苹果AI功能,AI训练数据缺乏,SD3推出,MJ6推出新特性
更多信息:
https://agifun.love
智源社区
2024智源大会议程公开丨大模型前沿探索
2024年6月14日-15日,第6届北京智源大会将以线下与线上结合的形式召开,线下会场设在中关村国家自主创新示范区会议中心。2024智源大会再次以全球视野,汇聚年度杰出工作研究者,交流新思想,探讨新思路,引领新前沿。目前已正式开放报名渠道。北京智源大会倒计时:3天论坛议程论坛主席李永翔,中国电信人工智能研究院 AI研发中心副总经理中国电信人工智能研究院 AI研发中心副总经理,作为核心成员参与从0-1组建中国电信人工智能研发队伍,打造完整的图像、语音、语义和多模态核心算法能力,支撑中国电信全网人工智能业务发展;建立基础大模型全栈自研能力,相继开源7B/12B/52B等多个版本语义大模...
来源:http://mp.weixin.qq.com/s?__biz=MzU5ODg0MTAwMw==&mid=2247548176&idx=1&sn=f653512368bdf69b09e638c40f6d33cb&chksm=ffb828b469545679de243cbb22ac22548197ae6392d92a1863f56426decf1e4fbe6670db18b5&scene=0&xtrack=1#rd
从事业编到蚂蚁集团,从热门大模型到小众岗位
今年1月份,我从上海人工智能实验室大模型团队的事业单位带编岗位离职,加入了蚂蚁集团,这个选择其实是基于我对于未来数据要素流通行业的信心和选择。时隔5个月,公司终于有重磅消息放出。上篇文章《北漂十年:走不出浪浪山,渡不过的书简湖》发布后,有朋友问我:为什么会选择从事业单位到私营企业,从热门的大模型岗位来搞什么小众的隐私计算?作为从业者,面向大家科普什么是数据要素流通?什么是隐私计算?还是挺有必要的。这也是我在继去年10月份后写的第二篇关于数据交易的科普文章,自我感觉经过半年时间的实践,确实要比之前纸上谈兵了解得扎实很多(看起来在蚂蚁半年状态拉满的工作没白干)。有兴趣的朋友可以看第一篇《探析数据交...
来源:http://mp.weixin.qq.com/s?__biz=MzIyNjM2MzQyNg==&mid=2247666501&idx=2&sn=521dfcf32393a4581308765d60563c3b&chksm=e9b15feb16413293f39bd05000eb01f4f3a05935ecab5ae7cbfb739867eaeaee3046424735d6&scene=0&xtrack=1#rd
苹果终于发布 AI 功能!苹果 AI,和谷歌、微软有什么不一样?
6 月 11 日的 WWDC,所有人的关注重点都在 Apple 的 AI 功能如何落地上,在经历了前一个小时的各种系统更新的介绍后(甚至包括 iPad 上发布计算器),总算是等来了 Apple 的 AI 大更新,虽说与之前的预测文章所差无几,但还是有颇多亮点。Apple Intelligence,虽然同样可以简写为 AI,但苹果最终选择将自己的 AI 命名为「苹果智能」。介绍时,库克特别强调他们想要打造的,是超越「人工智能」(Artificial Intelligence)的「个人智能」(Personal Intelligence)。与其他大模型「大力出奇迹」的发展理念不同,苹果在打造自己的 ...
来源:http://mp.weixin.qq.com/s?__biz=Mzg5NTc0MjgwMw==&mid=2247499252&idx=1&sn=3ebbece460c80f3d4b8d90fd2124dcd7&chksm=c182e6d773033e13213c871524a35c008eec9f30c99d658fc8db79ee766685c8b5993576a907&scene=0&xtrack=1#rd
活动邀请丨《人工智能重大应用场景白皮书》编制工作邀请函
《人工智能重大应用场景白皮书》编制工作邀请函 人工智能技术已经成为科技、经济、社会的基础性技术, 2024年政府工作报告提出:“‘人工智能+’行动”,推动人工智能为引擎的新质生产力。“人工智能+”行动将推动人工智能技术与经济社会各领域深度融合,支撑各行业应用创新,形成以人工智能为创新要素的经济社会发展新形态。为响应“人工智能+”行动,促进人工智能与大应用场景高效结合,加快人工智能技术成果转化、推动人工智能企业的市场开拓,实现我国人工智能高质量发展,清华大学人工智能国际治理研究院等联合进行调研和编辑《人工智能重大应用场景白皮书》(详见附件一),白皮书将公开出版并呈报国家相...
来源:http://mp.weixin.qq.com/s?__biz=MzU4MzYxOTIwOQ==&mid=2247510344&idx=2&sn=25db3dea55a1479528dfbf3c84cce855&chksm=fccce23b8c464bedea1e165e23e5beea5f16e8f7f0d356bfcb4205c1d786a0d5d65c89689497&scene=0&xtrack=1#rd
案例征集丨《人工智能重大应用场景白皮书》案例征集函
《人工智能重大应用场景白皮书》编制工作邀请函 人工智能技术已经成为科技、经济、社会的基础性技术, 2024年政府工作报告提出:“‘人工智能+’行动”,推动人工智能为引擎的新质生产力。“人工智能+”行动将推动人工智能技术与经济社会各领域深度融合,支撑各行业应用创新,形成以人工智能为创新要素的经济社会发展新形态。为响应“人工智能+”行动,促进人工智能与大应用场景高效结合,加快人工智能技术成果转化、推动人工智能企业的市场开拓,实现我国人工智能高质量发展,清华大学人工智能国际治理研究院等联合进行调研和编辑《人工智能重大应用场景白皮书》(详见附件一),白皮书将公开出版并呈报国家相...
来源:http://mp.weixin.qq.com/s?__biz=MzU4MzYxOTIwOQ==&mid=2247510344&idx=1&sn=d20130bf47c6251810565be73b35c26a&chksm=fc385aa754ab55eea468e46fe8413ac73fdf5d4ecb917a904e368832eb30669fdd71ffd9bd6a&scene=0&xtrack=1#rd
InfoQ
美图奇想大模型进阶至V5,一口气发布6款新品喊话友商:快来抄作业
从诞生至今已经步入第16个年头的美图,已经不再只是一个纯C端产品。
来源:https://www.infoq.cn/article/eSLdPhJ3dD4WC88KS8tY
AICon 全球人工智能开发与应用大会(上海) 2024 启动筹备,众多热点专题诚征演讲嘉宾
8月18-19日,AICon 上海站启动,不可错过的大模型前沿分享
来源:https://www.infoq.cn/article/Zvimp8MvEFT0GtPEk7jL
MaaS是伪命题吗?超级对齐本质是什么?顶级专家云集探讨大模型最新趋势
一场丰富的学术盛宴。
来源:https://www.infoq.cn/article/HjFQ3QWKz7KDebEiMPsR
乔布斯看了得哭!与小米、华为的AI 大模型应用打擂台,苹果盖不住的“安卓味儿”都上了热搜
苹果此次基于大模型推出的AI功能,与国内手机厂商相比在应用实现上有何区别?
来源:https://www.infoq.cn/article/Ty5Ae8jfB6Z4cYNA1KIU
复旦邱锡鹏教授讲述MOSS 2 研发进展:如何实现世界模型?
