【猫狗分类】Pytorch VGG16 实现猫狗分类1-数据清洗+制作标签文件
Pytorch 猫狗分类
用Pytorch框架,实现分类问题,好像是学习了一些基础知识后的一个小项目阶段,通过这个分类问题,可以知道整个pytorch的工作流程是什么,会了一个分类,那就可以解决其他的分类问题,当然了,其实最重要的还是,了解她的核心是怎么工作的。
那首先,我们的第一个项目,就做猫狗的分类。
声明:整个数据和代码来自于b站,链接:使用pytorch框架手把手教你利用VGG16网络编写猫狗分类程序_哔哩哔哩_bilibili
我做了复现,并且记录了自己在做这个项目分类时候,一些所思所得。
目前,我需要掌握pytorch针对于分类问题,解决整个分类问题的工作流程是怎么样的,其他的进阶,需要自己去不断的练习和体会。因为,分类问题也是,计算机视觉想要解决的一个重要问题,而且,对于yolo系列,直接解决了分类问题,所以,现在理解好基础的,以后就能更好的理解大佬们的框架,才知道怎么去优化网络。
前面说到,通过softmax函数,把分类问题,转换成了概率问题,把给你一个图片,神经网络回答我是什么的问题,转变成了,给你一个图片,神经网络输出,是什么类别的概率是什么的问题。而神经网络的整个训练过程,也是w在不断被训练的一个动态过程,最后,我们会训练出一个较好的w,输入图片,神经网络就能告诉我们是什么类别了。
那现在,就从数据开始吧。
数据清洗
拿到数据,首先要分析数据集是什么样子的,包括,数据集包含了什么图片,每张图片的命名时怎么样的?
现在,我们有很多猫和狗的照片,存放在train文件夹下面,猫照片,狗照片,分别存在cat和长这样:
再点开dog文件夹:
首先,要根据这两类照片,去生成一个标签文件,具体步骤是这样:
先遍历这两个数据集,遍历的意思是,相当于你打开照片的文件夹,把照片,一张一张的拿出来,然后把每个照片归好类,比如,第二个dog文件夹里面,你拿出第一张,标记是狗,记录下来类别和这张狗照片的路径位置,记录在一个txt文档里面,这就是,到时候训练的时候,提供给trian的一个label文件,这个label文件,告诉网络,我现在给你一张照片,记住,他是一只狗,你来训练吧。就按照这个逻辑,把很多张狗的照片,猫的照片,都喂给网络,让他训练,说到训练,训练的其实是w,就是权重,把权重w训练好了,我们希望到时候,给他随便一个猫或者狗的照片,网络能告诉我,这是一只狗还是一只猫。
那现在,就开始,准备标签文件。
刚说到,想象一下,我们从某个文件夹拿出来一张一张的照片,那就用getcwd函数,获取当前的工作目录。
1、导入包
Import os
from os import getcwd
【拓展:获取当前工作目录】
import os
current_directory = os.getcwd()
print("当前工作目录是:", current_directory)
2、指定照片的类别
classes=['cat','dog']#所有类别,放进列表,这个好处是可以修改,往里面添加或者删除就好了
3、定义数据集划分的方式
sets = ['train'] #这里是表示只有训练集
表示当前的这个脚本,是我们用来处理训练集的,模型通过学习训练集中的特征和标签,去构建预测模型;这样的写法,是便于添加的列表形式,如果项目还需要val和test集,那就直接在sets里面添加这些划分,比如:sets = ['train','val','test']
4、写标签文件(重点来了)
4.1先做一个空的txt文本文件,用来存放等下制作的标签文件。
- 取出这个训练集,对于sets里面的每一个数据集(这里是只有train):for se in sets
- 打开或创建标签文件list_file:
list_file = open('cls_'+se+'.txt'),创建或清空一个名为cls_train.txt的文件(如果se是'train')用于写入图像信息。'w' 是文件打开模式,表示写入,接下来的操作中,会通过,list_file.write()方法往这个文件里写入数据
4.2 空文件做好了,接下来放标签信息,内容是【某张图片类别+这个图片的储存位置】
4.2.1获取图片数据集储存位置
- 获取数据集路径,用os.join拼接起来:
wd = getcwd() #当前工作路径
datasets_path = os.path.join(wd,se) # 拼接,路径+train,意思数据集在trian文件夹这里面
最后指向的是train文件夹:
- 列出数据集根目录下的子目录(类别)
types_name = os.listdir(datasets_path)# 返回是['cat','dog']

