Redis-五种数据结构之列表(ziplist、quicklist)
列表
文章目录
- 列表
- 压缩列表-ziplist
- ziplist 定义
- 级联更新
- 快速列表-quicklist
- quicklistNode 定义
- quicklist 定义
- quicklist常用操作
- 其他操作
- quicklist 相对于普通链表优点
- quick应用场景
- 在redis 中使用quicklist
列表数据类型可以存储一组按插入顺序排序的字符串,他很灵活,支持两端插入、弹出数据可以充当栈和队列的角色。
压缩列表-ziplist
链表和数组都可以实现列表类型,Redis 使用的是链表结构,下面是一种常见的链表实现方式:
typedef struct listNode {struct listNode *prev; //上一个数据节点struct listNode *next; //下一个数据节void *value; //数据内容
} listNode;typedef struct list {listNode *head;listNode *tail;void *(*dup)(void *ptr);void (*free)(void *ptr);int (*match)(void *ptr, void *key);unsigned long len;
} list;
Redis 内部使用该链表来保存运行数据,比如主服务器下的所有从服务器的信息。
但Redis 并不使用该链表来保存用户列表的数据,因为他对内存管理不够友好,原因如下:
- 链表的每个节点都占用一块独立的内存,导致了内存碎片古过多。
- 链表节点中前后节点指针占用过多的额外内存。
那数组就可以完美的解决这两个问题
ziplist就是一个类似数组的紧凑型链表,他会申请一整块的内存,在这个内存上存放所有的数据,
这就是ziplist的设计思想。
ziplist 定义
ziplist 的总体布局如下
…
- zlbytes:ziplist的长度。 4字节
- zltail:ziplist头部到末尾元素的长度,通过zltail字段可以很方便获取末尾元素的地址。4字节
- zllen:元素的个数,最大可以存放65535个元素。2字节
- zlend:结束标志,值固定为0xFF。
- entry: ziplist 中保存的节点 1字节
节点布局
-
entry-data : 该节点元素,即节点存储的数据
-
prevlen: 记录前驱节点的长度,该属性的长度为1字节或者5字节
- 如果前一个元素长度小于254,则该属性占用1byte
- 否则,第一个字节固定为254,剩余4byte存放前一个元素的长度,不为255的原因是255和结尾标志重复
-
enconding:表示编码类型有以下几种:
-
字符串编码:字符串类型有1、2、5三种编码长度,前两位表示编码类型,剩余位表示字符串长度
00|aaaaaa:存储长度小于等于63byte的字符串。 01|aaaaaa bbbbbbbb:存储长度小于等于16383byte的字符串。 10|...... bbbbbbbb cccccccc dddddddd eeeeeeee:存储长度小于等于4294967295byte的字符串,'.'固定为0。 -
整型编码
1100 0000:表示16位有符号整数,entry-data占用2byte。 1101 0000:表示32位有符号整数,entry-data占用4byte。 1110 0000:表示64位有符号整数,entry-data占用8byte。 1111 0000:表示24位有符号整数,entry-data占用3byte。 1111 1110:表示8位有符号整数,entry-data占用1byte。 1111 0001 - 1111 1101:没有entry-data部分,依次表示整数0-12。
-
级联更新
级联更新是指因为插入、删除、更新等操作导致后续连续多个元素出现更新的现象。核心原因是ziplist的每个元素存放着上一个元素的长度。最差情况下,后面所有元素都得更新,但是这种情况很少见。
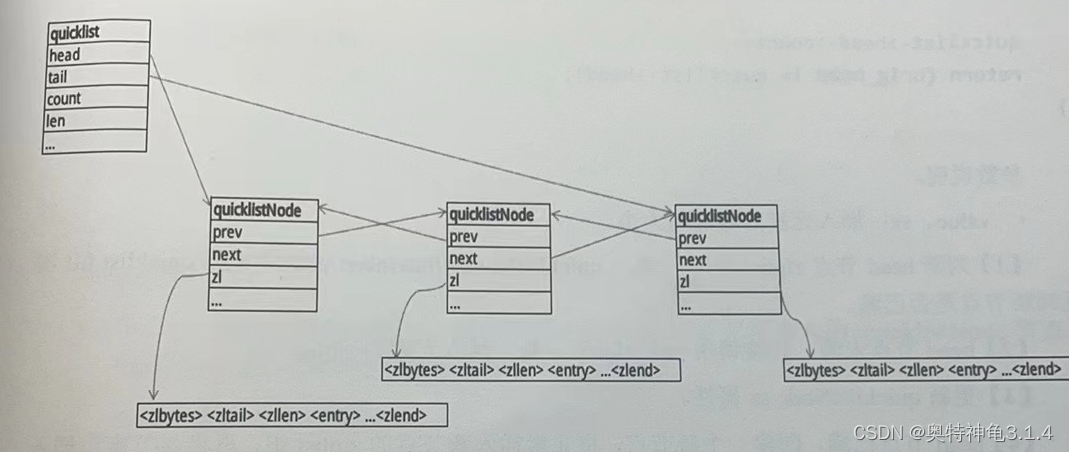
快速列表-quicklist
quicklist 的设计思想很简单,将一个ziplist 拆分成多个短的ziplist ,避免插入或者删除元素时会导致大量内存拷贝
**quicklist 其实就是简单的双链表,但每个双链表节点中保存一个 ziplist,**然后每个 ziplist 中存一批 list 中的数据 (具体 ziplist 大小可配置),这样既可以避免大量链表指针带来的内存消耗,也可以避免 ziplist 更新导致的大量性能损耗,将大的 ziplist 化整为零。
quicklistNode 定义
