深入Node.js:实现网易云音乐数据自动化抓取

随着互联网技术的飞速发展,数据已成为企业和个人获取信息、洞察市场趋势的重要资源。音频数据,尤其是来自流行音乐平台如网易云音乐的数据,因其丰富的用户交互和内容多样性,成为研究用户行为和市场动态的宝贵资料。本文将深入探讨如何使用Node.js技术实现网易云音乐数据的自动化抓取。
一、Node.js简介
Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它允许开发者在服务器端运行JavaScript代码。Node.js的非阻塞I/O模型使其在处理大量并发连接时表现出色,非常适合构建高性能的网络应用。
二、项目准备
在开始构建网易云音乐数据抓取项目之前,我们需要准备以下工具和库:
- Node.js环境:确保已安装Node.js。
- npm(Node Package Manager):Node.js的包管理器,用于安装和管理项目依赖。
- Mongoose:一个MongoDB对象模型工具,用于操作数据库。
- Cheerio:一个服务器端的jQuery实现,用于解析HTML。
- Request或Axios:用于发送HTTP请求。
- 代理服务器:由于反爬虫机制,可能需要使用代理服务器。
三、项目结构设计
一个基本的网易云音乐数据抓取项目可能包含以下几个部分:
- 数据库模型设计:使用Mongoose设计音频数据的存储模型。
- 爬虫逻辑:编写爬取网易云音乐数据的逻辑。
- 数据解析:解析爬取到的HTML,提取音频信息。
- 数据存储:将解析得到的数据存储到MongoDB数据库。
- 错误处理:处理网络请求和数据解析过程中可能出现的错误。
- 定时任务:设置定时任务,实现数据的周期性抓取。
四、实现步骤
4.1 安装依赖
首先,通过npm安装所需的库:
npm install mongoose cheerio request axios
4.2 设计数据库模型
使用Mongoose设计一个音频数据模型,例如:
const mongoose = require('mongoose');const AudioSchema = new mongoose.Schema({title: { type: String, required: true },artist: { type: String, required: true },url: { type: String, required: true },duration: { type: Number, required: true },
});const Audio = mongoose.model('Audio', AudioSchema);
4.3 编写爬虫逻辑
编写一个异步函数crawlAudio,用于爬取网易云音乐的数据:
const axios = require('axios');
const cheerio = require('cheerio');// 设置代理信息
process.env.http_proxy = 'http://' + encodeURIComponent('16QMSOML') + ':' + encodeURIComponent('280651') + '@www.16yun.cn:5445';
process.env.https_proxy = process.env.http_proxy;async function crawlAudio(url) {try {// 使用axios发送请求,代理配置已经在环境变量中设置const response = await axios.get(url);const $ = cheerio.load(response.data);const audios = [];// 假设Audio是之前定义的Mongoose模型$('audio').each((index, element) => {const title = $(element).attr('title');const artist = $(element).attr('artist');const url = $(element).attr('src');const duration = $(element).attr('duration');audios.push({ title, artist, url, duration }); // 这里应该是一个对象,而不是Audio实例});// 批量保存到数据库,假设Audio.insertMany是之前定义的Mongoose模型的静态方法await Audio.insertMany(audios);} catch (error) {console.error('Crawl error:', error);}
}// 调用函数,传入需要爬取的URL
crawlAudio('http://music.163.com/discover');
4.4 数据解析与存储
在爬虫逻辑中,使用Cheerio解析HTML,提取音频的标题、艺术家、URL和时长,然后创建Audio模型的实例,并保存到MongoDB数据库。
4.5 错误处理
在爬虫函数中添加错误处理逻辑,确保在请求失败或解析错误时能够记录错误信息,避免程序崩溃。
4.6 设置定时任务
使用Node.js的node-schedule库设置定时任务,例如每天凌晨抓取数据:
const schedule = require('node-schedule');schedule.scheduleJob('0 0 * * *', function(){crawlAudio('http://music.163.com/discover');
});
五、项目优化
- 代理池管理:为了应对IP被封的问题,可以引入代理池管理,动态切换代理。
- 分布式爬虫:对于大规模的数据抓取,可以考虑使用分布式爬虫技术。
- 数据清洗:对抓取的数据进行清洗,确保数据的准确性和可用性。
- 用户行为分析:对抓取的数据进行分析,挖掘用户行为模式和市场趋势。
相关文章:
深入Node.js:实现网易云音乐数据自动化抓取
随着互联网技术的飞速发展,数据已成为企业和个人获取信息、洞察市场趋势的重要资源。音频数据,尤其是来自流行音乐平台如网易云音乐的数据,因其丰富的用户交互和内容多样性,成为研究用户行为和市场动态的宝贵资料。本文将深入探讨…...
