bool {return v&LOCKED_PENDING_MASK == 0})if tail == val&TAIL_MASK {if atomic.CompareAndSwapUint32(&lock.val, val, LOCKED) {goto release}}next = node.nextnode.released = trueif next != nil {atomic.StoreUint32(&next.locked, MCS_UNLOCKED)}setLocked(lock)release:decreaseLockCount(&lock.count)
}func (l *qspinlock) Unlock() {for {// 读取当前值old := atomic.LoadUint32(&l.val)// 如果锁未被持有,继续if old&LOCKED == 0 {runtime.Gosched()continue}// 计算新值,清除锁标记val := old & LOCKED_CLEAR_MASK// 尝试更新变量值if atomic.CompareAndSwapUint32(&l.val, old, val) {break}// 如果更新失败,继续尝试}
}
Ref
- https://lwn.net/Articles/267968/
- https://lwn.net/Articles/852138/
- http://www.wowotech.net/kernel_synchronization/queued_spinlock.html
- https://elixir.bootlin.com/linux/v5.5-rc2/source
相关文章:
Linux自旋锁
面对没有获取锁的现场,通常有两种处理方式。 互斥锁:堵塞自己,等待重新调度请求自旋锁:循环等待该锁是否已经释放 本文主要讲述自旋锁 自旋锁其实是一种很乐观的锁,他认为只要再等一下下锁便能释放,避免…...
服务器----阿里云服务器重启或关机,远程连接进不去,个人博客无法打开
问题描述 在使用阿里云免费的新加坡服务器时,发现重启或者是关机在开服务器后,就会出现远程连接不上、个人博客访问不了等问题 解决方法 进入救援模式连接主机,用户名是root,密码是自己设置的 点击访问博客查看更多内容...

go 定时任务
在 Go 语言中,可以使用内置的 time 包来实现定时任务。以下是一个简单的示例: go package main import ( "fmt" "time" ) func main() { timer : time.NewTimer(2 * time.Second) <-timer.C fmt.Println(…...
Java Character 类
Java Character 类 Character 类用于对单个字符进行操作。 Character 类在对象中包装一个基本类型 char 的值 char ch a;// Unicode 字符表示形式char uniChar \u039A; // 字符数组char[] charArray { a, b, c, d, e };然而,在实际开发过程中,我们经…...

MQTT协议应用场景
MQTT协议的应用场景非常丰富,特别是在物联网领域。以下是对MQTT协议应用场景的清晰归纳: 1.物联网设备控制和监控:MQTT被广泛应用于物联网设备之间的通信,如智能家居、智能城市和工业自动化等领域。设备可以发布自身状态到特定主题…...

3.4.马氏链-随机游走的常返性
随机游走的常返态 1. 随机游走常返性定义1.1. 随机游走常返值和可能集1.2. 随机游走常返性2. 简单随机游走: 维数与常返性的关系2.1. 简单随机游走2.2. 二维及以下简单随机游走常返, 三维及以上简单随机游走非常返3. 随机游走 ( d ≤ 2 ) (d\leq 2) (d≤2): 常返的充分条件4. 随…...

HOT100与剑指Offer
文章目录 前言一、41. 缺失的第一个正数(HOT100)二、6. 从尾到头打印链表(剑指Offer)总结 前言 一个本硕双非的小菜鸡,备战24年秋招,计划刷完hot100和剑指Offer的刷题计划,加油! 根…...
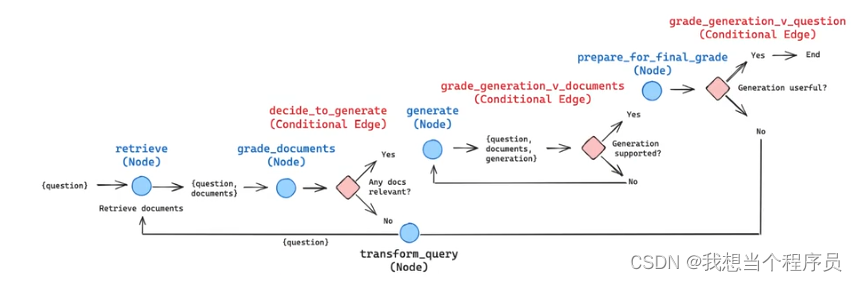
【AI开发】CRAG、Self-RAG、Adaptive-RAG
先放一张基础RAG的流程图 https://blog.langchain.dev/agentic-rag-with-langgraph/ 再放一个CRAG和self-RAG的LangChain官方博客 Corrective RAG(CRAG) 首先需要知道的是CRAG的特色发生在retrieval阶段的最后开始,即当我们获得到了近似的document(或者…...

