Kafka 之 KRaft —— 配置、存储工具、部署注意事项、缺失的特性
目录
一. 前言
二. 配置(Configuration)
2.1. 处理者角色(Process Roles)
2.2. 控制器(controller)
2.3. 存储工具(Storage Tool)
2.4. 调试(Debugging)
2.4.1. 元数据选举工具(Metadata Quorum Tool)
2.4.2. 转储日志工具(Dump Log Tool)
2.4.3. 元数据指令(Metadata Shell)
2.5. 部署注意事项(Deploying Considerations)
2.6. 缺失的特性(Missing Features)
一. 前言
目前,Kafka 在使用的过程当中,会出现一些问题。由于重度依赖 Zookeeper 集群,当Zookeeper 集群性能发生抖动时,Kafka 的性能也会收到很大的影响。因此,在 Kafka 发展的过程当中,为了解决这个问题,提供 KRaft 模式,来取消 Kafka 对 Zookeeper 的依赖。
二. 配置(Configuration)
2.1. 处理者角色(Process Roles)
原文引用:In KRaft mode each Kafka server can be configured as a controller, a broker, or both using the process.roles property. This property can have the following values:
- If process.roles is set to broker, the server acts as a broker.
- If process.roles is set to controller, the server acts as a controller.
- If process.roles is set to broker,controller, the server acts as both a broker and a controller.
- If process.roles is not set at all, it is assumed to be in ZooKeeper mode.
在 KRaft 模式中,每个 Kafka 服务器都可以使用 process.roles 属性配置为 controller、broker 或这两个。此属性可以具有以下值:
- 如果 process.roles 设置为 broker,则服务器将充当 Broker。
- 如果 process.roles 设置为 controller,则服务器将充当 Controller。
- 如果 process.roles 设置为 broker,controller,则服务器同时充当 Broker 和 Controller。
- 如果根本没有设置 process.roles,则假定它处于 ZooKeeper 模式。
原文引用:Kafka servers that act as both brokers and controllers are referred to as "combined" servers. Combined servers are simpler to operate for small use cases like a development environment. The key disadvantage is that the controller will be less isolated from the rest of the system. For example, it is not possible to roll or scale the controllers separately from the brokers in combined mode. Combined mode is not recommended in critical deployment environments.
同时充当 Broker 和 Controller 的 Kafka 服务器被称为“组合”服务器。对于像开发环境这样的小用例,组合服务器更易于操作。关键的缺点是控制器与系统的其余部分的隔离度较低。例如,在组合模式下,不可能将 Controller 与 Broker 程序分开滚动或缩放。不建议在关键部署环境中使用组合模式。
2.2. 控制器(controller)
原文引用:In KRaft mode, specific Kafka servers are selected to be controllers (unlike the ZooKeeper-based mode, where any server can become the Controller). The servers selected to be controllers will participate in the metadata quorum. Each controller is either an active or a hot standby for the current active controller.
在 KRaft 模式中,特定的 Kafka 服务器被选择为控制器(与基于 ZooKeeper 的模式不同,在该模式中,任何服务器都可以成为控制器)。被选为控制器的服务器将参与元数据选举。每个控制器都是当前活动控制器的活动控制器或热备用控制器。
原文引用:A Kafka admin will typically select 3 or 5 servers for this role, depending on factors like cost and the number of concurrent failures your system should withstand without availability impact. A majority of the controllers must be alive in order to maintain availability. With 3 controllers, the cluster can tolerate 1 controller failure; with 5 controllers, the cluster can tolerate 2 controller failures.
Kafka 管理员通常会为这个角色选择3到5台服务器,这取决于成本和系统在不影响可用性的情况下应该承受的并发故障数量等因素。为了保持可用性,大多数控制器必须是活动的。有3个控制器,集群可以容忍1个控制器故障;使用5个控制器,集群可以容忍2个控制器故障。
