无问芯穹Qllm-Eval:制作多模型、多参数、多维度的量化方案
前言
近年来,大语言模型(Large Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。大模型压缩,即将大模型“瘦身”后塞进资源受限的场景,以减少模型存储、访存和计算开销。在尽量不损失模型性能的前提下,提高大模型推理吞吐速度,使大模型在物联网边缘设备、嵌入式机器人、离线移动应用等边、端场景中保持优秀的推理性能和功耗表现。就在最近,来自清华大学电子工程系、无问芯穹和上海交通大学的研究团队展开了一次量化方案的“大摸底”,在《Evaluating Quantized Large Language Models 》(Qllm-Eval)这项工作中评估了不同模型、量化不同张量类型、使用不同量化方法、在不同任务上的性能,本篇工作已被ICML'24接收。Qllm-Eval列举出很多大模型落地环节应当关注的模型能力,对产业中的模型量化工作实践,比如如何选取量化方法、针对哪些层或组件进行优化等问题具有指导意义,下图是罗列的一些重要知识点。 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
训练后量化(Post-Training Quantization,PTQ)
大模型推理过程包括两个阶段:Prefill阶段和Decoding阶段:
- Prefill阶段的主要算子为矩阵-矩阵乘(GEMM),其推理速度受限于计算速度。
- Decoding阶段的主要算子为矩阵-向量乘(GEMV),其推理速度主要受限于访存速度。
- 当处理涉及长文本或大批量大小的任务时,KV Cache的存储开销会超过权重的存储开销。
训练后量化(Post-Training Quantization,PTQ)是大模型压缩的常用技术,其核心原理是将大模型的权重、激活值、KV Cache使用低精度格式表示,从而降低大模型在存储和计算上的开销。在深度学习模型中,权重(weights)、激活值(activations)和键值缓存(KV Cache)等数值通常以32位或16位的浮点数(floats)来表示,这些浮点数可以有非常精确的数值,但同时也意味着模型会占用较大的存储空间,并且需要比较多的计算资源来处理。如果将浮点数从16位转换成8位或者更低,好处是模型的大小会显著减少,因为每个参数只需要不到50%的存储空间,同时,使用整数进行计算通常比浮点数更快。
不同量化方式给大模型带来的影响
但量化压缩通常是有损的,不同量化方式的设计会对模型性能带来不同的影响。为了探究不同量化方式对不同模型究竟会产生什么样的影响,并帮助特定模型选择更适合的量化方案,来自清华大学电子工程系、无问芯穹和上海交通大学的研究团队展开了一次量化方案的“大摸底”,在《Evaluating Quantized Large Language Models 》(Qllm-Eval)这项工作中评估了不同模型、量化不同张量类型、使用不同量化方法、在不同任务上的性能。Qllm-Eval评测的量化张量类型包括权重(W)、权重-激活(WA)、KV Cache(KV),通过评估 PTQ 对 11 个系列模型(包括 OPT、LLaMA2、Falcon、Bloomz、Mistral、ChatGLM、Vicuna、LongChat、StableLM、Gemma 和 Mamba)的权重、激活和 KV 缓存的影响,对这些因素进行了全面评估,覆盖了从 125M 到 180B的参数范围。另外还评估了最先进的 (SOTA) 量化方法,以验证其适用性。同时在大量实验的基础上,系统总结了量化的效果,提出了应用量化技术的建议,并指出了大模型量化工作未来的发展方向。
大模型推理效率瓶颈分析
目前主流的大语言模型都是基于Transformer架构进行设计。通常来说,一个完整的模型架构由多个相同结构的Transformer块组成,每个Transformer块则包含多头自注意力(Multi-Head Self-Attention, MHSA)模块、前馈神经网络(Feed Forward Network, FFN)和层归一化(Layer Normalization,LN)操作。大语言模型通常自回归(Auto-regressive)的方式生成输出序列,即模型逐个词块生成,且生成每个词块时需要将前序的所有词块(包括输入词块和前面已生成的词块)全部作为模型的输入。因此,随着输出序列的增长,推理过程的开销显著增大。为了解决该问题,KV缓存技术被提出,该技术通过存储和复用前序词块在计算注意力机制时产生的Key和Value向量,减少大量计算上的冗余,用一定的存储开销换取了显著的加速效果。基于KV缓存技术,通常可以将大语言模型的推理过程划分为两个阶段(分别如下左图和右图所示): 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