构建世界知识可以不经过语言,直接让模型通过观察世界自己发现规律。
来源:https://www.infoq.cn/article/wpuQwSLaDd8zI7IpQp4J
ShowMeAI社区
打造AI爆款应用<新>黄金法则;盘点20款最流行AI搜索工具;ChatGPT对在线知识社区的影响;100万用户教会我的5个教训 | ShowMeAI日报
-
盘点 20 款最流行的AI搜索应用,你最喜欢哪几个? [图片] 国内秘塔AI搜索 https://metaso.cn/ 好用,免费,国内 Top 水平 天工AI (昆仑万维) https://www.tiangong.cn/ 好用,免费,技术实力 Top 且快速升级中 简单搜索 App (百度) https://secr.baidu.com/ 只有手机版,规规矩矩的一款AI增强搜索应用 360 AI 搜索 https://so.360.com 最近数据增长蛮快的,综合体验比较流畅 澜舟AI搜索 https://ai-search.langboat.com 中规中矩 BrainStorm …
来源:https://zhuanlan.zhihu.com/p/698345703
又一款爆火AI游戏诞生!《换你来当爹》做对了什么?| ShowMeAI体验报告
[图片] 社区里几百人玩一款AI游戏的场面,值得记录一下! 大模型游戏化极度看重〖有趣〗程度。可有趣的灵魂那么难得,以至于只要一眼,我们就在产品的海洋里发现了 ta 。1. 有趣的灵魂在发疯疯疯 《换你来当爹》是一款全员发疯的AI游戏,主线任务是任意设定一个角色,然后把他培养成「大孝子」!灵感估计来源于男生大学宿舍里互相喊「爸爸」的传统?看到设定的一瞬间,会心一笑 游戏最初在即刻平台出圈,随后传回微信社群,并成功激发起…
来源:https://zhuanlan.zhihu.com/p/697856247
朱啸虎:AI应用明年肯定大爆发;第3款爆火AI游戏出现了;AI应用定价策略「不能说的秘密」;人类数据不够用了怎么办 | ShowMeAI日报
日报&周刊合集 | 生产力工具与行业应用大全 | 点赞关注评论拜托啦!1. 换你来当爹:国内第3款爆火出圈的AI游戏应用,hhh 太搞笑了 [图片] 周末的时候,社群里伙伴们开始玩一款「 换你来当爹」的AI游戏 进入游戏界面后,输入名字,系统随机生成孩子的「出生设定」。 然后恭喜你!可以开始当爹了!! 好大儿的培养过程,伴随着各种糟心的意外,然后把难题摆在你面前。 哎呀呀!逆子… 这时,你可以在系统给定的两个选项中选择一个,当然也…
来源:https://zhuanlan.zhihu.com/p/697655366
上海交通大学《动手学大模型》编程实战课;提示工程大赛冠军经验分享;AI Agent最新行业地图(3份);人类与ChatGPT恋爱行为指南;提升AI产品留存率的7个技巧 | ShowMeAI日报
日报&周刊合集 | 生产力工具与行业应用大全 | 点赞关注评论拜托啦! 1. 终于来了!OpenAI 周一官网直播,ChatGPT 和 GPT-4 上新啦! [图片] Sam Altman 和 OpenAI 近期一直在造势,演讲、访谈、小更新等动作不断。终于!官方推特宣布,将于 美西时间5月13日上午10点 (⏰ 北京时间5月14日凌晨1点) 在 OpenAI 官网进行直播,演示 ChatGPT 和 GPT-4 的更新。 到底会更新什么呢?!!各方还在猜来猜去。@indigo 的猜测帖 传播度很广,精选…
来源:https://zhuanlan.zhihu.com/p/697448133
ShowMeAI | 全球最有前途的100家AI公司,中国2家上榜;混合专家模型MoE详解;人大最新《大语言模型》电子书开放下载;斯坦福最新AI指数报告
日报&周刊合集 | 生产力工具与行业应用大全 | 点赞关注评论拜托啦! 1. CB Insights 发布「AI 100 2024」榜单,评选出全球最有前途的 100 家人工智能公司 [图片] CB Insights 是全球知名的市场情报分析机构,以其深入的数据分析、前瞻性的行业洞察而著称。CB Insights 最近发布了「AI 100 2024 」榜单,综合考虑了公司交易活动、行业合作伙伴关系、团队实力、投资者实力、专利活动、专项评分等数据维度,并结合 CB Insights 调研和访谈,…
来源:https://zhuanlan.zhihu.com/p/696949266
Aminer.cn
文本压缩与大型语言模型:长文本处理的革新
想把握最新的科技进展和研究成果,却发现自己的阅读速度根本赶不上文献产出的速度?
来源:https://www.aminer.cn/research_report/6668fc88c028d8419b0f8b66
北大团队提出 BoT:让 Llama3-8B 超越 Llama3-70B|大模型周报
Mamba-2:速度提高 2-8 倍,与 Transformers 媲美
来源:https://www.aminer.cn/research_report/6668fb5dc028d8419b0f8a50
大型语言模型的不确定性表达:忠实度与准确性
大模型(LLM)是一种人工智能模型,旨在理解和生成人类语言。
来源:https://www.aminer.cn/research_report/665fc8bac028d8419b0a4168
清华大学唐杰:大模型与超级智能
本文探讨了大模型的发展历程,介绍了作者团队研发的GLM-4大模型,并针对AGI研究面临的挑战对AGI未来发展提出了一些思考。
来源:https://www.aminer.cn/research_report/665fc671c028d8419b0a3f77
训练数据匮乏:LLM在正式定理证明中的挑战
别担心,AMiner AI会帮助你高效检索和阅读文献!
来源:https://www.aminer.cn/research_report/665d2bd6c028d8419b08ba06
arXiv.org
TextGrad: Automatic "Differentiation" via Text
AI is undergoing a paradigm shift, with breakthroughs achieved by systems orchestrating multiple large language models (LLMs) and other complex components. As a result, developing principled and automated optimization methods for compound AI systems is one of the most important new challenges. Neural networks faced a similar challenge in its early days until backpropagation and automatic differentiation transformed the field by making optimization turn-key. Inspired by this, we introduce TextGrad, a powerful framework performing automatic ``differentiation'' via text. TextGrad backpropagates textual feedback provided by LLMs to improve individual components of a compound AI system. In our framework, LLMs provide rich, general, natural language suggestions to optimize variables in computation graphs, ranging from code snippets to molecular structures. TextGrad follows PyTorch's syntax and abstraction and is flexible and easy-to-use. It works out-of-the-box for a variety of tasks, where the users only provide the objective function without tuning components or prompts of the framework. We showcase TextGrad's effectiveness and generality across a diverse range of applications, from question answering and molecule optimization to radiotherapy treatment planning. Without modifying the framework, TextGrad improves the zero-shot accuracy of GPT-4o in Google-Proof Question Answering from $$51\$$ to $$55\$$, yields $$20\$$ relative performance gain in optimizing LeetCode-Hard coding problem solutions, improves prompts for reasoning, designs new druglike small molecules with desirable in silico binding, and designs radiation oncology treatment plans with high specificity. TextGrad lays a foundation to accelerate the development of the next-generation of AI systems.
来源:http://arxiv.org/abs/2406.07496v1
Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language
Models for Media Forensics DeepFakes, which refer to AI-generated media content, have become an increasing concern due to their use as a means for disinformation. Detecting DeepFakes is currently solved with programmed machine learning algorithms. In this work, we investigate the capabilities of multimodal large language models (LLMs) in DeepFake detection. We conducted qualitative and quantitative experiments to demonstrate multimodal LLMs and show that they can expose AI-generated images through careful experimental design and prompt engineering. This is interesting, considering that LLMs are not inherently tailored for media forensic tasks, and the process does not require programming. We discuss the limitations of multimodal LLMs for these tasks and suggest possible improvements.
来源:http://arxiv.org/abs/2403.14077v4
Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo
Tree Self-refine with LLaMa-3 8B This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks. Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance. Extensive experiments demonstrate MCTSr's efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench. The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making accuracy and reliability in LLM-driven applications.
来源:http://arxiv.org/abs/2406.07394v1
Test-Driven Development for Code Generation
Recent Large Language Models (LLMs) have demonstrated significant capabilities in generating code snippets directly from problem statements. This increasingly automated process mirrors traditional human-led software development, where code is often written in response to a requirement. Historically, Test-Driven Development (TDD) has proven its merit, requiring developers to write tests before the functional code, ensuring alignment with the initial problem statements. Applying TDD principles to LLM-based code generation offers one distinct benefit: it enables developers to verify the correctness of generated code against predefined tests. This paper investigates if and how TDD can be incorporated into AI-assisted code-generation processes. We experimentally evaluate our hypothesis that providing LLMs like GPT-4 and Llama 3 with tests in addition to the problem statements enhances code generation outcomes. We experimented with established function-level code generation benchmarks such as MBPP and HumanEval. Our results consistently demonstrate that including test cases leads to higher success in solving programming challenges. We assert that TDD is a promising paradigm for helping ensure that the code generated by LLMs effectively captures the requirements.