FFmpeg中内存分配和释放相关的源码:av_malloc函数、av_mallocz函数、av_free函数和av_freep函数分析
一、av_malloc函数分析 (一)av_malloc函数的声明 av_malloc函数的声明放在在FFmpeg源码(本文演示用的FFmpeg源码版本为5.0.3,该ffmpeg在CentOS 7.5上通过10.2.1版本的gcc编译)的头文件libavutil/mem.h中:…...

七天进阶elasticsearch[Four]
依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>...

数据库-数据定义和操纵-DDL语言的使用
创建一个数据库: create database 数据库名; 选择数据库: use 数据库名; 创建表 create table 表名( ); 添加字段; ALTER TABLE 表名 ADD 新字段名 数据类型 [约束条件] [FIRST|AFTER 已存在字段名] ; 删除字段: ALTER TABLE 表…...

黄金价格与美元的关系变了?
在一些传统的定价框架中,现货黄金的价格走势取,决于美元的实际利率水平——实际利率越高,黄金价格越低,反之亦然。在大多数的时候,美元的实际利率决定了美元指数的高低所以人们通常认为,现货金价与美元呈反…...

VB.net与C# 调用InitializeComponent的区别
VB.NET与C# 调用InitializeComponent的区别 在VB.NET和C#中,InitializeComponent 方法的调用方式有所不同。 C#: 在C#中,InitializeComponent 方法通常是在构造函数中显式调用的。它用于初始化窗体和控件的属性。代码示例如下: public pa…...
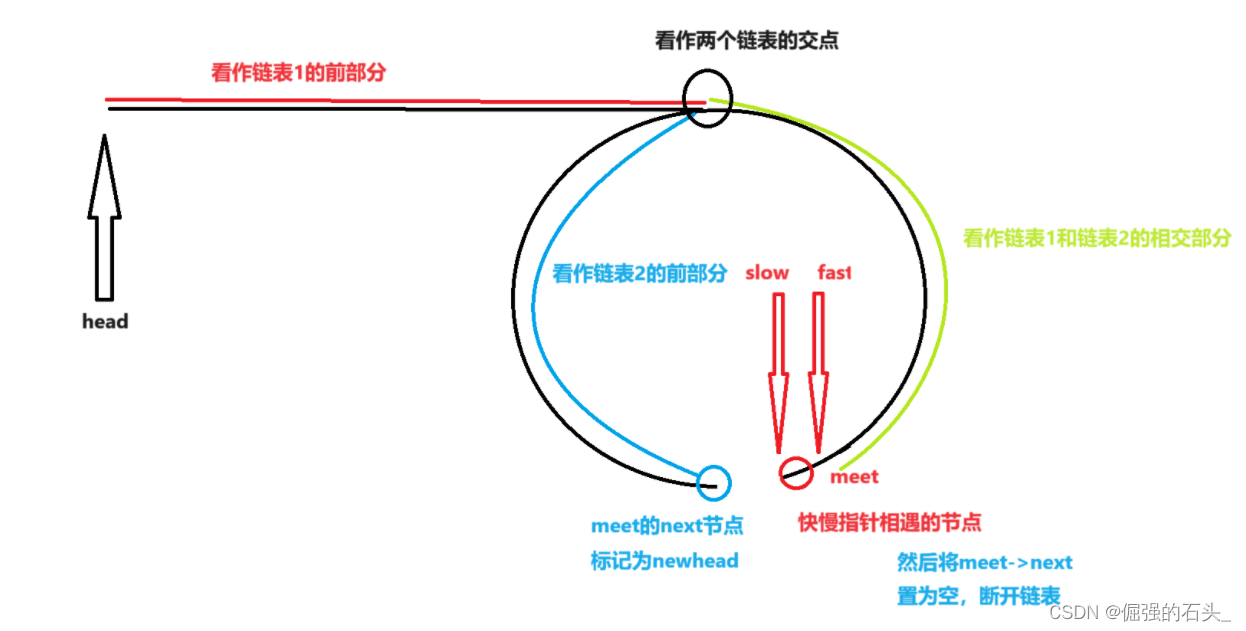
【数据结构与算法 刷题系列】求带环链表的入环节点(图文详解)
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《数据结构与算法 经典例题》C语言 期待您的关注 目录 一、问题描述 二、解题思路 方法一:数学公式推导法 方法…...