【Docker实战】jenkins卡在编译Dockerfile的问题
我们的项目是标准的CI/CD流程,也即是GitlabJenkinsHarborDocker的容器自动化部署。 经历了上上周的docker灾难,上周的服务器磁盘空间灾难,这次又发生了jenkins卡住的灾难。 当然,这些灾难有一定的连锁反应,是先发生的d…...

rust 多线程分发数据
use std::sync::{Arc, Mutex}; use std::collections::VecDeque; use std::thread::{self, sleep}; use rand::Rng; use std::time::Duration;fn main() {let list: Arc<Mutex<VecDeque<String>>> Arc::new(Mutex::new(VecDeque::new()));// 创建修改线程le…...

CentOS 7x 使用Docker 安装oracle11g完整方法
1.安装docker-ce 安装依赖的软件包 yum install -y yum-utils device-mapper-persistent-data lvm2添加Docker的阿里云yum源 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo更新软件包索引 yum makecache fast查看docker…...
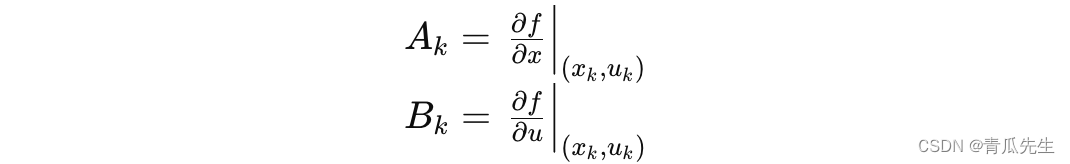
DDP算法之线性化和二次近似(Linearization and Quadratic Approximation)
DDP算法线性化和二次近似 在DDP算法中,第三步是线性化系统动力学方程和二次近似代价函数。这一步是关键,它使得DDP能够递归地处理非线性最优控制问题。通过线性化和二次近似,我们将复杂的非线性问题转换为一系列简单的线性二次问题,逐步逼近最优解。通过这些线性化和二次近…...

Shellcode详解
Shellcode详解 一、Shellcode的特点二、Shellcode的类型三、Shellcode的工作原理四、防御措施五、常见的PHP Web Shell示例5.1 简单的命令执行5.2 更复杂的Web Shell5.3 防御措施5.4 实际案例 Shellcode是一种小巧、紧凑的机器代码,通常用于利用软件漏洞或注入攻击中…...
+语音识别Python API)
sherpa-onnx说话人识别+语音识别自动开启(VAD)+语音识别Python API
专栏总目录 获取该开源项目的渠道,是我在b站上,看到了由csukuangfj制作的一套语音识别视频。以下地址均为csukuangfj在视频中提供,感谢分享! 新一代 Kaldi: 说话人识别+VAD+语音识别之 Python API_哔哩哔哩_bilibili 开源项目地址:GitHub - k2-fsa/sherpa-onnx: Speech-t…...