左:预填充(Prefilling)阶段:大语言模型计算并存储输入序列中词块的Key和Value向量,并生成第一个输出词块。右:解码(Decoding)阶段:大语言模型利用KV缓存技术逐个生成输出词块,并在每步生成后存储新词块的Key和Value向量。
数据层优化技术
数据层优化技术可以划分为两大类:输入压缩(Input Compression)和输出规划(Output Organization)。
输入压缩技术
在实际利用大语言模型做回答时,通常会在输入提示词中加入一些辅助内容来增强模型的回答质量,例如,上下文学习技术(In-Context Learning,ICL)提出在输入中加入多个相关的问答例子来教模型如何作答。然而,这些技术不可避免地会增长输入词提示的长度,导致模型推理的开销增大。为了解决该问题,输入压缩技术通过直接减小输入的长度来优化模型的推理效率。本综述将该类技术进一步划分为四个小类,分别为:
- 提示词剪枝(Prompt Pruning):通常根据设计好的重要度评估指标删除输入提示词中不重要的词块、句子或文段,对被压缩的输入提示词执行在线压缩。
- 提示词总结(Prompt Summary):通过对输入提示词做文本总结任务,在保证其语义信息相同地情况下缩短输入的长度。该压缩过程通常也是在线执行的。
- 基于软提示词的压缩(Soft Prompt-based Compression):通过微调训练的方式得到一个长度较短的软提示词,代替原先的输入提示词(在线执行)或其中固定的一部分内容(离线执行)。其中,软提示词指连续的、可学习的词块序列,可以通过训练的方式学习得到。
- 检索增强生成(Retrieval-Augmented Generation):通过检索和输入相关的辅助内容,并只将这些相关的内容加入到输入提示词中,来降低原本的输入长度(相比于加入所有辅助内容)。
输出规划技术
传统的生成解码方式是完全串行的,输出规划技术通过规划输出内容,并行生成某些部分的的输出来降低端到端的推理延时。以该领域最早的工作“思维骨架”(Skeleton-of-Thought,以下简称SoT)为例,SoT技术的核心思想是让大语言模型自行规划输出的并行结构,并基于该结构进行并行解码,提升硬件利用率,减少端到端生成延时。具体来说,如下图所示,SoT将大语言模型的生成分为两个阶段:在提纲阶段,SoT通过设计的提示词让大语言模型输出答案的大纲;在分点扩展阶段,SoT让大语言模型基于大纲中的每一个分点并行做扩展,最后将所有分点扩展的答案合并起来。SoT技术让包含LLaMA-2、Vicuna模型在内的9种主流大语言模型的生成过程加速1.9倍以上,最高可达2.39倍。在SoT技术发布后,一些研究工作通过微调大语言模型、前后端协同优化等方式优化输出规划技术,达到了更好的加速比和回答质量之间的权衡点。 添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
未来方向
本文进一步总结了未来的四个关键应用场景,并讨论了高效性研究在这些场景中的重要性:
- 智能体和多模型框架。在最近的研究中,大语言模型智能体和多模型协同框架受到了许多关注,这类技术可以提升大语言模型的应用能力,使得模型能更好地服务于人类。然而模型的数量增多,以及输入到模型中的指令变长,都会使得智能体或框架系统的推理效率变低。因此需要面向这些框架和场景进行大模型的推理效率优化。
- 长文本场景。随着输入模型文本变得越来越长,大语言模型的效率优化需求变得愈发提升。目前在数据层、模型层和系统层均有相关的技术来优化长文本场景下大语言模型的推理效率,其中设计Transformer的替代新架构受到了许多关注,然而这类架构还未被充分探索,其是否能匹敌传统的Transformer模型仍未清楚。
- 边缘端部署。最近,许多研究工作开始关注于将大语言模型部署到边缘设备上,例如移动手机。一类工作致力于设计将大模型变小,通过直接训练小模型或模型压缩等途径达到该目的;另一类工作聚焦于系统层的优化,通过算子融合、内存管理等技术,直接将70亿参数规模的大模型成功部署到移动手机上。
- 安全-效率协同优化。除了任务精度和推理效率外,大语言模型的安全性也是一个需要被考量的指标。当前的高效性研究均未考虑优化技术对模型安全性的影响。若这些优化技术对模型的安全性产生了负面影响,一个可能的研究方向就是设计新的优化方法,或改进已有的方法,使得模型的安全性和效率能一同被考量。
高性价比GPU算力:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0619_zhihu
相关文章:
无问芯穹Qllm-Eval:制作多模型、多参数、多维度的量化方案
前言 近年来,大语言模型(Large Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而…...