独立游戏之路:Tap篇 -- Unity 集成 TapTap 广告详细步骤
Unity 集成 TapADN 广告详细步骤 前言一、TapTap 广告介绍二、集成 TapTap 广告的步骤2.1 进入广告后台2.2 创建广告计划2.3 选择广告类型三、代码集成3.1 下载SDK3.2 工程配置3.3 源码分享四、常见问题4.1 有展现量没有预估收益 /eCPM 波动大?4.2 新建正式媒体找不到预约游戏…...
设计灵感源泉!7个令人赞叹的网页界面设计展示
网页的界面设计主要是指视觉设计和风格设计。高质量的界面更容易吸引用户的注意力,从而更准确地向用户传达信息。对于设计师来说,他们需要从高质量的作品中获得稳定的灵感,以帮助他们更高效地实现设计目标。在本文中,梳理了7个高质…...
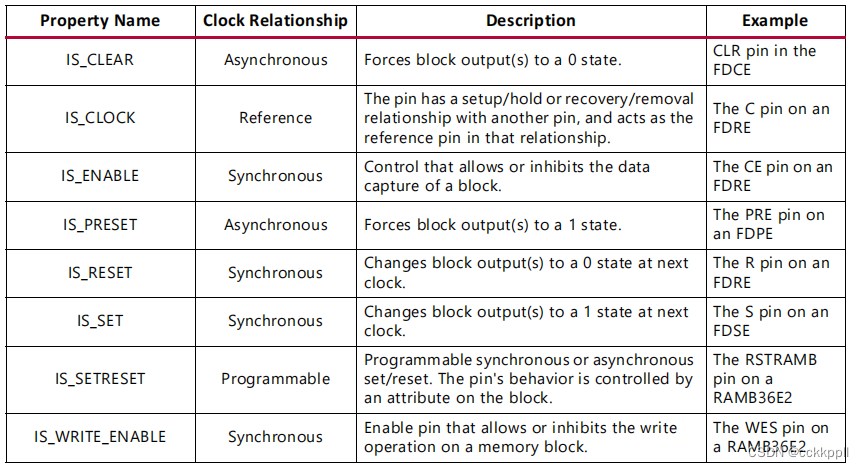
vivado PIN
描述 引脚是基元或层次单元上的逻辑连接点。引脚允许 要抽象掉单元格的内容,并简化逻辑以便于使用。引脚可以 是标量的,包含单个连接,或者可以定义为对多个进行分组的总线引脚 信号在一起。 相关对象 引脚连接到一个单元,并且可以…...

docker部署mysql+nginx+redis
部署mysql 1、拉去镜像 docker search mysql docker pull mysql:5.7 2、运行镜像 docker run -p 3306:3306 --name mysql \ -v /home/mysql/log:/var/log/mysql \ -v /home/mysql/data:/var/lib/mysql \ -v /home/mysql/conf:/etc/mysql/conf.d \ -v /home/mysql/mysql-files…...

python文件操作、文件操作、读写文件、写模式
with读取文件数据内容 with open(filepath,mode,encoding) as file:#具体操作,例如:print(file.read())#查看文件所有的内容。 with:Python中的一个上下文管理器,用于简化资源的管理和释放。它可以用于任意需要进行资源分配和释放的情境…...

