python pandas处理股票量化数据:笔记2
有一个同学用我的推荐链接注册了tushare社区帐号https://tushare.pro/register?reg=671815,现在有了170分积分。目前使用数据的频率受限制。不过可以在调试期间通过python控制台获取数据,将数据保存在本地以后使用不用高频率访问tushare数据接口,访问频率限制影响不大。
>>> data = pro.stock_basic(fields='ts_code,symbol,name,area,industry,list_date,market,is_hs,list_status,exchange,delist_date,curr_type')>>> type(data)
<class 'pandas.core.frame.DataFrame'>
>>> datats_code symbol name area ... list_status list_date delist_date is_hs
0 000001.SZ 000001 平安银行 深圳 ... L 19910403 None S
1 000002.SZ 000002 万科A 深圳 ... L 19910129 None S
2 000004.SZ 000004 国华网安 深圳 ... L 19910114 None N
3 000006.SZ 000006 深振业A 深圳 ... L 19920427 None S
4 000007.SZ 000007 *ST全新 深圳 ... L 19920413 None N
... ... ... ... ... ... ... ... ... ...
5360 873726.BJ 873726 卓兆点胶 江苏 ... L 20231019 None N
5361 873806.BJ 873806 云星宇 北京 ... L 20240111 None N
5362 873833.BJ 873833 美心翼申 重庆 ... L 20231108 None N
5363 920002.BJ 920002 万达轴承 None ... L 20240530 None N
5364 689009.SH 689009 九号公司-WD 北京 ... L 20201029 None None[5365 rows x 12 columns]
>>> data.info
<bound method DataFrame.info of ts_code symbol name area ... list_status list_date delist_date is_hs
0 000001.SZ 000001 平安银行 深圳 ... L 19910403 None S
1 000002.SZ 000002 万科A 深圳 ... L 19910129 None S
2 000004.SZ 000004 国华网安 深圳 ... L 19910114 None N
3 000006.SZ 000006 深振业A 深圳 ... L 19920427 None S
4 000007.SZ 000007 *ST全新 深圳 ... L 19920413 None N
... ... ... ... ... ... ... ... ... ...
5360 873726.BJ 873726 卓兆点胶 江苏 ... L 20231019 None N
5361 873806.BJ 873806 云星宇 北京 ... L 20240111 None N
5362 873833.BJ 873833 美心翼申 重庆 ... L 20231108 None N
5363 920002.BJ 920002 万达轴承 None ... L 20240530 None N
5364 689009.SH 689009 九号公司-WD 北京 ... L 20201029 None None[5365 rows x 12 columns]>
>>> data.describe()ts_code symbol name area ... list_status list_date delist_date is_hs
count 5365 5365 5365 5358 ... 5365 5365 0 5364
unique 5365 5365 5364 32 ... 1 2727 0 3
top 000001.SZ 000001 三维股份 浙江 ... L 20200727 NaN N
freq 1 1 2 706 ... 5365 31 NaN 2481[4 rows x 12 columns]
>>> data.index
RangeIndex(start=0, stop=5365, step=1)
>>> data.columns
Index(['ts_code', 'symbol', 'name', 'area', 'industry', 'market', 'exchange','curr_type', 'list_status', 'list_date', 'delist_date', 'is_hs'],dtype='object')
>>> data.shape
(5365, 12)
>>> data.shape[0]
5365
>>> data.shape[1]
12
>>> data.values
array([['000001.SZ', '000001', '平安银行', ..., '19910403', None, 'S'],['000002.SZ', '000002', '万科A', ..., '19910129', None, 'S'],['000004.SZ', '000004', '国华网安', ..., '19910114', None, 'N'],...,['873833.BJ', '873833', '美心翼申', ..., '20231108', None, 'N'],['920002.BJ', '920002', '万达轴承', ..., '20240530', None, 'N'],['689009.SH', '689009', '九号公司-WD', ..., '20201029', None, None]],dtype=object)
>>>
>>> print(data.dtypes)
ts_code object
symbol object
name object
area object
industry object
market object
exchange object
curr_type object
list_status object
list_date object
delist_date object
is_hs object
dtype: object
>>> 1、DataFrame操作
tushare pro接口返回的数据类型<class 'pandas.core.frame.DataFrame'>
>>> type(data)
<class 'pandas.core.frame.DataFrame'>
从上面可以看到data = pro.stock_basic(fields='ts_code,symbol,name,area,industry,list_date,market,is_hs,list_status,exchange,delist_date,curr_type')返回的数据是[5365 rows x 12 columns]
pandas.DataFrame.info
打印一个DataFrame的简要介绍(index范围、columns的dtype、非空值的数量和内存的使用情况):
DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, show_counts=None)[source]
verbose(adj 冗长的): bool, optional,决定是否打印完整的摘要, 如果为False,那么会省略一部分
buf: writable buffer, defaults to sys.stdout,,决定将输出发送到哪里,默认情况下, 输出打印到sys.stdout
max_cols: int, optional 从“详细输出”转换为“缩减输出”,如果DataFrame的列数超过max_cols,则缩减输出。
memory_usage: bool, str, optional 决定是否应显示DataFrame元素(包括索引)的总内存使用情况,默认情况下为True。True始终显示内存使用情况;False永远不会显示内存使用情况。
show_counts: bool, optional,是否显示非空值的数量,值为True始终显示计数,而值为False则不显示计数
>>> data.info(verbose=True)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5365 entries, 0 to 5364