原文引用:All of the servers in a Kafka cluster discover the quorum voters using the controller.quorum.voters property. This identifies the quorum controller servers that should be used. All the controllers must be enumerated. Each controller is identified with their id, host and port information. For example:
Kafka 集群中的所有服务器都使用 controller.quorum.voters 属性来发现 quorum 投票者。这标识了应使用的选举控制器服务器。必须列举所有控制器。每个控制器都通过其 id、host 和 port 信息进行标识。例如:
controller.quorum.voters=id1@host1:port1,id2@host2:port2,id3@host3:port3原文引用:If a Kafka cluster has 3 controllers named controller1, controller2 and controller3, then controller1 may have the following configuration:
如果一个 Kafka 集群有三个控制器,分别命名为 controller1、controller2 和 controller3,那么controller1 可能具有以下配置:
process.roles=controller
node.id=1
listeners=CONTROLLER://controller1.example.com:9093
controller.quorum.voters=1@controller1.example.com:9093,2@controller2.example.com:9093,3@controller3.example.com:9093原文引用:Every broker and controller must set the controller.quorum.voters property. The node ID supplied in the controller.quorum.voters property must match the corresponding id on the controller servers. For example, on controller1, node.id must be set to 1, and so forth. Each node ID must be unique across all the servers in a particular cluster. No two servers can have the same node ID regardless of their process.roles values.
每个 Broker 和 Controller 都必须设置 controller.quorum.voters 属性。controller.quorum.voters属性中提供的节点 ID 必须与 Controller 服务器上的相应 ID 匹配。例如,在 controller1 上,node.id 必须设置为1,依此类推。在特定集群中的所有服务器中,每个节点 ID 都必须是唯一的。无论两台服务器的 process.role 值如何,都不能具有相同的节点 ID。
2.3. 存储工具(Storage Tool)
原文引用:The kafka-storage.sh random-uuid command can be used to generate a cluster ID for your new cluster. This cluster ID must be used when formatting each server in the cluster with the kafka-storage.sh format command.
kafka-storage.sh random uuid 命令可用于为新集群生成集群 ID。使用 kafka-storage.sh format命令格式化群集中的每个服务器时,必须使用此群集 ID。
原文引用:This is different from how Kafka has operated in the past. Previously, Kafka would format blank storage directories automatically, and also generate a new cluster ID automatically. One reason for the change is that auto-formatting can sometimes obscure an error condition. This is particularly important for the metadata log maintained by the controller and broker servers. If a majority of the controllers were able to start with an empty log directory, a leader might be able to be elected with missing committed data.
这与 Kafka 过去的运作方式不同。以前,Kafka 会自动格式化空白存储目录,并自动生成新的集群 ID。修改的一个原因是,自动格式化有时会模糊错误条件。这对于由 Controller 和 Broker 服务器维护的元数据日志来说尤其重要。如果大多数 Controller 能够从一个空的日志目录开始,则可能能够在缺少提交数据的情况下选出 Leader。
2.4. 调试(Debugging)
2.4.1. 元数据选举工具(Metadata Quorum Tool)
原文引用:The kafka-metadata-quorum tool can be used to describe the runtime state of the cluster metadata partition. For example, the following command displays a summary of the metadata quorum:
Kafka kafka-metadata-quorum(元数据选举工具)可用于描述集群元数据分区的运行时状态。例如,以下命令显示元数据选举的摘要:
> bin/kafka-metadata-quorum.sh --bootstrap-server broker_host:port describe --status