【亲测可用】docker进入正在运行的容器
微信公众号:leetcode_algos_life,代码随想随记 小红书:412408155 CSDN:https://blog.csdn.net/woai8339?typeblog ,代码随想随记 GitHub: https://github.com/riverind 抖音【暂未开始,计划开始】…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...
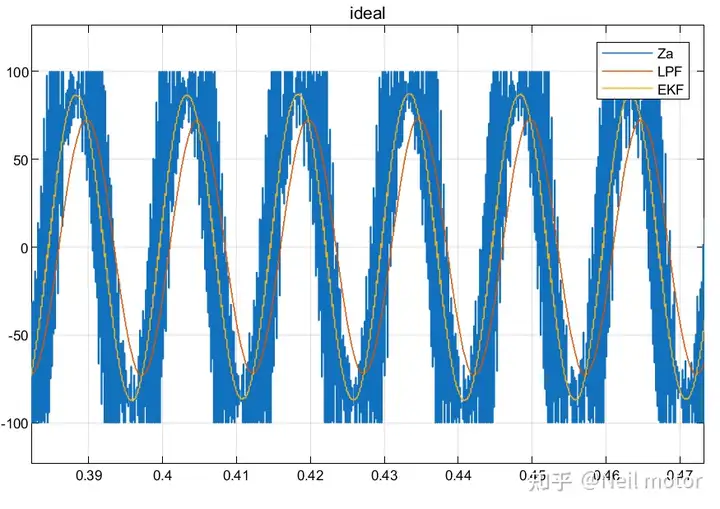
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...
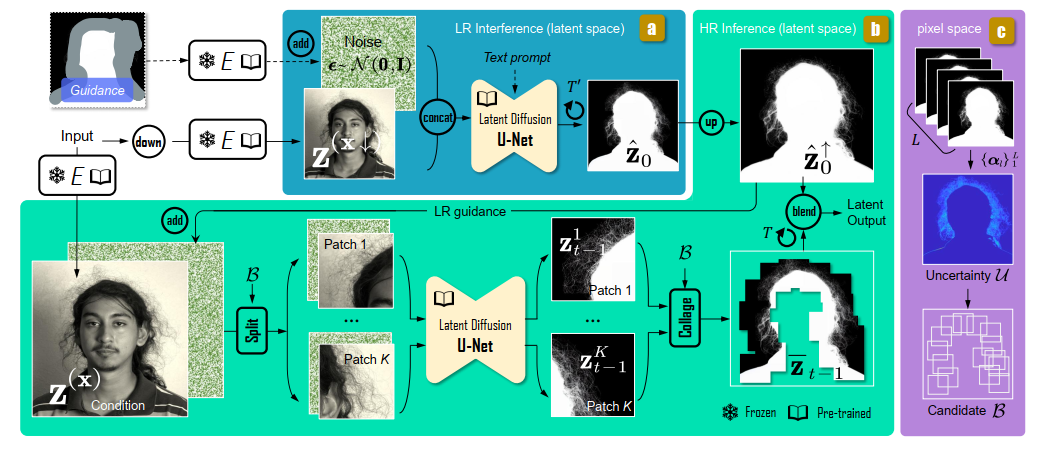