typedef struct quicklistNode {struct quicklistNode *prev;struct quicklistNode *next;unsigned char *zl; // quicklist节点对应的ziplist -指向了一个 ziplist 结构unsigned int sz; // ziplist的字节数 unsigned int count : 16; // ziplist的元素数量unsigned int encoding : 2; // 数据类型,2表示节点已压缩,1表示节点未压缩unsigned int container : 2; // 目前固定为2 表示使用ziplist 存储数据unsigned int recompress : 1; // 1表示暂时解压,后续需要时再将其解压- 表示该节点是否需要重新压缩。unsigned int attempted_compress : 1; // 节点无法压缩;太小了 unsigned int extra : 10; // 预留暂未使用
} quicklistNode;
quicklist 定义
当链表很长时,中间节点的访问频率较低,这时Redis 会将中间节点进行压缩,更进一步的节省内存空间–采用LZF压缩
//压缩后的节点定义
typedef struct quicklistLZF {size_t sz; // 压缩后的ziplist大小char compressed[];//存放压缩后的ziplist字节数组
} quicklistLZF;typedef struct quicklist {quicklistNode *head; /* 头结点 */quicklistNode *tail; /* 尾结点 */unsigned long count; /* 在所有的ziplist中的entry总数 */unsigned long len; /* quicklist节点总数 */int fill : QL_FILL_BITS; /* 16位,每个节点的最大容量 */unsigned int compress : QL_COMP_BITS; /* 16位,quicklist的压缩深度,0表示所有节点都不压缩,否则就表示从两端开始有多 少个节点不压缩 */unsigned int bookmark_count: QL_BM_BITS; /*4位,bookmarks数组的大小,bookmarks是一个可选字段,用来quicklist重新 分配内存空间时使用,不使用时不占用空间*/quicklistBookmark bookmarks [];
} quicklist;
其中,fill 和 compress 是两个重要的字段,它们决定了 quicklist 的内存和性能特性。
- fill 表示每个 quicklistNode 节点的最大容量,不同的数值有不同的含义,默认是 -2,当然也可以配置为其他数值,具体数值含义如下:
| fill | 含义 |
|---|---|
| -1 | 每个 quicklistNode 节点的 ziplist 所占字节数不能超过 4kb。 |
| -2 | 每个 quicklistNode 节点的 ziplist 所占字节数不能超过 8kb。 (默认配置&建议配置) |
| -3 | 每个 quicklistNode 节点的 ziplist 所占字节数不能超过 16kb。 |
| -4 | 每个 quicklistNode 节点的 ziplist 所占字节数不能超过 32kb。 |
| -5 | 每个 quicklistNode 节点的 ziplist 所占字节数不能超过 64kb。 |
| 任意正数 | 表示:ziplist 结构所最多包含的 entry 个数,最大为 215215。 |
- compress 表示 quicklist 的压缩深度,0 表示所有节点都不压缩,否则就表示从两端开始有多少个节点不压缩。例如,compress 为 1 表示从两端开始,有 1 个节点不做 LZF 压缩。LZF 是种无损压缩算法。Redis 为了节省内存空间,会将 quicklist 的节点用 LZF 压缩后存储,但这里不是全部压缩,可以配置 compress 的值。
quicklist常用操作
- 创建
quicklist *quicklistCreate(void); // 创建quicklist
quicklist *quicklistNew(int fill, int compress); // 用一些指定参数创建一个新的quicklist
void quicklistSetCompressDepth(quicklist *quicklist, int depth); // 设置压缩深度
- 头插和尾插
void quicklistPushHead(quicklist *quicklist, void *value, size_t sz); // 头插
void quicklistPushTail(quicklist *quicklist, void *value, size_t sz); // 尾插
- 头删和尾删
int quicklistPop(quicklist *quicklist, int where, unsigned char **data, size_t *sz, long long *slong); // 头删或尾删
- 查找
查找操作需要遍历整个 quicklist,对每个 ziplist 进行查找。如果找到了匹配的元素,就返回一个 quicklistEntry 结构体,表示该元素在哪个 ziplist 中,以及在 ziplist 中的位置。