来源:http://arxiv.org/abs/2402.13521v2
Algorithmic Persuasion Through Simulation
We study a Bayesian persuasion game where a sender wants to persuade a receiver to take a binary action, such as purchasing a product. The sender is informed about the (binary) state of the world, such as whether the quality of the product is high or low, but only has limited information about the receiver's beliefs and utilities. Motivated by customer surveys, user studies, and recent advances in AI, we allow the sender to learn more about the receiver by querying an oracle that simulates the receiver's behavior. After a fixed number of queries, the sender commits to a messaging policy and the receiver takes the action that maximizes her expected utility given the message she receives. We characterize the sender's optimal messaging policy given any distribution over receiver types. We then design a polynomial-time querying algorithm that optimizes the sender's expected utility in this game. We also consider approximate oracles, more general query structures, and costly queries.
来源:http://arxiv.org/abs/2311.18138v4
齐思
齐思头条2024/06/12「苹果iOS 18集成Chat GPT,OpenAI预测2027年实现AGI,Meta推出CRAG基准测试,Google启动NATURAL PLAN项目,LangChainAI展示WebRTC AI语音聊天技术」
Twitter:
Apple的AI集成与创新 : Apple在iOS 18中集成了Chat GPT,展示了多模态I/O、主动系统功能和隐私保护的AI技术。Apple还在Hugging Face平台上发布了四个新模型,并推出了3B参数SLM和扩散模型,强调本地或在Apple安全云上运行的模型。Apple还推出了“Ferret-UI”多模态视觉语言模型,能够理解iOS移动屏幕上的图标、控件和文本,并使用LoRA适配器进行设备端AI集成。更多详情请见Karpathy的推文、MaxWinebach的推文和Scobleizer的推文。
OpenAI的AGI预测 : OpenAI内部人士预测人工通用智能(AGI)将在2027年开发出来,比计算机科学家的中位数估计2047年早得多。这一预测引发了广泛讨论,更多信息请见Ethan Mollick的推文。
Meta的CRAG基准测试 : Meta推出了CRAG(Comprehensive RAG Benchmark),这是一个包含4,409个问答对和模拟API搜索的事实问答基准,提供了全面的问答性能评估。详细信息请见arankomatsuzaki的推文。
Google的NATURAL PLAN项目 : Google启动了NATURAL PLAN项目,旨在对大语言模型(LLMs)在自然语言规划任务中的表现进行基准测试,包括旅行和日程安排,提出了一个具有挑战性的现实世界规划基准。更多详情请见arankomatsuzaki的推文。
LangChainAI的WebRTC AI语音聊天实验室 : LangChainAI展示了如何使用WebRTC进行语音转文本和文本转语音技术,以构建和交互AI应用程序。更多信息请见LangChainAI的推文。
Mistral AI获得重大融资 : 总部位于巴黎的初创公司Mistral AI获得了6.4亿美元的股权和债务融资,目前估值为60亿美元。这一重大融资轮表明了投资者对AI领域的强烈信心。更多详情请见TechCrunch的推文。
Amazon Alexa的AI挑战 : Amazon的Alexa面临重大技术和组织挑战,导致其在对话式AI市场中的表现不佳。详细见Ethan Mollick的推文。
LangChain与Elasticsearch集成 : LangChain与Elasticsearch集成,使用户能够导入Elasticsearch的功能,包括灵活的检索系统和向量数据库,旨在构建更准确的检索系统。更多信息请见博客文章。
Mixture-of-Agents增强LLM能力 : Mixture-of-Agents(MoA)方法利用多个LLM的集体优势,在AlpacaEval 2.0上取得了65.1%的得分,显著超过了GPT-4 Omni的57.5%。MoA构建了一个分层架构,每层有多个LLM代理迭代优化响应,最终输出由一个聚合LLM合成。更多详情请见原始推文。
bGPT - 字节级Transformer : bGPT模型在字节级处理数据,在模拟CPU行为和转换符号音乐数据方面表现出色,准确率超过99.99%,错误率为0.0011 bits per byte。该模型可以直接解释和操作二进制数据,提供了预测、模拟和诊断算法或硬件行为的新可能性。更多信息请见原始推文。
DreamGaussian4D: 图像到3D动画 : DreamGaussian4D模型不仅实现了图像到3D的转换,还增加了动画功能,创造了4D体验。更多信息请见博客文章。
PGVectorScale优于Pinecone : PGVectorScale,一个开源的PostgreSQL扩展,在向量搜索任务中在延迟和查询吞吐量方面优于Pinecone。它在AWS EC2上自托管时实现了28倍的p95延迟降低和16倍的查询吞吐量提高,成本减少了75%。更多信息请见Jeremy Howard的推文。
Meta Llama 3黑客马拉松回顾 : Meta与Cerebral Valley合作举办的首届Meta Llama 3黑客马拉松吸引了350多名参与者,在24小时内创造了50多个项目。更多信息请见Meta AI的推文。
DayOneVC宣布1.5亿美元基金III : DayOneVC宣布其1.5亿美元的基金III,使其管理的资产超过4.5亿美元。该基金旨在支持致力于重大创意的杰出创始人。更多信息请见Suhail的推文。
ARC-AGI基准竞赛 : 一项新的100万美元竞赛旨在打破2019年的ARC-AGI基准,旨在重新启动开放的AGI进展。该竞赛由ARC Prize和F. Chollet发起,详细信息请见Mikeknoop的推文。
Google的Tx-LLM用于治疗 : Google推出了Tx-LLM,一个从PaLM-2微调的大语言模型,用于多种治疗方式。在66项任务中,该模型在43项任务上达到了最先进的性能,并在22项任务上超过了SOTA。更多信息请见IntuitMachine的推文。
结构化生成优于GPT-4 : 使用结构化生成,phi-3实现了95.5%的准确率,超过了之前未使用结构化生成的86%,并且比GPT-4的93.5%准确率高出2个百分点。更多信息请见Sebastien Bubeck的推文。
Hugging Face 3D Arena排行榜发布 : Hugging Face发布了官方的3D Arena排行榜,InstantMesh目前排名第一。排行榜旨在促进3D模型生成领域的竞争和创新。更多信息请见Hugging Face网站。
谈判竞技场用于LLMs : 研究人员引入了谈判竞技场,一个新的基准,LLMs在其中相互谈判以评估其表现。这一创新方法已被ICML 2024接受,旨在为LLM能力提供一个动态测试平台。更新的论文和代码可在此处获取。
RecurrentGemma扩展到90亿参数 : Google开发者宣布RecurrentGemma扩展到90亿参数,标志着高效深度学习研究的重大进展。更多信息请见公告推文。
François Chollet对OpenAI的AGI影响的看法 : François Chollet批评OpenAI因缺乏前沿研究出版物和大语言模型(LLMs)带来的分散,导致AGI进展倒退了5-10年。更多信息请见Gary Marcus的推文。
HackerNews:
介绍苹果的设备和服务器基础模型
链接: 苹果在2024年全球开发者大会上宣布了其新的个人智能系统Apple Intelligence,将AI深度集成到其设备中。
讨论要点:
-
缺乏新意 :对于AI研究人员来说,这次发布没有什么新内容。“适配器”的概念本质上是vanilla LoRA (低秩适配)的重述。
-
苹果的策略 :苹果以采用现有技术并将其改进以供主流使用而闻名,而不是开创新技术。例子包括iPhone、iPad和Apple Watch 。
-
历史背景 :苹果有使现有技术广泛普及的历史,例如在1999年首次将WiFi引入笔记本电脑 。
-
