NLP - word2vec详解
Word2Vec是一种用于将词汇映射到高维向量空间的自然语言处理技术。由Google在2013年提出,它利用浅层神经网络模型来学习词汇的分布式表示。Word2Vec有两种主要模型:CBOW(Continuous Bag of Words)和Skip-gram。
1. 模型介绍
Continuous Bag of Words (CBOW)
CBOW模型的目标是通过上下文预测中心词。给定一个上下文窗口中的多个词,CBOW模型尝试预测中心词。这种方法适用于大数据集,因为它更容易并行化。
例如,给定一个句子 “The quick brown fox jumps over the lazy dog”,假设我们选取 “jumps” 作为中心词,那么上下文词可以是 [“The”, “quick”, “brown”, “fox”, “over”, “the”, “lazy”, “dog”]。CBOW模型尝试通过这些上下文词来预测 “jumps”。
Skip-gram
Skip-gram模型的目标是通过中心词预测上下文词。与CBOW相反,Skip-gram模型给定一个中心词,尝试预测它的上下文词。Skip-gram模型在小数据集上表现更好,尤其适用于罕见词汇的表示学习。
例如,给定中心词 “jumps”,Skip-gram模型尝试预测上下文词 [“The”, “quick”, “brown”, “fox”, “over”, “the”, “lazy”, “dog”]。
2. CBOW模型详解
为了详细演示Continuous Bag of Words (CBOW)模型的整个过程,下面将分步骤介绍模型训练的主要流程,并包含每一步的公式和向量的计算过程。我们将用一个简化的示例来说明。
示例
假设我们有一个小语料库:
"The quick brown fox jumps over the lazy dog"
我们将使用一个窗口大小为2的CBOW模型来预测中心词。假设我们选择中心词 “jumps”,它的上下文词是 [“quick”, “brown”, “fox”, “over”]。
步骤1:预处理数据
将句子分词:
["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"]
构建词汇表并为每个词汇分配唯一的ID:
{"the": 0, "quick": 1, "brown": 2, "fox": 3, "jumps": 4, "over": 5, "lazy": 6, "dog": 7}
步骤2:构建训练样本
对于中心词 “jumps”,上下文词是 [“quick”, “brown”, “fox”, “over”]。我们用这些上下文词来预测中心词 “jumps”。
步骤3:定义模型
CBOW模型使用一个浅层神经网络,包含输入层、隐藏层和输出层。
- 输入层:每个上下文词用one-hot向量表示。例如,“quick” 的 one-hot 表示是 [0, 1, 0, 0, 0, 0, 0, 0]。
- 隐藏层:将输入层的向量通过权重矩阵 ( W ) 转换到隐藏层,得到词向量。
- 输出层:将隐藏层的向量通过另一个权重矩阵 ( W’ ) 转换到输出层,计算预测概率。
输入向量
上下文词的one-hot表示如下:
- “quick”:[0, 1, 0, 0, 0, 0, 0, 0]
- “brown”:[0, 0, 1, 0, 0, 0, 0, 0]
- “fox”:[0, 0, 0, 1, 0, 0, 0, 0]
- “over”:[0, 0, 0, 0, 0, 1, 0, 0]
权重矩阵
假设隐藏层维度为3,初始化权重矩阵 ( W ) 和 ( W’ ):
- ( W ) 是 ( 8 \times 3 ) 的矩阵(8是词汇表的大小,3是隐藏层的维度)
- ( W’ ) 是 ( 3 \times 8 ) 的矩阵
初始化权重矩阵(随机初始化):
W = [[0.1, 0.2, 0.3],[0.4, 0.5, 0.6],[0.7, 0.8, 0.9],[1.0, 1.1, 1.2],[1.3, 1.4, 1.5],[1.6, 1.7, 1.8],[1.9, 2.0, 2.1],[2.2, 2.3, 2.4]]W' = [[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],[0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6],[1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4]]
步骤4:前向传播
1. 隐藏层计算
计算每个上下文词的隐藏层表示:
- “quick”:[0, 1, 0, 0, 0, 0, 0, 0]
- “brown”:[0, 0, 1, 0, 0, 0, 0, 0]
- “fox”:[0, 0, 0, 1, 0, 0, 0, 0]
- “over”:[0, 0, 0, 0, 0, 1, 0, 0]
根据之前初始化的权重矩阵 ( W ):
W = [[0.1, 0.2, 0.3],[0.4, 0.5, 0.6],[0.7, 0.8, 0.9],[1.0, 1.1, 1.2],[1.3, 1.4, 1.5],[1.6, 1.7, 1.8],[1.9, 2.0, 2.1],[2.2, 2.3, 2.4]]
计算:
x_quick = [0, 1, 0, 0, 0, 0, 0, 0]
W^T * x_quick = [0.4, 0.5, 0.6]x_brown = [0, 0, 1, 0, 0, 0, 0, 0]
W^T * x_brown = [0.7, 0.8, 0.9]x_fox = [0, 0, 0, 1, 0, 0, 0, 0]
W^T * x_fox = [1.0, 1.1, 1.2]x_over = [0, 0, 0, 0, 0, 1, 0, 0]