2024-05-31T08:36:09.000+00:00 转换 YYYY-MM-DD HH-MM-SS
function formatDate(date) {// 处理ISO 8601字符串if (typeof date string) {date new Date(date);}// 处理时间戳else if (typeof date number) {date new Date(date * 1000); // 假设后端时间戳为秒,需要乘以1000转换为毫秒}// 自定义格式化,例如…...
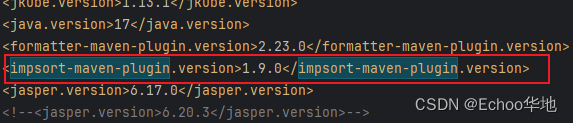
reason: the Java file contained parse errors
今天用Maven打包项目时发生一个错误: file: D:\workspace\echoo2.0-xxx-xxx-portal\src\main\java\com\echoo\service\impl\DecDataServiceImpl.java; reason: the Java file contained parse errors 打包报错显示这个类解析错误 在IDEA中没有任何错误提示 问题所…...
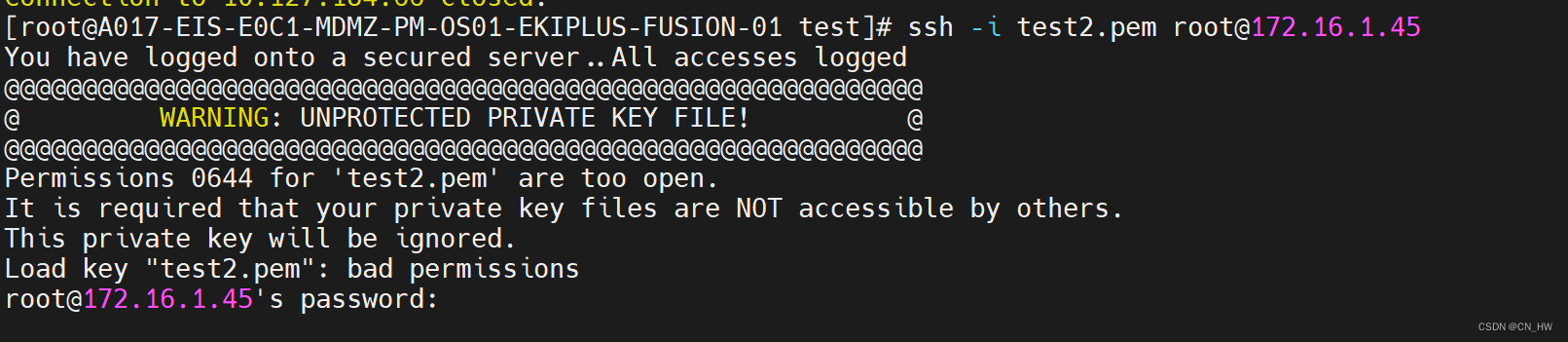
使用密钥对登录服务器
目录 1、使用密钥文件登录服务器 2、登录成功画面: 3、如若出现以下状况,则说明密钥文件登录失败 1、使用密钥文件登录服务器 首先需要上传pem文件 2、登录成功画面: 3、如若出现以下状况,则说明密钥文件登录失败 解决方法&…...