营销影响 :苹果的营销往往引领行业跟随其决策,无论好坏,例如移除3.5毫米耳机插孔 。
-
基准测试 :尽管缺乏新意,但苹果提供的基准测试还是受到了赞赏。
博客 - 私有云计算:云中AI隐私的新前沿 - Apple Security Research
链接: 苹果推出了私有云计算(PCC),用于在云中进行安全和私密的AI处理,确保用户数据隐私。
讨论要点:
-
信任问题 :尽管苹果声称如此,用户仍然必须信任苹果,因为它控制所有端点和更新。基于Web的加密 通常被认为不可靠。
-
与竞争对手的比较 :苹果被认为在确保没有员工可以访问用户数据方面做出了认真努力,不像谷歌 或OpenAI ,它们的商业模式围绕数据使用展开。
-
商业模式 :苹果的商业模式建立在隐私之上,使其不太可能违反访问控制,而相比之下,那些从数据中获利的公司更有可能这样做。
-
怀疑态度 :尽管如此,仍有人怀疑苹果的方法是否真的对隐私更好,考虑到其不断增长的广告和服务收入。
科学会议的解剖:有争议的杀虫剂研究如何几乎从一个主要会议上消失
链接: 关于新烟碱类杀虫剂的研究在一个主要会议上显著缺席。
讨论要点:
-
企业影响 :新烟碱类杀虫剂研究的缺席与杀虫剂公司 在资助和组织会议中的重要角色有关。
-
赞助特权 :公司获得赞助特权是被接受的,这可能影响研究主题的选择。
-
矛盾的声明 :一些科学家声称新烟碱研究没有被选中是因为它没有带来任何新东西,尽管该领域的研究和引用量在不断增加。
本地社区的巨大衰退和基于游戏的童年的丧失
链接: 文章讨论了紧密的社区如何保护儿童免受手机时代童年的伤害。
讨论要点:
-
物理环境设计 :物理环境的设计,特别是在美国与欧洲和日本 之间的差异,显著影响了儿童玩耍和安全移动的能力。
-
车辆设计 :美国卡车和SUV 的高度增加对行人,特别是儿童构成了危险,使他们步行或骑自行车不安全。
-
城市规划 :美国以汽车为中心的城市规划意味着儿童步行或骑自行车的地方更少,导致户外游戏的减少。
Max Leiter
链接: 这篇博客文章讨论了每天发布代码的做法及其对软件开发质量和生产力的影响。
讨论要点:
-
频繁发布的批评 :每天发布代码被认为助长了一种多动症式的态度 ,这会降低软件质量。开发人员需要时间深入思考和解决难题,而不是频繁提交代码的压力。
-
提交频率的争论 :有些人认为每天至少提交一次代码 是一个低目标,是生产力的标志,即使提交的内容很小。其他人认为这忽视了非提交工作,如需求分析和文档编写。
-
对团队动态的影响 :频繁提交代码可以被视为向经理展示活动并保持良好的git提交记录,但这可能导致搅动或翻腾 ,而不是有意义的进展。
-
平衡 :讨论建议在频繁发布 以保持势头和确保工作实质性和深思熟虑 之间找到平衡。目的是避免快速、浅显的提交和长时间、孤立的开发周期这两种极端。
-
最佳实践 :强调自动化测试、功能标志和增量改进 的重要性,以支持频繁发布而不影响质量。
Discord:
Stable Audio Model Training : 详细步骤包括数据集配置和模型配置,强调数据质量 和提示工程 对微调效果的重要性。
StableSwarm vs. Auto1111 : StableSwarm 被认为是Auto1111 的优越替代品,使用ComfyUI 作为后端支持多GPU批量图像处理,提供节点和简化界面。安装指南和使用指南可供参考。
Impact of RLHF on Creativity in LLMs : 论文"Creativity Has Left the Chat: The Price of Debiasing Language Models"探讨了人类反馈强化学习(RLHF) 如何减少偏见和毒性,但也限制了LLM输出的句法和语义多样性 ,影响创造力。
ZeroGPU Spaces for Serverless Inference : Hugging Face 的ZeroGPU Spaces 提供无服务器解决方案,运行GPU密集任务如扩散模型,免费提供GPU访问并高效管理GPU分配。更多详情。
MaPO for Text-to-Image Diffusion Models : Margin-aware Preference Optimization (MaPO) 技术用于在无参考模型的情况下对文本到图像扩散模型进行对齐,解决“参考不匹配”问题并提高性能。更多详情。
SuperMemory Project : SuperMemory 项目作为“第二大脑”管理书签和保存内容,使用Next.js 14 、Next Auth 、Drizzle ORM 和Cloudflare D1数据库 构建Web UI,后端使用Cloudflare Workers 和Cloudflare AI 。项目链接。
Apple Foundation Models : Apple 的基础模型研究展示了其在设备/云上运行的私有AI功能。
On-Device AI Potential : 未来0.5B模型有望执行设备上的任务,尽管之前的phi3模型被认为表现不佳。
Embedding and Multilingual Support : 使用Cohere 的多语言嵌入模型和Pinecone DB 进行古兰经文本项目,允许用户以不同语言互动。应用链接。
Memory Bandwidth Cost of nn.Embedding Layer : CUDA上的内存带宽成本主要与前向传递期间的唯一标记数量 和反向传递期间的权重大小和输出/输入大小 相关。来源。
Quantization Methods for Llama 3 : 讨论了GGUF I-Quants 、EXLv2 和AWQ 等量化方法,GGUF I-Quants表现优异,EXLv2与iMatrix相当但有优势,HQQ缺乏流行推理后端支持。MMLU分数和方法和LLM量化博客。
Sharding and Pipeline Parallelism : 通过将特定层分配给不同的GPU并手动发送激活来避免分片,确保流水线并行性以避免瓶颈。
Federated Learning : 讨论了在不转移设备外数据的情况下训练模型的潜力,涉及本地运行反向传播并将梯度发送到服务器,实际实现和隐私问题仍是重大挑战。
Batch API Implementation : 实现批处理API的高级方法包括创建JSONL文件,通过API上传到服务器,使用选定模型运行,并返回运行和文件ID以进行状态轮询。
RMSNorm vs. Other Normalization Techniques : RMSNorm 相比其他归一化技术具有更少的可训练参数 和更快的速度 ,在预训练期间具有优势,但在使用最佳内核时性能差异最小。
Tool Functions in LlamaIndex : 创建两个工具函数,一个用于从向量数据库检索结果,另一个在未找到产品时使用OpenAI Chat Completion API ,考虑使用ReAct 等代理框架。
Building a RAG System : 使用LlamaIndex 开发RAG系统 ,需要集成多个模块,包括SQL查询引擎 、向量搜索 、关键词搜索 和图像搜索(OpenAI CLIP) ,推荐使用Qdrant 进行向量存储。
ThunderKitten Performance on A100 : ThunderKitten 在A100上实现约75 TFLOPS,显著低于cuBLAS的约400 TFLOPS,原因是其专注于TMA导致的L1/加载-存储限制。
H100 FlashAttention Integration : 计划集成H100 FlashAttention ,这是BF16/FP16最快的非cuDNN FA实现,且具有公开的反向传递。
FP8 vs FP16 Training : 许多团队更喜欢FP16 而非FP8 进行训练,尽管FP8具有潜在优势,但由于稳定性和理解问题。
NuMojo Library : NuMojo 库用于Mojo中的数值计算,类似于Python中的NumPy ,扩展标准库数学函数以处理张量输入,利用Mojo的向量化和并行化能力。NuMojo GitHub。
Xoshiro PRNG in Mojo : Xoshiro 系列随机数生成器移植到Mojo,在笔记本电脑上实现64 Gbps ,使用SIMD和4个并行流实现180 Gbps 。GitHub仓库。
Quantization API Documentation Issue : 识别出Modular博客文章中的链接错误,正确的量化API文档链接应为此处。
LlamaGen: Autoregressive Model for Scalable Image Generation : LlamaGen 的论文介绍了图像生成的自回归模型,图像标记器在ImageNet上实现0.94 rFID和97%代码簿使用率,类条件模型(111M到3.1B参数)优于流行的扩散模型,文本条件模型(775M参数)具有竞争力的视觉质量和文本对齐,使用vLLM优化推理速度,达到326%-414%的加速。
LlavaGuard: VLM-based Safeguards for Vision Dataset Curation and Safety Assessment : LlavaGuard 提供高质量视觉数据集,具有广泛的安全分类和可定制类别,安全评估优于GPT-4,使用SGLang实现,提供代码片段和GitHub上的Docker镜像。
Chunking Strategies for RAG Systems : Stack Overflow博客文章讨论了RAG系统 的各种分块策略,强调分块大小对嵌入和检索准确性的重要性,涵盖固定大小、随机、上下文感知和自适应分块方法,突出其权衡和用例。