【拓展】os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。这里会返回,cat和dog这两个。
4.2.2 遍历最开始定义的数据集类别clsaaes取出索引作为图片数据集的类别
- 遍历类别:对于每个
type_name,检查它是否属于classes列表,classes是我们最开始定义的类别列表,包括,cat和dog如果不在,就跳过这个类别,否则,就继续,意思是,如果类别是猫或狗,就继续执行下面的代码,如果类别不是猫或者狗,就跳过不管了:
for type_name in types_name:
if type_name not in classes:
continue
-
记录类别ID:如果
type_name在classes列表中,获取其索引(即类别ID):
cls_id=classes.index(type_name)#输出0-1
【拓展】.index() 函数用于从列表中找出指定元素的第一个出现位置,并返回其索引。如果元素不存在于列表中,该方法会抛出一个 ValueError 异常。
classes.index(type_name)的意思是,从classes这个猫狗类别的列表中,根据,type_name在classes的索引位置,返回索引位置。
classes['cat','dog'],type_name会返回,0,1
4.2.3 遍历不同类别图片文件夹下的每一张图片,检查格式是不是满足jpg等
- 构建图片目录路径:photos_path=os.path.join(datasets_path,type_name),这里直接定位到存猫和狗的照片位置,就是工作路径下的train下的cat和dog文件夹
- 列出类别目录下的图片文件:
photos_name = os.listdir(photos_path)
【拓展】:os.listdir(path) 函数接收一个路径参数 path,这个路径可以是目录的绝对路径或相对路径。它的作用是返回指定目录下的所有文件和目录名(不包括子目录中的文件)组成的列表。列表中的每个元素都是一个字符串,代表了目录下的一个项(文件或子目录)的名称。
在这里,photos_path是两个照片的文件夹,这里是把所有照片的名字都取出来了,返回的形式是一个列表。
- 对每张照片的名字,进行检查,遍历图片文件:对于每个图片文件,检查其扩展名是否为
.jpg,.png, 或.jpeg。就算不是,也继续
for photo_name in photos_name:
_,postfix = os.path.splitext(photo_name) # os.path.splitext是用来分割文件名字和拓展名字的
if postfix not in ['.jpg','.png','.jpeg']:
continue
【拓展】os.path.splitext(path)是一个内置函数,它接受一个文件路径或文件名作为参数,并返回一个包含两个元素的元组:第一个元素是文件的基本名(不包括扩展名),第二个元素是文件的扩展名(包括前面的点);比如 返回('image', '.jpg'),如果 photo_name 是 'image.jpg'。
使用解包赋值(_, postfix = ...)时,下划线 _ 是一个常用的占位符,表示我们不关心元组的第一个元素(基本文件名),只想保留第二个元素(扩展名)。因此,postfix 变量将存储文件的扩展名,如 .jpg、.png 或 .jpeg.
注意!!!这个逻辑有个混淆的地方:
if postfix not in ['.jpg','.png','.jpeg']:
continue
这段条件语句的目的是排除那些非.jpg, .png, .jpeg格式的文件。具体解释如下:
- 当
postfix(即文件扩展名)不是.jpg,.png, 或.jpeg之一时,postfix not in ['.jpg','.png','.jpeg']这个条件为True。 - 当这个条件为真时,执行
continue语句,这意味着当前循环的剩余部分将被跳过,直接开始检查下一个文件。条件为真,意思是,我检查到的这一张照片的拓展名,不在这三个里面,所以,,针对于这一张,照片,我选择,continue,也就是说,我不管了,我继续执行下一张照片。如果下一张照片的拓展名,是属于这三个格式,那我就,进行进一步的图片操作。 - 因此,只有当文件扩展名确实是
.jpg,.png, 或.jpeg时,代码才会继续执行后续对这些图像文件的操作,比如将其路径写入到输出文件中。
所以,正确的理解是,这段代码是用来确保仅处理.jpg, .png, .jpeg这三种图片格式的文件,而忽略所有其他格式的文件。
4.2.4 把要的图片的类别和每张图片的路径写进label文本文件里
- 那么,对于是刚刚说的符合三个格式的照片,我们收集起来,写入到最开始,打开的那个list_file的文件里面去:
list_file.write(str(cls_id)+';'+'%s/%s'%(wd, os.path.join(photos_path,photo_name)))
list_file.write('\n')
-
构造字符串:
str(cls_id)+';'+'%s/%s'%(wd, os.path.join(photos_path,photo_name))这部分代码构造了一条记录,内容包括:cls_id:这是图像所属类别的ID,转换为字符串形式。假设cls_id为0或1(对应于'cat'或'dog')。';':分隔符,用于在类别ID与文件路径之间提供清晰的分隔。'%s/%s'%(wd, os.path.join(photos_path,photo_name)):这部分构造了图像的完整路径。%s是字符串格式化占位符,第一个%s会被wd(当前工作目录)替换,第二个%s会被os.path.join(photos_path,photo_name)的结果替换。os.path.join(photos_path,photo_name)确保了路径拼接的跨平台兼容性,生成从当前工作目录到目标图片的完整相对路径。
-
写入文件:
list_file.write(...)将上述构造的字符串写入到list_file所指向的文件中。这样,每张图片的信息(类别ID和相对路径)就会以文本形式存储在文件里,每条记录之间通过分号分隔,每条记录末尾通过list_file.write('\n')添加换行符,以便于之后读取时能清晰地区分每一条记录。
-
最后,list_file.close()
注意:原来的博主,用的是gbk编码,这样生成的label文件在我这是乱码,其实一般用utf-8会好,所以,需要写一个程序,把编码格式改成utf-8:

# 转换脚本
# 转换脚本
def convert_gbk_to_utf8(input_file, output_file):with open(input_file, 'r', encoding='gbk') as f:content = f.read()with open(output_file, 'w', encoding='utf-8') as f:f.write(content)# 调用函数进行转换
input_file = 'cls_train.txt' # 这里填写你的GBK编码文件名
output_file = 'cls_train_1.txt' # 输出的UTF-8编码文件名
convert_gbk_to_utf8(input_file, output_file)总结
到这里,就针对于我们的猫狗数据集,完成了,数据的清洗以及标签文件的制作。所以,对于其他的数据集,步骤也是大差不差的。
现在来,总结一下:
1、拿到数据做什么?
- 数据清洗+标签文件制作(两个步骤相辅相成)
首先,拿到数据集,我们要做两件事,数据清洗和制作标签文件,在这个项目里面,照片都是很干净的数据,不存在格式乱七八糟或者其他的情况,所以,清洗就是简单的判断是不是jpg等格式,还是很简单的。
另外就是,标签文件夹的制作。这里学到的一点是,我们可以先分析图片的存放形式,然后,通过索引的方式,遍历,train文件夹下的不同类别的子目录,完成自动生成好几个类别的作用。
2、分类标签文件存什么?
- 标签文件信息:类别+图片路径
映射文件:当图片和标签不是通过文件结构直接关联时,会使用一个映射文件来记录这种对应关系。这个映射文件(如CSV)通常包含至少两列,一列是图片的路径或文件名,另一列是对应的类别标签。例如:
1image_path,label
2data/cats/cat_001.jpg,0
3data/dogs/dog_002.png,1在这个映射文件中,第一列是图片的完整路径或相对于某个根目录的路径,第二列是类别标签,0代表猫,1代表狗。
在使用深度学习框架(如PyTorch)进行训练时,可以通过自定义的数据加载器(DataLoader)读取这种映射文件,根据映射关系动态地加载图像和对应的标签,从而实现图片与其类别信息的正确配对。
3、拓展到其他的数据处理过程
- 图片名字是各有不同的,有的很复杂,各种标点符号什么的,会涉及更复杂的处理。所以要学会观察图片名字,然后做出分割。
- 分类问题的标签还是很简单的,就是把图片文件路径读取,然后拆开,根据循环,一张一张图片的取出来解析,是什么类型,然后配上每张图片的路径。
完整代码
import os
from os import getcwdclasses=['cat','dog']
sets=['train']if __name__=='__main__':wd=getcwd()for se in sets:list_file=open('cls_'+ se +'.txt','w')datasets_path=setypes_name=os.listdir(datasets_path)#os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表for type_name in types_name:if type_name not in classes:continuecls_id=classes.index(type_name)#输出0-1photos_path=os.path.join(datasets_path,type_name)photos_name=os.listdir(photos_path)for photo_name in photos_name:_,postfix=os.path.splitext(photo_name)#该函数用于分离文件名与拓展名if postfix not in['.jpg','.png','.jpeg']:continuelist_file.write(str(cls_id)+';'+'%s/%s'%(wd, os.path.join(photos_path,photo_name)))list_file.write('\n')list_file.close()【为什么每个图片能精准匹配到他的类别?】实际上是因为用了两个循环,第一个大循环(for type_name in types_name),让你进入到cat文件夹,然后,第二个小循环(for photo_name in types_name),遍历,cat文件夹下面的每一张图片, 直到cat里面每一张图片都遍历完,在跳入dog文件夹的大循环,然后,遍历,dog文件夹下面的每一个狗的图片。
所以,数据集组织结构要清晰,每个类别下的图片需放在对应类别名称的文件夹中。
相关文章:
【猫狗分类】Pytorch VGG16 实现猫狗分类1-数据清洗+制作标签文件
Pytorch 猫狗分类 用Pytorch框架,实现分类问题,好像是学习了一些基础知识后的一个小项目阶段,通过这个分类问题,可以知道整个pytorch的工作流程是什么,会了一个分类,那就可以解决其他的分类问题࿰…...