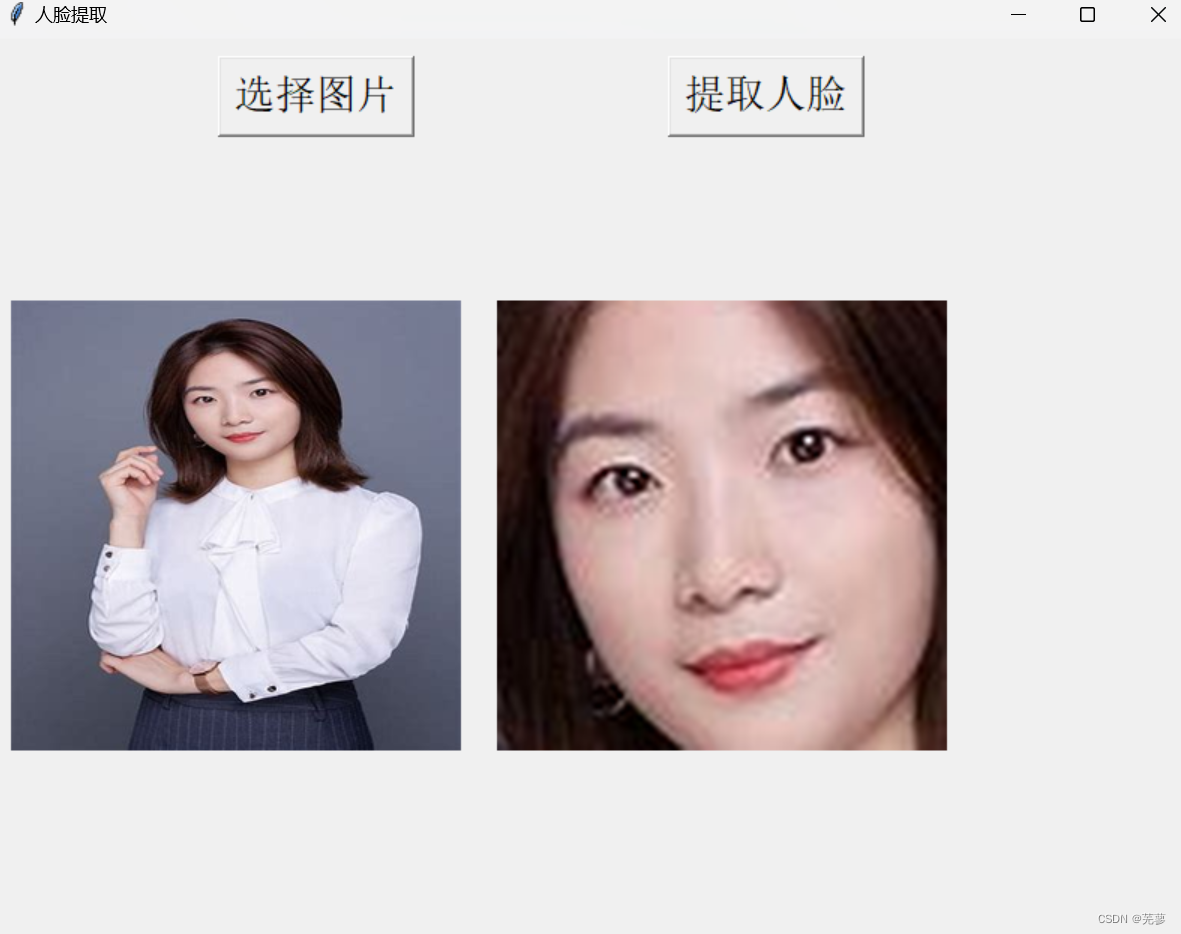
提取人脸——OpenCV
提取人脸 导入所需的库创建窗口显示原始图片显示检测到的人脸创建全局变量定义字体对象定义一个函数select_image定义了extract_faces函数设置按钮运行GUI主循环运行显示 导入所需的库 tkinter:用于创建图形用户界面。 filedialog:用于打开文件对话框。 …...