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...
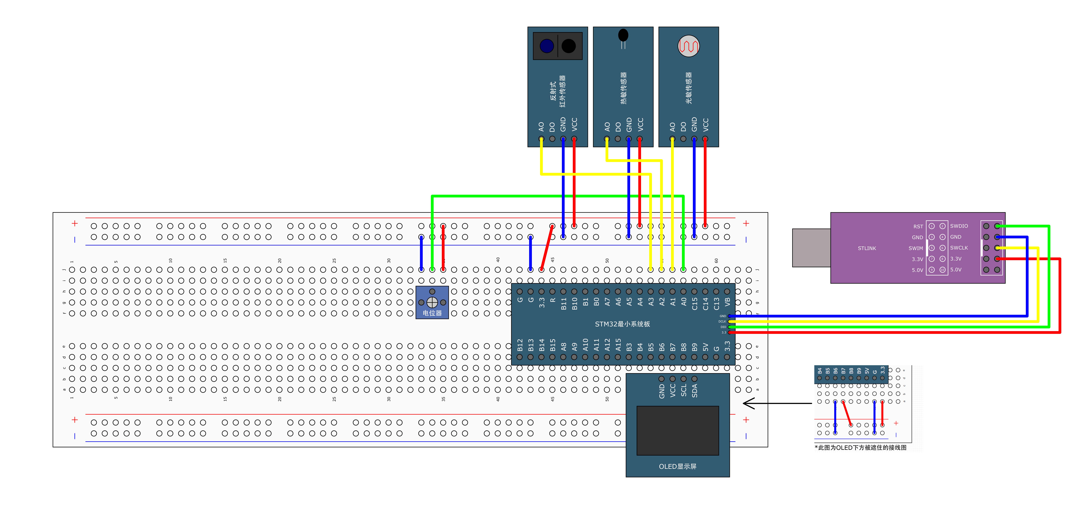
STM32标准库-ADC数模转换器
文章目录 一、ADC1.1简介1. 2逐次逼近型ADC1.3ADC框图1.4ADC基本结构1.4.1 信号 “上车点”:输入模块(GPIO、温度、V_REFINT)1.4.2 信号 “调度站”:多路开关1.4.3 信号 “加工厂”:ADC 转换器(规则组 注入…...
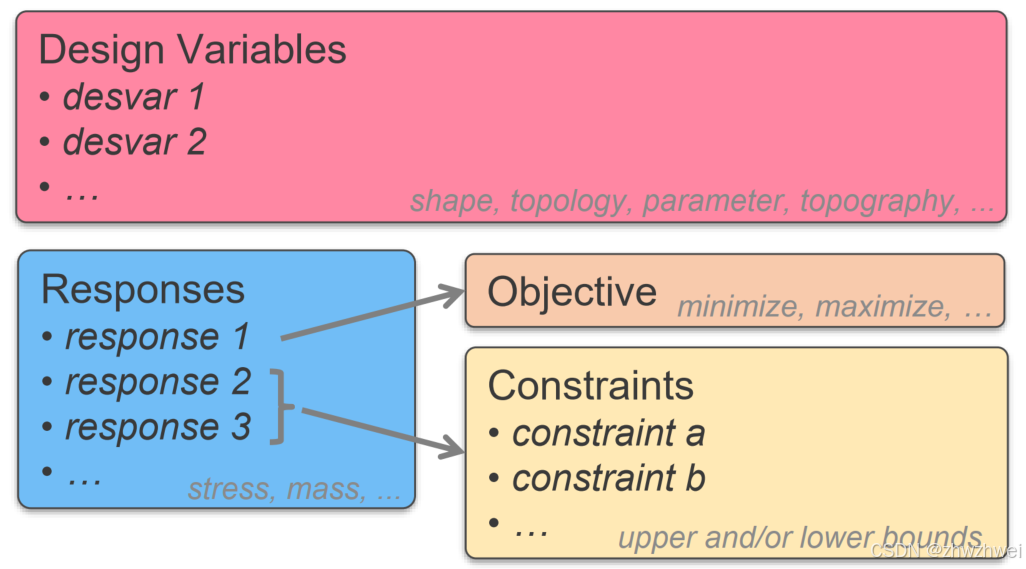
[拓扑优化] 1.概述
常见的拓扑优化方法有:均匀化法、变密度法、渐进结构优化法、水平集法、移动可变形组件法等。 常见的数值计算方法有:有限元法、有限差分法、边界元法、离散元法、无网格法、扩展有限元法、等几何分析等。 将上述数值计算方法与拓扑优化方法结合&#…...