磁盘管理 磁盘介绍 MBR
track:磁道,就是磁盘上同心圆,从外向里,依次1号、2号磁道..... sector:扇区,将磁盘分成一个一个扇形区域,每个扇区大小是512字节,从外向里,依次是1号扇区、2号扇区... cy…...

JSON响应中提取特定的信息——6.14山大软院项目实训2
在收到的JSON响应中提取特定的信息(如response字段中的文本)并进行输出,需要进行JSON解析。在Unity中,可以使用JsonUtility进行简单的解析,但由于JsonUtility对嵌套对象的支持有限,通常推荐使用第三方库如N…...

【C++高阶】高效搜索的秘密:深入解析搜索二叉树
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:C多态 🌹🌹期待您的关注 🌹🌹 ❀二叉搜索树 📒1. 二叉搜索树&…...

《软件定义安全》之七:SDN安全案例
第7章 SDN安全案例 1.DDoS缓解 1.1 Radware DefenseFlow/Defense4All Radware在开源的SDN控制器平台OpenDaylight(ODL)上集成了一套抗DDoS的模块和应用,称为Defense4ALL。其架构如下图,主要有两部分:控制器中的安全…...
java语言his系统医保接口 云HIS系统首页功能实现springboot框架+Saas模式 his系统项目源码
java语言his系统医保接口 云HIS系统首页功能实现springboot框架Saas模式 his系统项目源码 HIS系统的实施旨在整个医院建设企业级的计算机网络系统,并在其基础上构建企业级的应用系统,实现整个医院的人、财、物等各种信息的顺畅流通和高度共享,…...
使用vscode插件du-i18n处理前端项目国际化翻译多语言
前段时间我写了一篇关于项目国际化使用I18n组件的文章,Vue3 TS 使用国际化组件I18n,那个时候还没真正在项目中使用,需求排期还没有定,相当于是预研。 当时就看了一下大概怎么用,改了一个简单的页面,最近需…...
双系统下,如何隐藏另一个系统分区?
前言 最近有小伙伴在公众号下留言: 小伙伴说:“双系统时,非当前系统的系统盘能不能屏蔽?!比如Win7的系统盘在Win10系统时,盘符成了D盘,安装应用软件时,有些文件就到了D盘࿰…...
电脑意外出现user32.dll丢失的八种修复方法,有效解决user32.dll文件丢失
遇到与 user32.dll 相关的错误通常是因为该文件已损坏、丢失、或者与某些软件冲突。今天这篇文章寄给大家介绍八种修复user32.dll丢失的方法,下面是一步步的详细教程来解决这个问题。 1. 重新启动电脑 第一步总是最简单的:重新启动你的电脑。许多小问题…...