typedef struct quicklistEntry {const quicklist *quicklist; //指向所属的quicklist的指针quicklistNode *node; //指向所属的quicklistNode节点的指针unsigned char *zi; //指向当前ziplist结构的指针unsigned char *value; //查找到的元素如果是字符串,则存在value字段long long longval; //查找到的元素如果是整数,则存在longval字段 size_t sz; //保存当前元素的长度int offset; //保存查找到的元素距离压缩列表头部/尾部隔了多少个节点
} quicklistEntry;int quicklistIndex(const quicklist *quicklist, const long long idx, quicklistEntry *entry); // 根据索引查找元素
void quicklistRewind(const quicklist *quicklist, quicklistIter **iter); // 创建一个从头开始的迭代器
void quicklistRewindTail(const quicklist *quicklist, quicklistIter **iter); // 创建一个从尾开始的迭代器
int quicklistNext(quicklistIter *iter, quicklistEntry *node); // 迭代器获取下一个元素
void quicklistReleaseIterator(quicklistIter *iter); // 释放迭代器
- 删除
删除操作需要先找到要删除的元素在哪个 ziplist 中,然后调用 ziplist 的删除函数删除该元素。如果删除后导致 ziplist 空了,就把整 个 ziplist 节点从链表中删除
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry); // 删除迭代器指向的元素
int quicklistDelRange(quicklist *quicklist, const long start, const long stop); // 删除指定范围内的元素
其他操作
除了上面介绍的操作,quicklist 还有一些其它的操作,例如:
quicklistRotate(quicklist *quicklist); // 将尾部的元素移动到头部
quicklistDup(quicklist *orig); // 复制一个 quicklist
quicklistRelease(quicklist *quicklist); // 释放一个 quicklist
quicklistCompare(unsigned char *p1, unsigned char *p2, int p2_len); // 比较两个元素是否相等
quicklist 相对于普通链表优点
- 节省内存空间,因为每个节点是一个压缩列表,可以存储多个元素,并且可以根据配置进行 LZF 压缩。
- 降低更新复杂度,因为每次插入或删除元素时,只需要更新对应的压缩列表,而不需要重新分配整个链表的内存空间。
- 提高查询效率,因为每个节点有一个计数器,可以快速定位到目标元素所在的压缩列表,而不需要遍历整个链表。
quick应用场景
quicklist 的应用场景主要是在需要使用 list 类型的数据结构时,例如:
- 存储有序的数据,如时间线、消息队列、日志等。
- 实现栈或队列的功能,如 LIFO 或 FIFO 的数据结构。
- 实现发布订阅模式,如使用 BLPOP 或 BRPOP 命令阻塞地弹出元素。
- 实现阻塞队列,如使用 LPUSH 和 RPOP 命令实现生产者消费者模式
在redis 中使用quicklist
在 Redis 中使用 quicklist 的方法很简单,只需要使用 list 类型的命令,
如 lpush, rpush, lpop, rpop 等,就可以自动创建和操作 quicklist。
Redis 会根据配置文件中的参数,如 list-max-ziplist-size, list-compress-depth 等,来决定 quicklist 的结构和压缩策略。
你不需要关心 quicklist 的内部实现细节,只需要按照 list 的语义来使用即可。
相关文章:
Redis-五种数据结构之列表(ziplist、quicklist)
列表 文章目录 列表压缩列表-ziplistziplist 定义级联更新 快速列表-quicklistquicklistNode 定义quicklist 定义quicklist常用操作其他操作quicklist 相对于普通链表优点quick应用场景在redis 中使用quicklist 列表数据类型可以存储一组按插入顺序排序的字符串,他很…...
记一次全设备通杀未授权RCE的挖掘经历
想来上一次挖洞还在一年前的大一下,然后就一直在忙活写论文,感觉挺枯燥的(可能是自己不太适合弄学术吧QAQ),所以年初1~2月的时候,有空的时候就又会挖一挖国内外各大知名厂商的设备,拿了几份思科…...