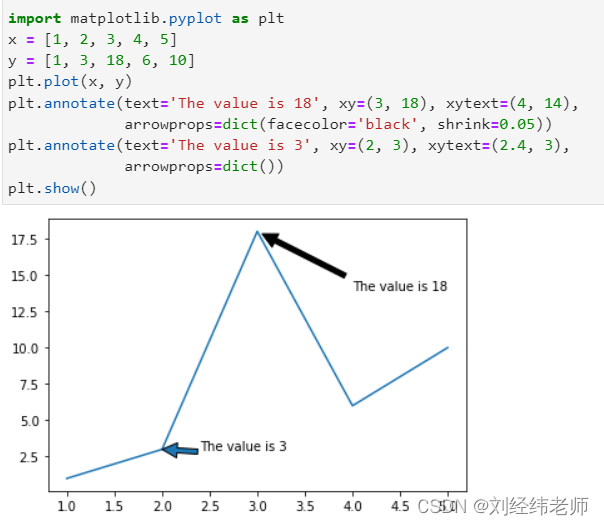
python数据可视化:在图形中添加注释matplotlib.pyplot.annotate()
【小白从小学Python、C、Java】 【考研初试复试毕业设计】 【Python基础AI数据分析】 python数据可视化: 在图形中添加注释 matplotlib.pyplot.annotate() 请问关于以下代码表述正确的选项是? import matplotlib.pyplot as plt x [1, 2, 3, 4, 5] y […...
IDEA debug 调试Evaluate Expression应用
链接: https://blog.csdn.net/xfx_1994/article/details/104136849?utm_mediumdistribute.pc_aggpage_search_result.none-task-blog-2aggregatepagefirst_rank_v2~rank_aggregation-2-104136849.pc_agg_rank_aggregation&utm_termidea%E4%B8%ADevaluate&s…...
04-echarts-立体柱状图扩展
柱状图扩展 一、前言二、思路1、新增面①、在drawShape方法中,新增一个实际左侧面,②、 在drawShape方法中,新增一个实际右侧面,③ 绘制 2、新增series对象① 添加实际值的左侧面和右侧面 三、效果图 一、前言 事情是这样子的&am…...

HTML5 Web Workers: 异步编程的强大力量
在现代Web开发中,随着应用程序变得越来越复杂,用户界面的流畅性和响应性成为了决定用户体验好坏的关键因素之一。传统的JavaScript执行模型中,所有脚本都在同一个线程上运行,这意味着复杂的计算任务会阻塞UI更新,导致页…...
Flutter第十二弹 Flutter多平台运行
目标: 1.在多平台调试启动Flutter程序运行 一、安卓模拟器 1.1 检查当前Flutter适配的版本 flutter doctor提供了Flutter诊断。 $ flutter doctor --verbose /Users/zhouronghua/IDES/flutter/bin/flutter doctor --verbose [✓] Flutter (Channel master, 2.1…...
30天学会QT---------------大项目之在线考试系统
前段时间真的很忙很忙,忙完这段时间,总算是有空来写文章了,开始写的时候我就以为能够有时间准备和写这个,但是发现有时候忙着忙着就忘记了,没有办法来写项目,真的是非常尴尬。 现在有时间了,就有充分的时间来写了。 为了避免笔记断更,我决定先存稿来写。 1、如何规划项…...

搜维尔科技:力反馈主手—手术机器人应用〈腔镜手术机器人平台—进入手术室动物实验〉
力反馈主手—手术机器人应用〈腔镜手术机器人平台—进入手术室动物实验〉 搜维尔科技:力反馈主手—手术机器人应用〈腔镜手术机器人平台—进入手术室动物实验〉...