CUDA系列-Kernel Launch-8
这里写目录标题 kernel launch 本章主要追踪一下kernel launch的流程,会不断完善。 kernel launch 先抛出一个问题,如果在一个循环中不断的发送kernel(kernel 内部while死循环),会是什么结果。 // kernel 函数 __glo…...
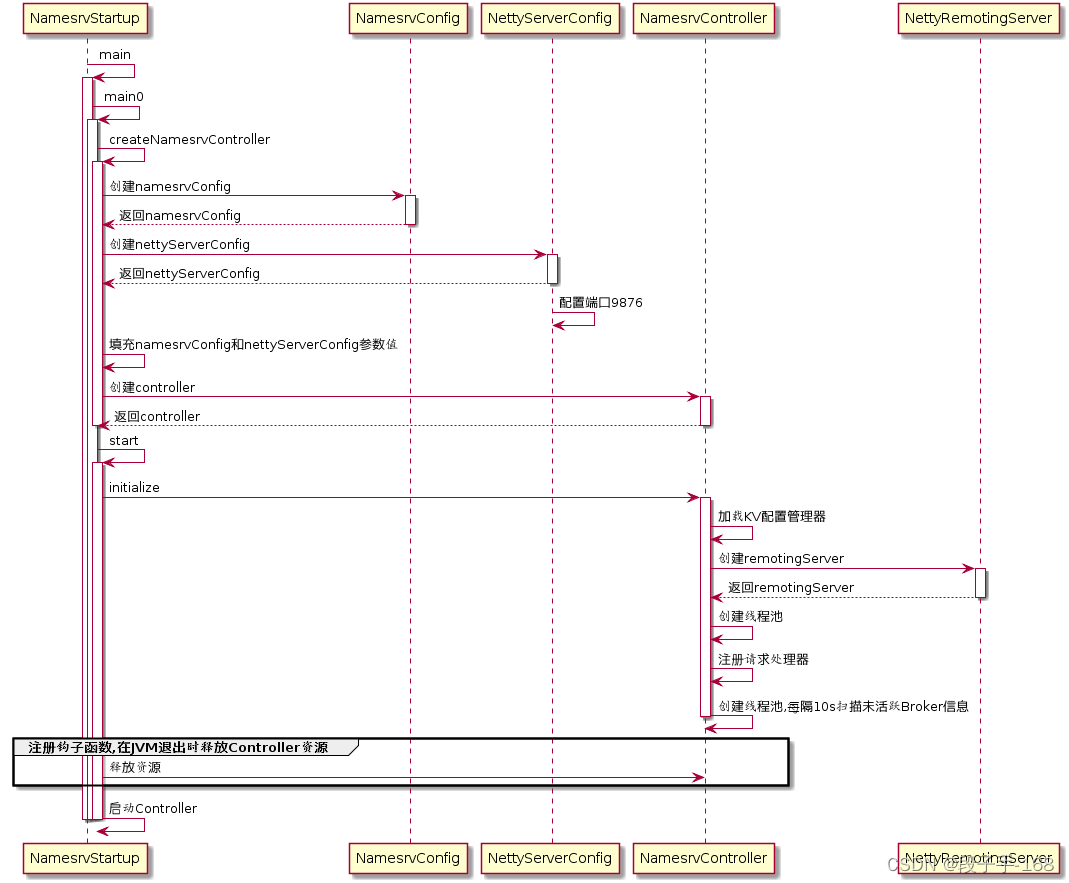
# 消息中间件 RocketMQ 高级功能和源码分析(四)
消息中间件 RocketMQ 高级功能和源码分析(四) 一、 消息中间件 RocketMQ 源码分析:回顾 NameServer 架构设计。 1、RocketMQ 架构设计 消息中间件的设计思路一般是基于主题订阅发布的机制,消息生产者(Producer&…...