W^T * x_over = [1.6, 1.7, 1.8]h = ([0.4, 0.5, 0.6] + [0.7, 0.8, 0.9] + [1.0, 1.1, 1.2] + [1.6, 1.7, 1.8]) / 4
h = [3.7, 4.1, 4.5] / 4
h = [0.925, 1.025, 1.125]
2. 输出层计算
根据之前初始化的权重矩阵 ( W’ ):
W' = [[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],[0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6],[1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4]]
计算:
u = W' * h
u = [[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],[0.9, 1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6],[1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4]] * [0.925, 1.025, 1.125]u_0 = 0.1*0.925 + 0.2*1.025 + 0.3*1.125= 0.0925 + 0.205 + 0.3375= 0.635u_1 = 0.2*0.925 + 0.3*1.025 + 0.4*1.125= 0.185 + 0.3075 + 0.45= 0.9425u_2 = 0.3*0.925 + 0.4*1.025 + 0.5*1.125= 0.2775 + 0.41 + 0.5625= 1.25u_3 = 0.4*0.925 + 0.5*1.025 + 0.6*1.125= 0.37 + 0.5125 + 0.675= 1.5575u_4 = 0.5*0.925 + 0.6*1.025 + 0.7*1.125= 0.4625 + 0.615 + 0.7875= 1.865u_5 = 0.6*0.925 + 0.7*1.025 + 0.8*1.125= 0.555 + 0.7175 + 0.9= 2.1725u_6 = 0.7*0.925 + 0.8*1.025 + 0.9*1.125= 0.6475 + 0.82 + 1.0125= 2.48u_7 = 0.8*0.925 + 0.9*1.025 + 1.0*1.125= 0.74 + 0.9225 + 1.125= 2.7875u = [0.635, 0.9425, 1.25, 1.5575, 1.865, 2.1725, 2.48, 2.7875]
计算softmax概率:
y_hat = softmax(u)
softmax函数定义为:
softmax(z_i) = exp(z_i) / sum(exp(z_j))
计算每个值的指数:
exp(0.635) ≈ 1.887
exp(0.9425) ≈ 2.566
exp(1.25) ≈ 3.490
exp(1.5575) ≈ 4.745
exp(1.865) ≈ 6.457
exp(2.1725) ≈ 8.788
exp(2.48) ≈ 11.932
exp(2.7875) ≈ 16.235
计算softmax概率:
sum_exp = 1.887 + 2.566 + 3.490 + 4.745 + 6.457 + 8.788 + 11.932 + 16.235 = 56.1y_hat = [1.887/56.1, 2.566/56.1, 3.490/56.1, 4.745/56.1, 6.457/56.1, 8.788/56.1, 11.932/56.1, 16.235/56.1]≈ [0.0336, 0.0458, 0.0622, 0.0846, 0.1152, 0.1566, 0.2127, 0.2893]
步骤5:计算损失
使用交叉熵损失计算真实标签和预测标签之间的误差:
假设 “jumps” 的 one-hot 表示是 [0, 0, 0, 0, 1, 0, 0, 0],则损失函数计算为:
L = -log(y_hat[4])= -log(0.1152)≈ 2.160
步骤6:反向传播和更新权重
1. 计算梯度
对权重矩阵 ( W’ ) 计算梯度:
dL/du_i = y_hat[i] - y_i
其中 ( y_i ) 是真实的one-hot标签。例如,对于中心词 “jumps”,( y_i = 0 ) 对于 ( i ≠ 4 ),而 ( y_4 = 1 )。
dL/du = [0.0336, 0.0458, 0.0622, 0.0846, -0.8848, 0.1566, 0.2127, 0.2893]
计算 ( W’ ) 的梯度:
dL/dW' = h * (dL/du)
对
( W ) 计算梯度:
dL/dh = W'^T * (dL/du)
2. 更新权重
使用梯度下降法更新权重:
W' = W' - learning_rate * (dL/dW')
W = W - learning_rate * (dL/dh)
假设学习率 ( learning_rate = 0.01 ):
更新 ( W’ ):
dL/dW' = h * (dL/du)= [0.925, 1.025, 1.125] * [0.0336, 0.0458, 0.0622, 0.0846, -0.8848, 0.1566, 0.2127, 0.2893]dL/dW'_0 = [0.925, 1.025, 1.125] * 0.0336 = [0.0311, 0.0345, 0.0378]
...
dL/dW'_4 = [0.925, 1.025, 1.125] * -0.8848 = [-0.8185, -0.9074, -0.9960]W'_0 = W'_0 - learning_rate * dL/dW'_0= [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] - 0.01 * [0.0311, 0.0345, 0.0378, ...]W' 更新后的值将逐个元素计算。
