【机器学习】CART决策树算法的核心思想及其大数据时代银行贷款参考案例——机器认知外界的重要算法
目录
引言
概述
CART决策树的特点
核心思想
减少不确定性的指标
基尼系数(Gini Index)
分类错误率
熵
银行实例
背景
数据准备
模型构建
模型评估与优化
应用与结果
代码示例

✈✈✈✈引言✈✈✈✈
CART算法既可以用于分类问题,也可以用于回归问题,这使得它在多个领域都有广泛的应用。例如,在电商推荐系统中,CART算法可以用于构建商品推荐模型,提高用户购物体验和销售额;在金融风控领域,CART算法可以应用于信用评分和欺诈检测等场景,帮助银行和其他金融机构降低风险。
相比于其他决策树算法(如ID3和C4.5),CART算法具有更强的适用性。它既可以处理离散型数据,也可以处理连续型数据,这使得CART算法能够处理更加复杂和多样化的数据集。
CART决策树生成的模型具有直观易懂的特点,每个节点和分支都代表了数据集中的一种模式或规则。这使得非专业人士也能够理解模型的工作原理,增加了模型的可信度和接受度。
今天来学习一下CART决策树吧
✈其他文章详见✈
【机器学习】机器的登神长阶——AIGC-CSDN博客
【Linux】进程地址空间-CSDN博客【linux】进程控制——进程创建,进程退出,进程等待-CSDN博客
⭐⭐⭐概述⭐⭐⭐
CART(Classification and Regression Trees)决策树是一种以基尼系数为核心评估指标的机器学习算法,适用于分类和回归任务。
CART决策树基于“递归二元切分”的方法,通过将数据集逐步分解为两个子集来构建决策树。CART既能作为分类树(预测离散型数据),也能作为回归树(预测连续型数据)。外观类似于二叉树。
对于每个节点,计算所有非类标号属性的基尼系数增益,选择增益值最大的属性作为决策树的划分特征。
通过递归的方式,将数据子集和分裂规则分解为一个二叉树,其中叶节点表示具体的类别(分类树)或预测值(回归树)。
CART决策树的特点
简单易懂:计算简单,易于理解,可解释性强。
处理缺失值:比较适合处理有缺失属性的样本。
处理大型数据集:能够在相对短的时间内对大型数据源得出可行且效果良好的结果。
模型复杂度:可以通过限制决策树的最大深度或叶子节点的最小样本数来控制模型的复杂度。
过拟合风险:CART决策树容易出现过拟合现象,生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据未必有很好的分类能力。
在线学习:CART决策树不支持在线学习,当有新的样本产生后,决策树模型需要重建。
以scikit-learn库中的CART决策树分类器为例,演示如何使用CART决策树进行分类任务
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score # 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建CART决策树分类器对象(使用默认参数,即为CART决策树)
clf = DecisionTreeClassifier(random_state=42) # 使用训练数据拟合模型
clf.fit(X_train, y_train) # 使用测试数据进行预测
y_pred = clf.predict(X_test) # 计算并打印准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)🧠🧠🧠核心思想🧠🧠🧠
| 特征1 | 特征2 | 目标值 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
有两种决策树的构建方法
以不同的特征作为根节点会有不同的模型
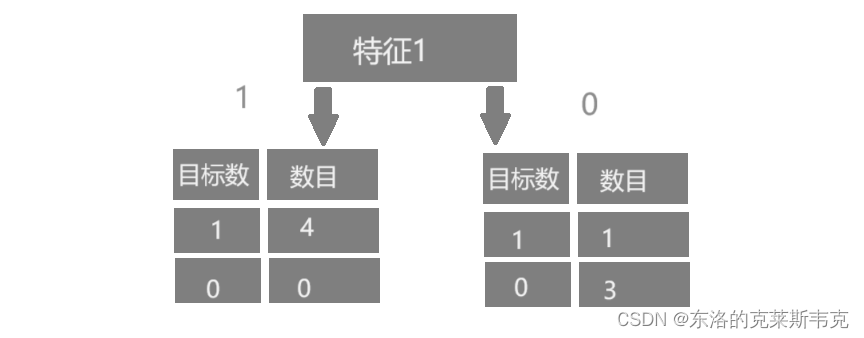
示例一
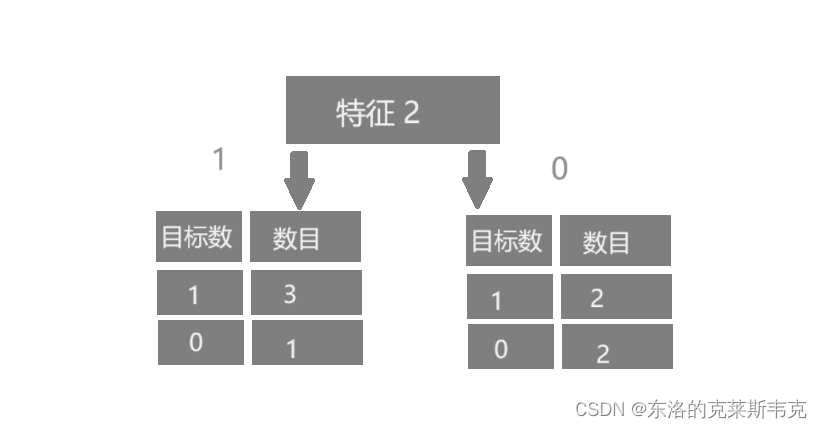
示例二
对于以特征一为根节点的树来说,传入参数为1,大概率会得到 1。传入参数为 0 大概率会得到 0。
对于以特征二为根节点的树来说,传入参数为1,大概率会得到 1。传入参数为 0 ,输出 1 的概率和输出0,的概率是相等的。这样的决策树的不确定性太高。
综上,应以以特征1为根节点
✌✌减少不确定性的指标✌✌
基尼系数(Gini Index)