面试_多线程
线程池 线程池的参数有哪些 线程池七大参数分别是corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue、threadFactory、handler corePoolSize:线程池中常驻核心线程数maximumPoolSize:线程池能够容纳同时执行的最大线程数keepAliveTime&…...
跨境电商必备?揭秘原生IP的作用
一、什么是原生IP? 原生IP(Native IP)是指由互联网服务提供商(ISP)或服务器提供商直接分配给用户的IP地址,这种IP地址直接与用户设备或网络相连,也就是指这个IP的注册地址和服务器机房所在的国…...

mysql竖表变横表不含聚合
文章目录 前言一、vertical_table二、转换1.要将其转换为横表形式,例如:2.sql 总结 前言 在MySQL中将竖表转换为横表(也称为行转列操作),不涉及聚合函数,通常可以通过使用条件判断和自连接来实现。假设有一…...

application/x-www-form-urlencoded和json的区别
application/x-www-form-urlencoded 和 application/json 是两种不同的数据格式,常用于HTTP请求中传递数据。 它们各自的特点和使用场景如下: 1. application/x-www-form-urlencoded •特点:这是一种传统的表单提交时采用的编码类型&#x…...
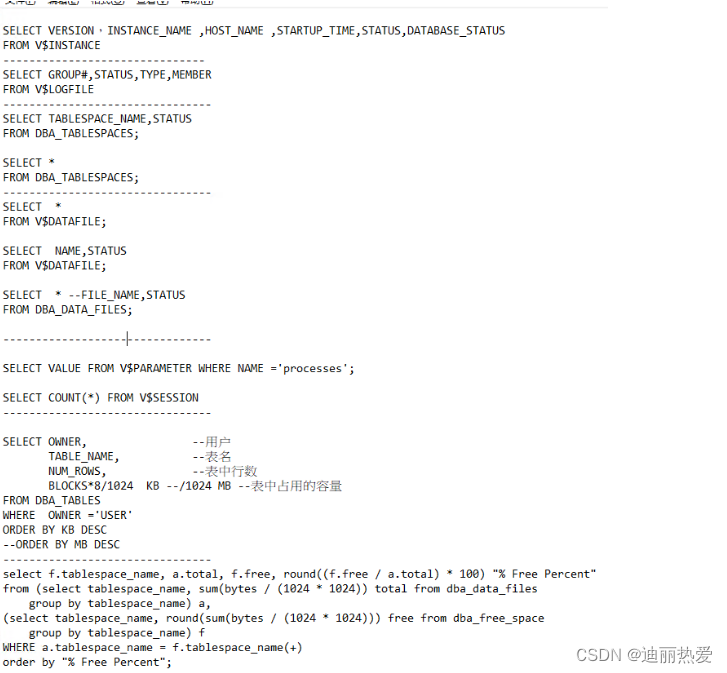
oracle数据库日常保养或巡检语句实践整理汇总
目录 1.目的 2.操作工具 3.实践说明 1.检查Oracle实例状态 2.检查Oracle在线日志状态 3.检查Oracle表空间状态 4.检查Oracle所有数据文件状态 5.检查Oracle数据库连接情况 6.检查Oracle表容量占用大小 7.检查Oracle备份 8.检查数据库表空间的使用情况 4.总结 1.目的 …...