更新 ( W ):
dL/dh = W'^T * (dL/du)= [[0.1, 0.9, 1.7], [0.2, 1.0, 1.8], ...] * [0.0336, 0.0458, 0.0622, 0.0846, -0.8848, 0.1566, 0.2127, 0.2893]dh = [0.1*0.0336 + 0.9*0.0458 + 1.7*0.0622 + 0.2*0.0846 + ... , 1.0*0.0336 + 1.8*0.0458 + ...]dL/dW = 输入层的平均值 * dL/dh
权重矩阵 ( W ) 和 ( W’ ) 会逐步更新,直到损失函数收敛。
步骤七:迭代
通过对整个语料库的多次迭代,模型会逐步优化权重矩阵,获得高质量的词向量表示。
3. 模型训练
训练Word2Vec模型涉及以下几个步骤:
- 预处理数据:对文本进行分词、去停用词、词干提取等预处理操作。
- 构建词汇表:将所有唯一词汇构建成一个词汇表,每个词汇分配一个唯一的ID。
- 建立训练样本:根据选择的模型(CBOW或Skip-gram),创建训练样本。对于CBOW模型,训练样本是上下文词和中心词的对;对于Skip-gram模型,训练样本是中心词和上下文词的对。
- 定义和训练模型:使用浅层神经网络模型(通常是一个隐藏层的前馈神经网络)来学习词汇的向量表示。通过最小化预测误差(如交叉熵损失),模型调整权重以提高预测准确性。
- 生成词向量:一旦模型训练完成,词汇的向量表示可以从模型的权重中提取出来。这些向量表示可以用于各种NLP任务,如词汇相似度计算、文本分类、聚类等。
3. 应用和优势
Word2Vec模型学习到的词向量具有以下几个优点:
- 捕捉词汇语义:词向量可以捕捉到词汇的语义相似性。例如,“king” - “man” + “woman” ≈ “queen”。
- 高效训练:相比于传统的统计模型(如共现矩阵、LSA),Word2Vec模型训练效率更高,可以处理大规模语料。
- 易于扩展:词向量可以作为其他NLP模型(如RNN、LSTM、Transformer等)的输入,提升模型性能。
4. 实践示例
以下是使用Gensim库训练Word2Vec模型的Python示例代码:
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize# 示例文本数据
sentences = ["The quick brown fox jumps over the lazy dog","I love natural language processing","Word2Vec is a great tool for NLP"
]# 分词
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]# 训练Word2Vec模型
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, workers=4)# 获取词向量
word_vector = model.wv['word2vec']# 查看相似词
similar_words = model.wv.most_similar('word2vec', topn=5)
print(similar_words)
5. 总结
Word2Vec的优点
| 优点 | 描述 |
|---|---|
| 高效性 | 使用浅层神经网络进行训练,计算效率高,能够在大规模语料库上快速训练 |
| 捕捉语义信息 | 有效捕捉词汇的语义相似性,例如“king - man + woman ≈ queen” |
| 低维表示 | 相比词袋模型和TF-IDF,词向量维度较低,减少计算复杂度和存储需求 |
| 广泛适用 | 生成的词向量可用于多种NLP任务,如文本分类、聚类、信息检索和机器翻译 |
Word2Vec的缺点
| 缺点 | 描述 |
|---|---|
| 对词序敏感 | 不考虑词的顺序,可能导致在某些任务中丢失重要的顺序信息 |
| 静态词向量 | 同一个词在不同的上下文中具有相同的向量表示,无法捕捉词汇的多义性 |
| 数据依赖 | 模型性能高度依赖于训练语料的质量和规模,若训练数据不足或质量不高,词向量质量可能会受到影响 |
Word2Vec的特点
| 特点 | 描述 |
|---|---|
| 分布式表示 | 每个词汇用一个固定长度的向量表示,向量的每个维度表示某种语义特征 |
| 浅层神经网络 | 使用一个隐藏层的前馈神经网络训练模型,包含CBOW和Skip-gram两种方法 |
| 基于上下文 | 通过上下文词预测中心词(CBOW)或通过中心词预测上下文词(Skip-gram) |
Word2Vec的应用场景
| 应用场景 | 描述 |
|---|---|
| 文本分类 | 使用词向量作为特征,提高文本分类模型的性能 |
| 信息检索 | 通过词向量计算词汇相似度,改进信息检索系统效果 |
| 聚类分析 | 使用词向量作为特征,更好地发现文本的主题和结构 |
| 机器翻译 | 词向量帮助捕捉源语言和目标语言之间的语义关系 |
| 情感分析 | 改进情感分析模型的效果,准确识别文本中的情感倾向 |
Word2Vec的发展趋势
| 发展趋势 | 描述 |
|---|---|
| 动态词向量 | ELMo和BERT等模型能够根据上下文动态生成词向量,解决词汇多义性问题 |
| 预训练模型 | 基于Transformer的预训练模型(如GPT和BERT)在各种NLP任务中取得显著成果 |
| 多模态表示 | 词向量在多模态任务(如图像、文本、音频的联合表示)中发挥重要作用 |
| 更高效的训练算法 | 新的训练算法和优化技术提高词向量训练的效率和效果,如负采样和分层Softmax |
| 应用扩展 | 词向量技术在推荐系统、知识图谱、对话系统等领域展现出潜力 |
更多问题咨询
Cos机器人
相关文章:

NLP - word2vec详解
Word2Vec是一种用于将词汇映射到高维向量空间的自然语言处理技术。由Google在2013年提出,它利用浅层神经网络模型来学习词汇的分布式表示。Word2Vec有两种主要模型:CBOW(Continuous Bag of Words)和Skip-gram。 1. 模型介绍 Con…...

AI办公自动化:用通义千问批量翻译长篇英语TXT文档
在deepseek中输入提示词: 你是一个Python编程专家,现在要完成一个编写基于qwen-turbo模型API和dashscope库的程序脚本,具体步骤如下: 打开文件夹:F:\AI自媒体内容\待翻译; 获取里面所有TXT文档ÿ…...

一键解压,无限可能——BetterZip,您的Mac必备神器!
BetterZip for Mac 是一款高效、智能且安全的解压缩软件,专为Mac用户设计。它提供了直观易用的界面,使用户能够轻松应对各种压缩和解压缩需求。 这款软件不仅支持多种压缩格式,如ZIP、RAR、7Z等,还具备快速解压和压缩文件的能力。…...

【数学】什么是最大似然估计?如何求解最大似然估计
背景 最大似然估计(Maximum Likelihood Estimation, MLE)是一种估计统计模型参数的方法。它在众多统计学领域中被广泛使用,比如回归分析、时间序列分析、机器学习和经济学。其核心思想是:给定一个观测数据集,找到一组…...