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ts_code 5365 non-null object
1 symbol 5365 non-null object
2 name 5365 non-null object
3 area 5358 non-null object
4 industry 5358 non-null object
5 market 5365 non-null object
6 exchange 5365 non-null object
7 curr_type 5365 non-null object
8 list_status 5365 non-null object
9 list_date 5365 non-null object
10 delist_date 0 non-null object
11 is_hs 5364 non-null object
dtypes: object(12)
memory usage: 251.5+ KB
>>> data.info(verbose=False)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5365 entries, 0 to 5364
Columns: 12 entries, ts_code to is_hs
dtypes: object(12)
memory usage: 251.5+ KB
>>>
>>> print(data.tail())
ts_code symbol name area ... list_status list_date delist_date is_hs
5360 873726.BJ 873726 卓兆点胶 江苏 ... L 20231019 None N
5361 873806.BJ 873806 云星宇 北京 ... L 20240111 None N
5362 873833.BJ 873833 美心翼申 重庆 ... L 20231108 None N
5363 920002.BJ 920002 万达轴承 None ... L 20240530 None N
5364 689009.SH 689009 九号公司-WD 北京 ... L 20201029 None None[5 rows x 12 columns]
>>> print(data.head())
ts_code symbol name area ... list_status list_date delist_date is_hs
0 000001.SZ 000001 平安银行 深圳 ... L 19910403 None S
1 000002.SZ 000002 万科A 深圳 ... L 19910129 None S
2 000004.SZ 000004 国华网安 深圳 ... L 19910114 None N
3 000006.SZ 000006 深振业A 深圳 ... L 19920427 None S
4 000007.SZ 000007 *ST全新 深圳 ... L 19920413 None N[5 rows x 12 columns]
>>>
# 获得DataFrame行索引信息
data.index
# 获得DataFrame列索引信息
data.columns# 获得DataFrame的size
data.shape
# 获得DataFrame的行数
data.shape[0]# 获得DataFrame的 列数
data.shape[1]# 获得DataFrame中的值
data.values# 获得DataFrame中列值数据类型
data.dtypes
Pandas describe()
Pandas describe()用于查看一些基本的统计详细信息,例如每列的均值、标准差、最大值、最小值和众数
>>> data.describe()
ts_code symbol name area ... list_status list_date delist_date is_hs
count 5365 5365 5365 5358 ... 5365 5365 0 5364
unique 5365 5365 5364 32 ... 1 2727 0 3
top 000001.SZ 000001 三维股份 浙江 ... L 20200727 NaN N
freq 1 1 2 706 ... 5365 31 NaN 2481[4 rows x 12 columns]
>>> type(data.describe())
<class 'pandas.core.frame.DataFrame'>
>>>
describe()的输出也是DataFrame
>>> import pandas as pd
>>> import pdb
>>>
dict_data={"X":list("abcdef"),"Y":list("defghi"),"Z":list("ghijkl")}
df=pd.DataFrame.from_dict(dict_data)
df.index=["A","B","C","D","E","F"]>>> dfX Y Z
A a d g
B b e h
C c f i
D d g j
E e h k
F f i l
>>> df.describe()X Y Z
count 6 6 6
unique 6 6 6
top a d g
freq 1 1 1
>>>
>>> type(df.describe())
<class 'pandas.core.frame.DataFrame'>
>>>
>>> # A 行 X 列数据,必须两个数据都输入,否则报错
print(df.at["A","X"])
# 第二 行 第二 列数据,序号从0开始
print(df.iat[2,2])
a
i
>>>
>>> # 指定行名和列名的方式,和at的用法相同
print(df.loc["A","X"],"\n","*"*20)# 可以完整切片,这是 at 做不到的
print(df.loc[:,"X"],"\n","*"*20)# 可以从某一行开始切片
print(df.loc["B":,"X"],"\n","*"*20)# 可以只切某一列
print(df.loc["B",:],"\n","*"*20)# 和指定上一条代码效果是一样的
print(df.loc["B"],"\n","*"*20)
a ********************
A a
B b
C c
D d
E e
F f
Name: X, dtype: object ********************
B b
C c
D d
E e
F f
Name: X, dtype: object ********************
X b
Y e
Z h
Name: B, dtype: object ********************
X b
Y e
Z h
Name: B, dtype: object ********************
>>>
>>> # 指定行号和列号的方式,和 loc 的用法相同
print(df.iloc[0,0],"\n","*"*20)# 可以完整切片
print(df.iloc[:,0],"\n","*"*20)# 可以从某一行开始切片
print(df.iloc[1:,0],"\n","*"*20)# 可以只切某一列
print(df.iloc[1,:],"\n","*"*20)# 和指定上一条代码效果是一样的
print(df.iloc[1],"\n","*"*20)
a ********************
A a
B b
C c
D d
E e
F f
Name: X, dtype: object ********************
B b
C c
D d
E e
F f
Name: X, dtype: object ********************
X b
Y e
Z h
Name: B, dtype: object ********************
X b
Y e
Z h
Name: B, dtype: object ********************
>>>DataFrame索引数据
at 函数:通过行名和列名来取值
loc函数主要通过 行标签 索引行数据
iloc函数主要通过行号、索引行数据
导出数据
dataframe可以使用to_csv方法方便地导出到csv文件中,如果数据中含有中文,一般encoding指定为”utf-8″,否则导出时程序会因为不能识别相应的字符串而抛出异常,index指定为False表示不用导出dataframe的index数据。
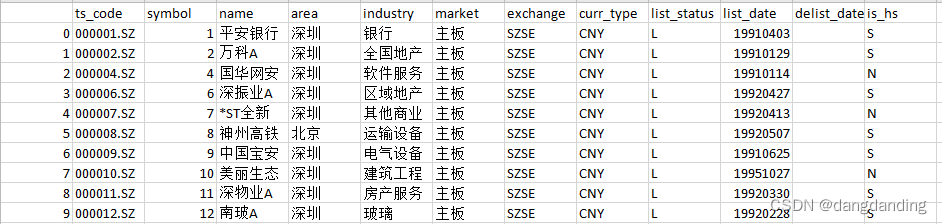
>>> data.to_csv("C:\\Users\\Downloads\\stock.csv", index=False)
>>> data.to_csv("C:\\Users\\Downloads\\stock_indx.csv", index=True)
index为False和True时区别如下