【数据库编程-SQLite3(一)】sqlite3数据库在Windows下的配置及测试
学习分析 1、资源准备2、环境配置2.1、将资源包下载解压缩保存。2.2、在QT中创建工程,配置环境 3、测试配置3.1、 sqlite3_open函数3.2、sqlite3_close函数3.3、代码测试 1、资源准备 资源包 2、环境配置 2.1、将资源包下载解压缩保存。 解压缩得到以下文件 2.2、在QT中创建…...

YOLOv10改进 | 主干篇 | YOLOv10引入华为VanillaNet替换Backbone
1. VanillaNet介绍 1.1 摘要: 基础模型的核心是“越多越好”的理念,计算机视觉和自然语言处理领域取得的惊人成功就是例证。 然而,优化的挑战和变压器模型固有的复杂性要求范式向简单性转变。 在这项研究中,我们介绍了 VanillaNet,一种设计优雅的神经网络架构。 通过避免…...

C++ 迷宫问题
描述 定义一个二维数组 N*M ,如 5 5 数组下所示: int maze[5][5] { 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, }; 它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走…...

【Linux】Linux文件系统中主要文件夹列举_作用说明
在Linux系统中,文件夹(或称为目录)的组织结构是系统功能和用户数据的重要组成部分。以下是Linux系统中一些主要文件夹的列举及其作用说明: / (根目录): 是Linux文件系统的起点。通常只包含其他目录,不建议直接在其中存…...