跟张良均老师学大数据人工智能|企业项目试岗实训开营
我国高校毕业生数量连年快速增长,从2021年的909万人到2022年的1076万人,再到2023年的1158万人,预计到2024年将达到1187万人,2024年高校毕业生数量再创新高。 当年高校毕业生人数不等于进入劳动力市场的高校毕业生人数&#x…...

Pentest Muse:一款专为网络安全人员设计的AI助手
关于Pentest Muse Pentest Muse是一款专为网络安全研究人员和渗透测试人员设计和开发的人工智能AI助手,该工具可以帮助渗透测试人员进行头脑风暴、编写Payload、分析代码或执行网络侦查任务。除此之外,Pentest Muse甚至还能够执行命令行代码并以迭代方式…...
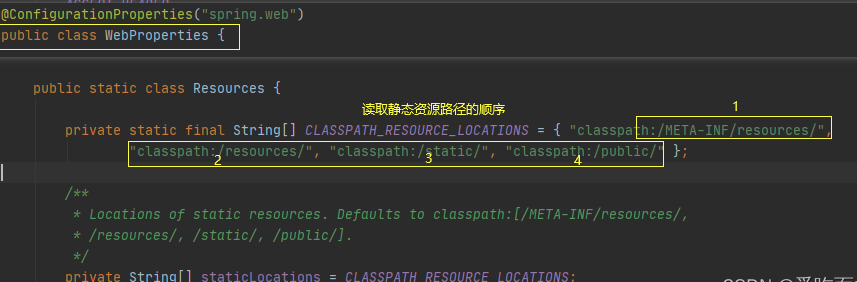
10 SpringBoot 静态资源访问
我们在开发Web项目的时候,往往会有很多静态资源,如html、图片、css等。那如何向前端返回静态资源呢? 以前做过web开发的同学应该知道,我们以前创建的web工程下面会有一个webapp的目录,我们只要把静态资源放在该目录下…...
Unity 之通过自定义协议从浏览器启动本地应用程序
内容将会持续更新,有错误的地方欢迎指正,谢谢! Unity 之通过自定义协议从浏览器启动本地应用程序 TechX 坚持将创新的科技带给世界! 拥有更好的学习体验 —— 不断努力,不断进步,不断探索 TechX —— 心探索、心进…...
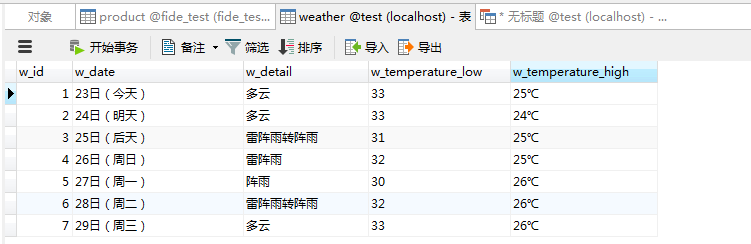
Python抓取天气信息
Python的详细学习还是需要些时间的。如果有其他语言经验的,可以暂时跟着我来写一个简单的例子。 2024年最新python教程全套,学完即可进大厂!(附全套视频 下载) (qq.com) 我们计划抓取的数据:杭州的天气信息…...
【超越拟合:深度学习中的过拟合与欠拟合应对策略】
如何处理过拟合 由于过拟合的主要问题是你的模型与训练数据拟合得太好,因此你需要使用技术来“控制它”。防止过拟合的常用技术称为正则化。我喜欢将其视为“使我们的模型更加规则”,例如能够拟合更多类型的数据。 让我们讨论一些防止过拟合的方法。 获…...

【Orange Pi 5与Linux内核编程】-理解Linux内核中的container_of宏
理解Linux内核中的container_of宏 文章目录 理解Linux内核中的container_of宏1、了解C语言中的struct内存表示2、Linux内核的container_of宏实现理解3、Linux内核的container_of使用 Linux 内核包含一个名为 container_of 的非常有用的宏。本文介绍了解 Linux 内核中的 contain…...