从文件读取数据到pandas
pandas在读取csv文件是通过read_csv这个函数读取
base_data = pd.read_csv("C:\\Users\\Downloads\\stock.csv")
base_data1 = pd.read_csv("C:\\Users\\Downloads\\stock_idx.csv") #比上一个文件多一列
看我发现了什么神奇的宝藏:从零开始用Python实现股票量化交易之小白笔记(1)-CSDN博客
躺平了,照着做吧。
mysql数据库
mysql -u root -p
alter user root@localhost identified by 'password';create database stock;
use stockCREATE TABLE `stock_basic` (`index` int(11) DEFAULT NULL,`ts_code` varchar(12) DEFAULT NULL,`symbol` varchar(10) DEFAULT NULL,`name` varchar(10) DEFAULT NULL,`area` varchar(10) DEFAULT NULL,`industry` varchar(50) DEFAULT NULL,`market` varchar(10) DEFAULT NULL,`exchange` varchar(10) DEFAULT NULL,`curr_type` varchar(10) DEFAULT NULL,`list_status` varchar(5) DEFAULT NULL,`list_date` varchar(10) DEFAULT NULL,`delist_date` varchar(20) DEFAULT NULL,`is_hs` varchar(5) DEFAULT NULL,KEY `ix_stock_basic_index` (`index`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE `stock_daily_qfq` (`id` int(11) NOT NULL AUTO_INCREMENT,`trade_date` varchar(10) DEFAULT '' COMMENT '交易日',`ts_code` varchar(12) DEFAULT '' COMMENT '股票代码',`open` decimal(10,2) DEFAULT '0.00' COMMENT '开盘价',`high` decimal(10,2) DEFAULT '0.00' COMMENT '最高价',`low` decimal(10,2) DEFAULT '0.00' COMMENT '最低价',`close` decimal(10,2) DEFAULT '0.00' COMMENT '收盘价',`pre_close` decimal(10,2) DEFAULT '0.00' COMMENT '昨日收盘价',`change` decimal(10,2) DEFAULT '0.00' COMMENT '价格变化',`pct_chg` double(16,4) DEFAULT '0.0000' COMMENT '涨跌幅',`vol` decimal(10,2) DEFAULT '0.00' COMMENT '成交量(手)',`amount` double(16,4) DEFAULT '0.0000' COMMENT '成交额(千元)',`turnover_rate` double(16,4) DEFAULT NULL COMMENT '换手率',`volume_ratio` decimal(10,2) DEFAULT '0.00' COMMENT '量比',`ma5` decimal(10,2) DEFAULT '0.00' COMMENT '五日均线',`ma_v_5` decimal(10,2) DEFAULT '0.00' COMMENT '5日指数平均值',`ma10` decimal(10,2) DEFAULT '0.00',`ma_v_10` decimal(10,2) DEFAULT '0.00',`ma30` decimal(10,2) DEFAULT '0.00',`ma_v_30` decimal(10,2) DEFAULT '0.00',`ma60` decimal(10,2) DEFAULT '0.00',`ma_v_60` decimal(10,2) DEFAULT '0.00',`ma13` decimal(10,2) DEFAULT '0.00',`ma_v_13` decimal(10,2) DEFAULT '0.00',`ma21` decimal(10,2) DEFAULT '0.00',`ma_v_21` decimal(10,2) DEFAULT '0.00',`ma55` decimal(10,2) DEFAULT '0.00',`ma_v_55` decimal(10,2) DEFAULT '0.00',PRIMARY KEY (`id`),UNIQUE KEY `uni_key` (`trade_date`,`ts_code`) USING BTREE,KEY `ts_code` (`ts_code`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=203 DEFAULT CHARSET=utf8mysql> show tables;
+-----------------+
| Tables_in_stock |
+-----------------+
| stock_basic |
+-----------------+
1 row in set (0.00 sec)mysql>quit相关文章:
python pandas处理股票量化数据:笔记2
有一个同学用我的推荐链接注册了tushare社区帐号https://tushare.pro/register?reg671815,现在有了170分积分。目前使用数据的频率受限制。不过可以在调试期间通过python控制台获取数据,将数据保存在本地以后使用不用高频率访问tushare数据接口…...