ClusterId: fMCL8kv1SWm87L_Md-I2hg
LeaderId: 3002
LeaderEpoch: 2
HighWatermark: 10
MaxFollowerLag: 0
MaxFollowerLagTimeMs: -1
CurrentVoters: [3000,3001,3002]
CurrentObservers: [0,1,2]2.4.2. 转储日志工具(Dump Log Tool)
原文引用:The kafka-dump-log tool can be used to debug the log segments and snapshots for the cluster metadata directory. The tool will scan the provided files and decode the metadata records. For example, this command decodes and prints the records in the first log segment:
Kafka kafka-dump-log(转储日志工具)可用于调试集群元数据目录的日志段和快照。该工具将扫描提供的文件并解码元数据记录。例如,此命令解码并打印第一个日志段中的记录:
> bin/kafka-dump-log.sh --cluster-metadata-decoder --files metadata_log_dir/__cluster_metadata-0/00000000000000000000.log原文引用:This command decodes and prints the records in the a cluster metadata snapshot:
此命令解码并打印集群元数据快照中的记录:
> bin/kafka-dump-log.sh --cluster-metadata-decoder --files metadata_log_dir/__cluster_metadata-0/00000000000000000100-0000000001.checkpoint2.4.3. 元数据指令(Metadata Shell)
原文引用:The kafka-metadata-shell tool can be used to interactively inspect the state of the cluster metadata partition:
Kafka kafka-metadata-shell(元数据外壳工具)可用于交互式检查集群元数据分区的状态:
> bin/kafka-metadata-shell.sh --snapshot metadata_log_dir/__cluster_metadata-0/00000000000000000000.log
>> ls /
brokers local metadataQuorum topicIds topics
>> ls /topics
foo
>> cat /topics/foo/0/data
{"partitionId" : 0,"topicId" : "5zoAlv-xEh9xRANKXt1Lbg","replicas" : [ 1 ],"isr" : [ 1 ],"removingReplicas" : null,"addingReplicas" : null,"leader" : 1,"leaderEpoch" : 0,"partitionEpoch" : 0
}
>> exit2.5. 部署注意事项(Deploying Considerations)
原文引用:
- Kafka server's process.role should be set to either broker or controller but not both. Combined mode can be used in development environments, but it should be avoided in critical deployment environments.
- For redundancy, a Kafka cluster should use 3 controllers. More than 3 controllers is not recommended in critical environments. In the rare case of a partial network failure it is possible for the cluster metadata quorum to become unavailable. This limitation will be addressed in a future release of Kafka.
- The Kafka controllers store all the metadata for the cluster in memory and on disk. We believe that for a typical Kafka cluster 5GB of main memory and 5GB of disk space on the metadata log director is sufficient.
- Kafka 服务器的 process.role 应该设置为 broker 或 controller,但不能同时设置。组合模式可以在开发环境中使用,但在关键部署环境中应避免使用。
- 对于冗余,一个 Kafka 集群应该使用3个 Controlloer。不建议在关键环境中使用3个以上的Controlloer。在极少数的部分网络故障情况下,群集元数据选举可能变得不可用。这一限制将在 Kafka 的未来版本中得到解决。
- Kafka Controller 将集群的所有元数据存储在内存和磁盘上。我们认为,对于典型的 Kafka 集群,元数据日志导向器上 5GB 的主内存和 5GB 的磁盘空间就足够了。
2.6. 缺失的特性(Missing Features)
原文引用:The following features are not fully implemented in KRaft mode:
- Supporting JBOD configurations with multiple storage directories
- Modifying certain dynamic configurations on the standalone KRaft controller
- Delegation tokens
以下功能未在 KRaft 模式中完全实现:
- 支持具有多个存储目录的 JBOD 配置。
- 修改独立 KRaft 控制器上的某些动态配置。
- 委派令牌。
相关文章:

Kafka 之 KRaft —— 配置、存储工具、部署注意事项、缺失的特性
目录 一. 前言 二. 配置(Configuration) 2.1. 处理者角色(Process Roles) 2.2. 控制器(controller) 2.3. 存储工具(Storage Tool) 2.4. 调试(Debugging)…...

专业和学校到底怎么选,兴趣和知名度到底哪个重要?
前言 2024高考已经落下帷幕,再过不久就到了激动人心的查分和填报志愿的时刻,在那天到来,小伙伴们就要根据自己的分数选取院校和专业,接下来我就以参加22年(破防年)河南高考的大二生来讲述一下我自己对于如何选取院校和专业的看法以…...

【MySQL】数据库
数据库概述 【MySQL】数据库概述-CSDN博客 数据库基本操作 【MySQL】数据库基本操作-CSDN博客 数据表基本操作 【MySQL】数据表基本操作-CSDN博客 约束 【MySQL】约束-CSDN博客 基本增删改查 【MySQL】基本增删改查-CSDN博客 多表操作 【MySQL】多表操作-CSDN博客 视图 …...

D111FCE01LC2NB70带流量调节派克比例阀
D111FCE01LC2NB70带流量调节派克比例阀 派克比例阀:由于采用(秉圣135陈工6653询3053)电液混合控制技术,响应速度更快、精度更高、控制更平稳。同时,由于采用高质量的材料制造,具有较高的承压能力和抗磨损性…...
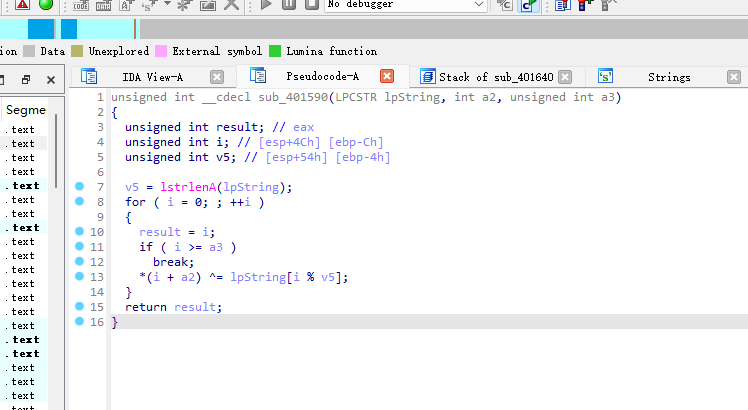
buuctf-findKey
exe文件 运行发现这个窗口,没有任何消息 32位 进入字符串就发现了flag{ 左边红色代表没有F5成功 我们再编译一下(选中红色的全部按p) LRESULT __stdcall sub_401640(HWND hWndParent, UINT Msg, WPARAM wParam, LPARAM lParam) {int v5; // eaxsize_t v6; // eaxDWORD v7; /…...

针对oracle系列数据库慢数据量大的问题
-- 确保索引存在 create index idx_risk_assessment_hazard on risk_assessment_hazard(data_time, perception_id); create index idx_risk_dispose_base_info on risk_dispose_base_info(perception_id); -- 使用并行查询和with子句进行优化 explain plan for with t2 as (se…...
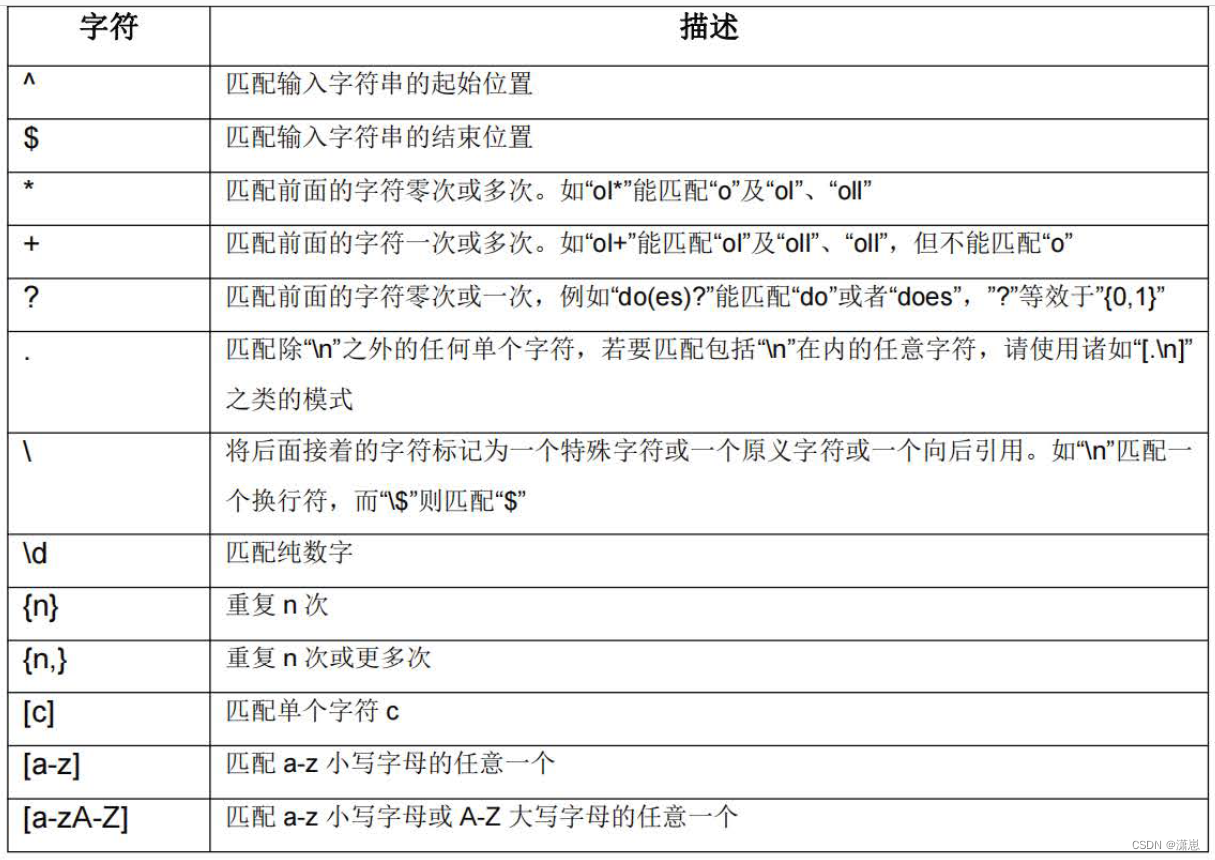
Nginx-Rewrite
1、Rewrite的定义 rewrite功能就是使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向。rewrite只能放在 server { }, location { }, if { }中,并且只能对域名后边的除去传递的参数外的字符串起作用。 例如location…...