003.Linux SSH协议工具
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈 入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈 虚 拟 环 境 搭 建 :👉&…...

web前端组织分析:深入剖析其结构、功能与未来趋势
web前端组织分析:深入剖析其结构、功能与未来趋势 在数字化浪潮的推动下,Web前端组织作为连接用户与数字世界的桥梁,其重要性日益凸显。本文将从四个方面、五个方面、六个方面和七个方面对Web前端组织进行深入分析,揭示其结构特点…...
GitCode热门开源项目推荐:Spider网络爬虫框架
在数字化高速发展时代,数据已成为企业决策和个人研究的重要资源。网络爬虫作为一种强大的数据采集工具受到了广泛的关注和应用。在GitCode这一优秀的开源平台上,Spider网络爬虫框架凭借其简洁、高效和易用性,成为了众多开发者的首选。 一、系…...

实现一个二叉树的前序遍历、中序遍历和后序遍历方法。
package test3;public class Test_A27 {// 前序遍历(根-左-右)public void preOrderTraversal(TreeNode root){if(rootnull){return;}System.out.println(root.val"");preOrderTraversal(root.left);preOrderTraversal(root.right);}// 中序遍…...
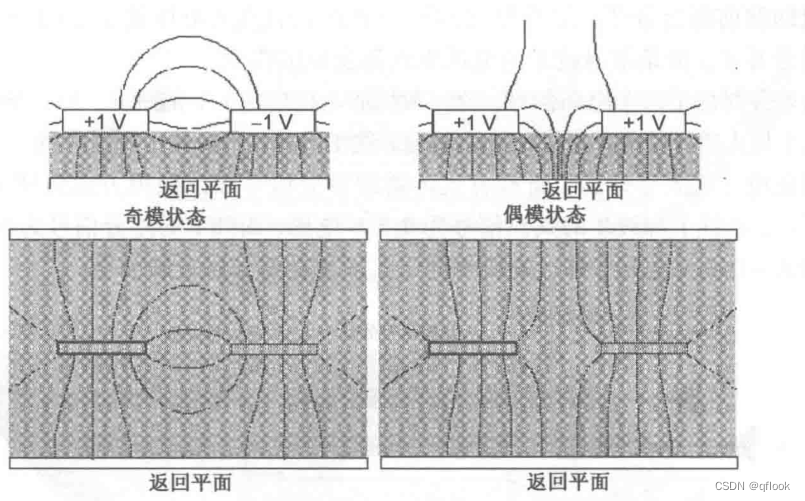
串扰(二)
三、感性串扰 首先看下串扰模型及电流方向: 由于电感是阻碍电流变化,受害线的电流方向和攻击线的电流方向相反。同时由于受害线阻抗均匀,故有Vb-Vf(感应电流属于电池内部电流)。 分析感性串扰大小仍然是按微分的方法…...
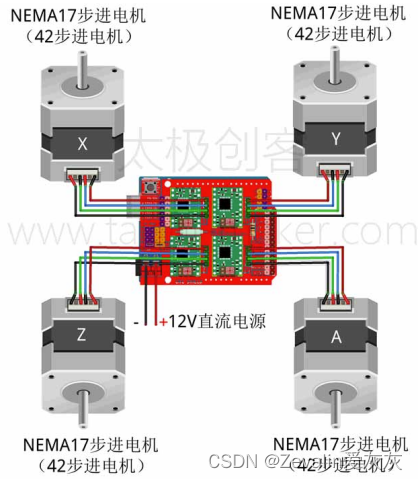
零基础入门学用Arduino 第四部分(三)
重要的内容写在前面: 该系列是以up主太极创客的零基础入门学用Arduino教程为基础制作的学习笔记。个人把这个教程学完之后,整体感觉是很好的,如果有条件的可以先学习一些相关课程,学起来会更加轻松,相关课程有数字电路…...

Mp3文件结构全解析(一)
Mp3文件结构全解析(一) MP3 文件是由帧(frame)构成的,帧是MP3 文件最小的组成单位。MP3的全称应为MPEG1 Layer-3 音频 文件,MPEG(Moving Picture Experts Group) 在汉语中译为活动图像专家组,特指活动影音压缩标准,MPEG 音频文件…...