enum库
Python enum 模块教程 enum 是 Python 3.4 引入的一个模块,用于定义枚举类型。枚举类型是一种特殊的数据类型,由一组命名的值组成,这些值称为枚举成员。使用 enum 可以提高代码的可读性和可维护性,特别是在处理一组相关的常量值时…...

【CT】LeetCode手撕—141. 环形链表
目录 题目1- 思路2- 实现⭐141. 环形链表——题解思路 3- ACM实现 题目 原题连接:141. 环形链表 1- 思路 模式识别 模式1:判断链表的环 ——> 快慢指针 思路 快指针 ——> 走两步慢指针 ——> 走一步判断环:若快慢相遇则有环&a…...

python,自定义token生成
1、使用的包PyJWT来实现token生成 安装:pip install PyJWT2.8.0 2、使用例子: import jwt import time pip install pyJWT2.8.0 SECRET_KEY %^ES*E&Ryurehuie9*7^%$#$EDFGHUYTRE#$%^&%$##$RTYGHIK DEFAULT_EXP 7 * 24 * 60def create_token(…...

小米SU7遇冷,下一代全新车型被官方意外曝光
不知道大伙儿有没有发现,最近小米 SU7 热度好像突然之间就淡了不少? 作为小米首款车型,SU7 自上市以来一直承载着新能源轿车领域流量标杆这样一个存在。 发售 24 小时订单量破 8 万,2 个月后累计交付破 2 万台。 看得出来限制它…...

JavaScript 函数与事件
1. JavaScript自定义函数 语法: function 函数名(参数列表){ 方法体; } 在函数被调用时,一个 arguments 对象就会被创建,它只能使用在函数体中,以数组的形式来管理函数的实际…...