2024 年 Python 基于 Kimi 智能助手 Moonshot Ai 模型搭建微信机器人(更新中)
注册 Kimi 开放平台 Kimi:https://www.moonshot.cn/ Kimi智能助手是北京月之暗面科技有限公司(Moonshot AI)于2023年10月9日推出的一款人工智能助手,主要为用户提供高效、便捷的信息服务。它具备多项强大功能,包括多…...
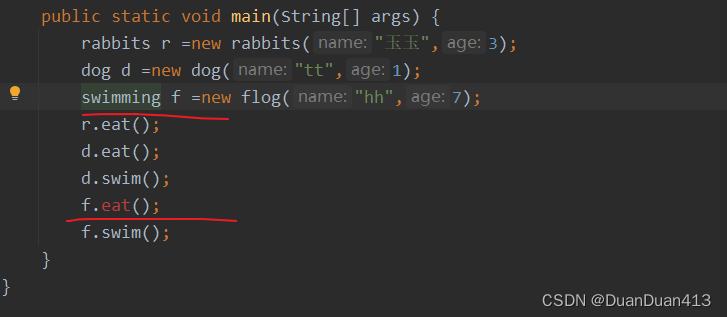
关于接口多态,何时使用接口名创建对象?何时使用子类创建对象?
接口创建对象只能创建他的实现类,所以会出现两种创建方式: 1、接口 对象名 new 类名 2、子类对象 对象名 new 类名 举个例子,swimming是一个接口,flog是他的一个实现类,重写了swimming的eat()方法 子类对象 对象名…...