移植案例与原理 - HDF驱动框架-驱动配置(1)
HCS(HDF Configuration Source)是HDF驱动框架的配置描述源码,内容以Key-Value为主要形式。它实现了配置代码与驱动代码解耦,便于开发者进行配置管理。应该,类似Linux DTS(Device Tree Source)设备树。 HC-GEN(HDF Configuration Generator)是…...
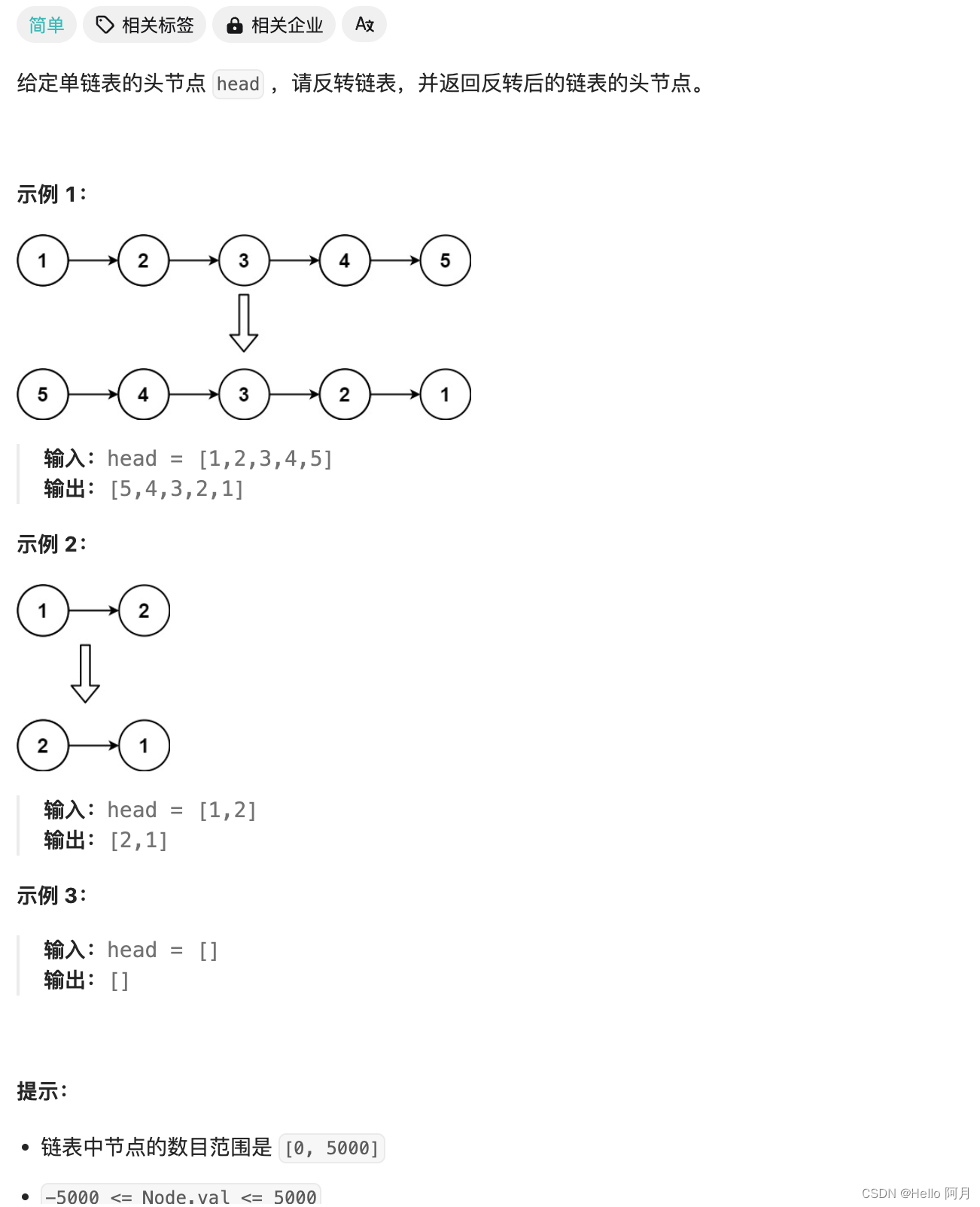
坚持刷题|反转链表
文章目录 题目思考实现1. 迭代方式实现链表翻转2. 递归方式实现链表翻转 Hello,大家好,我是阿月。坚持刷题,老年痴呆追不上我,今天继续链表:反转链表 题目 LCR 024. 反转链表 思考 翻转链表是一个常见的算法问题&a…...
升级和维护老旧LabVIEW程序
在升级老旧LabVIEW程序至64位环境时,需要解决兼容性、性能和稳定性等问题。本文从软件升级、硬件兼容性、程序优化、故障修复等多个角度详细分析。具体包括64位迁移注意事项、修复页面跳转崩溃、解决关闭程序后残留进程的问题,确保程序在新环境中的平稳运…...