Qt 焦点系统关键点总结
1.1 焦点窗口 指的是当前时刻拥有键盘输入的窗口。 Qt提供了如下接口,用于设置窗口是否是”可获取焦点“窗口: void QWidget::setFocusPolicy(Qt::FocusPolicy policy); Qt::FocusPolicy Qt::TabFocus 与焦点链相关,详解见下一…...
SpringBoot+Maven项目的配置构建
文章目录 1、application.properties2、pom.xml 1、application.properties 也可使用yml yaml #静态资源 spring.mvc.static-path-pattern/images/** #上传文件大小设置 spring.http.multipart.max-file-size10MB spring.http.multipart.max-request-size10MBspring.mvc.path…...
c#调用c++dll方法
添加dll文件到debug目录,c#生成的exe的相同目录 就可以直接使用了,放在构造函数里面测试...

ACM算法学习路线、清单
入门 模拟、暴力、贪心、高精度、排序 图论 搜索 BFS、DFS、IDDFS、IDA*、A*、双向BFS、记忆化 最短路 SPFA、bellman-fort(队列优化)、Dijkstra(堆优化)、Johnson、Floyd、差分约束、第k短路 树 树的重心和直径、dfs序、树链刨分与动态树、LCA、Prufer编码及Cayley定理…...
sqoop的安装配置
1. 上传并解压安装包 tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C ../server/ 重命名:mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop 2. 配置环境变量 sudo vim /etc/profile # 配置sqoop的环境变量 export SQOOP_HOME/export/server/sqoop export PATH$PATH…...

代码随想录算法训练营第六十四天 | 图论理论基础、深搜理论基础、广搜理论基础、98. 所有可达路径
图论理论基础 我写在了个人语雀笔记中 https://www.yuque.com/yuqueyonghu8mml9e/bmbl71/ex473q4y0ebs0l3r?singleDoc# 深搜理论基础 https://www.yuque.com/yuqueyonghu8mml9e/bmbl71/zamfikz08c2haptn?singleDoc# 98. 所有可达路径 题目链接:98. 所有可达…...

【教师资格证考试综合素质——法律专项】教师法笔记以及练习题
《中华人民共和国教师法》 一.首次颁布:第一部《中华人民共和国教师法》于1993年10月31日由第八届全国人民代表大会常务委员会第四次会议通过,1994年1月1日起执行。 二.历次修改:2009年8月27日第十一届全国人民代表…...
图卷积网络(Graph Convolutional Network, GCN)
图卷积网络(Graph Convolutional Network, GCN)是一种用于处理图结构数据的深度学习模型。GCN编码器的核心思想是通过邻接节点的信息聚合来更新节点表示。 图的表示 一个图 G通常表示为 G(V,E),其中: V 是节点集合,…...
】pipeline 实际调用的是什么? __call__ 方法!)
【diffusers 极速入门(一)】pipeline 实际调用的是什么? __call__ 方法!
在使用 diffusers 库进行图像生成时,你可能会发现管道(pipeline)对象可以像函数一样被调用。这背后的魔法是什么呢?答案是:__call__ 方法!本文将通过简单的案例代码,带你快速了解 diffusers 管道…...

【DPDK学习路径】二、DPDK简介
DPDK(Data Plane Development Kit)是一个框架,用于快速报文处理。 在linux内核提供的报文处理模型中,接收报文的处理路径为:首先由网卡硬件接收,产生硬中断,触发网卡驱动程序注册的中断函数处理,之后产生软…...
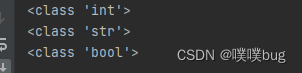
python基础 002 - 2 常用数据类型
python的常用数据类型 int , 整型 1,2,3float ,小数,浮点类型1.2bool , boolean 布尔,真假。判断命题。True Flasestr ,字符串 list , 列表 a []tuple, 元组 a ()dict , dictionary, 字典 a {}set , 集合 a {} 1 查看数据类型 typ…...

爆赞!GitHub首本Python开发实战背记手册,标星果然百万名不虚传
Python (发音:[ paiθ(ə) n; (US) paiθɔn ] n. 蟒蛇,巨蛇 ),是一种面向对象的解释性的计算机程序设计语言,也是一种功能强大而完善的通用型语言,已经具有十多年的发展历史,成熟且稳定。Python 具有脚本语言中最丰富…...