ES 8.14 Java 代码调用,增加knnSearch 和 混合检索 mixSearch
1、pom依赖 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>8.14.0</version></dependency><dependency><groupId>co.elastic.clients<…...

被腰斩的颍川郡守赵广汉
在颍川,他发明了举报箱,铁腕扫黑除恶。因为曾经在郡府所在地阳翟(禹州)当过县令,熟悉颍川社情民意,所以,任职郡守后雷厉风行,才不到一年,不但制服了骄横的豪门大族&#…...

Redis 集群从裸奔到全副武装:搭建、可视化、监控、告警、看板一条龙
你的 Redis 集群还在"裸奔"吗?跑着跑着挂了不知道,内存爆了没人管,慢查询堆成山还蒙在鼓里。网上教程要么只讲搭建,要么只讲监控,想找一篇从头到尾串起来的——没有。所以我写了这篇,从 搭建集群…...

基于微信小程序的移动医院挂号预约系统
目录需求分析与功能设计数据库设计接口开发小程序页面开发测试与部署注意事项项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与功能设计 核心功能模块: 用户端:挂号预…...

AI时代新赛道:一文看懂GEO优化服务商
因生成式AI呈爆发式增长态势,GPT、、文心一言等AI工具成了用户获取信息的主要入口,这一变革催生出新的数字营销领域——GEO( ,生成引擎优化),此 GEO与传统SEO以提升网页在搜索引擎的排名目的不一样…...

AI编程助手Claude Code、Codex、OpenCode一站式Docker环境
AI编程助手Claude Code、Codex、OpenCode一站式Docker环境 一、为什么要搭建这样一个环境?1.1 背景与动机1.2 你能得到什么 二、相关截图二、整体架构与核心概念三、准备工作(是什么 & 为什么)3.1 基础环境3.2 可选:Ollama服务…...

2026 AWE:具身智能机器人开启家庭服务新时代
追觅“轮椅机器人”:补齐家庭清洁与出行短板在 2026 年 AWE 展会上,追觅包下七千平方米的 E7 馆展示众多新品。其“轮椅机器人”引人注目,它依靠四个轮子能稳定快捷地在卧室和阳台间移动,老人还能当轮椅使用。此外,它配…...

【69页PPT】全生命周期数字健康智慧医共体解决方案:“1”朵健康云、“3”大核心应用、“N”类服务应用迭代、区域医院智慧管理平台...
本方案以“健康云”和大数据中心为核心,构建市县级智慧医共体。通过开放平台整合医疗资源,实现数据互联互通与业务协同。方案提供从临床辅助、运营决策到居民服务的全周期应用,旨在打破信息孤岛,提升区域医疗服务效率与管理水平&a…...

COMSOL 助力燃料电池冷启动仿真:探索低温下的运行奥秘
COMSOL 燃料电池,冷启动仿真 低温质子交换膜燃料电池冷启动仿真模型,cold start,可仿真包括冰的形成过程,温度分布,电流分布,物质浓度分布,速度压力分布以及膜中水分布,可提供相关方…...

四旋翼无人机空中悬停研究
四旋翼无人机空中悬停是无人机应用中的核心功能之一,其核心作用在于通过精确控制四个旋翼的转速差异,实现无人机在三维空间中的稳定静止状态。这一功能不仅为航拍、测绘、环境监测等任务提供了稳定的操作平台,更在复杂环境如城市峡谷、室内空…...

PyTorch通用开发环境快速上手:预装依赖+ModuleNotFoundError解决方案
PyTorch通用开发环境快速上手:预装依赖ModuleNotFoundError解决方案 1. 引言 如果你刚接触深度学习,或者每次开始新项目都要花半天时间配环境,那这篇文章就是为你准备的。 想象一下这个场景:你拿到一个新项目,满心欢…...

STM32简易示波器设计:ADC采样与TFT显示全链路实现
1. 项目概述本项目是一款基于STM32微控制器的便携式简易示波器,面向嵌入式系统学习、基础信号观测及教学实验场景设计。其核心目标是在资源受限的MCU平台上实现双通道模拟信号采集、实时波形显示与基础触发功能,兼顾硬件简洁性、可复现性与工程实用性。不…...