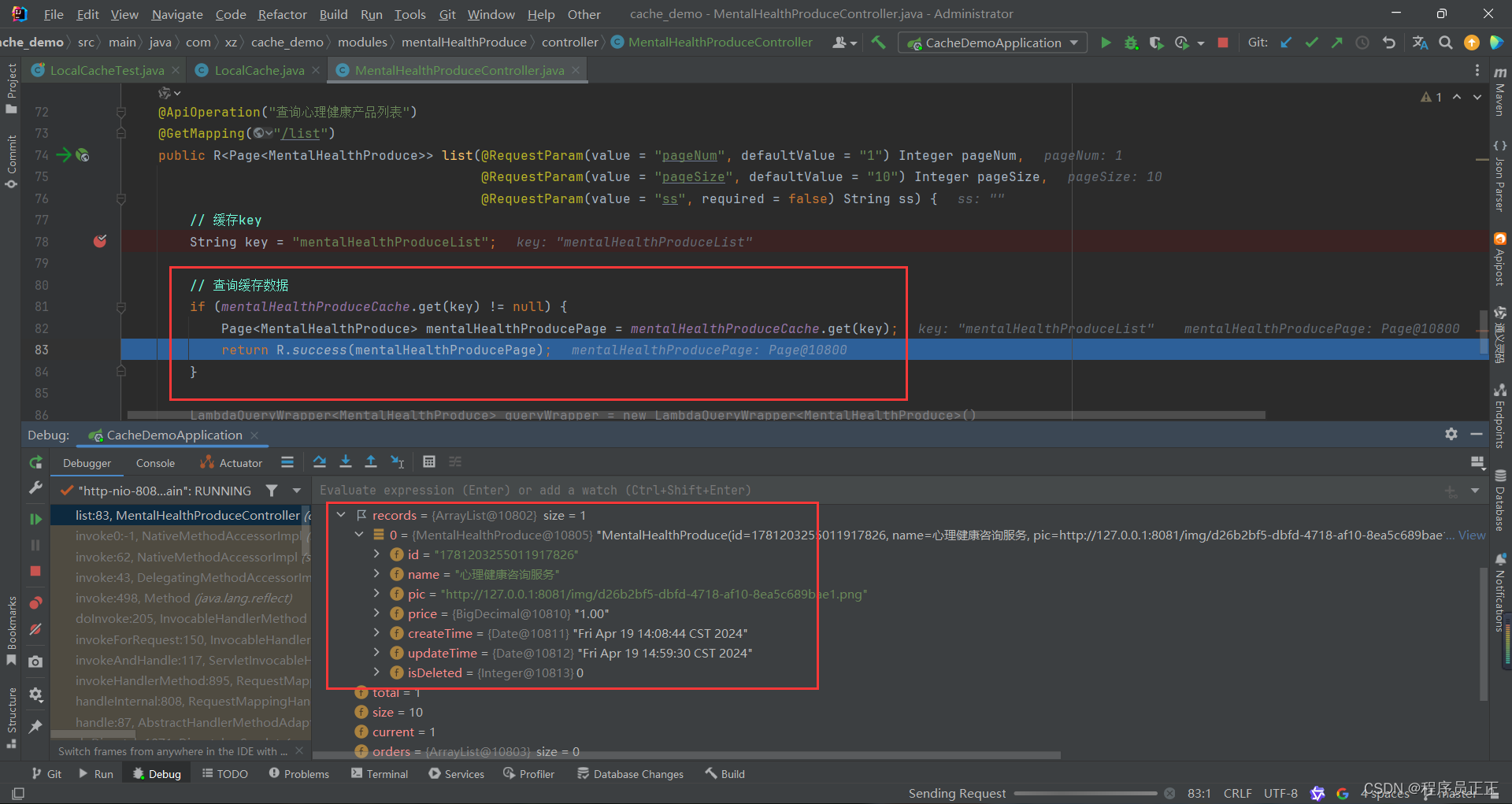
缓存技术实战[一文讲透!](Redis、Ecache等常用缓存原理介绍及实战)
目录 文章目录 目录缓存简介工作原理缓存分类1.按照技术层次分类2.按照应用场景分类3.按照缓存策略分类 应用场景1.硬件缓存2.软件缓存数据库缓存Web开发应用层缓存 3.分布式缓存4.微服务架构5.移动端应用6.大数据处理7.游戏开发 缓存优点缓存带来的问题 常见常用Java缓存技术1…...