Pinecone's Insights on Chunking : Pinecone 的Roie Schwaber-Cohen解释了将文本块向量与查询向量匹配的重要性,强调较小、语义连贯的块通常能产生更好的结果,元数据可用于过滤和链接内容,增强检索准确性。
HuggingFace & Github:
人工智能与技术创新
-
Qwen2大型语言模型 介绍:Qwen2是一个新系列的语言模型,参数范围从0.5到72亿 ,包括基础语言模型和经过指导训练的语言模型。Qwen2在语言理解、语言生成、多语言能力、编码、数学、推理 等方面表现出色,基于Transformer架构 ,具有SwiGLU激活、注意力QKV偏置、组查询注意力 等特点。Qwen2使用大量数据进行预训练,并进行了有监督微调和直接优化。推荐安装transformers >= 4.37.0 以使用Qwen2代码。
-
Qwen2模型性能 在多种基准测试中表现出色,包括MMLU、HumanEval、GSM8K、C-Eval和IFEval 等指标,超越了许多开源模型并与专有模型竞争。提供了代码片段,展示了如何加载tokenizer和model 以及如何生成内容。
来源:https://news.miracleplus.com/share_link/29762
einsum is all you needed
这篇指南深入探讨了PyTorch中torch.einsum函数的强大功能,该函数以其在执行超过10,000个张量操作方面的多功能性而备受赞誉。它在支持微分和反向传播方面脱颖而出,是深度学习应用中的宝贵工具。内容灵感源自爱因斯坦求和约定,通过使用虚拟指标简化张量操作,使表达更加简洁,减少错误。该指南展示了该函数在处理涉及批处理维度的高阶张量的复杂操作中的优雅和便利之处。通过提供矩阵乘法的实际示例,它演示了torch.einsum如何简化传统复杂的计算。对于那些希望加强对PyTorch中张量操作的理解,并希望将这个“所需一切”函数应用于简化他们的深度学习工作流程的人来说,这篇文章尤为有用。
来源:https://zhuanlan.zhihu.com/p/542625230?utm_psn=1784149282254807040
当水向上流动时
在这个有趣的视频中,名为“当水向上流动时”的物理学家Takashina博士探讨了莱顿弗罗斯特效应,这是一种现象,水滴似乎可以在热表面上违背重力。视频深入探讨了这一效应的历史,首次于1756年描述,并其现代应用潜力,如冷却微芯片。观众将被Takashina博士及其团队进行的实验所吸引,这些实验揭示了温度和表面结构如何影响水滴在有脊的表面上攀爬的方向和能力。视频的亮点是创建了一个莱顿弗罗斯特迷宫,展示了这一科学奇观的实用和教育潜力。对于那些对物理学和科学以意想不到的方式使水看起来向上流动感兴趣的人来说,这个内容是必看的。
来源:https://www.youtube.com/watch?v=zzKgnNGqxMw
硅谷最好的秘密:创始人的流动性
在这篇富有洞察力的文章中,软件工程师斯特凡·西尔德(Stefan Theard)揭示了硅谷中经常被忽视的创始人流动性实践。西尔德挑战了创始人承担风险主要责任的普遍说法,揭示了创始人在融资轮中经常出售股份以确保个人财务稳定的做法。这种通常不向员工披露的做法与创始人全心投入公司成功的形象相矛盾。西尔德主张透明和公平,分享了他自己在创业中打算为早期员工提供更好的股权条款和流动性选择。这篇文章因呼吁重新评估创始人和早期员工之间的风险分配,并鼓励在初创公司股权讨论中建立开放文化而脱颖而出。对于任何涉足初创生态系统的人来说,这是一篇必读之作,提供了一个难得的机会,让人窥见幕后发生的财务动态。
来源:https://www.stefantheard.com/silicon-valleys-best-kept-secret-founder-liquidity/
手机流畅运行470亿大模型:上交大发布LLM手机推理框架PowerInfer-2,提速29倍
上海交通大学通过开发PowerInfer-2.0,取得了移动AI技术的重大突破,这是一个移动推理框架,可以使Mixtral 47B等大型模型在智能手机上高效运行。该框架以其令人印象深刻的速度脱颖而出,平均速度比现有的llama.cpp快25倍,最高速度达到29倍。PowerInfer-2.0利用动态神经缓存和Turbo Sparse等创新技术优化内存和计算效率,实现模型稀疏化而不损失性能。这一突破具有实际意义,因为研究团队正在与智能手机制造商合作,将PowerInfer-2.0集成到实际应用中,有望改变我们在移动设备上使用AI的方式。如果您对设备上AI和移动技术的最新进展感兴趣,这一发展值得关注。
来源:https://mp.weixin.qq.com/s/vylZp7MG7TA3pQKOBWbYRQ
小互
Stability AI 开源其 Stable Diffusion 3 Medium 模型 可在消费级笔记本电脑上运行
Stability AI 开源其 Stable Diffusion 3 Medium 模型 可在消费级笔记本电脑上运行
来源:https://xiaohu.ai/p/9539
Midjourney 推出 Personalization 功能 Midjourney会记住你的艺术喜好
Midjourney 推出 Personalization 功能 Midjourney会记住你的艺术喜好
来源:https://xiaohu.ai/p/9512
教程:如何使用 Midjourney 换脸 将一个人面部复制并粘贴到任意人身上
教程:如何使用 Midjourney 换脸 将一个人面部复制并粘贴到任意人身上
来源:https://xiaohu.ai/p/9490
『iOS 18.0 超详细体验报告』 52 项改进详细介绍以及BUG和升级方法
苹果对 Siri 进行全面改造 具有屏幕感知能力以及跨应用执行各种任务
来源:https://xiaohu.ai/p/9483
Proofread:利用大语言模型自动修正键盘输入的文本错误 提升打字体验
Proofread:利用大语言模型自动修正键盘输入的文本错误 提升打字体验
来源:https://xiaohu.ai/p/9477
宝玉
探索检索和评估相关上下文的挑战 [译]
利用 Ragas, TruLens 和 DeepEval 对一年级阅读理解练习进行上下文相关性评估的案例研究
来源:https://baoyu.io/translations/rag/the-challenges-of-retrieving-and-evaluating-relevant-context-for-rag
最佳论文 [译]
虽然这篇文章的标题称其为“最佳论文”,但实际上并非如此。我的目标是探索一篇真正的最佳论文应具备的特质。
来源:https://baoyu.io/translations/writing/the-best-essay
苹果新推出的设备内及云端服务器基础模型介绍 [译]
在 2024 年全球开发者大会上,我们向大家展示了苹果智能系统,这是一套深度融入 iOS 18、iPadOS 18 及 macOS Sequoia 的个人智能体系。这一系统集成了多个功能强大的生成式 AI,专为处理用户日常需求而设计,能够根据用户当前的活动实时调整。苹果智能中的基础模型经过专门微调,以优化各种用户体验,如文本编写、通知的排序与摘要、为家庭及朋友对话创造有趣的图像,以及简化应用间的交互操作。
来源:https://baoyu.io/translations/apple/introducing-apple-foundation-models
使用大语言模型 (LLMs) 构建产品一年后的经验总结 [译]
现在是使用大语言模型 (LLMs) 构建产品的激动人心的时刻。在过去的一年中,LLMs 的表现已经“足够好”可以应用于现实世界。LLMs 改进的速度,加上社交媒体上的大量演示,将推动预计到 2025 年 AI 投资达到 2000 亿美元。LLMs 的广泛可用性,让每个人,而不仅仅是机器学习工程师和科学家,都能在他们的产品中构建智能。虽然构建 AI 产品的门槛已经降低,但要创建那些不仅仅是演示效果好的产品,仍然充满挑战。
来源:https://baoyu.io/translations/llm/what-we-learned-from-a-year-of-building-with-llms
测试 Chrome 内置 Gemini Nano 大语言模型 (4bit 3.25B) 的方法
如何测试 Chrome 内置的 Gemini Nano 大语言模型
来源:https://baoyu.io/blog/ai/how-to-enable-gemini-nano-for-chrome
Github
Codium-ai/cover-agent
CodiumAI Cover-Agent: An AI-Powered Tool for Automated Test Generation and Code Coverage Enhancement! 💻🤖🧪🐞
来源:https://github.com/Codium-ai/cover-agent
openrecall/openrecall
OpenRecall is a fully open-source, privacy-first alternative to proprietary solutions like Microsoft's Windows Recall. With OpenRecall, you can easily access your digital history, enhancing your memory and productivity without compromising your privacy.