基尼系数是CART决策树中用于分类任务的一个评估指标,用于衡量数据集的不确定性。基尼系数的值介于0和1之间,值越大,表示数据集的不确定性越高,纯度越低。
对于包含K个类别的数据集D,其基尼系数的定义为:
Gini(D)=1−∑k=1Kpk2
其中,pk表示第k个类别在数据集D中出现的概率。
当使用某个特征A对数据进行划分时,划分后数据集D的基尼系数定义为:
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
其中,D1和D2表示按照特征A进行划分后得到的两个子集,∣D∣、∣D1∣和∣D2∣分别表示数据集D、D1和D2的样本数量。
分类错误率
CART决策树的分类错误率是指在使用CART算法构建的决策树模型对测试集进行分类时,错误分类的样本数占总样本数的比例。错误率的计算依赖于具体的数据集和模型表现。
在CART决策树的构建过程中,为了降低分类错误率,通常会使用诸如Gini指数(Gini Index)或信息增益(Information Gain)等度量标准来选择最佳划分特征。CART算法倾向于选择那些能够使得划分后子节点纯度更高的特征,即分类错误率更低的特征。
CART决策树的分类错误率可以通过以下步骤计算:
数据准备:首先,需要有一个已经标记好类别的数据集,并将其划分为训练集和测试集。
模型训练:使用训练集来训练CART决策树模型。在这个过程中,模型会基于Gini指数或其他度量标准来选择最佳划分特征,并递归地构建决策树。
模型评估:将训练好的CART决策树模型应用于测试集,并对测试集中的每个样本进行分类。
计算错误率:统计测试集中被错误分类的样本数,并将其除以测试集的总样本数,得到CART决策树的分类错误率。
需要注意的是,CART决策树的分类错误率会受到多种因素的影响,包括数据集的特性、特征的选择、树的深度(即剪枝的程度)等。因此,在实际应用中,通常需要通过交叉验证等技术来评估模型的表现,并选择最优的模型参数。
此外,对于不同的数据集和任务,CART决策树的分类错误率也会有所不同。在一些复杂的数据集上,CART决策树可能难以达到很低的错误率,但在一些简单的数据集上,CART决策树可以取得很好的效果。因此,在选择使用CART决策树时,需要根据具体的应用场景和数据集特性来评估其适用性。
熵
CART决策树在分类任务中并不直接使用熵(Entropy)作为划分标准,而是采用基尼不纯度(Gini Impurity)或者说基尼系数。
熵是信息论中的一个重要概念,用于衡量数据的不确定性或混乱程度。
在决策树中,熵通常用于ID3算法,作为划分数据集的特征选择。
熵的计算公式为:
(H(X) = -\sum_{i=1}^{n} p(x_i) \log_2 p(x_i)),其中(p(x_i))是某个类别在数据集中的比例。
CART决策树与熵的关系:
不直接使用熵:CART决策树在分类任务中不直接使用熵作为划分标准,而是采用基尼不纯度。
基尼不纯度:基尼不纯度也是衡量数据混乱程度的一个指标,但计算上更为简单。其计算公式为:(Gini(D) = 1 - \sum_{i=1}{n} p(x_i)2),其中(p(x_i))是类别(i)在数据集(D)中的概率。
选择划分特征:CART决策树通过计算每个特征的基尼不纯度增益来选择最佳划分特征。基尼不纯度增益定义为父节点的基尼不纯度减去所有子节点基尼不纯度的加权平均。
CART决策树的特征选择:CART决策树通过递归地将数据集划分为越来越小的子集来构建决策树。
在每个节点上,CART决策树会评估每个特征,并选择能够最大程度地减少基尼不纯度的特征进行划分。
通过不断地划分,CART决策树可以逐渐构建出一个高效的分类器。
💵💵💵银行实例💵💵💵

背景
一家大型银行为了提高信贷审批的效率和准确性,决定采用决策树算法来辅助审批过程。银行收集了包括客户年龄、收入、信用记录等多个维度的数据,这些数据将作为特征数据输入到决策树模型中。
数据准备
数据收集:银行从客户档案、信贷申请表中提取关键信息,如年龄、收入、职业、信用历史等。
数据清洗:对收集到的数据进行清洗,去除重复、错误或无效的数据,确保数据的准确性和可靠性。
特征选择:从所有可能的特征中,选择对分类有较大贡献的特征。在信贷审批中,通常会选择年龄、收入、信用记录等作为关键特征。
模型构建
数据划分:将清洗后的数据集划分为训练集和测试集。训练集用于构建决策树模型,测试集用于评估模型的性能。