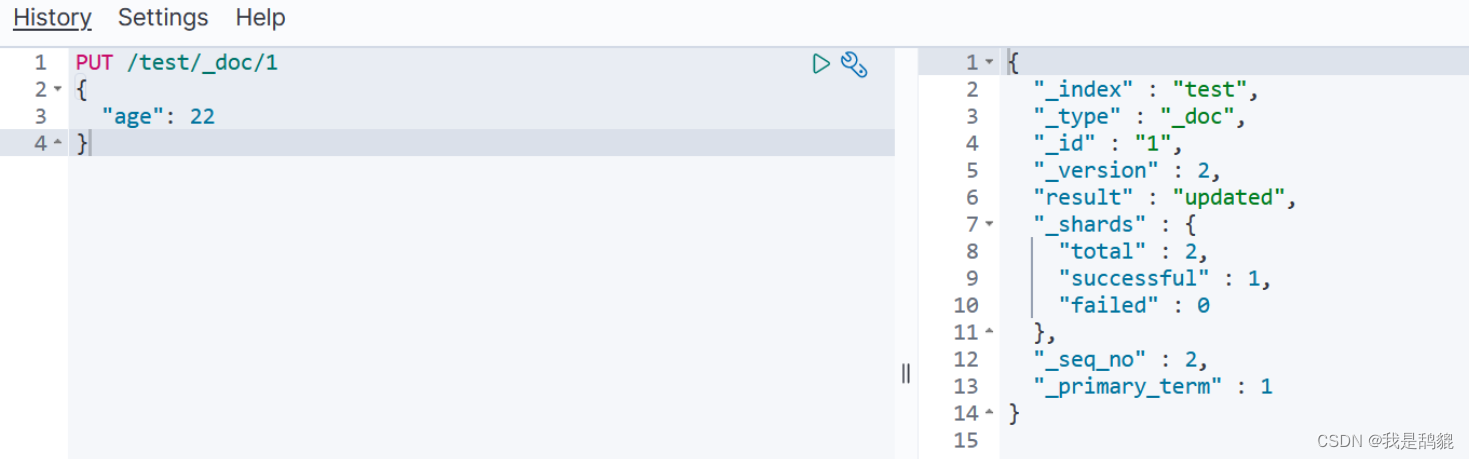
初识es(elasticsearch)
初识elasticsearch 什么是elasticsearch?: 一个开源的分部署搜索引擎、可以用来实现搜索、日志统计、分析、系统监控等功能。 什么是文档和词条? 每一条数据就是一个文档对文档中的内容进行分词,得到的词语就是词条 什么是正向…...