sqlite数据库整体迁移进mysql整个流程并解决中文异常问题
咨询【QQ】 sqlite轻量数据还行,随着数据量增大,不得不迁移进mysql 首先 电脑执行 sqlite3 db.sqlite3 .dump > dump.sql 会把整个sqlite的数据导出进 dump.sql中 紧接着我们把sqlite的sql转换成mysql的sql语句,因为mysql语句和 sq…...

Hadoop3:MapReduce中的Partition原理及自定义Partition
一、默认Partition分区配置 以WC案例来进行验证。 1、设置setNumReduceTasks 修改的代码 这行代码,确定了reduceTask的数量,也确定了分区逻辑 在mapper文件中,打上断点 计算分区的代码 这里会对每一个kv进行计算,然后&#…...
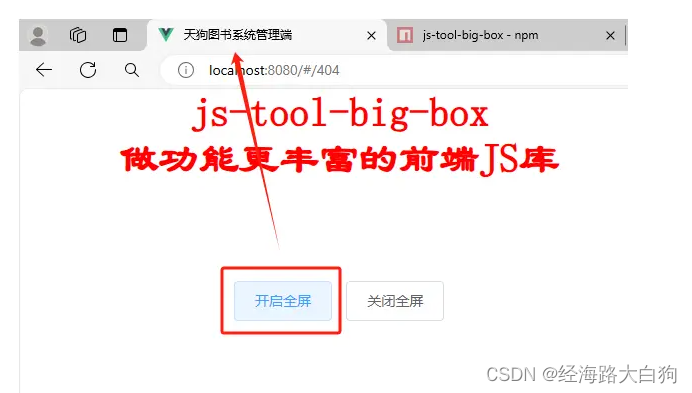
就因为没在大屏项目加全屏按钮,早上在地铁挨了领导一顿骂
“嗯嗯”,“嗯嗯”,“那产品也没说加呀”,“按F11不行吗?”,“嗯嗯”,“好的”。 早上在4号线上,我正坐在地铁里,边上站着的妹子,我看他背着双肩包,打着电话…...
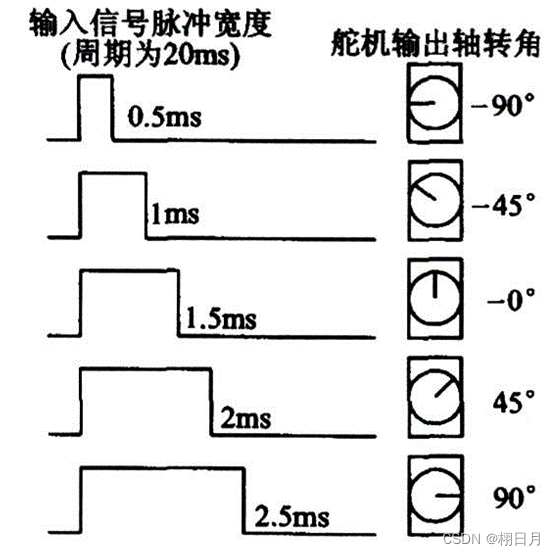
STM32学习记录(八)————定时器输出PWM及舵机的控制
文章目录 前言一、PWM1.工作原理2.内部运作机制3. PWM工作模式4.PWM结构体及库函数 二、PWM控制舵机 前言 一个学习STM32的小白~ 有错误评论区或私信指出提示:以下是本篇文章正文内容,下面案例可供参考 一、PWM 1.工作原理 以向上计数为例࿰…...