构建决策树:从根节点开始,递归地选择最优特征对数据进行划分。在信贷审批中,例如,第一个节点可能根据年龄进行划分,将客户分为青年、中年和老年三组。然后,在每个子节点上,再根据其他特征(如收入、信用记录等)进行进一步的划分。
计算节点纯度:计算每个节点的纯度,即该节点下数据属于同一类别的比例。纯度越高,说明该节点下的数据越纯净,分类效果越好。
停止条件:当节点中的样本数量低于预定阈值、节点纯度达到预定阈值或树的深度达到预定阈值时,停止划分并生成叶节点。叶节点对应于最终的决策结果,如“批准贷款”或“拒绝贷款”。
模型评估与优化
评估模型性能:使用测试集评估构建好的决策树模型的性能。常用的评估指标包括准确率、召回率、F1值等。通过评估结果,可以了解模型在信贷审批中的表现。
模型优化:如果模型性能不佳,可以通过调整参数(如树的深度、最小样本数等)或采用集成学习(如随机森林)等方法来优化模型。
应用与结果
自动化审批:将构建好的决策树模型集成到银行的信贷审批系统中,实现自动化审批。当客户提交信贷申请时,系统可以自动调用模型进行预测,并给出审批结果。
提高审批效率:通过自动化审批,银行可以大大提高审批效率,减少人工干预和等待时间据统计,采用决策树算法后,贷款审批的准确率提高了10%,审批时间缩短了30%。
优化客户体验:客户可以更快地获得审批结果,提高了客户满意度和忠诚度。同时,银行也能更准确地识别高风险客户,降低信贷风险。
代码示例
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score # 1. 数据准备
# 假设数据集为'credit_data.csv',包含'Age', 'Income', 'Credit_History', 'Loan_Status'等列
data = pd.read_csv('credit_data.csv') # 查看数据前几行
print(data.head()) # 假设'Loan_Status'是目标变量,其中'Y'表示批准贷款,'N'表示拒绝贷款
X = data[['Age', 'Income', 'Credit_History']] # 特征变量
y = data['Loan_Status'].map({'Y': 1, 'N': 0}) # 目标变量,转换为0和1 # 2. 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 3. 模型构建
clf = DecisionTreeClassifier(random_state=42) # 创建决策树分类器
clf.fit(X_train, y_train) # 训练模型 # 4. 预测与评估
y_pred = clf.predict(X_test) # 对测试集进行预测
accuracy = accuracy_score(y_test, y_pred) # 计算准确率 print(f"Accuracy: {accuracy}") # 5. 可视化决策树(可选,对于较大的树可能不易阅读)
# 需要安装 graphviz 和 pydotplus 库
# from sklearn.tree import export_graphviz
# import pydotplus
# dot_data = export_graphviz(clf, out_file=None,
# feature_names=X.columns,
# class_names=['No', 'Yes'],
# filled=True, rounded=True,
# special_characters=True)
# graph = pydotplus.graph_from_dot_data(dot_data)
# graph.write_png('loan_approval_tree.png') # 注意:可视化部分可能需要额外的库,并且对于复杂的树可能不太实用。相关文章:
【机器学习】CART决策树算法的核心思想及其大数据时代银行贷款参考案例——机器认知外界的重要算法
目录 引言 概述 CART决策树的特点 核心思想 减少不确定性的指标 基尼系数(Gini Index) 分类错误率 熵 银行实例 背景 数据准备 模型构建 模型评估与优化 应用与结果 代码示例 ✈✈✈✈引言✈✈✈✈ CART算法既可以用于分类问题࿰…...