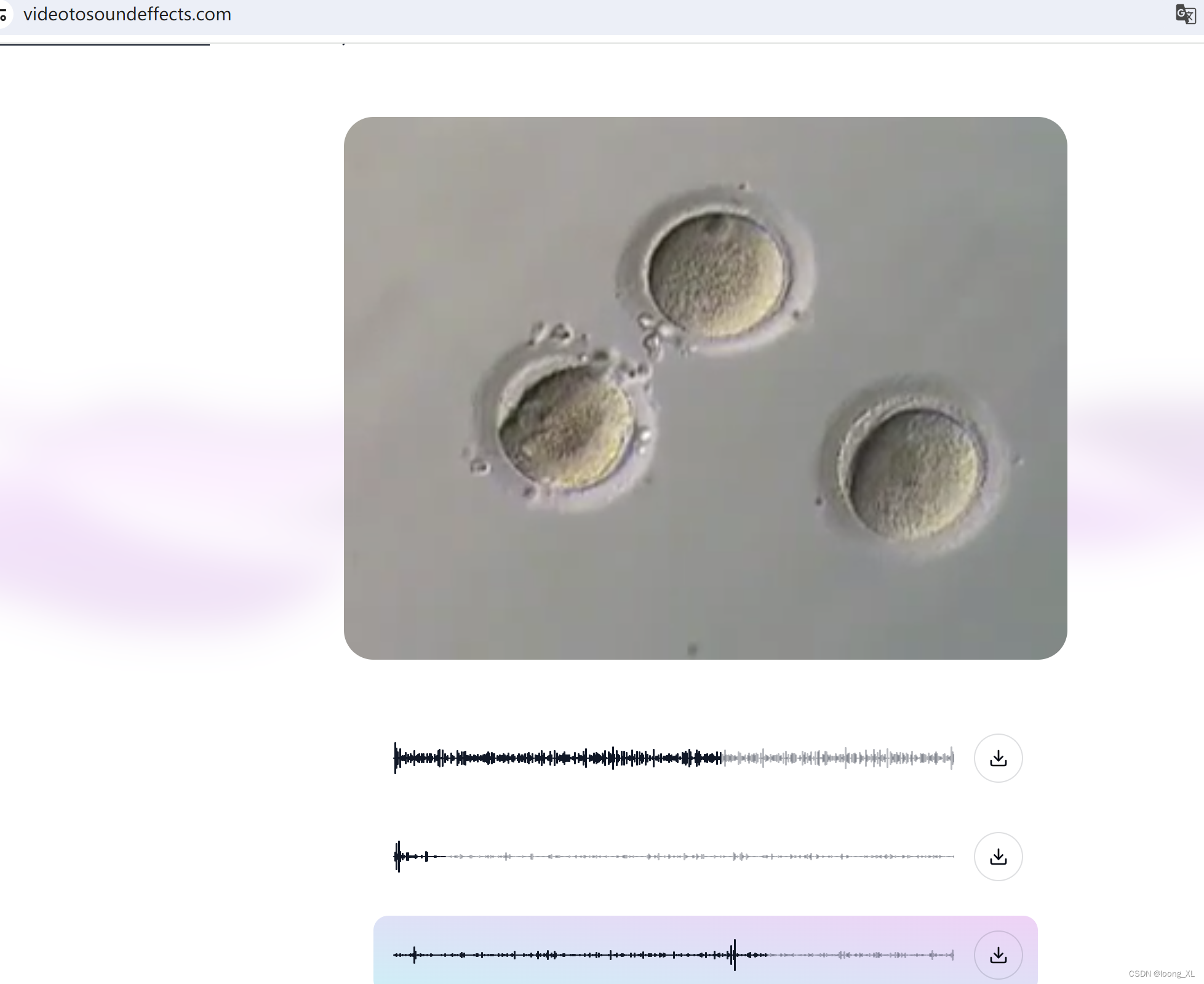
AI在线免费视频工具2:视频配声音
1、视频配声音 https://deepmind.google/discover/blog/generating-audio-for-video/ https://www.videotosoundeffects.com/ (免费在线使用)...

Kafka 如何保证消息顺序及其实现示例
Kafka 如何保证消息顺序及其实现示例 Kafka 保证消息顺序的机制主要依赖于分区(Partition)的概念。在 Kafka 中,消息的顺序保证是以分区为单位的。下面是 Kafka 如何保证消息顺序的详细解释: ⭕分区内消息顺序 顺序写入&#…...