Elasticsearch 第一期:基础的基础概念
前言 Elasticsearch(弹性搜索) ,简称为ES, 它是一个开源的高扩展的分布式全文检索引擎,它提供的功能主要分为:实时存储,实时分析搜索;本身扩展性很好,可以扩展到上百台服…...

MySQL数据库笔记(二)
第一章 单行函数 1.1 什么是函数 函数的作用是把我们经常使用的代码封装起来,需要的时候直接调用即可。这样既提高了代码效率,又提高了可维护性。在SQL中使用函数,极大地提高了用户对数据库的管理效率。 1.2 定义 操作数据对象。 接受参数返回一个结果。 只对一行进行…...

谷歌邮箱:2024年最全使用指南及技巧
注册谷歌邮箱时遇到麻烦了吗?收件箱乱得让人头疼,找不到提升效率的方法?或者是在处理多个谷歌邮箱账户时感到手忙脚乱? 掌握Gmail邮箱的使用技巧是每个外贸人员都必须学会的,本文将提供一个实用的谷歌邮箱注册和使用指…...

工业设计初学者手册——第四部分:制造工艺
工业设计初学者手册 文章目录 工业设计初学者手册第四部分:制造工艺7. 常见制造工艺介绍7.1 传统制造工艺7.2 现代制造工艺 8. 材料选择与应用8.1 材料的基本分类与特性8.2 材料选择的原则8.3 环保材料的应用 总结 第四部分:制造工艺 7. 常见制造工艺介…...

Scala语言:大数据开发的未来之星 - 零基础到精通入门指南
前言 随着大数据时代的到来,数据量的急剧增长为软件开发带来了新的挑战和机遇。Scala语言因其函数式编程和面向对象的特性,以及与Apache Spark的完美协作,在大数据开发领域迅速崛起,成为该领域的新兴宠儿。本篇将从零基础开始&…...
Springboot整合Zookeeper分布式组件实例
一、Zookeeper概述 1.1 Zookeeper的定义 Zookeeper是一个开源的分布式协调服务,主要用于分布式应用程序中的协调管理。它由Apache软件基金会维护,是Hadoop生态系统中的重要成员。Zookeeper提供了一个高效且可靠的分布式锁服务,以及群集管理…...
Python | 使用Matplotlib生成子图的示例
数据可视化在分析和解释数据的过程中起着举足轻重的作用。Python中的Matplotlib库提供了一个强大的工具包,用于制作各种图表和图表。一个突出的功能是它能够在单个图中生成子图,为以组织良好和结构化的方式呈现数据提供了有价值的工具。使用子图可以同时…...

云原生巡检监控报告
一、巡检概述 本次云原生巡检工作主要围绕云原生平台的稳定性、安全性以及性能进行,通过对平台资源的监控、日志分析以及安全扫描,发现了一些潜在的问题和隐患。巡检工作采用了自动化工具和人工分析相结合的方式,确保了巡检结果的准确性和全…...

Linux系统编程——部分内容补充
回顾 进程 内核相关数据结构 代码和数据,一个可执行程序加载到内存变成进程,不仅仅是把代码和数据加载进去就完事了,得“先描述,再组织”,每个进程都有内核数据结构,地址空间,进程相关页表&a…...

数学建模基础:非线性模型
目录 前言 一、非线性方程组 二、非线性规划 三、微分方程模型 四、非线性模型的应用 五、实例示范:传染病传播模型 实例总结 五、总结 前言 非线性模型用于描述变量之间的非线性关系,相比线性模型,其数学形式更为复杂,但…...
Kotlin 语言基础学习
什么是Kotlin ? Kotiln翻译为中文是:靠他灵。它是由JetBrains 这家公司开发的,JetBrains 是一家编译器软件起家的,例如常用的WebStorm、IntelliJ IDEA等软件。 Kotlin官网 JetBrains 官网 Kotlin 语言目前的现状: 目前Android 已将Kotlin 作为官方开发语言。 Spring 框…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...