Spring源码-xxxAware实现类和BeanPostProcessor接口调用过程
xxxAware实现类作用 以ApplicationContextAware接口为例 ApplicationContextAware的作用是可以方便获取Spring容器ApplicationContext,从而可以获取容器内的Bean package org.springframework.context;import org.springframework.beans.BeansException; import or…...

Uni-app x
uni-app x,是下一代 uni-app,是一个跨平台应用开发引擎。 uni-app x 是一个庞大的工程,它包括uts语言、uvue渲染引擎、uni的组件和API、以及扩展机制。 uts是一门类ts的、跨平台的、新语言。uts在iOS端编译为swift、在Android端编译为kotli…...

电子电路中的“心脏”:电源铝
前言 Kubernetes 本身并不复杂,是我们把它搞复杂的。无论是刻意为之还是那种虽然出于好意却将优雅的原语堆砌成 鲁布戈德堡机械 的狂热。平台最初提供的 ReplicaSets、Services、ConfigMaps,这些基础组件简单直接,甚至显得有些枯燥。但后来我…...

解放你的无人机!DankDroneDownloader:轻松掌控DJI固件的终极指南
解放你的无人机!DankDroneDownloader:轻松掌控DJI固件的终极指南 【免费下载链接】DankDroneDownloader A Custom Firmware Download Tool for DJI Drones Written in C# 项目地址: https://gitcode.com/gh_mirrors/da/DankDroneDownloader 你知道…...
ArcGIS Pro 范围内汇总、汇总统计数据与交集制表:空间统计三工具全攻略)
(27)ArcGIS Pro 范围内汇总、汇总统计数据与交集制表:空间统计三工具全攻略
点赞+关注送: 1、天地图GS(2024)0650号_2025.9版; 2、全国土地覆盖数据CLCD2025年; 注:其他数据也可私信或留言,看是否有 前言 在GIS项目全流程中,空间统计是连接数据处理…...

书匠策AI:论文写作界的“智能导航仪”,让课程论文创作如行云流水!
在学术的征途中,每一篇课程论文都是一次智慧的探险,既充满挑战也孕育着成长的喜悦。然而,面对浩瀚的知识海洋和复杂的写作规范,许多学子常常感到力不从心,甚至迷失方向。别怕,今天我要为你揭秘一位论文写作…...

2026届最火的六大AI辅助写作工具实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下的学术环境当中,AI论文网站给研究者供给高效的辅助工具,这类平…...

**标题:MLOps实战进阶:用Python+Docker+Kubernetes打造自动化模型部署流水
标题:MLOps实战进阶:用PythonDockerKubernetes打造自动化模型部署流水线 在现代机器学习工程中,模型从实验到上线的全流程自动化已成为企业级落地的关键瓶颈。传统手动部署模式不仅效率低下,还容易因环境差异导致“在我电脑上能跑…...
)
华为OD机考双机位C卷 - 游戏分组 (Java)
游戏分组 2026华为OD机试双机位C卷 - 华为OD上机考试双机位C卷 华为OD机试双机位C卷真题目录(Java)点击查看: 【全网首发】2026华为OD机位C卷 机考真题题库含考点说明以及在线OJ(Java题解) 题目描述 有n(n为2到24之间的偶数,包含2和24)位玩家参与一款在线对战游戏,游…...
)
PHP 8.9 JIT调试稀缺资源包首发:含自研jit-trace-analyzer工具链、12个真实微服务JIT崩溃core dump样本(限前500名下载)
第一章:PHP 8.9 JIT调试稀缺资源包发布说明 PHP 社区正式发布首个面向 PHP 8.9(开发代号“Vesuvius”)的 JIT 调试资源包(JIT Debug Resource Pack, JD-RP v0.1.0),专为深度分析 OPCache JIT 编译行为、寄存…...

WRKFLW性能优化:如何加速大型矩阵构建和工作流执行?
WRKFLW性能优化:如何加速大型矩阵构建和工作流执行? 【免费下载链接】wrkflw Validate and Run GitHub Actions locally. 项目地址: https://gitcode.com/gh_mirrors/wr/wrkflw WRKFLW是一个强大的GitHub Actions本地验证和运行工具,能…...

MySQL 性能调优:索引优化、慢查询分析与千万级数据实战技巧
一、前言在 2026 年的软件开发中,Java 已经成为每一位工程师必须掌握的技能。无论是构建高性能后端服务、开发响应式前端界面,还是维护生产级服务器集群,这项技术都在其中扮演着关键角色。很多开发者在入门阶段会遇到一个普遍问题:…...