短视频热恋进行时:成都柏煜文化传媒有限公司
短视频热恋进行时:情感与创意的碰撞与融合 在数字时代的浪潮中,短视频以其独特的魅力,成为了当代人表达情感、分享生活的新宠。它如同一个浓缩的时空胶囊,将那些瞬间的美好、感人的故事、创意的火花,封装在短短几十秒…...
springBoot多数据源使用、配置
又参加了一个新的项目,虽然是去年做的项目,拿来复用改造,但是也学到了很多。这个项目会用到其他项目的数据,如果调用他们的接口取数据,我还是觉得太麻烦了。打算直接配置多数据源。 然后去另一个数据库系统中取出数据…...
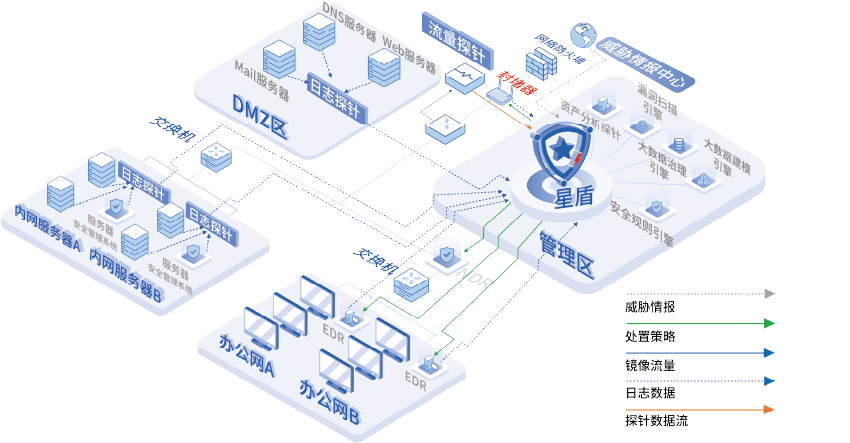
打破安全设备孤岛,多源威胁检测与响应(XDR)如何构建一体化安全防线
在数字化和信息化迅猛发展的当下,安全设备孤岛现象成为网络安全治理中的一大挑战。在多元化的市场环境中,不同厂商的安全设备因数据格式与系统兼容性的差异,导致信息流通受阻、共享困难,形成孤立的安全防线。 安全设备孤岛现象不仅…...
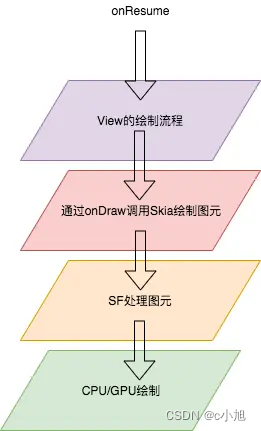
Android SurfaceFlinger——概述(一)
一、基础介绍 SurfaceFlinger 是 Android 系统中的一个关键组件,负责管理屏幕显示的合成和渲染。 服务角色:SurfaceFlinger 作为一个系统服务独立运行,它不依赖于任何应用程序进程,而是由系统启动并持续运行。窗口管理:…...
工业 web4.0,UI 风格令人赞叹
工业 web4.0,UI 风格令人赞叹...

HarmonyOS 角落里的知识 —— 状态管理
一、前言 在探索 HarmonyOS 的过程中,我们发现了许多有趣且实用的功能和特性。有些总是在不经意间或者触类旁通的找到。或者是某些开发痛点。其中,状态管理是ArkUI开发非常核心的一个东西,我们进行了大量的使用和测试遇到了许多奇奇怪怪的问…...

TDengine数据迁移
前言 taosdump 是一个支持从运行中的 TDengine 集群备份数据并将备份的数据恢复到相同或另一个运行中的 TDengine 集群中的工具应用程序。 taosdump 可以用数据库、超级表或普通表作为逻辑数据单元进行备份,也可以对数据库、超级 表和普通表中指定时间段内的数据记录…...

使用ZIP包安装MySQL及配置教程
在本教程中,我们将指导您完成使用ZIP包安装MySQL的过程,并对配置文件进行必要的修改,以及解决可能遇到的问题。本示例以MySQL 5.7.44为例,但步骤同样适用于其他版本如MySQL 8.3.0等。请根据实际需要选择适合的版本下载:…...

Java基础入门day64
day64 web项目 数据库设计 在小米商城主页,主要的内容是多种商品类型的展示,分别有手机,智能穿戴,笔记本平板,家电,生活电器,厨房电器,智能家具等大的七个分类,根据这个…...

高德地图轨迹回放/轨迹播放
前言 本篇文章主要介绍高德地图的轨迹回放或播放的实现过程,是基于vue2实现的功能,同时做一些改动也是能够适配vue3的。其中播放条是用的是element UI中的el-slider组件,包括使用到的图标也是element UI自带的。可以实现轨迹的播放、暂停、停…...