编程软件是由什么编程的
编程软件是由什么编程的 在数字化的世界里,编程软件作为构建数字生态的基石,其背后所蕴含的奥秘往往令人感到困惑。那么,这些编程软件究竟是由什么编程的呢?这背后隐藏着怎样的逻辑与技术?接下来,我们将从…...
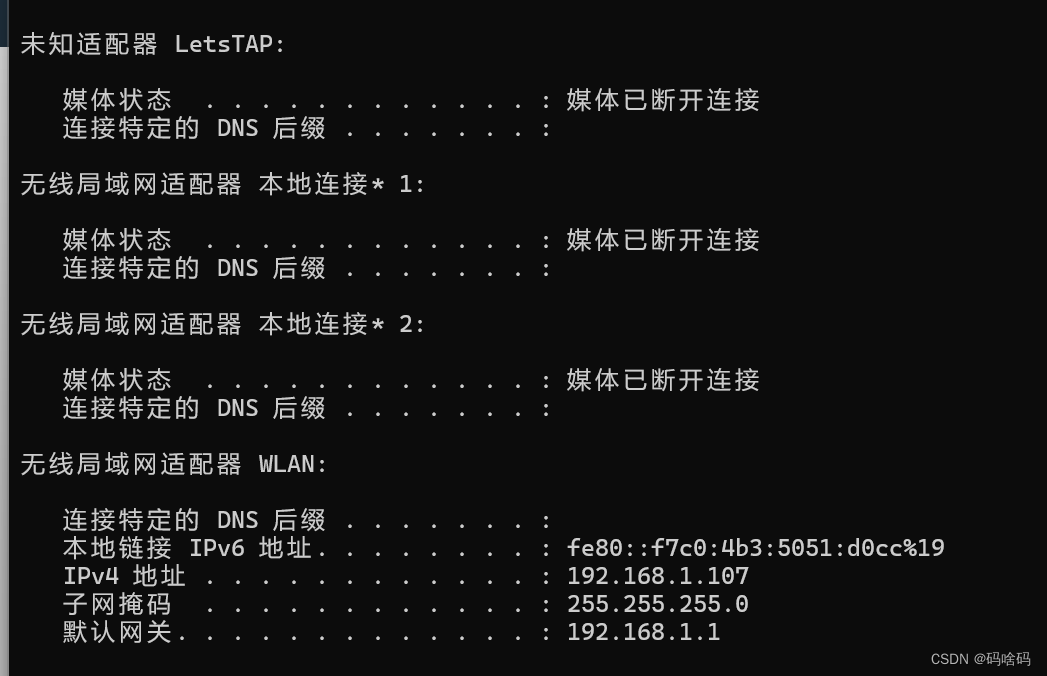
如何查看自己本地ip
1.winR 2.cmd 3.ipconfig...

高考分数限制下,选好专业还是选好学校?
高考分数限制下,选好专业还是选好学校? 高考作为每年一度的盛大考试,不仅关乎学生们的未来,更承载了家庭的期望。2004年高考刚刚结束,许多考生和家长已经开始为填报志愿而焦虑。选好学校和专业,直接关系到…...
项目实战)
Django学习(2)项目实战
1、环境及简介 前端开发:HTML、CSS、JavaScript 后端开发:Java、PHP、Python、GO 数据库:MySQL、MSSQL、Oracle、Redis 安装Django pip install Django 或 下载.whl后 pip install D:\xxx.whl 创建Django项目 File--New Projec…...
pdf格式转成jpg图片,pdf格式如何转jpg
pdf转图片的方法,对于许多人来说可能是一个稍显陌生的操作。然而,在日常生活和工作中,我们有时确实需要将pdf文件转换为图片格式,以便于在特定的场合或平台上进行分享、展示或编辑。以下,我们将详细介绍一个pdf转成图片…...