来源:https://github.com/openrecall/openrecall
BuilderIO/micro-agent
An AI agent that writes (actually useful) code for you
来源:https://github.com/BuilderIO/micro-agent
squaredtechnologies/thread
AI-Powered Jupyter Notebook built using React
来源:https://github.com/squaredtechnologies/thread
Bklieger/groqbook
Groqbook: Generate entire books in seconds using Groq and Llama3
来源:https://github.com/Bklieger/groqbook
本文档由扣子生成,资讯版权属于原作者。 豆包机器人链接:https://www.coze.cn/store/bot/7343089859382444051?bot_id=true 一支烟花社区提供技术支持,了解更多点击:https://sourl.cn/MsNyXj
相关文章:

苹果AI功能,AI训练数据缺乏,SD3推出,MJ6推出新特性
更多信息: https://agifun.love 智源社区 2024智源大会议程公开丨大模型前沿探索 2024年6月14日-15日,第6届北京智源大会将以线下与线上结合的形式召开,线下会场设在中关村国家自主创新示范区会议中心。2024智源大会再次以全球视野&#x…...

超越中心化:Web3如何塑造未来数字生态
随着技术的不断发展,人们对于网络和数字生态的期望也在不断提升。传统的中心化互联网模式虽然带来了便利,但也暴露出了诸多问题,比如数据滥用、信息泄露、权力集中等。在这样的背景下,Web3技术应运而生,旨在打破传统中…...
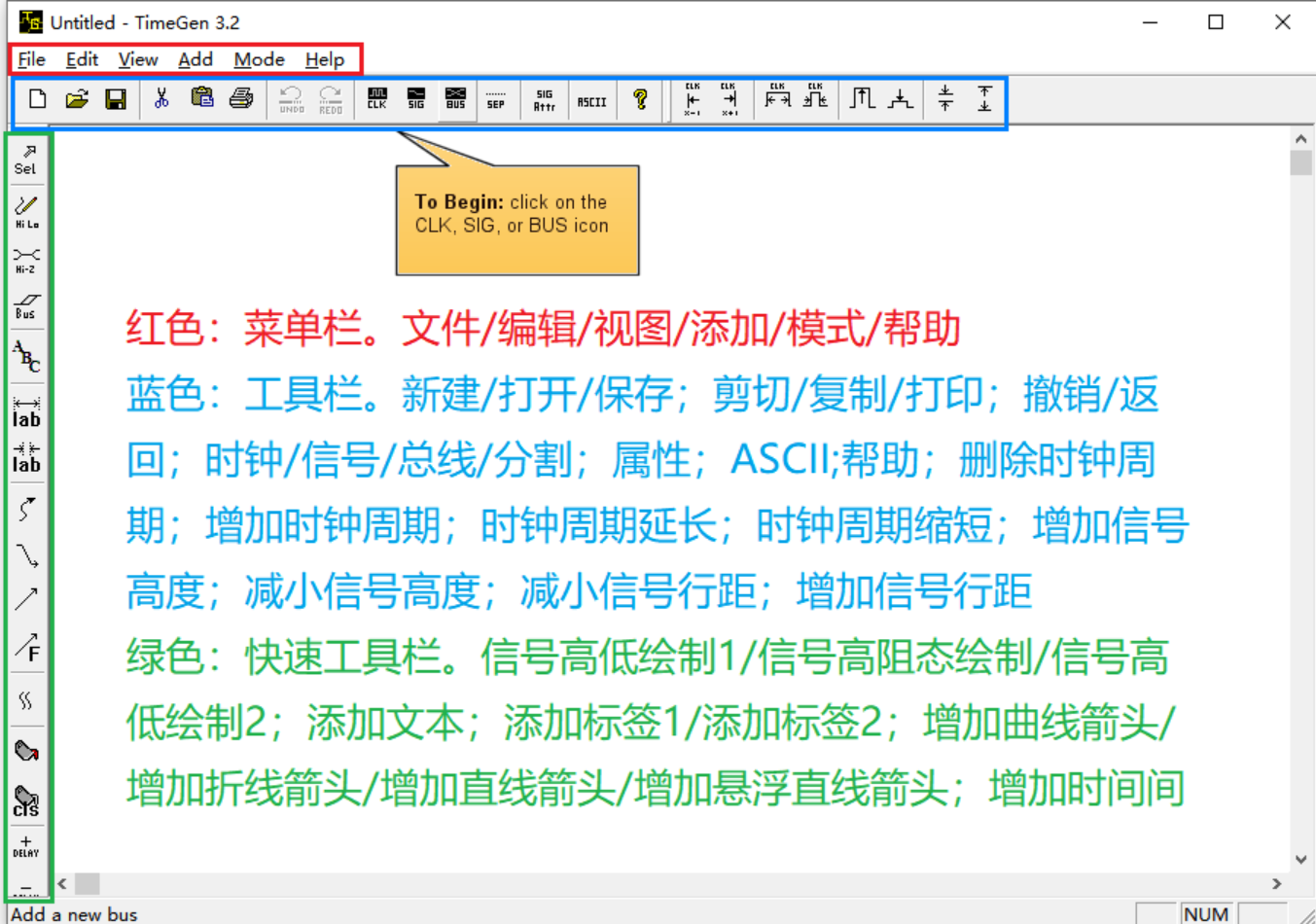
【ic-tool】timegen使用
一、前言 TimeGen是一个用于时序波形编辑的CAD工具,它允许数字设计工程师快速有效地绘制数字时序图。TimeGen时序图可以很容易地导出到其他窗口程序,如microsoftword,用于编写设计规范。可直接从官网下载TimeGEN软件:TimeGen Pro…...