像素、像素密度、位图和矢量图
像素、像素密度、位图和矢量图 像素 -- 图像元素pt分辨率ppidpi 点阵图 - bitmap常见的类型 矢量图点阵图 vs 矢量图参考小结 像素、矢量图等概念在前端开发中经常遇到,这里做一个简单的梳理。 像素 – 图像元素 做前端开发的经常遇到它。像素是图像的最小单位&am…...

cp-ddd-framework架构演进:如何支撑业务系统从单体到微服务
cp-ddd-framework架构演进:如何支撑业务系统从单体到微服务 【免费下载链接】cp-ddd-framework 轻量级DDD正向/逆向业务建模框架,支撑复杂业务系统的架构演化! 项目地址: https://gitcode.com/gh_mirrors/cp/cp-ddd-framework 在当今快…...

终极指南:Emscripten原子操作调试与内存一致性模型全解析
终极指南:Emscripten原子操作调试与内存一致性模型全解析 【免费下载链接】emscripten 项目地址: https://gitcode.com/gh_mirrors/ems/emscripten Emscripten作为将C/C代码编译为WebAssembly的核心工具,其原子操作与内存一致性模型是多线程应用…...

终极mojs浏览器兼容性实战指南:从问题诊断到完美解决方案
终极mojs浏览器兼容性实战指南:从问题诊断到完美解决方案 【免费下载链接】mojs 项目地址: https://gitcode.com/gh_mirrors/moj/mojs mojs作为一款强大的动画库,能够帮助开发者轻松创建流畅精美的网页动画效果。然而,在实际开发过程…...

程序调试操作
文章目录一 什么是调试二 常见调试方式2.1 阅读代码与日志打印2.2 使用工具三 使用IDEA调试Java程序3.1 如何打断点3.2 如何启动调试3.3 调试界面3.4 逐过程Step over:快捷键F83.5 逐语句Step into: 快捷键F73.6 强制步入功能:AltShiftF73.7 跳出功能3.8 运行到光标所在位置3.9…...

Qwen3-Reranker-0.6B入门必看:与bge-reranker-base、cohere-rerank对比选型指南
Qwen3-Reranker-0.6B入门必看:与bge-reranker-base、cohere-rerank对比选型指南 1. 为什么需要重排序模型? 当你使用RAG(检索增强生成)系统时,通常会先用检索器找到一批相关文档,但这些文档的质量参差不齐…...
)
Vue项目实战:用AiLabel.js打造图片标注功能(附完整代码下载)
Vue项目实战:用AiLabel.js打造智能图片标注系统 在计算机视觉和机器学习项目的前期准备中,数据标注是构建高质量训练集的关键环节。作为前端开发者,我们经常需要在Web应用中实现图片标注功能,让用户可以直观地标记图像中的关键区域…...

ZYNQ7100板级原理图设计实战:从入门到精通
1. ZYNQ7100硬件设计入门指南 第一次接触ZYNQ7100这块开发板时,我和大多数硬件工程师一样有点懵——这玩意儿既有ARM处理器又有FPGA,原理图该怎么画?后来在几个实际项目中摸爬滚打,才发现掌握几个关键点就能轻松上手。XC7Z100-2FF…...

效率提升秘籍:用快马平台自动生成Touchgal复杂手势管理代码
作为一名经常和复杂交互打交道的开发者,我深知处理像“绘图面板同时支持绘画和缩放平移”这类需求有多头疼。事件冲突、状态管理、性能优化,每一个环节都可能成为“时间黑洞”。最近在尝试用Touchgal库结合InsCode(快马)平台来应对这类挑战,发…...

【cuda】deepep 学习 cudaHostGetDevicePointer cudaHostAllocMapped
https://blog.csdn.net/KIDGIN7439/article/details/146131893?spm1001.2014.3001.5502 notify_dispatch过程中会计算其他所有rank发送给当前rank多少token,写入到host的moe_recv_counter_mapped,还会计算其他所有rdma_rank发送给当前rank多少token&am…...

程序员通吃版:从 0 到 1 学 AI Agent!用 LangGraph 六步实现,新手也能上手的实操指南
如果说此前AutoGPT代表的早期自主Agent还停留在“宽泛探索”阶段,那么2025年无疑成为AI Agent真正扎根生产环境的关键元年。与过去追求“全场景覆盖”的通用型Agent不同,如今能够落地企业业务的生产级Agent,正朝着垂直化深耕、边界清晰化、管…...