Java的三个接口Comparable,Comparator,Cloneable(浅拷贝与深拷贝)
Comparable 当我们要进行对象的比较的时候,我们是不能直接用>、< 这些符号直接进行比较的。 由于这是引用类型变量也是自定义类型变量,直接进行比较的时候,我们是通过对象的地址进行比较的,我们可以使用、! 进行两个对象的…...
pytorch学习笔记7
getitem在进行索引取值的时候自动调用,也是一个魔法方法,就像列表索引取值那样,一个意思 import torchvision from torch.utils.data import DataLoaderdata_transformtorchvision.transforms.Compose([torchvision.transforms.ToTensor()] ) test_datatorchvision.datasets.C…...

LeetCode热题3.无重复的最长字串
前言: 经过前序的一系列数据结构和算法学习后,开始用leetCode热题练练手。 . - 力扣(LeetCode) 给定一个字符串 s ,请你找出其中不含有重复字符的最长子串的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为…...
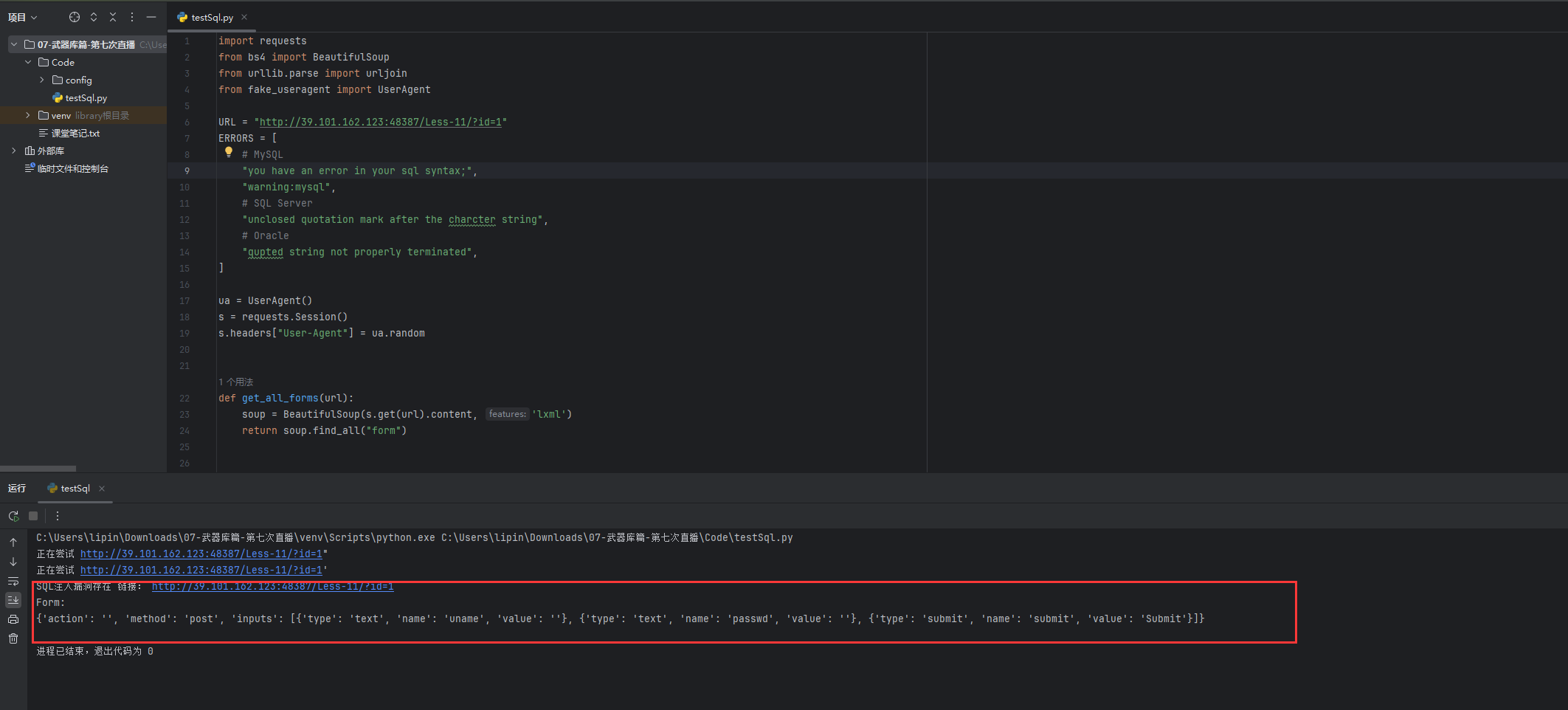
Python武器库开发-武器库篇之SQL注入扫描器(五十九)
Python武器库开发-武器库篇之SQL注入扫描器(五十九) SQL注入漏洞简介以及危害 SQL注入漏洞是一种常见的Web应用程序漏洞,攻击者可以利用该漏洞在应用程序的数据库中执行恶意的SQL查询或指令。这可能导致数据泄露、数据损坏、应用程序崩溃或未经授权的访问。 SQL注…...