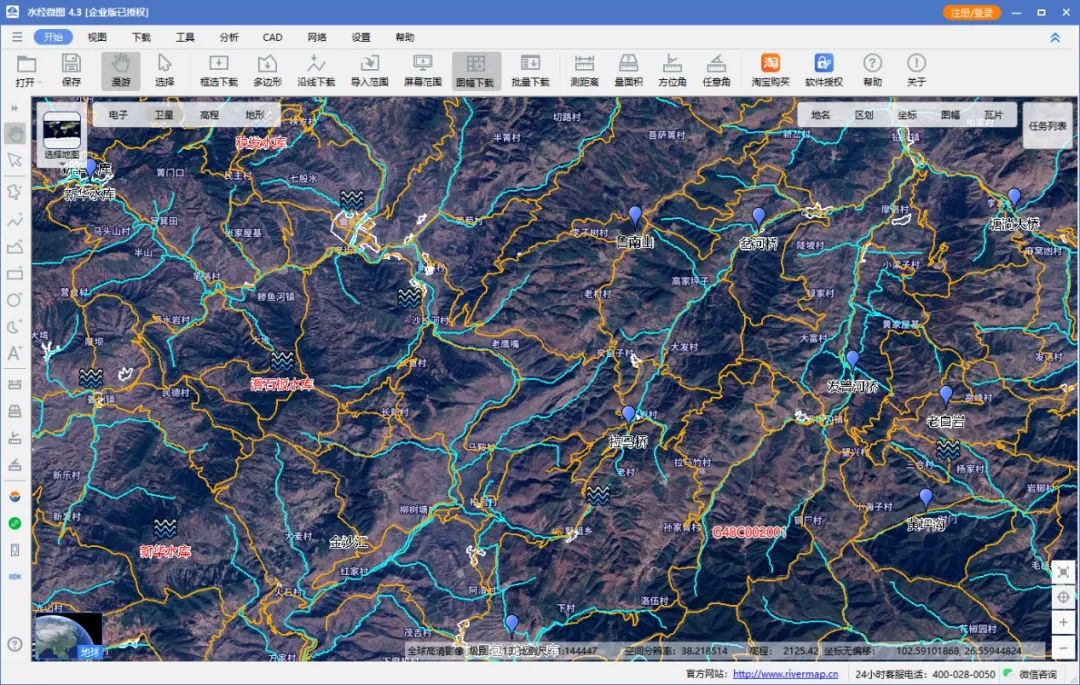
1:25万基础电子地图(云南版)
我们在《50幅1:25万基础电子地图(四川版)》一文中,为你分享过四川的50幅基础电子地图。 现在我们再为你分享云南的1:25万基础电子地图,你可以在文末查看该数据的领取方法。 基础电子地图云南版 下载后可以看到该数据…...
springboot宠物领养系统-计算机毕业设计源码07863
摘 要 21世纪的今天,随着社会的不断发展与进步,人们对于信息科学化的认识,已由低层次向高层次发展,由原来的感性认识向理性认识提高,管理工作的重要性已逐渐被人们所认识,科学化的管理,使信息存…...

牛客热题:最长回文子串
📟作者主页:慢热的陕西人 🌴专栏链接:力扣刷题日记 📣欢迎各位大佬👍点赞🔥关注🚓收藏,🍉留言 文章目录 牛客热题:最长回文子串题目链接方法一&am…...

如何访问寄存器
标题 方式一:对地址进行宏定义方式二:用结构体封装寄存器 访问寄存器是CPU执行程序的基础,每种CPU架构都有其特定的寄存器集合和访问方式。 方式一:对地址进行宏定义 #define GPIOA_BASE ((unsigned int)0x48000000) #define GPI…...

苍穹外卖笔记-18-修改密码、bug记录
文章目录 1 修改密码1.1 需求分析和设计1.2 代码实现1.2.1 admin/EmployeeController1.2.2 EmployeeService1.2.3 EmployeeServiceImpl 1.3 功能测试 2 bug记录 1 修改密码 完结的时候发现还有一个接口未实现。这里补充 1.1 需求分析和设计 产品原型: 业务规则&am…...

java如何截取字符串
如果想在一个字符串中截取一段字符,形成新的字符,那么在java中途需要用到substring语句 substring的语法格式是 str.substring(beginindex,endindex) 其中str是字符串 beginindex是起始索引,endindex是结束索引 截取的字符串包含起始索引…...

虚拟淘宝-Virtual-Taobao论文解读(AAAI2019)
目录 1 论文简介 2 文章的主要贡献 3 文章技术的简要说明 4 技术的详细说明 4.1 GAN-SD:生成客户特征 4.2 MAIL:生成交互过程 4.3 ANC:动规范约束 5 实验设定及结果 6 结论 7 参考 1 论文简介 南京大学LAMDA团队的侍竞成、俞扬等…...
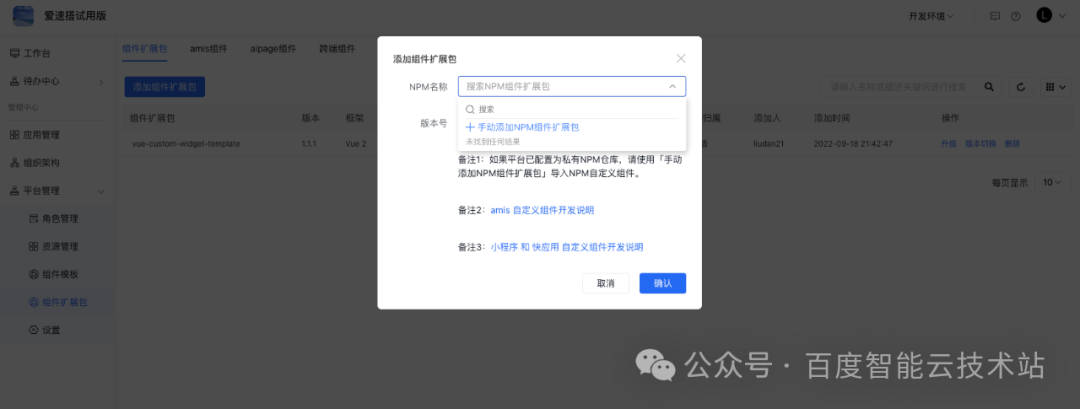
低代码组件扩展方案在复杂业务场景下的设计与实践
组件是爱速搭的前端页面可视化模块的核心能力之一,它将前端研发人员从无休止的页面样式微调和分辨率兼容工作中解放了出来。 目前,爱速搭通过内置的上百种功能组件(120),基本可以覆盖大部分中后台页面的可视化设计场景…...

震撼科技界的GPT-4o发布首日即遭“越狱破防”
前言 本文主要解读分析OpenAI最新推出的大型模型GPT-4o可能存在的越狱风险。 5 月14 日凌晨的科技圈再一次被OpenAI轰动,其发布的最新大模型GPT-4o,能力横跨语音、文本和视觉,这一成果无疑再次巩固了OpenAI在人工智能领域的领先地位。 然而…...
保护密码安全,探讨密码加盐及其在Go语言中的实现
介绍 在当今数字化时代,个人隐私和数据安全成为了人们关注的焦点之一。随着网络犯罪的不断增加,用户的密码安全性变得尤为重要。密码加盐作为一种常见的安全措施,被广泛应用于密码存储和认证系统中。本文将深入探讨密码加盐的概念、重要性以…...
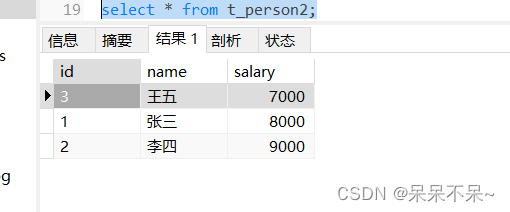
Sqoop学习详细介绍!!
一、Sqoop介绍 Sqoop是一款开源的工具,主要用于在Hadoop(HDFS/Hive/HBase)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的H…...