如何通过数据库与AI实现以图搜图?OceanBase向量功能详解
OceanBase支持向量数据库的基础能力 当前,数据库存储系统与人工智能技术的结合,可以体现在两个主要的应用方向上。 一、近似搜索。它利用大语言模型(LLM,简称大模型)的嵌入(embedding)技术&am…...

Kafka内外网分流配置listeners和advertised.listeners
问题背景: Kafka部署在内网,内网Java服务会使用Kafka收发消息,另外,Java服务会与其他第三方系统使用kafka实现数据同步,也就是外网也会发送消息到kafka,外网IP做了端口映射到了内网,advertised…...
Linux系统编程——网络编程
目录 一、对于Socket、TCP/UDP、端口号的认知: 1.1 什么是Socket: 1.2 TCP/UDP对比: 1.3 端口号的作用: 二、字节序 2.1 字节序相关概念: 2.2 为什么会有字节序: 2.3 主机字节序转换成网络字节序函数…...

信息安全技术基础知识-经典题目
【第1题】 1.在信息安全领域,基本的安全性原则包括机密性(Confidentiality)、完整性(Integrity)和 可用性(Availability)。机密性指保护信息在使用、传输和存储时 (1) 。信息加密是保证系统机密性的常用手段。使用哈希校验是保证数据完整性的常用方法。可用性指保证…...

nextjs(持续学习中)
return ( <p className{${lusitana.className} text-xl text-gray-800 md:text-3xl md:leading-normal}> Welcome to Acme. This is the example for the{’ } Next.js Learn Course , brought to you by Vercel. ); } 在顶级 /public 文件夹下提供静态资产 **默认 /…...

数据预处理与特征工程、过拟合与欠拟合
数据预处理与特征工程 常用的数据预处理步骤 向量化:将数据转换成pytorch张量值归一化:将特定特征的数据表示成均值为0,标准差为1的数据的过程;取较小的值:通常在0和1之间;相同值域处理缺失值特征工程&am…...

甲辰年五月十四风雨思
甲辰年五月十四风雨思 夜雨消暑气,远光归家心。 只待万窗明,朝夕千家勤。 苦乐言行得,酸甜日常品。 宫商角徵羽,仁义礼智信。...

java分别使用 iText 7 库和iText 5 库 将excel转成PDF导出,以及如何对excel转PDF合并单元格
第一种 package com.junfun.pms.report.util;import com.itextpdf.kernel.font.PdfFontFactory; import com.itextpdf.layout.Document; import com.itextpdf.layout.element.Paragraph; import com.itextpdf.layout.property.TextAlignment; import com.itextpdf.layout.prop…...

Java特性之设计模式【访问者模式】
一、访问者模式 概述 在访问者模式(Visitor Pattern)中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随着访问者改变而改变。这种类型的设计模式属于行为型模式。根据模式&…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

探索Selenium:自动化测试的神奇钥匙
目录 一、Selenium 是什么1.1 定义与概念1.2 发展历程1.3 功能概述 二、Selenium 工作原理剖析2.1 架构组成2.2 工作流程2.3 通信机制 三、Selenium 的优势3.1 跨浏览器与平台支持3.2 丰富的语言支持3.3 强大的社区支持 四、Selenium 的应用场景4.1 Web 应用自动化测试4.2 数据…...