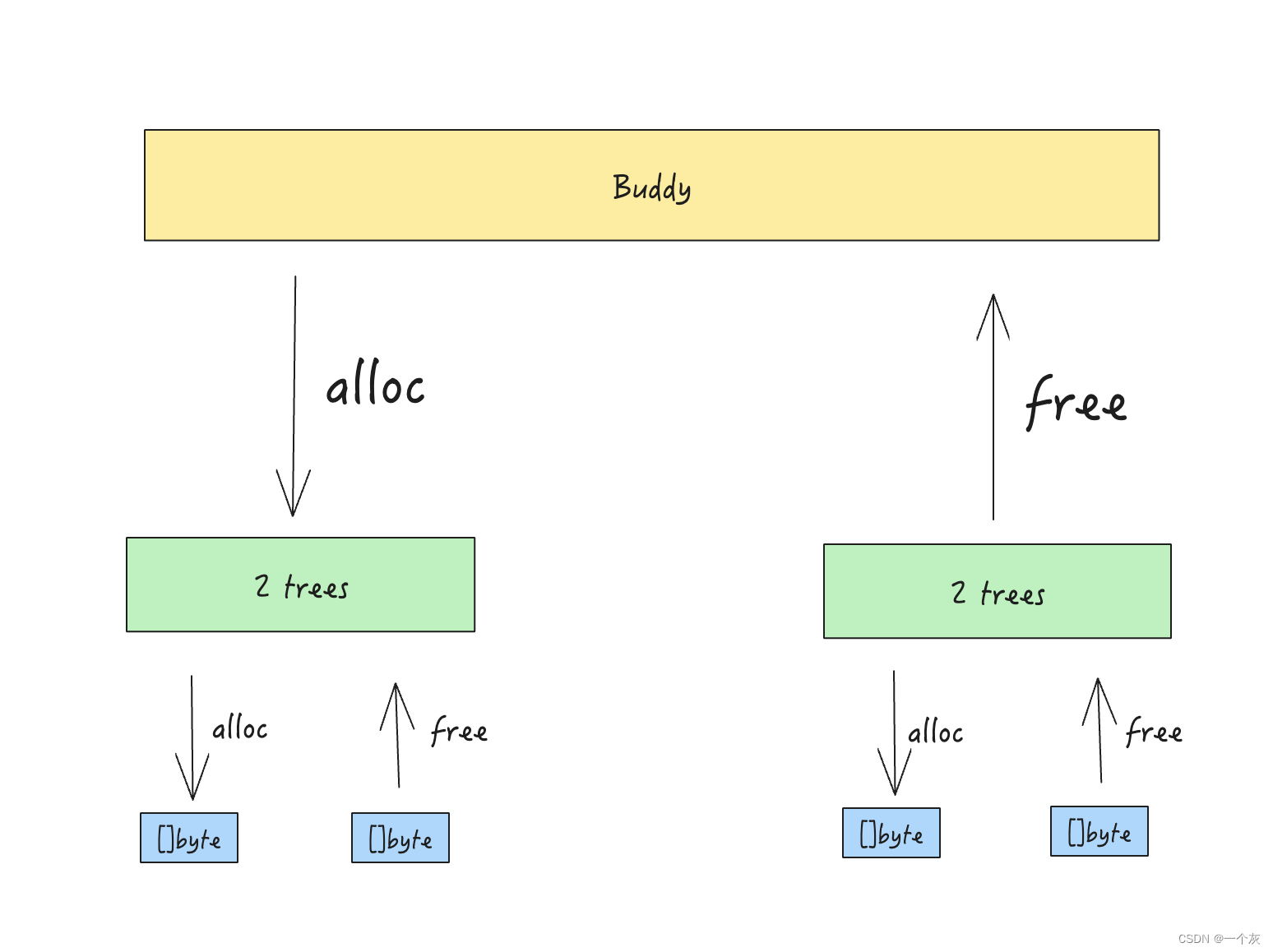
内存分配器性能优化
背景 在之前我们提到采用自定义的内存分配器来解决防止频繁 make 导致的 gc 问题。gc 问题本质上是 CPU 消耗,而内存分配器本身如果产生了大量的 CPU 消耗那就得不偿失。经过测试初代内存分配器实现过于简单,产生了很多 CPU 消耗,因此必须优…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...