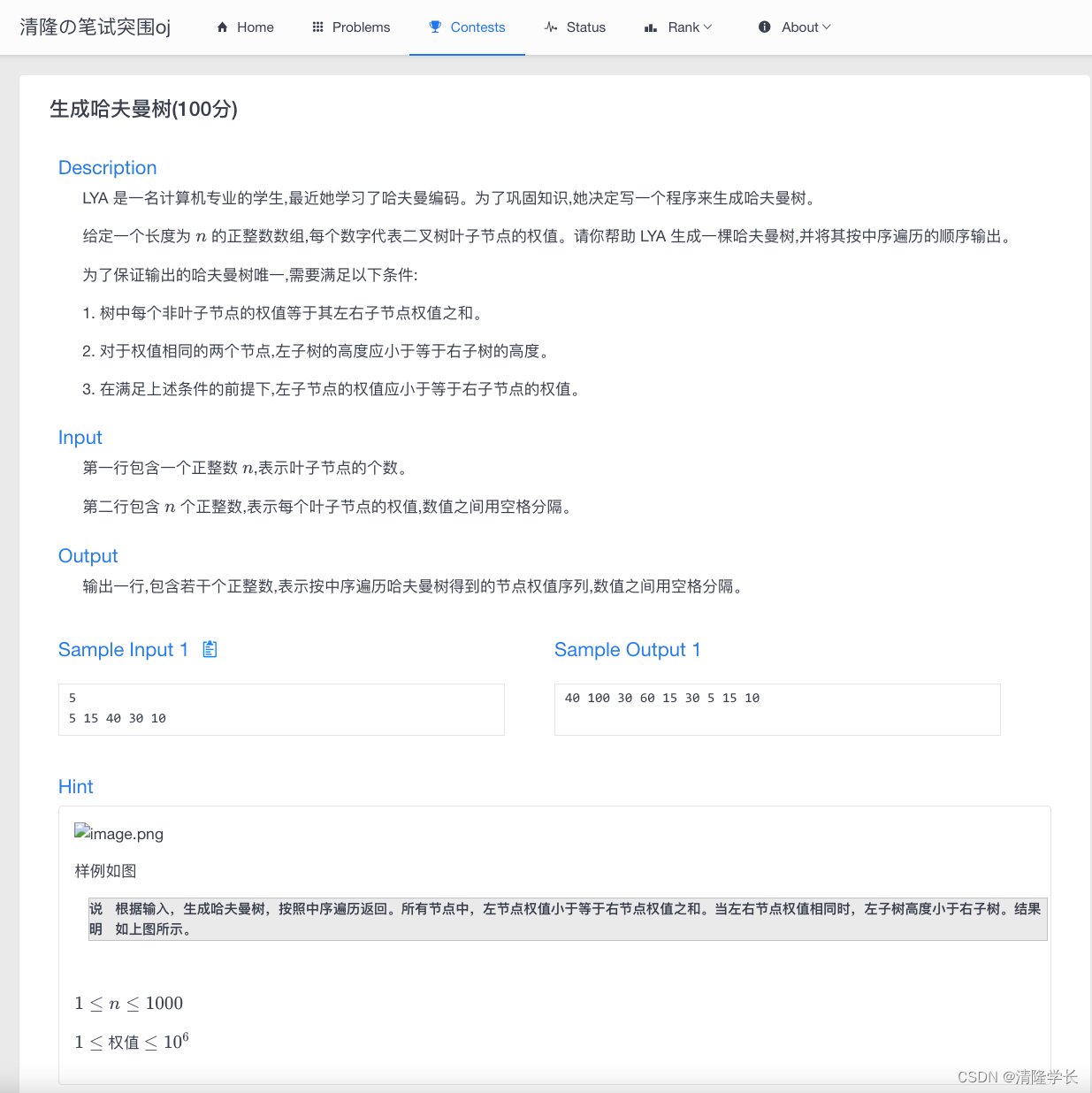
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 生成哈夫曼树(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 📎在线评测链接 生成哈夫曼树(100分) 🌍 评测功能需要订阅专栏后私信联系清…...
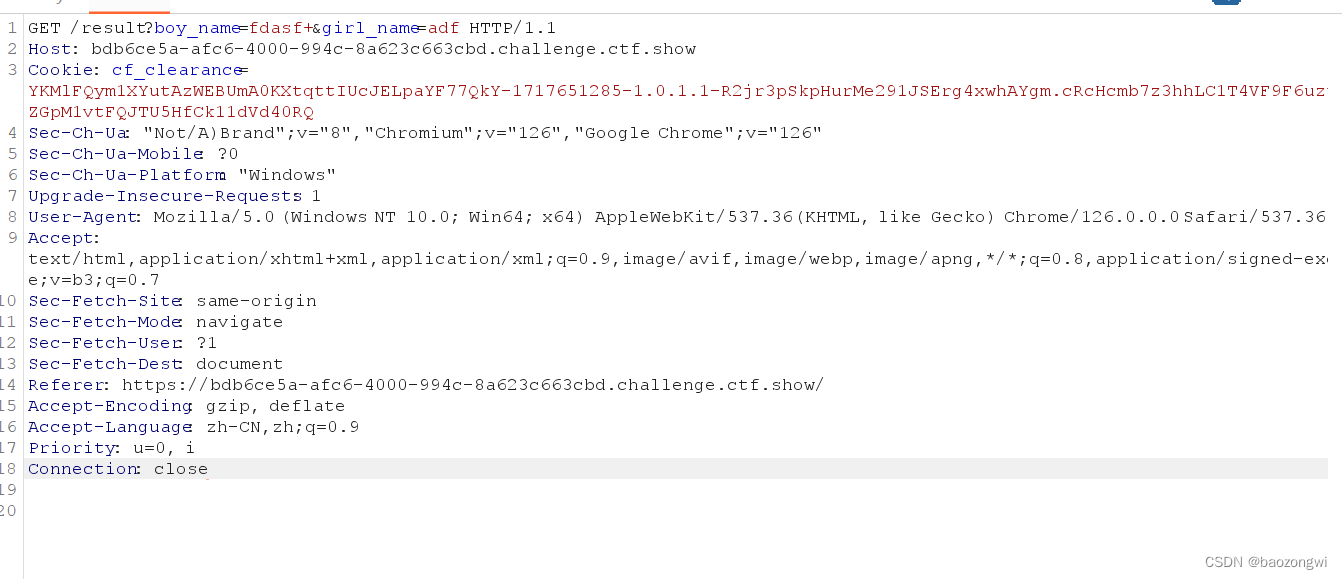
ctfshow web 单身杯
web签到 <?phperror_reporting(0); highlight_file(__FILE__);$file $_POST[file];if(isset($file)){if(strrev($file)$file){ //翻转函数include $file;}}要进行反转并且包含文件用data协议 自己写不好写可以用函数帮你翻转 <?php $adata:text/plain,<?eval(…...

天锐绿盾加密软件,它的适用范围是什么?
天锐绿盾数据防泄密软件的适用范围广泛,主要可以归纳为以下几点: 行业适用性: 适用于各个行业,包括但不限于制造业、设计行业、软件开发、金融服务等,特别是对数据安全性要求较高的行业。企业规模与类型: 适…...

mysql面试题 Day2
1 长文本如何存储? 可以使用Text存储 TINYTEXT(255长度) TEXT(65535) MEDIUMTEXT(int最大值16M) LONGTEXT(long最大值4G) 2 大段文本存储如何设计表结构? 分表存储 分表后多段存储 3 大段文本查找时如何建立索引࿱…...
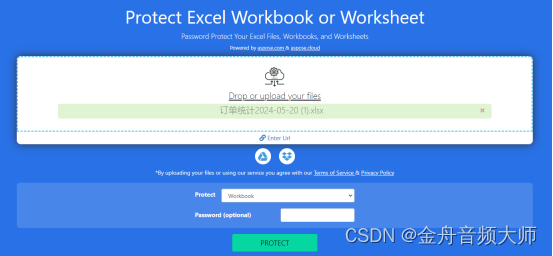
Excel加密怎么设置?这5个方法不容错过!(2024总结)
Excel加密怎么设置?如何不让别人未经允许查看我的excel文件?如果您也有这些疑问,那么千万不要错过本篇文章了。今天小编将向大家分享excel加密的5个简单方法,保证任何人都可以轻松掌握!毫无疑问的是,为Exce…...

2024年下一个风口是什么?萤领优选 轻资产创业项目全国诚招合伙人
2024年,全球经济与科技发展的步伐不断加快,各行各业都在探寻新的增长点与风口。在这样的时代背景下,萤领优选作为一个轻资产创业项目,正以其独特的商业模式和前瞻的市场洞察力,吸引着众多创业者的目光。(领取ÿ…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

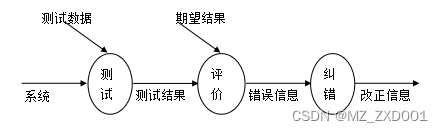
突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...