图说设计模式:单例模式
更多C学习笔记,关注 wx公众号:cpp读书笔记 5. 单例模式 单例模式 模式动机模式定义模式结构时序图代码分析模式分析实例优点缺点适用环境模式应用模式扩展总结 5.1. 模式动机 对于系统中的某些类来说,只有一个实例很重要,例如…...
探索设计模式——单例模式详解
前言:设计模式的作用主要是为了——利用设计方式的重用来自动地提高代码的重新利用、提高代码的灵活性、节省时间, 提高开发效率、低耦合,封装特性显著, 接口预留有利于扩展。 设计模式的种类有很多种,本篇内容主要讲解…...
建筑垃圾/城市固废倾倒转移乱象:EasyCVR+AI智能视频监控方案助力城市环保监管
近日有新闻记者报道,中央生态环境保护督察组在上海、浙江、江西、湖北、湖南、重庆、云南7省市督察发现,一些地方建筑垃圾处置工作存在明显短板,乱堆乱倒问题时有发生,比如,江西湘东区在杨家田地块违规设置弃土场&…...

C的I/O操作
目录 引言 一、文件与目录操作 1. 打开与关闭文件 2. 文件读写操作 3. 文件定位与错误处理 二、字符流与字节流 1. 字符流处理 2. 字节流处理 三、序列化与反序列化 1. 序列化 2. 反序列化 四、新的I/O(NIO) 表格总结 文件与目录操作 字符…...
)
Android Audio实战——声道信息回调(五)
在前面的 AudioTrack 构造中,我们传入了音频的声道信息,这一节我们就来详细介绍一下声道的配置信息。 一、声道介绍 音频中的声道配置从单声道到双声道(立体声)、再到多声道系统(如5.1和7.1),代表了声音录制和回放技术的发展,旨在提供越来越丰富和沉浸式的听觉体验。 …...
)
ThreeJS给模型添加介绍文字(贴在模型上 不会一直面向我们)
使用到 FontLoader跟 TextGeometry 引包 import {TextGeometry} from "three/examples/jsm/geometries/TextGeometry"; import {FontLoader} from "three/examples/jsm/loaders/FontLoader";使用 // 创建字体加载器并加载字体 const fontLoader new Fo…...
[Qt] Qt Creator 以及 Qt 在线安装教程
一、Qt Creator 下载及安装 1、从以下镜像源下载安装包常规安装即可 Qt Creator 也可以在第二步Qt 在线安装时一次性勾选安装,见后文 Qt Creator 中科大源下载地址 二、Qt 在线安装 1、根据所在平台选择对应的安装器下载 Qt 在线安装器下载 2、可能的安装报错…...

【大分享05】动态容差归档,打通不动产登记管理“最后一公里”
关注我们 - 数字罗塞塔计划 - 本篇是参加由电子文件管理推进联盟联合数字罗塞塔计划发起的“大分享”活动投稿文章,来自上海涵妍档案信息技术有限责任公司,作者:陈雪。 一、政策背景 在“互联网政务服务”的浪潮下,各级政府机构…...
)
嵌入式模拟电路面试题大全及参考答案(持续更新)
目录 理想运算放大器的两个基本特性 共模抑制比(CMRR)及其重要性 负反馈在放大器中的作用 差分放大电路的工作原理 使用运算放大器构建非反相放大器 电源抑制比(PSRR) 带宽(BW)在放大器中的含义 计算RC低通滤波器的截止频率 基本的积分电路及其时间常数 增益-带…...

【C语言】解决C语言报错:Uninitialized Variable
文章目录 简介什么是Uninitialized VariableUninitialized Variable的常见原因如何检测和调试Uninitialized Variable解决Uninitialized Variable的最佳实践详细实例解析示例1:局部变量未初始化示例2:数组未初始化示例3:指针未初始化示例4&am…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...