Vue CLI,Vue Router,Vuex
前言 Vue CLI、Vue Router 和 Vuex 都是 Vue.js 生态系统中的重要组成部分,它们在构建 Vue 应用程序时扮演着关键角色。 Vue CLI Vue CLI 介绍 Vue CLI 是 Vue.js 的官方命令行工具,用于快速搭建 Vue.js 项目。它提供了一个图形界面(通过…...

互联网广告相关概念
互联网广告概念涉及多个关键指标和定价模式,它们帮助广告主和广告平台衡量广告效果、优化广告投放策略,并计算广告成本。以下是互联网广告中一些核心概念的简要概述: 1.ROI (投资回报率) 衡量广告投资的效益,计算公式为ÿ…...

如何在服务器上部署一个java程序
如何在服务器上部署一个java程序? 一、在服务器上安装jdk环境 1.创建目录用于存放jdk文件 cd /usr/local 2.下载最新版oracle jdk22 wget https://download.oracle.com/java/22/latest/jdk-22_linux-x64_bin.tar.gz 3.解压 tar -zxf jdk-22_linux-x64_bin.ta…...

白酒:中国的酒文化的传承与发扬
中国,一个拥有五千年文明史的国度,其深厚的文化底蕴孕育出了丰富多彩的酒文化。在这片广袤的土地上,酒不仅仅是一种产品,更是一种情感的寄托,一种文化的传承。云仓酒庄的豪迈白酒,正是这一文化脉络中的一颗…...

算法金 | 再见!!!梯度下降(多图)
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 接前天 李沐:用随机梯度下降来优化人生! 今天把达叔 6 脉神剑给佩奇了,上 吴恩达:机器…...
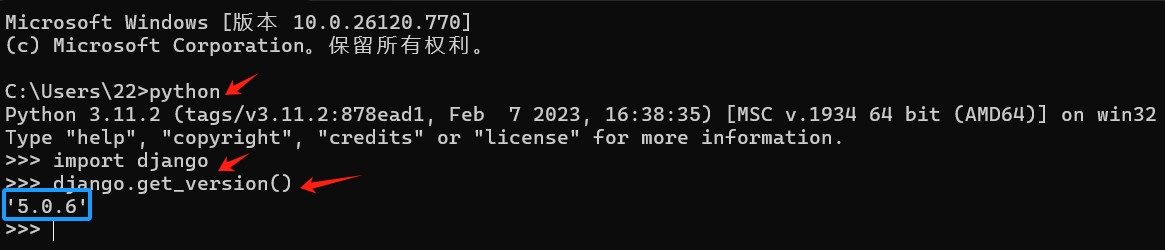
python Django安装及怎么检测是否安装成功
一、winr 输入cmd 进入控制台。输入pip install Django5.0.1 二、如果安装过程没有问题。就进行下一步进行检查是否成功安装。 三、 1.在控制台输入python,进入python环境 2.输入 import django 3.继续输入 django.get_version()。显示版本号表示成功安装。...

Swift开发——存储属性与计算属性
Swift语言开发者建议程序设计者多用结构体开发应用程序。在Swift语言中,结构体具有了很多类的特性(除类的与继承相关的特性外),具有属性和方法,且为值类型。所谓的属性是指结构体中的变量或常量,所谓的方法是指结构体中的函数。在结构体中使用属性和方法是因为:①匹别于结…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...

boost::filesystem::path文件路径使用详解和示例
boost::filesystem::path 是 Boost 库中用于跨平台操作文件路径的类,封装了路径的拼接、分割、提取、判断等常用功能。下面是对它的使用详解,包括常用接口与完整示例。 1. 引入头文件与命名空间 #include <boost/filesystem.hpp> namespace fs b…...

HTTPS证书一年多少钱?
HTTPS证书作为保障网站数据传输安全的重要工具,成为众多网站运营者的必备选择。然而,面对市场上种类繁多的HTTPS证书,其一年费用究竟是多少,又受哪些因素影响呢? 首先,HTTPS证书通常在PinTrust这样的专业平…...